
用语图分析揭示语言系统中的隐性规律
——赢家通吃和赢多输少算法
2015-04-21 10:52陈振宁陈振宇
中文信息学报 2015年5期
陈振宁,陈振宇
(1.浙江大学 人文学院,浙江 杭州 310058;2.复旦大学 中日语言文学系,上海 200433)
用语图分析揭示语言系统中的隐性规律
——赢家通吃和赢多输少算法
陈振宁1,陈振宇2
(1.浙江大学 人文学院,浙江 杭州 310058;2.复旦大学 中日语言文学系,上海 200433)
该文用“图”这一数学工具,通过定量分析来揭示语言系统中的隐性规律,设计了“赢家通吃”和“赢多输少”两种生成算法,将理想算法“步步竞争、择优而行”的博弈论思路贯彻到非理想状态。两种新算法都较前人有更好的概括能力。赢多输少算法更兼顾了充分概括和适度概括均衡。生成语图后,该设计着重准确率的最小简图和着重覆盖率的最大简图归纳算法,挖掘控制的主流规则、分析语言系统的语言学规律。在最小简图基础上提出控制度公式以评价语言系统。
隐性规律;图论;博弈论;规则挖掘
1 引论
类型学在跨语言比较研究中引入语义地图(Semantic Maps)理论,它以基元(即所调查的语言项目)为“点(node)”,根据这些基元项的共现“关系(relationship)”连接成“边(edge)”,生成一个“图(graph)”。然后用这一地图去挖掘各项目间的规律。[1-3]这种地图其实就是“图论(graph theory)”研究的内容[4];这种关系,是研究在“交际”中形成的“隐性控制”关系。
另外,“语义地图”并不限于狭义的语义。“任何形式、语义甚至语用项目,只要对象个体间具备某种联系,或者说相关性”,就都可以研究[1,3]。因此,本文扩展这一术语为“语图”(Graphs of Languages)。
1.1 交际—控制理论
交际-控制是一个社会学概念。“社会”(society)是人的集合,但仅仅把人弄到一起还不够,其中必须有一套内在控制机制,令人群成为有类别有等差、一体运行的集体。粗略地讲,“社会=成员集合+控制机制”。
社会存在着两种控制模式[5]:
1) 显性控制: 成员产生明确的关于某种运行规则的认识,这一规则“外化”于社会,有明确标记,相对独立、静止。
2) 隐性控制: 未曾事先规定任何规则的社会在其自身的运行中,会自发地形成运行机制,但它仅仅是现在的、当下的、自动地形成着。
隐性控制难以认识与把握,具有模糊性、即时性、变化性等特征,即难以识别,又可能产生过强的识别。“错误理解”(mis-understanding)和“过度理解”(over-understanding)都是对事实的非真实反映。所以,隐性控制最需要定量的分析。
“交际-控制理论”把隐性控制机制看成是一系列交际过程中呈现的即时的事实,试图通过对论域中的交际活动的定量分析,来构建隐性控制机制的轮廓。
在交际的过程中,各个成员(称为“基元”)参与交际的程度并不一样,其中有的参与程度高,从而成为“控制中心”,并形成一定的“控制路径”,对整个系统起着主要的甚至是决定性的作用[5-6]。例如,一个俱乐部有A、B、C三个成员,假定他们有两种共现情况,分别如表1、表2所示(其中“+”号表示共现关系,“yes数”表示共现成员的数量)。
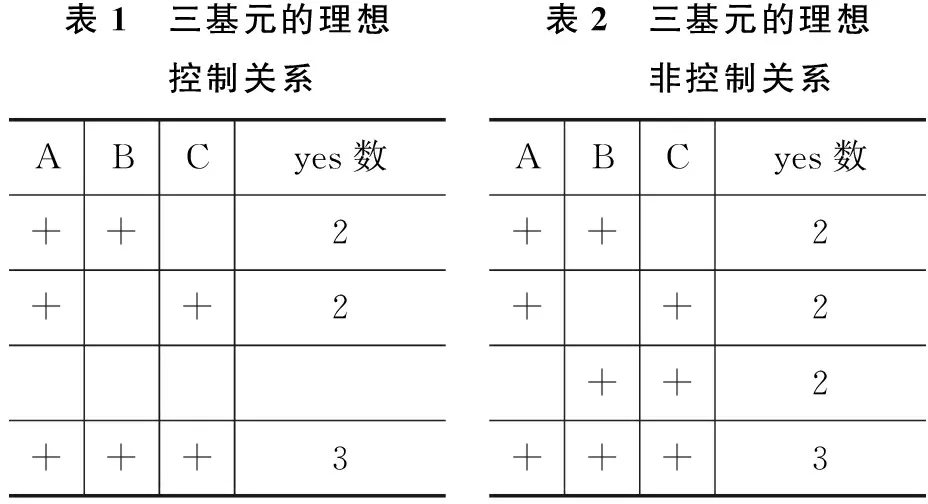
表1 三基元的理想控制关系ABCyes数++2++2+++3表2 三基元的理想非控制关系ABCyes数++2++2++2+++3
根据Haspelmath、Haan,Ferdinand提出的理想状态下的经典绘制算法[3,7](简称理想算法),我们只考虑这些基元之间共现关系的“有无”: 无共现的点不能连接;有共现的点则加以连接;三以上多元共现要核对“两两排他共现”以避免出现“圈”(cycle)。因此从表1、表2分别生成两个关系图,如图1、图2所示。
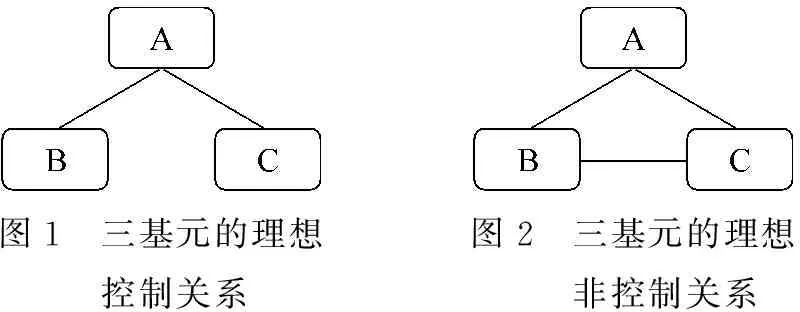
图1 三基元的理想控制关系图2 三基元的理想非控制关系
表1、表2都有A、B、C三者共现。但在表1中,B、C之间并无两两排他共现,所以B与C之间没有直接关系,是经由A作为“中间人”才能沟通,因此在图1中有以下隐性规律: A点作为辐射中心,B、C只能和A点直接交际,A可视为星(star)图的中心,是典型的隐性控制中心: B与C共现时,一定是A沟通的,因此A一定出现。
在表2中,A、B、C两两之间都有直接关系,是图论中的“完全图”(complete graph),因为任意两点之间都有边,所以整幅图的关系“均匀划一”,所有成员“人人平等”,没有任何控制关系,也称为“空地图”。
图3是基于上述原理构建的不定代词(indefinite pronoun)各个功能项之间的关系地图[7],可以看到,其中有很好的控制关系,如(2)控制(1),(6)控制(7),(8)控制(9);但功能项(3)、(4)、(5)之间是完全图,(4)、(5)、(8)、(6)是“圈”(cycle),都无法找到隐性控制者。
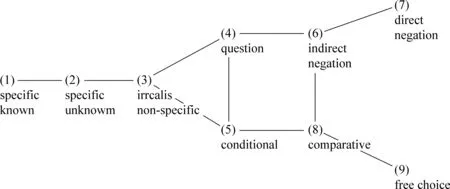
图3 世界语言中“不定代词”各功能项之间的关系
注意,排除调查数据有误,确实可能有无法去除的圈,说明这一系统局部仍处于“自由竞争”状态,本身不具有稳定的隐性规律[5]。
1.2 非理想系统已有分析算法: 完全加权
现实中的真实数据并不总是理想的,大多数情况下,基元之间的共现关系并不是绝对的“有无”,而是以不同频次体现出来的相对“多少”倾向。Cysouw 研究跨语言人称语义时就遇到这个问题。他将人称语义分解为八个基元,调查了这些基元的跨语言共现,如表3所示[7]。
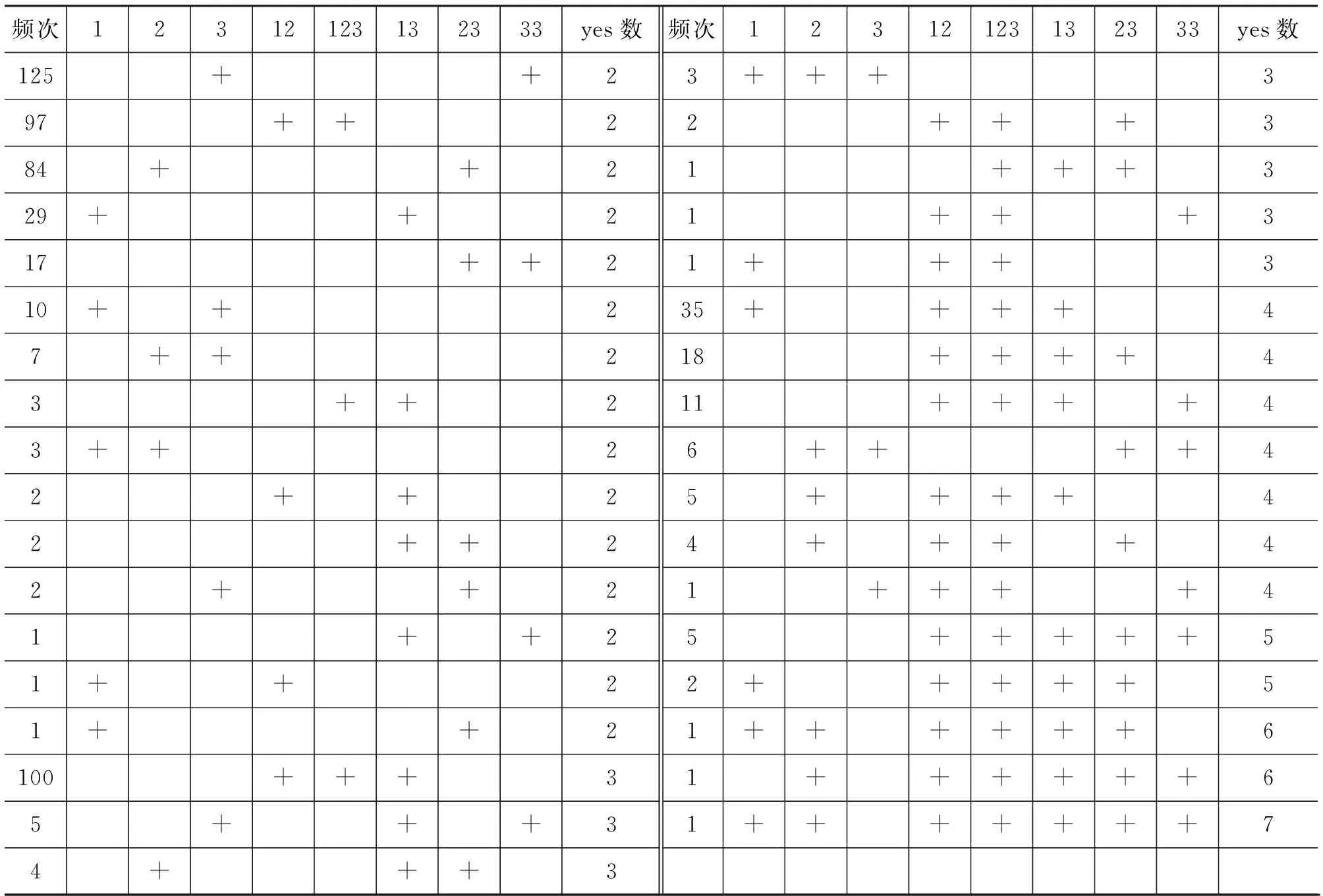
表3 人称八个基元的共现情况表
注: 人称八基元含义: 1第一人称;2第二人称;3第三人称;12、123、13第一人称复数;23第二人称复数;33第三人称复数
人称基元的共现很复杂,光看“有无”无法获取有价值信息,但不同共现间的频次差异很大。Cysouw提出了基于共现频次高低的加权算法[8]: n个基元共现,认为它们两两之间全部存在同一关系,于是直接两两全部连接起来形成n*(n-1)/2条边,所有n*(n-1)/2条边都直接加上共现频次f作为权重,如表4所示。
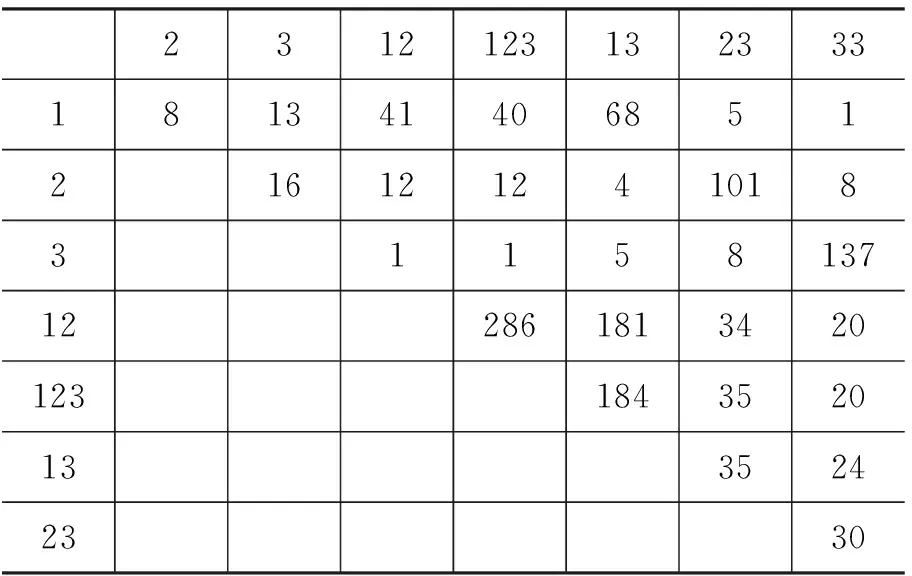
表4 完全加权生成的人称语图权重矩阵
这样,每个共现记录局部是完全图,表4中所有边的权重都大于0,所以本文简称其为完全加权算法。显然,完全加权生成的语图包含大量的圈。Cysouw按主观判断删略一定的“粗边”得到揭示跨语言人称语义蕴含规律的简图。全图如图4,因为主观取舍的不确定性,简图有多幅,如图5、图6所示。
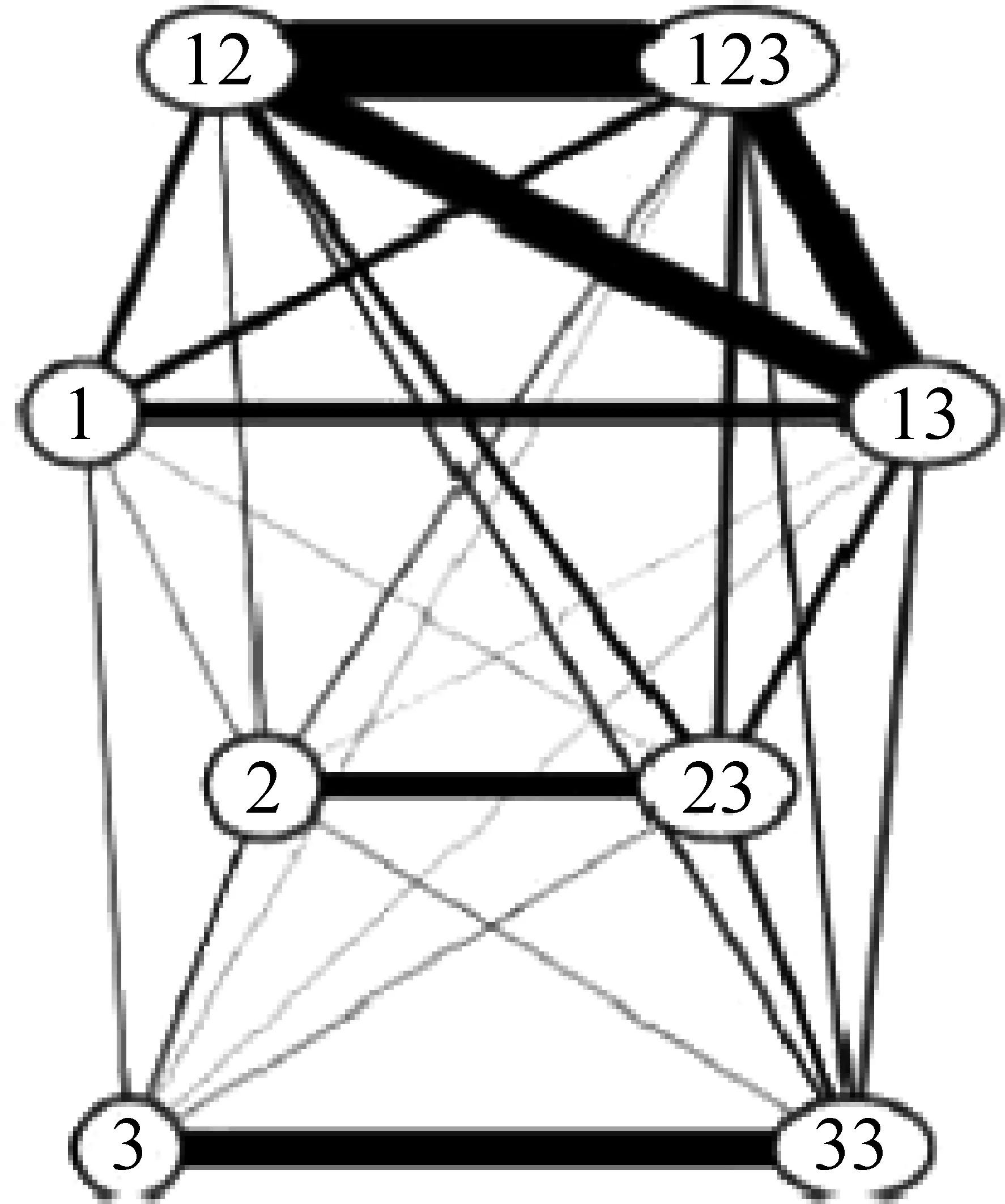
图4 完全加权生成的人称全图
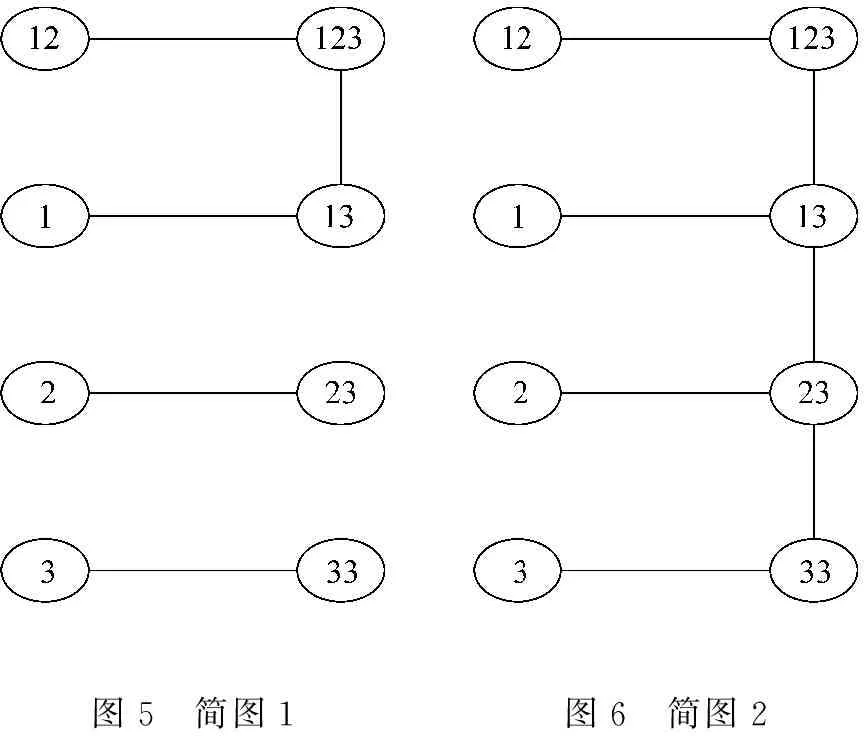
图5 简图1图6 简图2
完全加权不兼容理想算法,图4控制能力差,无法很好地归纳规律。这就产生了一系列问题,例如,
问题1 基元3、13、33有共现且频次为5,这三个基元的两两排他共现见表5。
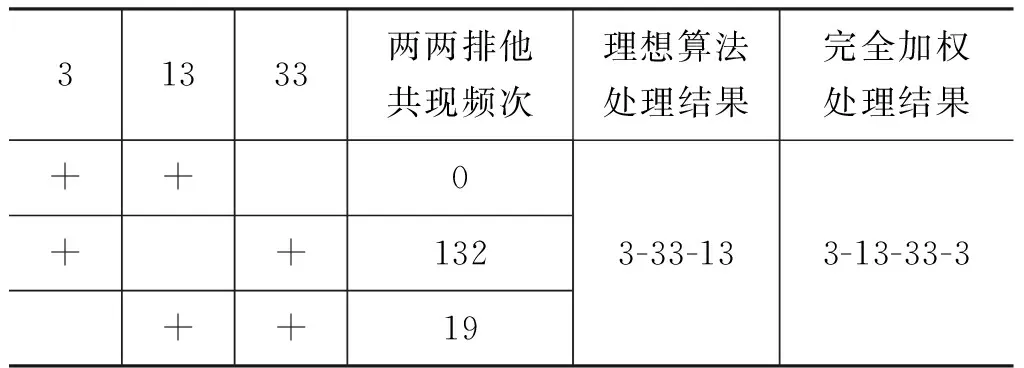
表5 3、13、23的两两排他共现
这个局部共现明明是理想状态,应生成控制链(chain)3-33-13,却被完全加权处理为圈3-13-33-3,其中本应权重为0的3-13在表4中有权重5。
问题2 基元12-13完全加权后累计权重181,是图4中第三“粗”的,两幅简图都删掉了它。边 1-13权重68,相对较“细”,却在简图中保留。这样做不是基于算法而是基于研究者的直觉,其主观性很难操作。
国外其他学者的研究也多以局部完全加权为基础[9]。在国内,郭锐提出的完全关联度算法[2]大体上也是一种完全图,所以未能避免有关的问题。
1.3 本文的研究目标与技术路线
本研究致力于解决在非理想状况下系统的隐性控制规律分析问题。我们认为:
1. 加权算法引入共现频次来处理非理想数据是合理的。这一点上我们的技术路线与它相同: 定量分析,按频次为每条边逐步累计加权[5],按权重之和确定倾向性,得到一语言系统的控制规律“主流”(mainstream)。
2. 我们不同意完全加权,这种在每个局部生成完全图的做法反而违背了定量分析的要求,不符合图论与隐性控制的基本原理,和理想算法在数学方法上相悖,最终概括力度太弱。我们的技术路线修订为: 每一步计算累计都综合其他记录提供的竞争参数,按竞争参数定量分析,设计博弈论(Game Theory)的优先决策算法,对“赢家”和“输家”边给予不同的加权策略。
另外,隐性控制的探索还要注意两点: 充分概括,建立具有充分概括力的算法,把各基元、各边之间的不平等关系充分地体现出来;适度概括: 过强的概括力可能会把较小的差异“放大”为显著的区别,“过犹不及”,需加以压制。
就已有的研究看,尚未能找到充分概括的算法是主要矛盾,但也不能忽视次要矛盾,在找到充分概括的道路后应关注适度概括。
2 我们的方案
2.1 赢家通吃算法[6]
赢家通吃将理想算法的基本原则扩展到非理想状态:
1. 对每个n≥3的多元共现,提供竞争参数“两两独立共现频次”,按参数大小竞争。先计算局部共现中所有“两两对子”的两两独立共现频次,再按从大到小顺序排列这些两两对子,选取频次大的n-1个对子为“赢家”,剩下的对子都是“输家”;
2. “优胜劣汰”博弈策略: 赢家获得全部加权,输家无加权。
其中,两两独立共现包括: 1.两两排他共现;2.不同多点共现中出现的两点单独共现。
以表3中人称12、123、13三者共现100次的记录为例。12、123、13能形成最多三个对子: 12-123、123-13和12-13。这三个对子的“两两独立共现频次”计算如表6所示。
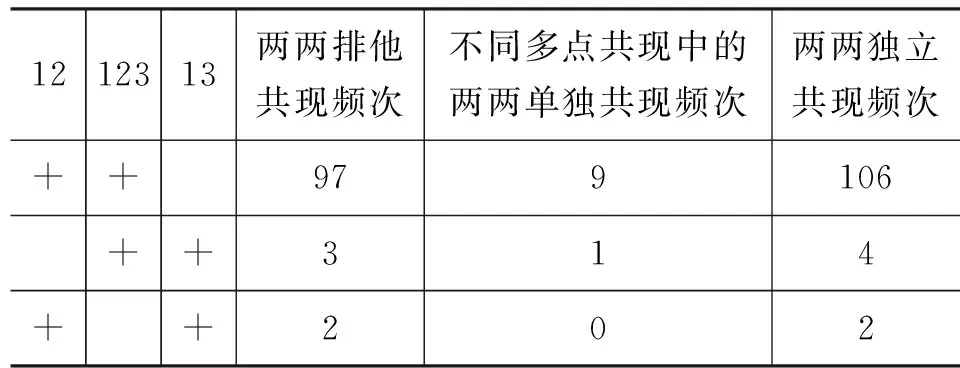
表6 12、123、13的两两独立共现频次
然后,保留n-1=2个“赢家”: 两两独立共现频次相对大的12-123、123-13全部加权100;剩下12-13是输家,无加权。如图7所示。

图7 赢家通吃生成的12、123、13局部语图
对人称语义应用赢家通吃算法,可得到权重矩阵如表7,语图如图8。因为兼容理想算法,理想状态下明确可以删除的边权重都为0。
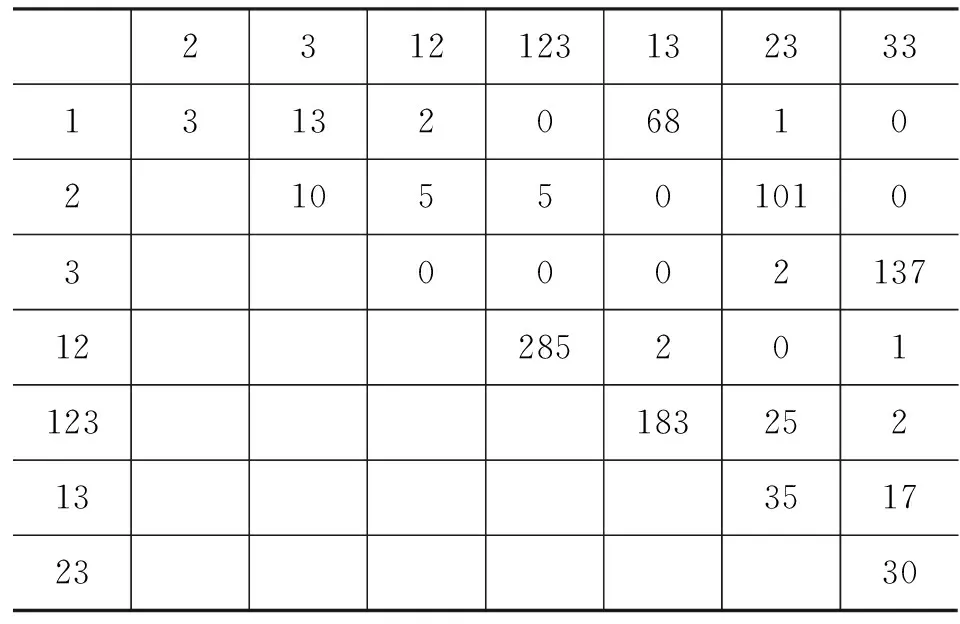
表7 “赢家通吃”生成的人称语图权重矩阵
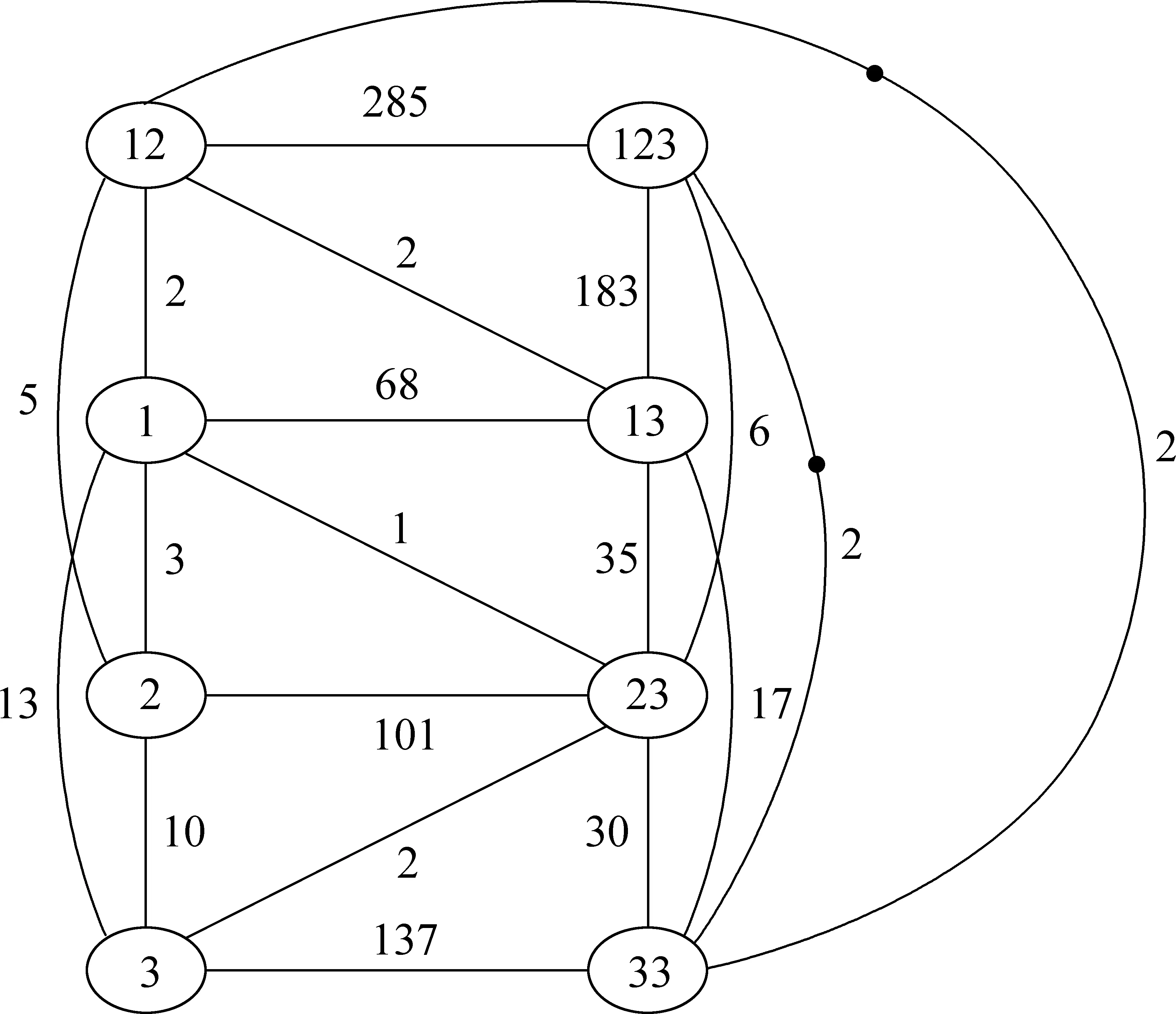
图8 赢家通吃生成的人称全图
最后,赢家通吃算法设计了简单的归纳算法: 严格按权重阙值“删细留粗”。如果设置阙值为35,得到完全加权主观简化的简图5;设置阙值为30,得到完全加权的简图6。
注意,赢家算法中每个局部的赢家选择n-1个,遵循的是图论的如下定理及其推论[4]。
定理1 n个顶点的连通图是一颗树,当且仅当它有n-1条边。
推论1 每个连通图均包含一棵支撑树。
由此,不考虑全图本身可能是“森林”、图中有“歧义”、“可恢复边”*森林:由几棵彼此不连通的树构成的图[4]。歧义和可恢复边的数学定义见节3。等特殊情况,选取竞争参数相对最大的n-1条边,是为了归纳局部语图的“最大支撑子树(max spanning subtree)”。
这意味着赢家通吃算法局部最大限度地加强概括力度,反过来说可能造成概括过度: 赢家与输家差别不大时,完全不赋予输家权重可能不太合理。
2.2 赢多输少算法
赢多输少对赢家通吃可能出现的过度概括进行均衡: 博弈采取“优多劣少”,按照两两共现频次的“多少”倾向程度,对赢家输家按比例加权。这样也能在加权策略上更彻底地贯彻定量分析方法。
分配比例理论上应按“连接所有基元的路”来分配,但这样算法复杂度高达O(n!)*“n个基元共现于同一语言形式”的数学定义: n个基元共现于同一语言形式,是指基元间至少存在一条能够连接所有基元的非圈最长“路(path)”。并有推论: 推论: 每个局部最多可能有n!/2条连接所有基元的路。于是,比例以“路”为单位来分配,就要计算n!/2条路,算法复杂度为O(n!),以阶乘增长。。为降低算法复杂度,本文采用一个近似的比例分配算法: 前面n-2个赢家都直接100%加权;最后一个(第n-1个)赢家和所有输家一起按比例分配加权。这样连接所有基元的路最多可能有n-1条,算法复杂度降为O(n)。
如对前述12、123、13局部共现运用赢多数少算法生成,结果如表8和图9所示。
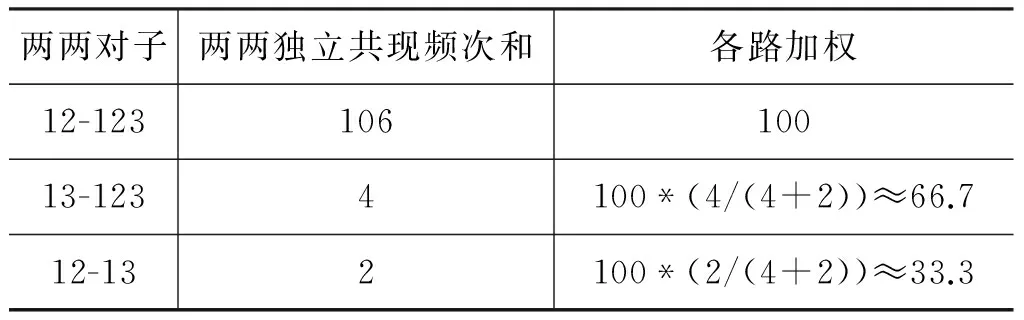
表8 赢多输少按12、123、13的两两独立共现频次比例加权
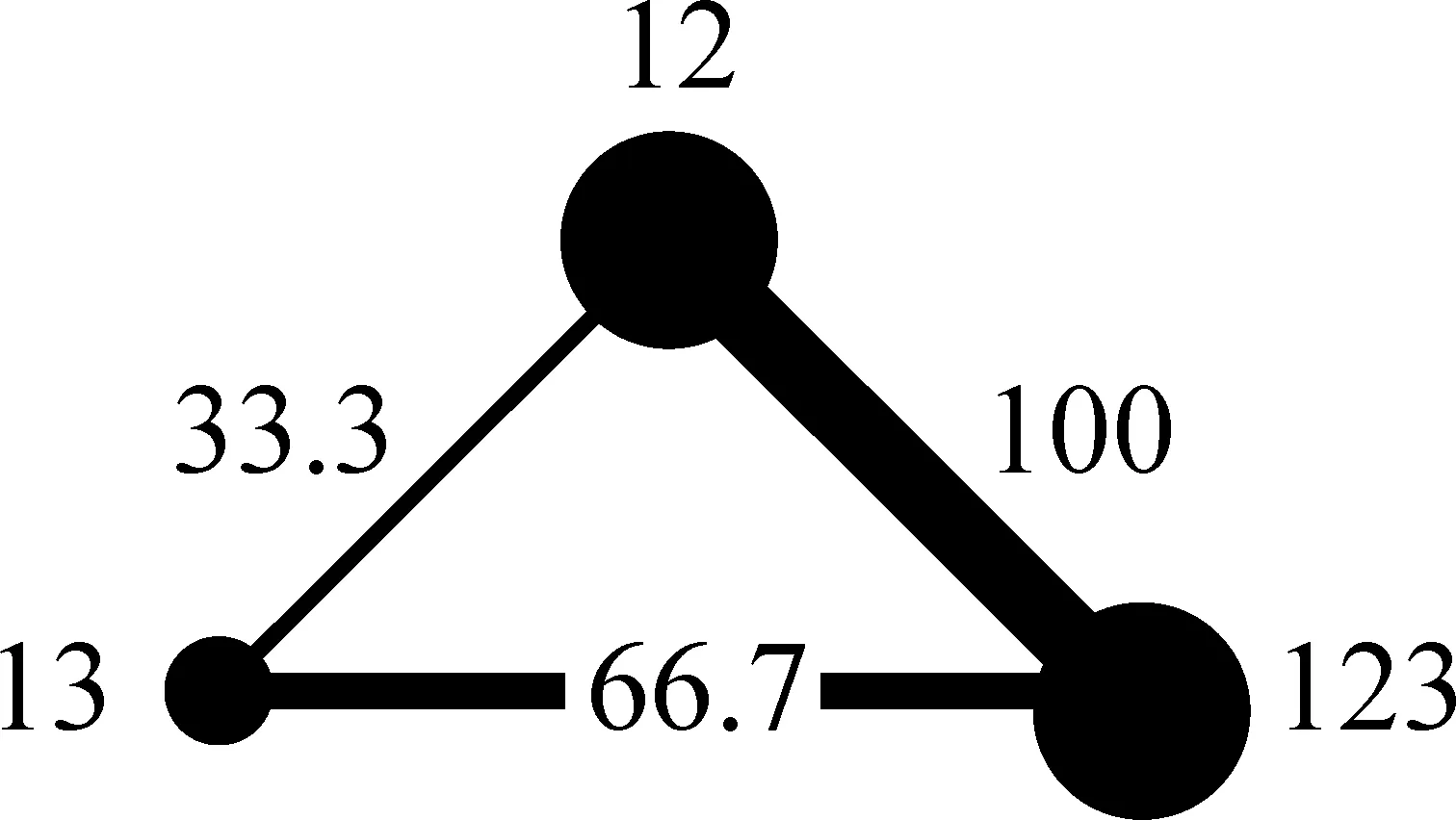
图9 “赢多输少”生成的12、123、13局部语图
赢多输少算法的概括能力趋向于“均衡”,各边粗细差异图9比图7小。
1. 输家12-13不再“彻底失败”,多少能分配到一些权重,劣势不那么明显;
2. 处于赢家末位的“小赢家”13-123的竞争参数并不比输家高多少,分到的权重被“压低”,优势不那么明显。
赢多输少算法生成人称语图的权重矩阵如表9,全图如图10所示。
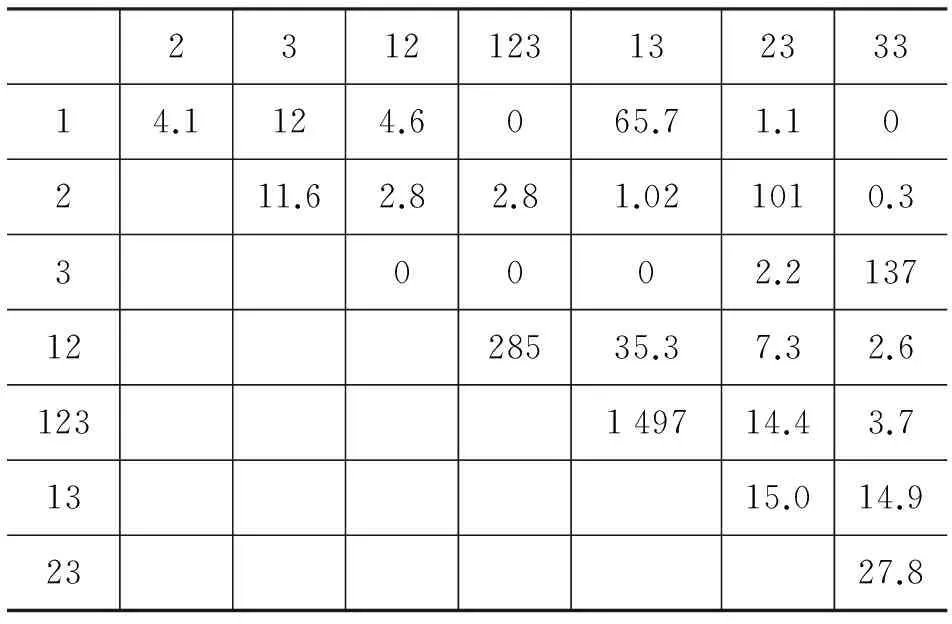
表9 “赢多输少”算法生成的人称语图权重矩阵
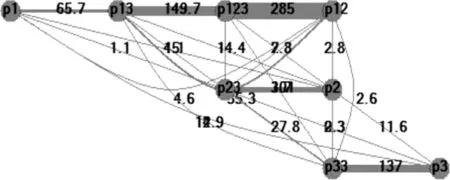
图10 “赢多输少”生成的人称全图
赢多输少权重为0的边比赢家通吃少,如边 2-33,表7中权重0,表9中权重0.33。这是因为 2-33出现过的局部其实不是理想状态,但因为 2-33的两两独立共现频次很低,次次当输家。在赢家通吃算法输家无法加权,被“伪装”成了理想状态下的断路。赢多输少算法对输家多少有权重,剥除了2-33的“伪装”。
3 归纳算法和非理想系统的评价
本文前述讨论的算法都是语图的“生成”算法。在理想状态或数据很少的时候,研究者很容易看出一个图的性质: 典型的控制?典型的无控制?还是居于其间的状态?
但数据量较大的非理想数据复杂性高,使得任何生成算法得到的语图都太过复杂,无法主观评判全图性质,因此: 1.需要用可操作的算法进行简化,但现有简化或者太主观(等于没有算法)、或者太简单(阙值简化)、或者只对基元分类根本没有控制关系(MDS算法等[1-3]);2.也需要提供评估参数,迄今为止尚未看到有研究者提出这一问题。
为此本文设计了两种归纳算法做规律“挖掘(mining)”。根据挖掘出的规律,进一步评估不同生成算法的合理性,同时提出对非理想系统隐性规则“强弱”的评价参数。
3.1 最小简图和控制度
主要思想: 找到每个基元“关联性最强”的关系。
操作流程: 从任意基元出发,检查基元P关联的所有边,保留且只保留权重最大的一条边;以此类推,直到遍历所有基元。
这一算法保留最少的边,同时保证保留下来的边权重最大,因此挖掘的是“主流中最简约控制规律”。因为最简约,所以能最大程度上保证规则的准确率。
在最简约的最小简图基础上,我们引入“控制度”这一概念,其计算公式为式(1)。
(1)
式中∑e∈GminW(e)为最小简图的权重之和,∑e∈GminamW(e)为最小简图歧义边的权重之和,∑e∈GsuperW(e)为全图的权重之和。
其中“歧义”定义为: 点P有歧义边,指和P关联的边中,权重相等的边数m大于等于2,这m条边则是“关于点P有歧义的边”。
简化如果遇到点P有“权重最大的m条歧义边”,就无法确定点P到底通过谁主要和其他边相连,因此m条边都不可删除,留在简图内形成无法简化的子圈。无法简化的子圈无法预测控制路径,对控制度无贡献,因此需要减去。
归纳算法可以独立应用,我们对前文各算法生成的人称语图应用最小简图归纳算法, 得到图11、
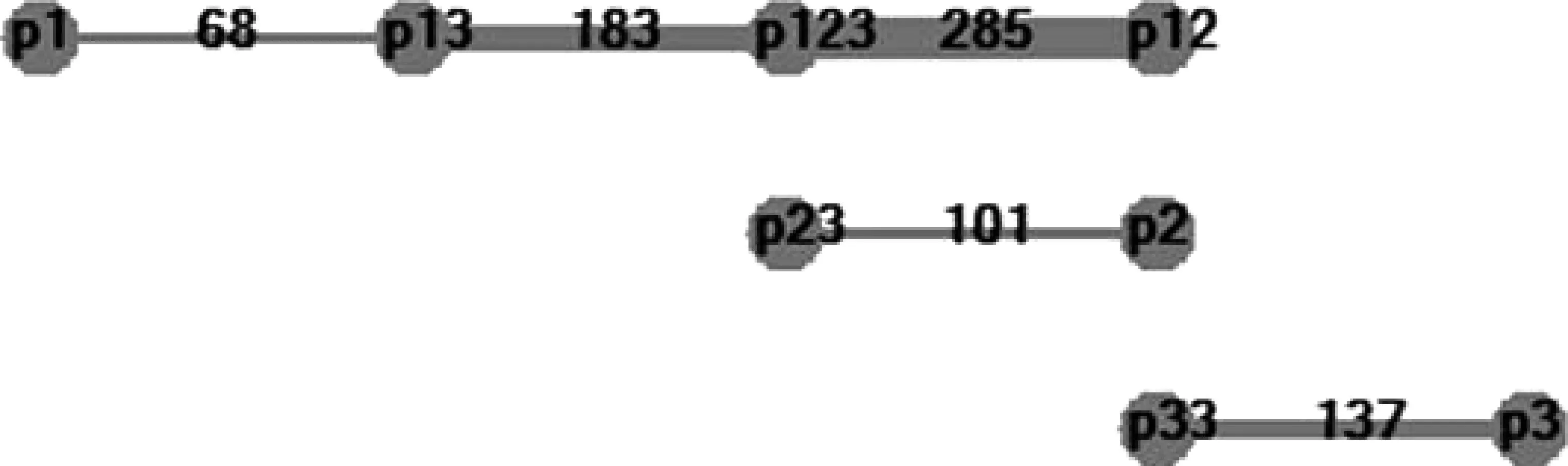
图11 完全加权的人称最小简图
图12、图13。再根据最小简图计算各算法控制度如表10所示。
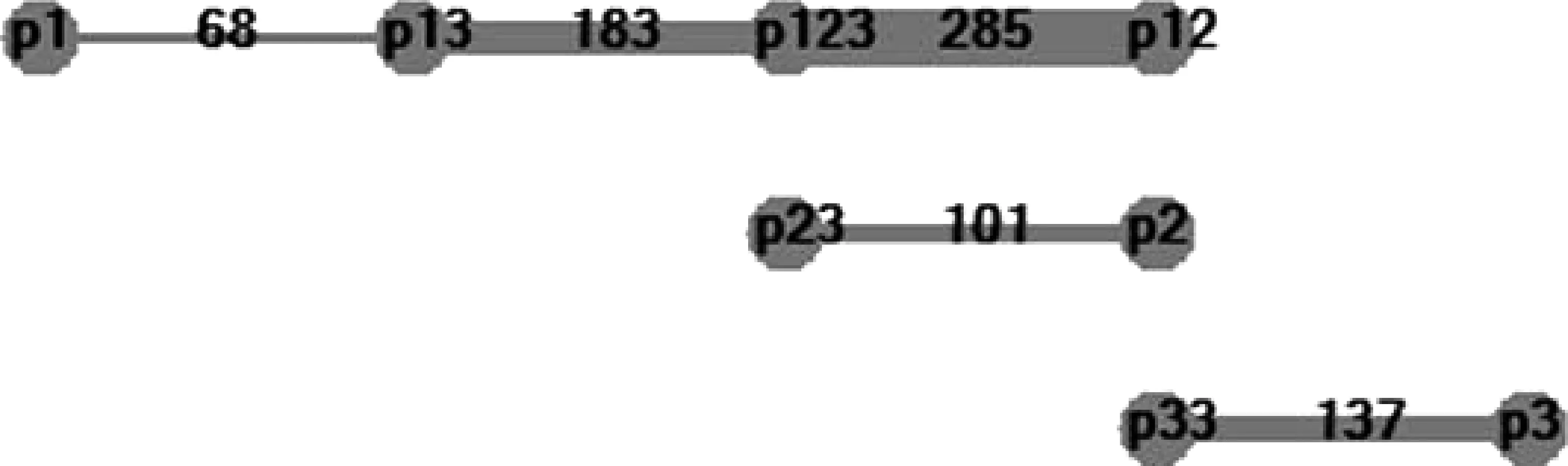
图12 赢家通吃的人称最小简图
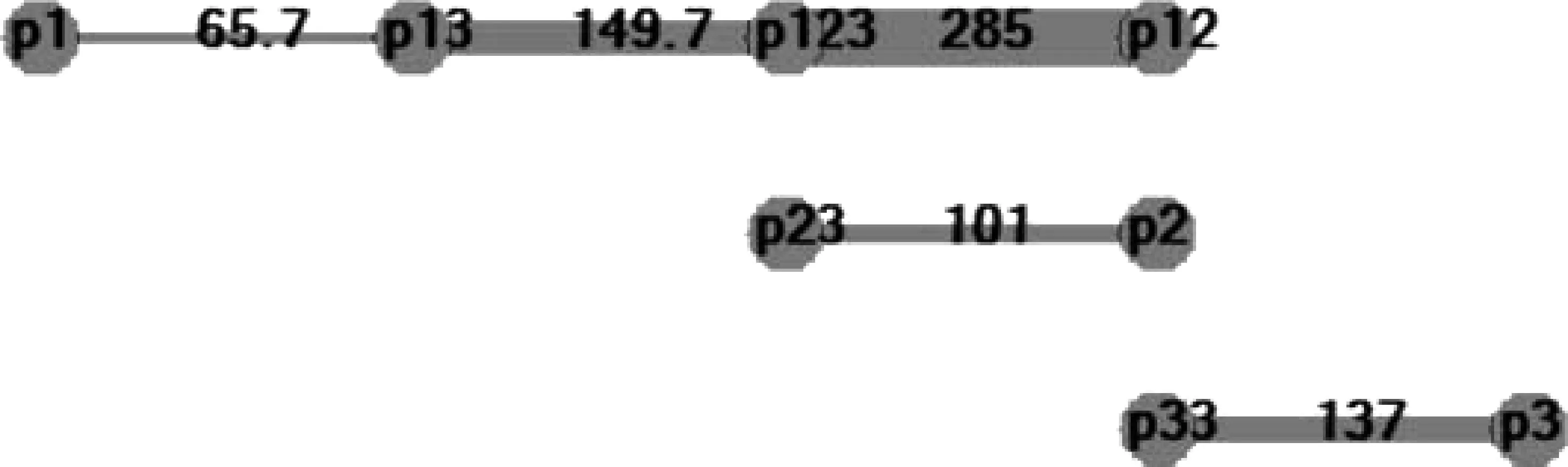
图13 赢多输少的人称最小简图
各算法的最小简图拓扑结构一致,可见最小简图因为“最简约”准确率确实可观。
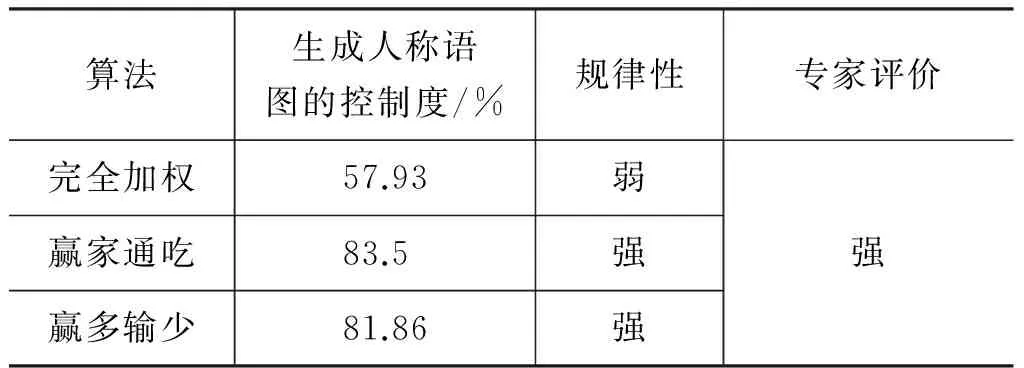
表10 跨语言人称系统的各算法控制度
各算法的最小简图还和前文Cysouw凭主观简化得到的简图1(图5)拓扑一致,可见“语言学家的直觉”确实是有数学规律可循的。
最小简图所揭示的规律比MDS等基元分类法更全面。
1. 可以确定分类: 人称8基元分成三类,第一人称(1、13、123、12)、第二人称(2-23)和第三人称(3-33);
2. 可以确定最主流的控制路径: 第一人称内部控制路径为1-13-123-12;“我”与“我们”间的主要控制中心是排斥听者13;“我们”中包含三方的123居于主要控制中心位置,各排斥了某一方的12和13之间语义关系疏远;
3. 第二人称、第三人称内部只包含两个基元,谈不上控制路径,只表示各自的单复数之间关系最紧密。
尽管最小简图拓扑结构一致,权重差异却很大,各算法所得控制度颇为不同。
完全加权所得控制度颇低,近58%的控制度意味人称系统很“松散”,“最主流”的一、二、三人称之间混淆得很厉害,但研究者直觉上对“人称三分”的规律性评价是较强的[8],这就产生了矛盾。
两种赢家算法算出人称系统控制度高达80%以上,虽然略有差异而在一个数量级中,因此更加合理。
3.2 最大简图
2.1节论及赢家通吃算法在局部生成“最大支撑子树”,这正是一种归纳算法: 删除语图中任意圈里权重相对最小的边,从而把语图中每个圈都“打破”,最后必然得到语图权重最大的支撑子树。
所谓“最大”支撑子树,主要是: 1.保留的边权重相对最大;2.子树支撑全图,最大限度连通所有基元,挖掘的是“覆盖率最大的主流控制规律”,因此称之为“最大简图”。
各算法的人称语图可生成最大简图如图14、图15、图16所示。
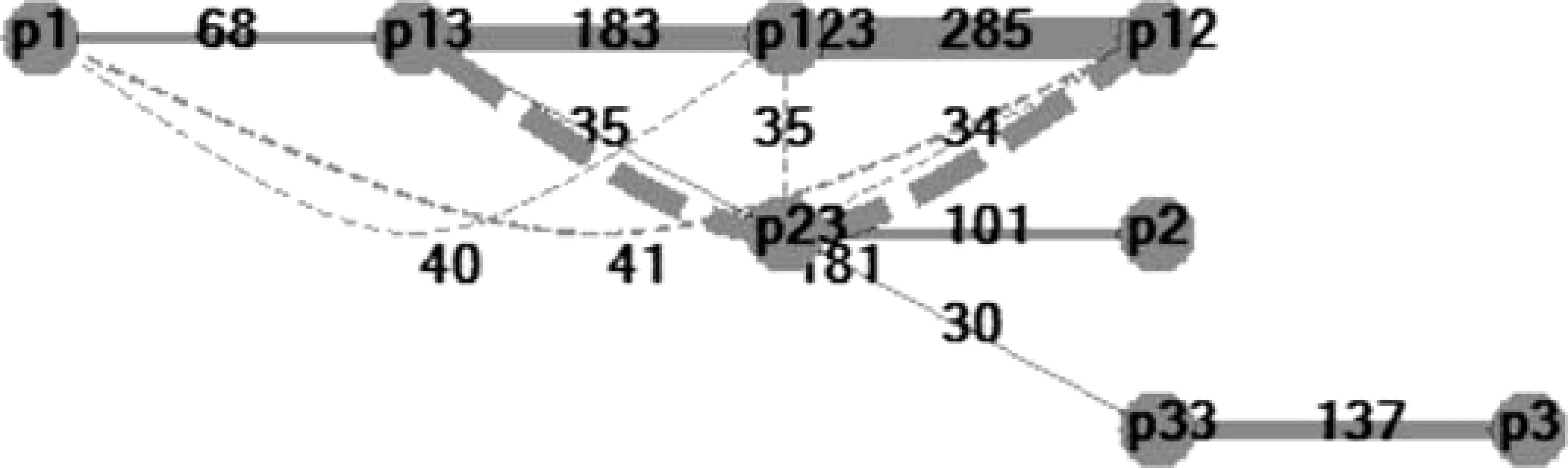
图14 完全加权的人称最大简图
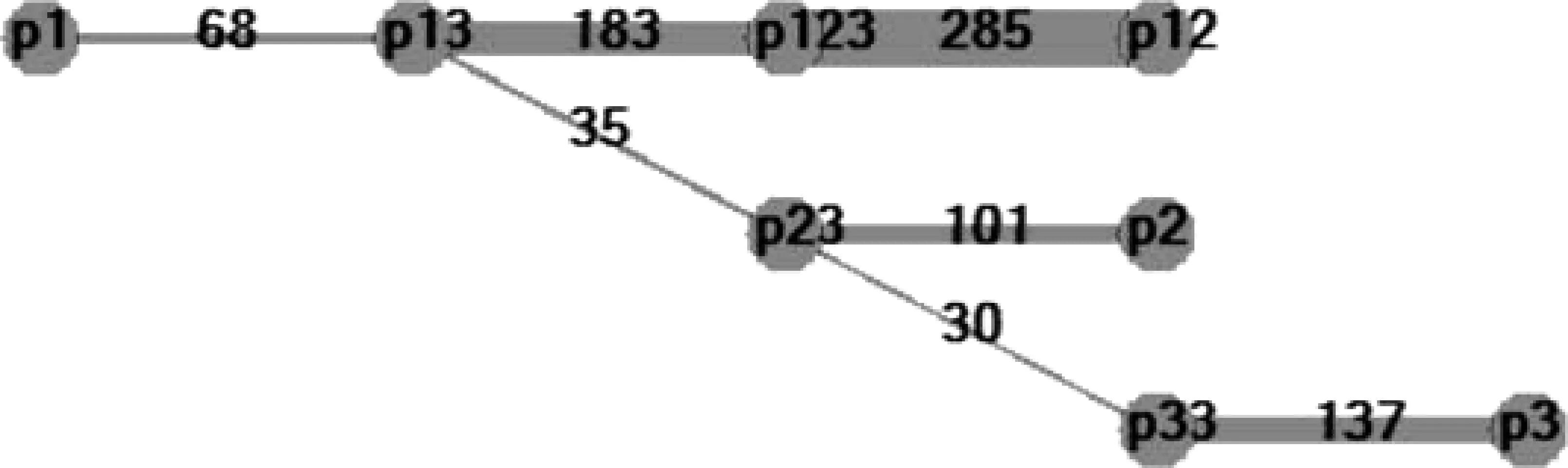
图15 赢家通吃的人称最大简图
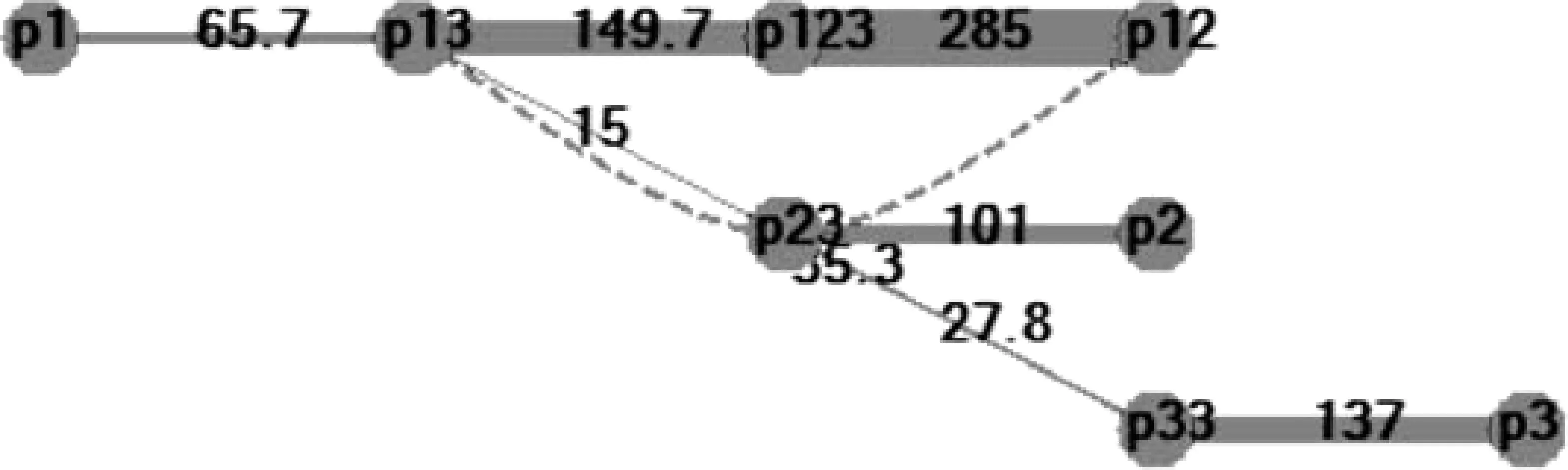
图16 赢多输少的人称最大简图
所有最大简图在“主流”上依旧是拓扑一致的,且与Cysouw主观删减得出的简图6一致。可见这一算法的准确率还是很高,同时语言学家的直觉有数学规律可循。
但是,图中有三条不同的虚线边。虚线边的权重比最大简图中的“最细边”高,这意味着有些权重可以跻身“主流”之列的关系十分“纠结”,很难概括明晰的控制路径,由此而成的圈是“可保留的圈”,相应的虚线边本文称之为“可恢复边”。如果硬要删除不免过度概括。
问题是语图的生成算法不同,可恢复边的情况就不同。不同算法得到人称语图可恢复边共计三条: 1-123、1-12、13-12。
1. 1-123: “我(1)”和典型的“我们(123)”完全没有两两独立共现,恰恰是理想的没有关联的基元。完全加权不兼容理想算法,因其在1、123、13三点共现中出现过,每次都给1-123完全加权,最终其权重较高可恢复,是不合适的。赢家二算法在1、123、13中都只连接1-13,保持权重为0。
2. 1-12: “我(1)”和“咱们(12)”的两两独立共现频次为1,是一个“非主流”规律。完全加权因其在1、12、123、13四点的多点场合里共现过,局部完全图累计较高权重,把“非主流”推成了“主流”,也不大合适。赢家通吃算法把输家1-12断开,赢多输少则保持其为非主流。
3. 12-13: 两个不太典型的“我们”间两两独立共现频次为2,相对较低。但是,它们主要在包含12、123、13三点的多点场合共现,“我们”集成12、123、13是极其主流的现象,有关共现频次数百,远超其他所有共现。因此,12-13“瘦死的骆驼比马大”,获得较高权重。
这确实是非常特殊的情况,赢多输少也能将其挑选出来。而赢家通吃算法因其生成时先行局部最大概括,所有输家都被直接“杀掉”,不免出现概括过度的“误杀”。
4 案例分析
4.1 汉语常用动词和时间标记的搭配
郭锐调查的汉语常用动词和时间标记搭配如表11[10]所示。
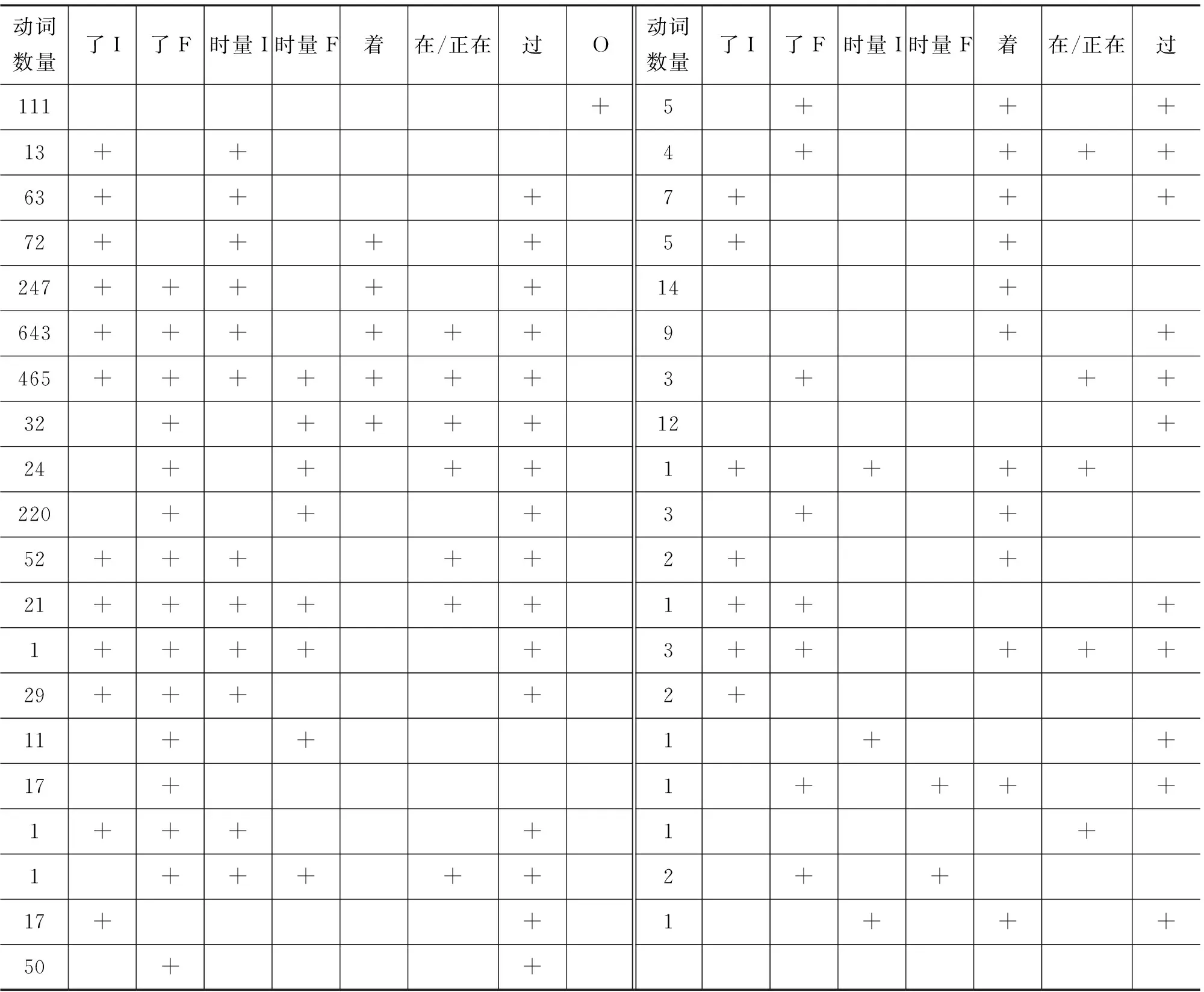
表11 汉语动词与时间标记的搭配
注: “了I”指动词可加“了”表示事件的开始,“了F”表示事件的完结;“时量I”指动词加时量成分表示事件持续的时量,“时量F”表示事件完始后的时量。
暂不考虑第一行不能和所有时间标记搭配的动词,整理其他各行数据,各算法生成的最小简图如图17、图18、图19所示,最大简图如图20、图21、图22 所示。
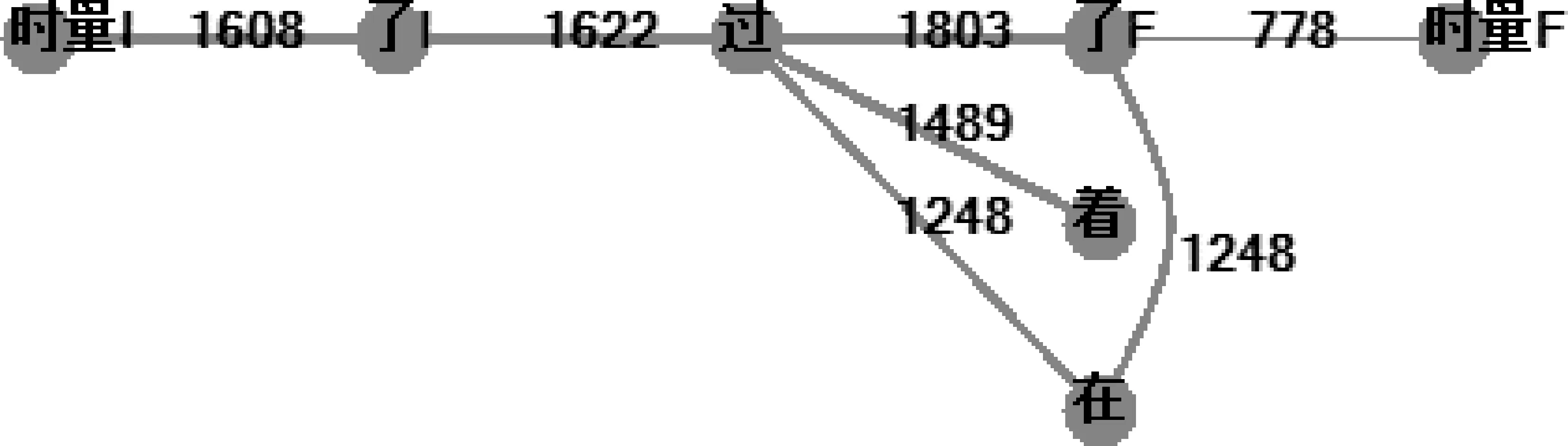
图17 完全加权的时间标记最小简图
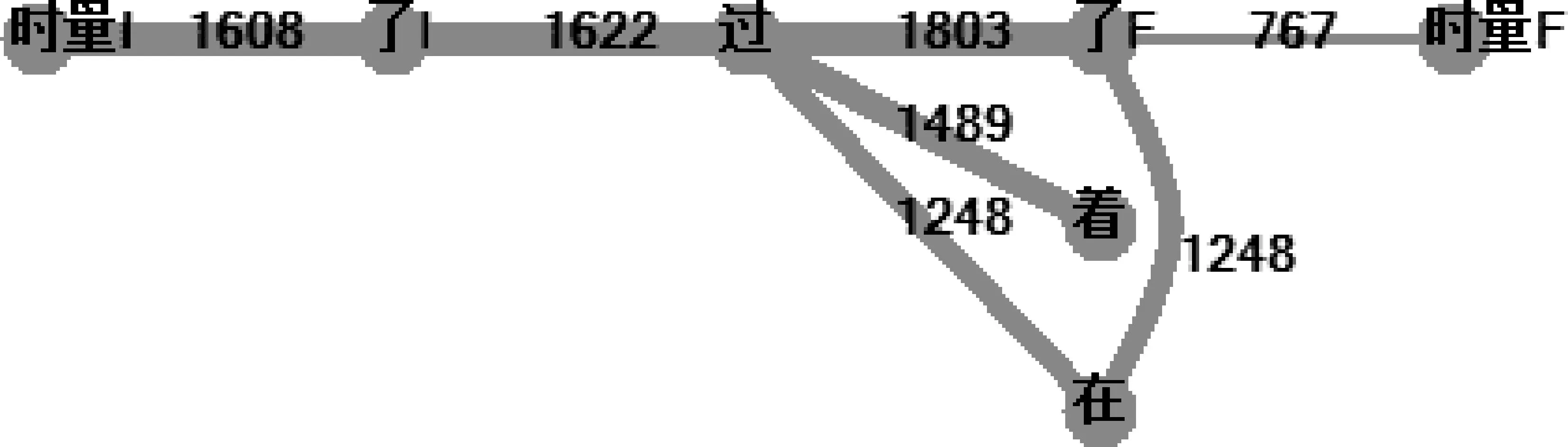
图18 赢家通吃的时间标记最小简图
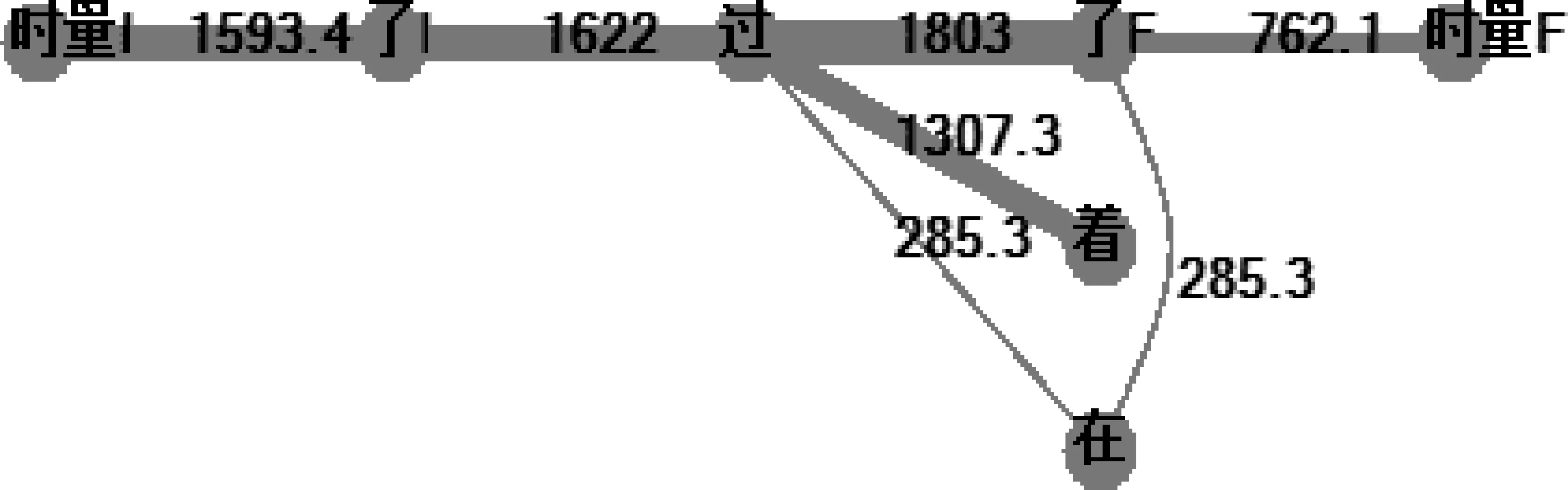
图19 赢多输少的时间标记最小简图
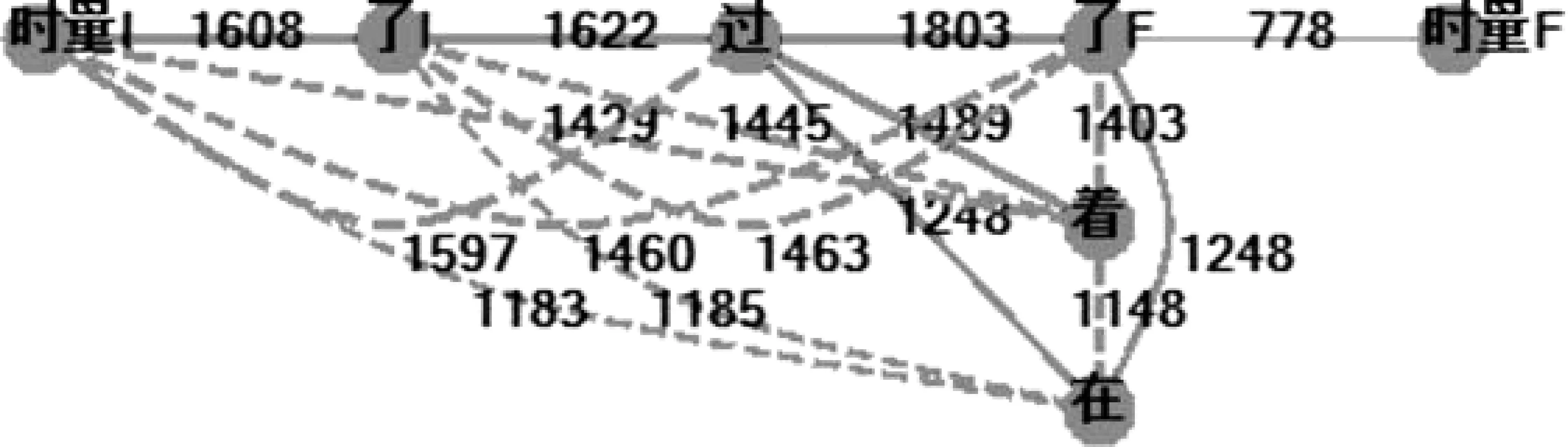
图20 完全加权的时间标记最大简图
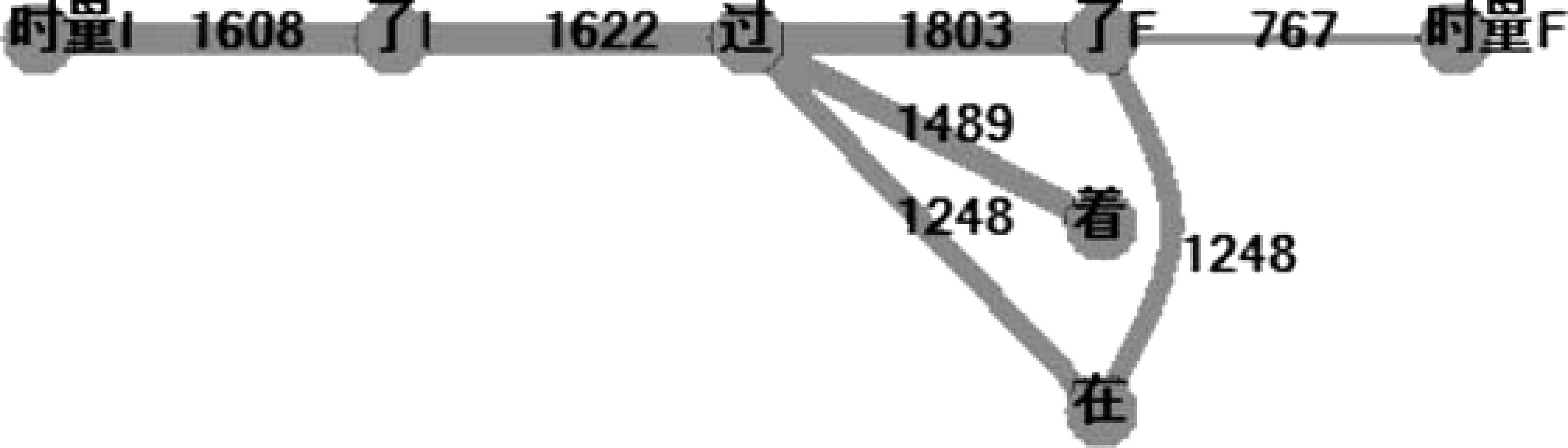
图21 赢家通吃的时间标记最大简图
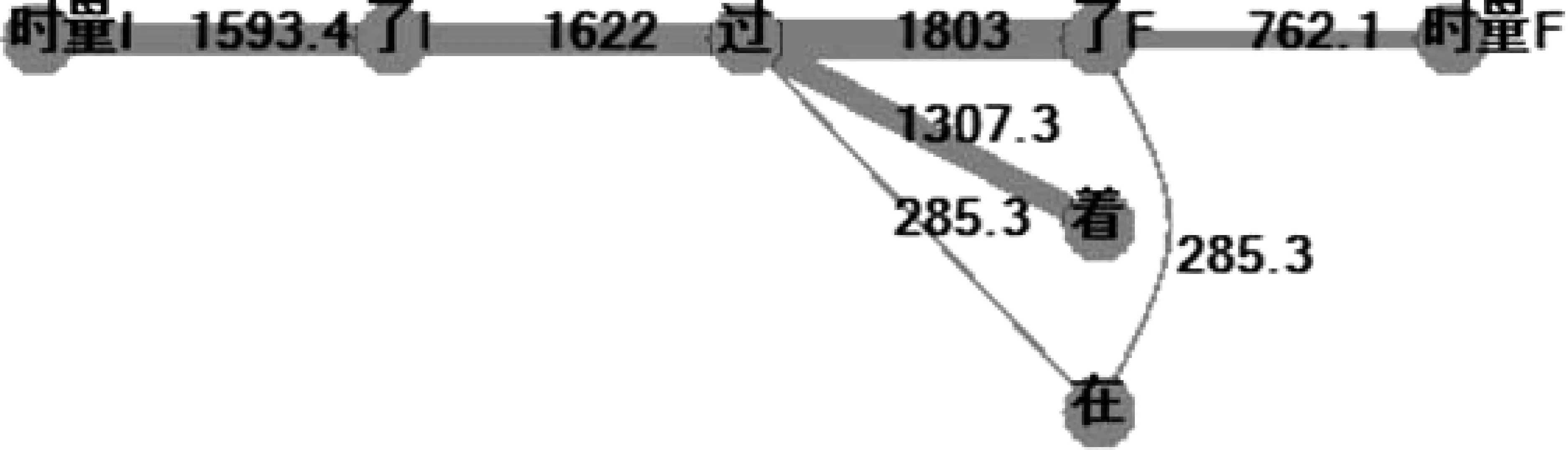
图22 赢多输少的时间标记最大简图
所有最小简图拓扑一致,“最主流”的规律准确率高:
1. 汉语的时间标记统为一类;
2. 不论歧义,基本上是以“过”为控制中心的星图;
语言学解释: “过”的语义模型包含事件“开始、持续、结束”阶段整体,因此分别控制表开始的“了I”、结束的“了F(结束)”、持续的“着、在”。
3. “时量I、时量F”分别只与“了I、了F”关联,符合其语言学定义;
4. “在”有歧义,“在”和表结束的“3F”也联系紧密。
“在、着”都表示持续阶段,其中“在”是动态持续,“着”是静态持续。那么,我们是否可以考虑: 动态和静态的差异在于,动态更倾向于结束,而静态的结束点相对“遥遥无期”?
各算法最大简图的主流是一致的。“可复活边”差异很大。
赢家二算法没有可复活边,最大简图和最小简图合一了。可见在这两种算法中,主流控制规律是很明晰的。
完全加权算法却大大不同,它的可复活边极多,各种关联纠结在一起。似乎“汉语时间标记关联混乱,几乎难以确定规律”,但这正是完全加权违背了理想算法所造成的“误会”。
例如,“了I、了F”,它们的语言学定义就是分化“了”的两种情况,不可能出现大量纠缠不清的关联。但完全加权后边“了I-了F”的权重高达1 463,显然不合理。
计算时间标记系统各算法的控制度,如表12所示。
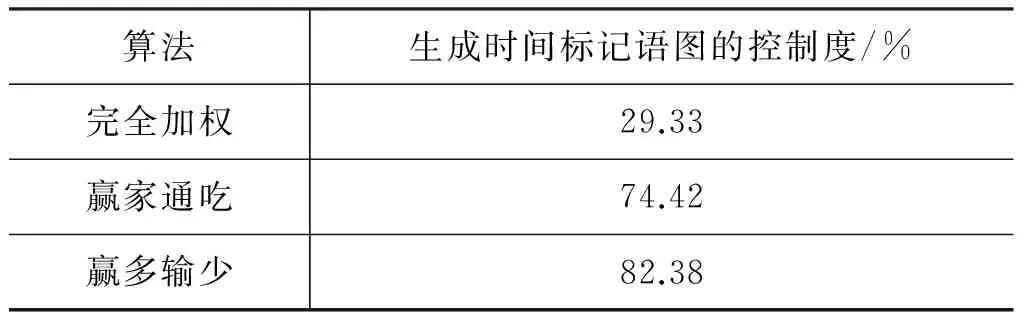
表12 时间标记系统的各算法控制度
完全加权算法的控制度极低,这与其可复活边畸多的现象一致。赢家通吃和赢多输少的控制度相对很高,因为它们没有可复活边,主流控制规律明晰。
确实,汉语是显性规律很少的语言,汉语的“时间标记”没有彻底标记化,时间标记系统没有100%控制度。
但是,研究者普遍称之为时间“标记”,将之归类为“虚词/功能词”,汉语时间标记即使没有完全标记化,其标记程度还是比较高的,赢家二算法明显比完全加权更符合“语言学家的直觉”。
值得注意的是时间标记系统里控制度最高的不是赢家通吃,而是赢多输少。
究其原因在于歧义: 遇到歧义无法取舍,赢家通吃会直接给予所有歧义边都加权100%,赢多输少则认为“m个歧义=m条机会相当比例均等的路”,因此给每条歧义边1/m加权。所以歧义边越多、越“重”的系统中,赢家通吃的歧义会比赢多输少“重”得多,按公式1反而减弱了控制度。
可见,赢家二算法的概括力度高低不可一概而论,有待深入研究。
4.2 多个语言系统控制度参数研究
对于不同的系统,我们需比较它们的控制度。作为社会性系统,其隐性控制的程度会有差异,呈现出一种动态的梯级,其中一端是最为严格的控制系统,其控制度为1,即最小简图与全图完全一样,这种系统就可以直接显性化了;另一端则是完全没有隐性控制的自由状态的系统,控制度为零,即无法抽取出最小简图。
1.1节中的表1理想状态下控制度为1,表2完全无控制则为0,大部分系统则居于中间。我们对语言现象做了大量的实证研究,其控制度如表13所示。
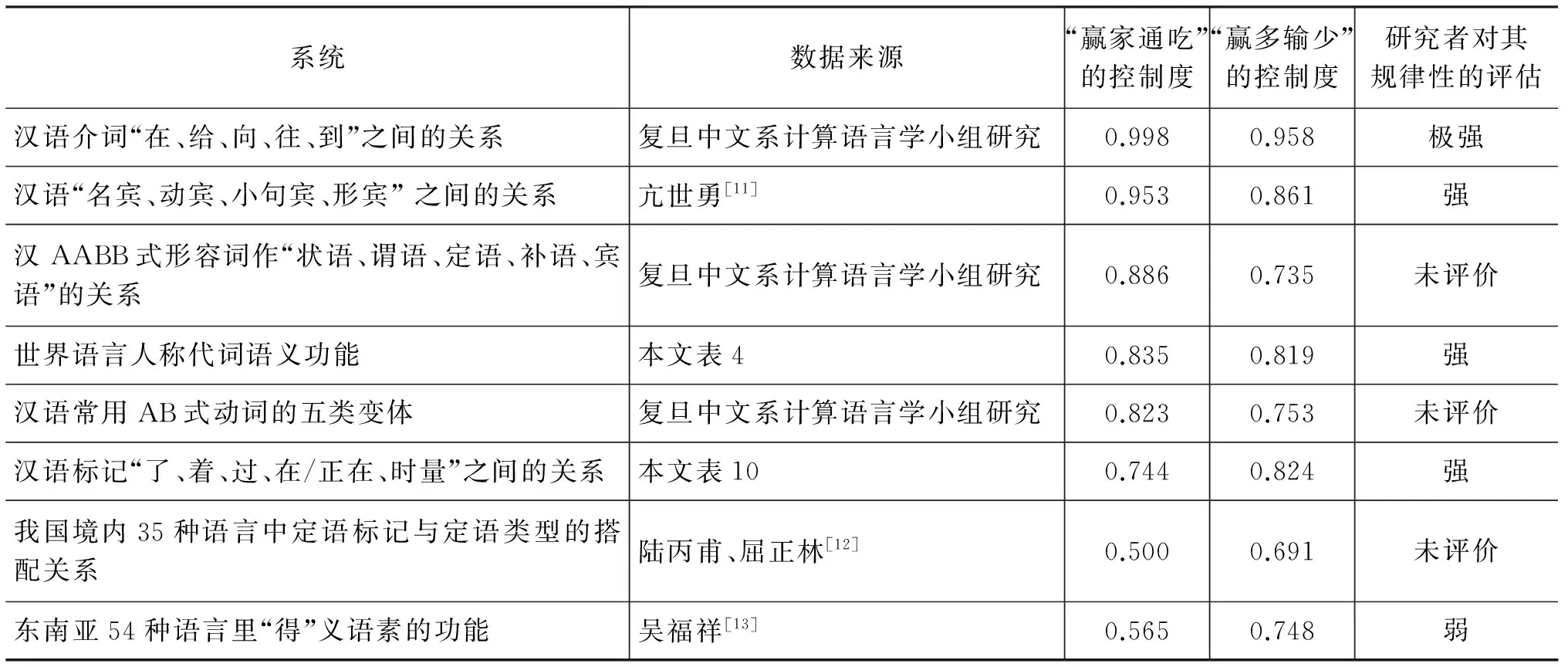
表13 不同系统控制度参数举隅
上述研究中,同一语言内部一般的系统控制度普遍高,跨语言的对比分析中则有高有低这可能是两个原因造成的,
1. 同一语言内部共性普遍较强,跨语言间的共性偏弱;
2. 同一语言内部数据调查容易些,数据多歧义易分化;跨语言调查困难,数据不足导致歧义畸多。
5 结论
语图是一种研究系统规律的工具: 在多基元共现调查数据的基础上,通过算法生成一张语图,再从中归纳隐性规律。
以“理想数据”为出发点的理想算法遵循图论的原则,是一种极好的算法。但对现实中大量出现的“非理想数据”无能为力。而过去采用“完全加权”或与之本质相同的算法(如“完全关联度”等)来处理“非理想数据”,导致算法在每个局部没有概括力,生成的整个语图概括度偏弱。本文的研究即致力于解决这一问题,同时也注意到需要避免概括过度。
笔者提出的“赢家”二算法,试图在非理想数据中继续贯彻理想算法的策略: 生成时步步按整体情况统计的“两两独立共现”频次计算各边的优先顺序,对n基元共现取n-1个边为赢家,其余为输家,通过“优胜劣汰”博弈优化,大大增加了概括力度。
其中,赢家通吃把共现频次只赋予赢家,在每个局部达到最大概括,从而使整个语图概括力度最大化,缺点是造成过度概括。赢多输少则更注意兼顾均衡,对赢家与输家按比例分配权重,在保证概括力度的同时防止出现过度概括。
本文还提出了前人尚未考虑到的问题,即对“非理想数据”如何评估其规律化的程度。为此引入了最小简图,并通过它与全图的权重比较计算出系统的控制度参数。
挖掘规律要兼顾准确率和覆盖率。最小简图的“准确率”最大,但“覆盖率”不足。为此,本文又构建了“最大简图”分析。
文中对语言学若干案例进行了研究,赢家二算法较之过去的算法更吻合系统的数据表现和语言学解释。赢多输少的归纳更适中,尤其在着重覆盖率的最大简图算法中所得简图更精确。另外,通过对若干语言系统的赢家二算法控制度进行比较,确实是参数取值越大,系统规律性越高。以上具体研究,还需要更多的检验和深入研究。
笔者为本文讨论的所有算法编制了程序,可在本文两位作者建设的网站“永新语言学(http://www.newlinguistcs.org)”输入数据自动计算权重控制度、绘制语图。据作者所知,本文研究至少在国内尚属首创,虽然具有填补空白的功效,但也难免会考虑不够周全。网站的目的既是为广大同行提供可资运用的技术手段,也是为了请研究者们提出批评意见。
[1] 曹晋.语义地图理论及方法[J].语文研究,2012(2):3-6.
[2] 郭锐.语义地图概念的最小关联原则和关联度[A].李小凡,张敏,郭锐.汉语多功能语法形式的语义地图研究[M].北京:商务印书馆,2015,152-172.
[3] H.Martin,The geometry of grammatical meaning:semantic maps and cross-linguistic comparison[C]//Proceedings of the New Psychology of Language:Cognitive and Functional Approaches to Language Structure.Mahwah,NJ.Erlbaum.2003:211-242.
[4] Reinhard Diestel,于青林,王涛译.图论(第四版)[M].北京:高等教育出版社,2013.
[5] 陈振宇,陈振宁.通过地图分析揭示语法学中的隐性规律——“加权最少边地图”[J].中国语文,2015,05:428-438.
[6] Nooy, Mrvar, Batagelj,等. 蜘蛛: 社会网络分析技术(第二版)[M].北京:世界图书出版公司,2012.
[7] H Martin.Indefinite Pronouns[M].Oxford:Clarendon,1997.
[8] C Michael.Building Semantic Maps:the Case of Person Marking[M].M Miestamo & B Walchli.New Challenges in typology:Broadening the horizons and redefining the foundations.Berlin:Mouton,2007:225-248.
[9] Ferdinand de Haan. On Representing Semantic Maps[EB/OL]. URL:http://emeld.org/workshop/2004/deHaan-paper.doc.2004.
[10] 郭锐.汉语动词的过程结构[J].中国语文,1993,06:410-419.
[11] 亢世勇.面向信息处理的现代汉语语法研究[M].上海:上海辞书出版社,2004.
[12] 陆丙甫,屈正林.语义投射连续性假说:原理和引申——兼论定语标记的不同功能基础[M].语言学论丛(第四十二辑).北京:商务印书馆,2010:112-128.
[13] 吴福祥. 从“得”义动词到补语标记——东南亚语言的一种语法化区域[J]. 中国语文,2009,03:195-211,287.
Revealing Covert Laws in Language Systems Through Graphs——Algorithms of Winner-Get-All & Winner-More-Loser-Less
CHEN Zhenning1, CHEN Zhenyu2
(1. School of Humanities, Zhejiang University, Hangzhou, Zhejiang 310058, China;2. Department of Chinese Langage and Literature, Fudan University, Shanghai 200433, China)
We tried to reveal convert laws with quantitative analysis through graphs and designed two generating algorithms of language graphs: Winner-get-all and Winner-more-loser-less, which extend the game theory used by idea-algorithm to none-perfect state. Compared to previous methods, the proposed two algorithms have better generalization capability. Especially, we balance between full and modest generation in the Winner-more-loser-less algorithm. There are two kinds of inductive algorithms to mine mainstream rules and analyze linguistic laws: Min-Subgraphs for accuracy, as well as Max-Subgraphs for coverage. A formula for control degree based on min-subgraphs is put forward to evaluate language systems.
covert laws; graph theory; game theory; rules mining

陈振宁(1977—),博士研究生,主要研究领域为计算语言学。E-mail:706867589@qq.com陈振宇(1968—),通信作者,副教授,主要研究领域为汉语句法语义。E-mail:chenzhenyu@fudan.edu.cn
1003-0077(2015)05-0020-11
2015-08-10 定稿日期: 2015-09-26
教育部人文社会科学规划基金“现代汉语句法与语义计算研究”(13YJA740005)
TP391
A
猜你喜欢
兵工学报(2021年4期)2021-06-19
小天使·三年级语数英综合(2021年3期)2021-06-15
声学与电子工程(2021年1期)2021-04-19
暨南学报(哲学社会科学版)(2020年5期)2020-05-15
中国外汇(2019年12期)2019-10-10
语文教学与研究(综合天地)(2018年10期)2018-12-24
科学导报(2018年30期)2018-05-14
校园英语·下旬(2016年3期)2016-04-18
中国测试(2015年11期)2015-12-17
中学英语之友·上(2008年1期)2008-03-20
