
基于粒子群优化算法的Hadoop调度算法研究
2015-03-18 05:21刘盼红
河北工程大学学报(自然科学版) 2015年1期
刘盼红
(河北工程大学信息与电气工程学院,河北邯郸056038)
近年来,随着互联网、物联网、移动网络、传感网络等各种新技术在各行各业的渗透式应用,数据呈现爆炸式的增长,对海量数据的处理与分析被称为“大数据”[1]。Hadoop,以一种可靠、高效、可伸缩的方式进行数据处理,为处理海量数据提供了一个很好的解决方案[2]。任务调度器是Hadoop中最核心的组件,负责整个集群资源的管理和分配。因此调度算法的好坏直接影响到Hadoop平台的整体性能和集群的资源利用率[3]。Hadoop自带的调度算法在处理混合作业时没有考虑资源负载均衡的问题,在调度各节点任务时,没有达到一种最优的状态。基于以上问题,文中考虑到混合作业的特点提出了一种基于粒子群优化算法的调度算法,以便可以更高效全面的进行任务调度,平衡资源负载,减少数据处理时间,提高平台性能。
1 Hadoop任务调度
1.1 Hadoop原有的任务调度算法
默认调度器FIFO。FIFO将所有用户提交的作业都放到一个队列中,并将作业按照优先级高低和提交的先后顺序进行排序,然后按此队列的顺序执行作业。优点是实现非常简单、调度过程快;缺点是资源的利用率不高。
计算能力调度算法Capacity Schedule。Capacity Schedule[4]采用多个队列,每个队列分配一定的系统容量,空闲资源可以动态分配给负荷重的队列,支持作业优先级;优点是支持多作业并行执行,提高资源利用率,动态调整资源分配,提高作业执行效率;缺点是用户需要了解大量系统信息,才能设置和选择队列。
公平调度算法 Fair Schedule。Fair Schedule[5]将作业分组形成作业池,每个作业池分配最小共享资源,然后将多余的资源平均分配给每个作业;优点是支持作业分类调度,提高服务质量,动态调整并行作业数量,充分利用资源;缺点是不考虑节点的实际负载状态,导致节点负载实际不均衡。
2 基于PSO的调度算法
粒子群优化算法(Particle Swarm Optimization,简称PSO)最早是由J.Kennedy和电气工程师R.Eberhart模拟自然界的生物群体觅食而提出的一种优化方法[6],通过粒子之间的集体协作来交换信息并作出决策。算法采用迭代的方式,使每个粒子向找到的最佳位置和群体中最佳粒子靠近,从而搜索到最优解。
本文将粒子群算法引入到大数据处理框架Hadoop中,用于解决任务调度的问题。采用粒子群算法进行作业调度时,任务被作为粒子,资源池即为搜索空间,粒子寻找最优解的过程即为任务调度的过程[7-8],通过为任务赋予其在资源池中的初始位置和速度信息,并对其速度和位置进行迭代更新,最终形成任务和资源的映射关系。
2.1 相关定义
定义 1:集合T={t1,t2,…,tn}表示待分配的n个任务。
定义2:集合R={r1,r2,…,rm}表示 YARN 资源管理系统中m个Container资源。
执行时间。其中元素eij(i=1,2,…,m;j=1,2,…,n)表示任务ti在rj个 Container资源上的执行时间。
2.2位置和速度的更新
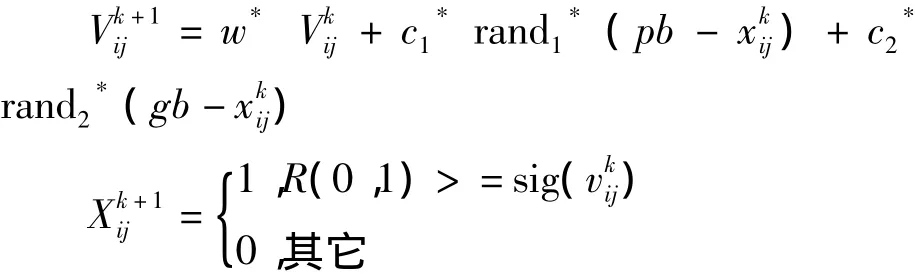
其中,c1、c2为学习因子,w为权重参数,rand()、R(0,1)是出于0和1之间的随机数,pb和gb分别表示个体极值和全局极值所对应的位置,表示粒子当前位置。
2.3 确定目标函数
Container资源节点rj上执行的任务时间为H,任务的完成时间计算公式为T=max(H(rj))。
2.4 算法的实现
采用PSO进行调度的具体步骤如下:
1)接收用户提交的任务,并把每个任务划分为若干个子任务。
2)初始化算法参数(c1、c2、w等),随机产生初始种群,设定每个粒子的位置和速度初始值,设定最大迭代数。
3)通过目标函数计算每个粒子的适应度函数值,比较粒子当前适应值与自身历史最优值,若当前粒子优于历史最优值,则当前粒子替代历史最优值作为个体最优pb;否则pb取历史最优。
4)比较粒子种群的适应度函数值,从所有粒子中选取最小的作为最优粒子,最优粒子值作为群体最优值gb。
5)利用速度更新公式,更新每个粒子的速度及位置信息。
6)判断是否达到最大迭代次数,若没有,则重复步骤(3)(4)(5)。达到迭代次数则输出最优结果,算法结束。采用PSO进行调度的流程图如图1所示。

3 实验结果
3.1 实验环境
集群环境配置如表1所示。

表1 实验环境配置Tab.1 The experimental environment configuration
3.2 实验结果及性能分析
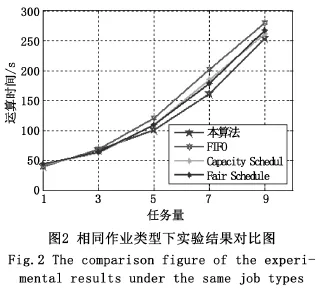
1)处理相同作业的性能。本实验在Hadoop系统中将本算法与Hadoop现有的FIFO算法、Capacity Schedule计算能力调度算法和Fair Schedule公平调度算法进行对比验证,将此四种算法分别作为调度方法,提交1~10个相同的WordCount作业,每个WordCount作业处理相同的128MB文本文件,记录其作业。其中,运算时间通过代码获取运算开始及结束的计算机系统时间相减得到。为减少误差,同样的实验进行5次运算取平均值,效果对比图如图2所示。
2)处理不同类型作业的性能。实验将一个WordCount作业、一个Teragen作业与一个Terasort作业作为一个作业组。WordCount作业属于统计词频的CPU资源密集型作业;TeraGen作业属于随机生成数据的磁盘I/O密集型作业;TeraSort作业是对输入数据进行排序的作业,它既是CPU密集型的也是磁盘密集型的。其中WordCount作业处理128 MB的文本文件,Teragen作业生成一个500 M的数据集,Terasort则对一个事先已经生成好的500 MB的数据进行排序。同时运行1~5组这样的作业组,记录其平均运行时间。效果对比图如图3所示。

从图2、图3中可以看出使用本文提出的调度算法平均运行时间是最少的。实验证明本算法针对不论是相同类型的作业还是面对负载不均衡的不同类型的作业都能较好的完成调度任务,使得整体运算效率较高。
4 结语
采用粒子寻优策略,找到调度层面最优的粒子进行寻优,以减少调度计算所用的时间。通过在实际Hadoop平台的测试和分析表明,本文提出的调度算法能够很好的平衡不同类型作业之间的负载,减少作业运行时间,提高了平台性能。
[1]MANYIKA J,CHUI M,BROWN B,et al.Big data:The next frontier for innovation,competition,and productivity[J].Communications of the ACM,2011,56(2):100-105.
[2]SHVACHKO K,KUANG H,RADIA S,et al.The hadoop distributed file system[C]//Mass Storage Systems and Technologies(MSST),2010 IEEE 26th Symposium on.IEEE,2010:1-10.
[3]曹 英.大数据环境下 Hadoop性能优化的研究[D].大连:大连海事大学,2013.
[4]Capacity Scheduler for Hadoop[EB/OL].http://hadoop.apache.org/docs/current/hadoop-yarn/hadoopyarn -site/CapacityScheduler.html,2014 -09 -05.
[5]Fair Scheduler for Hadoop[EB/OL].http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarnsite/FairScheduler.html,2014 -09 -05.
[6]李爱国,覃征.粒子群优化算法[J].计算机工程与应用,2002,38(21):1-3.
[7]刘素芹,王 婧,李兴盛,等.基于粒子群优化算法的集群调度策略[J].郑州大学学报:理学版,2010,42(2):43-46.
[8]张京军,刘文娟,刘光远.基于改进免疫遗传算法的网格任务调度[J].河北工程大学:自然科学版,2013,30(2):80-83.
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
军营文化天地(2018年2期)2018-12-15
浙江工业大学学报(2017年5期)2018-01-22
产品可靠性报告(2017年7期)2017-09-05
