
开放式图书馆数字资源检索系统研究
2015-05-29 11:49曹异卿唐俊
电脑知识与技术 2015年10期
曹异卿+唐俊

摘要:该文设计了一个基于互联网技术的开放式图书馆数字资源检索系统,系统采用多粒度索引技术建立数字资源的索引数据库,使用逆向最大匹配算法实现分词,提升了系统的检索能力。测试结果表明系统在准确率、召回率和F-measure上取得较好的效果。
关键词:数字资源;检索系统;多粒度索引;逆向最大匹配
中图分类号:TP315 文献标识码:A 文章编号:1009-3044(2015)10-0012-03
1 概述
现代图书馆的发展越来越趋向于数字化、移动化,因此图书馆的建设也与传统的纸质图书馆模式产生了很大的不同。国内主要公共图书馆和高校图书馆都将图书采购的主要来源定位于数字资源。[1-2]图书馆数字资源的不断增加给图书馆对数字资源的加工、处理、存储、检索和使用带来了考验与挑战。目前国内图书馆数字资源的建设主要包括购买国内外著名的数据库和图书馆的特色馆藏。[3-4]
购买的数据库都提供了数字资源的检索系统,而图书馆的特色馆藏资源的形式多样。[5]特色馆藏资源一般包括图像、文本、声音、视频等方方面面,这类数字资源的查询条件有时候难以准确描述,所以查询条件的描述本身就是难点,而且检索的对象或者集合也可能是模糊的。其中的原因可能是因为信息检索的处理对象通常是自然语言,自然语言本身就变化无常,而且自然语言没有固定的结构,它们的语义经常具有模糊性,导致经常检索不到所需要的资源。[6]
本文第二节提出了一种图书馆数字资源的多粒度混合索引技术,第三节基于混合索引技术进行了基于互联网的开放式数字图书馆检索系统,第四节对系统进行了测试,测试结果表明系统在准确率、召回率和F-measure上取得较好的效果。
2 多粒度混合索引技术
多粒度索引技术是构建倒排索引数据文件的一种方法和技术。多粒度索引技术采用了统计学方法,该方法先识别文档中包含的未登录词语,然后把识别出来的未登录词语依次放在一个扩展的词典里面,采用统计学方法识别未登录词语会有错误的情况发生,使得扩展的分词词典里面含有错误的词语。在保存扩展的分词词典时,把识别出来的新词语再用基本分词词典进行二次切分,并保存好切分开的词语序列。
多粒度索引技术采用统一倒排文件索引词典,没有二级索引词典,不会产生额外的访问开销。多粒度索引技术不限制扩展词语的长度,可以把更长的短语建成索引,这样使得信息检索时更加灵活。与词语索引结合Bigram索引的技术相比,多粒度索引技术采用了未登录词语识别技术,能够避免Bigram索引带来的倒排索引数据词典膨胀的问题。
多粒度索引技术中增加的扩展词语索引,可以使得更多词语或短语被索引,从而提高信息检索系统的检索效率,所以多粒度索引技术是可行的。
多粒度索引技术的实现包括未登录词语识别和扩展词典构建两个部分。
第一部分 未登录词语识别算法
1) 提取m元组:采用基本词语词典,对文本进行词语切分,从得到的分词结果中提取出包含m个相邻基本词语的字符串,称为 m元组。
2) 噪声处理:把停用词搜集起来构成停用词表,在m元组中进行删除。
3) 删除重复的m元组:把那些重复出现的多余m元组进行删除。
4) 把最后剩下的m元组按照它们出现的频次从高到低排列,超过一定阈值就作为未登录词语加入扩展词语表。
未登录词语可以从网页文档语料数据中提取得到。在提取m元组时,网页文本中的用户经常查询的词语优先被考虑。也可以从网页文本文摘文字中选择m元组。这样可以提高未登录词语的识别效果。
第二部分 扩展词典构建
把识别出来的新词语保存在扩展的词典中。可以先进行基本分词词典分词,并将结果转换成基本词语的序列。然后使用散列查找表把基本词语的序列转换成连续整数编码。那么扩展分词词典里面就保存新词语中基本词语的整数编码,相当于由整数编码构成的m元组集合。
3 开放式图书馆数字资源检索系统设计
3.1 逆向最大匹配算法设计
逆向最大匹配法通常简称为RMM法。RMM法的基本原理与MM法相同 ,不同的是分词切分的方向与MM法相反,而且使用的分词辞典也不同。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的2i个字符(i字字串)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。逆向最大匹配算法如图1所示。
3.2 创建索引
在索引创建的算法方面,采用两趟的内存倒排索引创建算法,首先是依次对每个规模小的文档集合创建倒排索引,然后执行多路归并算法,最后得到总的倒排索引文件。主要的创建步骤如下:
1) 页面分析。按照HTML标签语法规则分析源文件的标签结构。在分析的过程中记下每个索引词的词频和文档频率,然后利用散列表把它们转换成索引词语编码,并把这些结果保存到词典文件中,同时把页面分析的结果保存到临时文件里面,留给后面的步骤使用。
2) 按照统计方法得到索引词语的词频和文档频率属性,能够估计出索引词语对应得倒排文件数据可能的长度,并预先申请文档集合需要的倒排索引内存空间。读取页面分析得到的临时文件,并在内存里面按照临时文件的内容创建倒排索引,并把得到的结果保存在临时的倒排文件里面。
3) 读取上面得到的多个临时的倒排文件的内容,然后执行多路归并算法,并进行编码压缩,最后输出到最终的倒排文件里面保存。
在索引创建模块中,页面分析过程,尤其是中文分词过程是主要的时间开销。算法的后面步骤相对来说速度很快。
3.3 内容检索
检索模块同建立索引模块一样,都是异构数字资源检索系统的核心模块,检索模块的功能是首先获取用户输入的关键词,然后对其进行预处理,继而对处理后的关键词进行中文分词,最后从索引库中将用户需求的数字资源检索出来。检索模块中,用户可根据不同的检索需求(比如资源题目、资源作者、资源简介等等),选取不同的检索条件,获取不同的检索结果。
3.4 结果排序
排序模块的功能主要是对检索模块检索出来的结果进行排序,从而给用户呈现出相应的资源列表。首先获取用户输入的检索词进行分词之后获得的关键词,然后计算关键词与检索结果中文档的相关度,最后根据相关度大小进行排序。排序模块的流程图如图2所示。
4 测试与验证
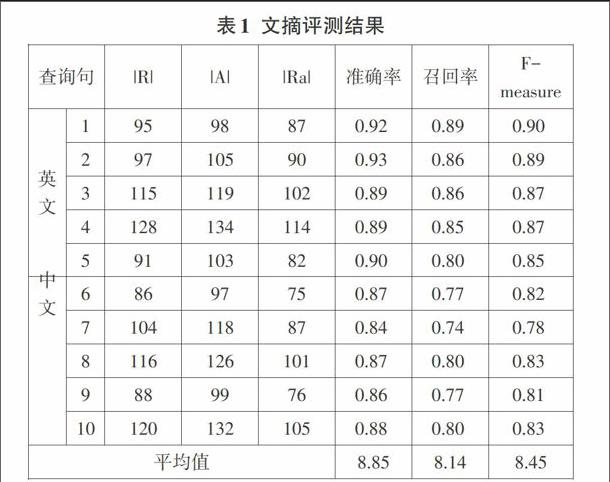
根据美国情报学家Lancaster基于传统的信息检索系统提出的信息检索的性能指标,取480个数字资源作为测试数据,测试数据包含等量的四种类型的数字资源,即120个epub格式的文本资源、120个epub格式的音频资源、120个epub格式的视频资源以及120个epub格式的图像资源,每一种类型的数字资源包含全英文的以及全中文的,所有的中文资源不仅仅只关注同一个关注点。本文从十个不同的方面精心选择了十个查询句,其中包括5个中文查询句和5个英文查询句,其中军事、医药、体育、经济、环境、 健康、艺术、教育、 政治、交通方面分别有一个查询句。
表1中,R 代表相关文档集合,变量A 代表检索结果构成的文档集合,变量Ra 代表相关文档集合R 和检索结果构成的文档集合 A 的交集。
本系统的平均查准率为88.5%,平均査全率为81.4%。在查准率和查全率上与传统搜索引擎有较大提升。英文资源的查全率和查准率都高于中文资源的查全率和查准率,这是因为英文和中文本身的差异引起的,英文的分界符非常明显,而对中文进行切分需要各种分词算法,准确度自然没有英文高。
5 总结
开放式数字图书馆需要一个能检索各种类型资源的检索系统,本文提出的开放式图书馆数字资源检索系统采用了多粒度索引、逆向最大匹配算法等技术来提高搜索的精度。对检索系统的分词、索引、搜索和结果展现等模块进行了设计,并基于Java平台进行系统的原型创建。测试结果表明系统在准确率、召回率和F-measure上取得较好的效果。
参考文献:
[1]马文峰. 数字资源整合研究[J]. 中国图书馆学报,2002(4):63-66.
[2]刘阳. 基于开放获取的高校图书馆科学数据信息资源管理与服务[J]. 科技情报开发与经济,2015,05:29-31.
[3]毕强,王传清,李洁. 基于语义的数字资源超网络聚合研究[J]. 情报科学,2015(3):8-12.
[4]王小君,何庆. 资源网格中的一种资源检索机制[J]. 计算机技术与发展,2010(3):63-66.
[5]郑伟青. 云计算在图书馆群资源检索中的研究与应用[J]. 图书馆建设,2010(4):85-87.
[6]陈旭,陈德华,乐嘉锦. 基于语义相关度排序的政务信息资源检索算法[J]. 计算机工程与应用,2011(25):121-125.
猜你喜欢
自然资源信息化(2019年3期)2019-03-29
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
电脑与电信(2018年12期)2018-03-23
教学月刊·小学综合(2016年11期)2016-12-05
中国集体经济(2016年26期)2016-11-19
知音励志·社科版(2016年9期)2016-11-09
