
基于高性能计算平台的地理信息系统算法调度引擎的研究
2015-12-02 20:33薛晨曦陈荦李军
现代电子技术 2015年22期
薛晨曦++陈荦++李军

摘 要: 主要针对传统模式下的地理信息系统算法调度引擎无法满足用户对于地理信息系统响应速度快的要求,研究并且提出了利用高性能的计算平台进行地理信息系统中地理计算算法的调度,从而提高地理信息系统的性能。经过实验表明:新的高性能计算平台对于地理信息系统的算法调度有了一定提高,改善了地理信息系统的部分性能指标。
关键词: MapReduce; 地理信息系统; Spark; 地理计算
中图分类号: TN958?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2015)22?0044?04
0 引 言
随着地理信息系统(Geographic Information System,GIS)在大众日常生活中应用场景越来越广泛,基于地理信息系统开发的软件不仅满足了人们日常生活中对于路径规划,地标指引等需求,同时一些部门和城市建立了各具特色的综合或者专业性GIS[1]。然而传统的基于地理信息系统开发软件,由于其平台性能限制,已经逐渐难以满足用户的需要。随着用户设备的硬件配置、网络情况的不断提高,用户对于长时间等待的容忍度渐渐地降低。因此,地理信息系统不仅需要更为精确智能的算法对用户提供信息,同时也需要调度引擎更快地对地理计算算法和空间分析算法进行调度。以加快地理信息系统中的计算速度,从而减少用户等待时间,提高用户体验。
在现有的地理信息系统中,算法调度引擎多基于MPI架构[2],采用Touque/PBS进行算法调度。MPI架构存在着很多影响性能的问题,比如通信延迟比较大、负载不平衡,并且MPI本身编程模型复杂,可扩展性和容错性差。本文主要将高性能的计算平台引入地理信息系统中,实现地理信息算法和空间分析算法的快速调度,对地理信息系统算法调度引擎进行优化。
1 关键技术平台简介
谷歌在自己的论文中提出了MapReduce编程模型之后,很多从事数据处理的学者受到了巨大的启发。Apache Software Foundation就利用这个模型,在2005年开发了一个分布式架构——Hadoop。Hadoop所采用的MapReduce技术为数据的快速运算提供了重要的帮助,而Hadoop的出现意味着传统并行计算遇到了巨大的挑战。伴随着计算平台的进一步发展,一些采取其他技术的高性能计算平台也不断涌现。本文主要针对Apache的Hadoop和UC Berkeley AMP Lab研发开源的Spark,在地理信息系统算法调度引擎中的应用进行讨论。
1.1 MPI
消息传递接口(Message Passing Interface,MPI)是MPI的工作小组为了解决单个核心的计算机无法处理海量数据的计算而制定的并行计算标准[3]。其在20世纪90年代被提出之后,广泛地应用在科学计算领域:在生物学、化学、计算机科学等领域上发挥着重要的作用。MPI也是目前最为成熟的并行计算平台。目前MPI主要有MPICH以及OpenMPI两个实现。这两个实现分别定义了MPI的核心库函数的语法规则,以便用户利用C语言和C++语言编写MPI的语句。这也决定了MPI的编程主要是面向过程的编程。MPI允许同一程序在一台计算机上的多个进程一起运行,或者分布在多台计算机的多个进程上一起运行。其中每个进程相对独立,拥有各自的数据,在不发生通信的时候分别异步地处理数据。然后在需要互相访问的时候,根据MPI标准规定的通信函数进行数据的迁移、同步计算等操作。
1.2 Hadoop
Hadoop是Apache Software Foundation公司所开源的一个分布式计算的项目。Hadoop让用户在无需了解整个分布式系统底层细节的前提下,便可以通过构建分布式集群来实现系统运算速度的优化。它支持用户采用Java,Python,Ruby等语言进行编程。Hadoop除了采用谷歌公司提出的MapReduce技术来实现快速计算以外,Apache Software Foundation创新性地提出了Hadoop分布式文件系统(Hadoop Distributed File System,HDFS),对于海量数据的处理提供了便利。
HDFS[4]具有很高的容错性,可以部署在多台性能不高的硬件上。在分布式集群各个节点之间提供了很高的吞吐量用来进行数据的交换。MapReduce[5]利用“map”函数将一组杂乱无章的数值映射到一组新的数值对里面,并且指定其为“Reduce”函数,保证映射的数值正好对应数值组中。
1.3 Spark
Spark是美国UC Berkeley的AMP实验室开源的一个项目,是Apache基金会的顶级项目。Spark基于Scala语言开发,支持用户采用Java,Scala,Python等语言进行编程,具有良好的可拓展性。Spark比起传统的计算平台有了新的突破:Spark提出了一个叫做弹性分布式数据集(Resilient Distributed Datasets,RDD)的结构[6]。RDD是分布在一组节点中的只读对象集合,通过这些支持数据内存驻留的弹性数据集,Spark避免了Hadoop在MapReduce过程中将处理结果写回HDFS文件系统,减少了硬盘访问次数,从而提高了迭代算法的运行效率,很好地适应了需要多次进行迭代的算法。RDD还可以实现在数据集的一部分丢失的情况下,对整个数据集进行重建,从而使整个系统具有了强大的容错性。Spark不仅仅在数据处理上获得广泛应用,更是产生了一系列相关的生态系统[7]。比如Shark,Spark SQL,Spark Streaming,MLLib,GraphX等。这些相关组件配合Spark本身在数据库支持、实时数据处理、图计算等方面发挥了巨大作用。
2 地理信息系统算法调度引擎架构
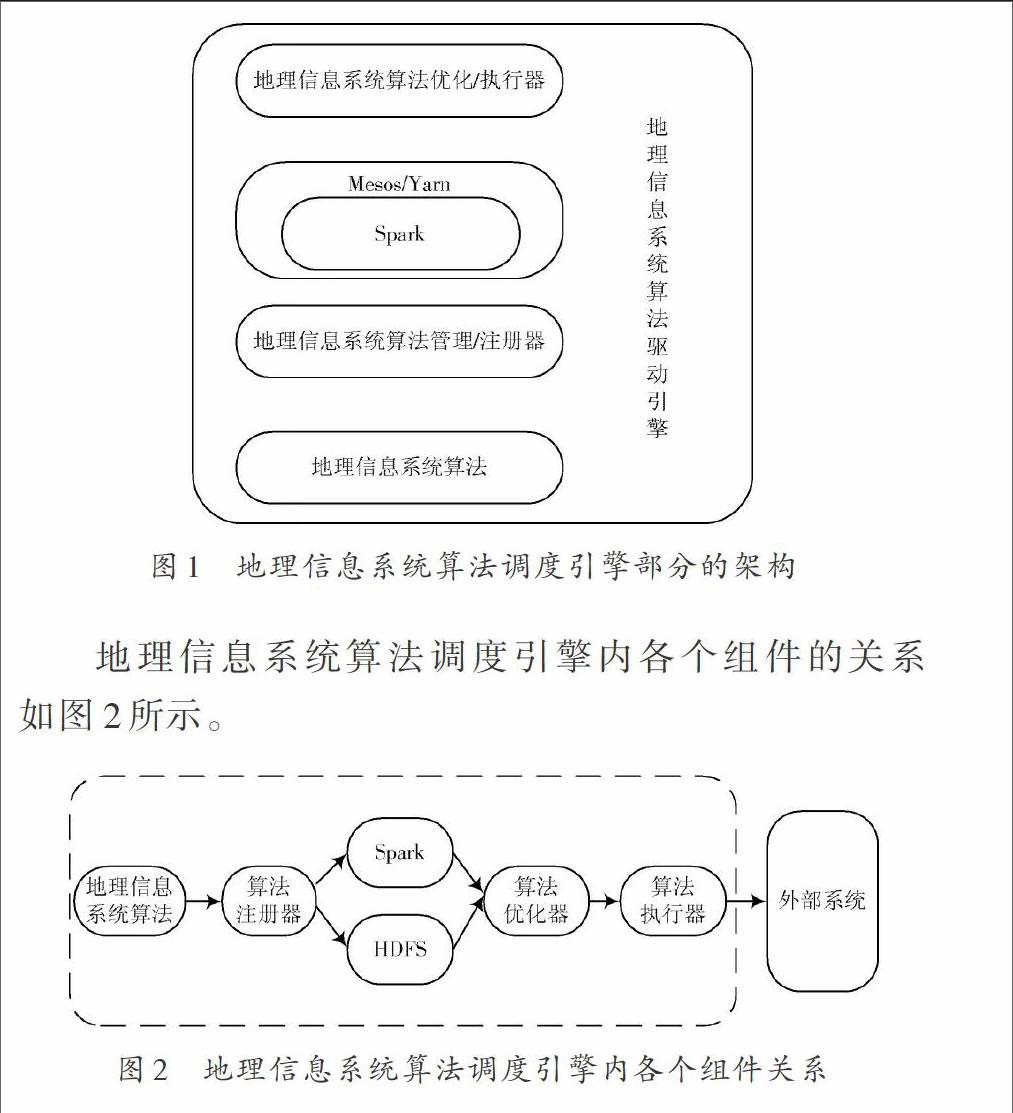
为了验证设想,将Spark配置在原有的地理信息系统[8]中。利用Spark平台,对地理信息系统中原有地理计算的算法进行调度。配置Spark平台之后的地理信息系统算法调度引擎的架构如图1所示。
地理信息系统算法调度引擎结构的原理主要是通过Spark和原有的MPI对底层经过注册的地理计算算法和空间分析算法进行调度,通过计算流程执行优化器优化,交由计算流程模型执行器进行执行,从而实现整个地理计算算法的调度。但是由于Spark没有设计自己的文件系统,因此需要借用Hadoop的HDFS作为文件系统。
3 实验与结果分析
3.1 实验环境
硬件环境:本文采用一台高性能PC和一台Mac进行程序设计和测试,以及一个包含2台服务器的集群作为主要环境进行实验。PC的主要硬件配置为Intel Core i5 CPU,4 GB内存,64位Windows 7操作系统。利用虚拟机搭建更多的Datanode环境。
软件环境:原配置部署MPI的地理信息系统,Spark,Hadoop以及所需要的环境。
实验预设条件:在相同配置环境下部署不同的算法调度平台。各平台下代码按照未做优化和最佳优化区别分开。
3.2 实验一:对MPI和Spark的性能进行比较
3.2.1 实验内容
为对比MPI和Spark在地理信息系统中作为算法调度引擎的性能,在配置好环境之后采用MPI和Spark分别进行一次同样的地理计算。在本次实验中,选取了对制定目标占地面积的计算作为任务,对比2次计算的结果。
3.2.2 实验方法
假设有一块地域,其面积可以用矩形法求定积分得出。求这块区域面积的算法如下:
BEGIN
1.double x1 //定义起始区间
2.double x2 //定义结束区间
3.double dx //定义步长
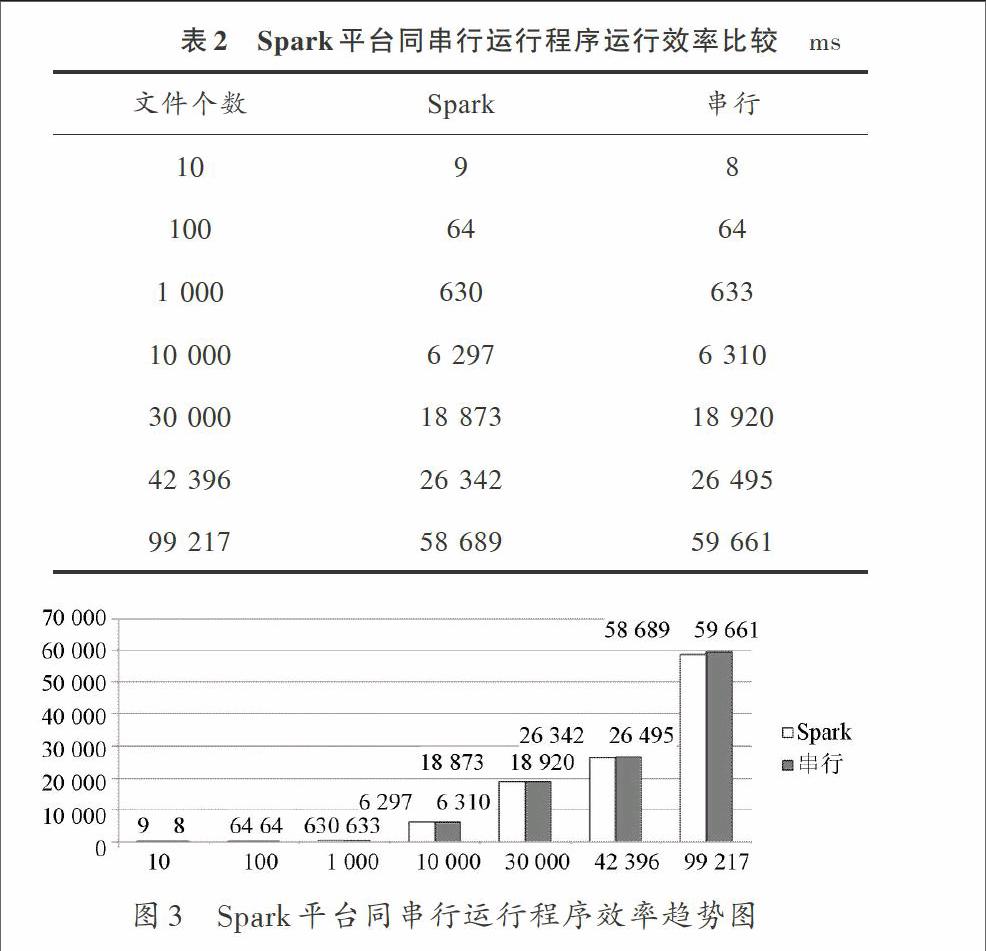
4.for(x=x1;x 5.y = y+dx*x*x //细小矩形取其左侧作为高 6.输出面积y END 将算法转化为MPI使用的C语言之后,有效代码共计12行。 将代码转化为Spark使用的Scala语言之后,有效代码仅为5行。将此代码进行循环优化之后也只有7行。 3.2.3 实验结果 不同环境平台下运行程序后的效率如表1所示。 表1 MPI和Spark运行效率比较 从表1可以看出,未经优化的Spark Scala代码比MPI C的代码简洁很多。但是运行时间消耗太多。经过优化代码之后,Spark Scala依然比MPI C代码简单一些,运行效率比未经优化的MPI C代码要快一些。并且同MPI相比,Spark编程更为简练,需要的代码更少,可以缩短开发周期,并且Spark支持动态增加节点,在系统进行变化之后无需重新编程。 3.3 实验二:对Spark和Hadoop进行比较 3.3.1 实验内容 为了对比Spark同普通串行运行程序在地理信息系统算法引擎调度中的性能,在配置好相应环境之后在Spark平台和串行运行分别做了1次相同的地理计算。在本次试验中,选择根据地图图片的哈希值求出地图图片之间的汉明距离,从而计算出地图中地点的相似程度,并且对比2次计算结果。实验数据为百度地图上长沙市地图的截图,每张大小大概为40 KB。 3.3.2 实验方法 假设有N张地图上截取的部分地区图片,为了判断其相似度,可以利用感知哈希算法[9] 将图片转化为8×8大小的图片,并且设置为灰度图片,计算各个图片的哈希值,从而求出图片的汉明距离,通过汉明距离判断图片的近似度。相关代码如下: BEGIN 1.im=im.resize(8,8) //将图片转化为8×8 2.im=Image.ANTIALIAS).convert(′L′) //将图片转化为灰度图片 3.avg=reduce(lambda x,y:x+y,im.getdata())/64 4.return reduce(lambda x,(y,z):x|(z< 5.enumerate(map(lambda i:0 if i im.getdata())), //计算图片的哈希值 6.dis=hamming(hashx,hashy) //利用图片的哈希值求汉明距离 END 3.3.3 实验结果 不同环境平台下运行程序的效率如表2所示,Spark平台同串行运行程序效率趋势图如图3所示。 从实验结果可以看出,随着地图数据量的增大,Spark与串行运行程序的效率相比,在数据量为几百KB时处于劣势;在数据量为几MB时效率相当;当数据量达到GB级别,Spark远远超出串行运行的效率。从表2也可以看出,在TB级别时Spark的效率将更加优于串行运行。 3.4 实验结果分析 通过两个实验可以看出,采用Spark的地理信息系统算法调度引擎比传统的地理信息系统算法调度引擎有着一定的优势。虽然MPI可以通过深度优化代码来减小差距,但是由于MPI本身编程复杂,在地理信息系统中优化全部地理计算算法工作量巨大,难以实现这样层次的优化。并且MPI在系统发生变化之后必须要重新配置才可以运行,在可拓展性上有着巨大的缺陷。因此可以看出Spark在地理信息系统中的应用有着良好的效果。
4 结 语
本文通过实验测试对比了Spark和MPI在地理信息系统算法调度中的性能,提出在地理信息系统的算法调度过程中应用Spark平台技术,对地理信息系统的性能有了一定的提升,同时改良了系统的复杂程度,减小了工作人员维护系统的成本。同时缩短了一定的系统响应时间,提升了用户体验。在下一步的工作中,还需要解决在更大规模集群下运行Spark,并且利用Spark实现对地图进行图像金字塔算法[10]并处理地理计算的问题。
参考文献
[1] 张广莹,张广宇,黄昊.地理信息系统在智能交通系统中的应用[J].自动化技术与应用,2013(13):30?33.
[2] 吴立新,杨宜舟,秦承志,等.面向新型硬件构架的新一代GIS基础并行算法研究[J].地理与地理信息科学,2013,29(4):1?8.
[3] 都志辉.高性能计算之并行编程技术:MPI并行程序设计[M].北京:清华大学出版社,2001.
[4] KALA K A, CHITHARANJAN K, KALA K A, et al. A review on hadoop?HDFS infrastructure extensions [J]. IEEE Conference on Information & Communication Technologies, 2013, 21(1):132?137.
[5] Anon. MapReduce [DB/OL]. [2013?03?25]. http://en.wikipedia.org/wiki/MapReduce.
[6] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault?tolerant abstraction for in?memory cluster computing [J]. USENIX Symposium on Networked Systems Design and Implementation, 2011, 70(2): 141?146.
[7] 高彦杰.Spark大数据处理技术、应用与性能优化[M].北京:机械工业出版社,2014.
[8] 林碧英,王艳萍.基于Hadoop的电力地理信息系统数据管理[J].计算机应用,2014,34(10):2806?2811.
[9] 丁凯孟,朱长青.一种用于遥感影像完整性认证的感知哈希算法[J].东南大学学报:自然科学版,2014(4):723?727.
[10] 姜代红.基于影像金字塔的GIS地图动态漫游算法[J].计算机工程与设计,2013,34(5):1711?1715.
[11] 张华伟,张洪永,蔡一兵,等.基于OCI的GIS数据库的开发与应用[J].现代电子技术,2010,33(15):190?191.
猜你喜欢
少先队活动(2021年2期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
学生天地(2020年17期)2020-08-25
数学大王·低年级(2020年3期)2020-03-12
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
商周刊(2017年22期)2017-11-09
河南电力(2015年5期)2015-06-08
