
利用词的分布式表示改进作文跑题检测
2015-04-21 10:52陈志鹏陈文亮朱慕华
中文信息学报 2015年5期
陈志鹏,陈文亮,朱慕华
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 软件新技术与产业化协同创新中心,江苏 苏州 215006;3. 淘宝(中国)软件有限公司,浙江 杭州 311100)
利用词的分布式表示改进作文跑题检测
陈志鹏1,2,陈文亮1,2,朱慕华3
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 软件新技术与产业化协同创新中心,江苏 苏州 215006;3. 淘宝(中国)软件有限公司,浙江 杭州 311100)
作文跑题检测任务的核心问题是文本相似度计算。传统的文本相似度计算方法一般基于向量空间模型,即把文本表示成高维向量,再计算文本之间的相似度。这种方法只考虑文本中出现的词项(词袋模型),而没有利用词项的语义信息。该文提出一种新的文本相似度计算方法:基于词扩展的文本相似度计算方法,将词袋模型(Bag-of-Words)方法与词的分布式表示相结合,在词的分布式表示向量空间中寻找与文本出现的词项语义上相似的词加入到文本表示中,实现文本中单词的扩展。然后对扩展后的文本计算相似度。该文将这种方法运用到英文作文的跑题检测中,构建一套跑题检测系统,并在一个真实数据中进行测试。实验结果表明该文的跑题检测系统能有效识别跑题作文,性能明显高于基准系统。
文本相似度;词分布式表示;跑题检测;文本表示
1 引言
作文跑题指文章偏离了预设的主题。举个例子,例如,现在有一个题目“online shopping”,很明显是要求写关于网上购物的文章。如果学生写的文章与此无关,而是写的其他主题的文章,比如写的是关于读书的文章或者是关于大学生活的文章,我们就认为该作文跑题。作文的质量和是否跑题没有必然联系,有的文章虽然写的很短很差,但是并没有跑题。作文跑题的原因很多,可能是作者有意为之,也可能是无意间的提交错误。
作文跑题检测用于判断一篇作文是否跑题,其核心是计算文本之间的相似度,根据相似度和跑题标准来判断文章是否跑题[1]。文本相似度是表示两个文本之间相似程度的一个度量参数。除了用于文章跑题检测,在文本聚类[2]、信息检索[3]、图像检索[4]、文本摘要自动生成[5]、文本复制检测[6]等诸多领域,文本相似度的有效计算都是解决问题的关键所在。
目前最常用的文本表示模型是向量空间模型VSM (Vector Space Model)。向量空间模型的基本思想是用向量形式来表示文本:vd=[w1,w2,w3,……,wn],其中wi是第i个特征项的权重。最典型的向量空间模型是词袋模型(Bag-of-Words)。该方法以文本中的词作为特征项形成向量表示,并且采用词的TF-IDF值作为特征权重*TF-IDF是常用的特征权重计算方法。除此之外,亦可采用二元特征或者以词频作为权重。。词袋模型方法简单而且有一定效果,但是这种方法忽略了文本中词项的语义信息,没有考虑到词与词之间的语义相似度。例如,“笔记本”和“手提电脑”这两个词在词袋模型中被认为两个独立的特征而没有考虑这两个词在语义上的相近性。
针对传统向量空间模型在文本相似度计算中存在的问题,很多研究人员进行了研究,其中词扩展是最常见的一种策略。现有词扩展方法主要采用基于词典的方法,比如使用WordNet[7]、HowNet等词典。文献[8]提出了基于WordNet词扩展计算英语词汇相似度的方法。文献[9]提出了基于HowNet计算词汇语义相似度的方法,并将其用于文本分类。这些方法严重依赖于人工构造的词典资源,在新语言和新领域应用中会遇到很多问题。
针对上述现有方法的不足,本文将词袋模型与词语的语义信息结合起来,提出一种基于词分布式表示[10]的文本相似度计算方法。我们首先对文本中单词进行分布式表示,即将它们映射为向量形式,然后在分布式的词向量空间中找出与其语义上相近的词,并将它们加入到文本表示中,最后再计算扩展后的文本相似度。本文将这种方法运用到英文作文的跑题检测中,构建了一套跑题检测系统,并在一个真实数据集上进行了测试。实验结果表明本文的跑题检测系统能有效识别跑题作文,性能明显高于基准系统。
本文的其余部分做如下安排:第2节对相关工作进行介绍;第3节详细介绍我们提出的计算文本相似度的方法。第4节介绍实验和结果分析,第5节是结论和下一步工作介绍。
2 相关工作
TF-IDF方法是一种经典的基于向量空间模型的文本相似度计算方法。它用词的TF-IDF值来衡量其对于文本的重要程度,一个词的重要程度与它在文章中出现的次数成正比,但同时也会与它在语料库中出现的频率成反比。这里包含了两个重要的概念。
词频(TermFrequency),即一个词在文档中出现的次数。一个词在文章中出现的次数越多,它对这篇文章就越重要,它与文章的主题相关性也就越高。要注意的是停用词(stopwords),像中文的“的”、“了”,英文的“a”、“the”,这些词并不具备这种性质,它们虽然出现的次数比较多,但是它们不能反映文章的主题,应该将它们过滤掉。
逆文档频率(InverseDocumentFrequency),如果一个词在文档集合中出现的次数越多,说明这个词的区分能力越低,越不能反映文章的特性;反之,如果一个词在文档集合中出现的次数越少,那么它越能够反映文章的特性。例如,有100篇文档,如果一个词A只在一篇文档中出现,而词B在100篇文档中都出现,那么,很显然,词A比词B更能反映文章的特性。
将上面两个概念结合起来,我们可以计算一个词项的TF-IDF值,对于一个词项(wi):
(1)
其中TFIDF(wi)表示当前词项wi的TF-IDF值,tf(wi)表示词项wi的词频,idf(wi)表示词项wi的逆文档频率,词项wi的TFIDF(wi)等于tf(wi)乘以idf(wi)。很显然,词频就等于一篇文档中该词项出现的次数除以文章的总词数,而逆文档频率的计算公式如式(2)所示。
(2)
N表示的是文档集合中文档的总数,df(wi)是包含词项wi的文档的总数,加1是为了防止分母为0。将式(2)带入到式(1)中,词项TF-IDF值的计算公式为
(3)
根据上述公式计算出文本中每个词项wi的TD-IDF值,然后利用这些TF-IDF值,将文档转化成一个向量空间模型,再利用余弦公式来计算相似度。余弦公式[11]如下:
(4)
其中,D1,D2表示两个文本向量,a1k表示第一篇文章D1中单词的TF-IDF值,a2k表示第二篇文章D2中单词的TF-IDF值。
TF-IDF方法是一种简单有效的计算文本相似度的方法,但是这种方法并没有考虑词语背后的语义信息,忽视了词与词之间的相似度。人们为了更准确的计算文本相似度,提出了一些基于语义的相似度计算法:文献[12]和文献[13]提出了基于本体的文本特征抽取和相似度计算方法。文献[14]提出了基于HowNet语义词典的文本相似度计算方法。文献[15]利用WordNet语义词典研究局部相关性信息以此来确定文本之间的相似性。这些方法利用了特定领域的知识库来构建词语之间的语义关系,与基于统计学的方法相比准确率有提高,但是知识库的建立是一项复杂而繁琐的工程,需要耗费大量人力。与上述方法不同的是,本文将词进行分布式向量表示,在新的分布式表示空间,自动地找出与某个词项语义上相似的单词,将这些词加入到文本的表示中,然后再用传统的方法对文本进行相似度计算。
作文跑题检测的研究起于国外,目的是为了提高作文自动评分系统的性能。随着研究的深入,许多研究者提出了检测作文跑题的方法。文献[1]提出了一种不需要特定主题训练数据的跑题检测方法。文献[16]利用主题描述来检测作文跑题的方法,通过计算文章与主题描述的相似性来判断文章是否跑题。和这些方法相比,本文的不同之处在于计算文章与范文的相似度来判断是否跑题,计算时采用了基于词分布式表示的词扩展方法,提高了检测系统的性能。
3 作文跑题检测
本文将词的分布式表示和向量空间模型结合,提出一种新的作文跑题检测方法。
3.1 词的分布式表示(WordDistributedRepresentation)
自然语言处理中,将一个词表示为向量的最简单、最常用方式是One-hotRepresentation。这种方法把词表中的每个词表示为一个很长的向量,向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。比如:“笔记本”和“手提电脑”,“笔记本”的表示为[0,0,0,1,0…0…],“手提电脑”的表示为[0,0,0,0,0,0,1,0,0…0…]。这种表示方法简单有效,不过忽视了词的语义信息,“笔记本”和“手提电脑”是语义上近似的词,但这种方法表示出的向量却无法反映这点。
词的分布式表示(WordDistributedRepresentation)是指将词表中的词映射为一个稠密的、低维的实值向量,每一维表示词的一个潜在特征。这种方法基于深度学习,可以表示出词与词之间的联系。例如,“笔记本”表示成[0.231,0.678,-0.535,0.178…],“手提电脑”表示成[0.032,0.561,0.233,0.411…],向量的维数可以在训练前通过手工设定,是一个固定的值。虽然我们无法确切解释每一个维度具体表示什么,但是我们可以根据单词的向量形式找出与其语义上相近的词。
3.2 基于词分布式表示的词扩展
基于词的分布式表示,本节先进行词扩展,然后基于词扩展结果计算文档间相似度。基于词扩展的文档相似度计算具体描述如下所示。
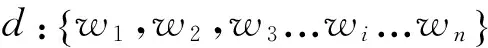
3.3 跑题检测
在本文跑题检测任务中,对每个作文题目给定K篇文章作为范文。利用上节描述的词扩展得到的文本表示,计算学生作文和范文之间的相似度。本文使用余弦相似度(Cosine)来计算相似度。假设给定的K篇范文集合记为D,其中第m篇范文记为dm(1≤m≤K),学生作文dx,则相似度计算过程如下。
首先,使用之前所述的方法计算范文与学生作文的相似度Sim(dm,dx),然后系统取均值作为最终相似度Sim(dx),如式(5)所示。
(5)
我们用最终相似度作为系统对文章的评分,将其与系统的阈值进行对比,以此来判断作文有没有跑题。
4 实验
本节先介绍实验数据,再介绍如何构造标准集,以及实验的评价方法,最后一部分是实验的结果和分析。
4.1 实验数据
本次实验中,我们收集了10 709篇英文作文,共包括20个不同的题目,每个题目下有500篇左右的文章。这些文章都有教师对文章的总体评分,评分越高的文章写得越好,为了便于比较,在实验前,我们先对每个题目下的文章评分进行归一化处理,将文章的人工评分映射到0到1的范围。对于每个作文题目,选择人工评分靠前的K篇文章作为我们的范文。
为了学习词语的idf值和训练词向量,我们另外收集了41 225篇不带评分的英文作文。
词向量的训练方法有很多,Bengio等人提出FFNNLM模型[17](Feed-forwardNeuralNetLanguageModel)可以训练出词的向量表示形式,不过FFNNLM并非是专门用来训练词向量,词向量只是训练模型过程中产生的副产品。Google开源了一款专门用来训练词向量的工具Word2Vec[18-20],它可以根据给定的语料库,通过训练后的模型将词表示成向量形式,并能找出与某个词语义上相近的词。相比较FFNNLM模型,Word2Vec对训练模型做出了优化,运行速度更快。我们的实验使用Word2Vec工具*https://github.com/NLPchina/Word2VEC_java来训练词向量。
4.2 构造标准集
标准集里面包含的是人工判断为跑题的文章的集合。由于文章数目较多,不可能人工检查所有文章,因此我们借助教师评分自动构造标准集。构造标准集的步骤如下。
(1) 将各个题目下的文章按照人工评分从高到低排序。评分越高说明文章写得越好,这部分文章几乎不会跑题;而分数越低说明文章写得越不好,这里面可能就有跑题的文章出现。
(2) 对于每个作文题目的文章,取得分最低的十篇文章,人工阅读每一篇文章,判断它有没有跑题,如果跑题则将它加入到标准集中。对于这十篇文章,如果它们全是跑题的文章,或者绝大多数是跑题的文章,就接着往上检查十篇文章,循环操作直到出现大部分的不跑题文章为止。如果这十篇文章只有少部分跑题,或者完全没有跑题的文章,就完成该作文题目的跑题作文人工检查工作。
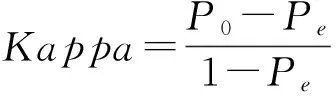
最后得到的标准集共有54篇文章。每个题目下的跑题文章数是不一样的,有的题目比较好写,没有文章跑题;而有的题目比较难写,相对而言,跑题文章较多。表1给出了不同题目下跑题文章的分布。
从表1中我们可以看出,有13个题目下没有跑题文章,占65%,很大的比例;另外,有三个题目下跑题文章数在1到5篇之间;跑题文章数为在6—10篇之间和11篇以上的题目数都是两个。

表1 跑题文章的分布
4.3 实验评价方法
我们利用准确率(Precision)、召回率(Recall)和F1值来评价系统。首先要构造标准集和预测集两个集合,标准集是正确答案的集合,按上述方法构造。预测集是系统预测答案的集合。我们用M来表示标准集合中元素的数目,N表示预测集中元素的数目,假设预测集中有K个元素是标准集中的元素。用P来表示准确率,R表示召回率,F表示F1值,则计算方法如下:
(6)
(7)
(8)
为了更好地分析系统,我们计算召回率取不同
值的时候的准确率和F1值,具体就是计算出当召回率为0.1、0.2、0.3.....1.0的时候的系统的准确率和F1值,以此作为我们评价系统的依据。
4.4 实验结果
本次实验,我们共构建了四套不同的跑题检测系统。除了上述的TF-IDF方法和基于词分布式表示的词扩展方法,还有另外两种方法作为比较:Word2Vec方法和Sent2Vec方法。Word2Vec方法是进行简单地替代和拼接。用单词训练出的词向量来代替TF-IDF方法中的TF-IDF值,然后再将所有单词的词向量首尾相连,拼接成一个长的向量,最后使用余项公式来计算相似度。假设之前TF-IDF方法中的文章表示为一个1×M的向量,每一维表示一个词的TF-IDF值,使用Word2Vec训练出的词向量是N维,用词向量代替TF-IDF值后,文章就表示为一个1×MN的向量。Sent2Vec方法是使用Sent2Vec工具*http://research.microsoft.com/en-us/downloads/731572aa-98e4-4c50-b99d-ae3f0c9562b9/,与Word2Vec不同的是它可以对句子进行分布式向量表示,我们将一篇英文文章看作一句话,然后训练出一篇文章的向量表示,直接用余弦公式计算文章之间的相似度。
图1和图2是选取一篇文章作为范文的实验结果,对于词扩展(WordExtend)方法,每个单词扩展了50个词。

图1 一篇范文时准确率随召回率变化的曲线

图2 一篇范文时F1值随召回率变化的曲线
图3和图4是选取五篇文章作为范文的实验结果。
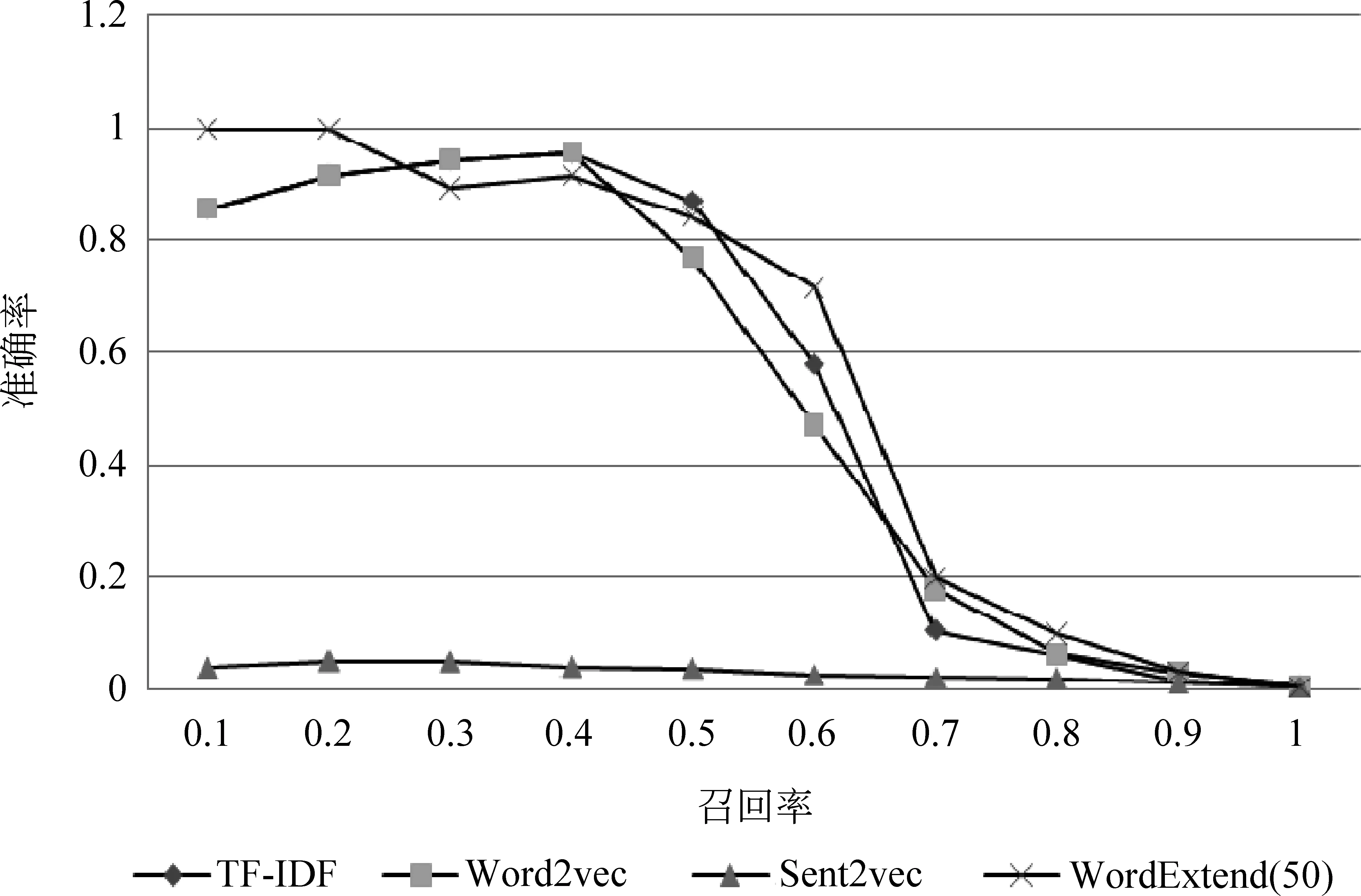
图3 五篇范文时准确率随召回率变化的曲线
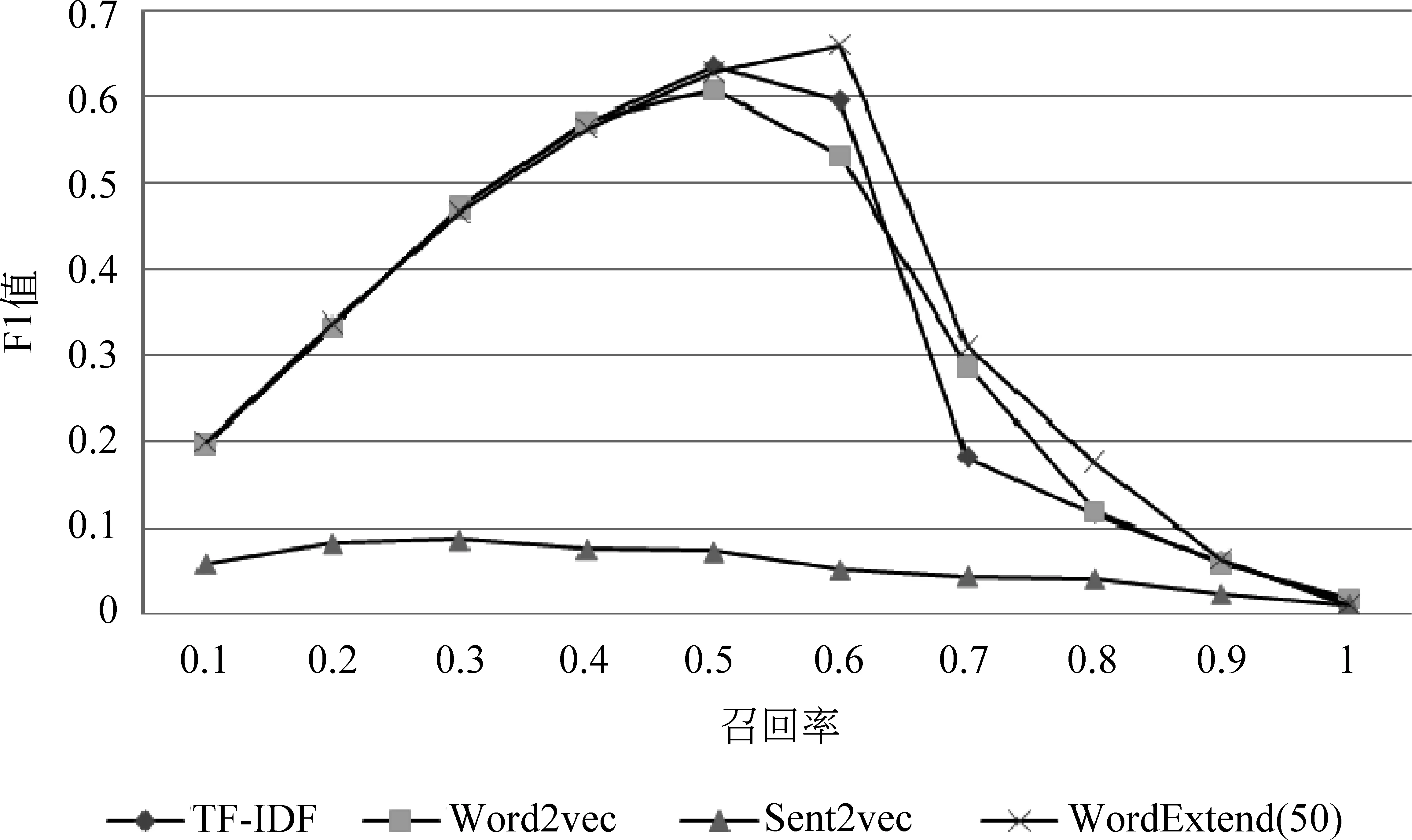
图4 五篇范文时F1值随召回率变化的曲线
从实验结果,我们可以看出:
(1)Word2Vec方法性能略低于传统的TF-IDF方法,Sent2Vec方法的性能最差,而词扩展方法的性能要明显优于其他三种方法。
(2) 当范文数为一的时候,我们可以看到:R=0.6的时候,TF-IDF方法的F1达到峰值,为0.455, 而词扩展方法的F1值为0.611;TF-IDF方法的准确率只有0.363;而词扩展方法的准确率为0.611,相比较之下,使用词扩展方法的系统的整体
性能有明显的提升。
(3) 当范文数为5的时候,TF-IDF方法的F1值最高为0.635,而词扩展方法的F1值的峰值为0.66,略高于TF-IDF方法。
(4) 另外,对比范文数为1的和范文数为5的结果。我们可以发现,范文数少的情况下,词扩展方法的效果比传统的TF-IDF方法明显要好很多。这是因为通过词扩展的方式,一篇范文所包含的语义信息更加丰富,所以系统的判断也会更加准确。在实际使用中这点很有用,因为实际情况下一般不会提供太多范文。
5 结论和下一步工作介绍
本文提出了一种基于词分布式表示的作文跑题检测方法。这种方法将传统的TF-IDF方法和单词语义信息相结合,寻找与文本中单词语义上相近的词,并将其加入到文本的表示中,实现了对文本的词扩展。在此基础上,对扩展后的文本用TF-IDF方法计算相似度。实验结果表明这种方法要明显优于传统的TF-IDF方法。
在接下来的工作中,我们还会进行更深入的研究。例如,文中的词扩展数目是人工选取的50个单词,虽然效果提升明显,但还不是最优解,还有待于通过开发集来选取最优值。另外,还可以改进我们词扩展的方式,寻找一种更好的方式来将单词的语义信息融入到文本相似度的计算中。
[1]DHiggins,JBursteinAttali.Identifyingoff-topicstudentessayswithouttopic-specifictrainingdata[J],NaturalLanguageEngineering, 2006, 12(2): 145-159.
[2]AHuang.Similaritymeasuresfortextdocumentclustering[C]//ProceedingsoftheNewZealandComputerScienceResearchStudentConference, 2008: 44-56.
[3]KUMARN.Approximatestringmatchingalgorithm[J].InternationalJournalonComputerScienceandEngineering, 2010, 2(3): 641-644.
[4]COELHOTAS,CALADOPP,SOUZALV, 等.Imageretrievalusingmultipleevidenceranking[J].IEEETransonKnowledgeandDataEngineering, 2004, 16(4): 408-417.
[5]KOY,PARKJ,SEOJ.Improvingtextcategorizationusingtheimportanceofsentences[J].InformationProcessingandManagement,2004, 40(1): 65-79.
[6]THEOBALDM,SIDDHARTHJ,SpotSigs:robustandefficientnearduplicatedetectioninlargewebcollection[C]//Proceedingsofthe31stAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACMPress, 2008: 563-570.
[7]MillerG.Wordnet:AnOn-lineLexicalDatabase[J].InternationalJournalofLexicography, 1990, 3(4): 235-244.
[8] 颜 伟, 荀恩东. 基于WordNet的英语词语相似度计算[C]//计算机语言学研讨会论文集. 2004.
[9] 朱嫣岚, 闵锦, 周雅倩, 等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1):14-20.
[10]Lee,DanielD,H.SebastianSeung.Algorithmsfornon-negativematrixfactorization[C]//ProceedingsoftheAdvanceinNeuralInformationProcessingSystem.MITPress,2001:556-562.
[11] 张霞, 王建东, 顾海花. 一种改进的页面相似性度量方法[J]. 计算机工程与应用, 2010, 46(19): 141-144.
[12]SánchezJA,MedinaMA,StarostenkoO, 等.OrganizingOpenArchivesviaLightweightOntologtoFacilitatetheUseofHeterogeneousCollection[J].AslibProceedings, 2012, 64(1): 46-66.
[13]VicientC,SánchezD,MorenoA.AnAutomaticApproachforOntology-BasedFeatureExtractionfromHeterogeneousDocumentalResource[J].EngineeringApplicationofArtificialIntelligence, 2013, 26: 1092-1106.
[14]LiuQ,LiSJ.SemanticSimilarityCalculationBasedonHowNet[C]//Proceedingsofthe3rdChineseLexicalSemanticsWorkshop.Taipei,China, 2002: 59-76.
[15]RamageD,RaffertyAN,ManningCD.Randomwalksfortextsemanticsimilarity[C]//Proceedingsofthe2009WorkshoponGraph-basedMethodsforNaturalLanguageProcessing.Suntec,Singapore, 2009: 23-31.
[16]ALouis,DHiggins.Off-topicessaydetectionusingshortprompttexts[C]//ProceedingsoftheNAACLHLT2010FifthWorkshoponInnovativeUseofNLPforBuildingEducationalApplications,LosAngeles,California, 2010:92-95.
[17]YBengio,RDucharme,PVincent,etal.Aneuralprobabilisticlanguagemodel[J].JournalofMachineLearningResearch, 3:1137-1155.
[18]TomasMikolov,KaiChen,GregCorrado,etal.EfficientEstimationofWordRepresentationsinVectorSpace[C]//ProceedingsofWorkshopatICLR, 2013.
[19]TomasMikolov,IlyaSutskever,KaiChen,etal.DistributedRepresentationsofWordsandPhrasesandtheirCompositionality[C]//ProceedingsofNIPS, 2013.
[20] Tomas Mikolov, Wen-tau Yih, Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations[C]//Proceedings of NAACL HLT, 2013:746-751.
Exploiting Distributed Representation of Words for Better Off-Topic Essay Detection
CHEN Zhipeng1,2, CHEN Wenliang1,2,ZHU Muhua3
(1. School of Computer Science and Technology, Soochow University, Suzhou, Jiangsu 215006, China;2. Collaborative Innovation Center of Novel Software Technology and Industrialization, Suzhou, Jiangsu 215006, China;3.Taobao (China) Software Co., Ltd,Hangzhou,Zhejiang 311100, China)
Similarity measure is the core component of off-topic essays detection. To compute the text similarity, the bag-of-words model is widely used, which represents a text as a vector with each dimension corresponds to a word. To further capture the word semantic information, this paper proposes a new method to compute text similarity: a method exploits word distributed representation. The proposed method combines the traditional bag-of-words model with the word semantic information. For each word in a text, we search for a set of similar words in a text collection, and then extend the text vector with these words. Finally we compute text similarity with the updated text. Experimental results show that our method is more effective than baseline systems.
text similarity; word distributed representation; digress test; text representation

陈志鹏(1991—),硕士研究生,主要研究领域为自然语言处理。E-mail:chenzhipeng341@163.com陈文亮(1977—),通信作者,博士,主要研究领域为自然语言处理。E-mail:wlchen@suda.edu.cn朱慕华(1981—),博士,主要研究领域为自然语言处理。E-mail:zhumuhua@gmail.com
1003-0077(2015)05-0178-07
2015-06-29 定稿日期: 2015-09-18
国家自然科学基金(61203314, 61333018)
TP391
A
猜你喜欢
作文成功之路·小学版(2020年9期)2020-10-28
艺术评论(2018年5期)2018-07-23
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
情感读本·道德篇(2017年6期)2017-07-04
东方教育(2017年2期)2017-04-21
课堂内外·创新作文小学版(2016年6期)2016-07-04
雷达与对抗(2015年3期)2015-12-09
中学生天地·高中学习版(2014年8期)2014-08-21
自动化博览(2014年12期)2014-02-28
