
中文社会化信息搜寻系统比较研究*
2015-03-19 06:17陆阳琪杨建林王丽雅
图书与情报 2015年4期
陆阳琪 杨建林 王丽雅
(1.南京大学信息管理学院 江苏南京 210023)
(2.江苏省数据工程与知识服务重点实验室 江苏南京 210023)
1 引言
随着Web2.0、Web3.0的提出,现有的信息搜索模式也出现了改变,社会化搜索已具备雏形。社会化搜索一般是指利用在线社会网络、社会化媒体、社会化标注系统等社会化信息系统,将搜索引擎技术与用户的社会关系图(Social Graph)结合起来,以达到提高搜索质量与相关度的目的。相对于传统的搜索,社会化搜索更依靠用户,用户可以一边分享知识和经验,一边获得帮助。短期内,社会化搜索可以改善用户的搜索体验,长期来看可以帮助用户加入自己感兴趣的圈子和社区,进一步提高搜索的准确率和信任度,增强用户的黏性。
当前的社会化搜索系统主要有两类,社交化问答系统和社交反馈系统。社交化问答系统是介于百科和传统问答之间的问答类SNS系统,是一个公共的知识平台,它的价值在于重建人与信息的关系。用户提出问题,其他用户来回答,答案可以来自不同社交亲近性的用户,可以是关系紧密的朋友和工作伙伴,也可以是陌生人。社交反馈系统利用社交注意力数据来对检索结果进行排序,这种系统包含许多用户的注意力数据和反馈。系统获取用户的注意力数据和反馈主要有两种方式,一是隐式地从用户日志获取,二是直接让用户来投票、添加标签和书签。
社会化信息搜寻这一概念是互联网应用发展到一定阶段的产物,目前社会化信息搜寻的主要研究成果主要集中在影响因素分析、模型构建等方面。本文选取了国内现有的三个典型社会化搜寻网站 (知乎、豆瓣和果壳),从基本功能、社会化程度等方面进行比较研究,以对社会化信息搜寻网站的进一步完善与发展提出建议、推动社会化信息搜寻的理论研究发展。
2 社会化信息搜寻网站介绍
Evans认为任何包含社会交互的信息搜寻都是社会化信息搜寻,社会交互与协作的目的是为了促进信息搜寻和意义建构。一般来说,用户的信息行为主要包括:信息需求认识与表达行为、信息查寻行为、信息交互行为、信息选择行为、信息吸收与利用行为。在整个循环过程中,每一阶段都存在不同形式的社会化。信息需求来源于外部需求和内部需求,外部需求包括来自客户、领导等的信息需求,内部需求包括自身为了完成各种需求进行的信息寻求行为。在信息需求认识与表达阶段,用户通常会向他人寻求意见、经验从而不断改善,形成最佳表达式。信息搜寻过程中,包括信息查寻、信息交互、信息选择行为,根据Evans的实验结果,大部分用户在搜索过程中都存在一定程度的信息交换行为。对于搜索到的结果大部分用户会采取行动进行重新组织和利用,并可能与有同样信息需求的人共享结果。
本文选取了知乎、豆瓣、果壳三个典型的中文社会化搜索网站,这些网站在国内的知名度和实用性都很高,又各具特色,具有一定的典型性。
2.1 知乎
知乎是类似于Quora的一个中文网络问答社区,在产品设计上,用户在社区内不仅仅可以提出问题或解答,还可以跟随其他用户、问题和话题,从关注人和关注事两个不同维度来更好地发现内容。在问题答案中,用户可以用类似Digg的支持机制,给好的答案投票,将好的答案顶到页面靠上的位置。每个问题也设立了“答案总结”区域,像维基百科一样,每个用户都可以修改总结。图1显示了“知乎”的主要问答功能,用户可以关注任何其他用户,可以向他提问、回答他的问题,关注问题和赞同他的答案;用户也可以关注感兴趣的问题和话题,每个话题都包含一些问题,其中有些已经有人回答了,用户可以阅读它们,给自己喜欢的答案投票,对无效的回答点击没有帮助。用户还可以单独关注某一个问题,持续追踪这个问题的最新答案。
2.2 豆瓣
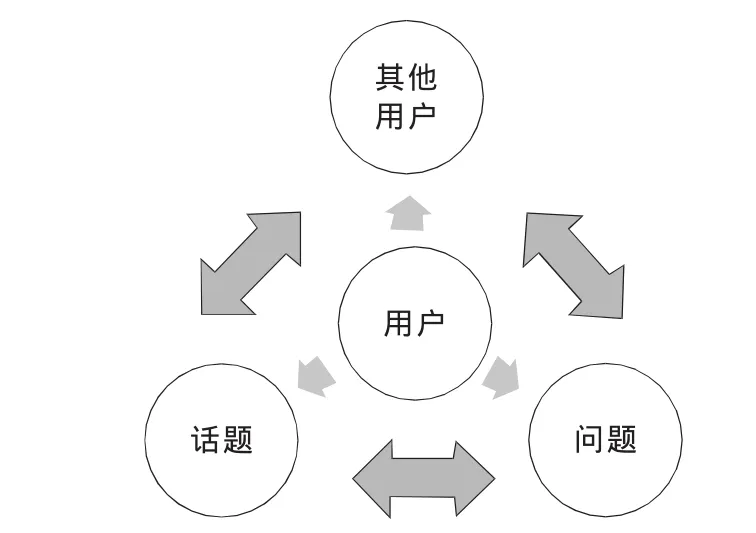
图1 “知乎”问答社区功能示意图
豆瓣表面上看是一个评论网站,实际上它却提供了书目推荐和以共同兴趣交友等多种服务功能,它更像一个集BLOG、交友、小组、收藏于一体的新型社区网络。豆瓣呈现给每个注册用户的主页各不相同,而且同一个用户在不同时间上豆瓣,也会看到不同的首页。与大多数网站不同的是,豆瓣的早期版本是一套基于数学统计模型的推荐引擎,能够在用户点击过、看过内容以后自动分析出“与其口味最像的人”,并主动推荐用户最有可能喜欢的书籍、音乐或者电影。豆瓣由用户的标签来决定分类,使用频率高的标签分类排在前面,不准确的分类会被淘汰。
如图2所示,用户在网络上发现自己喜欢的内容(好书好碟、精彩评论、好看相册、有趣活动、文章、网页、视频等)都可以“推荐”。用户推荐的内容及推荐语会出现在“友邻广播”里,第一时间被朋友们知晓,同时用户也会获得朋友们推荐的内容。豆瓣由各种各样的“兴趣小组”构成,以个人为核心,跟每个用户自己的兴趣有关,豆瓣再根据用户喜爱的东西找到志同道合者,然后通过他们找到更多的好东西。
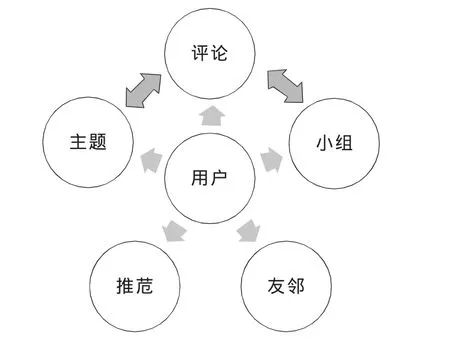
图2 “豆瓣”主要功能示意图
2.3 果壳
果壳网可看作是一个开放、多元的泛科技兴趣社区。在这里用户可以关注自己感兴趣的人,阅读他们的推荐,也可以将有意思的内容分享给关注的人;用户依据兴趣关注不同的小组,精准阅读喜欢的内容,并与网友交流;在“果壳问答”里提出困惑自己的科技问题,或者提供靠谱的答案。果壳网现有四大版块:主题站、小组、MOOC(大型开放式网络课程)学院和问答,如图3所示。主题站是由果壳网编辑部策划制作的内容版块,每个主题站的文章都围绕着一个共同的主题,比如专注于破解各种谣言和误区的谣言粉碎机、关注数学和逻辑的死理性派等。果壳网的主要功能与知乎、豆瓣相似,它们之间最大的不同就是果壳网定位在负责任、有智趣的泛科技主题内容。
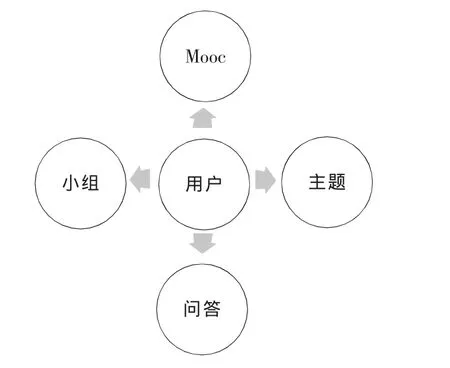
图3 “果壳”主要功能示意图
3 社会化信息搜寻网站比较
3.1 基本功能的异同
本文选取的社会化信息搜寻网站侧重各有不同,对于基本功能的比较,主要从用户界面、互动方式、开放程度3个方面展开分析。
(1)用户界面。界面是这些社会化搜索网站给用户的第一印象,对用户体验有一定影响。知乎采用象征严肃和优雅的蓝色作为主色调,用户界面设计美观,对产品体验的细节要求极为苛刻。豆瓣非常精巧地应用DIV和ESS,并且通过色系的运用,最大限度减少图片方式就使得网站页面清新可人。果壳页面选择蓝色、绿色、灰黑为主色调,给人感觉理性严谨。总体而言这三个网站页面排版都比较简洁、图文兼备。
(2)互动方式。知乎用户除了查看最新问题及回答之外,也可以通过 “设置”、“关注问题”、“添加评论”“分享”、“感谢”和“收藏”等功能参与到自己感兴趣的问题中。知乎作为互联网问答网站不仅要强调人与互联网的互动,同时也强调用户与用户或用户与行业专家之间的互动。知乎用户可以通过提问、回答、评论、私信的方式与其他用户或行业专家进行交流,同时可以对答案进行感谢、分享、收藏或举报。
豆瓣用户可以自由发表有关书籍、电影、音乐等的评论,在豆瓣上点击其他用户的名字或头像,可以看到他们的简单介绍、收藏、推荐和发表过的评论。如果觉得这个人有意思,或者口味相投,可以点击“把他/她加入我的友邻”。用户把这些趣味相投的人加入友邻后形成自己的小圈子。用户可以留言、评论、推荐和发豆邮与其他用户交流。
果壳问答类似于知乎,用户可以关注其他用户,可以发站内信交流,可以“@”其他用户。果壳的新模块“在行”用户可以发起约见,根据自己的问题找到适合的行家发出申请,行家与用户了解情况选择约见时间地点。这种新型互动方式将线上交流转移到线下了,果壳成为了服务提供的第三方平台,至于效果如何,还得时间来考证。
(3)开放程度。开放程度不仅对用户操作有影响,对网站本身的管理也很重要。过严会对用户造成不便,而过松则会加重网站管理难度。知乎可以用邮箱注册账号,或者直接用新浪微博账号或者QQ登录;豆瓣只能邮箱注册;果壳可以邮箱注册,也可以用新浪微博账号、QQ或豆瓣账号直接登录。知乎、果壳、豆瓣大致遵循一个原则,注册用户拥有提问、回答和相关权利,游客只能搜索和浏览。如果没有注册直接浏览知乎,浏览有限内容后就会跳出登录窗口,否则无法继续浏览其他内容;当浏览豆瓣页面时,也会跳出登录窗口,但是不登录不影响浏览阅读;果壳的科学人和小组可以直接浏览,但问答模块和MOOC学院需要登录才能浏览。
3.2 社会化方式方面的异同
信息检索主要涉及4个方面,即信息资源、用户需求表达、信息资源与用户需求的匹配、结果排序,对这4个方面的社会化改造形成社会化信息检索。因此,本文从内容来源、资源标注、需求表达、结果排序来比较网站在社会化方式方面的异同。
(1)内容来源。用户生成内容(User-Generated-Content,UGC)泛指以任何形式在网络上发表的由用户创作的文字、图片、音频以及视频等内容,是Web2.0环境下社会化媒体中一种新兴的网络信息资源创作与组织模式,它有别于传统的权威生成、中心辐射形式,倡导为用户创建一个参与表达、创造、沟通和分享的环境,用户的参与行为也逐渐从原先的全民上网转变为全民织网,即除了传统的点击浏览行为,用户还可以在网上开辟自己的信息空间,并进行信息共享、内容创作以及贡献等行为。赵宇翔等将UGC中的内容分为娱乐型、社交型、商业型、兴趣型和舆论型。
作为Web2.0的产物,知乎、豆瓣、果壳这三大网站的大部分内容都来自用户创作,且为社交型和兴趣型内容。社交型内容主要指以建立个体间的相互关系为主要特征的产物,如“顶”、“踩”、“关注”等情感性指针和“社交图谱”(social graph)、“人立方”等自主生成的关系结构图;兴趣型内容主要指以爱好交流、兴趣小组、信息/知识共享和沟通为主要特征的内容,如维基创作、在线问答、公众科学、设计竞赛等。
本文利用搜集的信息对三个站点用户生成内容进行更深层次的比较,分别从三个网站上抓取网站2015年2月3日的热点内容(见表1),发现三大网站的侧重有所不同,知乎网站上用户的内容创造更多是一种经验性问题的求解,每个用户的角度不同对问题的理解就会不同,观点各不相同,其他用户通过对其点赞来表明是否认同;果壳更多的是科普问题的事实性探讨,用户所提出的问题,会由专业人士来解答,认可度较高;豆瓣的热点与其他两者差异明显,所选取的10篇标题是豆瓣首页的推荐,从这些文章标题就能看出,豆瓣上用户内容的创作更多是一些情感、兴趣的成分。
以每个站点的第一个热点问题举例比较三个站点的社会价值:
知乎的热点问题“统计物理/生物物理有什么有意思值得深入的研究吗?”一共收获11个答案,被304人关注。该问题回答被用户认可高的回答者中有北京大学生物学专业毕业、香港大学物理学专业毕业、南京大学物理博士在读等,可以看出能够在知乎站点回答问题并获得认可的用户大都具有高等教育水平,在行业内具有丰富的知识。在传统信息搜寻过程中,用户需要跨行业搜寻时,很可能会遇到难题难以解决,在知乎的平台上,用户可以向各行业的专业人士请教。虽然知乎在初建时涉及领域较少,但是随着知乎不断壮大,各个领域的专业人士也都纷纷成为知乎的用户。
豆瓣的热点文章《N1自学经验:从86分到132分》被2943人喜欢,382人推荐(截止至2015年2月3日),这更像是一篇读物,如果刚好有需要考N1或者以后需要的用户,他们就会被集结在一起,用户可能会在评论中相互讨论,相互鼓励,或者相互分享资料,这无形中就形成了一种社会化信息搜寻模式。
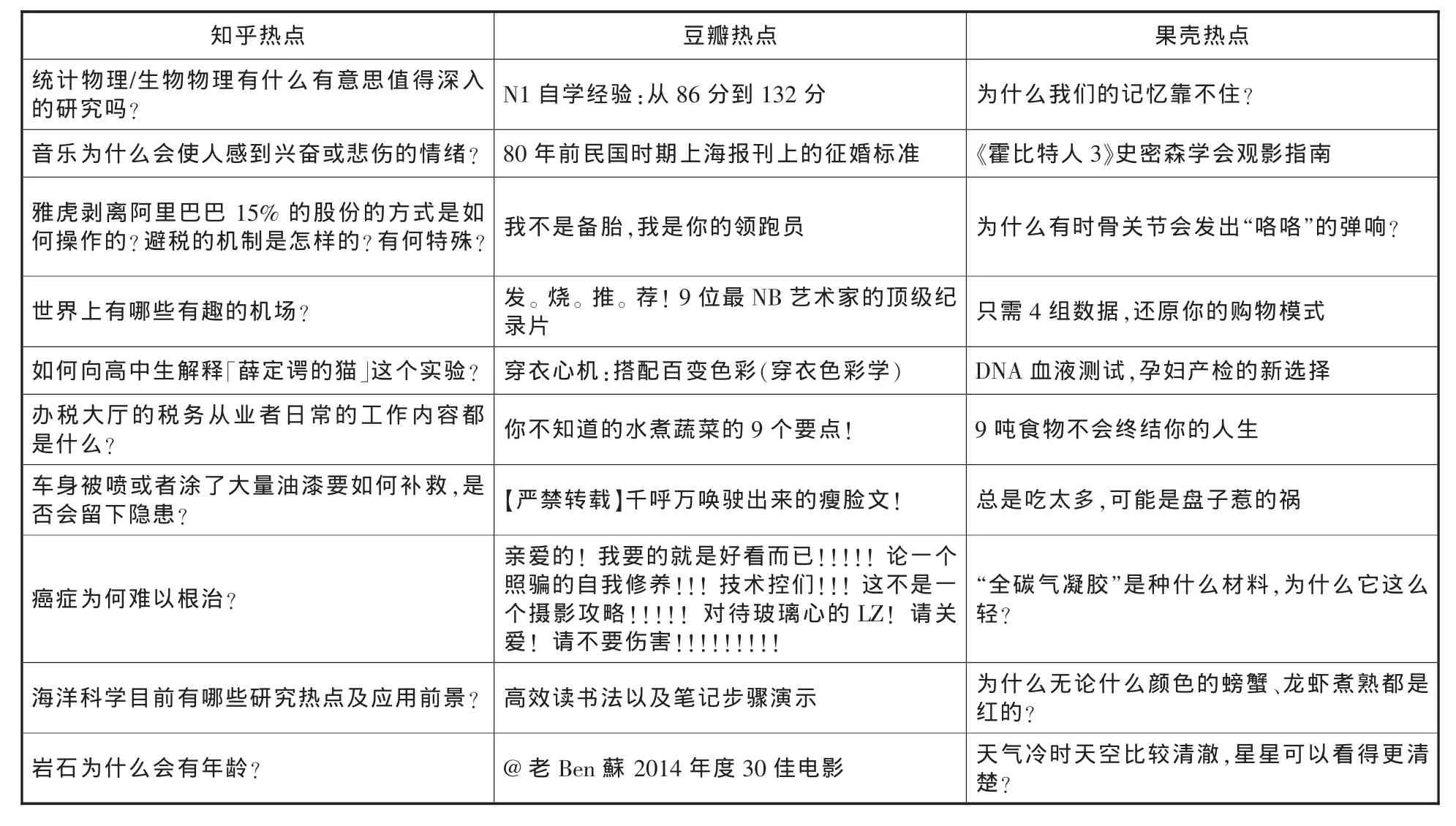
表1 知乎、豆瓣、果壳随机热点内容列表
(2)资源标注。标注(Tagging)是定义标签的过程,是用户为某一资源加入描述性元数据并赋予某项资源关键字来达到划分类目的过程。标注建立起了标签或标签组、资源、用户、时间四者之间的联系。社会化标注指的是众多用户所进行的标注行为,用户基于个人的或者社群的目的对资源赋予标签,这种看似私人的行为在众多用户的共同参与时产生了社会性价值:用户对某个特定资源指定了数个标签,标签因此成为了连接用户与资源之间的桥梁。资源之间也可以通过某种方式彼此相互连接 (如被同一用户标注过的资源、使用了同一标签的资源),并且用户也可以透过标签或资源的社会网络来相互关联。
知乎的 “话题”有别于很多其他网站上的 “标签”,并非由用户自由创建、自由使用。如果话题被合理地添加到问题上,意味着根据社区的共识和使用习惯,一些可能相似的内容被联系在了一起。知乎站点上这些基于话题的联系和分组能够帮助用户方便快速地发现关于某个主题的内容。果壳站点的 “标签”类似于知乎的“话题”,一个标签聚集一类特定主题的内容。用户可以添加或修改标签,如果标签不存在,系统会自动提示用户是否创建新标签。点击标签之后,可以看到标签的图片和详细描述。任何人都可以修改这些信息;在标签描述已经比较完善的情况下,标签将被锁定。如果用户认为仍有改进空间,可将修改理由告知管理员。豆瓣用户可以自定义标签,并且豆瓣会以每个用户的标签来决定分类。豆列是豆瓣一个极具特色的收集工具。豆列的标题、收集的原则、收哪本书,都由用户决定,比如豆列“普利策小说奖历年获奖作品”或“2009年我的私人阅读”。好的有趣的豆列,会得到他人的推荐和收藏,“普利策小说奖历年获奖作品”这样的豆列很可能就比“2009年我的私人阅读”得到更多的青睐。每个条目的右侧,会显示收藏了此条目的最受欢迎的5个豆列。
(3)需求表达。当用户提出查询请求时,搜索引擎根据用户的输入内容,对本地信息按一定算法和策略进行匹配,最终将匹配结果反馈给用户。搜索引擎的服务方式主要包括目录式服务和关键词式检索服务两种,目录式服务可以帮助用户按一定的结构条理清晰地找到自己感兴趣的内容,关键词式检索服务可以查找包含一个或多个特定关键词或词组的Web页面,而用户最喜欢使用关键词式Web搜索引擎9。
知乎用户可以按关键字或话题搜索问题,可以通过关注的人、话题、问题等寻求答案。用户也可以在知乎上提问,提问之前首先要确保问题没有重复,提问的需求表达包括问题、相关说明和话题,话题越精准,越容易让相关领域专业人士看到问题。知乎搜索还增加了时间排序的选择,让用户对具有时效性的内容可以进行更高效的搜索,选项包括过去一天内,过去一周内与过去三个月内,来满足不同时间需求的用户。这里的时间是指问题的最近活动时间,用户在时间线内找到并查看但错过的过去一天内好回答,用一周内找过去一周发生的大事件的讨论,或者在三个月的选项中看看过去的新一季活动的精彩内容,结果页默认的是时间不限的搜索结果。在结果页上方,用户可以选择问答、用户、话题来满足对不同内容的搜索需求。结果页右边是与用户的搜索内容相关的话题卡片,用户可以直接关注,或进入话题页查看话题内容。用户可以通过更多的维度来找到值得关注的人:用户的一句话介绍、工作信息、教育信息、所在地等都可以被搜索。同时也包含了一些辅助信息,比如“谁关注了用户A关注的人B”,来帮助A判断B是否值得自己关注。
豆瓣的搜索框可以搜索用户感兴趣的内容和人,但效果不尽人意。豆瓣的搜索功能是被弱化的,豆瓣重在帮助用户找到内容,直接告诉用户他们想要的内容,而不是通过搜索找到内容。田莹颖爬取豆瓣用户收集书籍的标签信息后进行数据分析实验结果表明,由于豆瓣用户的兴趣较为广泛,用户对于同一图书的标识各有所爱,标签的离散性较大,用户个性化信息推荐的精度大约为50%。
果壳用户可以利用关键词搜索全站、文章、问答、帖子、日志和用户,可选择模糊匹配或精确匹配,搜索结果可以按相关排序或时间排序。
(4)结果排序。知乎通过用户对问题的回答进行赞同或者反对,决定排序结果。知乎采用“威尔逊”得分算法如下,即如果把一个回答展示给很多人看并让他们投票,内容质量不同的回答会得到不同比例的赞同和反对票数,最终得到一个反映内容质量的得分。当投票的人比较少时,可以根据已经获得的票数估计这个回答的质量得分,投票的人越多则估计结果越接近真实得分。公式如下:
每一个行业中均会存在人员流动问题,这一点属于不可控因素,而工程建设单位也同样会面临此种问题,且人员流动所带来的损失也相对较大。工程造价管理工作较为繁杂,多数工作人员基于长时间忍受巨大的工作量而脱离此行业。工程造价管理具有着一定的地域性特征,也就是在不同的区域中工程造价管理工作形式存在着较大的差异,在同一个团队的长期运作下会形成一种独立的模式,一旦出现人员流动交接工作会面临着诸多难题,且流动人员去往一个全新的单位后也需要接受全新的工作模式以及工程计价方式,从这一点来看,人员流动对原有工作的开展及其自身均会造成较大的影响[5]。
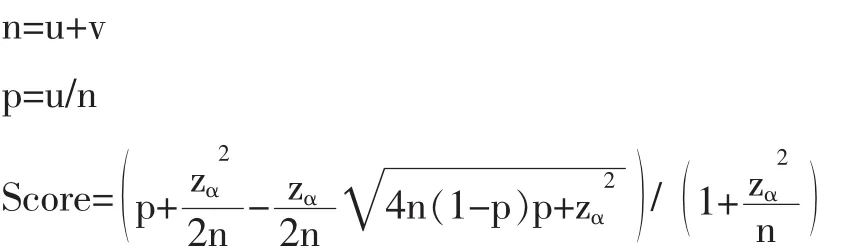
其中:u为加权赞同票数,v为加权反对票数,z为对应某置信水平下的z统计量。
关于用户投票的权重,知乎认为:在知乎上创作了专业、严谨、认真、高质量回答的人应该在他/她擅长的领域里有更大的判断力;用户在一系列相关话题下发布的全部回答所得到赞同、反对、没有帮助票数决定用户在该领域下的权重;问题添加的话题和话题父子关系决定问题归属的领域。知乎对社会化信息的排序结果归根结底是通过知乎社区中用户的集体智慧的选择而完成,具体体现为每一次对 “赞同”、“反对”、“没有帮助”按钮的点击。
参考IMDB的算法,豆瓣对社会化信息的排序依据综合分数和人数,是一种贝叶斯统计的算法得出的加权分。公式如下:
Weight Rank(WR)=(v/(v+m))*R+(m/v+m)*C
其中:R为用普通方法计算出的平均分,v为投票人数(只有经常投票者才会被计算在内),m为进入top250需要的最小票数 (只有三两个人投票的电影就算得满分也没用的),C为目前所有电影的平均得分。
依据果壳问答网页的介绍,其排序算法为:总票数=支持数-反对数,如果票数相同,则按照发布时间来排序。果壳与知乎不同点在于果壳票数完全透明化,赞同和反对票数完全公开,能让读者和答主非常清晰地看到某个答案的排序权重。知乎出于保护答主的自尊心,鼓励答主在这个平台上待下去,只显示赞同数,隐去反对数。
综上,知乎、豆瓣、果壳三大社会化网站侧重各有不同(从内容来源、资源标注、需求表达、结果排序来衡量网站的社会化方式汇总见表2)。
3.3 与理想目标的差距及发展建议
Evans和Chi整合以往研究成果,总结出了一个规范性社会化模型(Canonical social model),揭示了用户在整个搜索过程中潜在的信息分享行为 (见图 4)。
像“知乎”、“果壳问答”这类利用社交网络帮助用户找到符合的、主观问题答案的社会化问答网站,用户的参与程度是衡量其是否具有持续竞争力的重要指标。相较于Evans的模型来说,“知乎”和“果壳问答”为用户提供的参与方式还比较单一,社交属性较弱。知乎的用户主要分为三类,核心用户、轻度用户和浏览用户,核心用户贡献大部分的内容,轻度用户偶尔贡献,浏览用户不贡献内容,但会关注、赞同或分享。“知乎”应该有两张社交网,一张是核心用户(行业精英)和普通用户的关系网,另一张是熟人和朋友网,目前“知乎”更加侧重普通用户与行业精英之间的关系网,在社交方面的功能不够深入,导致大多数用户只是浏览用户,并不想建立自己的社交圈子,网站对用户粘性不够。

表2 信息搜寻网站的社会化比较
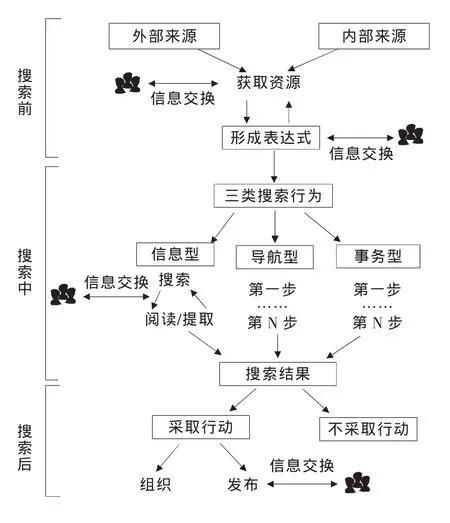
图4 Evans和Chi的规范性社会化模型
社交网络中包含的数据异构性高,信息量大,又有权限控制和隐私保护,所以对社交网络的内容搜索难度较大。推荐系统研究用户模型和用户喜好,通过社交网络进行个性化的计算,由系统主导用户的浏览内容。豆瓣网是具有影响力的中文社会性标签系统之一,姜婷婷等人曾基于豆瓣网分析发现社会性标签系统用户采取的信息搜寻模式包括搜索、代理浏览、偶遇和追踪,而浏览者成为主流,在数量上甚至略微超过搜索者。根据Evans的模型,在搜索过程中,豆瓣用户能将满足需求的内容收藏,内容会显示在个人主页上,进而与友邻共享信息。社会化标签系统提供的搜索功能都比较简单,只能实现最基本的文字匹配,社交网络对信息的实时性要求比较高,可以将主题与时间因素、朋友因素等结合考虑,如搜索结果加入“好友曾关注”类似这样的模块。至于“豆瓣”的主动推荐功能,可以利用现在流行的云计算技术如 Hadoop、Map reduce及 Cascading等,Liang H Z等人就基于此提出了一种并行用户分析方法及基于此的可伸缩的推荐系统。
果壳网大部分功能更加偏向于社会化阅读的模式,可以从主题站、小组的帖子丰富见识,可以通过微博、人人网等社交工具进行分享和交流,缺乏搜索过程中实时交流的互动方式,只能达到Evans模型中搜索结束后知识的组织和共享。果壳推出的新产品“在行”,是一个O2O经验咨询平台。在遇到无法解决的问题时,用户可以找到有经验的行家,一对一见面交谈,让他给自己答疑解惑、出谋划策。这一方式成本比较高,还需要雇请专人,知识共享程度和效率也都比较低。根据Evans的模型我们可以发现大部分社会化信息搜寻网站在不同程度上涉及到社会化,由于每个网站的建设要求不同,并没有从每一个方面都设计,但是统观大部分社会化信息搜寻网站,在搜索前的需求优化这一块都没有做或做的不好。需求优化的过程中涉及到许多信息交换的方式,比如直接向认识的人并可能了解自己需求的人直接求助,寻求一些引导信息,这样就能够避免搜索过程中因为信息太过杂乱造成“迷航”的问题。
费洪晓等从算法角度分析了社交化搜索算法模型应用于不同环境下的效果,已有模型仍存在一些局限和不足,如时间复杂度高、响应速度慢、数据集的范围有限、社交特性利用程度不高等,指出社交网络的复杂性和现有算法的局限性是目前造成现实搜索工具与理想目标差距的最主要原因。综上所述,由于社会化信息搜寻相关的理论还不完善,具体算法、模型的实现也有很多的因素有待研究,因此社会化信息搜寻的实用化还需要众多研究。
4 结语
本文选取了三个典型的中文社会化搜索网站,详细分析了三个站点的基本功能和社会化方式方面的异同,指出已有社会化信息搜寻网站与理想目标的差距,最后提出社会化信息搜寻系统的改进建议。由于社会化信息搜寻的理论还不完善,还有许多因素有待研究,笔者在后续工作中对社会化信息搜寻系统用户行为影响因素进行研究,为更加完善社会化信息搜寻系统提供依据。
[1] Evans BM,Chi E H.Towards a model of understanding social search [C].Proceedings of the 2008 ACM conference on Computer supported cooperative work,2008:485-494.
[2] Cao J,Tang Y,Lou B.Social search engine research [C].20103rd International Conference on Computer Science and Information Technology,2010:308-309.
[3] Chi E H.Information seeking can be social[J].Information Seeking Support Systems,2008.
[4] Evans BM,Chi E H.An elaborated model of social search[J].Information Processing&Management,2010,46(6):656-678.
[5] 杨建林,秦嘉杭,王丽雅,等.社会化信息搜寻研究综述[J].情报理论与实践,2015(3):134-137.
[6] 赵宇翔.社会化媒体中用户生成内容的动因与激励设计研究[D].南京:南京大学,2011.
[7] 赵宇翔,范哲,朱庆华.用户生成内容(UGC)概念解析及研究进展[J].中国图书馆学报,2012(5):68-81.
[8] Philip J.Binkowski.The Effect of Social Proof on Tag Selectionin Social Bookmarking Applications[EB/OL].[2015-01-21].http://etd.ils.unc.edu:8080/dspace/bit stream/1901/358/1/philipbinkowski.pdf.
[9] 杨建林,严明.一种面向Web搜索的查询修正方案[J].情报理论与实践,2008(1):146-149.
[10] 田莹颖.基于社会化标签系统的个性化信息推荐探讨[J].图书情报工作,2010(1):50-53.
[11] 曾加.浅析知乎新的回答排序算法[EB/OL].[2015-01-21].http://zhuanlan.zhihu.com/MathplusPlus/19909161.
[12] 姜婷婷,迟宇,史敏珊.社会性标签系统中的信息搜寻——基于豆瓣网的实证调查[J].图书情报工作,2013(21):112-118.
[13] Liang HZ,HoganJ,YueX.ParallelUser Profiling Based on Folksonomy for Large ScaledRecommender Systems:An lmplimentation of Cascading MapReduce[EB/OL].[2011-05-25].http://eprints.qut.edu.au/41889/1/icdm-cloudcomputing-cameraKeady.pdf.
[14] 费洪晓,莫天池,秦启飞,等.社交网络相关机制应用于搜索引擎的研究综述[J].计算技术与自动化,2014(1):1-9.
猜你喜欢
星星·诗歌原创(2020年11期)2020-12-03
读者(2018年12期)2018-05-30
意林(2018年2期)2018-02-01
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
现代情报(2014年8期)2014-11-06
教育(2014年4期)2014-02-25
世界知识(2009年8期)2009-06-10
浙江社会科学(2004年2期)2004-04-21
