
基于语料库的《诗经·关雎》两种英译本的翻译风格
2015-11-27 04:26蔡永贵
肇庆学院学报 2015年4期
蔡永贵
(嘉应学院 外国语学院,广东 梅州 514015)
一、引言
《诗经》是我国最古老的诗歌总集,共收录诗歌305篇,故又称之为“诗三百”。《国风·关雎》是我国现存最早的一首爱情诗,作为《诗经》的开篇之作,它以真挚动人的感情、大胆的表露和明快的节奏而广为流传并引发不少翻译名家的关注,各种译本层出不穷。自19 世纪末,理雅各(James Legge)开始《诗经》翻译以来,《关雎》已经有了12 种译本[1]。然而,由于不同译者所处的文化背景和时代背景不同、对原文的理解与英文表达水平的差异,不同的译本之间也存在着巨大的差异。
在众多译本中,理雅各的非韵体译本和许渊冲的韵体译本颇具代表性。然而,尚未有学者对他们的翻译风格差异进行研究。因此,本研究拟使用语料库检索和分析工具Wordsmith 对《诗经·关雎》两个译文作量化对比分析,考察分析两个译本翻译风格的差异。
二、基于语料库的译者风格研究
译者风格有广义和狭义之分。广义的译者风格是指译者在语言运用方面所表现出来的个性特征以及包括译本选择、翻译策略应用、序跋和译注等在内的非语言特征。而狭义译者风格是指译者语言应用或语言表达偏好,或在译本中反复出现的语言表达方式[2]。
上世纪90 年代中期,曼切斯特大学莫娜·贝克(Mona Baker)教授带领其研究团队建立了世界上第一个翻译英语语料库,并利用该语料库开始了翻译共性、译者风格和翻译规范等方面的研究,从而拉开了语料库语言学与翻译研究相结合的序幕。
基于语料库的译文文体风格研究是一种全新的翻译文体风格研究手段和方法。Mona Baker 曾借助语料库从类符/形符比、平均句长和叙述结构三方面描述和分析英国翻译家Peter Bush 和Peter Clark两位译者文体风格的差异[3]。英国曼切斯特大学翻译与跨文化中心Maeve Olohan 博士同样利用翻译英语语料库考察了英国翻译家Peter Bush 与Dorothy s.Blair 翻译作品中助动词和系动词省略式和完整式的使用差异[4]。
国内方面,不少学者近年也开始利用语料库进行翻译风格研究。杨晓琳利用语料库检索软件从词汇和语篇层面对杜甫《兵车行》的四个英译本进行数据统计和分析,进而探讨四个译本风格上的异同[5]。肖忠华通过建立与汉语母语语料库LCMC相对应的汉语译文平衡语料库“浙天汉语译文语料库”,采用对应平衡语料库与平行语料库相结合的实证办法系统考察了汉语译文的区别性特征[6]。
基于语料库的译者风格研究应用避免了传统译者风格研究中所采用的内省式和诱导式研究方法所导致的主观性和随意性,它将研究建立在语料分析和数据统计的基础上,使得研究结果更为客观、可信。
三、语料的描述及研究方法
在国际汉学界被誉为“汉学三大巨擘”之一的理雅各(James Legge,1815-1897)是第一个系统研究、翻译中国古代经典的外国学者。《诗经》第一部英文全译本便是由他完成的。理雅各汉语功底扎实,又有江苏学者王韬相助,同时,他在翻译过程中进行了大量考据以期减少差错,故其译文较为忠实。他的译诗基本上是分行的散文,读起来流畅自然。他的《诗经》译本附有长达200页的序言和详尽的注释,使西方读者得以了解中国古典文化。该译本在欧洲广为流传,被视为标准译本。
北大教授许渊冲是中国诗译英法第一人。他从事文学翻译六十余年,译作包括《诗经》《楚辞》《西厢记》《包利法夫人》和《红与黑》等中外名著。许渊冲不仅是一位杰出的翻译大师,还是一位重要的翻译理论家。他从多年的中国古诗英译和法译实践中总结出的诗歌翻译“三美论”(意美、音美、形美)对诗歌翻译实践有着很重要的指导作用。
本研究选用的语料为《关雎》的理雅各译本(以下简称理译本)和许渊冲译本(以下简称许译本),其中理译本选自1871 年出版的理雅各无韵体全译本The She King(Classic of Poetry),而许译本选自1994 年出版的许渊冲韵体全译本An Unexpurgated Translation of Book of Songs.本研究使用的语料库检索和分析软件为WordSmith 4.0。为了对译本做词汇密度和词性方面的研究,本研究利用英国兰卡斯特大学网站提供的免费CLAWS词性赋码服务对两个译本进行词性赋码。本文从类符形符比、词汇密度、平均词长、高频词“the”和“of”的使用和平均句长五个方面对比理译和许译《诗经·关雎》,分析两个译本各自的风格特征。
四、研究过程及分析
(一)类符形符比
类符形符比(Type/Token Ratio,简称TTR)是指特定文本中类符(type)和形符(token)之间的比值。所谓类符(type)指的是特定文本中不同词语的数量;而形符(token)则是指特定文本的总词数。类符形符比可以反映文本用词的丰富程度。Mona Baker 曾借助此比值来描述所研究译者的文体和风格。TTR比值高,说明文本用词丰富,词汇变化大,可读性强;比值低,意味着文本词汇量小,词汇变化不大,可读性较弱。利用TTR 对翻译文本进行比较时,比值的高低说明译者受原文影响程度的大小。TTR 比值的差异可以在一定程度上反映不同译家的用词习惯和翻译风格。表1是两个译文和原文的类符形符比统计情况:

表1 两个译文和原文的类符形符比
由表1 可以看出,许译《关雎》的形符数远远小于理译本,但类符形符比却远远高于理译本。这说明许译本承载信息量更多,词汇变化多样,译本可读性更高。例如,原文出现四次“窈窕淑女”,许渊冲 分 别 译 成“maiden fair”(两 次),“fiancée”和“bride”,而理雅各的译文并没有变化。理译本在翻译篇幅上大于许译本,而词汇的变化多样性却低于许译本。究其原因,Legge 在翻译过程中更加注重对原文的精确理解与诠释,他对原文中的难词采取了显化(explication)的翻译策略,即译者在翻译过程中倾向把原文内容阐述得更加具体、明了[7],从而使得译文读者能够更好地理解原文。
例如:
原文:关关雎鸠,在河之洲。窈窕淑女,君子好逑。
理译本:
Kwan kwan go the ospreys,
On the islet in the river.
The modest,retiring,virtuous,young lady:—
For our prince a good mate she.
许译本:
By riverside a pair
Of turtledoves are wooing;
There’s a maiden fair
Whom a young man is wooing.
从以上例句可看出,在描述窈窕淑女这一形象时,理译本所费笔墨较多,形象刻画得更为丰满、具体,而许译本“maiden fair”较为抽象简洁。
(二)词汇密度
词汇密度指的是特定文本中实词与总词数之间的比值。根据胡壮麟[8]的分类,英语中的实词(lexical word 或content word)主要包括名词、动词、形容词和副词;而虚词(grammatical word 或function word)主要包括介词、连词、代词和冠词。句子的意思主要靠实词来传递,因为实词才具有完整而稳定的词汇意义。因此,词汇密度的高低可以反映出文本的信息承载量和难易程度。一般而言,词汇密度越高,说明实词在总词数中所占比例越高,信息承载量也就越大,文本的阅读难度也就越高。相反,词汇密度越低,说明文本中功能词汇所占比重大,文本阅读难度越低,更易于读者理解。本研究参照胡壮麟的词性分类方法并采用Ure[9]提出的词汇密度计算方法,即词汇密度=实词数/总词数×100%,对《关雎》理译本和许译本的实词数量进行统计,结果如表2所示:

表2 两个译本的词性及词汇密度统计
从表2 可以看出,许译本的词汇密度比理译本高出不少。这无疑印证了上文类符形符比所得出的许译本承载的信息量更大这一结论。理雅各在翻译过程中增加了较多功能词,从而降低了信息含量和阅读难度。许译本总词数只有理译本的三分之二,但实词的数量却只是稍稍低于理译本,这说明许渊冲在翻译中力求以最精简的译文传达原诗的内容。例如:
原文:求之不得,寤寐思服。优哉游哉,辗转反侧。
理译本:
He sought her and found her not,
And waking and sleeping he thought about her.
Long he thought;oh!Long and anxiously;
On his side,on his back,he turned,and back again.
许译本:
His yearning grows so strong,
He cannot fall asleep,
But tosses all night long,
So deep in love,so deep!
从上文例句可看出,许渊冲非常简洁地传达原诗的大意,几乎没有半点多于原文的信息;而理雅各则在翻译中增加了自己的理解与想象,使得诗歌画面更加生动,内容更加丰富。许译本与理译本的风格迥异,由此可见一斑。
(三)平均词长
平均词长是指特定文本中所有单词的平均长度。平均词长反映了特定文本用词的复杂程度。平均词长越长,说明该文本中的长词越多。反之,则表明该文本的长词越少。一般文本的平均词长是4 个字母左右,低于4 个则说明该文本词汇使用相对简单,远高于4 个则说明该文本词汇使用较为复杂。WordSmith 的统计数据显示,理译本的平均词长为4.19个字母,许译本的平均词长为4.12个字母。两个译本的平均词长非常接近,总体用词难度差别不大。两个译本在7个字母以上长词的数量统计如表3所示:

表3 两个译本7个字母及以上的长词数量比较
由于大多简单的英语单词是由2-6个字母构成的,上表只列出了7 个字母及以上的长词使用情况。许译本中只有8个单词是7个字母及以上的长词,长词百分比只有7.69%,远低于理译本的14.19%。从平均词长和长词百分比看,理译本的词汇阅读难度稍高于许译本。这说明许渊冲在翻译过程中采用了简略化(simplification)的翻译策略,选择使用较为简单的词汇,从而使得译文简洁流畅。
(四)高频词“the”和“of”的使用
冯庆华在对《红楼梦》的两个英译本进行词频统计时曾指出,诸如“the”“of”的词频可以反映出词组和句子结构的复杂性,若译本中“the”和“of”的词频较高,则说明该译本的语体偏正式[10]。
本研究利用Wordsmith软件统计出的两个译本中“the”与“of”的词频进行对比分析,同时比照它们在美国布朗语料库(简称BC)中的出现频数(见表4)。

表4 两个译本及BC中“the”与“of”的词频
从表4可以看出,理译本中“the”和“of”的使用频率和BC 中的出现频率相近,说明这理译本在这两个词的使用上较接近英语母语使用者的习惯,对英语本族语读者而言,理译本是流畅自然的。相比之下,许译本中“the”和“of”使用的频率较低,这说明许译本更为简单易懂。由于这两个词是偏正式语体的词语,它们的使用频率可以反映词组合句子结构的复杂性,因此可以认为,从语体的正式化程度上来说,理译本>许译本。究其原因,主要是因为许渊冲在译诗中遵守“音美、形美、意美”三原则,力求在音、形、意三方面都忠实于原诗,用词极为简洁,表1 中译本的形符数也反映出这一特点。理译本是自由体译本,由于没有押韵的限制,在用词上更为自由和详尽,用了大量“the”作修饰,力求在内容上忠实于原诗。
(五)人称代词主语的使用
英语和汉语两种语言具有十大差异,其中之一是英语重形合而汉语重意合。作为意合程度较高的古代汉语在构句上主语通常隐化,它的施动者是通过语境和逻辑关系进行推断[11]。相反,英语轻意合而重形合,常常是用明确的主语来表示施动者。因此,在进行汉英翻译时,通常需要显化人称代词作主语。本研究对两个译本中出现的人称代词主语进行了统计,结果见表5。
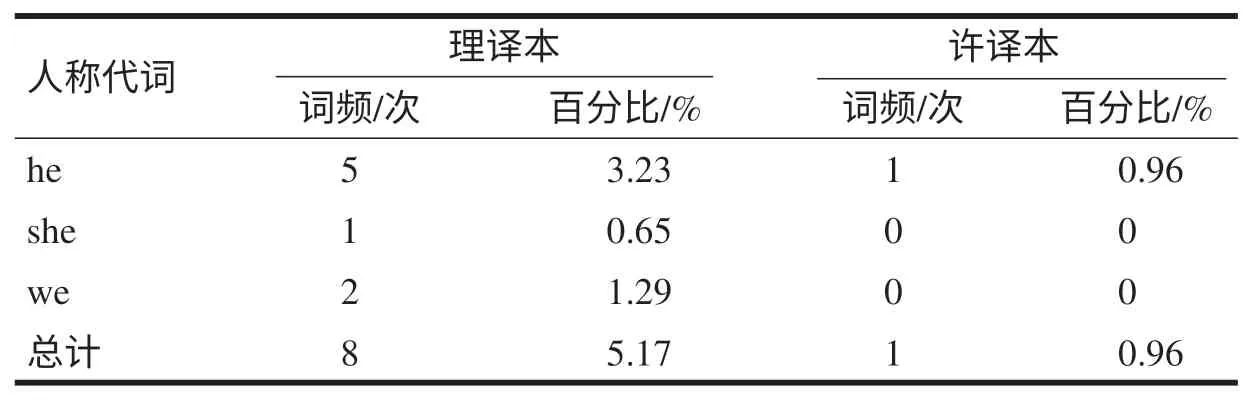
表5 两个译本人称代词主语频率统计
从上表可以看出,理译本人称代词主语使用数量和频率远高于许译本。这表明理雅各在翻译时顺应英语语法习惯,把原文隐去的主语显化出来,而许渊冲则在翻译中把汉语语法习惯“迁移”到译文中,隐去主语。例如:
原文:参差荇菜,左右采之;窈窕淑女,琴瑟友之。
理译本:
Here long,there short,is the duckweed;
On the left,on the right,we gather it,
The modest,retiring,virtuous,young lady:—
With lutes,small and large,let us give her friendly welcome.
许译本:
Now gather left and right
Cress long or short and tender!
O lute,play music light
For the fiancée so slender!
从上文例句中可看出,理雅各根据英语的语法要求将原文中隐去的主语“we”翻译出来,清晰明确地传达了原文的意思;为了译文押韵,许渊冲稍微调整了第一句译文的前后顺序且隐去主语,接着直接用“lute”作第二句译文的主语,从而使得译文更为简洁。
五、结语
通过上述对比与分析可以看出,许译本篇幅较短,但承载的信息量更大;理译本的篇幅较长,但承载的信息量却不如许译本。这主要是因为理雅各在翻译过程中采用了显化翻译策略,把原文晦涩的内容阐述得更加详细、明了,增加了大量功能词和定冠词“the”,并显化了原文隐去的人称代词主语。其译文在英语本族语读者看来会更加自然流畅。相较而言,理译本的词藻更为华丽,而许译本的用词简洁朴实。这主要是因为许渊冲在翻译过程中采用了简化策略,避免过多增加功能词、定冠词、修饰语和人称代词主语等。其韵体译文用词凝炼,句法结构简单,篇幅短小,能够很好地再现原诗的音美、形美和意美,可读性更高。
基于语料库的译者风格批评可以避免传统翻译批评的点评式和感悟式研究方法带来的主观性和随意性,这种定量和定性相结合的方法可以使相关研究更具直观性、客观性和说服力。
[1]李玉良.《诗经》名物翻译偏离及其诗学功能演变——以《关雎》英译为例[J].山东外语教学,2014(1):91-96.
[2]胡开宝.语料库翻译学概论[M].上海:上海交通大学出版社,2011:19.
[3]BAKER M.Towards a Methodology for Investigating the Style of a Literary translator[J].Target,2000(2):241-266.
[4]OLOHAN M.How Frequent are the Contractions?A study of Contracted Forms in the Translational English Corpus[J].Target,2003,15(1):59-89.
[5]杨晓林.杜甫《兵车行》四种英译本的翻译风格——基于语料库的分析探讨[J].外国语言文学,2012(4):274-279.
[6]肖忠华.英汉翻译中的汉语译文语料库研究[M].上海:上海交通大学出版社,2012.
[7]余国良.语料库语言学的研究与应用[M].成都:四川大学出版社,2008.
[8]胡壮麟.语言学教程[M].中译本.北京:北京大学出版社,2002:60.
[9]URE J N.Lexical Density and Register Differentiation[M]//Applications of Linguistics.Cambridge:Cambridge University Press,1971.
[10]冯庆华.母语文化下的译者风格——《红楼梦》霍克斯与阂福德译本研究[M].上海:上海外语教育出版社,2008:225.
[11]王力.王力选集[M].长春:东北师范大学出版社,2002:123.
猜你喜欢
疯狂英语·初中天地(2021年9期)2021-12-06
西南科技大学学报(哲学社会科学版)(2021年5期)2021-11-29
做人与处世(2021年24期)2021-03-23
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
外语学刊(2019年2期)2019-11-26
西夏研究(2019年1期)2019-03-12
西夏学(2017年1期)2017-10-24
外语教学理论与实践(2014年4期)2014-06-13
军事历史(1993年5期)1993-08-21
