
数据仓库、数据挖掘在财政系统中的应用
2015-12-21 02:49陈化
长春工程学院学报(自然科学版) 2015年3期
数据仓库、数据挖掘在财政系统中的应用
陈化
(徐州医学院后勤管理处,江苏 徐州 221004)
主要研究现代教育技术、数据挖掘。
摘要:随着技术发展,财政系统信息化建设得到较好发展,各类业务管理系统积累了大量的数据,如何在海量数据中挖掘有用的信息资源,就显得十分迫切。简述了数据仓库、知识发现和数据挖掘的产生、发展及相关技术和应用,研究了聚类算法及聚类分析的度量标准。以聚类算法为例,讲述了针对实际应用中数据挖掘算法的应用改进。提出了应用推广阶段的改进型聚类分析算法,并对某市财政的数据集合进行了实验分析。针对财政决策系统的应用整合问题,选择以某市财政决策管理系统为例,介绍了进行数据挖掘之前要经历的步骤,最后得出了税源户聚类信息。
关键词:财政;数据仓库;数据挖掘;聚类;K-Means
doi:10.3969/j.issn.1009-8984.2015.03.030
收稿日期:2015-04-29
作者简介:陈化(1978-),男(汉),江苏徐州,助理实验师
中图分类号:TP319献标志码:A
0引言
在信息化时代,财政系统面临着如何从数以万计的历年数据中筛选信息、挖掘重要的潜藏信息,为财政管理决策者提供必要的信息支持的难题。信息网络技术的飞速发展使得数据库应用有了很大的进展。随着数据和数据库的快速增长,依靠单纯的查询检索机制和统计分析方法已很难满足现实需要。
我国的税收信息化建设已经发挥了一定的作用,取得了较大进展,但从税收工作的实际需求来看,税收信息化还有很多不足。主要体现在:1)高技术与低效益并存;2)高投入与低产出共生,税收成本不但没有减少,反而不断攀升;3)税收业务与信息化发展的不一致;4)设备闲置与紧缺现象并存;5)信息收集和数据采集准确性欠佳;6)人才不足是信息化建设的“瓶颈”[1]。
数据仓库、数据挖掘就是为迎合这种要求而产生并迅速发展起来的,它是对以前的旧数据进行传统的检索查询,找出数据彼此之间的内部联系,进行更高层次的分析。运用数据仓库和数据挖掘,我们就可以从数据库的海量数据集合中抽取整合出对我们有价值的高层次、多层次的信息。从而使大型数据仓库成为一个丰富、可靠的资源,为知识的提取服务[2-3]。
1DW和DM概述
为解决如何对已有的海量数据进行深层有效的组织和应用的问题,产生了数据仓库DW(Data Warehouse)及数据挖掘技术DM(Data Mining),也就是知识发现(Knowledge Discovery in Databases)。
1.1 数据仓库(DW)
数据仓库是一个面向主题的、集成的、相对稳定的数据集合,用于支持管理决策[4-5]。数据仓库相对于操作性数据库的优势见表1。
数据仓库概念结构包括:数据源,数据准备区,数据仓库数据库、数据集市/数据挖掘库和各种管理及应用工具。数据仓库在创建以后,首先需要从数据源中抽取所需要的数据到数据准备区,初始数据在数据准备区中经过净化处理后再加载到数据仓库数据库中,最后再根据用户需求把数据发布到数据集市/数据挖掘库中[6-7]。数据仓库结构如图1所示。
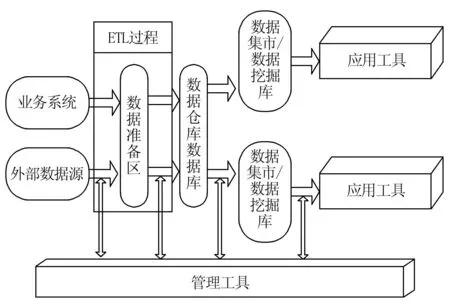
图1 数据仓库结构
1.2 数据挖掘(DM)
数据挖掘是指从数据集中提取出可信的、新颖的、有效的并能被人们理解的模式的非平凡过程[8-9]。数据挖掘的方法有如下几种:
1)回归分析(regression analysis)是寻求2种以上(含2种)变量之间相互依赖的定量关系的一种统计分析方法[10]。
2)时间序列预测[11]就是通过编制和分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年内可能达到的水平。
3)关联分析。
4)决策树分析。
2聚类算法研究
聚类分析是对样品或指标进行分类的一种多元统计分析方法。它的目标就是在相似的基础上收集数据来分类。聚类分析过程可以分为3个步骤[13]:1)数据变换;2)选择计算聚类统计量;3)选择聚类方法。
2.1 聚类分析数据变换处理
2.1.1标准化变换
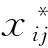
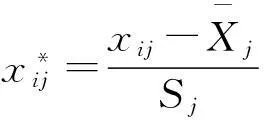
(1)
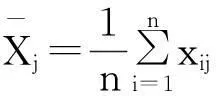
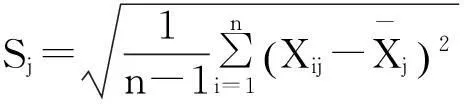
(2)
2.1.2规格化变换
规格化变换是从数据矩阵中的每列数据中找出最大值和最小值,并用最大值减去最小值得出极差。然后以每一个原始数据减去该列中的最小值,再除以极差,即得规格化数据。
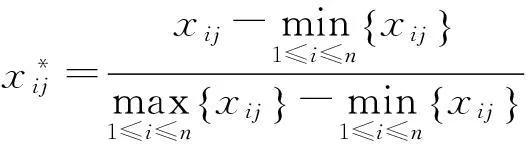
(3)

经过规格化变换后,将每列的最大数据变为1,最小数据变为0,其余数据取值在0~1之间。规格化变换后的数据也消除了计量单位的影响。
2.2 K-means聚类分析算法及其应用改进
2.2.1K-means聚类分析算法
假设要将数据组成K个划分,经典的K-means算法的处理流程如下:
步骤1:随机的把所有数据元组对象分配给K个簇,一般每个簇都不为空。
步骤2:计算每个簇内各个数据元组对象的平均值,并用该值作为相应簇的中心点。
步骤3:将每个对象根据其余各个簇中心的距离,重新分配到与它最近的簇中,即进行一次简单聚类。
步骤4:判断准则函数是否收敛(即达到用户给定的收敛值),若收敛则结束,否则转步骤2,直到达到用户给出的最大循环次数。
在步骤1中,常用的方法是随机选取几个数据元组对象或由用户指定的数据元组对象作为初始聚类中心。步骤2是对簇内所有数据元组的各个变量求平均值。在步骤3中,距离的计算公式一般是用欧式距离公式。步骤4中的准则函数通常有2种:一种是直接使用均方误差准则,定义为
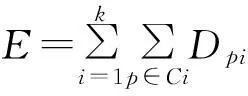
(4)
式中:E是数据集中所有数据元组对象的均方误差的总和;p是给定的数据元组对象;Ci代表一个簇;Dpi是p到Ci中心点的欧式距离公式。
另一种准则函数是在前一种基础上变化出来的,即比较相邻两次聚类的E值(一般有2种,一种是直接相减,一种是就变化率|Ei+1-Ei|/Ei)判断,若变化不大(达到用户给定的阈值),则认为收敛。
在实际应用中,该算法遇到不少的现实困难:
1)关于步骤4,它实际上就是算法的终止条件,如果是使用E做准则函数且达到收敛时,能保证聚类结果的紧致价值函数最小(与前面循环的聚类结果相比)且满足要求。但应用中收敛性阈值不容易确定。聚类很少能达到阈值而终止,时常是达到最大循环次数而终止。
2)K-means聚类算法尽管在处理大数据量时有其优势,但对高维数据就显得力不从心了。
2.2.2对K-means算法的应用改进
选择更加紧致的聚类结果,记录每次简单聚类的紧致价值函数的值,及相应的聚类中心,当算法达到最大循环次数后,选取紧致价值函数值较高的那次聚类中心作为聚类结果交付给客户。
改进后的K-means算法的处理流程如下:
步骤1:随机地把所有数据元组对象分配给K个簇,一般每个簇都不为空。
步骤2:计算每个簇内各个数据元组对象的平均值,并用该值作为相应簇的中心点。
步骤3:将每个对象根据其余各个簇中心的距离,重新分配到与它最近的簇中,即进行一次简单聚类。
步骤4:判断准则函数是否收敛(即达到用户给定的收敛值),若收敛则结束(当准备函数不是E时,也应转入步骤5),否则进入步骤5。
步骤5:记录本次聚类中心和紧致价值函数值,判断是否达到最大循环次数。若达到转步骤6;若未达到,转步骤2。
步骤6:找出紧致价值函数值最小的那次聚类中心作为最终聚类中心,并对数据元组对象重新分配到K个簇中,算法结束。
与原算法比,该算法仅在达到最大循环次数时多了一次聚类时间,并需要空间记录各次简单聚类的聚类中心点及紧致价值函数值,其多出的空间代价及时间代价基本可以忽略,而它却能找出更好的聚类中心。
下面以某市的财税数据为例:该数据集包含19 674条税源户(企业)的信息数据;选取总资产、纳税额度(2012年)、年纳税增长额度3项作为分析变量(这些数据是经过ETL处理得到的);最大循环次数为20,采用比较相邻2次聚类的E值变化率做为准则标准,其阈值为0.001;初始聚类中心随机产生。
在所得数据中,最后一次的紧致价值函数值并不是整个过程中紧致价值函数值最小的那次,而很显然,即使用E做准则函数,这个阈值也是不容易确定的。聚类结果如图2所示。


图2 聚类结果
通过分析聚类的整个过程及结果值,可以看到算法循环了16次就终止了,但最终聚类中心(即最后一次的)的紧致度较高。该过程同时记录了紧致度最低的那次的聚类中心,该次聚类中心的数据即是标准化后的聚类中心,转为实际聚类中心后,在紧致度最低的那次聚类和最后一次聚类结果的比较中,可以看出紧致度最小的那次各个簇之间的区别较为明显,并且以2次的第3簇为列,该簇的特点是纳税额与总资产的比值较高,且年纳税额增长了1倍多。从数据库中查看到的紧致度最小的那次比最后一次找出的符合该特征的企业更多,不同紧致度的聚类结果比较如图3所示。

图3 不同紧致度的聚类结果比较
3数据仓库数据挖掘的财政应用系统
财政管理是关系到国计民生的大事。然而目前我国财政管理系统比较分散,各地方内部各系统之间(地税、工商、社保等)数据无法整合利用,而各地区之间的财政数据整合利用更是难上加难。下面详细介绍笔者参与设计的为方便财政管理决策而开发的数据仓库数据挖掘系统。
3.1 系统整体架构
该系统架构在广度计算、深度计算的基础上遵循从数据驱动到模型驱动再到业务驱动然后到目标驱动的过程;其功能涵盖元数据管理、数据集成、ETL处理、OLAP分析、数据挖掘、智能决策支持等。
数据挖掘平台软件的设计目标是基于概率学、统计学、计算机等多种学科的基础,运用多种成熟的经典算法,帮助用户从海量的数据中发现隐藏的规律或知识,为用户进行的预测、各种分析提供支持,提高用户决策的科学性、可行性和精确性,有效防止各种负面事件或行为的发生,从而提高用户的效益。数据挖掘系统图如图4所示。

图4 数据挖掘系统图
3.2 在财政方面的应用实施
上述系统应用的流程大致如下:1)对财政系统的应用需求进行细致分析,如决策范围,容纳的数据有哪些部门,哪些方面数据种类(收费、支出等),格式等。2)根据分析出的需求,提出设计数据仓库模型,与设计公司相关技术人员探讨模型的可行性与有效性。3)根据数据仓库模型和挖掘分析的需求,配置ETL过程(确定数据源类型、抽取周期、处理后的数据格式等),与此同时配置OLAP系统。4)等部分相关主题数据进入数据仓库中,则可以逐步交付给用户,进行OLAP分析或挖掘分析等来支持用户决策,如果有需求改动的,则重复以上步骤,直至整个财政决策系统部署实施完成。
以税源户的聚类为例,我们的原始数据是Sybase IQ下的企业资产负债表和企业纳税情况表(2013-2014),我们先确定需求,确认要进行税源户的挖掘,然后决定聚类所使用的属性及属性类型并设计出模型请用户确认,然后使用ETL从资产负债表中抽取各个企业的总资产;从企业纳税表中,先清理数据(如取得2013年、2014年都有的企业,因为可能有的企业建立或消亡了;再比如纳税人ID清理并与资产负债表的ID统一等)根据时间(年份),纳税人ID抽取企业每年的纳税额,并用2014年纳税额减去2013年纳税额,作为增长额度属性。最后把抽取的两个数据集通过纳税人ID属性进行等值链接,放入Oracle库中,就得到了我们实验中所用的数据集。就可以使用DM工具进行挖掘了。
从图5可以看出一个完善的财政决策平台需要结合多家兄弟单位的数据才能完成,而由于各单位电算化、信息化水平不一样,数据及系统标准也不统一,所以,要整合利用,必须坚持知识发现的一般过程,一步一步来。该市财政局计划整合33个部门的数据,目前已经整合了财政局、地税局、工商局、劳动局等几个部门的数据,做了税收、税源监管,社保支出等方面的应用,如对税户的聚类分析,对该市整体财政收入及各行业的相关分析及回归分析、时间序列预测,各种税费等的关联比较等应用。

图5 某市财政局计划监管或协管的部门
4结语
在数据爆炸的新时期,财政信息化建设将是一场财政管理系统的革命。财政改革对财政信息化建设提出了很高的要求,同时,财政信息化建设又为财政改革提供了重要的基础和条件,有力地支撑和促进了财政改革。本文对数据挖掘技术在财政管理中的应用研究还不是很深入,财政系统的数据仓库和数据挖掘的应用目前认识还不够充分,实际成功案例还比较少,如何推进财政系统信息化进程是一个很复杂的课题,我们还有很长一段路要走,需要我们持续不断地深入研究。
参考文献
[1] 王祺扬.提高认识 扎实做好2008年全省财政信息化建设工作[J].财政与发展,2008(2):6-10.
[2] 颜丙通.“金保”工程建设中的政府信息资源规划研究[D].苏州:苏州大学,2007:27-31.
[3] 左春荣,唐成成.数据挖掘技术在税收征管信息化中的应用[J].中国管理信息化, 2007,10(1):61-63.
[4] William H Inmon.数据仓库[M]. 王志海,译.北京:机械工业出版社,2009:99-105.
[5] Mitchell Melanie. An introduction to genetic algorithms[M]. Cambridge, MA:MIT Press, 1998:110-115.
[6] 曹书涛.数据挖掘技术在税收征管决策中的应用[D].合肥:安徽大学,2011:31-36.
[7] 关心.面向税务稽查选案的数据挖掘研究[D].阜新:辽宁工程技术大学,2011:17-20.
[8] 秦鸿霞.论知识发现的技术与方法[J].内蒙古科技与经济,2009,197(19):58-61.
[9] 刘霞,冉成彦.利用ARIMA模型对GDP的分析与预测[J].大众商务,2011,105(5):18.
[10] 奕丽华,吉根林.决策树分类技术研究[J].计算机工程,2004,30(9):94-95.
[11] 刘天桢.基于多维数据分析的神经网络与分布式计算研究[D].武汉:武汉理工大学,2008:91-95.
[12] 赵恒.数据挖掘中聚类若干问题研究[D].西安:西安电子科技大学,2011:36-40.
[13] 陈黎飞.高维数据的聚类方法研究与应用[D].厦门:厦门大学,2007:11-17.
Research on application of DW&DM in finance system
CHEN Hua
(LogisticsManagement,XuzhouMedicalCollege,XuzhouJiangsu221004,China)
Abstract:With the development of technology, finance system informationization has been expanded and substantial data has been accumulated in various business management systems. Thus, it is imperative to understand how to acquire useful information resources from mass data. This paper gives a brief introduction of emergence, development, related technologies and application of data warehouse, knowledge discovery and data mining, and researches clustering algorithm and the metric of clustering analysis. Take clustering algorithm for instance, application improvement to data mining algorithm in practical application is represented, and then the optimal clustering analysis algorithm is proposed in application promotion stage, and experimental analysis is conducted to the data set of an urban finance system. In brief, directing at the application integration problem of finance decision making system, this paper takes an urban finance system as an example to introduce necessary steps before data mining, and finally acquires clustering information of tax source.
Keywords:finance; data warehouse; data mining; clustering; K-Means
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电子乐园·下旬刊(2021年3期)2021-02-08
铁道通信信号(2019年6期)2019-10-08
自然资源信息化(2019年4期)2019-03-29
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
山东工业技术(2016年15期)2016-12-01
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
信息通信技术(2015年6期)2015-12-26
