
K-均值聚类算法的MapReduce模型实现
2015-12-07 06:59王鹏王睿婕
长春理工大学学报(自然科学版) 2015年3期
王鹏,王睿婕
(长春理工大学 计算机科学技术学院,长春 130022)
随着计算机网络通信技术的迅速发展,如今已经进入了大数据时代。大体上讲,大数据(Big Data)是指在一定时间内,不能够使用常规计算机和软硬件工具对其进行感知、获取、管理、处理和服务的数据集合[1]。快速增长的大数据,在处理复杂度与存储规模上对现有的计算机体系架构提出了严峻的考验,传统的关系型数据库并行管理技术在扩展性方面遇到了巨大的障碍[2]。MapReduce编程模型则可以很好地处理这一问题,提高数据挖掘算法的执行效率。刘义等人[3]提出了MapReduce框架下R-树的k-近邻连接算法,顾荣等人[4]提出了MapReduce框架下预测复杂网络链路的实现,饶君等人[5]提出了高效可扩展语义推理引擎的MapReduce模型实现。MapReduce是Google提出的可在Hadoop分布式云集群上并行处理海量数据集的编程模型[6],具有良好的容错性与扩展性,Map和Reduce的概念,即映射与化简,是借鉴于函数式的编程语言,这也是该模型的重要思想。它将大数据“分而治之”地分解为多个小规模数据,并分布到多个集群节点中去,共同完成对大数据的处理。这样可以提高运行效率,降低每一部分的运算强度,最终达到节省时间的目的。
聚类分析是处理大数据的常用算法,常常被用于市场分析、图像分割、语音识别等科研领域,为了提高对大规模数据的聚类效率,很多并行算法相继被提出,吕奕清等人[7]提出了基于MPI的并行PSO混合K-均值聚类算法,张军伟等人[8]提出了二分K-均值聚类算法,陶冶等人[9]提出了基于消息传递接口的并行K均值算法。本文将K-均值聚类算法应用于MapReduce编程框架中,并在Hadoop分布式云计算平台上进行对大规模数据聚类实验。
1 MapReduce编程模型
MapReduce模型因其简单、高效、易写等优势,近年来被广泛运用于并行处理海量数据集,可实现于Hadoop开源分布式云计算平台之上。在Hadoop集群中,执行MapReduce任务的节点分为Job-Tracker和 TaskTracker两个角色[10],JobTracker负责分配、调节任务,TaskTracker负责执行任务,一个集群中只有一个JobTracker节点。每一个MapReduce任务会经历两个阶段:Map阶段与Reduce阶段。用户可按需定义Map函数和Reduce函数,数据文件首先被分割成多个split,以<key,value>对的形式输入至Map函数,经多个Map函数并行处理后,得到新的<key,value>对,作为中间结果,系统将包含相同Key值的<key,value>对合并后排序,形成诸如<key,list<value>>形式的中间结果,并输入到Reduce函数,最后将各个Reduce函数并行处理后形成的结果整合,得到最终结果。MapReduce计算流程图如图1所示。
2 K-均值聚类的MapReduce模型实现
2.1 K-均值聚类
K-均值算法简洁和高效的优点,使之成为最著名的划分聚类算法,并获得了广泛的应用。用户给定一个数据点集合D和需要的聚类数目K,在对样本类别不清晰的情况下,根据已有样本特征向量对样本进行类别划分,K-均值算法根据距离函数反复的将数据点划分成K类,并返回给用户划分结果[11]。
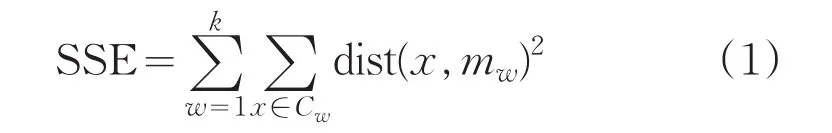
其中k表示聚类数目,Cw表示第w个聚类数目,mw是聚类Cw的聚类中心,即Cw聚类中所有数据点均值向量,dist(x,mw)表示点x与聚类中心mw的距离。
K-均值算法适用于均值能被计算的数据集
定义1 包含在某一聚类中所有数据点的均值,即为聚类中心。
定义2 设数据点的集合为D,D={x1,x2,x3,…,xn},其中 xi=(Xi1,Xi2,Xi3,...,Xir),是实数空间X⊆Rr中的向量,r表示数据空间的维度,在这里指数据点的属性数目。该算法将给定的数据点集划分为K个聚类,每个聚类有一个聚类中心,通常用聚类中心来表示这一聚类,又因为共划分为K个聚类,所以该算法的名字为K-均值聚类算法。
算法的描述如下:
(1)Algorithm K-均值(K,D)
(2)随机选得K个数据点作为聚类中心
(3)Repeat
(4)For 获取集合D中的每一个数据点X do
(5)计算数据点x到K个聚类中心的距离
(6)选择与x距离最小的聚类,将x归为此聚类
(7)End for
(8)在当前划分的情况下,计算新的聚类中心
(9)Until停止规则出现 返回结果
其中停止规则可以是以下任何一个:
a.不再有数据点被重新分配,或者有在规定很小数量内的数据点被重新分配;
b.不再有聚类中心发生变化,或者有在规定很小数量内的数据中心发生变化;
c.误差平方和(SSE)局部最小。误差平方和的计算公式如下:上。在欧式空间中,可以用下面的公式计算聚类均值:

图1 MapReduce计算流程图
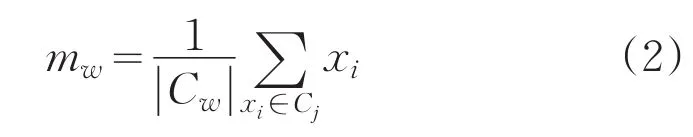
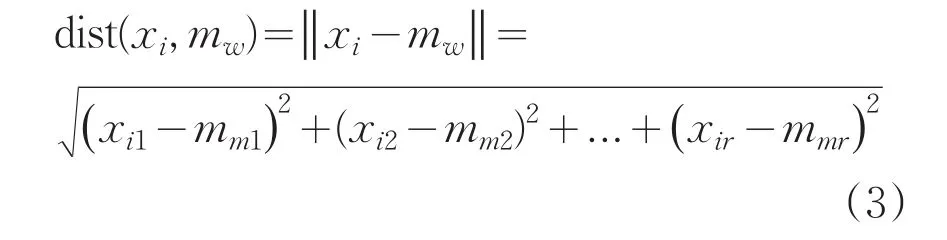
2.2 K-均值聚类的MapReduce模型实现方法
MapReduce框架并不适合所有算法,只有具备可伸缩性的算法才适用。MapReduce框架在处理大规模数据时采用分-总的方式进行并行计算,Map函数负责对数据进行“分布计算”,各个Mapper节点在工作时不能够实时的交互,只有中间结果生成完毕才能得到最终的结果,这一点也要求必须保证分到每一个Mapper节点的工作相互独立且相同,无论任务大小,工作方法都不改变。Reduce函数负责对中间结果进行处理,以得到最终结果。完整的MapReduce框架程序由Main函数、Map函数和Reduce函数组成。
K-均值算法是迭代式运行,数据运行完一遍后,判断是否满足终止条件,从而决定是否停止下一次迭代,本算法以第一种终止规则为例,即判断是否存在重新分配的点,若不存在,则停止迭代。
该算法运行过程如下:
(1)Main函数负责生成随机的聚类中心,并发送到每一个Mapper节点上。
(2)Map函数负责计算数据点与聚类中心的距离。输入<Key,Value>对应于<数据分片中的行号,数据记录>。输出<Key,Value>对应于<数据点的唯一标识,聚类中心编号+该数据点与该聚类中心的距离>。Map函数伪代码如下:
输入:数据点集;
输出:数据点与各个聚类中心的距离;
1.Key:数据文件行号 Value:数据记录
2.For each datapoint in DataPointDS
3.For i←0 To K//K为聚类数
4.设置Key:数据点 Value:i_distance(数据点,cluster[i])
//使用公式3,求出数据点到每个聚类中心的距离
5.输出(Key,Value)
(3)Reduce函数负责比较出距每个数据点最近的聚类中心。输入<Key,Value>与Map函数的输出一致。输出<Key,Value>对应于<数据点的唯一标识,与该数据点距离最近聚类中心编号>。Reduce函数伪代码如下:
输入:数据点到各个聚类中心的距离列表
输出:数据点、与该数据点距离最近的聚类中心
1.Key:数据点 Values:Iterator(1_distance_1,2_distance_2,…,K_distance_K)
2.设置MinDistance:MAX_VALUE
3.For i←0 To K
4.IF distance_i<MinDistance
5.设置MinDistance:distance_i
6.设置Value:MinDistance
7.输出(Key,Value)
(4)Main函数最后将数据点分配给各个聚类,判断是否有数据点被重新划分,若划分情况没有改变,则说明算法已完成,程序结束,返回聚类中心及分类情况,否则重新计算聚类中心,启动下一次迭代。
根据上述思路,设计出基于MapReduce框架的分布式K-均值聚类算法,运行过程流程图如图2所示。
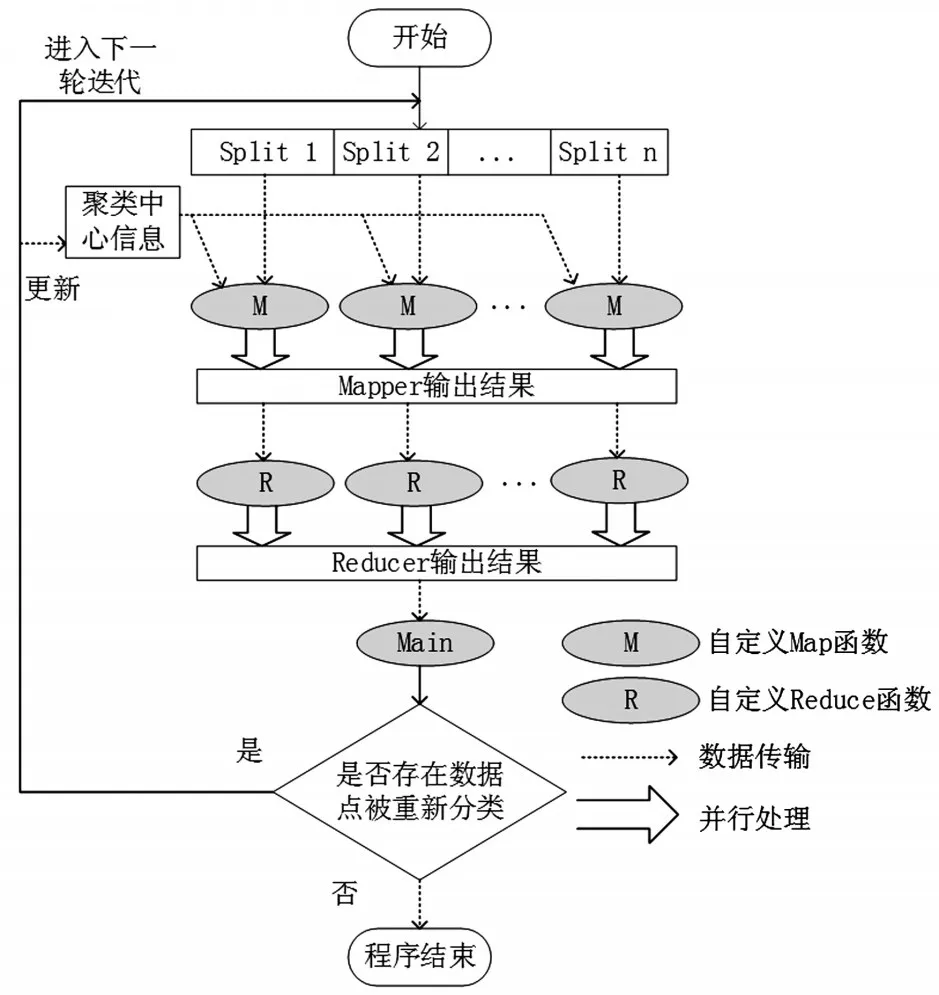
图2 K-均值算法分布式流程图
2.3 理论性能分析
MapReduce编程模型运行所在的Hadoop平台使用HDFS分布式文件系统作为数据存储方式,将大规模待聚类数据分片存储,降低了计算机存储量,K-均值聚类算法中每迭代一次都要计算出数据点与每个聚类中心的距离,对于属性数量较多的数据集,是个庞大的工作量。而在Hadoop集群中,每个节点仅需对所分配Split数据进行处理,少量数据被装入CPU进行计算,减少了CPU的工作量,提高了数据处理效率,设集群中TaskTracker工作节点数为n,忽略启动MapReduce任务所耗时间,则集群节点CPU工作量为原单机环境下CPU工作量的1/n,处理效率提高了n倍。
3 实验结果与分析
该试验运行所需的云平台由实验室5台电脑组成,每台电脑装有3台虚拟机,共15个节点。Hadoop分布式云计算集群中各点配置如下:Intel Core i7-2630CPU、3.1GHz、2048MB Memory,并采用Centos6.0操作系统、jdk-8u20-linux-i586版本的jdk、hadoop-1.1.2版本的Hadoop。其中一个作为Master节点,其余作为Slave节点。
实验样本仿真于淘宝用户购买商品类别记录,设商品种类为8种(服饰、学习用品、厨房用品等),每个样本有8个属性,每个属性值为购买某类商品的数量。分别生成106(数据大小为20M)、107(数据大小为200M)和108(数据大小为2000M)个样本构造成数据集,现将用户分为7类(初级主妇,在校学生,高级厨神等),即聚类数K设置为7。本实验主要内容为:比较K-均值聚类算法在相同硬件环境支持下单机运行时间,与在Hadoop不同数量节点集群上运行时间的长短、加速比。实验结果如图4所示。
由图3(a)可看出,单机运行时间远远少于并行运行的时间,这归因于以下两个方面:
(1)MapReduce类库将文件分为大小为64M得块,由于该数据量小于64M,所以无需分割,每个Mapper节点可运行两个Mapper任务,在此只需执行一个Mapper任务,所以直接分给一个Mapper节点运行,节点数的增加与否并不影响执行时间。
(2)单机环境下运行小规模数据集时较为灵活,而初始MapReduce任务需要耗费一定的时间,因此单机比并行所花费的时间少。由此可得出结论,处理小规模的数据不适合将其在MapReduce框架中并行计算。
由图3(b)可看出,随着数据量的增大,并行计算的优势慢慢显露出来,200M会分为4个分片,因此需要两个节点来进行并行计算。节点数在增加到2时,加速比有了明显的提高。节点数大于2后,计算节点数的增加对执行时间已无影响。
由图3(c)可以看出,当数据规模足够大时,运行时间随着集群中节点数目的增加在不断减少,这里数据大小为2000M,可分为32个分片,也就是说当节点数达到16个时,运行时间最短。
比较得出,当数据量较小时,使用云计算平台执行任务没有单机环境下执行效率高,当数据规模足够大时,并且每一个数据分片都在进行处理工作时,集群的效率最高。
由实验可得出结论,将算法改造为MapReduce模型算法后,运行结果与理论性能相符合,降低了CPU的工作量,提高了处理数据效率,降低了对大数据的聚集工作复杂度。
4 结论与展望
本文首先介绍了当前处理大数据的重要性,为了提高大规模数据处理效率,提出了解决该问题的思路,即对传统算法进行MapReduce编程框架的实现,本文将K-均值算法应用于MapReduce编程模型中,并用实验验证该方法的可行性。当数据量较小时,单机处理相对比较简单快捷,但数据量较大时,用此方法可以提高运行效率,节省运行时间。
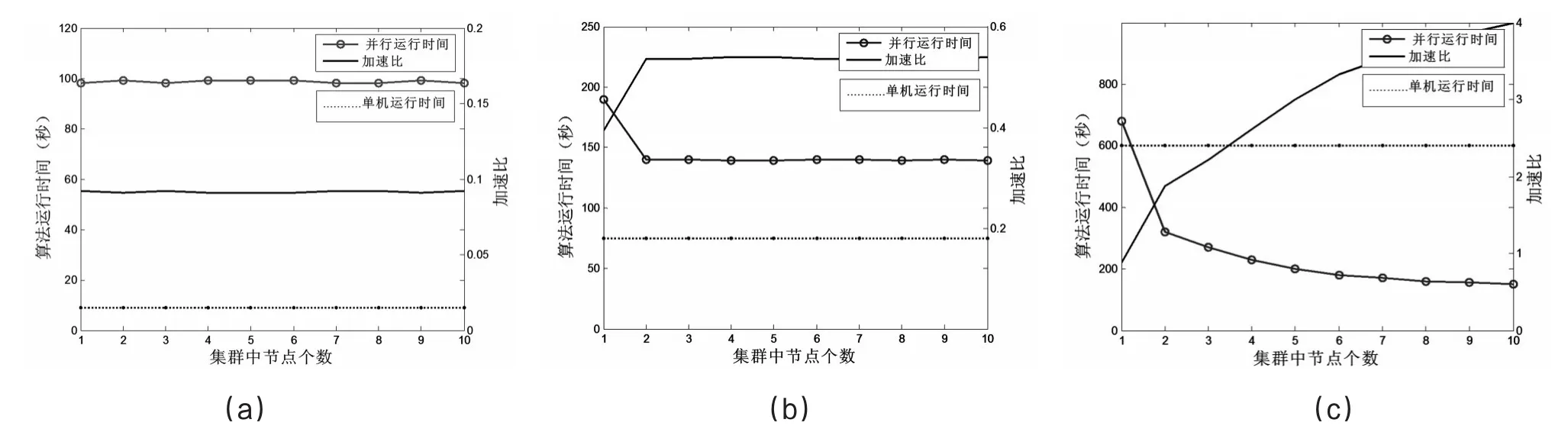
图3 K-均值聚类算法在不同数量级的样本运行时间及加速比
将算法并行运行于Hadoop集群中虽然提高的执行效率,但仍然存在一些问题需要改进。首先,K-均值算法需要反复迭代,对于大规模数据而言,每一次迭代都要花费很长时间,如何控制迭代次数需要好好研究。其次,在分布式计算中,根据特定样本,如何选取初始聚类中心也是一个很关键的问题,这将直接影响运行的效率与结果的准确性,需要在未来进一步研究,加以完善。
[1]李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):647-657.
[2]覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与 MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[3]刘义,景宁,陈荦,等.MapReduce框架下基于R-树的k-近邻连接算法[J].软件学报,2013,24(8):1836-1851.
[4]顾荣,王芳芳,袁春风,等.YARM:基于 MapReduce的高效可扩展的语义推理引擎[J].计算机学报,2014,37(24):1-13.
[5]饶君,吴斌,东昱晓.MapReduce环境下的并行复杂网络链路预测[J].软件学报,2012,23(12):3175-3186.
[6]Zhang Shufen,Yan Hongcan,Chen Xuebin.Proceedings of 2010 International Conference on Future Information Technology and Computing(FITC 2010)[C].Beijing University,Intelligent Information Technology Application Research Association,Beijing,2010.
[7]吕奕清,林锦贤.基于MPI的并行PSO混合K均值聚类算法[J].计算机应用,2011,31(2):428-431+437.
[8]张军伟,王念滨,黄少滨,等.二分K均值聚类算法优化及并行化研究[J].计算机工程,2011,37(17):23-25.
[9]陶冶,曾志勇,余建坤,等.并行k均值聚类算法的完备性证明与实现[J].计算机工程,2010,36(22):72-74.
[10]Polo J,Carrera D,Becerra Y,et al.Performance-Driven task co-scheduling for MapReduce environments[J]//Network Operationsand Management Symposium(NOMS):IEEE,2010:373-380.
[11]Bing Liu.Web数据挖掘[M].北京:清华大学出版社,2012:89-91.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
军事运筹与系统工程(2019年4期)2019-09-11
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
雷达学报(2017年6期)2017-03-26
知识就是力量(2017年2期)2017-01-21
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
