
基于评论数据的电子商务网站口碑分析方法
2015-12-26 05:41文|胡莹
环球市场信息导报 2015年35期
文|胡 莹
基于评论数据的电子商务网站口碑分析方法
文|胡 莹
随着Web2.0以及新兴媒体的兴起,互联网自媒体的数量庞大,发表信息极度自由,相关信息传播速度达到几何级数传播,其形成的力量对于公司的品牌形象及产品的口碑正发挥着越来越大的影响。网络上用户的评论中的赞扬、喜好、抱怨等信息蕴含着巨大的商机,它是企业窥探竞争对手产品弱点以及发现新的用户需求与喜好的丰富来源。这些信息对于公关部门、品牌部门、研发部门深入了解用户状态与心理非常有帮助。网络口碑传播具有匿名性、速度快、范围大、持续力强、传播渠道多元化、传播效果容易测量等特点。网络口碑在很大程度上也是现实口碑的一种反映,无论是正面评价还是负面评价都可以被迅速传播,而其中的负面评价更会被迅速放大。好的口碑传播可以推动企业的产品销售,而负面口碑的传播可以迅速导致企业的危机。
如何合理的收集消费者或潜在消费者的口碑信息,对企业品牌维护、消费者调研、市场选择都有很重要的帮助。因此,本文提出一种电商网站的网络口碑分析方法,为企业分析网站的口碑评论得出依据。
实现方式
技术特点。本方法采用了自然语音处理NLP(分词,词法分析,句法分析)、特征数据挖掘、情感分析、观点词提取等数据分析处理技术。
随着互联网的发展,网名的信息发表自由度提高,相关信息的传播速度达到几何级数传播,其形成的力量对于公司的品牌形象及产品的口碑发挥着非常大的影响。网络上用户的口碑及意见反馈,是企业窥探竞争对手产品弱点以及发现新的用户需求与喜好的丰富来源。如何合理的收集消费者或潜在消费者的口碑信息,对企业品牌维护、消费者调研、市场选择都有很重要的帮助。因此,本文提出一种电商网站的网络口碑分析方法,为企业分析网站的口碑评论得出依据。
本方法提出的通过产品特征数据挖掘方法(分词与词性标注、Apriori算法提取高频词汇、然后利用KNN算法进行分类聚合和裁剪)可以准确的提取产品数据特征数据。创新性的提出把特征数据挖掘与中文情感分析技术相结合,准确获取产品特征数据,并分析产品特征评价的倾向性,进一步提升产品网络口碑分析的实用性和针对性。
实现说明
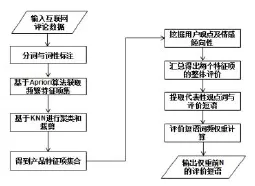
本方法的数据处理流程如下图所示,包括分词与词性标注、基于Apriori算法获取频繁特征项集、基于KNN进行聚类和裁剪、挖掘用户观点及情感倾向性、提取代表性观点词与评价短语、评价短语词频权重计算等主要步骤。
采集大量网络评论数据,用IKAnalyzer分词工具对数据进行分词和词性标注,提取出其中的名词及名词短语。
输入一批小米3手机评论:“用了2天才来评价,感觉不错,性价比高,不足手机发热严重,系统内存控制不行”;“已经收到货,物流很给力啊,目前正在使用,感觉还不错,日后追加评价”;“很好,超出我的想象,另外莲米的服务超赞,只是物流有点慢,转到ems就超慢,八天时间才收到货”;“打电话时通话不顺畅,信号差,设置2G后正常了,不知是运营商的问题,还是手机的问题,想退换货又很纠结,电池也是一天一充”;“性价比比较高,像素貌似没有1300万,手机用用还可以,不卡,通话清晰”……
提取出其中的名词及名词短语如下:通话, 手机, 性价比, 系统内存, 物流, 服务,……
针对名词及名词短语,基于关联规则的Apriori算法获取频繁特征项集作为候选产品特征集合。
Apriori算法对数据集进行循环处理挖掘频繁项集,其算法过程如下:
a) 统计每个元素出现的频率,并找出那些不小于最小支持度的项目集, 即1项频繁项集;
b) 循环处理,将第(k-1)步生成的(k-1)项频繁项集中的元素两两组合,统计每个组合中两个元素同时出现的频率,找出不小于最小支持度的组合,生成k项频繁项集;
c) 循环处理直至生成的n项频繁项集为空,所有的1,2,…,n项频繁项集构成最终的频繁项集。
在评论挖掘算法中,我们计算每个名词及名词组合在评论中出现的频率,采取最小支持度为0.01,生成产品特征项;由于3项以上的频繁项明显不是产品特征,我们只考虑3项以下的频繁项。针对上述小米3手机评论,对提取出来的名词,计算其出现的频率,两两组合后计算同时出现的频率,提取出大于给定的最小支持度的项目作为特征项,得到下列特征项:
[系统], [速度], [手机] , [用户], [评论], [小米], [手机], [功能], [性价比], [价格], [外观], [物流], [用户, 评论], [小米, 手机]……
将候选产品特征集合按照K最近邻(k-Nearest Neighbor,KNN)分类算法进行聚类和裁剪,得到最终产品特征项集合。KNN算法思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
a)初始化距离为最大值
b)计算未知样本和每个训练样本的距离dist
c)得到目前K个最临近样本中的最大距离maxdist
d)如果dist小于maxdist,则将该训练样本作为K-最近邻样本
e)重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
f)统计K-最近邻样本中每个类标号出现的次数
g)选择出现频率最大的类标号作为未知样本的类标号
经过此步骤,可以获得了最终的产品评价数据
以句子为单位分析评论,若句子包含特征项,挖掘出用户对于该特征项的观点词及情感倾向性。观点词的提取,我们使用了stanford nlp工具进行句法分析,根据句法分析树提取出修饰特征项的形容词,并利用情感词典判断其情感倾向性。
例如:句子“用了一阶段,质量很好”,对特征项[质量]提取出其修饰词“好”,为正面评价;句子“质量不错,外观喜欢,速度快,信号好”,对特征项[质量]提取出其修饰词“不错”,为正面评价;对特征项[速度]提取出其修饰词“快”,为正面评价;
汇总包含每个特征项的正面句子数量和负面句子数量,得到用户对特征项的整体情感倾向性;例如,对特征项[质量]统计出正面句子数量为8,负面句子数量为1,整体评价为正面;对特征项[系统]统计出正面句子数量为7,负面句子数量为0,整体评价为正面;
根据每个特征项的整体情感倾向性,从相应的正面或负面句子中提取出代表性观点词,组成评价短语。
代表性观点词的提取:给定某个特征项,统计其每个观点词出现的次数n(opinion)及观点词和特征项之间的距离d(opinion, feature),,根据以下公式计算观点词的权重,选取权重最大的词语作为代表性观点词。
weight = n(opinion)/( d(opinion,feature) * n(senctences) ),其中n(senctences)为句子总数。
例如,经计算得到特征项[质量]的代表性观点词“不错”;得到特征项[质量]的代表性观点词“流畅”;依据评价短语出现的频率计算评价短语的权重,按照评价短语的权重降序排列,分别获取前N项正负面评价短语。最终计算得到评价短语及其权重如下:速度快:0.5367, 手机不错:0.2731,性价比高:0.16139, 屏幕清晰:0.0222, 反应快:0.0177,物流快:0.013
通过以上的方法,能为电子商务网站在众多用户的评论数据中获得评价结论。企业能够通过此方式迅速了解市场的口碑,从而了解用户需求,为企业改进产品和下一步开拓市场决策提供了依据。
武汉软件工程职业学院商学院连锁经营管理研究所)
猜你喜欢
知识经济·中国直销(2018年8期)2018-08-23
中国老区建设(2016年1期)2016-02-28
海峡姐妹(2016年2期)2016-02-27
计算机工程(2014年6期)2014-02-28
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
