
基于两种耦合方法的模拟-优化模型在地下水污染源识别中的对比
2015-08-25 06:16肖传宁卢文喜安永凯顾文龙吉林大学地下水资源与环境教育部重点实验室吉林长春130012吉林大学环境与资源学院吉林长春130012
中国环境科学 2015年8期
肖传宁,卢文喜*,安永凯,顾文龙,赵 莹(1.吉林大学地下水资源与环境教育部重点实验室,吉林长春 130012;2.吉林大学环境与资源学院,吉林 长春 130012)
基于两种耦合方法的模拟-优化模型在地下水污染源识别中的对比
肖传宁1,2,卢文喜1,2*,安永凯1,2,顾文龙1,2,赵莹1,2(1.吉林大学地下水资源与环境教育部重点实验室,吉林长春 130012;2.吉林大学环境与资源学院,吉林 长春 130012)
采用一种基于模拟-优化模型的方法对地下水污染源进行识别研究.模拟-优化模型分别采用响应矩阵法和状态转移方程法进行耦合,并利用遗传算法求解,经过多次迭代,使得模拟结果与观测数据的误差达到最小.最后,通过一个假想例子评估模拟-优化模型的性能,同时比较应用不同耦合方法的计算结果.研究表明:应用响应矩阵法耦合模拟-优化模型所得结果的绝对误差范围为0.1~1.6g/L,应用状态转移方程法时,绝对误差范围为 0~5.2g/L,因此,采用遗传算法求解模拟-优化模型能够有效且准确地得到地下水污染源的释放量,可以应用于地下水污染源识别问题,并且采用响应矩阵法耦合模拟-优化模型优于状态转移方程法.
地下水;污染源识别;模拟-优化;响应矩阵法;状态转移方程法;遗传算法
由于我国当前水资源短缺、水环境不断恶化,地下水污染的治理已经成为亟待解决的问题[1].地下水污染源识别是地下水污染治理的首要步骤,对保护地下水资源有重要意义[2-5].
针对地下水污染源识别问题,Atmadja等[6]总结了解决地下水污染源识别的一些数学方法,并将其分为四类:优化方法、解析方法、直接法、随机理论[7-8]和地质统计学方法[9].在这些方法中,优化是使用最为广泛的解决方法.Gorelick等[10]较早使用优化方法研究理想的二维含水层中的污染物识别问题,他们假设算例含水层参数不存在不确定性,采用线性规划法、多元线性回归求解优化模型.Mahar等[11]利用初步识别的污染源位置优化观测井网,应用优化后的观测井网得到的监测数据采用非线性规划法得到了更准确的源位置.
由于地下水优化模型的非线性,仅仅通过非启发式的优化算法,如Newton法、单纯形法、共轭梯度法、Hooke-Jeeves方法等来解决污染源的识别问题存在较大的困难,这些传统的优化算法都是与初始点有关的算法,所求解容易陷入局部最优,在求解地下水逆问题时可能难以得到满意的结果[12].因此需要运用启发式优化算法才能解决地下水污染源识别的优化问题.如Aral等[13]将进步式遗传算法应用于解决二维含水层中的污染物溯源问题,提高了模型的计算效率.Singh等[14]采用外部连接的形式将遗传算法和地下水流及溶质迁移模型耦合在一起,形成模拟-优化模型,并将其应用于二维溯源问题.Ayvaz[15]利用和声搜索算法解决污染源的识别问题,并用两个复杂程度不同的案例评估了优化模型的性能.江思珉等[16-18]分别利用和声搜索算法、单纯形模拟退火算法和Hooke-Jeeves吸引扩散粒子群混合算法求解地下水污染源反演的模拟-优化模型.范小平等[19]利用遗传算法,结合最佳摄动思想设计了一种改进遗传算法,确定了淄博沣水南部地区的地下水硫酸污染源强度.
上述研究在耦合模拟模型与优化模型时,大多数采用的是外部连接的方式,需要求解的变量多.本文以污染源释放量为决策变量建立优化模型,分别采用响应矩阵法和状态转移方程法将地下水水流模型和污染物运移模型与优化模型进行耦合.响应矩阵法充分考虑污染源释放量与污染物浓度在时空分布上的数量关系,显著减少了变量个数,提高了模型的计算效率,状态转移方程法利用动态规划的思想,表示出地下水系统从某一时段到下一时段的状态转移规律.最后基于遗传算法求解模拟-优化模型,将其应用到地下水污染源识别研究中,并比较应用两种不同耦合方法时的计算所得的结果.
1 模型及其耦合方法
1.1模拟-优化模型
地下水污染源识别问题的模拟-优化模型由模拟模型与优化模型两部分组成,模拟模型描述地下水运动的基本规律,包括水流模型与溶质运移模型,优化模型则用来将污染源识别问题转化为决策变量为污染物释放量的最优化问题.
1.1.1模拟模型二维含水层系统稳定流基本微分方程表示为[20]:
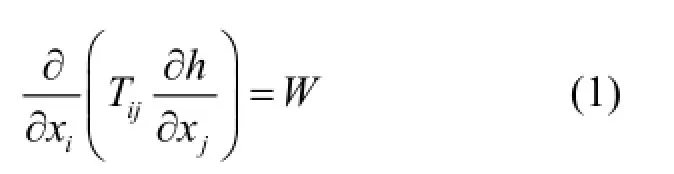
式中:xi和xj为i,j=x,y的直角坐标系,h为水头值, m;W为单位面积流入(负值)或流出(正值)水的体积通量,m/s;Tij为导水系数(m2/s),并且当 Kij为水力传导系数(m/s),b为饱和含水层厚度时,Tij=Kijb.需指出二维水力传导系数,Kxx和Kyy与x,y轴方向一致并且所有的非主要的量都为零.
描述二维含水层系统中污染物运移的基本微分方程可以表示为[20]:
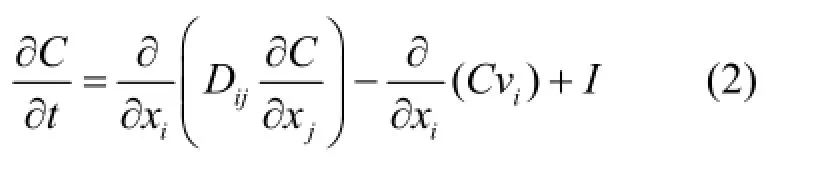
式中:t为时间,s;C为溶解浓度,mg/L;vi为平均线型渗流速度,m/s;I为源汇项,指单位时间单位液相体积(只包含液相的体积)内溶质质量的增减量,mg/(L·s);Dij为水动力弥散张量,m2/s,其要素由纵向(αL)与横向(αT)弥散度(m)、分子扩散系数(D*)(m2/s)和νi计算可得.
上述两式可通过达西定律产生联系,如下式[20]:
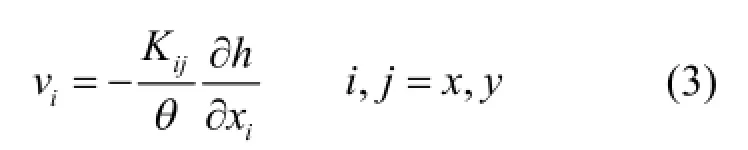
式中: θ为有效孔隙度,无量纲.
1.1.2优化模型如前文所述,解决地下水污染源识别问题的方法是建立优化模型.优化模型一般由决策变量、目标函数、约束条件三个要素构成[21].在本文的优化模型中,决策变量为污染源流量,状态变量为研究区内各处污染物浓度,目标函数是使观测点浓度的观测值与模拟值之间的误差最小,如下式(4)所示.
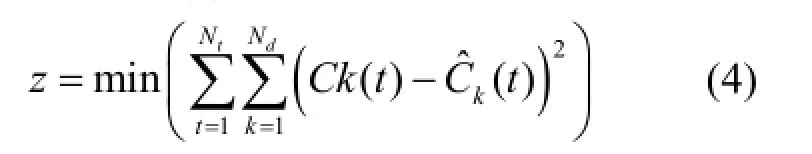
式中:Nt为观测的时刻数;Nd为观测点的数目;Ck(t)、分别为第k个观测点在第t时刻污染物浓度的模拟值和测量值.
约束条件如下式(5)所示:
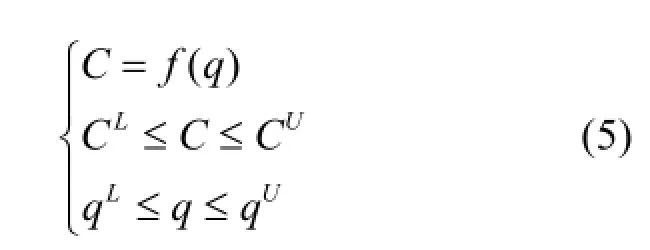
式中:C为污染物浓度;f为污染物迁移模拟模型;q为污染源流量;CL、CU分别为污染物浓度的上下界;qL、qU分别为源流量的上下界.
1.2耦合方法
在优化模型进行寻优的过程中,必须要以模拟模型为基础才能遵循地下水实际系统固有原理和规律[22].因此就需要将模拟模型通过某种途径或方式嵌入到优化模型中,使之成为优化模型的组成部分,实现模拟模型与优化模型的连接耦合.地下水流运动和污染物迁移的模拟模型与优化模型耦合方法主要有嵌入法、响应矩阵法以及状态转移方程法.
嵌入法是把地下水系统模拟模型的转换形式—代数方程组作为等式约束条件嵌入到优化模型中,连同地下水管理的其他约束条件和目标函数一起,构成地下水系统模拟-优化模型.通过嵌入法可以对地下水系统中任一结点的污染物浓度构造约束条件,是一种比较“细”的处理方法,其缺点是没有考虑状态变量与决策变量间的函数关系,将两者同时作为决策变量,使得模型的维数剧增,对于多时段非稳定问题,还会产生所谓的“维数灾难”[22].
响应矩阵法首先运用地下水系统的模拟模型来确定系统的输出(污染物浓度)对输入(污染源流量)的响应关系—单位脉冲响应函数,并形成其函数值的集合—响应矩阵.这种输入—输出的函数相应关系反映了具体表现为系统的状态变量(污染物浓度)和决策变量(污染源流量)间的数量关系.当污染源在dj点以释放量I(dj,t)在0~t之间连续释放污染物,那么在di点在t时刻产生的累计浓度变化值为
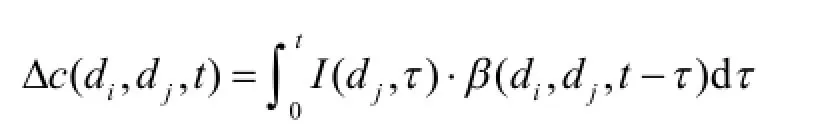
经离散化后,单位脉冲响应函数的离散形式为β(i,j,n-k-1),表示为第j个结点在第k个时段以单位释放量释放污染物,在第i个结点在第n个时段末所产生的浓度变化响应.累计浓度变化响应为:

若同时存在m个污染源,则它们产生的综合累计浓度变化响应应为
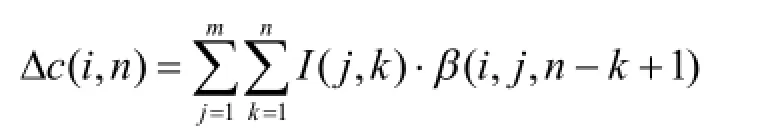
当单位释放量确定后,单位脉冲响应函数仅与地下水系统本身的特征有关,对于非稳定问题,还与时间有关.将上述数量关系应用在优化模型中,用决策变量将需要加以控制的状态变量表达出来.在此基础之上,综合考虑其他因素,就可以完成模拟-优化模型的构建.与嵌入法相比,响应矩阵法确定了状态变量与决策变量间的函数关系,可以显著地减少优化模型中决策变量和约束方程的个数,从而提高模型的计算效率[22].
状态转移方程法运用动态规划的思想将地下水系统在某一时刻随时间的变化过程划分为若干个时段,把每一时段的末刻浓度值看成该时段的初始浓度值及可控输入变量的函数,运用一阶泰勒级数展开式,把末刻浓度用初始浓度和可控输入近似地表示出来,构成状态转移方程,其形式可以表示为
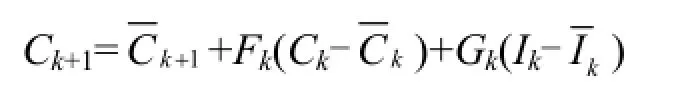
式中:Ik为实际污染物释放量,为初估值,Ck、分别为由初估值计算所得的k、k+1时刻的浓度值,Ck+1、Ck为 k、k+1时刻的实际浓度值,Fk、Gk为Jacobian矩阵.利用上式并综合考虑其它因素,就可实现模拟模型与优化模型的耦合连接.式中的Jacobian矩阵Fk、Gk由模拟模型离散后所形成的代数方程组求得,具体表示形式为
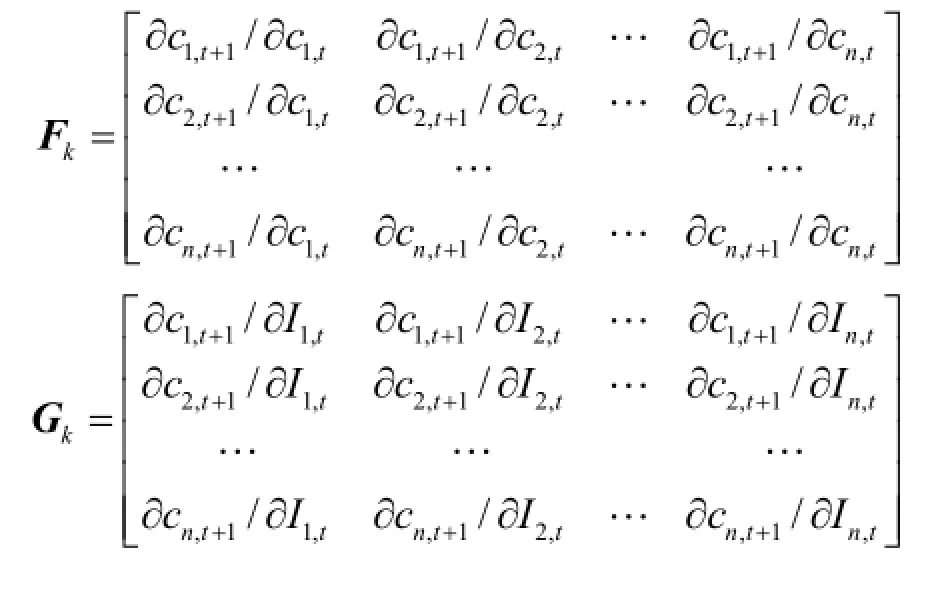
在实际计算中,通常可以将一个时段再划分成若干个小时段,首先给定一组决策变量的初估值,正演模拟模型,得到各时段的初始浓度和末刻浓度,利用求出的Jacobian矩阵,建立每个小时段的状态转移方程,进而推导出各大时段的状态转移方程,然后将其与优化模型进行耦合,这种方法物理意义明确,容易理解.需要说明的是,当地下水系统的模拟模型中的偏微分方程是线性偏微分方程时,Jacobian矩阵是不变的,所以只需求解一次 Jacobian矩阵,而当地下水系统模拟模型中的偏微分方程为非线性偏微分方程时,在每次迭代中Jacobian矩阵都需要重新计算[22].
本文分别采用响应矩阵法和状态转移方程法将模拟模型嵌入优化模型构建出反演地下水污染源浓度的模拟-优化模型.
2 遗传算法
遗传算法是一类随机优化算法,它模拟了自然选择和遗传中的复制、交叉和变异现象,从任一初始种群(Population)出发,通过随机选择、交叉和变异操作,产生一群更适应环境的个体,使种群进化到搜索空间中越来越好的区域,这样一代一代不断繁衍进化,最后收敛到一群最适应环境的个体(Individual),求得问题的最优解[23].
完整的遗传算法流程可以用图1来描述[24].
由图1可以看出,使用上述3种遗传算子(选择算子、交叉算子、变异算子)的遗传算法的主要运算过程如下[24]:
(1)编码:解空间的解数据x,作为遗传算法的表现型形式.从变现型到基因型的映射称为编
码.遗传算法在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结构数据,这些串结构数据的不同组合就构成了不同的点.
(2)初始群体的生成:随机产生N个初始串结构数据,每个串结构数据称为一个个体,N个个体构成了一个群体.遗传算法以这N个串结构作为初始点开始迭代.设置进化代数计数器t←0,设置最大进化代数T;随机生成M个个体作为初始种群P(0).
(3)适应度值评价检测:适应度函数表明个体或解的优劣性.对于不同的问题,适应度函数的定义方式不同.根据具体问题,计算群体 P(t)中各个个体的适应度.
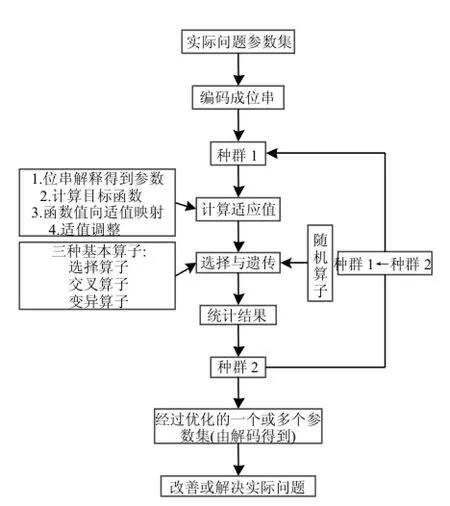
图1 遗传算法流程Fig.1 Schematic representation of Genetic Algorithm
(4)选择:将选择算子作用于群体.
(5)交叉:将交叉算子作用于群体.
(6)变异:将变异算子作用于群体.群体P(t)经过选择、交叉、变异运算后得到下一代群体P(t+1).
(7)终止条件判断:若t≤T,则t←t+1,转到步骤(2);若t>T,则以进化过程中所得到的具有最大适应度的个体作为最优解输出,终止运算.
从遗传算法运算流程可以看出,进化操作过程简单,容易理解.
3 案例应用
3.1问题概述
如图2所示,研究区存在二维均质各向同性的矩形承压含水层(800m×700m),用边长为100m的正方形网格将研究区剖分成7行8列的有限差分网格.假设含水层水流运动为稳定流,左右两条边界是线性变化的定水头边界,上下边界为隔水边界,含水层的各项相关参数见表 1 .初始时刻,研究区内无污染物.假定研究区存在一个污染源,污染源的位置为(4,3)(位置以行、列表示),污染源流量真值见表 2,污染源的污染物释放不会影响水流状态,同时在污染区布置6个污染物浓度监测点,污染物浓度在每个时段末进行测量.
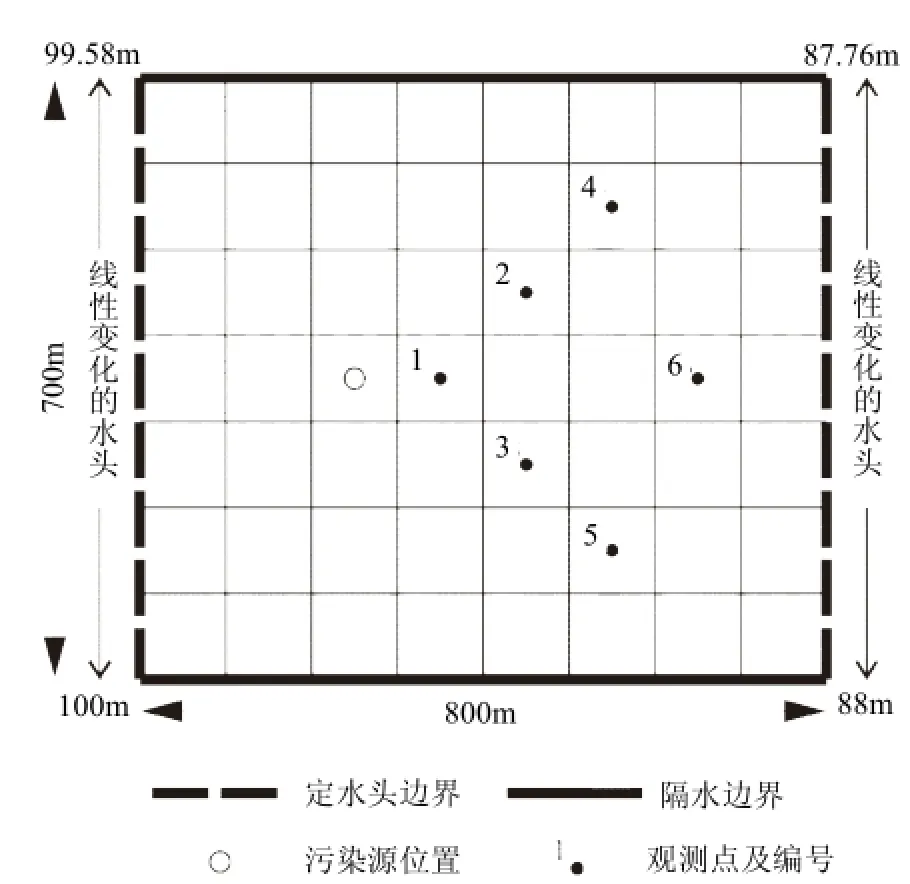
图2 假想例子含水层模型Fig.2 Hypothetical aquifer model
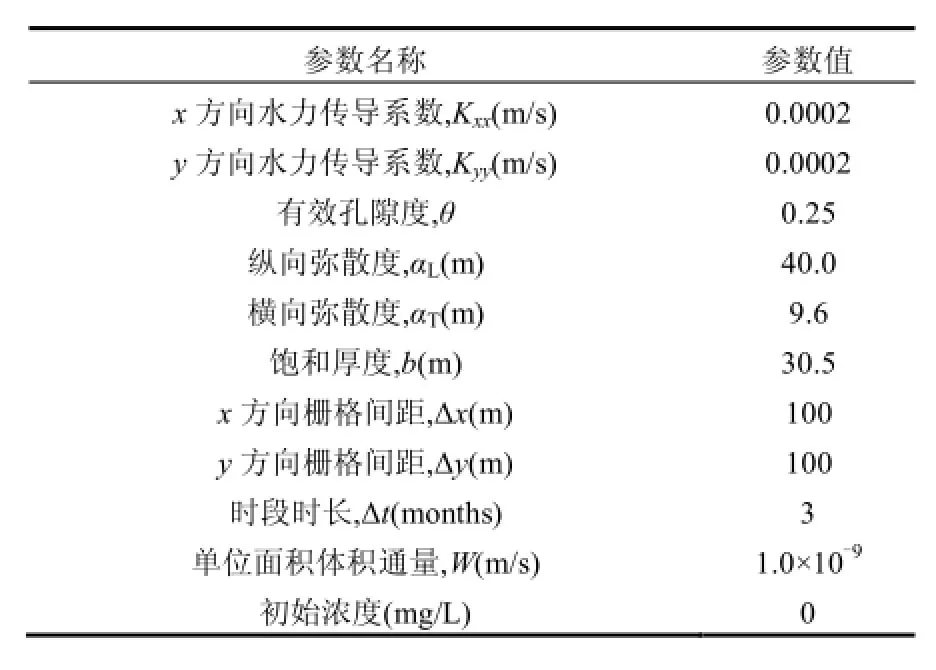
表 1 含水层相关参数Table 1 Related solution parameters
假想案例中监测点的污染物浓度监测值利用模拟程序GMS 中的 MODFLOW 模块和MT3DMS模块正演计算得到[25],模拟时段为九个月,分三个释放期.模拟程序正演得到各监测点浓度变化曲线见图3.

表2 污染源流量真值(SP:释放期)Table 2 Actual values of the source fluxes (SP: stressperiod)
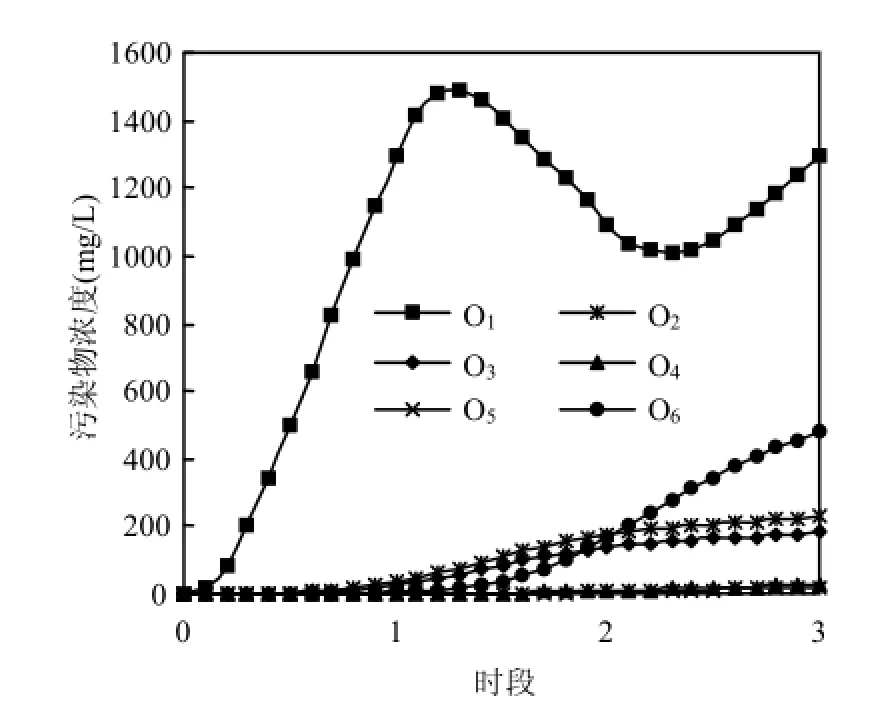
图3 监测点浓度变化曲线Fig.3 Concentration curve of the monitoring location
3.2模型求解
假想例子中,决策变量为污染源释放量,共有3个(1个污染源×3个释放期),其取值范围的上下边界分别设置为qU=100g/L,qL=0g/L. 6个监测点(O1~O6)在3个时段末的浓度监测值作为已知量代入模拟-优化模型中.建立假想例子的模拟-优化模型见式(6):
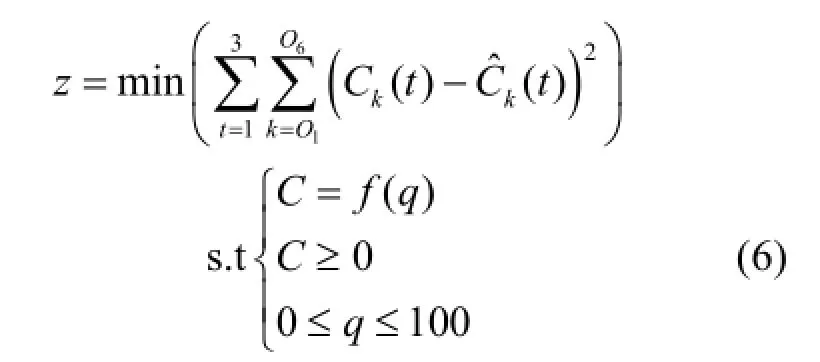
利用MATLAB软件中的遗传算法工具箱求解模拟-优化模型,主要参数设置为: Population size(种群尺寸)=20,Initial range(初值范围)=[0;1], Fitness scaling(适应度缩放比例)为Rank(排列算法),Selection(选择参数)为 Stochastic uniform(随机均匀分布),Mutation(变异参数)为 Adaptive feasible(自适应约束),Crossover(交叉参数)为Scattered(分散交叉),Migration(迁移参数)方向为Forward,其他参数设置为缺省值.为检验遗传算法稳定性,以相同的参数分别计算5次所得结果见表3和图4.表3为应用不同耦合方法分别计算5次所得结果,图4为计算结果的绝对误差柱状图.

表3 应用不同耦合方法的计算结果Table 3 The results calculated by different coupling methods
3.3结果分析
由图 4计算结果绝对误差柱状图可以看出应用响应矩阵法耦合模拟-优化模型计算源释放量得到结果的绝对误差范围为 0.1~1.6g/L,误差较小,计算值接近真实值,但随着时段的推移,误差逐渐增大,分析原因可能在于应用该方法时需将地下水溶质运移过程假定为线性过程,由此产生的误差会随时段的推移累积.应用状态转移方程法时,绝对误差范围为0~5.2g/L,第一时段和第三时段误差值较大,第二时段误差接近 0,在构建地下水系统状态转移方程时需忽略一阶以上的高阶微量,因此存在截断误差.比较两种耦合方法计算结果不难看出,响应矩阵法耦合模拟-优化模型要优于状态转移方程法.
同时,由表3和图4可看出利用遗传算法多次计算所得结果都较为相近,且绝对误差值在可接受范围内,说明遗传算法求解地下水污染源模拟-优化模型时精度高、稳定性好,具有良好的性能.
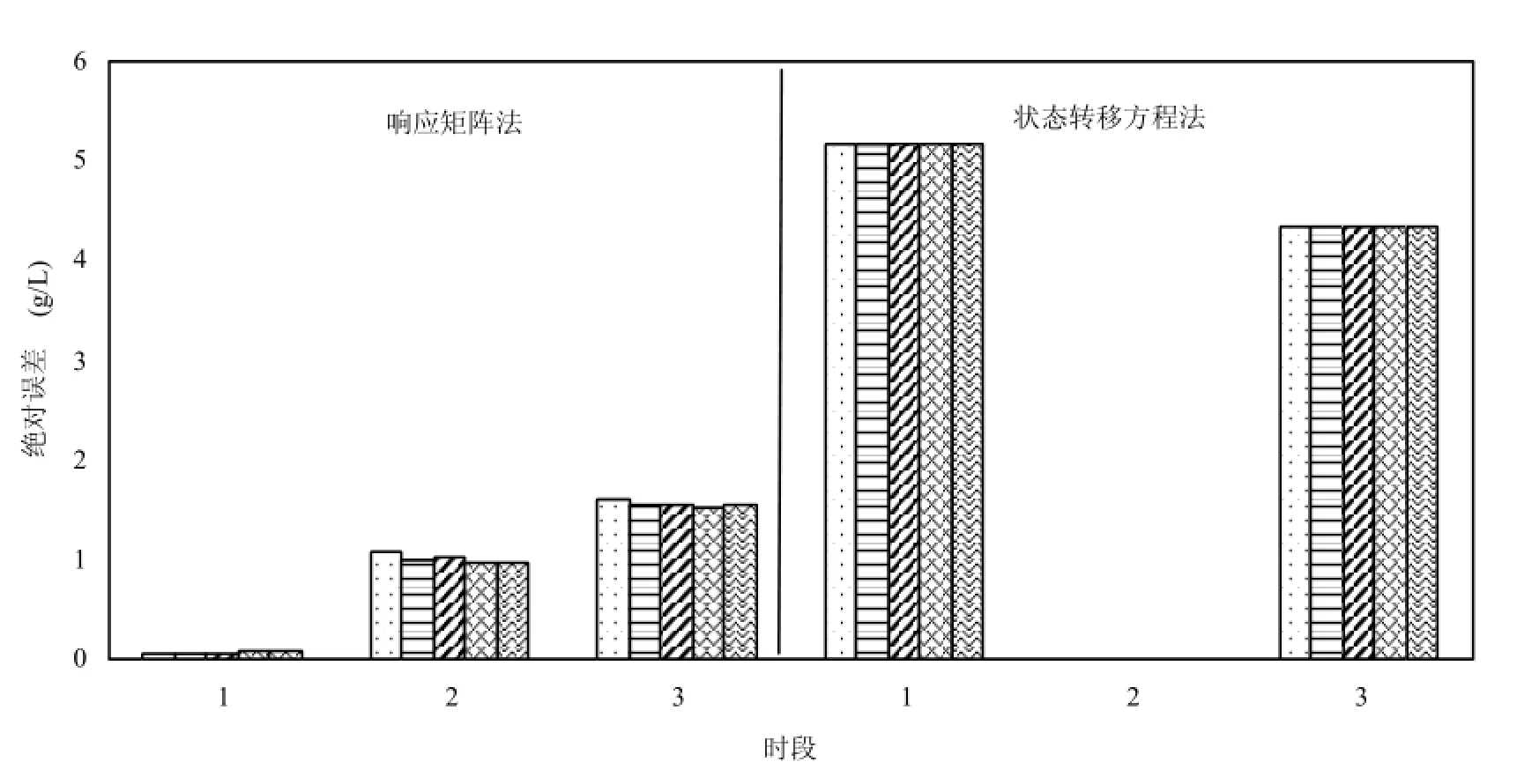
图4 应用不同耦合方法计算结果的绝对误差Fig.4 Absolute error histogram of the results calculated by different coupling methods

4 结论
4.1本文将采用不同耦合方法的模拟-优化模型应用到同一个假想例子,假想例子为一个二维均质各向同性的矩形承压含水层,在已知污染源数量、位置和释放历史的前提下,利用有限的浓度监测数据反演污染源各时段的释放量.研究表明基于遗传算法的模拟-优化模型能够用来求解污染源释放量,并且计算结果误差较小,是一种较为有效的地下水污染源识别方法.
4.2采用响应矩阵法耦合模拟模型与优化模型可以显著地减少变量和约束条件的个数,提高模型的计算效率,但其要求边界条件具备线性齐次条件,实际应用中难以满足,还需采取一定的补救措施;状态转移方程法物理意义明确,但在构建地下水系统状态转移方程时存在截断误差,所求结果差于响应矩阵法.
[1] 罗兰.我国地下水污染现状与防治对策研究 [J]. 中国地质大学学报(社会科学版), 2008,8(2):72-75.
[2] 王红旗,秦成,陈美阳.地下水水源地污染防治优先性研究 [J].中国环境科学, 2011,31(5):876-880.
[3] Atmadja J, Bagtzoglou A C. Pollution source identification in heterogeneous porous media [J]. Water Resources Research, 2001,37(8):2113-2125 .
[4] Skaggs T H, Kabala Z J. Recovering the release history of a groundwater contaminant [J]. Water Resources Research, 1994, 30(1):71-79.
[5] 刘博,肖长来,梁秀娟,等.吉林市城区浅层地下水污染源识别及空间分布 [J]. 中国环境科学, 2015,35(2):457-464.
[6] Atmadja J, Bagtzoglou A C. State of the Art Report on Mathematical Methods for Groundwater Pollution Source Identification [J]. Environmental Forensics, 2001,(2):205-214.
[7] Hazart A, Giovannelli J, Dubost S, et al. Inverse transport problem of estimating point-like source using a Bayesian parametric method with MCMC [J]. Signal Processing, 2014,96:346-361.
[8] 江思珉,张亚力,周念清,等.基于污染羽形态对比的地下水污染源识别研究 [J]. 水利学报, 2014,45(6):735-741.
[9] 瞿明凯,李卫东,张传荣,等.基于受体模型和地统计学相结合的土壤镉污染源解析 [J]. 中国环境科学, 2013,33(5):854-860.
[10] Gorelick S M, Evans B, Ramson I. Identifying sources of groundwater pollution: an optimization approach [J]. Water Resources Research, 1983,19(3):779-790.
[11] Mahar P S, Datta B. Optimal monitoring network and groundwater pollution source identification [J]. Journal of Water Resources Planning and Management, 1997,123(4):199-207.
[12] McKinney D C, Lin M D. Genetic algorithm solution of groundwater management models [J]. Water Resources Research, 1994,6(30):1897-1906.
[13] Aral M M, Guan J, Maslia M L. Identification of contaminant source location and release history in aquifers [J]. Journal of Hydrological Engineering, 2001,6(3):225-234.
[14] Singh R M, Datta B. Identification of groundwater pollution sources using GA-based linked simulation optimization model [J]. Journal of Hydrological Engineering, 2006,11(2):101-109.
[15] Ayvaz M T. A linked simulation-optimization model for solving the unknown groundwater pollution source identification problems [J]. Journal of Contaminant Hydrology, 2010,117:46-59.
[16] 江思珉,蔡奕,王敏,等.基于和声搜索算法的地下水污染源与未知含水层参数的同步反演研究 [J]. 水利学报, 2012, 43(12):1470-1477.
[17] 江思珉,张亚力,蔡奕,等.单纯形模拟退火算法反演地下水污染源强度 [J]. 同济大学学报(自然科学版), 2013,41(2):253-257.
[18] 江思珉,王佩,施小清,等.地下水污染源反演的 Hooke-Jeeves吸引扩散粒子群混合算法 [J]. 吉林大学学报(地球科学版), 2012,42(6):1866-1872.
[19] 范小平,李功胜.确定地下水污染强度的一种改进的遗传算法[J]. 计算物理, 2007,24(2):187-191.
[20] 薛禹群,吴吉春.地下水动力学 [M]. 北京:地质出版社, 2010:47-51.
[21] 郭科.最优化方法及其应用 [M]. 北京:高等教育出版社, 2007:3-5.
[22] 卢文喜.地下水系统的模拟预测和优化管理 [M]. 北京:科学出版社, 1999:104-109.
[23] 李敏强,寇纪淞,林丹,等.遗传算法基本理论与应用 [M]. 北京:科学出版社, 2002:7.
[24] 雷英杰,张善文,李续武,等.MATLAB遗传算法工具箱及应用[M]. 西安:西安电子科技大学出版社, 2005:1-10.
[25] 易立新,徐鹤.GMS应用基础与实例 [M]. 北京:化学工业出版社, 2009:47-119.
致谢:文章的英文部分由吉林大学环境与资源学院杨青春教授修改与指导,在此表示感谢.
Simulation-optimization model of identification of groundwater pollution sources based on two coupling method.
XIAO Chuan-ning1,2, LU Wen-xi1,2*, AN Yong-kai1,2, GU Wen-long1,2, ZHAO Ying1,2(1.Key Laboratory of Groundwater Resources and Environment, Ministry of Education, Jilin University, Changchun 130021, China;2.College of Environment and Resources, Jilin University, Changchun 130021, China).
China Environmental Science, 2015,35(8):2393~2399
This paper presents a study of groundwater pollution sources identification using simulation-optimization model based on the Genetic Algorithm. The simulation-optimization model was coupled with response matrix approach and state transition equation method, which was solved with genetic algorithm, and the minimum error between the simulated results and the observed data was obtained after multiple iteration. The performance of the model was evaluated with a hypothetical example. The simulated results indicate that the absolute error of response matrix approach and state transition equation method was 0.1~1.6g/L and was 0~5.2g/L, respectively. It proves that the simulation-optimization model based on the genetic algorithm for identifying single groundwater pollution source was feasible. Also, response matrix approach was superior to the state transition equation method.
groundwater;pollution source identification;simulation-optimization;response matrix approach;state transition equation method;genetic algorithm
X523
A
1000-6923(2015)08-2393-07
2014-11-11
中国地调局项目(1212011140027,12120114027401)
* 责任作者, 教授, luwenxi@jlu.edu.cn
肖传宁(1990-),男,山东济宁人,主要从事地下水污染源识别方面的研究.
猜你喜欢
房地产导刊(2021年12期)2021-12-31
环境保护与循环经济(2021年7期)2021-11-02
汽车工程(2021年12期)2021-03-08
环境影响评价(2020年2期)2020-12-02
电子制作(2019年16期)2019-09-27
电子制作(2019年24期)2019-02-23
中国资源综合利用(2017年4期)2018-01-22
青海政报(2017年6期)2017-07-24
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中国惯性技术学报(2015年1期)2015-12-19
