
一种改进的邻接关系可查询压缩算法
2015-06-27 08:26高圣巍
计算机工程 2015年1期
高圣巍,彭 超
(华东师范大学软件学院,上海200062)
一种改进的邻接关系可查询压缩算法
高圣巍,彭 超
(华东师范大学软件学院,上海200062)
目前多数数据压缩算法不能直接在压缩结果上进行数据查询,大数据的线性化压缩算法虽然可直接在压缩后的数据上进行邻接关系查询,但压缩率较低。针对该问题,对线性化压缩的实现原理进行研究,分析MPk线性化算法在不同社会网络样本下的压缩效率,发现线性化压缩结果中存在冗余信息,并针对该情况设计改进算法,删去原有数据结构中的冗余部分,进一步提高压缩率。实验结果证明,改进算法的时间复杂度与原算法相同,压缩率平均提升23%。
线性化压缩算法;大数据;社会网络;启发式算法;Eulerian数据结构
1 概述
近些年来,由于在生物、天文、经济和社会网络等诸多领域的应用,超大规模复杂图的相关研究受到广泛重视。这当中社会网络尤为突出,其能帮助人们发现潜在问题,做出决策,管理人际关系、组织机构乃至国家社会。社会网络通常被建模为超大图,成员对应图的节点,而成员间的关系则为图的边。这些关系可以是友谊、血缘、贸易或冲突等,是研究的重点对象。因此,在分析社会网络时,查询邻居节点是最频繁也最重要的工作之一[1]。
社会网络一般都由上百万的节点和边组成,存储社会网络需要很大的空间。问题也随之而来:如何压缩网络数据以节省空间?好的算法会利用社会网络的一些特性来获得高压缩率,比如节点通常会以簇的形式出现在社会网络中。在以往,人们在查询社会网络时,都会将其图数据解压缩。如果查询操作能直接在压缩数据上进行,将可以大量节省解压缩的时间。本文利用线性化压缩的特性,提出一种改进的线性化压缩算法。该算法不需要解压即可查询,通过计算节点间的关联度,调整节点在压缩结果中的排放位置,从而提高线性化压缩的压缩率。
2 相关研究
在大规模复杂网络数据的压缩方面,国内外已经有一些相关研究工作。例如:文献[2]将压缩问题转化为在有向图中寻找最小生成树的过程;文献[3]通过广度优先遍历的方法压缩图,并优化了压缩图的编码方式;文献[4]介绍了几种常用无损数据压缩算法。
针对海量社会网络数据,要获得高压缩率,首先,图中顶点出现的顺序十分重要,文献[5]说明了节点的排列对压缩实际带来的影响。其次,设计良好的数据结构来存储数据十分重要。文献[6-7]中总结了一些压缩社会图的方法,主要有记录邻接表、记录间距、引用压缩和差量压缩,并且设计了通用的图压缩框架。在后续的工作中,Paolo Boldi采用Task Decomposition技术[8],将压缩框架扩展为在多核架构上运行,提高压缩速度。文献[9]分析了社会网络不同于普通图的特性,提出通过找出具有相似邻居的节点进行压缩的方法。这些压缩方法都有着较好的压缩率,但在社会网络上做查询操作前,都要先将压缩的图解压。
文献[10]提出了一种“线性化”技术,这种技术将社会网络中的节点表示成一个序列,序列中的每个节点仅存储序列中相邻节点的邻居关系,虽然这样压缩率与其他压缩算法稍有降低,但这种技术使得查询可以直接在压缩后的结果上进行。寻找这样一种序列基本上被认为是NP完全的问题,因此一般来说不存在有效的多项式时间算法,文献[11]对此作了阐述。
本文对线性化压缩的实现原理进行研究,分析线性化方法在不同社会网络样本下的压缩效率,发现线性化压缩结果中存在的冗余信息,并针对该情况提出一种改进算法。
3 MPK线性化算法
一个社会网络可以用一个有向图G(V,E)表示,其中,V表示图中点的集合;E表示图中边的集合,即E∈V×V,本文假定网络是简单的(即没有自环),源节点到目的节点最多只有一条边。有向图的边用e=(u,v)表示,其中,u为源节点;v为目的节点,且(u,v)≠(v,u)。图1是一个有向图示例。

图1 有向图G
定义有向图对应的无向图,无向图存在边,当且仅当(u,v)∈E(G)或(v,u)∈E(G)。图2是图1中有向图G对应的无向图。
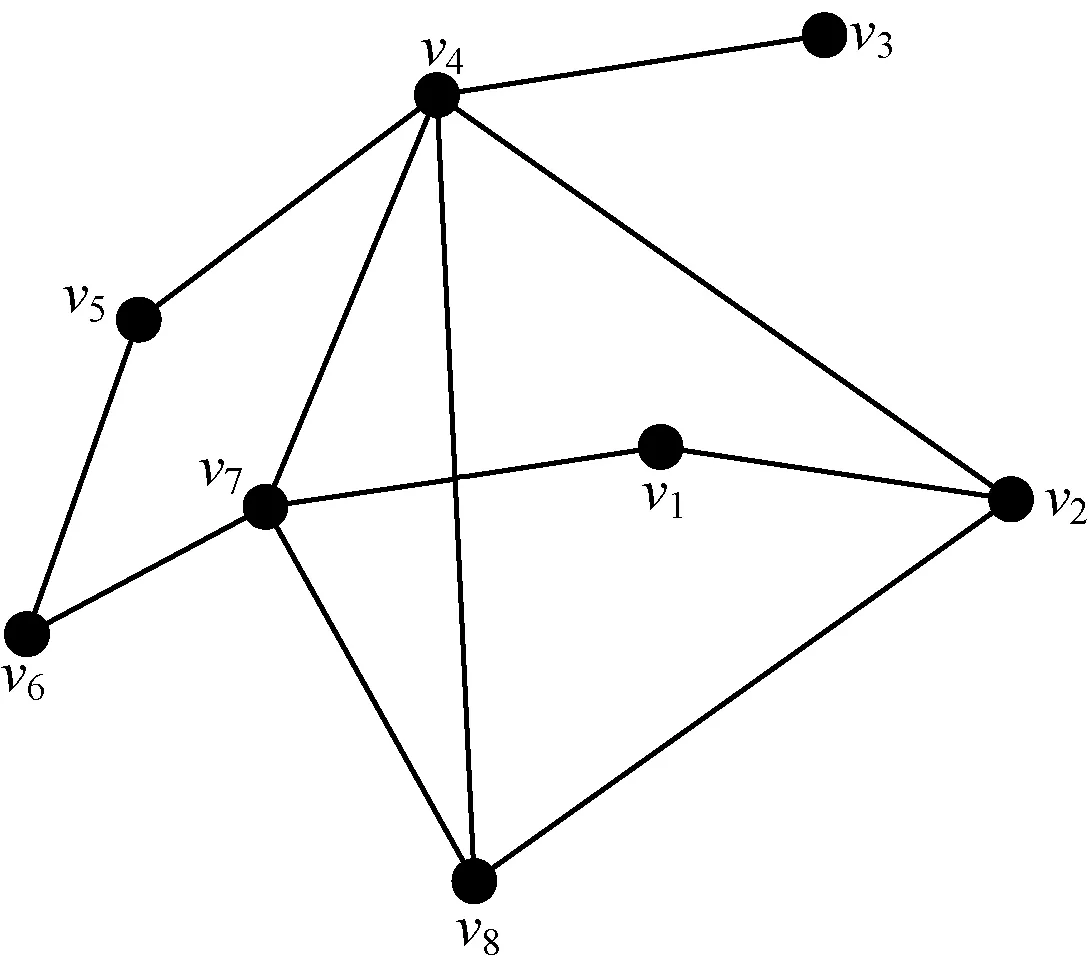
图2 G对应的无向图
定义有向图对应的转置图GT,转置图存在边(u,v)∈E(GT),当且仅当(v,u)∈E(G)。
对有向图G的查询分为2种:查询节点u指向的所有邻点{v|(u,v)∈G};查询所有指向节点u的邻点{v|(v,u)∈G}。为有效支持这2种查询,多数压缩算法需要存储图G和转置图GT。而线性化算法将图G进行编码,节省了大量的空间,同时支持在已编码的结果上直接作查询。下文将给出MPk的定义和用 MPk于存储图G的编码的数据结构——Eulerian结构。
3.1 MPk线性化定义
定义1设S=(vi1,vi2,…,vim)是由图G的节点组成的序列,如果G中所有的节点在S中至少出现一次,则称S覆盖了图G,这里请注意S中前后相邻出现的点不一定在G中存在邻接边。
定义2给定一个覆盖图G的序列S,dist(u,v)表示序列S中节点u和节点v最相近的距离。
定义3给定一个覆盖图G的序列S,如果对于图G中所有的边(u,v)∈E(G),在S中都有dist(u,v)≤k,则称S是图G的MPk阶线性化序列。图G中的节点允许在S中重复出现。
3.2 Eulerian数据结构
Eulerian数据结构用来保存对图G的MP线性化序列L,它是一个数组,L的长度用|L|表示,设v(i)是出现在数组第i个位置的节点,v(i)保存2个信息:
(1)邻居信息:对于MP1线性化序列,邻居信息占2 bit,分别记录有向边(v(i),v(i+1))和(v(i+1),v(i))是否属于E(G)。对于MPk线性化,每个元素需要一个2kbit的比特串保存邻居信息,其中,第2j-1个和第2j个比特分别记录有向边(v(i),v(i+j))和(v(i+j),v(i))是否属于E(G)。
(2)节点指针:同一节点在序列中允许重复出现。节点指针指向节点下一次出现的位置。节点最后一次出现时,节点指针指向它首次出现的位置。
图G的MP1和MP1线性化序列的Eulerian表示如图3和图4所示。

图3 图G的MP1线性化序列的Eulerian表示
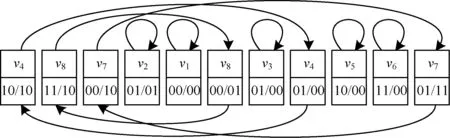
图4 图G的MP2线性化序列的Eulerian表示
4 MPk线性化的改进
4.1 Eulerian数据结构的存储冗余
在稀疏图中,节点的出入度都较小,在k比较大的情况下进行MPk压缩,会导致Eulerian数据结构中的邻居信息存储着大量的不连续的0 bit(表示节点之间没有边相连)。假设图G的MPk序列的某一段如下排列:a,u1,v1,u2,v2,…,uk/2,vk/2,其中,,则节点a的邻居信息表示为:001100110011…(共2kbit)。如果变换节点出现的顺序为a,u1,u2,…,uk/2,v1,v2,vk/2,同时保证序列仍然符合MPk的定义,则节点a的邻居信息变为:0000…01111…1(0 bit与1 bit各k个),可以省去开始的k个0 bit,从第1个1 bit开始记录邻居信息。由于邻居信息的长度不再固定为2k,因此需要增加lbk个比特记录邻居信息的比特串长度。通常lbk远小于k,所以,整体压缩率仍然是提高的。
改进的Eulerian数据结构除了保存图G的节点外,还保存着一个二元组(NI,δN),其中,δN表示邻居信息比特串的长度;NI表示邻居信息。
4.2 改进的MPk线性化算法
本文通过算法调整序列中节点出现的顺序。用数组L来记录线性化序列中的节点,初始时L长度为0,此时随机选择一个节点加入到L。当向L加入新节点时,计算每个候选节点u与L中最后k个节点的关联度,称之为权值。设当前L的长度为|L|,权值C的计算方法如下:

最终,权值最大的节点优先加入数组L中。
结合上述的分析,本文对MPk算法进行了重新设计,并使用改进的Eulerian数据结构,称为IMPk算法。算法描述如下:
输入图G,k
输出G的线性化序列

4.3 MPk与IMPk的计算复杂度对比
在构造线性化序列时,IMPk算法与MPk算法的主要区别在于选择新加入节点时的策略不同,MPk算法选择与X集合有最多相连边的节点优先加入序列,完成这个过程的步骤如下:
(1)找出X集合中节点的所有邻居,最多有个邻居;
(2)对于X集合的每个邻居v,判断v与X集合共有多少边相连,复杂度为c1×K,其中,c1为判断两节点之间是否有边的开销。因此,MPk算法完成整个选择的复杂度为:
而IMPk算法在上述第(2)步加入了权值计算,对于X集合的每个邻居v,判断其权值的复杂度为(c1+c2)×K,其中,c2表示计算v与X中节点的距离所花费的开销,完成整个选择的复杂度为:(c1+c2)×K×
由于X集合每次更新一个节点,根据其中节点顺序可以快速计算到v的距离,c2的值比c1小很多。因此,IMPk算法计算复杂度与MPk算法复杂度基本相当。
4.4 MPk线性化的长度下界
设MPk线性化序列L的长度为|L|,L中的每个节点需要lb|L|个比特保存节点指针,2k个比特保存邻居信息,整个序列需要保存。本文用图G中每条有向边,在压缩结果中占用的bit数来衡量压缩率,称为BPE(Bits Per Edge),其值为:
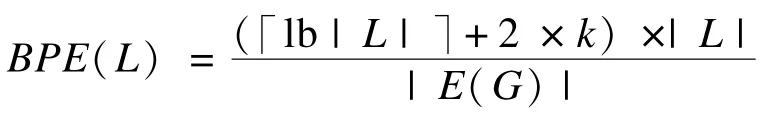
本文给出改进MPk线性化序列长度的下界,设v∈V(G),L中每个节点邻居信息占用2kbit,在最好情况下,只能记录它的k个邻居,所以,v在最终序列L中至少出现「deg(v)/k⌉次,deg(v)为节点v的度数。则L的长度至少为:

5 实验与结果分析
本文使用C++实现了改进的算法,并用网站http://snap.stanford.edu/data中提供的社会网络图数据作为输入,分别取k=10,k=15,k=20,k=30为参数进行实验。实验结果如表1和表2所示,表中数据为原 MPk算法与 IMPk算法运行结果的BPE值。
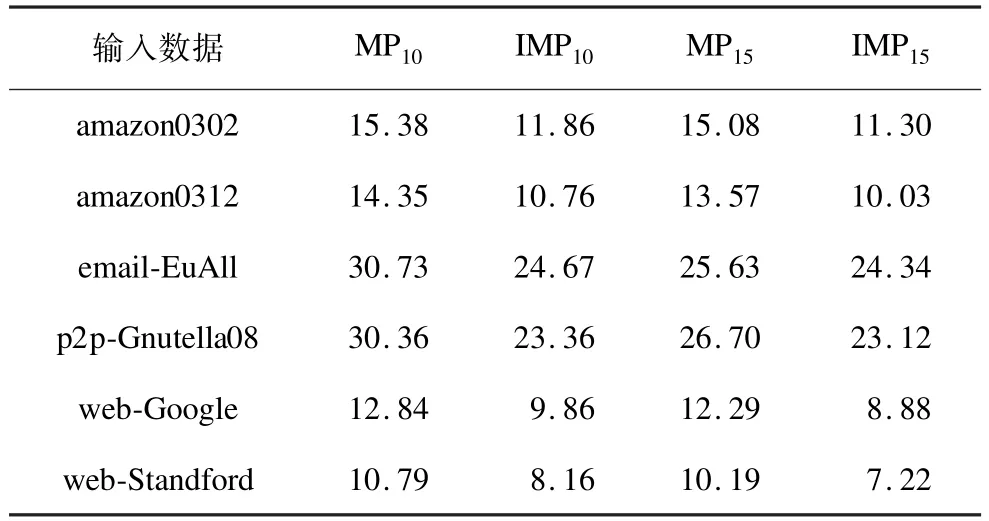
表1 MP10,MP15与IMP10,IMP15序列压缩结果比较

表2 MP20,MP30与IMP20,IMP30序列压缩结果比较
可以看出,改进后的IMPk算法之平均压缩效率比原MPk算法平均高出大约23%。本文对实验结果作进一步分析后发现,社会网络的聚合度对压缩效率有很大的影响。在这些社会网络中,web-Standford图中的节点都以簇的形式分布[12],簇内的节点连接紧密,而与其他簇连接较少,因此该网络的压缩效率最好,达到6.37 bits/edge,比原MPk算法效果提升38%。在email-EuAll图中,各节点的邻居分布比较随机,使得算法在执行时,加入了许多随机节点(即跳至外层while循环,选择随机节点)来保证序列符合MPk定义。最终,改进算法仍比原算法有2%的效率提升。
6 结束语
本文改进社会网络的线性化压缩算法,通过计算权值,优化最终序列中的节点顺序和Eulerian数据结构。实验结果证明,改进后的压缩算法的压缩率相比原算法平均提高了23%。下一步工作是深入分析社会网络的聚合程度对算法的影响,改进算法以适应社会网络的不同特征。
[1] 马 帅,李 佳,刘旭东,等.大数据时代的图搜索技术[J].信息通信技术,2013,(6):44-51.
[2] Adler M,Mitzenmacher M.Towards Compressing Web Graphs[C]//Proceedings of 2001 Data Compression Conference.Snowbird,USA:IEEE Press,2001:202-213.
[3] Apostolico A,DrovandiG.Graph Compression by BFS[J].Algorithms,2009,2(3):1031-1044.
[4] 郑翠芳.几种常用无损数据压缩算法研究[J].计算机技术与发展,2011,21(9):73-76.
[5] Boldi P,Santini M,Vigna S.Permuting Web Graphs, Algorithms and Models for the Web-Graph[M].Berlin, Germany:Springer,2009:116-126.
[6] Boldi P,Vigna S.The WebGraph Framework I: Compression Techniques[C]//Proceedings of the 13th International Conference on World Wide Web.New York, USA:ACM Press,2004:595-602.
[7] Boldi P,Vigna S.The WebGraph Framework II:Codes for the World-wide Web[C]//Proceedings of 2004 Data Compression Conference.Snowbird,USA:IEEE Press, 2004:528.
[8] Boldi P,Rosa M,Santini M,et al.Layered Label Propagation:A Multiresolution Coordinate-free Ordering for Compressing Social Networks[C]//Proceedings of the 20th International Conference on World Wide Web. Hyderabad,India[s.n.],2011:587-596.
[9] Chierichetti F,Kumar R,Lattanzi S,et al.On Compressing Social Networks[C]//Proceedings of the 15th ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining.Paris,France: ACM Press,2009:219-228.
[10] Maserrat H,Pei J.Neighbor Query Friendly Compression of Social Networks[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Washington D.C.,USA: [s.n.]:2010:533-542.
[11] Papadimitriou C H.The NP-completeness of the Bandwidth Minimization Problem[J].Computing,1976,16(3): 263-270.
[12] Easley D,Kleinberg J.Networks,Crowds,and Markets[M]. Cambridge,UK:Cambridge University Press,2010.
编辑 金胡考
An Improved Compression Algorithm Supporting Neighbor Query
GAO Shengwei,PENG Chao
(Software Engineering Institute,East China Normal University,Shanghai 200062,China)
Nowadays,most data compression algorithms do not support performing query directly on compressed data. Though the compression algorithm can perform query neighbor relations on compressed result,the compression ratio is relatively low.To solve the problem,this paper does some research on the principle of linearization compression algorithm.It analyzes the compression ratio of MPkalgorithm in different sample social network and finds the redundant information in compressed result.To eliminate these redundant information,it improves the original data structure, removes the unnecessary bits and improves the compression ratio.Experiments show that the proposed algorithm has same time complexity compared with primal algorithm,but the compression ratio can be increased by 23%in average.
linearization compression algorithm;big data;social network;heuristic algorithm;Eulerian data structure
1000-3428(2015)01-0061-04
A
TP312
10.3969/j.issn.1000-3428.2015.01.011
国家自然科学基金资助项目(91118008,61232006);国家“863”计划基金资助重点项目(SQ2010AA0101016001);上海市教育委员会科研创新基金资助项目(44440590)。
高圣巍(1989-),男,硕士研究生,主研方向:移动路由算法;彭 超,副教授。
2014-01-20
2014-03-15 E-mail:51111500026@ecnu.cn
中文引用格式:高圣巍,彭 超.一种改进的邻接关系可查询压缩算法[J].计算机工程,2015,41(1):61-64.
英文引用格式:Gao Shengwei,Peng Chao.An Improved Compression Algorithm Supporting Neighbor Query[J]. Computer Engineering,2015,41(1):61-64.
猜你喜欢
云南民族大学学报(自然科学版)(2021年3期)2021-06-24
铁道通信信号(2019年9期)2019-11-25
科学与财富(2018年26期)2018-10-24
科技信息·中旬刊(2018年4期)2018-10-21
四川师范大学学报(自然科学版)(2018年4期)2018-07-04
廊坊师范学院学报(自然科学版)(2017年3期)2017-10-11
电讯技术(2017年4期)2017-04-16
滁州学院学报(2016年5期)2016-12-16
科教导刊·电子版(2016年23期)2016-10-31
电测与仪表(2015年14期)2015-04-09
