
改进的给水管网节点K 均值空间聚类
2015-07-11 10:10柳景青郭东进
浙江大学学报(工学版) 2015年11期
柳景青,郭东进,叶 萍
(1.浙江大学 建筑工程学院市政工程研究所 浙江 杭州310058;2.嘉源给排水有限公司 浙江 嘉兴314000)
城市给水管网由水厂、泵站、节点、闸阀、监测设备等组成,是一个十分复杂的系统.给水管网节点指的是给水管网中,主干管、干管、支管之间,相互交叉连接的节点,目前给水管网模型一般考虑管径200 mm 以上的管道,管径200 mm 以下管道由于流量较小,一般不考虑.一个中等城市,管径在200 mm以上的管网系统可能有上千个节点,因此,从计算分析的角度,需要以聚类为基础的简化.数量之外,城市给水管网节点系统同时又是一个复杂的关联体系,节点与节点之间既相对独立又相互影响.因此,它们不是简单空间位置、空间距离划分的聚类,需要综合考虑节点属性功能的响应及重要性,问题复杂.
在K 均值聚类法之前,处理类似的给水管网节点空间聚类问题,常用系统聚类法.王旭冕等[1]利用三步分析法筛选水质指标,利用系统聚类方法,对管网节点进行聚类,实现水质分区.李雅洁等[2]采用系统聚类中的类平均法对给水管网节点聚类,并利用离均差从各类中筛选出代表点.程广河等[3]计算了管网压力敏感矩阵,利用系统聚类的方法,建立城市给水管网水量漏失点定位模型.Lina 等[4]利用深度优先搜索算法(DFS)和宽度优先搜索算法(BFS)搜索的方法进行给水管网聚类,实现给水管网简化.上述给水管网节点聚类的研究是基于简单的管网中试模型,以管网模型的节点压力敏感矩阵作为聚类的指标.在实际给水管网中,由于管网结构复杂,压力受到多种原因影响,无法得到可靠的节点压力敏感矩阵[5].贾新强等[6-7]的研究证明,给水管网节点相似性除受到压力变化规律影响外,还受到地理位置的影响.因此,在选择节点聚类方法时,应能同时考虑空间的相近性和非空间属性的相似性.
相比于系统聚类,K 均值空间聚类因为能够同时反映地理位置与压力的相似性,更适合用于实际给水管网节点的聚类分析.戴一明等[8]在管网水压监测点优化布置研究中对监测点进行了K 均值空间聚类尝试,选取离聚类中心最近的点作为水压监测点.在实际应用研究过程中,研究者发现普通K均值空间聚类方法结果往往很大程度上依赖于初始聚类中心的选取和属性权重的选取,存在类内误差过大和聚类结果不稳定等诸多问题[9],本文引入信息熵和改进遗传算法,试图克服以上K 均值空间聚类方法的不足.
1 改进的K 均值空间聚类算法
1.1 管网节点K 均值空间聚类算法
在K 均值聚类分析中,表示两点之间的差距一般采用欧氏距离,距离越近,相似度越大.普通K 均值聚类分析一般有一个属性,或者有几个属性但类型、量纲相同,因此在计算聚类簇内距离的时候无需设置权重,简单叠加即可.
对于同时包含空间属性和非空间属性的给水管网节点的类问题,2个节点之间的“距离”需要能够同时反映出空间距离和压力变化规律的相似性,因此需要设置属性权重,建立新的节点距离计算公式.本文在李新运等[10]提出的坐标与属性一体化的空间聚类方法的基础上,考虑非空间属性中实际节点压力与模拟节点压力在误差精度上的差异(一般相差5倍以上),引入节点置信系数,定义了给水管网节点距离.
假设给水管网中存在i,j2个节点:

式中:Dij为两节点之间的距离;x、y 为节点平面坐标,坐标值由自来水公司提供;wx、wy为平面坐标权重,权重值由信息熵方法计算求得;a 为非空间属性值,本文选择压力均值和峰度系数表示非空间属性;wk为第k 个非空间属性权重,权重值由信息熵方法计算求得;∂为节点的置信系数,置信系数根据经验取值.实际监测节点压力值误差在2%以内,而水力模拟节点的压力值误差在10%以内.因此,本文设置当节点为实际监测节点时,∂=1当节点为水力模拟节点时∂=0.5.
K 均值空间聚类过程为:首先随机选择聚类中心,计算得到点与聚类中心的之间的聚类距离后,逐个将需分类的样本按最近距离分配给某一个聚类中心Ci,所有样本分成k 个聚类簇,每一个聚类簇中至少有一个以上的样本.重新计算各个聚类簇的聚类中心,以各聚类域中所包含样本的均值向量作为新的聚类中心.直到每个聚类簇不再发生变化.
1.2 基于自适应遗传算法的初始聚类中心寻优模型
K 均值聚类方法的初始聚类中心对于聚类结果有很大影响,普通K 均值聚类的初始聚类中心是随机生成的,因此聚类结果随机性很强.对于给水管网而言,节点数量众多,因此需要选择合适的优化方法来确定最优的初始聚类中心.
遗传算法的优点是全局搜索能力强,计算时间少,鲁棒性高.武兆慧等[11]将遗传算法引入K 均值聚类,寻找最优初始聚类中心,证明遗传算法能够较好的实现寻优功能.本文利用自适应遗传算子和精英保留策略的遗传算法优化一体化K 均值聚类,同时将其与采用经典遗传算法、模拟退火遗传算法优化的K 均值空间聚类结果进行对比.
将遗传算法应用于K 均值空间聚类优化,需要根据聚类结果评价指标,构造合适的目标函数.本文选择聚类簇类内距离之和作为目标函数值.

式中:k为聚类簇个数,n为类内节点个数,Dij为第i类第j 个个体与聚类中心的距离.
为了保证每个聚类簇中节点个数处于相同水平,需要在目标函数中增加惩罚项.新构造的目标函数为
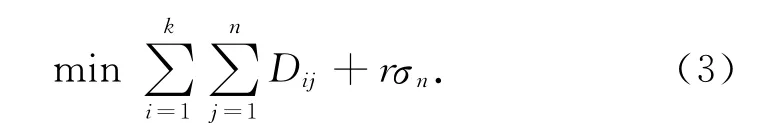
式中:r为惩罚因子;σn为聚类簇个数均方差.
K 均值聚类需要设置聚类簇个数,至少为1;同时,任一聚类簇中至少有1个个体,所以,目标函数约束条件为

为了区分每个初始聚类中心的优劣程度,需要在目标函数的基础上构造适应度函数,计算得到每一个聚类中心的适应度函数值,以此作为评价标准.本文采用目标函数值的倒数构造适应度函数:

式中:F 为构造适应度函数常数,本文根据经验,取100;Dis为目标函数值,即所有聚类簇内距离之和.
1.3 权重确定的信息熵算法
K 均值空间聚类属于加权聚类.加权聚类的关键是权重的确定.目前常用的权重确定方法是经验法或专家评分法[12].2种方法的主观性很强,不能准确反应属性之间的真实权重.并且给水管网节点数量多,采用经验法或专家评分法操作复杂,在实际管网分析中难以实施.
自1948年shannon等[13]提出信息理论以来,信息熵理论得到了得到了广泛应用,是确定权重的重要手段之一[14-16].信息熵法是基于客观数据的确定权重方法.
本文利用信息熵原理,确定给水管网节点空间与非空间属性权重,以克服权重确定主观性强、操作性差的缺陷,信息熵方法计算权重的过程为
计算归一化属性矩阵:
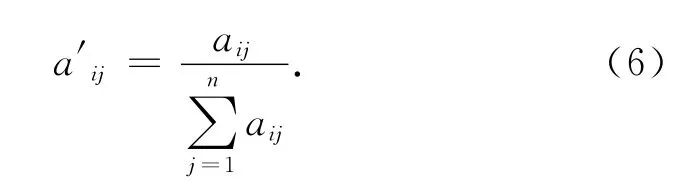
式中:aij为第i个属性第j 个对象的属性值;a′ij为归一化后属性值.
计算第i个属性的信息熵:

式中:Ej为第j个属性信息熵值;g为聚类对象个数.定义属性j对于方案的区分度:

式中:Fj为属性j 的区分度.

式中:wj为属性j 的权重.
1.4 管网节点空间聚类的改进算法步骤
结合自适应-精英保留策略遗传算法和信息熵的K 均值空间聚类计算过程如图1所示.
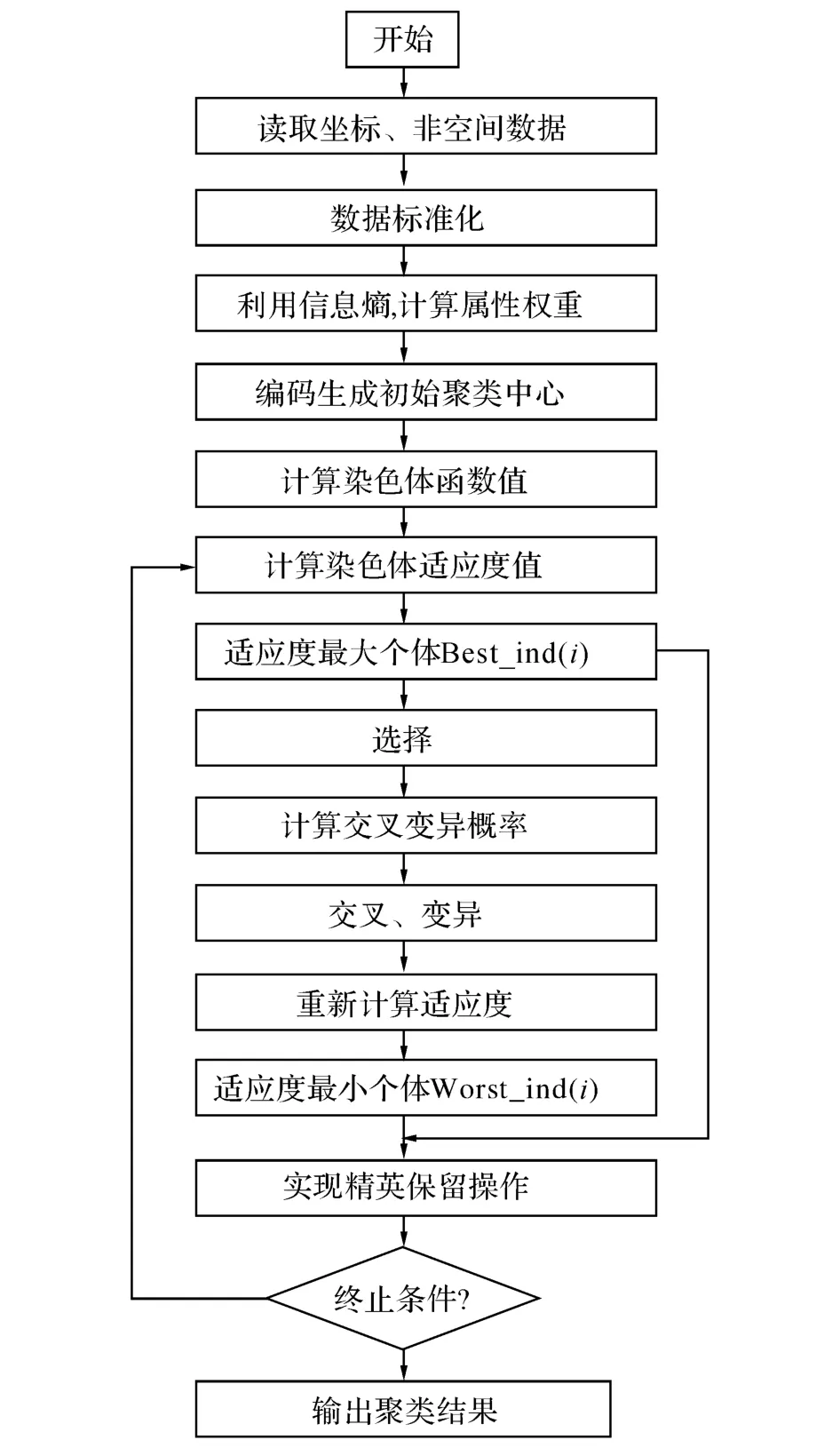
图1 改进的K 均值空间聚类模型框架Fig.1 Framework of K-means spatial clustering combined with adaptive-elitist genetic algorithm and entropy model
2 实例分析
2.1 指标选择
选择华东某中等城市给水管网作为研究对象,给水管网给水服务范围30km2.其中在线压力监测节点40个,在线压力监测数据来自于自来水公司的管网综合管理系统,可以得到120h的节点压力历史数据,数据采样间隔为5min,压力监测设备采样精度2%以内.其他管网节点的压力值,通过自来水公司已建立的在线管网水力模型模拟得到,误差精度在10%以内.在线压力监测节点空间属性由坐标表示,坐标由自来水管公司提供.简化后的管网系统图如图2所示.
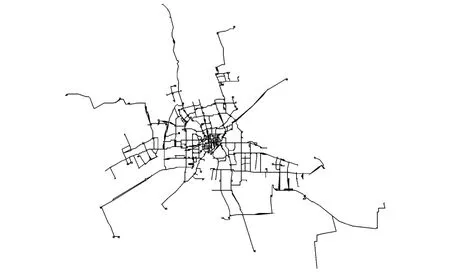
图2 给水管网模型Fig.2 Water distribution system model
给水管网的节点压力值分布在一均值附近,需要利用统计分析的手段描述压力的变化规律.常用的分布统计指标有均值、标准差、偏态系数、峰度等.
压力均值代表每个节点压力的平均水平,但仅靠均值无法描述管网节点的压力变化规律,所以还需要选择其他的统计指标.
峰度是表征概率密度分布曲线在平均值处峰值高低的特征数.在相同的标准差下,峰度越大,其分布就更加陡峭.根据节点压力的变化规律,2个节点压力的均值、标准差、偏态系数有可能很接近,峰度反映节点压力顶端尖峭或扁平程度的指标,能够反映征节点压力分布的独特特征,所以选择峰度系数作为管网节点.
选择管网节点的X、Y 坐标值,压力均值pZ与峰度系数Kc(Kurtosis Coefficient)作为管网节点属性;选择算法消耗时间te(Elapsed Time)、迭代次数S、类内距离Dc(Class Distance)以及各算法迭代结果类内距离的均值AVG、标准差SD(Means、Standard Deviation of 5Iterations Results)作为聚类结果的评价指标,如表1所示为部分节点属性.
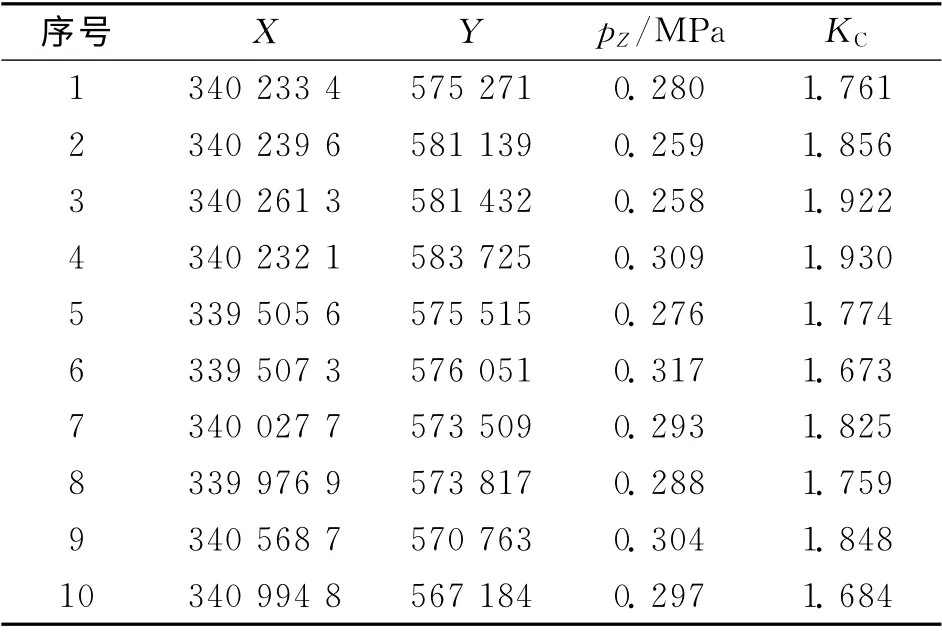
表1 节点坐标与非空间属性Tab.1 nodes’coordinates and non-spatial attributes
2.2 实验结果
本文设计了4种算法,分别为:1)普通K 均值空间聚类(K average spatial clustering);2)GAK 均值 空 间 聚 类(genetic algorithm k average spatial clustering),经典遗传算法K 均值空间聚类(3)AEGAKK 均 值 空 间 聚 类(adaptive elitist genetic algorithm k average spatial clustering),自适应精英保留策略遗传算法K 均值空间聚类;4)SAGAK 均值空间聚类(simulated annealing genetic algorithm k average spatial clustering),模拟退火遗传算法K均值空间聚类.
经过实例验证,从聚类精度、消耗时间、迭代次数3 个方面对比分析4 种算法的性能,结果表明AEGAK 均值空间聚类性能较其他3种方法更优.
另外,为了证明信息熵确定权重的可行性,将AEGAK 均值空间聚类方法中,经过信息熵方法计算得到的权重替换为平均权重,并将2种权重确定方法进行对比.
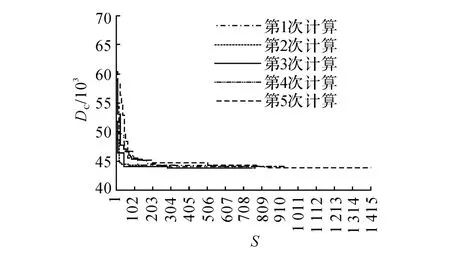
图3 AEGAK 均值空间聚类过程Fig.3 AEGAK-average spatial clustering

表2 4种空间聚类方法性能对比Tab.2 Contradistinction of four spatial clustering methods'performance
如图3所示为AEGAK 均值空间聚类计算过程.如表2所示为4种聚类算法的结果,类内距离表示所有聚类簇的类内距离之和.如表3所示为信息熵方法主观确定权重方法计算得到的属性权重值.如图4、5 所示分别为2 种权重计算方法下,AEGAK 均值空间聚类得到的聚类结果,聚类簇分为8类,数字1-8表示节点所属类别.

表3 2种方法权重对比Tab.3 Contradistinction of weights determined by two different methods
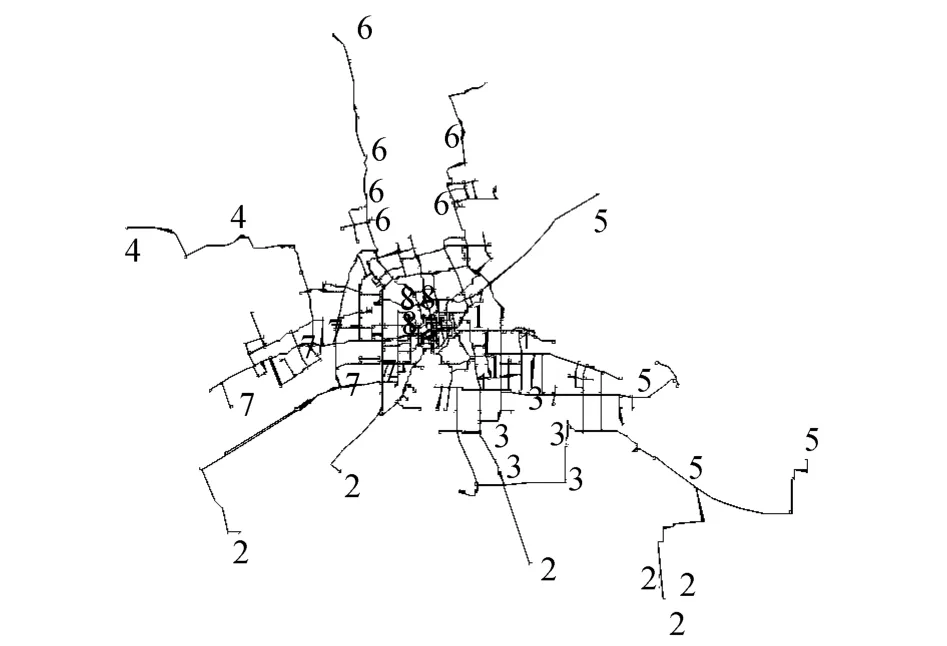
图4 信息熵确定权重的AEGAK 均值空间聚类结果Fig.4 Results of AEGAK-means spatial clustering with entropy-defined weights
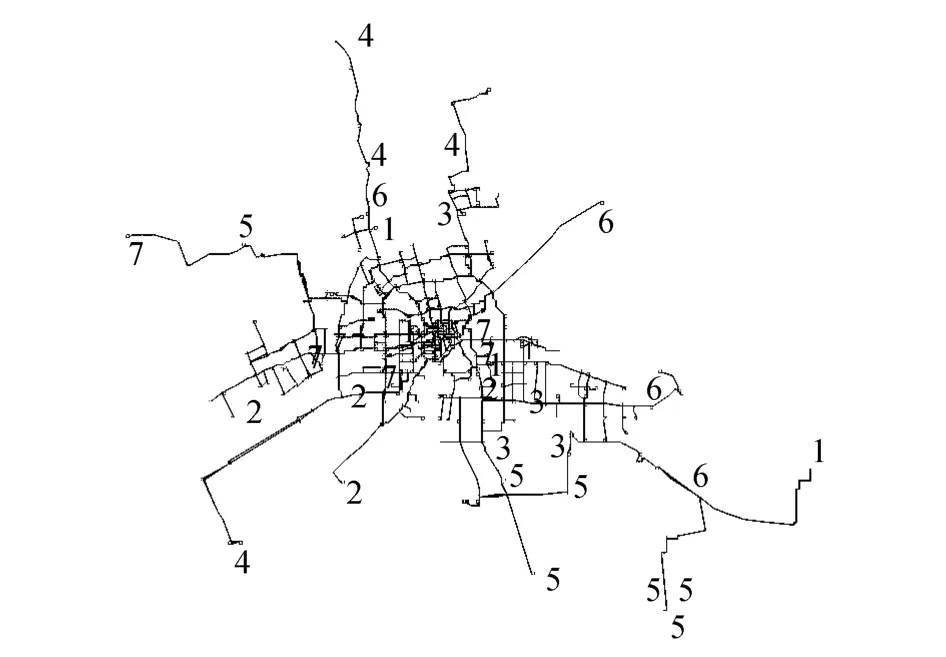
图5 平均权重的AEGAK 均值空间聚类结果Fig.5 Results of AEGAK-means spatial clustering with average weights
1)比较初始聚类中心优化方法.
4种聚类方法的类内距离:普通空间K 均值聚类方法类内距离均值最大,效果最差,其他3种经过优化后的聚类方法得到的结果基本保持在同一水平.
4种聚类方法的稳定性:AEGAK 均值空间聚类类内距离标准差最小为0,相对其他3种方法最稳定.其他3种方法,SAGAK均值空间聚类优于GA K 均值空间聚类,普通均值空间聚类稳定性最差.
4种聚类方法消耗的时间:普通空间K 均值聚类方法基本不需要消耗时间,AEGAK 均值空间聚类消耗时间比GAK 均值空间聚类少,SAGAK 均值空间聚类消耗时间最长.
分别分析4个程序本身的特点,造成以上结果的原因是:
1)普通空间K 均值聚类结果受到初始聚类中心的选取影响较大,空间K 均值聚类结果具有一定的随机性,难以得到最优的聚类结果.相反,经过优化后的聚类算法得到了“最优”初始聚类中心,因此能够得到较好的聚类结果.2)经典GA 算法整体搜索性强,但是容易陷入局部最优解,因此,在相同的终止条件下,得到的最终结果随机型强,并且可能需要消耗大量的时间跳出局部最优解.3)SAGAK 均值空间聚类中,模拟退火部分虽然能够保证算法可以跳出局部最优解,但是却增加了计算的复杂度.4)AEGAK 均值空间聚类方法在迭代初始,设置较大的变异概率比,从而能够保证算法跳出局部最优解,同时采用精英保留策略,可以保证算法的收敛性,并且AEGA 算法没有增加计算量,因而消耗时间比SAGA 少.
2)比较确定权重的方法.
从图4-5可以看出,利用信息熵确定权重,得到的聚类结果是位置相近的节点聚合在一起;而主观将4个属性权重设置成相同值的聚类结果,几个聚类簇包含的节点分布在不同的位置,这是由于非空间属性权重过大造成的.根据经验知道,空间距离越远,节点之间相互影响越小.在同一个聚类簇中,2个距离较远的节点仅仅是压力表现相似,但是造成两者相似的原因可能相同,也可能不同,因此不能真正作为同一类节点.由此可知,利用信息熵确定权重的方法,要优于主权确定权重的方法.
3 结 论
提出利用管网节点的压力均值、压力峰度值2个指标作为给水管网节点的属性,基于管网的空间、非空间属性,对管网节点进行聚类,将多种改进方法应用空间聚类的优化,相对于传统的空间聚类算法,在指标与权重选取、聚类稳定性、聚类精度、等方面都有一定的创新性.
在空间K 均值方法的基础上,进行了以下的工作:(1)利用改进的遗传算法,对一体化空间K 均值聚类方法进行改进,得到优化的初始聚类中心;(2)引入信息熵的方法,得到属性之间的权重;比较了普通GAK 均值空间聚类、AEGAK 均值空间聚类、SAGAK 均值空间聚类法、普通一体化K 均值空间聚类4种聚类方法,认为其中AEGAK 均值空间聚类花费较少的时间,可以得到最好的聚类结果;(3)比较了信息熵确定权重与主观确定权重的方法对于AEGAK 均值空间聚类的影响,认为信息熵确定权重要优于主观确定权重的方法.
给水管网空间聚类应用广泛:在进行管网建模时,需要根据管网节点空间聚类进行简化;开发给水管网调度决策系统时,需对给水管网数百个节点的压力变化及相互间关系进行分析;在管网诊断分析时,需要将管网节点聚为一类,进行信息的融合,提高判断结果的可靠性等.
空间聚类是空间数据挖掘和知识发现的主要途径之一,目前空间聚类方法种类繁多,对于不同问题需要通过比较选择合适的优化与聚类方法.
(
):
[1]王旭冕,黄廷林,刘勇,等.给水管网水质分区聚类分析中的指标三步筛选法[J].西安建筑大学学报:自然科学版.2009,41(5):709-714.WANG Xu-mian,HUANG Ting-lin,LIU Yong,et al.The three-step screening method of indexes for cluster analysis in water supply system's subregion[J].Journal of Xi’an University of Architeture &Technology,2009,41(5):709-714.
[2]李雅洁,王景成,赵平伟.聚类算法在给水管网节点选择中的应用[J].计算机工程,2010,36(8):245-250.LI Ya-jie,WANG Jing-cheng,ZHAO Ping-wei.Application of clustering algorithm in choosing nodes from water supply network[J].Computer Engineering,2010,36(8):245-250.
[3]程广河,任绪才,张让勇.城市给水管网水量漏失监测机制研究[J].给水排水,2007,33(zl):355-357.CHENG Guang-he,REN Xu-cai,ZHANG Rang-yong.Monitoring mechanisms for leakage of urban water distribution system[J].Water & Wastewater Engineering,2007,33(zl):355-357.
[4]PERELMAN L,OSTFELD A.Water-distribution systems simplificationsthrough clustering [J].Journal of Water Resources Planning andManagement,2012,18(3):218-228.
[5]黄璐,李树平,周巍巍,等.基于原有测压点的给水管网压力监测点优化布置研究[J].给水排水.2013,39(2):119-122.HUANG Lu,LI Shu-ping,ZHOU Wei-wei.Study on optimized layout of pressure monitoring points in water supply network based on existing pressure monitoring points[J].Water & Wastewater Engineering,2013,39(2):119-122.
[6]贾新强.基于趋势面分析的城市给水管网系统漏损区判定的研究[D].太原:太原理工大学.2007:25-28.JIA Xin-qang.Research on network leakage region determination based on the analysis method of trend surface[D].Taiyuan:Taiyuan University of Technology.2007:25-28.
[7]邰明明.基于kriging 的给水管网节点压力插值研究[J].中国建筑金属结构.2013,(6):210-211.Tai Ming-ming.Study on node pressure interpolation based on kriging[J].China Construction Metal Structure,2013(6):210-211.
[8]戴一明.基于Kmeans聚类法的给水管网水压监测点优化布置[J].建筑安全.2014,29(8):74-77 DAI Yi-ming.Optimal placement of water distribution system pressure monitors based on k-means clustering[J].Construction Safety,2014,29(8):74-77.
[9]李光强,邓敏,程涛,等.一种基于双重距离的空间聚类方法[J]测绘学报.2008,37(4):482-483.LI Guang-qian,DENG Min,CHENG Tao.et al.A dual distance based spatial clustering method[J].Acta Geodaetica et Cartographica Sinica,2008,37(4):482-483.
[10]李新运,郑新奇,闫弘文.坐标与属性一体化的空间聚类方法研究[J].地理与地理信息科学.2004,20(03):38-40.LI Xin-yun,ZHENG Xin-gi,YAN Hong-wen.On spatial clustering of combination of coordinate and attribute[J].Geography and Geo-Information Science,2004,20(03):38-40.
[11]武兆慧,张桂娟,刘希玉.基于模拟退火遗传算法的聚类分析[J].计算机应用研究.2005,22(12):24-26.WU Zhao-hui,ZHANG Gui-juan,LIU Xi-yu.Clustering based on simulated annealing genetic algorithm[J].Application Research of Computers,2005,22(12):24-26.
[12]桂云苗,朱金福.一种用信息熵确定聚类权重的方法[J].统计与决策.2005(16):29-30.GUI Yun-miao,ZHU Jin-fu.A method of determining clustering weights with entropy information[J].Statistics and Decision.2005(16):29-30.
[13]ZHANG Jun,CHUNG H S H,HU B J.Adaptive probabilities of crossover and mutation in genetic algorithms[J].IEEE Trans Syst Man and Cybernetics,1994,24(4):656-667.
[14]魏书堤,姜小奇.一种利用信息熵确定属性权重的模糊单因素评价方法[J].计算机工程与科学.2010,7(32):93-94.WEI Shu-di,JIANG Xiao-qi.A single-factor fuzzy evaluation method of using information entropy to determine the property weights[J].Computer Engineering and Science,2010,7(32):93-94.
[15]朱红灿,陈能华.粗糙集条件信息熵权重确定方法的改进[J].统计与决策.2011(08):154-156.ZHU Hong-can,CHEN Neng-hua.Improved rough set information entropy method for weight determining[J].Statistics and Decision,2011(08):154-156.
[16]刘冀,王本德.基于组合权重的模糊可变模型及在防洪风险评价中应用[J].大连理工大学学报.2009,49(02):272-275 LIU Ji,WANG Ben-de.Variable fuzzy model based on combined weights and its application to risk assessment for flood control engineering[J].Journal of Dalian University of Technology,2009,49(02):272-275.
猜你喜欢
建筑与预算(2022年10期)2022-11-08
军民两用技术与产品(2022年1期)2022-06-01
建材发展导向(2022年5期)2022-04-18
门窗(2021年2期)2021-08-12
建材发展导向(2021年13期)2021-07-28
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
能源(2018年8期)2018-09-21
中成药(2017年7期)2017-11-22
中国公路(2017年8期)2017-07-21
