
Apriori法在急诊内科病历数据中的应用
2015-10-25 03:53张婷婷汪峰坤
新乡学院学报 2015年9期
张婷婷,汪峰坤,葛 静
(1.安徽机电职业技术学院信息工程系,安徽芜湖241000;2.安徽交通职业技术学院管理工程系,安徽合肥230051)
Apriori法在急诊内科病历数据中的应用
张婷婷1,汪峰坤1,葛静2
(1.安徽机电职业技术学院信息工程系,安徽芜湖241000;2.安徽交通职业技术学院管理工程系,安徽合肥230051)
提出通过建立疾病字符库的字符串比对算法来解决早期数据录入不规范的问题。通过设置Apriori算法的最小关联度和置信度,对急诊内科病例数据进行数据采集、预处理和关联挖掘,揭示各类急性发作疾病潜在的关联规则。研究结果可为急诊医生提供决策支持,为治疗争取时间。
字符串比对;Apriori算法;急诊内科
急诊内科承担着医院多种急危重症首诊首接抢救任务。因为在接诊的病人中,有相当一部分患者的病情凶猛、意识模糊,且病史不清、发病时间不详,所以在第一时间对突发疾病做出正确诊断,并进行有效抢救非常困难,尤其是一些病因复杂的疾病,确诊难度更大[1]。探讨急诊内科患者病因之间的潜在关联,可为医生做出快速诊断提供决策帮助,争取抢救治疗的时间。
针对早期病历数据没有采用统一的录入规范,同一种疾病存在多种记录形式的特点,笔者提出一种疾病字符库的疾病名称字符串比对算法,并采用典型的关联规则Apriori算法,对某三甲医院急诊内科2009—2013年15 316条历史病历数据进行挖掘分析,以揭示各类急性发作疾病的潜在关联规则。
1 关联规则Apriori法
关联规则是美国IBM Almaden Research Center的Rakesh Agrawal等人于1993年提出的KDD(Knowledge Discover in Database)研究中的一个重要课题[2],是数据挖掘中一种重要的方法,它能从大量数据中发现其中的关联[3]。我们利用最典型的案例,即购物篮分析,把病人的疾病看成是放入购物篮中的商品,并从中挖掘出各疾病之间的潜在关联。
关联规则中最经典的是Agrawal等人于1994年提出的一种布尔型数据的关联规则挖掘算法—Apriori算法[4]。该算法的核心是寻找出所有的频繁项集,并在此基础上确定强关联规则[5]。算法可分为连接和剪枝两部分,伪代码如图1所示。

图1 算法伪代码
2 数据采集
实际应用中,数据挖掘算法结论的正确性受多方面因素的制约,如:是否存在噪声数据干扰,数据是否有缺失,数据是否一致,待挖掘数据的结构是否合理等[3,6-7]。
急诊内科的历史数据相当一部分来源于医生手写病历,包括病人的基本信息(年龄、性别和体重等)和诊断结果等。这就要求系统对多个数据源进行统一采集,并存放在统一存储位置,如统一的Excel表中。为了适应Apriori算法,需要确定数据结构,并对待挖掘数据进行统一处理,具体办法包含以下3点[2-3]。
(1)相同属性名称的识别。不同医生在手写病历中对同一属性可能采用不同的表示方法,比如,PName和Name都表示同一属性:病人姓名,对这样的数据在采集时需合并,并统一标识。
(2)去冗余问题。当某些属性可以由其他属性推导得到时,这样的属性就可以作为冗余属性不予采集。比如,住院天数可以由入院日期和出院日期计算出来,可视做冗余数据。
(3)数据值的转换。由于不同数据源的计数方法和编码可能不同,相同数据值可能存在不同的表现形式,需要统一转化处理。如:身高数据在一病历中可能以厘米计量,而在另一病历数据中就可能以米计量。这样的数据在采集时要转化成统一的计量单位。
病历数据采集结构如图2所示。

图2 病历数据采集结构图
3 数据预处理
在使用Apriori算法进行数据挖掘之前,关键的一点是必须对数据进行预处理,即去除住院号、X线号、CT号和家庭住址等无关属性,对保留的有效属性进行预处理[3]。
(1)分类型数据的取值是有限个特定数据,因此处理较为简单,只需用几个特定的整数分别替代不同的分类值即可。例如:可以分配0~N个整数分别代表N+ 1个医生;在“是否危重”属性中,0表示不危重,1表示危重;在“治疗效果”属性中,0表示好转,1表示治愈,2表示死亡,3表示未愈,4表示转院;在“性别”属性中,0表示女性,1表示男性。各属性可用“缩写+数字”的形式加以区分。
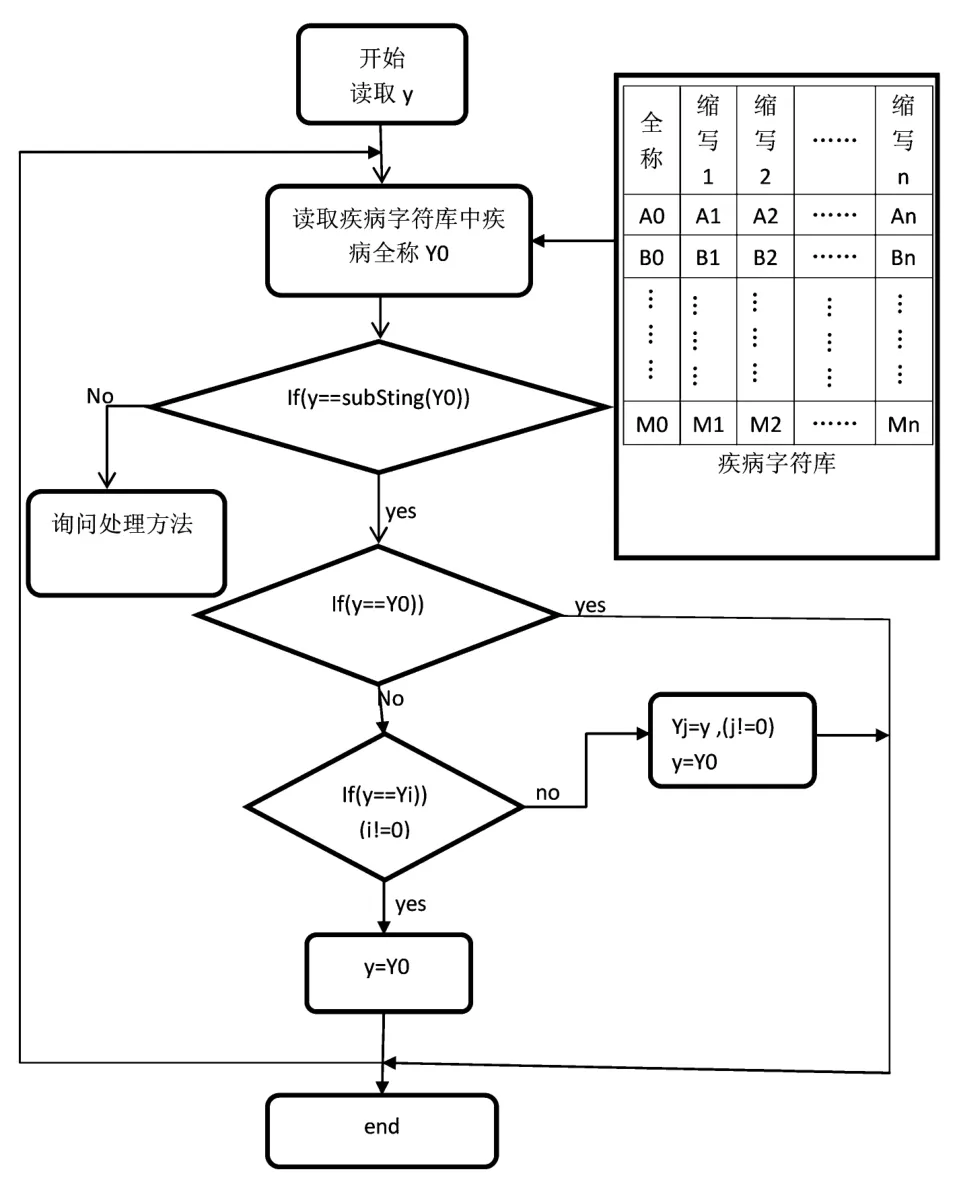
图3 疾病名称字符串比对算法
(2)对连续型数据进行离散化处理,将其映射为一组保留原有次序的整数区域。需要注意的是,医疗数据离散化应该遵循一定的行业规则,比如:根据联合国卫生组织的划分标准,可以将年龄划分为[0,6]、[7,17]、[18,40]、[41,65]和[66,MAX],这样挖掘出的规则才具有实际的价值。
对于图2中入院诊断和出院诊断属性,因为历史病历数据没有采用统一的录入规范,所以根据不同医生的习惯,对于同一种疾病可能会有多种记录方法。例如,对“支气管扩张”这种疾病,有的医生可能录入为全称“支气管扩张”,有的医生则可能录入为“支扩”;对于“上呼吸道感染”这种疾病,有的医生录入为全称“上呼吸道感染”,有的医生则可能录入为“上感”。为提高数据挖掘结果的准确性,必须对此类数据进行处理。因为大部分疾病的简称都是疾病全称的一部分,比如“支扩”为“支气管扩张”的子字符串,“上感”为“上呼吸道感染”的子字符串,所以,文中提出建立疾病字符库,即预先存储常见的疾病全称Y0和简称Yi(i!=0),再通过字符串比对将病历采集表中的疾病名称依次替换为疾病全称。疾病字符库和字符串比对算法流程图见图3。
具体算法如下:
(1)读取病例数据采集表(以下简称采集表)中的诊断疾病名称y,并与疾病字符库(以下简称字符库)中的疾病全称Y0依次比对;
(2)若y不是Y0的子字符串,则说明y是字符库中不存在的疾病,这时请求管理员做出处理,管理员可以根据情况决定是否将y添加到字符库中;
(3)若y等于Y0,则y就是疾病全称,不作处理;
(4)若y等于Yi(i!=0),说明y是Y0的简称,并且已经存在于字符库中,则用全称Y0替换采集表中的简称y;
(5)若y等于Yi(i!=0),说明y是Y0的简称,但不在字符库中,则将y添加到字符库中,并且用全称Y0替换采集表中的简称y;
(6)如此循环,直至遍历完采集表中所有的y。
4 数据挖掘
采用Java对Apriori算法进行编程实现,由频繁L项集算出频繁L+1项集。
因为本文主要关注急诊内科各疾病之间的潜在关联,所以只保留子集为与相关内科疾病的频繁项集,合并后得{脑梗塞后遗症(316),高血压病(3328),冠状动脉粥样硬化性心脏病(396),肺炎(376),低钾血症(524),颈椎病(672),高脂血症(244),冠心病(2844),慢性胆囊炎(396),急性支气管炎(848),脑梗塞(1060),糖尿病(1040),慢性胃炎(420),心律失常(660),眩晕综合征(352),房颤(184),支气管炎(452),心功能不全(348),急性胃炎(300),支气管肺炎(404),前列腺增生(192),尿路感染(284),急性上呼吸道感染(152),肺部感染(268),眩晕综合征(444),慢性阻塞性肺疾病急性加重(168),高血压病+糖尿病(236),高血压病+颈椎病(152),高血压病+冠心病(1020),高血压病+脑梗塞(356),高血压病+心律失常(188),糖尿病+冠心病(232),冠心病+脑梗塞(300),冠心病+心律失常(284),冠心病+心功能不全(204),高血压病+冠心病+脑梗塞(152)}。
设最小支持度为20%,最小置信度为30%,用Java对Apriori算法进行编程实现,得到七条有效规则。置信度保留两位小数,按降序排序。
(1)心功能不全→冠心病(心功能不全患者同时患有冠心病),可信度:0.59;
(2)冠心病、脑梗塞→高血压病,可信度:0.51;
(3)心率失常→冠心病,可信度:0.43;
(4)高血压病,脑梗塞→冠心病,可信度:0.43;
(6)脑梗塞→高血压病,可信度:0.34;
(5)冠心病→高血压病,可信度:0.36;
(7)高血压病→冠心病,可信度:0.31。
5 结果分析
从实验结果可以得到以下结论:
(1)急诊内科收治病人所患疾病中包括高血压病、糖尿病、冠心病、脑梗塞和心律失常等,这些疾病发病凶猛,致死致残率高,因此医院可以考虑将抢救资源向这些疾病倾斜,为危重病人争取抢救时间;
(2)规则(1)表示,如果该病人心功能不全,应高度怀疑为冠心病,需做相应检查来确诊并治疗;
(3)规则(2)表示,如果该病人同时患有冠心病和脑梗塞,那么在抢救治疗时应该考虑其患高血压病的可能性;
(4)规则(3)表示,如果该病人患有心率失常,那么他有可能也患有冠心病,应该做相关检查;
(5)规则(4)表示,如果该病人同时患有高血压病和脑梗塞,那么在抢救时应考虑其患有冠心病的可能性;
(6)规则(5)表示,如果该病人患有冠心病,那么应该确诊其是否患有高血压病;
(7)规则(6)表示,如果该病人患有脑梗塞,那么应该确诊其是否患有高血压病;
(8)规则(7)表示,如果该病人患有高血压病,那么要求其做冠心病的相关检查是有必要的。
6 结束语
本文详细描述了典型的关联规则Apriori算法对某三甲医院急诊内科2009—2013年15 316条历史病历数据进行挖掘分析的过程。首先阐述了Apriori算法的原理;然后针对急诊内科住院病历的数据特点,对原始数据进行了数据采集,具体包括相同属性名称的识别、去冗余问题和数据值转换,得到病历数据采集结构图;接着对数据进行预处理,针对早期病历数据没有采用统一的录入规范,同一种疾病存在多种记录形式的特点,提出一种建立疾病字符库的疾病名称字符串比对算法;最后用Java对Apriori算法进行编程实现,得到了一些有价值的结论,为急诊内科医生快速判断病情、争取抢救时间提供了决策支持。
[1]刘启举,李雪梅.258例急诊内科昏迷病人临床分析[J].当代医学,2012,18(12):11-12.
[2]AGRAWAL R,IMIELINSKI T,SWANI A.Mining Association Rules Between Setsof Items in Large Databases[C]//Proc ACM SIGM0D Conference on Management of Data,Washington D C,May 26,1993:207-216.
[3]王越,桂袁义.基于关联分析的数据挖掘在体检CRM中的应用[J].重庆理工大学学报(自然科学版),2010(3):36-42.
[4]安颖.基于Apriori算法的兴趣集加权关联规则挖掘[J].北京联合大学学报(自然科学版),2008(4):44-47.
[5]苏莉.哈尔滨市高校体育教师脂肪肝与体质健康关系的研究[J].哈尔滨体育学院学报,2011(5):126-128.
[6]颜雪松,蔡之华.一种基于Apriori的高效关联规则挖掘算法的研究[J].计算机工程与应用,2002(10):209-211.
[7]李绪成,王保保.挖掘关联规则中Apriori算法的一种改进[J].计算机工程,2002(7):104-105.
【责任编辑梅欣丽】
The Application of Apriori Algorithm to Emergency Internal Case Data
ZHANG Tingting1,WANG Fengkun1,GE Jing2
(1.Department of Computer Science,Anhui Technical College of Mechanical and Electrical Engineering,Wuhu 241000,China;2.Department of Management Engineering,Anhui Communication Vocational and Technical College,Hefei 230051,China)
In order to solve the problem of data nonstandard input,this paper put forward a string matching method based on disease character library.Through setting the minimum correlation degree and minimum confidence level,the method collected,pretreated and mined the emergency internal case data,then revealed the potential association rules for all kinds of acute diseases.Those provide decision support for diagnosis and give aid to curative time.
string matching;Apriori algorithm;emergency internal medicine
TP311
A
2095-7726(2015)09-0026-03
2015-05-10
安徽高校省级自然科学基金重点项目(KJ2014A038)
张婷婷(1983-),女,安徽芜湖人,讲师,硕士,研究方向:计算机软件和计算机网络。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
数学小灵通·3-4年级(2020年9期)2020-10-27
中国卫生(2016年10期)2016-11-13
中国民族医药杂志(2016年5期)2016-05-09
中国继续医学教育(2015年6期)2016-01-07
中国继续医学教育(2015年1期)2016-01-06
中国卫生(2015年10期)2015-11-10
中国当代医药(2015年9期)2015-03-01
中国中医药现代远程教育(2014年11期)2014-08-08
中医研究(2014年4期)2014-03-11
