
保险公司重大自然灾害的内部模型构架
2015-04-25 01:58章力
上海保险 2015年5期
章 力
德国安顾保险集团风险管理部
保险公司重大自然灾害的内部模型构架
章 力
德国安顾保险集团风险管理部
一、概述
自然灾害是指由于自然界异常变化造成的人员伤亡、财产损失、社会失稳、资源遭破坏等现象或一系列事件。它的形成必须具备两个条件:一是要有自然异变作为诱因,二是要有受到损害的人、财产、资源作为承受灾害的客体。
2004年上映的电影《后天》给了大家一个很直观的感受,大自然如果真的展现其破坏力,人类的一切活动,包括生存都将受到威胁。现实生活中,我们自然不会有机会经历到电影中所描绘的情景,然而自然灾害所带来的实际损失依然是触目惊心的。例如:2005年8月的卡特琳娜飓风,在美国境内一共造成至少1833人丧生,直接经济损失达到1080亿美元。中国2008年的汶川地震,尽管国家已经投入了巨大的人力物力救灾,依然有8万多人死亡或失踪,37万人受伤,直接经济损失达8000多亿元人民币。表1记录了自1980年以来,全球发生的造成损失最严重的自然灾害。
灾害的发生通常都是小概率事件,但同时伴随的却是极其惊人的人员伤亡和经济损失。在目前科学技术尚未掌握大多数自然灾害形成规律的时候,如何对自然灾害进行监测、预警,比如利用飞机和卫星遥感监测、地理信息系统、全球定位系统等先进技术迅速准确地获得灾害信息,是每个国家都面临的重大课题。
同时,人类发展史也是一部人为灾害的发展历史。全球化经济的发展更加剧了经济发展的不平衡,而人类活动流动性大大增加,城市居住密度进一步提高,由此滋生了新型恐怖袭击活动。反人类的极端种族主义的发展,给人类的日常活动带来了前所未有的威胁,有人身威胁、经济威胁,甚至是生存威胁。前不久发生的德翼副驾驶员自杀坠机事件就应归于人为的灾害事件。
二、保险在灾害中所起的作用
诚然,面对数量众多且损失巨大的灾害,完全的灾害规避是不现实的。因此,保险作为一个有效的风险规避手段,既能帮助社会稳定,也能保证各类经济活动的持续进行。
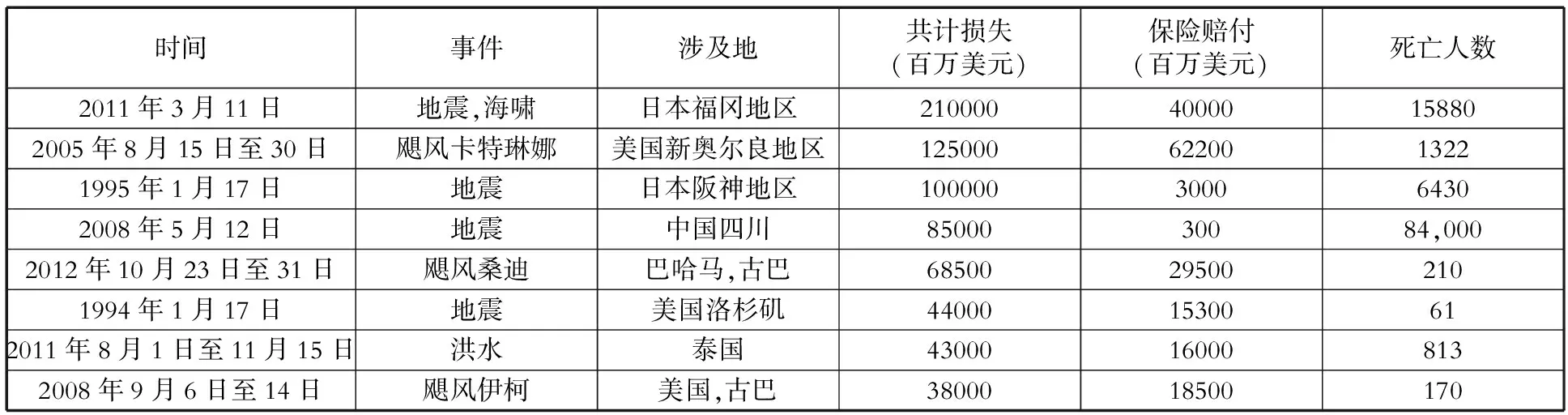
表1 1980年以来全球造成损失最严重的自然灾害
数据来源:Munich Re NatCatSERVICE灾害保险一览
在灾害面前,如果事先进行了保险投资,在灾害降临的时候,很大一部分的经济损失就可以被弥补。在美国,针对卡特琳娜飓风这类的灾害,商业保险公司一共赔付了将近一半的损失。
由于人为重大灾害在事故界定上还存在很多分歧,比如恐怖袭击(terror attack)或者数字风险(cyber risk),因此暂不纳入本文讨论重点。本文将重点讨论重大自然灾害给保险公司带来的挑战。
目前,市场上抗自然灾害风险的保险主要由直保公司和再保险公司共同承担。比如,安联保险(Allianz)的AGCS部门对于航空意外险一直承担主承保人的角色,承保后再分散其风险到各个参保公司;全世界最大的再保险公司慕尼黑再保险(Munich Re),还有第二大的瑞士再保险公司(Swiss Re),同时也是最大的发行自然灾害债券的券商,都为自然灾害风险提供再保险。而全球管理资产总额最大的法国安盛保险(AXA)则由其全球各地分公司共同建立自然灾害基金池来对抗不同地区、不同时间发生的自然灾害。
另外,也有一些公司专注于灾害的风险模型,力求在最大程度上能够掌控灾害所带来的损失。详见表2。

表2 全球领先的自然灾害模型软件公司
三、灾害模型介绍及其在直保公司内部模型中的运用
保险公司的核心业务在于风险管理,作为风险的承担者,如果不能对自己签下的风险项目有深刻的认识,这对保险公司的持续发展是极其危险的。同时,基于监管机构严苛的偿二代条款,无论在欧洲国家,还是在中国,保险企业都被要求对自身的保险业务有具体量化的风险资金要求。
而对于如何对极小概率事件的自然灾害构建内部模型,将是本文重点介绍的内容。通常来讲,建立灾害模型有三种类型,基于地理地质的模型,基于直保公司自身赔付数据的模型,以及基于不同方案的模型。
由于灾害的发生概率极小,通常直保公司没有足够的数据来提供模型的参数设定,而方案的选取也缺乏充分性,所以市场上较为广泛应用的是基于地质地理的模型。
地质地理模型一般由大型直保公司或者再保险公司联合软件开发商单独或者共同开发,比如慕尼黑再保险和RMS公司就建立了长期的战略合作伙伴关系,另外还有软件公司和政府职能研究部门合作,比如AIR的中国台风模型,就是上海台风研究中心联合软件公司开发的。
以下部分将提供一种模拟的方案,用以研究自然灾害风险是如何运用在内部模型上的。
直保公司可以通过把自己的保单组合代入模型,最终得到适合自己公司的风险预测结果。
(一)保单原始数据提供
目前,市场提供的模型都是基于独立的灾害,而直保公司需要准备的模型参数包括:地理位置信息,比如地址、邮政编码及其他的地理位置参数;保额,即被保对象的投保价值、责任险的最高投保额等;渠道,如个人、小型企业或大型企业;保险对象,如人身、财产,如果涉及房屋的话,还可以细分到房屋类型;保险范围,如房屋、室内外财产、企业运营中断损失赔付等;条款类别,包括自付部分、赔付上限等等。
(二)自然灾害模块 (Hazard Module)
自然灾害模块对于每一个灾害事件进行预估,并对其破坏程度进行评级。比如,地震模型会根据地震发生的地理位置来评估地壳运动的剧烈程度,并同时考虑地震波的传播范围,以此来给每一个地震确定震级。而飓风模型则会考虑每一次飓风的风力强度,并考虑其所经地方的地势、地貌及建筑环境。
(三)自损预估模块(Vulnerability Module)
该模块会根据保险公司提供的原始数据来套入模型,根据不同的决定项的参数决定拟合函数,最后进行回归处理得到初步模型结果(Ground Up Loss)。这个函数通常具有很强的区域性特点,并且根据不同的承保对象,所在地区的受灾程度与风险会存在极大的损失差异。如上所述,地理信息、房屋构建情况(年代、结构、承重等)等都会影响结果。模型不仅对物业财产的损坏,也会对灾害的时间持续性做出预测,对于企业营业中断损失赔付责任的承保项目来说,这将作为理赔款计算的依据,并预测某个时间段内的企业营业中断损失赔付。因此,能够提供的原始数据的详尽程度决定了模型的质量。
(四)财务模块(Financial Module)
如果保险公司能够提供再保险方案计划或者是联合保险的具体条款,比如免赔额(deductable)、赔付上限(limit)等,那么应用到初步结果上之后就能得出最终的自偿部分。
(五)模型结果(model result)
决定模型结果品质的关键因素为以下两方面:
第一是详细的数据。增加不同决定项的数据有助于提高模型的精度,对模型结果有着很大的影响,而最终又反过来影响公司的产品定价及制定再保险组合。所以原始数据的采集及数据库建设是其关键。
第二是时间性。保险公司能够提供的都是历史数据,而很多决定项数据都有时间性,比如房屋的折旧率,或者赔付人身伤害需要考虑到的通胀率。更重要的是对于新业务以及已有业务退保率的估算,如果投入模型的保险组合很大程度地区别于来年的实际组合,那模型结果的可用性就变得很低。
表3是由AMS公司提供的灾害损失情况。
1.基于ELT的模型构建
模型条件如下:
(1)每一个灾害事件(scenarioi),1≤i≤n都是独立不相关的。
(2)每一个独立事件都被看成是一个聚合风险模型:
A .每一次发生事件Xij的损失值都是独立不相关的,并且同分布;
B .每一个随机变量Xij及发生事件次数Ni都是独立不相关的。
(3) Ni是泊松分布,拥有泊松参数λi。
(4)对于每一个事件i,定义保额损失率zij∶=Xij/maxi,其中maxi是上述表格中的保险规模,即由于事件i所能产生的最大损失值。
由于保额损失率的取值区间为[0,1],符合Beta分布的概率函数的值域,所以可以用Beta分布的随机数来进行模拟。其需要的参数则为αi与βi。Beta概率的密度函数为:

表3 灾害损失表(Event Loss Table)
而根据聚合模型理论,综合泊松分布的和分布中,发生事件数的概率也是泊松分布,并且其泊松参数可以由上述表中的所有事件发生概率叠加而得到,也就是说:
其中λ是泊松分布的N的参数。
由此,我们已经有了建立模型所需要的全部参数,据此进行如下模拟步骤:
(1)在每一次运行中先产生一个由λ-泊松分布的随机非负整数。
(2)将每一个独立事件进行加权平均抽取,得到一组模拟的发生事件。
(3)根据ELT提供的相对应的数据可以通过以下运算,来得到模拟beta分布所需要的概率函数参数:
A.表3中提供的平均损失值mi除以保险规模maxi就是zij的期望E(zij),即E(zij) =mi/ maxi
B.zij的标准差σ(zij)=σi/ maxi
C.根据距估计方法(method of moment estimate),我们可以通过下列方程

反推得到正数参数αi与的βi估计值。而最后的随机概率数乘以保险规模,就是每次独立事件所产生的损失值。
(4)所有抽取的独立事件结果相加,得到一次模拟运行的总结果。
(5)按照不同置信区间要求及概率稳定性需求,可以进行几千到几百万次运行。
2.基于其他模型结果
有些时候,模型提供的是OEP或者AEP曲线。OEP的全称是Ocurrence Exceedance Probability,记录的是一年中达到某最大赔付额的最小概率。而AEP,即Aggregated Exceedance Probability,则是聚合一年中的所有赔付额。

表4 OEP曲线
表4的左列显示的是年数的间隔,右列是可能产生的赔付最小值。最简单的模拟方法是,我们假设一年发生的事件作为单位,那么表格中的灾害发生在概率函数中的体现就是:
那么表4就能直接转化成概率函数的分位点(Quantile)和其所对应的分位值(Quantile Value),以此作为模拟模型的经验分布。
四、灾害模型的局限性及前景展望
(一)第三方软件
以上介绍的是一些行业内所常用的模型。所有的模型只能给保险公司提供一个行业内的尺度比较。对应公司的保险业务,事实上,在决定模型构建之前,建模者更应该先解决以下问题:该模型的内在运作方式,即模型建立及面向的对象;该模型的地理视野和涵盖是否充足;是否考虑到重要的二级风险(secondary uncertainty);模型建立所用的数据来自的业务范围与所需要的业务范围是否吻合;对于目前模型所得出的结论和我们的经验数据是否有相关性和运用价值。
(二)不同灾害类型的模型整合
对于大型的保险公司或保险集团来说,它们的保险业务分布范围是极其广泛的,有时候甚至跨越了大洲。
一方面,灾害跨越了国界,影响相邻的国家,同时由于业务本身的特点及公司内部组织结构的不同,不同国家的业务可能有不同的再保险需求,这就对内部模型的建立和整合过程提出了挑战。要么统一安排再保险来提高单一灾害的风险管理精确性(Top-Down),以符合集团要求,要么各自为营,从分公司自身业务绩效的角度出发,结合其间的业务相关性(calibration of correlation), 作何选择是亟需解决的问题。另一方面,从模型参数来讲,如果是选择montecarlo模拟模型,则需要关注:如何选择关联结构(Gauβ-Copula, T-Copula, Gumble-Copula);如何定义相关性系数(correlation coefficient);研究各个灾害的尾部相关性(tail dependency);在缺少数据的事实面前,是否可以通过引入确定性理论(Credibility Theory)来慢慢聚积数据,并逐步调整模型结果。
(三)人为灾害的模型模拟
至此,讨论的范围一直局限于自然灾害,而新型的人为灾害更是保险领域的难点。通常来讲,在9·11事件之前,人们倾向于将人为灾害归于责任险的大额理赔,比如德国2008年伊斯堡的踩踏事件,以及各类空难。而当恐怖袭击降临的时候,对于这一新型的重大人为灾害,如何界定其风险,保险公司各有各的想法。有的将其称为man-made disaster,通过对承保范围的不动产或人口密度来估算经济规模,作不同的压力测试(stress case scenario及worst case scenario);有的将其称为operational risk,模拟的方法也各有不同,比如可以建立在专家建议(expert judgment)的分位点估算来得出概率分布所需的参数。
由于偿二代的风险资金要求,重大灾害会一直作为产险公司的很重要的风险驱动,在目前无法获取大量有效数据的情况下,各类模型都应该尝试,再不断对比历史数据(back testing),对比行业数据(benchmark),反推压力测试(reverse stress test),资源校正参数(calibration),调整验证(Validation)模型,最终形成比较可行的方案。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
工程数学学报(2022年1期)2022-05-30
江苏安全生产(2021年6期)2021-08-05
数学小灵通·3-4年级(2021年5期)2021-07-16
江苏安全生产(2020年5期)2020-06-15
公民与法治(2020年5期)2020-05-30
证券市场红周刊(2019年37期)2019-10-09
今日农业(2019年15期)2019-01-03
消费导刊(2018年8期)2018-05-25
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
