
基于流水化和滑动窗口结构的低功耗指令Cache设计
2016-01-08 05:31李伟,肖建青
计算机工程与科学 2015年6期
关键词:低功耗
基于流水化和滑动窗口结构的低功耗指令Cache设计*
李伟,肖建青
(西安微电子技术研究所,陕西 西安 710065)
摘要:嵌入式处理器中Cache的应用极大地提高了处理器的性能,同时Cache,尤其是指令Cache功耗占据了处理器很大一部分功耗,关闭不必要的tag SRAM和data SRAM的访问,可以极大地降低功耗。提出了一种流水化的指令Cache访问机制,关闭不必要的data SRAM的访问;并且通过记录指令Cache行的信息和预测下一行的Cache形成一个Cache行滑动窗口,关闭不必要的tag SRAM访问。所提出的方法没有性能损失,在SMIC 90 nm工艺下进行功耗分析,其指令访问的功耗降低50%。
关键词:指令Cache;低功耗 ;流水化;滑动窗口;CPU
中图分类号:TP303 文献标志码:A
doi:10.3969/j.issn.1007-130X.2015.06.001
收稿日期:*2014-05-02;修回日期:2014-09-01
基金项目:国家863计划资助项目(2011AA120201)
作者简介:
通信地址:710065 陝西省西安市太白南路198号研究生部
Address:Graduate Department,198 Taibai Rd South,Xi’an 710065,Shaanxi,P.R.China
Low power instruction cache design based on pipeline and sliding window structure
LI Wei,XIAO Jian-qing
(Xi’an Microelectronic Technology Institute,Xi’an 710065,China)
Abstract:While the application of cache significantly improves the performance of the embedded processors, the cache, especially the I-cache, also consumes a large proportion of power. Reducing unnecessary accesses to the tag SRAM and the data SRAM can lower the power consumption. In this paper we design a pipeline I-Cache access mechanism that can deny the unnecessary access to the data SRAM. We also present a slide window of the cache lines by recording the information of the current introduction cache line and by predicting the information of the next cache line to reduce the unnecessary access to the tag SRAM. In the SMIC 90nm, the proposed method can achieve a 50% power reduction of the I-Cache without any performance degradation.
Key words:I-cache;low power;pipeline;slide window;CPU
1引言
在现代嵌入式处理器中,Cache的功耗占很大一部分比例,例如strong-arm110的Cache功耗占处理器功耗的43%[1]。在嵌入式应用中load/store指令的比例一般不超过25%[2],并且数据没有明显的局部性特点,数据Cache大都采用直接映射,因此其所占功耗较小。指令一般具有显著的局部性特点,为了提高指令Cache的命中率,一般指令Cache都采用多路组相连的Cache结构,功耗较大,因此降低指令Cache的功耗一直是嵌入式处理器设计的重点。
在嵌入式应用环境中,功耗可以说是设计的第一要素。随着功耗问题的日益明显,Cache的低功耗设计方法也层出不穷。指令Cache分阶段访问就是将tag位和data位的访问分为两个阶段,只有在tag位命中的情况下,才去访问data位,以减小指令Cache的访问功耗[3],但是该方法引入了一个时钟周期的延迟,降低了指令Cache的性能。为了消除分阶段访问带来的延迟,文献[4]提出了一种路预测的方法,通过直接访问预测命中路的指令,以减小访问的功耗。但是,功耗的降低与预测的准确率相关,当准确率较低时,不仅没有降低功耗,同样会造成性能的损失。文献[5]提出了基于预测机制的Filter Buffer技术,通过预测将要访问的指令是在指令Cache中还是在Filter Buffer中来降低指令Cache的访问次数。文献[6]提出了一种基于分支折合的低功耗设计方法,充分利用指令缓冲队列中执行过的指令来减小指令Cache访问功耗。以上两种技术分别增加了额外的存储结构,发掘程序中的短循环体,以降低访问功耗,一方面额外的存储结构会带来额外的功耗消耗;另一方面如果发掘算法不合理或缓冲队列的深度不合适,反而会额外增加指令Cache的功耗。文献[7~9]提出了基于特定算法的动态可重构的指令Cache设计,通过动态改变指令Cache的容量和组相联数达到减小访问次数和功耗的目的。由于指令的动态功耗与存储体访问宽度关联较大,与容量关联度较小,因此动态功耗下降有限,此外容量的动态调整滞后于实际的程序需要,因此对指令Cache的性能有一定的影响。
本文对LEON3处理器的指令Cache进行分析后,充分发掘利用指令Cache访问时已经读出的tag信息,减小tag访问的次数;此外,采用了基于双时钟沿流水化分阶段访问的结构,减小数据区域访问的次数,在增加很小的硬件代价的基础上,大幅度降低了指令Cache的动态功耗。
2滑动窗口的原理分析
通过对指令Cache行的执行情况进行分析,可以将指令流归纳为四种情况,如图1所示。
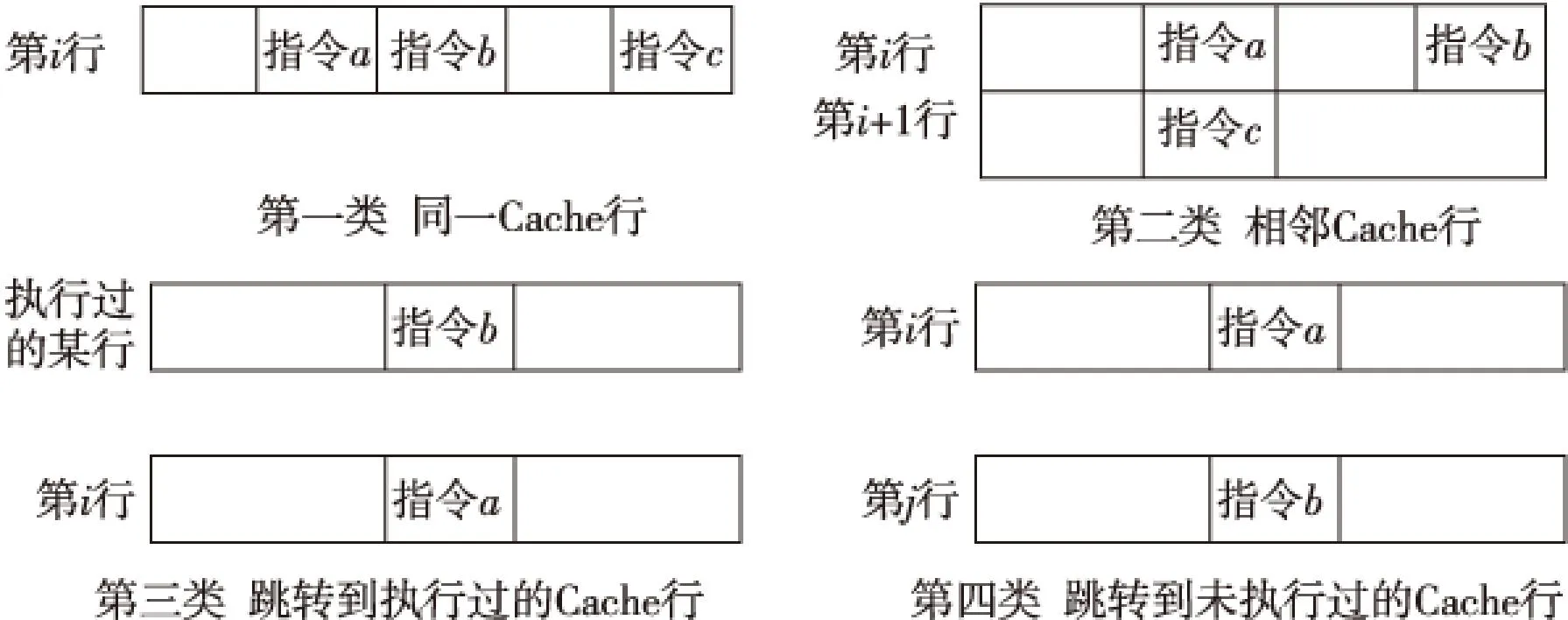
Figure 1 Four types of instruction flow 图1 四种类型的指令流
第一类为指令流在同一Cache行。如当前指令为指令a,当不发生跳转时将执行指令b,如果发生跳转时,跳转到本行指令c。无论哪种情况其相继执行的指令都在同一Cache行中。对于某一Cache行的多条指令,共享tag标志位。
第二类为相邻的Cache行。如指令b为当前指令最后一行,如果不发生跳转,将要执行下一Cache行的第一条指令,如果发生跳转,其跳转的目标指令为下一行的指令b。也就是说将要执行的指令在相邻的下一个Cache行中。在第一类指令发生的空隙,tag SRAM处于空闲,如果利用空闲周期,预先读出同一路下一个Cache的tag标志位和有效位,在指令发生Cache行切换时,预先比较预测的Cache行是否命中,如果命中就可以关闭tag SRAM,其余路的比较器也可以不参与比较,这样便可以有效地降低功耗。事实上由于指令的局部性特征比较明显,预测的成功率很高。
第三类是在第i行Cache发生跳转,跳转到最近执行过的Cache行。对于此类指令可以记录最近执行过的多个Cache行的信息,当指令发生跳转时,首先比较记录中的Cache行是否命中,同样,如果命中便可以降低tag SRAM的功耗。
第四类是发生跳转指令,其跳转地址不在以上三类的记录信息内,对于此类指令流没有规律可循,因此不做处理。
因此,本文通过设置一个滑动的寄存器窗口来记录预测的Cache行信息、当前Cache行的信息和最近访问Cache行的信息,用于提前比较指令Cache是否命中,如果命中,可以有效地降低指令Cache的功耗,如果不命中,也不会带来额外的性能损失。其原理示意图如图2所示,图中采用了四路组相联Cache,每一Cache指令字为4,滑动窗口深度为3。滑动窗口由三个字段组成:(1)set字段用于保存有效指令所在的Cache组号;(2)tag字段用于记录tag信息,用于命中判断;(3)valid字段用于记录对应指令是否有效。不失一般性,假设刚刚执行过和正在执行的指令均来自第一路Cache,当执行到第i行指令Cache时,首先将当前Cache行tag、valid等信息保存到记录窗口中,此后同一行Cache的指令通过滑动窗口进行命中判断。利用Cache tag SRAM访问的空闲时间段,将同一路Cache的下一行信息保存到记录窗口中。当Cache行发生变化时,首先判断记录窗口记录的tag信息是否命中,如果命中发生窗口滑动,将下一行信息保存为当前信息,当前信息保存为历史信息。如果没有命中,首先将当前信息保存为历史信息,重新记录当前Cache信息和预取下一Cache行信息。事实上,通过设置set字段保存有效的Cache组号,Cache的跳转可以是不同组的Cache行。考虑到顺序执行的指令序列占总指令的很大一部分比例,记录窗口只是预取同一路的下一Cache信息,而不做复杂的预测。
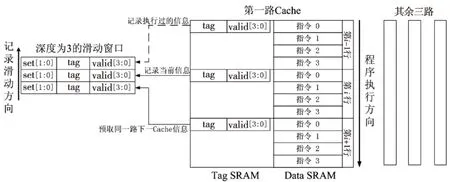
Figure 2 Schematic of instruction cache sliding window 图2 指令Cache滑动窗口原理示意图
3基于流水化和滑动窗口结构的低功耗指令Cache设计
3.1滑动窗口的低功耗设计
滑动窗口的状态控制有四种状态,如图3所示。
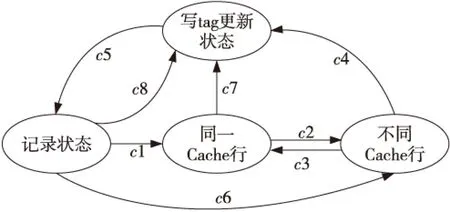
Figure 3 Schematic diagram of the sliding window 图3 滑动窗口状态示意图
(1)记录状态,记录当前Cache行的tag位和valid位;
(2)同一Cache行状态,预取下一行指令的tag、valid位;
(3)不同Cache行状态,当相继两条指令不在同一Cache行时,需要更新当前Cache行和历史Cache行的tag、valid位;
(4)写tag更新状态,当Cache不命中时,需要重新写Cache行,此时如果需要更新的Cache行在窗口内,需要更新其有效值。
状态迁移条件有八种,分别是:c1记录当前Cache行信息,并且下一条指令在同一Cache内;c2当前指令不在同一Cache内;c3更新记录窗口后,跳转到同一Cache行状态;c6记录状态时发生跳转,当前指令与记录指令不在同一Cache内;c4、c7和c8为Cache指令不命中,需要跳转到写tag更新状态,更新相应的标志位;c5状态为写更新后跳转到记录状态得新开始记录。
指令Cache 的滑动窗口由三类寄存器组构成:current寄存器用于记录当前行tag、set、valid信息;next寄存器用于记录预测行tag、set、valid信息;history寄存器用于记录最近执行过的Cache行信息。滑动窗口的命中判断过程如图4所示。首先将NPC中tag值与记录窗口中的所有tag字段进行比较,当均不相同时表示记录窗口缺失,需要打开四路tag区域进行tag位的读取,并随后更新记录窗口。当命中时,通过set字段的组号生成Data SRAM的片选信号并保存到Data_Enable寄存器中,用于指示指令所在的区域,并根据NPC的地址偏移量来选择有效位,如果有效位valid_x有效,表示指令字有效可以关闭tag SRAM;如果valid_x无效,表示指令字在Cache中缺失,按指令字缺失做处理,当指令字重新从主存中取回时,更新相应的标志位。
3.2分段流水化的低功耗设计
为了进一步减小指令Cache数据区域的访问次数,降低功耗,在本文的指令Cache设计中,将取指令操作分为了三个流水阶段,分阶段比较和输出,减小data SRAM的访问次数。在寄存器和SRAM全部采用时钟上升沿采样时,取tag标志位信息、tag位输出比较并根据结果使能data SRAM和指令输出将分别对应处理器流水的W(写回)、F(取指)和D(译码)。在这种情况下,SRAM输出的时延将压缩译码阶段电路的译码时间,对译码电路本就紧张的时序造成影响。因此,本文对data SRAM的控制信号采用了下降沿采样的设计方法,将3个时钟周期压缩为2.5个时钟周期或2个时钟周期。其电路结构如图5所示。
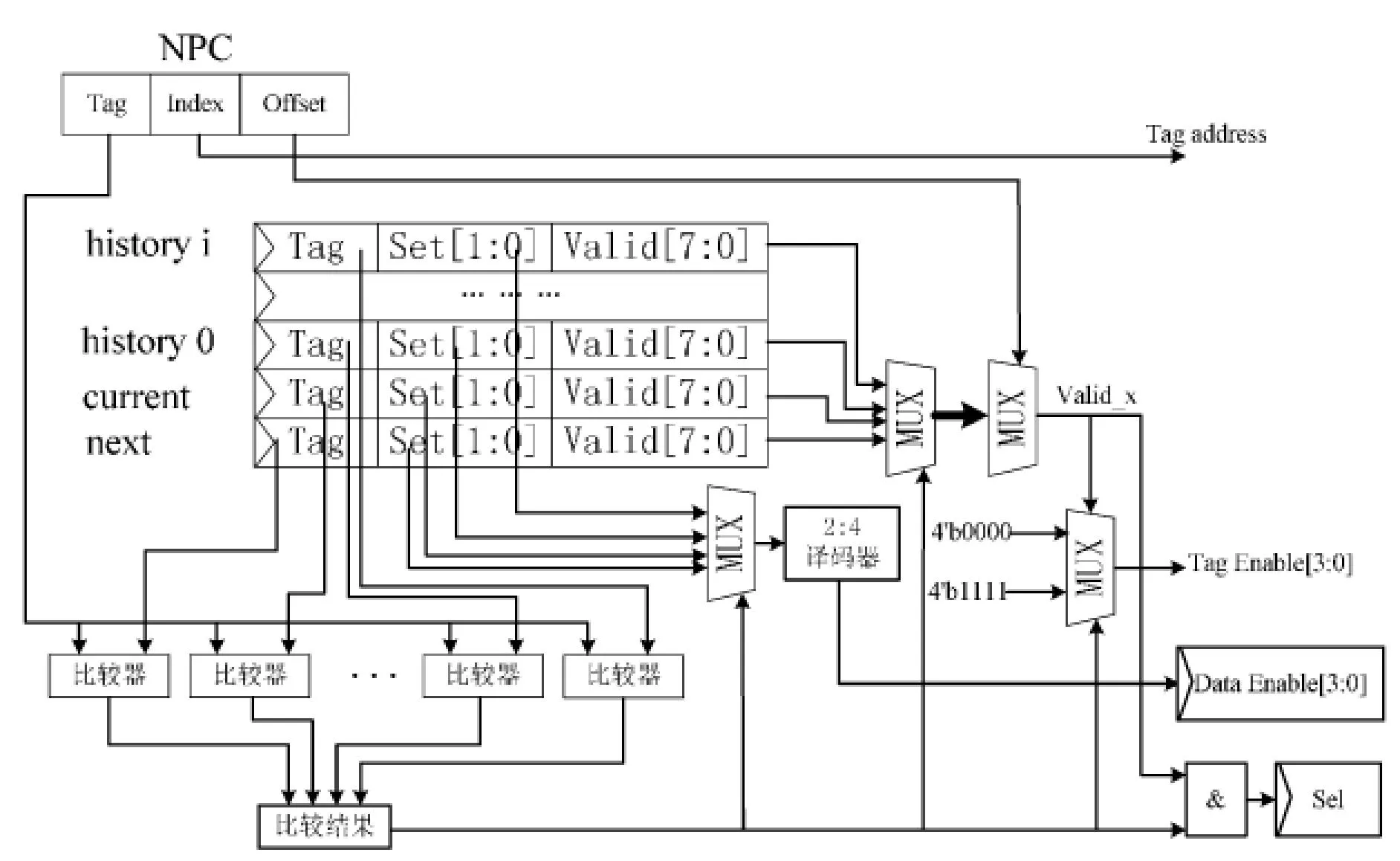
Figure 4 Hit judgment of the sliding window 图4 滑动窗口命中判断
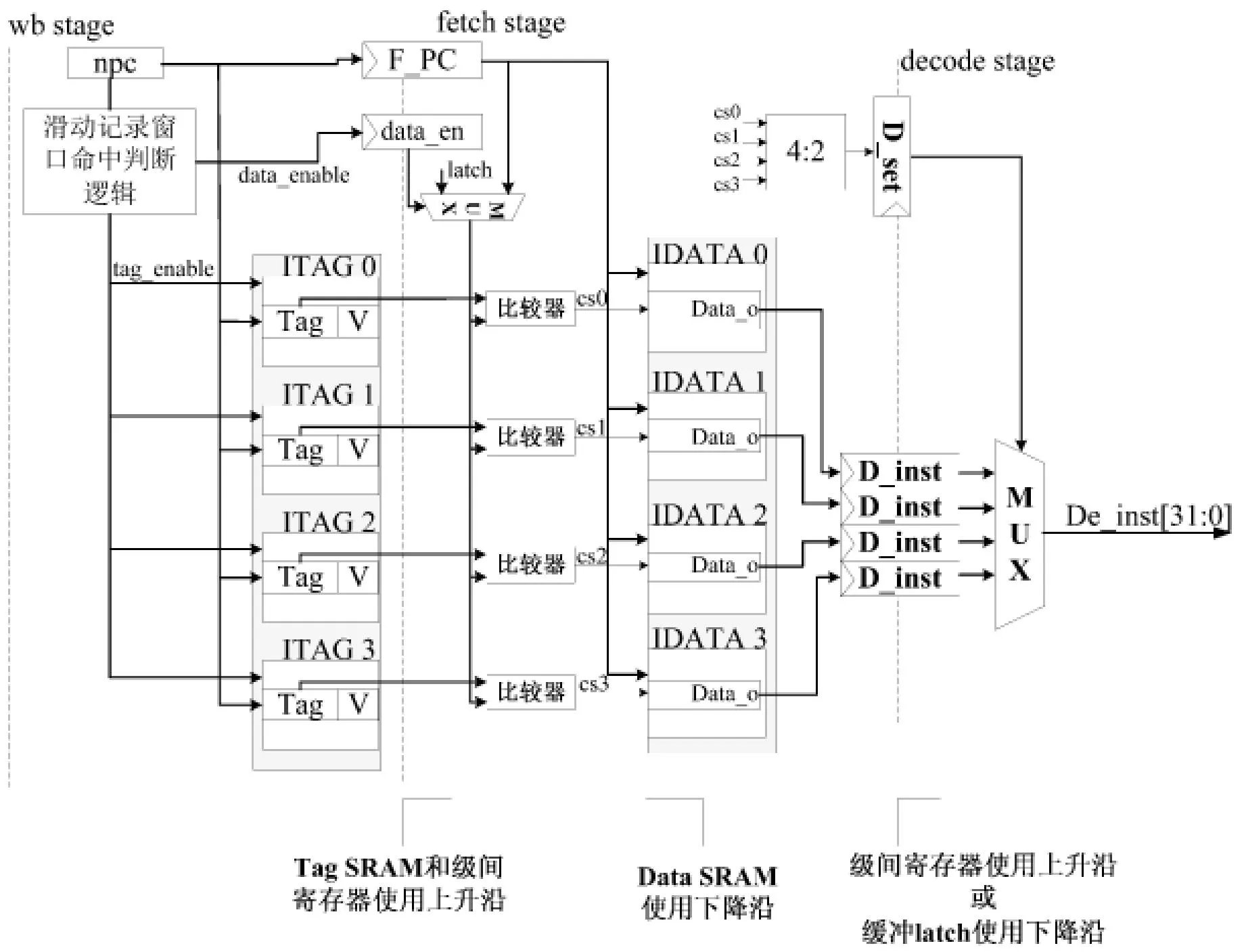
Figure 5 Scheme of instruction cache with pipeline 图5 流水化操作电路结构图
在W流水级,根据NPC值将使能信号和地址信号输入到四路tag SRAM中,同时进行记录窗口的预判,并将预判结果保存到寄存器中。
在F流水级,如果记录窗口命中,通过多路选择器和latch进行操作数隔离,减小索引和PC比较的功耗,如果没有命中,使用PC地址和tag SRAM输出的索引进行命中判断,将命中的结果保存到D_set寄存器中。在时钟的下降沿,data SRAM采样控制和地址信号,并将数据输出。当时钟频率较低时,使用寄存器保存指令输出结果,当时钟频率较高时,寄存器的建立时间无法保障,采用锁存器保存输出结果,锁存器在高电平时透明,在低电平时将数据锁存,保证译码阶段指令的持续输出。对于使用锁存器保存指令的结构,同时需要设置额外的一个寄存器用于保存指令字,保证流水由于数据相关停顿时,译码器的指令字来自指令寄存器,从而可以最大限度地减小指令Cache的访问。在本文的设计中,时钟的频率为200 MHz,完全可以满足使用寄存器保存指令的时序要求。
通过流水化的指令Cache设计,可以将分段访问Cache技术带来的额外时钟消耗完成隐藏到流水线中。同时,利用分段访问组相联Cache原理,根据tag的比较结果选择有效的数据区域进行访问,减少了访问Cache数据区域的次数,有效地降低了Cache的功耗。
4实验及结果分析
4.1访问量分析
我们使用Power Stone Benchmarks[10]嵌入式功耗测试向量对改进前后的LEON3指令Cache tag、data区域的访问次数进行了统计,发现next和current寄存器的设置可以有效地降低tag SRAM访问的次数,而history的数量对减少tag SRAM访问次数的贡献较小,在设置1、2、4个history寄存器时,平均访问减少3.583%、3.589%、3.589%。因此,本文的历史寄存器数量设置为1。最终的统计结果如表1所示。

Table 1 Number of access to the tag SRAM before
通过以上的统计信息可以看出,采用滑动记录窗口的技术,可以有效地降低tag SRAM的访问次数,访问次数减小为初始设计的39%,而处理器总的执行周期没有任何变化。
对选取的Power Stone测试向量进行了指令Cache数据区域访问的统计,统计结果如表2所示。

Table 2 Number of access to the data SRAM before
通过以上统计结果可以看出,采用基于分段访问的流水结构的Cache访问,极大地减少了对指令Cache数据区域的访问次数,data SRAM的访问次数下降为优化前的27%。
4.2功耗分析
指令Cache的tag SRAM和data SRAM采用TSMC 90 nm工艺的Memory Compiler生产,指令Cache控制器同样采用TSMC 90 nm工艺在Synopsys DC工具综合生产。基于时钟周期的仿真采用Power Stone Benchmarks测试程序集,功耗分析采用Synopsys PTPX工具进行分析。tag SRAM和data SRAM的功耗对比图如图6和图7所示。
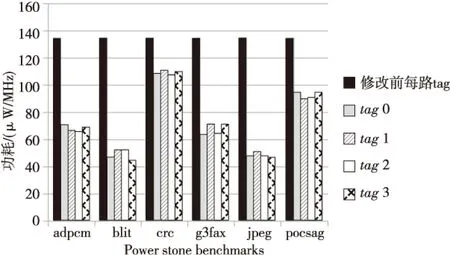
Figure 6 Power comparison of each set tag SRAM with and without the sliding record window 图6 采用滑动记录窗口技术前后 指令Cache各路tag功耗对比
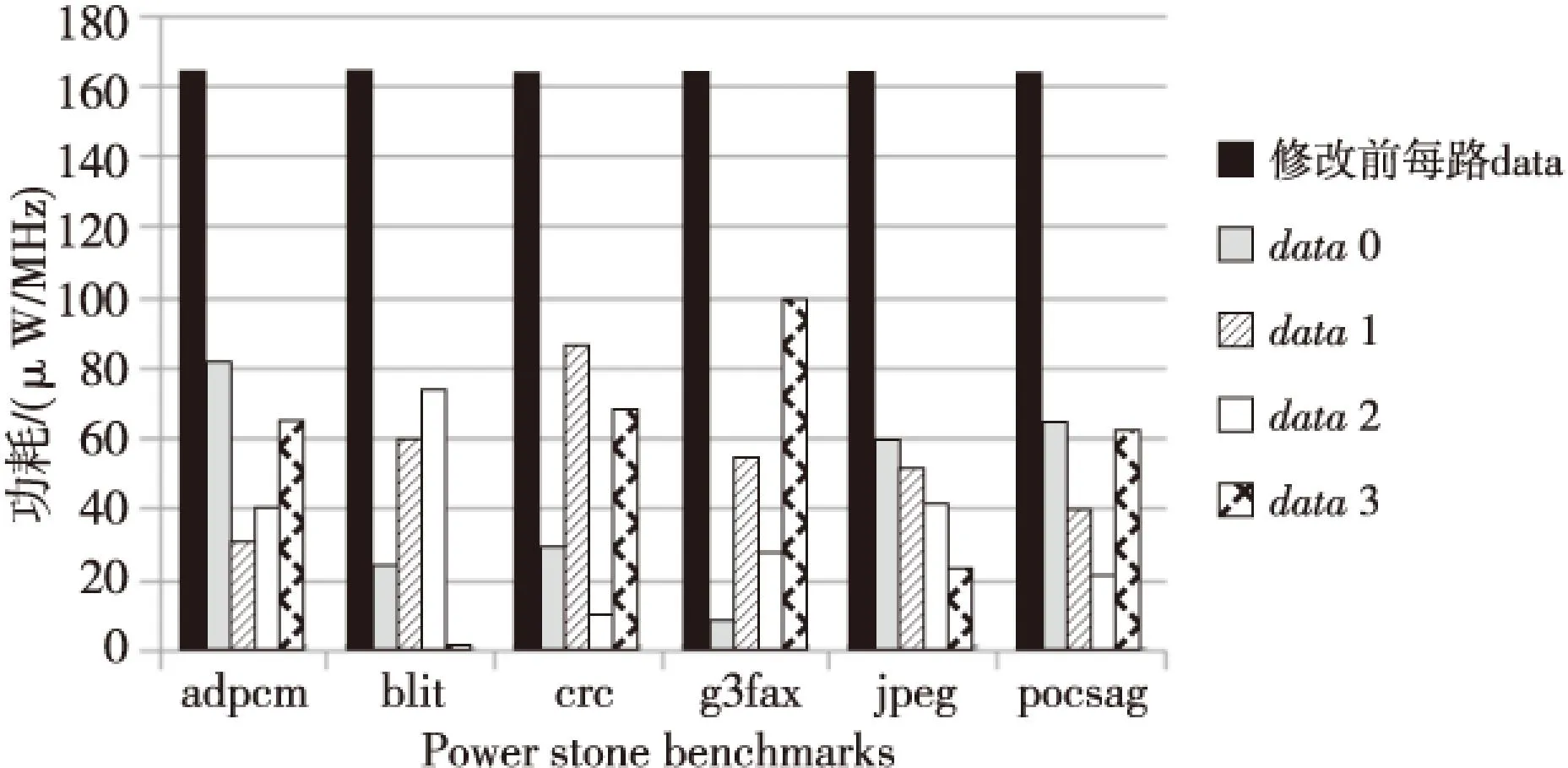
Figure 7 Power comparison of each set data SRAM with and without the technique of phased access and pipeline 图7 采用分阶段访问和流水化技术前后 每路data SRAM功耗对比
从图6可以看出,通过采用流水化分阶段访问技术,指令Cache的data SRAM区域功耗得到了有效的控制,平均功耗下降至原始设计功耗的40%。从图7可以看出,通过采用滑动记录窗口技术,指令Cache的tag SRAM区域的访问功耗大幅下降,平均减少到原始设计的60%。
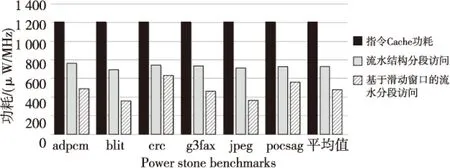
Figure 8 Total power comparison of instruction cache 图8 指令Cache的总功耗对比
从图8的功耗仿真结果可以看出,采用流水化指令Cache以后,其指令Cache的功耗减少了约40%,同时采用流水化设计和滑动窗口设计后指令Cache的功耗减少了约60%。因此,极大地降低了指令Cache的功耗。
5结束语
本文首先研究分析了现有的降低指令Cache的设计方法和技术,并结合具体项目中的Cache结构,设计一种滑动记录窗口的流水结构指令Cache,用于降低指令Cache的动态功耗。该技术通过将指令Cache的访问分为三级流水结构,将指令Cache的tag位读取、tag位的比较和指令的读取分为三个阶段完成。由于只有在tag位命中后才进行指令的读取,有效地降低了指令Cache的指令区域的访问量,有效地降低了功耗。同时,基于指令访问显著的空间局部性特点,通过设置滑动记录窗口记录当前的和最近访问过的tag标志位,在读取指令Cache的tag标志位之前首先比较记录窗口的tag标志位,只有不命中时,才读取指令Cache的tag标志位,有效地降低了tag位的比较和tag区域的访问次数,可以有效地降低功耗。
参考文献:
[1]Montenaro J,Loe T H,Witek R T,et al. A 160MHz 32b 0.5W CMOS RISC microprocessor[J]. IEEE ISSCC,1996,31(11):1703-1714.
[2]Guthaus M R,Ringenberg J S,Ernst D,et al. Mibench:A free,commercially representative embeded benchmark suite[C]//Proc of IEEE 4th Annual Workshop on Workload Characterization,2001:3-14.
[3]Megalingam R K,Deepu K B,Joseph I P,et al. Phased set associative cache design for reduced power consumption[C]//Proc of International Conference on Computer Science and Information Technology,2009:551-556.
[4]Raveendran B K,Sudarshan T S B,Patil A,et al. Predictive placement scheme in set-associative cache for energy efficient embedded systems [C]//Proc of International Conference on Signal Processing,Communications and Networking,2008:152-157.
[5]Ali K,Aboelaze M,Datta S. Energy efficient I-Cache using multiple line buffers with prediction[J]. Computer&Digtial Techniques,2008,2(5):355-362.
[6]Meng Jian-yi,Yan Xiao-lang,Ge Hai-tong,et al.Instruction recycling based low power branch folding[J].Journal of Zhejiang University (Engineering Science),2010,44(4):632-638. (in Chinese)
[7]HSU P H,Chien S Y. Reconfigurable cache memory architecture for integral image and integral histogram applications[C] //Proc of International Conference on Signal Processing Systems,2011:151-156.
[8]Alipour M,Moshari K,Bagheri M R,et al. Performance per power optimum cache architecture for embedded applications,a design space exploration[C]//Proc of the 2nd IEEE International Conference on Networked Embedded Systems for Enterprise Application,2011:1-6.
[9]Ren Xiao-xi, Liu Qing. Study of dynamically reconfigurable algorithm for lowpower cache[J].Application Research of Computers,2013,30(20):414-416.(in Chinese)
[10]Scott J,Lee L H,Arends J,et al. Design the low-power M CORE architecture[C]//Proc of IEEE Power Driven Microarchitecture Workshop,1998:145-150.
参考文献:附中文
[6]孟建熠,严晓浪,葛海通,等. 基于指令回收的低功耗循环分支折合技术[J]. 浙江大学学报(工学版),2010,44(4):632-638.
[9]任小西,刘清. 一种低功耗动态可重构cache算法的研究[J]. 计算机应用研究,2013,30(20):414-416.

李伟(1980-),男,山西晋中人,博士生,研究方向为SoC低功耗设计。E-mail:David_lw@foxmail.com
LI Wei,born in 1980,PhD candidate,his research interest includes low power design of SoC.
猜你喜欢
成都信息工程大学学报(2021年1期)2021-07-22
减速顶与调速技术(2020年4期)2020-11-22
电子制作(2019年24期)2019-02-23
电子测试(2018年15期)2018-09-26
成都信息工程大学学报(2018年1期)2018-05-31
电子制作(2017年13期)2017-12-15
电子制作(2017年13期)2017-12-15
计算机测量与控制(2017年6期)2017-07-01
浙江大学学报(工学版)(2015年1期)2015-03-01
电子设计工程(2014年17期)2014-02-27
