
基于HDFS和IMPALA的碰撞比对分析
2015-10-20 09:13潘晨光
电视技术 2015年14期
王 艳,潘晨光
(公安部第一研究所,北京 100048)
实时计算是不断获取、计算和分析大流量数据,迅速洞察变化原委,自动化响应变化的数据[1]。交互式即席查询和报表查询面临整合异构数据源,统一元数据存储和大规模迭代运算模型等难点。公共安全领域积累了大量的人员、案件、轨迹和社会行为等数据信息。实时分析和计算这些持续大流量的公共安全数据是巨大的挑战。
Hadoop上的Hive追求高吞吐量,导致时间延迟较高。Hive可支持百亿级的数据量,但很难应对秒级响应的需求,只适合做分钟级别的离线分析系统而不支持实时分析系统[2-3]。Hive的缺陷导致其不能满足业务高速发展所带来的实时和高维的数据处理需求,但公共安全的情报分析需实时获取当前正在发生的案件和嫌疑人的状况。
如何基于公共安全数据构建大数据查询系统实现关系查询和实时跟踪,是公共安全大数据迫切需要解决的问题。本文提出了HDFS和Impala相结合的架构,搭建了存储海量数据的分布式文件系统,实现了交互式数据查询和分析,提供即席查询的功能,便于快速获取数据和决策支持。基于HDFS和Impala构建大数据查询系统可提供统一的元数据访问和管理接口,支持SQL查询优化、列存储、查询谓词下推、高效压缩技术、预先计算、高效索引和并行查询等,可按照时间、空间和业务进行分层和元数据管理,方便构建兼容应用。
为解决公共安全大数据的实时查询问题,本文首次并创新性地将Impala计算引擎应用于公共安全大数据的智能分析,整合非结构化、半结构化和结构化的数据存储和分析,设计了数据存储组织结构和数据分层策略,尽量隐藏查询对原始文件访问的需求,即席查询共享存储、统一计算,可扩展性强,实现了以人查案和以案找人的业务功能,取得了较好的实战效果。
1 MapReduce上Hive的缺陷
分布式文件系统适合处理非结构化数据,而已存储在数据库中的数据是结构化的,结构化数据转换为非结构化数据会丢失很多重要价值的信息[4]。MapReduce是基于磁盘进行数据处理,每次计算要经历从磁盘读取数据、计算数据和保存数据等阶段,导致运行过程复杂,迭代任务时效低,不适合对延时要求高的交互式分析或复杂迭代的数据分析任务。
Hive是面向行存储的数据库,不存储和计算数据,底层执行依赖MapReduce引擎,不能解决已有关系数据库中数据的迁移和查询操作[5]。运行机制是将结构化数据文件映射为数据库表,提供类SQL查询,并将SQL语句转换为MapReduce任务运行[6]。查询先转化为映射-归约作业,再提交给集群以批量方式执行。MapReduce调度只适合批量和周期长的任务,类似查询结构化数据的业务效率低,Hive的运行机制导致查询速度慢[7]。Hive的缺陷原理如表1所示。
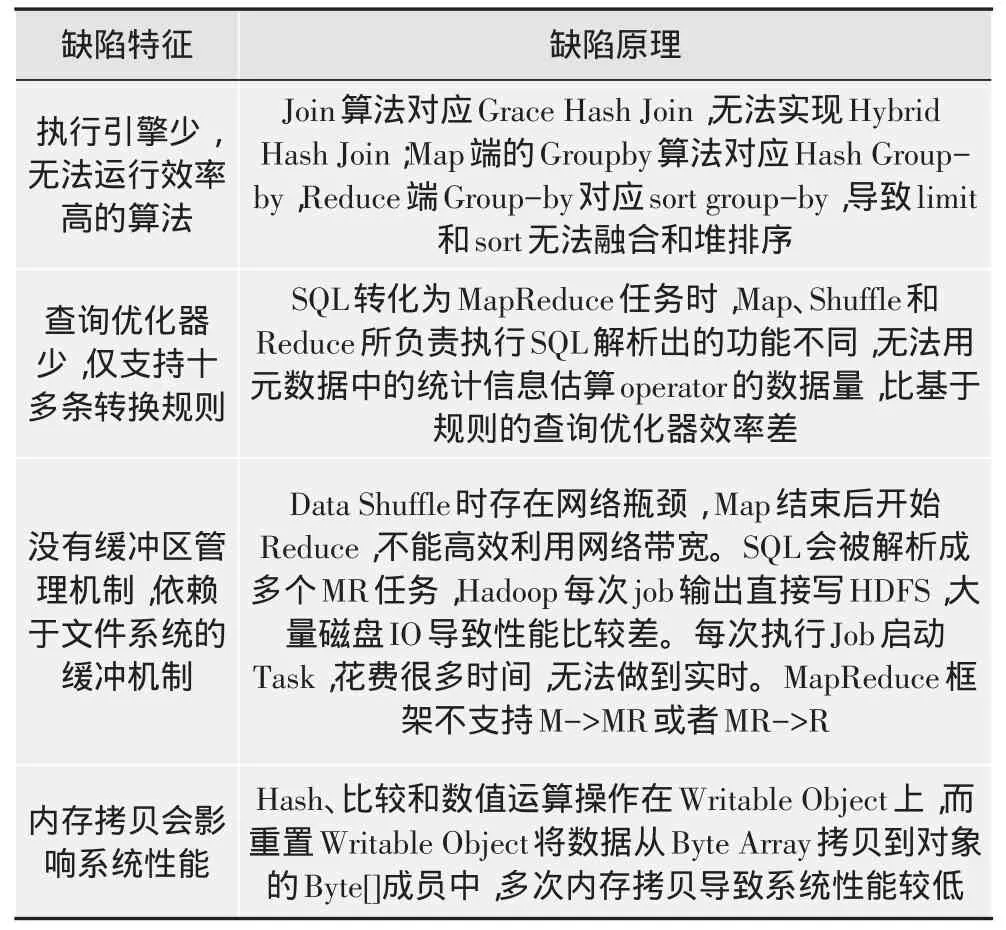
表1 Hive的缺陷原理表
2 Impala的原理与架构
Impala是Cloudera参考Google Dremel思想实现交互SQL大数据查询,支持Parquet列存储格式,结构嵌套记录转换成列存储[8],高效状态机实现记录正向和反向转换,减少了查询数据量;支持多层树,查询树根节点接收查询,底层节点获取数据执行查询,使任务在数千个节点上并行执行和聚合;采用推送方式传输数据,分散了网络压力,提高了任务的执行效率。
Impala主要分为Impalad、StateStore和CLI等模块[9]。Impalad与DataNode在相同节点上运行,接收查询请求Coordinator。通过JNI调用Java前端解释SQL查询语句,生成查询计划树,通过调度器把执行计划分发给数据对应的Impalad运行,读写数据并行执行查询。StateStore跟踪集群中Impalad运行状态和位置信息,创建多线程处理注册订阅和心跳检测。进程离线后,进入recovery模式反复注册;进程重新加入集群后,自动恢复正常,更新缓存数据。CLI提供查询的命令行、Hue、JDBC和ODBC使用接口。查询的执行过程如图1所示。
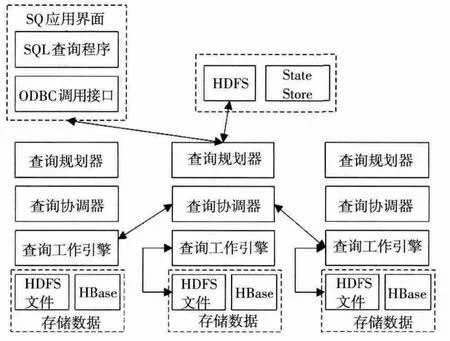
图1 Impala的运行架构
1)客户端SQL查询通过ODBC发送到集群内任一Impalad。查询规划器采用Jflex和CUP解析SQL语句,解析查询请求为多个执行片段发送至查询协调器,查询节点单独原子执行相关操作。
2)查询规划器初始化Impalad执行任务,RDBMS存储表的元数据信息。进程StateStored调度查询请求,分发metadata数据,提供对外的Thrift服务,存储集群中进程的资源。
3)查询协调器执行聚合函数Limit n,截取Top-n,完成局部Aggregation回传结果至客户端。查询工作引擎通过流式交换输出,协调客户端提交查询请求,分配任务至其他Impalad并收集执行结果。Impalad执行分配的任务,操作本地HDFS和HBase的数据完成查询请求。
3 HDFS和Impala结合的数据分析
3.1 HDFS和Im pala结合的优势
由于Hive本身的缺陷,本文提出了采用Impala直接为存储在HDFS中的数据提供快速、交互式SQL查询的技术方案。HDFS和Impala结合的原理是把HDFS接入Impala后端作为存储引擎,直接从HDFS获取查询所需数据,请求被解析成片段调度至相应节点上执行,某些源数据或中间数据存放在HDFS中[10]。Impala把多个执行计划分配到内存中并行执行,高效I/O调度和优化的LLVM本地代码完成初始化,中间结果在进程间进行流式回传。HDFS和Impala架构比MapReduce和Hive架构的优势分析如表2所示。

表2 HDFS和Impala结合架构的优势分析表
HDFS和Impala架构的优势体现在:1)Impala直接在HDFS中存取数据,不必把中间过程写入磁盘,节省了大量I/O开销;2)减小了MapReduce的启动作业开销,Impala直接从对应服务进程进行作业调度,提高了执行效率;3)去掉MapReduce不太适合做SQL查询的范式,Impala支持实时分析的MPP查询引擎,降低了不必要的shuffle和sort等开销;4)采用LLVM统一编译代码,减少了通用编译的开销;5)支持数据的I/O调度机制,尽量将数据分布到所在节点内存中并行完成,省去了大量I/O网络开销。
3.2 HDFS和Im pala相结合的实现方法
Impala由JAVA前端与C++后端组成,接收客户端连接进行查询的Coordinator,通过JNI接口调用JAVA前端对查询SQL分析生成执行计划树。JAVA前端的执行计划树以Thrift数据格式回传Impala C++后端。其原子操作由计划片段表示,查询语句可由多个片段组成,片段0表示执行树的根,汇聚结果回传查询,执行树的叶子结点由Scan操作,可分布式并行执行。
数据存储信息通过Libhdfs与HDFS进行交互,通过HDFSGetHosts方式获取文件数据块所在节点位置信息,Simplescheduler由Round-robin算法实现,通过调度器Exec对生成执行计划树分配给对应的后端执行器执行。调用GetNext方法获取计算结果,执行insert语句将计算结果通过Libhdfs写回HDFS。Shuffle Join有稳定性能,适用大型复杂关联操作。其流程框图如图2所示。

图2 Impala查询请求的流程控制
Broadcast Join将右表作小表分发在Join,Shuffle Join是分发后左表驱动右表进行Join。嵌套类型数据Parquet列存储格式及扩展SQL查询语义通过基于LLVM的Just-In-Time运行时代码生成,查询以最大CPU速度执行,能快速扩展系统功能。Parquet格式实现 Dictionary Encoding、Bit Packing、Delta Encoding、Run-Length Encoding等压缩技术,过滤无关数据减少I/O。Run Length Encoding在列压缩中减少3个数量级存储,提升2~3个数量级的内存应用,Dictionary Encoding对磁盘空间的占用约为之前的1/20,对内存的占用约为之前的1/5。
4 改进的CURE碰撞比对算法
碰撞比对算法的应用是对嫌疑人多种信息进行分析处理,查找与嫌疑人或案件的相关信息、活动轨迹和网络行为等。为满足碰撞比对的需要,将数据从HDFS同步到Impala的表中。Impala上运行CURE聚类算法设计是将改进的CURE聚类算法对训练集进行聚类,对簇进行标识基于矩形的建模建立相关性模型,将待检测数据与该模型进行碰撞比对。若符合该模型则是与嫌疑人相关的数据,否则判断为与嫌疑人不相关的数据。
CURE算法是自下而上的层次聚类,用定量特征点来表示簇,合并相邻簇直到簇的数目在特定阈值范围内。由于簇的个数无法提前预设,需对多个簇进行强制合并或把簇强行分割,影响聚类效果。为提高聚类的质量,本文提出将聚合条件设定为相邻簇间距离达到设定阈值时聚类形成,簇间相似度决定簇的个数。Impala处理大数据量时,CURE聚类算法采用随机取样数据技术,分区聚类后将局部聚类的中间结果进行分析得到最后结果。先局部后整体的方法应用到分布式Impala系统中,CURE聚类算法可高效处理海量数据。Impala上改进CURE算法描述如下:
Dis(X1,X2)表示X1和X2间的距离,其距离度量是欧几里得距离、曼哈顿距离或闵可夫距离等,本文采用欧几里得距离。X1和X2是簇时,定义Dis(X1,X2)为相邻簇中特征点间的距离,即Di(s X1,X2)=min{Di(s ri,r)j,ri∈Q(X1),rj∈Q(X2)}。
步骤1,输入<key,value>,从源数据集中抽取随机样本S,向量di创建簇Ci,实现S={C1,C2,…,Cn},Q(Ci),Q(Ci)={di}。
步骤2,将样本S分割,若|S|<2,终止。
步骤3,将S聚类,找出簇集S中特征点相邻距离的簇Cu、Cv,Dis(Ci,Cj)=min{Dis(Ci,Cj),Ci∈S,Cj∈S,i≠j}。若Dis(Cu、Cv)>w,终止。
步骤4,随机取样剔除孤立点,合并簇Cu和Cv,Cnew←Cu⋃Cv,tmpSet←φ ,计算 Cnew的 中 心 :
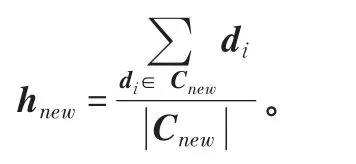
步骤5,对局部簇聚类,合并距离近的簇,从Cnew中选择di,若 tmpSet=φ ,Dis(di,tmpSet)=max{dist(dj,tmpSet),dj∈ Cnew},Dis( dj,tmpSet )=min{Dis( di,dk) ,dk∈ tmpSet},将 di并入tmpSet,tmpSet←tmpSet⋃{di}。
步骤6,簇标签标记数据,若|tmpSet|<min{|Cnew|,λ},执行步骤5。
步骤 7,输出<key,value>收缩代表点:Q(Cnew)←{dk+a*(hnew-dk∈ tmpSet),dk},更 新 簇 集 S ← SCu-Cv+Cnew,执行步骤2。KD数存放数据点,小顶堆存放簇,将簇按照与其最近邻簇间距离升序排序。
Hadoop平台下使用Hive类SQL语句实现不同粒度的聚合,类SQL语句会转化为Map和Reduce任务去执行,在某粒度上聚合实际数据时会造成的较大开销,而Hive无法一次性实现多粒度融合。为提高在不同粒度的查询响应时间,基于Impala的改进CURE聚类算法将不同粒度上的实时数据一次性聚合后存储到Impala中,可识别任意形状的簇,不断凝聚或分裂簇,对非球形簇的识别度较高。改进CURE聚类算法对孤立点敏感度低。在簇识别的过程中,若簇增长缓慢或异常的小,可作为异常点来剔除,降低了孤立点敏感度。
5 实验与系统实现
碰撞比对系统通过界面拖拽可实现数据的任意碰撞或根据自定义规则进行碰撞,支持两两数据源碰撞和多数据源碰撞,方便实现以人找案和以案找人的功能。碰撞比对系统支持单点碰撞比对和分布式碰撞比对。省厅里某些数据在本地数据源里没有碰撞出来,可分步到各地市数据源进行碰撞,将结果分别返回并且合并汇总再统一展示。碰撞效率高,比传统的架构要快数10倍,同时支持数据源上传和碰撞结果下载。该应用准确并极速地实现单类多源、多类多源数据间的碰撞比对,比传统基于Oracle数据库的碰撞比对性能提高上百倍,大大提高了破案效率。其系统的界面实现如图3所示。
6 结束语
由于Hadoop和Hive处理数据存在不足,不适合对延时要求高的交互式分析、复杂迭代的数据处理和实时分析系统。为适应公共安全领域实时查询的应用需求,本文创新性提出将Impala框架应用于公共安全领域数据的实时查询分析中,研制了在Impala和HDFS上运行的改进CURE碰撞比对算法,为存储在HDFS的数据提供快速、交互式的ANSI-92 SQL所有子集的SQL查询,实现了异构数据源的统一查询,其并发客户端处理的速度上超越了Hive。Impala不使用缓慢的Hive和MapReduce批处理,通过与商用并行关系数据库中类似分布式查询引擎,直接从HDFS中用SELECT、Join和统计函数查询数据降低了延迟。该系统的实现对公安构建大规模的数据分析查询系统具有借鉴意义,可提供技术参考。
[1]MELNIK S,GUBAREV A,LONG Jingjing,et al.Dremel:innteractive analysis of Web-scale datasets[J].Proceedings of the VLDB Endowment,2010,3(1):330-339.
[2] CDH4里的Impala安装使用文档[EB/OL].[2015-01-03].http://download.csdn.net/detail/lostage2/4911752.
[3] ENGLE C,LUPHER A,XIN R,et al.Shark:fast data analysis using coarse-grained distributed memory[EB/OL].[2015-02-03].http://libra.msra.cn/Publication/56916420.
[5]D'ORAZIO L,BIMONTE S.Multidimensional arrays for warehousing data on clouds[C]//Proc.the Data Management in Grid and Peer-to-Peer Systems.Berlin,Heidelberg:Spring-Verlag,2010:26-37.
[6]OLSTON C,REED B,SRIVASTAVA U,et al.Pig latin:A notso-foreign language for data processing[EB/OL].[2015-02-03].http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.124.5496.
[7] DEBRABANT J,PAVLO A,TU S,et al.Anti-Caching:a new approach to database management system architecture[EB/OL].[2015-02-03].http://www.dajudeng.com/d20120810089e6ef5158fb 770bf68a5518.htm l.
[8] YOU J G,XI J Q,ZHANG P J,et al.A parallel algorithm for closed cube computation[J].Computer and Information Science,2008(8):103-115.
[9]HAN H,LEE Y C,CHOI S,et al.Cloud-aware processing of MapReduce-based OLAP applications[EB/OL].[2015-02-03].http://www.researchgate.net/publication/262242831_Cloud-aware_proces sing_of_MapReduce-based_OLAP_applications.
[10]LICHTENWALTER R N,LUSSIER JT,CHAWLA N V.New perspectives and methods in link prediction[EB/OL].[2015-02-03].http://videolectures.net/kdd2010_lichtenwalter_npml/.
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
计算机教育(2020年5期)2020-07-24
江苏安全生产(2020年4期)2020-05-30
福建基础教育研究(2020年3期)2020-05-28
计算机与生活(2018年3期)2018-03-12
中国公共安全(2017年7期)2017-10-13
中国科技期刊研究(2017年2期)2017-05-14
山东工业技术(2016年15期)2016-12-01
浙江大学学报(工学版)(2015年2期)2015-05-30
