
基于GSP算法的Web用户访问序列模式挖掘
2016-01-09 14:31王子卿樊楠
电脑知识与技术 2015年30期
王子卿+樊楠
摘要: 该文以某电子商务网站的Web访问日志为研究对象,利用SQL Server提供的SSIS服务和T-SQL语句进行数据预处理,得到序列数据库,然后用java语言编程实现GSP算法对其进行序列模式的挖掘测试分析,通过对结果分析可以做出对该网站布局和内容(或产品)调整提供参考,使其更好为其用户提供针对性的服务。
关键词: Web日志; 序列模式挖掘; GSP算法
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)30-0217-02
随着网络服务的迅速发展,互联网上已有庞大数量的网站,且还在不断的建设,通过对网站服务器的操作和访问进行专业而详细的分析,可以了解网站的运行情况并能进一步发现网站所存在的缺陷,为促使网站更好的运营与发展提供可靠的技术支持与决策依据。为了能够促使网站更好的运营与提供针对性与个性化的服务,必须要了解电子商务网站以及其所展示的各产品模块的具体访问情况,而这些信息只能通过获取对Web服务器上网站的相关运行日志文件,并对其包含的数据信息进行统计与分析得到。
互联网用户具有多样性的特点,全球大概有10亿多个网站,网民数量接近30亿,他们来自不同的民族,具有不同层次的经济收入水平,具备不同的教育背景与不同的个人兴趣,他们访问的目的也均不同,但他们在浏览Web页面过程中均留下了访问信息。特别是像淘宝、京东等大型的电子商务网站,它们每天都有数亿的在线交易额,而这些交易以及用户的浏览(指没有交易的用户)都产生可谓海量的Web访问日志数据。Web日志挖掘是Web大数据应用领域或者电子商务商业智能应用中的一个最为重要的内容。
本文以某电子商务网站的Web访问日志为研究对象,利用SQL Server提供的SSIS服务和T-SQL语句进行数据预处理,得到序列数据库,然后用java语言编程实现GSP(Generalized Sequential Patterns)算法对其进行序列模式的挖掘测试分析,通过对结果的分析可以为改善该网站的布局以及产品展示方式的调整提供参考。
1 基于Web日志的序列挖掘
Web日志序列挖掘一般分三个步骤,即数据预处理、挖掘算法处理以及模式分析。
数据预处理主要是对Web日志进行序列挖掘之前的对原始日志文件进行数据转换、清洗等一系列的操作,最终形成可供序列模式挖掘算法所使用的规范化数据。其具体工作主要包含数据净化、会话识别、用户识别以及路径补充等过程。数据净化工作主要是对挖掘中不需要的相关数据进行删除操作;会话识别主要是对每个用户在某一段时间内的所有请求页面进行分解从而得到用户会话;用户识别是将用户和请求的页面进行相关联的过程,其中主要是处理多个用户通过防火墙或代理服务器访问站点的情况。在用户识别的过程中,不仅需要服务器日志,还需要知道站点的拓扑结构;路径补充过程就是将本地或代理服务器缓存所造成的遗留请求也补充完整。执行上面的操作后,就得到了序列模式挖掘算法所需要的输入信息(用户会话文件),该文件中包含访问Web站点的用户,用户请求的页面及请求发生的顺序,每一页浏览的时间等信息[1]。
挖掘算法处理主要是指在基于数据预处理的基础上,通过实现某种序列算法得到挖掘结果,这些结果主要包括如每页的访问数,最频繁的访问的页面,每页的平均浏览时间等。序列模式算法主要有两类:一类是类Apriori算法,以GSP算法为代表,这种算法基于一个事实:一个序列是频繁的,它的所有子序列必然是频繁的;另一种挖掘序列模式的思想是基于数据库投影的序列模式生长技术的应用,如PrefixSpan算法。
模式分析是依据挖掘算法所得到的模式集合,再结合实际所感兴趣的模式进行筛选和分析,然后采用可视化技术对这些模式作为挖掘的最终结果进行直观和个性化的展示。
2 基于GSP算法的实现流程
序列模式挖掘一般分为五个步骤,这些步骤分别为排序阶段、大项集阶段、转换阶段、序列阶段以及选最长序列阶段。
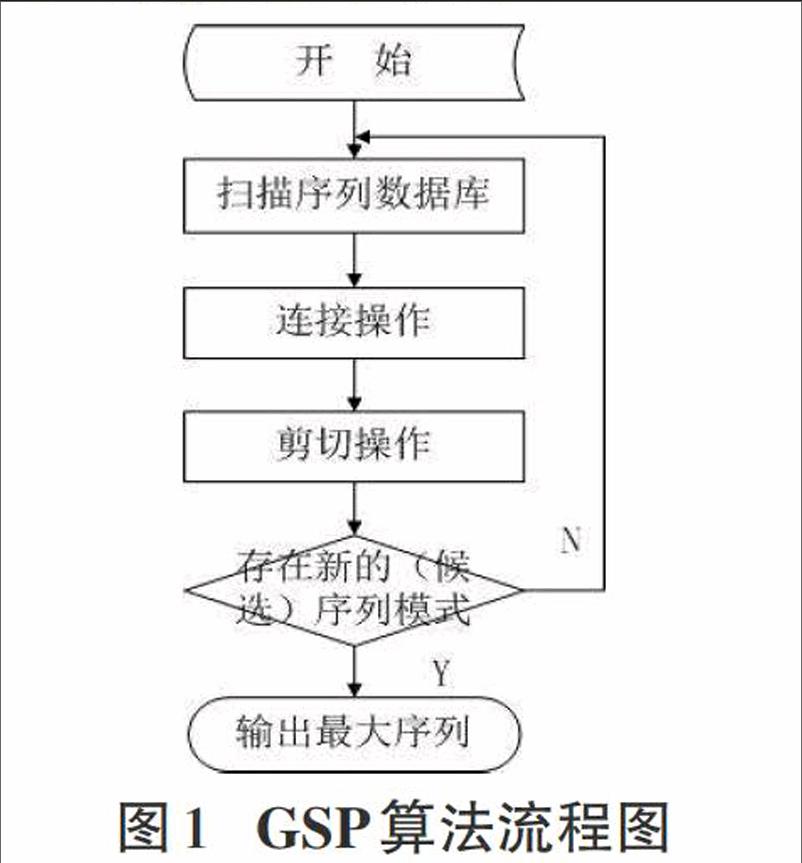
GSP算法的主要流程如图1所示:
1)序列数据库进行扫描,得到长度为1的序列模式L1,作为初始的种子集。
2)根据长度为i的种子集Li通过连接操作和剪切操作生成长度为i+1的候选序列模式Ci+1;然后扫描序列数据库,计算每个候选序列的支持数,产生长度为i+1的序列模式Li+1,并将Li+1作为新的种子集。
3)重复第二步,直到没有新的序列模式或候选序列模式产生为止。
3 网站日志挖掘实例分析
本文采用ECML_PKDD 2005会议提供的公共点击流数据,它收集了380多万条电子商务网站的服务器日志记录,每个日志文件包含的是一个小时所收集的记录,每个文件包含的信息有时间、IP、会话标识、请求页面和引用页面等相关信息。日志记录形式如下:
16;1074661208;212.209.160.2;09b611d2583514c458f 8946841f880a5;/ls/?id=139;http://www.shop6.cz/
其主要结构如表1所示。
本文通过取该站点上的一个服务器日志文件,共计353K字节,2978条记录,为了减少算法的计算量以及提高数据挖掘结果的准确性,利用T-SQ语句和SQL Server的SSIS服务功能将原始数据文件进行数据转换净化、代理访问的处理、用户识别、会话识别、链接规范化、排序等数据预处理,然后得到序列数据库,总共是179条记录,107个序列。
通过java编写的GSP算法对该电子商务网站的访问日志进行数据挖掘测试,根据GSP算法,我们将最小支持度设为8,得到了该电子商务网站的频繁访问序列总共计9条,其序列模式挖掘的结果如图2所示:
从运行的结果我们可以很容易看出,用户对该网站的这9种产品相对比较感兴趣,其中最感兴趣的是该网站的Digital cameras产品。
4 结束语
本文利用SQL Server对某电子商务网站的日志进行了数据预处理并产生序列数据库,并通过java编程实现GSP序列模式挖掘算法对其进行测试分析,通过对结果分析可以做出对该网站布局和内容(或产品)调整提供参考,使其更好为其用户提供针对性的服务。
参考文献:
[1]朱鹤祥.Web日志挖掘中数据预处理算法的研究[D].大连:大连交通大学,2009.
[2]汪莉栋. Web日志挖掘中数据预处理算法的研究及实现[D].贵阳:贵州大学,2008.
[3]赵畅,杨冬青,唐世渭.Web日志序列模式挖掘[J]. 计算机应用,2000,20(9):15-18.
[4]李林,崔志明.用户Web日志序列模式挖掘研究[J]. 微机发展,2005,15(5): 119-121.
[5]朱琳玲,胡学钢,穆斌.基于Web的数据挖掘研究综述[J].电脑与信息技术,2002,20(6):45-48.
[6]王璟. Web使用记录挖掘技术综述[J].四川经济管理学院学报,2008,20(1):49-50.
[7]王新,马万青,潘文林.基于Web日志的用户访问模式挖掘[J].计算机工程与应用,2006,21(9):156-158.
[8]刘沛骞,郭海儒,袁玲玲.Web日志挖掘中的用户访问模式识别[J].雁北师范学院学报,2006(2).
[9]邵峰品,于忠清.数据挖掘原理与算法[M].北京:中国水电水利出版社,2003.
[10]毛国群. 数据挖掘原理与算法[M].北京:清华大学出版社,2005.
