
分布式实时计算引擎
——Storm研究
2015-11-05 02:24王润华毋建军侯佳路
中国科技信息 2015年6期
王润华 毋建军 侯佳路
北京政法职业学院信息技术系
分布式实时计算引擎
——Storm研究
王润华 毋建军 侯佳路
北京政法职业学院信息技术系
王润华(1978)女,硕士,讲师,研究方向为移动互联网方向。

本文介绍了一种分布式实时计算引擎——Storm,它具有简单、高性能、高可靠、可伸缩等特点,并且支持广泛的编程语言。本文不仅介绍了Storm的架构和特性,还结合实例演示了使用Strom进行实时计算的具体过程。
过去十年在数据处理(data processing)领域发生了一场革命,MapReduce,Hadoop和其他相关技术的出现,已经使数据处理系统的存储能力、计算能力、伸缩能力达到了之前无法想象的高度。但是遗憾的是这些技术是“批处理系统”而不是实时系统,实时性也不是这些系统所关心的,然而业界对实时处理海量数据的需求却越来越强烈,Storm的出现填补了数据处理生态系统(data processing ecosystem)在实时方面的空白。
Storm概述
对于实时处理,典型的传统方式是手工建立一个由queues和workers组成的网络。workers处理来自queue的messages,更新数据库(或其他操作),然后生成新的messages发送给其他的queues做进一步处理。这种方式有以下几个问题。
(1)繁琐:需要花大量的时间去配置向哪里发送messages、部署workers、部署intermediate queues,真正涉及实时处理逻辑代码所占的比例很小。
(2)脆弱:缺乏完善的故障容错(f aul ttolerance)机制,在程序运行过程中需要确保每一个worker和queue都是正常运行的。
(3)伸缩性差:系统运行过程中当message的吞吐量超过了单台物理机的承载能力时,就需要将数据分布到更多的机器上去处理,这需要手工重新配置workers以便可以将数据分发新增的机器上,这样做不仅麻烦还极易出错。
虽然queues和workers方式在容错和伸缩方面有很大的缺陷,但是基于消息处理(message processing)的模型却非常适合作为实时计算的基础模型,Strom也使用基于消息处理(message processing)的基础模型。
Storm具有如下几个主要特点:
极其广泛的应用场景;
良好的伸缩性;
无消息丢失保证;
稳定与可维护性好;
良好的容错性;
支持广泛的编程语言;
Storm架构
Storm集群
从表面上看Storm集群与Hadoop集群非常类似,Hadoop集群上运行MapReduce任务而Storm集群运行被称为Topology的任务,但MapReduce与Topology有着非常大的差别——最关键的一点是MapReduce任务最终会结束而Topology一直处理消息,直到被主动结束。
Storm集群架构如图1所示,Storm集群由一个主节点(master node)和多个工作节点(worker node)组成。主节点上运行着一个被称为Nimbus的守护进程,它负责在集群中部署代码、为每个工作节点分派任务并监控任务的执行状态。每个工作节点上也运行着一个被称为Supervisor的守护进程,Supervisor监听分派给该工作节点的任务,并根据需要启动或关闭工作进程(worker processes),每个工作进程负责执行一个Topology的子集;每个Topology由分布在多个工作节点上的多个工作进程共同执行。
Nimbus与Supervisors之间通过一个Zookeeper集群来进行协调。Nimbus和Supervisor被设计为无状态和快速失败(fail-fast)的,所有的状态信息都保存在Zookeeper集群或本地磁盘中,这意味着Nimbus和Supervisor失败退出或被结束后重新启动将不会丢失任何信息,这样的设计使得Storm非常的稳定。
Topology
前面提到Storm任务被称为Topology,一个Topology实际上是一个由计算逻辑组成的“图”,“图”中每个节点包含计算逻辑,节点之间的连接指示数据如何在节点间传播。Storm使用Thrift作为通信中间件,所以可以使用任何Thrift支持的语言来编写Topology。
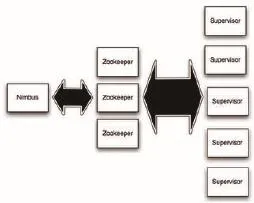
图1 Storm集群架构
Stream
Stream是Storm的核心抽象概念。在Storm中消息被称为元组(tuple),Stream就是一个数量无限的元组序列,Storm提供了一组原语可以以分布和可靠的方式将一个Stream传播到另一个Stream,其中Spout和Bolt就其中两个最基本的原语,用户程序通过实现Spout和Bolt的接口来定制自己的应用逻辑。Spout是Stream的源,Bolt是一个或多个Stream的消费者,做一些处理,也可能生成新的Stream。一个复杂的应用往往需要多个步骤也就是多个Bolt,Bolt可以做非常多的事情,例如:运行函数、元组过滤、Stream聚合、Stream join、与数据库对话等。
由Spout和Bolt组成的网络(图)既是Topology,而图中的边则是Stream,Stream指示元组如何在Spout和Bolt间传播。Topology中的每个节点(Spout或Bolt)都是并行执行的,用户可以指定每个节点的并行度,Storm便会产生相应数量的子任务在集群上执行。
前面提到Topology会一直处理消息,直到被主动结束。Storm会重新分配失败的任务,此外Strom保证没有消息会丢失,即使硬件出现故障。
数据模型
Strom使用消息即元组(tuple)作为数据模型,一个元组可以有多个字段(field),字段的类型可以是字符串或字节数组,通过一定的扩展用户也可以使用自定义的字段类型。
Stream grouping
Stream grouping告诉Topology如何在节点间传输元组。前面提到Spout和Bolt都是并行执行的,如图3所示,如果Bolt A需要向Bolt B发送元组,那么元组如何在Bolt A的子任务和Bolt B的子任务间传播呢?传播策略的不同在有些情况下可能会极大的影响计算结果,Stream grouping就是用来解决这个问题的,我们将在Strom应用实例部分进行详细的说明。
圆圈代表Spout或Bolt的并行子任务
Storm应用实例
这里通过一个对单词计数的Topol o gy(WordCountTopology)来演示Storm的具体应用方法。代码如图4所示,该代码摘自Storm自身的示例程序,并去掉了对说明用法无关的细节。
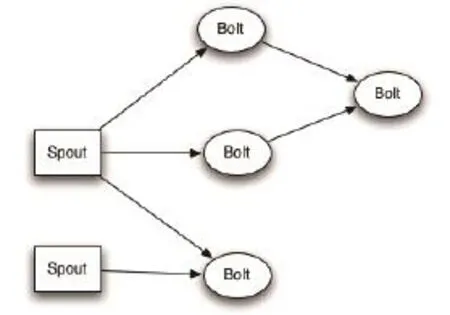
图2 Topology是由Spouts和Bolts组成的图
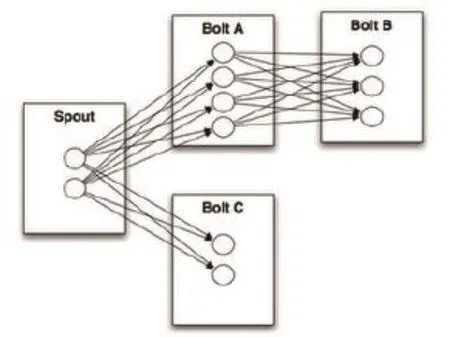
图3 Topology的执行过程

图4 WordCountTopology代码
要实现一个Topology最主要的工作就是提供具体的Spout、Bolt (用户的Spout和Bolt需要实现特定接口或继承自已有的基类)和他们之间Stream grouping。WordCountTopology有一个Spout和两个Bolt,Soput引用了已有的一个类RandomSentenceSpout来产生随机的句子,Bolt SplitSentence将句子拆分成单词,Bolt WordCount对单词进行统计。RandomSentenceSpout与SplitSentence之间的Stream grouping类型为Shuffle grouping,即子任务间任意传播元组,而SplitSentence与WordCount间的Stream grouping类型为Fields grouping,即相同的单词都传输给同一个子任务,这对单词统计的正确性是非常重要的。
结语
Storm的出现填补了数据处理生态系统(d ata processing ecosystem)在实时方面的空白,同时Storm具有高可靠、伸缩性好、编程模型简单、支持广泛的编程语言等特点,极大的简化了分布式实时系统的开发。
10.3969/j.issn.1001-8972.2015.06.027
猜你喜欢
电脑报(2021年14期)2021-06-28
计算机与生活(2020年8期)2020-08-12
软件学报(2019年11期)2019-12-11
军事运筹与系统工程(2019年4期)2019-09-11
计算机与生活(2019年5期)2019-07-18
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
电子制作(2018年11期)2018-08-04
