
互联网新闻话题特征选择与构建
2015-12-25 08:07赵旭剑邓思远李波张晖杨春
软件 2015年7期
关键词:特征选择
赵旭剑++邓思远++李波++张晖++杨春明++喻琼++王耀彬

摘要:新闻话题的特征表示是建立话题模型以及进行话题聚类(融合)的基础,传统的特征构建一般采用关键字构成的向量表示模型,未对特征的选取、分类以及质量等方面进行完整的研究,因此本文拟针对互联网新闻文档进行特征提取、特征构建以及话题聚类质量分析等方面的系统研究,阐明话题特征的选择与构建对文本话题研究的影响,为后续的话题检测与追踪等应用提供更科学的特征理论模型。实验结果表明经过话题特征优选后的聚类效果有助于提高话题模型的准确性,避免噪声特征带来的话题歧义。
关键词:话题特征;话题模型;话题聚类;特征选择
中图分类号:TP391
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.07.004
0 引言
信息技术的快速发展以及互联网的迅速普及,在线新闻文档数据成爆炸式增长。然而,这些文档数据大部分是半结构化或者非结构化的文本数据,人们要想从中快速、准确地找到自己所想要的内容极其困难。因此,如何合理、有效地组织和管理这些信息,从而提高人们检索数据的速度和准确程度,已经成为信息检索和数据挖掘领域中的热点课题,文本聚类和分类作为处理这一难题的有力手段,已经成为研究的热点课题。文本聚类、分类等针对互联网新闻的分析和挖掘技术在推荐系统、信息过滤、舆情分析和个性化推荐等领域具有较高的应用价值。实现对新闻话题的挖掘应用,需要首先对新闻报道构建话题模型,将话题转化为可进行计算和比较的信息表示模型,因此,如何有效选择话题特征构建话题模型将对互联网的新闻话题挖掘研究产生重要影响。
有效的特征选择方法不仅可以降低文本的特征向量维数,删除冗余特征,保留类别区分能力较强的特征,而且在处理非平衡数据集分类时,也应该能够克服类别当中特征分布不平衡的问题,提高正类样本的识别率,从而有助于提高分类器的整体性能;合理的特征加权方法可以扼制噪声特征对分类的负面影响,并将特征代表文档属于某个类别的能力差别最大化。从话题模型的类别来看,目前话题特征的选择主要采用三种方式。首先,作为信息检索领域一种重要的文本表示模型,向量空间模型(Vector Space Model, VSM)以其结构简单、方便计算等特点得到了诸多学科和应用的广泛关注,该模型主要采用词项作为话题特征,而概率主题模型(Probabilistic Topic Model,PTM)则根据词项、文档和话题三者的贝叶斯概率来表示话题特征,具有扎实的数学基础。词项与词项之间的语义关联体现了话题的线索,因此,采用词汇链的方式构建话题特征也具有一定代表性。然而,传统的话题特征选择方法未阐明特征选择与构建对话题挖掘性能的影响,没有考虑特征的分类和选择策略,针对该问题,本文拟针对互联网新闻文档进行特征提取、特征构建以及话题聚类质量分析等方面的系统研究,建立面向互联网新闻话题的话题特征选择和构建机制,为话题挖掘研究提供科学的特征模型。
1 话题特征提取
对于新闻文档,我们采用报道中的词项作为话题特征的基本对象,通过对词项的选择构建新闻报道的话题特征。因此,本文首先利用自然语言处理技术对新闻文本进行话题特征提取。
1.1 停用词过滤和命名实体识别
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。对于一个给定的目的,任何一类的词语都可以被选作停用词。通常意义上,停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,比如'the'、'iS'、at、'which'、'on'等。另一类词包括词汇词,这些词应用十分广泛,但是对词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率,所以通常会把这些词从文本中移去,从而提高搜索性能。中文中常见的停用词包括“一下”,“一直”,“三番两次”,“不仅…而且”,“具体地说”等等。
而命名实体识别(NER)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。本文正是基于不同命名实体的类别,并结合词项的其余特征,进行话题特征的选择,因此,命名实体的识别性能将影响话题特征的选择。命名实体识别的过程通常包括两部分:(1)实体边界识别;(2)确定实体类别(人名、地名、机构名或其他)。英语中的命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
1.2 词性标注
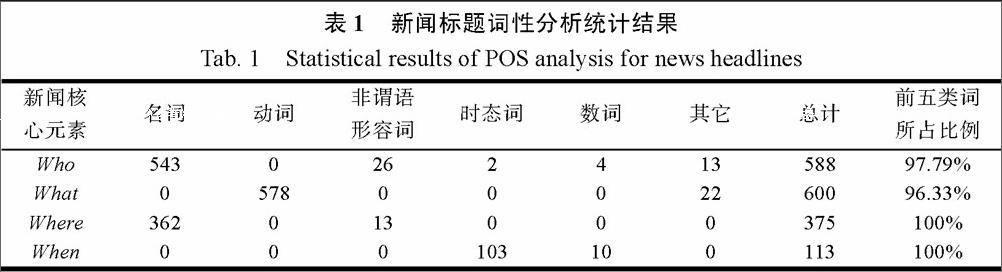
词性标注即判定给定句子中每个词的语法范畴,确定其词性并加以标注的过程。因为在中文中一个词语往往会有很多种词性,为了更加精准的区分每个词在句中的含义,所以我们需要使用词性标注。在本文的研究中,我们认为词性体现了话题的语义信息,通过对词项词性进行筛选,有助于提高话题特征的准确性。针对600篇中文新闻的新闻标题,我们进行了中文分词和词性标注,得到如表1所示的统计结果。从表格数据不难发现新闻核心四元素主要集中来源于五类词语,即名词、动词、非谓语形容词、时态词以及数词。因此,对于标注后的结果我们只需要关注以上五类词语,在细化抽取对象的同时排除助词、连词等噪声词语对于话题抽取的干扰。
1.3 特征权重计算
构建话题特征模型后,每一维特征值根据词项的TF-IDF模型计算得到。文档的权重向量d表示为 ,其中
是词组t在文档d中出现的频率(一个局部参数), 可是逆向文件频率(一个全局参数),IDI是文件集中的文件总数, 是含有词组t的文件数。因此,文件 和q之间的余弦相似度可通过公式3计算得到。
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
电信科学(2017年6期)2017-07-01
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年24期)2015-04-09
振动工程学报(2014年4期)2014-03-01
