
基于归一化算法的噪音鲁棒性连续语音识别*
2015-08-16 09:20刘妍秀孙一鸣杨华民
吉林大学学报(理学版) 2015年3期
刘妍秀,孙一鸣,杨华民
(1.长春大学 教务处,长春 130022;2.长春理工大学 计算机科学技术学院,长春 130022)
基于归一化算法的噪音鲁棒性连续语音识别*
刘妍秀1,孙一鸣2,杨华民2
(1.长春大学 教务处,长春 130022;2.长春理工大学 计算机科学技术学院,长春 130022)
针对归一化方法在连续语音特征曲线调整时存在的问题,提出一种优化解决方案,解决了噪声的不稳定性及不可预测性对语音特征的影响.结果表明,基于该优化方法建立的鲁棒性连续语音识别模型可实现在实验室干净环境和现实噪音环境下同时得到较好的识别结果.
归一化;噪音鲁棒性;连续语音识别
目前,大多数语音识别系统都采用隐Markov模型(HMM)进行识别,它的识别率高、速度快.针对实验室干净环境和噪音环境,通常要使用不同的模型才能得到较好的识别结果[1].本文通过归一化方法建立一个鲁棒性模型,实现了在实验室干净环境和现实噪音环境下同时都能得到较好的识别结果.
1 归一化方法
语音识别领域中针对不同的归一化方法有不同的优化方法.某些归一化方法的计算量较大,因此不能真正应用于实时的语音识别,特别是实时的连续语音识别[2].而计算量小、时间复杂度低的归一化方法又无法获得理想的识别结果.虽然语音识别可根据说话方式、词汇量等输入语音的限制进行分类,但实时性对任何一种语音识别系统都非常重要.针对归一化方法、时间复杂度和识别结果之间的矛盾关系,不同的语音识别需求有不同的实际问题.因此,如何合理地将归一化方法应用到实时性的连续语音识别中是连续语音识别的一个关键问题.
在归一化方法中,动态范围调整(DRA)方法简单、高效,本文基于DRA方法提出了其改进方法.如果以音素为单位,并在每个音素内直接使用DRA方法可能存在缺陷:除无音音素外,其余有效音素的范围太小,一般是3~15帧数据.无音音素包括短暂的停顿(sp)、语音开始和结束时的无音部分(SilB和SilE).如果在音素范围内直接使用DRA方法,会导致语音特征发生急剧变化,且在连续语音中如何精确获取音素的边界也是一个难题[3].如果把范围扩充,例如以10个音素为一组应用DRA方法,归一化过程中,每组的不同最大值会破坏特征曲线在组与组边缘的连续性,且音素的边界确定问题仍未解决.
针对上述问题,本文以语音特征曲线的自然分段为单位进行归一化,虽然不能解决音素边界的精确提取问题,但可通过该方法避免语音特征发生急剧变化的问题.为了最大限度地保持待识别噪音数据与建模数据的相似性,把特征曲线的自然分段定义在过零点附近,在过零点附近对语音特征曲线进行分段可保持特征曲线的连续性.在进行语音特征调整时需确定3个参数:选择过零点的范围、用于进行归一化的最大值和噪声影响系数[4].
在选择过零点时不考虑该过零点是否出现在音素特征曲线的中间位置,因为多数过零点并不出现在音素特征曲线的边界,而出现在音素特征曲线的中间位置.在检测过零点时不考虑检出特征曲线中所有的过零点,因为受噪音影响,短时内可能出现多个过零点.特征曲线调整的思想是通过对过零点的选择及部分显著特征的部分恢复保持待识别噪声特征曲线和建模特征曲线的相似性,并在两个过零点之间应用DRA方法保证特征曲线的连续性.
2 噪声影响分析
噪声信号会对语音信号产生影响,理论上,噪音对信号增益部分与信号直流分量部分产生的影响不同,相对于纯净的语音信号,噪音对直流分量部分会产生较强的影响.图1为噪声对孤立词语音特征曲线的影响.其中:蓝色表示纯净语音的特征曲线,绿色表示受噪声干扰后的特征曲线.由图1可见:在红线标识处的差异导致了识别精度的下降,但通过归一化方法最大限度地减少了这种差异;受干扰后特征曲线的动态范围小于纯净语音特征曲线的动态范围.因此归一化方法在孤立词识别中作用明显[5].由语音特征曲线可见,特征曲线的显著部分虽会受噪声的影响,但影响后的特征与其他部分相比仍为明显特征.
在孤立词中,噪声对峰值的影响多成比例关系,因此通过归一化算法能减少噪声带来的影响.但在连续语音特征曲线中,噪声对特征曲线动态范围的影响与孤立词相同,但随着连续语音特征曲线的延长,虽然部分语音特征被噪声完全破坏,但其明显特征部分比孤立词多,而且明显特征部分受噪音影响的程度也不一致,在明显特征部分也没有孤立词中较稳定的对应关系[6].图2为噪声对连续语音特征曲线的影响.

图1 噪声对孤立词语音特征曲线的影响Fig.1 Effect of noise on the isolated wordspeech characteristic curve
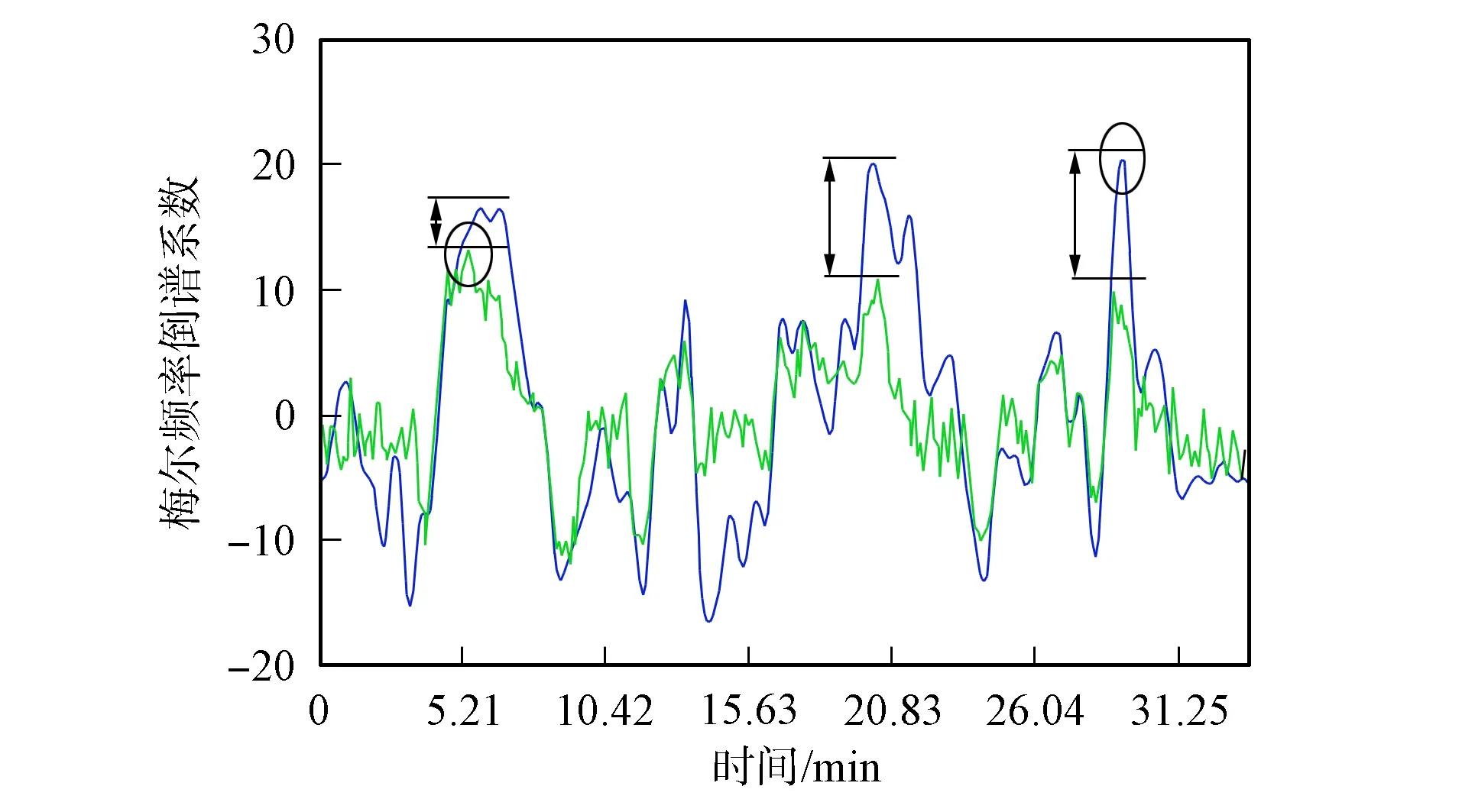
图2 噪声对连续语音特征曲线的影响Fig.2 Effect of noise on continuous speechcharacteristic curve
如果在连续语音特征调整中使用归一化方法,必须对原有方法进行改进.在改进过程中,期望通过不同的调整值保持显著特征部分能相互匹配,从而增加识别的正确比例.由图2可见,受噪声影响特征曲线的最高峰值与纯净语音的最高峰值并不对应,因此容易判断出该位置不能很好地匹配,这部分的显著特征需要进行单独处理.继续观察可见,特征曲线中峰值显著部分的比例关系由于噪声的影响也受到了破坏,因此,在算法中还需对受噪声影响显著特征部分的比例关系进行恢复[7].
3 特征调整算法的优化
特征调整算法优化步骤如下.

(1)

2)获得调整值.从第一帧到LP2之间,选择一个绝对值最大的峰值并定义该值为P2,从LP3到最后一帧之间,选择一个绝对值最大的峰值并定义该值为P3.最大值在DRA算法中决定了特征向量的压缩比例,在不同分段内使用不同的调整值,在每个分段内的最大值定义为Tmax,然后将Tmax与P2和P3进行比较.定义Mmax=max{Mmax,P2,P3},如果P1-Mmax<2,则将max{Mmax,P2,P3}作为最终的调整值;否则,选择P1作为调整值.
3)添加噪音系数.噪音类型和信噪比会对语音产生不同的影响,因此噪音系数包含噪音类型系数和噪音信噪比系数,定义N1,N2和N3为不同类型的噪音系数,SSNR为噪音信噪比系数,S10,S15和S20分别对应10,15,20 dB,分别设置S10=0.1,S15=-0.1,S20=-0.8,N1:-0.2~0.3,N2:0~0.3,N3:-0.2~0.1,这些系数的值和范围均来自实验数据.
4)在分段内使用DRA算法.根据已得到的分段和调整值以及噪音系数对语音特征进行归一化处理,在主分段内,使用(P1+SSNR+N2)作为调整值进行归一化,在主分段左侧使用(Mmax+SSNR+N2)作为调整值进行归一化,在主分段右侧使用(Mmax+SSNR+N3)作为调整值进行归一化.新的语音特征归一化向量为
(2)
其中:CB(n)表示归一化后的语音特征;CBf表示主分段左侧的任意一个特征向量;CBb表示主分段右侧的任意一个特征向量;CBm表示主分段内的任意一个特征向量.
由式(2)可见,所有连续语音特征的动态范围都被调整到(-1,1)内,在实验仿真时,可精确知道噪音的类型,但在实际环境中,很难得到确切的噪音类型,因此,在未知噪音类型的情况下,可将N1,N2和N3设置为0,即在实际应用中可以只考虑信噪比而不考虑噪音类型[8].
4 模型建立与识别
本文以音素为基本识别单位建立HMM模型,建模数据为实验室环境的纯净语音数据.虽然建模数据为实验室环境下的语音数据,但在信号处理阶段仍使用倒谱均值相减法(CMS)去除信道的噪声,去除噪声后先用梅尔频率倒谱系数(MFCC)对连续语音特征进行提取,再用运行频谱分析(RSA)方法对得到的MFCC语音特征进行优化,最后使用DRA方法对语音特征进行归一化处理.在模型训练阶段,使用归一化后的特征对语音文本进行上下文文本相关训练.为了保证发音的多样性,在训练过程中未对训练语音进行任何分段处理.建模过程中根据发音的主要特点对上下文相关的三音素进行分类,得到最终模型.分类规则列于表1.

表1 音素分类规则Table 1 Phoneme classification rule
如果设置“X”为中心音素,在中心音素左侧的音素用“-”标识,中心音素右侧的音素用“+”标识,根据表1中规则对三音模型进行聚类,聚类后的模型用于识别匹配.
在识别中,为了保证识别实时性的需求,信号处理阶段只使用最基本的CMS方法进行去噪,并使用MFCC进行连续语音特征提取,针对MFCC语音特征再使用本文提出的算法.RSA方法主要对特征曲线进行平滑处理,有利于训练过程中对纯净语音下大量的相似特征进行建模,而识别中要尽量保持有限的明显特征,故在识别中不使用RSA方法,而是通过本文提出的算法尽量去保持连续语音特征中的明显部分.
5 实验结果分析
通过对算法的改进,在识别时有效放大了连续语音特征曲线中特征明显的部分,针对训练和识别中采样量化、建模工具及需要设置的各种参数如下:采样频率为16 kHz;量化标准为16位;特征向量为12维MFCC参数+12维一阶MFCC参数+1阶能量特征(共25维);帧长为25 ms;偏移量为10 ms;窗口类型为海宁窗;音素个数为43个;语音增强公式为1~0.97z-1;HMM状态数为5个状态(由左至右HMM,含开始和结束状态);高斯混合数为16;聚类状态约为2 000个;训练数据为153人朗读共计23 561个句子;无语言模型;建模工具为HMM ToolKit;识别工具为JULIUS.
为了验证模型的鲁棒性,在识别时不仅使用建模数据进行验证,还使用了与建模数据完全不同的数据进行测试.建模数据为12人朗读共50个句子;未知数据为6人朗读共180个句子;采样分帧条件同上.
分别使用建模数据和未知数据对系统模型进行测试能更好反应声学模型的鲁棒性和算法的可靠性.识别正确率(corr)可反映在连续语音所有单词序列中正确识别单词的比例;识别精度(acc)可反应连续语音的整体识别性能.在识别结果中,针对单词的错误被分成插入性错误(insertion error)、删除性错误(deletion error)和子词错误(subsitution error).与识别精度相比,识别正确率中只考虑对单词的识别是否正确,而不考虑插入性错误对识别的影响.在连续语音识别中,一般以识别的正确率作为评价标准.用公式表示为:
(3)
(4)
其中:N为连续语音中总的单词数;S为子词性错误;D为删除性错误;I为插入性错误;RC为识别正确率;RA为识别精度[9].
针对实验室环境下的非训练数据,本文算法也体现了良好的性能.表2和表3分别列出了使用原方法和本文方法的识别结果.由表2和表3可见,算法对删除性错误有显著影响.

表2 原有方法的识别结果Table 2 Recognition results by the original method

表3 本文方法的识别结果Table 3 Results of this method using the identification
在各种噪声中,因为白噪声会在所有的频谱内对语音产生影响,甚至淹没整个语音特征,一般除信号去噪外算法很难对该噪声产生影响,因此是最难处理的噪声信号.表4为不同噪声类型系数对10 dB白噪声识别精度的影响,取S10=0.1.由表4可见,本文算法可有效识别白噪声.

表4 白噪声下不同噪声系数对识别精度的影响Table 4 Effect of different factors on the recognition accuracy under the white noise
在噪声测试中,对NOISEX-92中规定的标准噪声全部进行算法有效性的测试.实验中应用15种噪音类型,分别为babble,buccaneer1,buccaneer2,destroyerengniner,destroyerops,f16,factory1,factory2,hfchannel,leopard,m109,machinegun,pink,volvo和white.针对不同种类和不同强度的噪声对算法进行测试.测试结果表明,本文提出的基于分段DRA方法对连续语音特征向量进行了优化,提出的方法不仅在实验室环境下体现了良好的噪音鲁棒性,在噪音环境下算法仍比原方法有效,表5列出了15种不同噪音下的平均识别精度.在各种噪声中,相同的信噪比环境下,白色噪声和气泡噪声的识别精度最低,汽车噪音下的识别精度最高.在不同噪声下,算法对噪声类别的影响系数均设置为0,如果针对不同的噪声取不同的噪声系数,识别结果的均值在10 dB情况下比表5中给出的结果约高10%,但由于实际环境中噪声复杂,所以本文未针对不同噪音系数下给出系数值和相应的结果.表5中结果所有的噪音系数均为0.
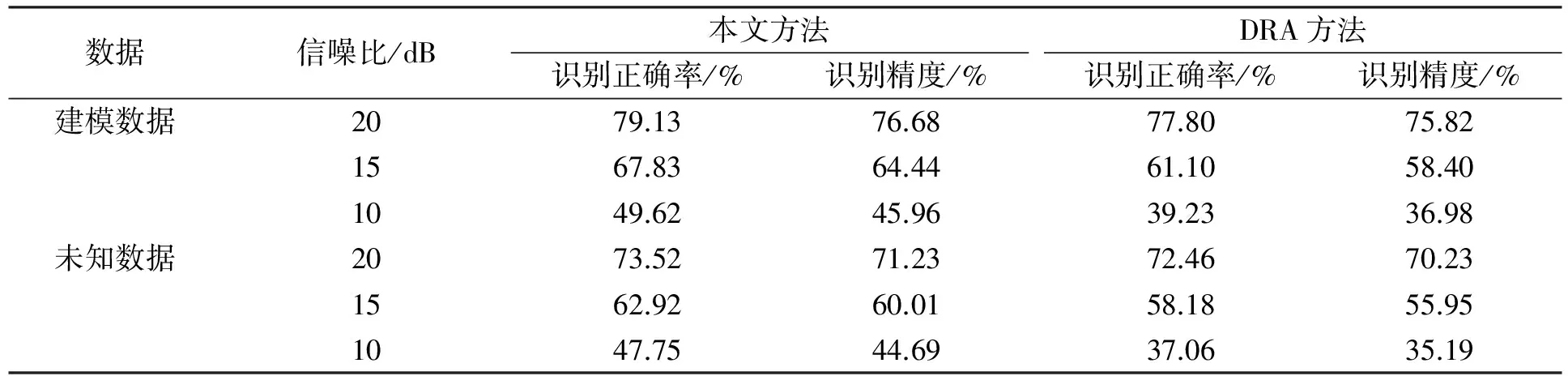
表5 不同信噪比下的识别精度Table 5 Recognition accuracy at different SNR
综上所述,本文从归一化方法出发,通过分析归一化方法在孤立词中应用的优势和噪声对语音特征的影响,发现了归一化方法在连续语音特征曲线调整时存在的问题,并根据问题提出了优化解决方案,同时,进一步解决了噪声的不稳定性及不可预测性对语音特征的影响.
[1] 钟金宏,杨善林,徐士林.三字词语调的模糊识别方法 [J].系统工程与电子技术,2000,22(12):69-72.(ZHONG Jinhong,YANG Shanlin,XU Shilin.Fuzzy Recognition of Three Words and Intonation [J].Systems Engineering and Electronics,2000,22(12):69-72.)
[2] Lev-Ari H,Ephraim Y.Extension of the Signal Subspace Speech Enhancement Approach to Colored Noise [J].IEEE Signal Processing Letters,2003,10(4):104-106.
[3] 金银燕,于凤琴,何艳.基于时频分布与MFCC的说话人识别 [J].计算机系统应用,2012,21(4):189-190.(JIN Yinyan,YU Fengqin,HE Yan.Based on the Speaker Recognition of Frequency Distribution and MFCC [J].Computer Systems and Applications,2012,21(4):189-190.)
[4] 胡坚,樊可清.基于归一化互相关法的声学回声消除及仿真 [J].微计算机信息,2010,4(1):186-187.(HU Jian,FAN Keqing.Based on Acoustic Echo Normalized Cross-Correlation Method of Elimination and Simulation [J].Microcomputer Information,2010,4(1):186-187.)
[5] SUN Yiming.A Study on Noise Robust Continuous Speech Recognition System Using Block Based Dynamic Range Adjustment [D].[S.l.]:Graduate School of Information Science and Technology of Hokkaido University,2012:25-27.
[6] 韩纪庆,张磊,郑铁冉.语音信号处理 [M].北京:清华大学出版社,2004:98-102.(HAN Jiqing,ZHANG Lei,ZHENG Tieran.Speech Signal Processing [M].Beijing:Tsinghua University Press,2004:98-102.)
[7] 庞全,陈晨方,杨翠容.基于美尔倒谱系数和复杂性的语种辨识 [J].计算机工程,2008,34(19):203-204.(PANG Quan,CHEN Chenfang,YANG Cuirong.Based Mel Cepstral and Complexity of Language Identification [J].Computer Engineering,2008,34(19):203-204.)
[8] 倪崇嘉,刘文举.汉语大词汇量连续语音识别系统研究进展 [J].中文信息学报,2009,23(1):56-57.(NI Chongjia,LIU Wenju.Progress Identification System Chinese Large Vocabulary Continuous Speech [J].Journal of Chinese Information,2009,23(1):56-57.)
[9] 袁里驰.基于改进的隐马尔科夫模型的语音识别方法 [J].中南大学学报,2008,39(6):23-26.(YUAN Lichi.Improved Voice Recognition Method Based on Hidden Markov Models [J].Journal of Central South University,2008,39(6):23-26.)
(责任编辑:韩 啸)
NoiseRobustContinuousSpeechRecognitionBasedonNormalization
LIU Yanxiu1,SUN Yiming2,YANG Huamin2
(1.OfficeofAcademicAffairs,ChangchunUniversity,Changchun130022,China;2.Collegeof
ComputerScienceandTechnology,ChangchunUniversityofScienceandTechnology,Changchun130022,China)
Analyzing the impact of normalization method applied in isolated word speech dominant and noise characteristics to discover the continuous speech characteristic curve adjustment problems.The authors raised optimized solutions to further solve the problem of instability and unpredictability of the noise characteristics for voice effects.Robust continuous speech recognition model by normalization method in this paper can achieve a clean environment in the laboratory and real noise environment so as to get the best recognition results.
normalization;noise-robust;continuous speech recognition
10.13413/j.cnki.jdxblxb.2015.03.32
2014-12-18. *“吉林省计算机学会2015年学术年会(JLPCF2015)”征集论文.
刘妍秀(1984—),女,汉族,硕士,实验师,从事计算机语音识别的研究,E-mail:klxx123456@163.com.
吉林省自然科学基金(批准号:20140101227JC).
TP319
:A
:1671-5489(2015)03-0519-06
猜你喜欢
数学物理学报(2021年4期)2021-08-30
小学科学(学生版)(2020年10期)2020-10-28
北京教育·普教版(2020年9期)2020-10-09
疯狂英语·新悦读(2019年10期)2019-12-13
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
小学生学习指导(低年级)(2018年11期)2018-12-03
疯狂英语·新策略(2018年7期)2018-08-29
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
