
一种Hadoop小文件存储优化方案
2016-02-27 01:53王全民赵小桐雷佳伟
计算机技术与发展 2016年11期
王全民,张 程,赵小桐,雷佳伟
(北京工业大学 计算机学院,北京 100124)
一种Hadoop小文件存储优化方案
王全民,张 程,赵小桐,雷佳伟
(北京工业大学 计算机学院,北京 100124)
Hadoop分布式文件系统(HDFS)适合处理和存储大文件,在处理的文件体积较大时表现出色,但是在处理海量的小文件时效率和性能下降明显,过多的小文件将会导致整个集群的负载过高。为了提高HDFS处理小文件的性能,提出了双重合并算法-即基于文件之间的关联关系和基于数据块平衡的小文件合并算法,能够将小文件的文件体积大小进行均匀分布。通过该算法能够进一步提升小文件的合并效果,减少HDFS集群主节点内存消耗,降低负载,有效降低合并所需的数据块数量,最终能够提高HDFS处理海量小文件的性能。
Hadoop分布式文件系统;小文件;合并算法;文件关联
0 引 言
随着互联网的高速发展,当今社会所产生的数据量在急速增长,据统计目前人类一年产生的数据量的规模就相当于人类进入现代化以前所有历史的总和。2014年国内数据总量约为1.4 ZB,是2012年的3.5倍,预计2020年国内产生的数据总量将超过8.6 ZB[1]。
Hadoop是一个能够对大数据进行分布式处理的软件框架,以一种高效、高扩展性、低成本、高可靠性的方式进行数据处理[2]。Hadoop在互联网领域应用广泛,例如Yahoo使用4 000个节点的Hadoop集群来支持广告系统和Web搜索的研究;Facebook使用1 000个节点的集群运行Hadoop,存储日志数据,支持其上的数据分析和机器学习;百度用Hadoop处理每周200 TB的数据,从而进行搜索日志分析和网页数据挖掘工作;中国移动研究院基于Hadoop开发了“大云”(Big Cloud)系统,不但用于相关数据分析,而且还对外提供服务;淘宝将Hadoop系统应用在存储并处理电子商务交易的相关数据。
物联网、电子商务、社交网络和移动互联网的迅猛崛起,带来的是海量数据的存储问题,尤其在小型文件的存储上,目前还没有十分高效的解决方案[3]。目前存在一些针对大文件研发的文件系统,如EXT4,Lustre,GFS,HDFS等,这些文件系统在架构设计、数据管理和实现策略上都偏重于大文件,而在小文件的存储效率和性能方面就会大幅下降[4]。
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop底层基础架构的存储部分,是分布式计算中数据存储管理的基础,现在已经成为海量数据存储集群部署的主流文件系统。处理大量小文件时,HDFS中用于管理元数据的NameNode节点中的元数据量就会激增,导致NameNode内存空间消耗过大、检索效率降低等问题[5]。
文中提出一种基于文件关联关系与基于数据块平衡的小文件双合并算法,用于优化HDFS在小文件存储中表现出的劣势,使系统更加适合小文件存储。
1 相关工作
对于HDFS存储小文件时面临的诸多问题,目前已经提出一些解决方案:
文献[6]是Hadoop自带的两种解决方案,Hadoop Archive方法可以将小文件归档成一个相对较大的文件并存放在对应的HDFS存档工具中。该方案的优点是能够在一定程度上缓解大量小文件对NameNode内存的消耗,缺点是对于小文件进行归档后,之前的文件需要用户自己删除,创建之后不可更改,如需删除或者增加就必须重新创建归档文件。SequenceFile序列文件是Hadoop提供的第二个小文件解决方案,序列文件用于存储二进制形式的键值对,支持数据压缩。
文献[7]针对WebGIS系统的特点,提出了针对于HDFS小文件存储问题的解决方案。根据地理信息系统(GIS)的特点将数据切分成kB大小的小文件存储在分布式系统中。根据WebGIS数据的关联特性将相邻地理位置信息的小文件合并成一个大的文件进行存储。但是应用面较为狭窄,庞大数量的互联网小文件并没有像GIS小文件一样具有很强的关联性。
文献[8]针对海量的MP3小文件存储在HDFS的情况,提出了利用MP3自身文件所包含的信息,通过归类算法将MP3小文件归并到SequenceFile文件中,同时引入索引机制来解决NameNode的内存瓶颈问题。
文献[9]针对教育资源小文件提出了基于HDFS的存储优化方案,利用教育资源中小文件之间的关联关系,将大量小文件合并成大文件,通过索引和预取机制,缓解了NameNode的内存负担并且提高了Hadoop分布式文件系统对小文件的存储和读取效率。
文献[10]针对HDFS中存储小文件的不足,提出了一种基于DataNode缓存部分小文件元数据的策略。该策略让Client在请求小文件时将大部分的小文件请求交由DataNode处理,当DataNode不能处理请求时交给NameNode进行处理,从而减少NameNode接收请求的次数,提高整个分布式系统的性能,但没有很好地解决NameNode元数据量因众多小文件而猛增的问题。
2 解决方案
2.1 方案设计
已有的小文件合并解决方案大都采用小文件数目达到一个设定阈值就进行合并的方法,这样很容易造成数据块分布不均。文献[11]在合并之前基于大量的历史文件访问日志分析小文件之间的关联关系,然后在文件集合遍历,将该文件与关联文件合并成一个不大于64 M的大文件,然后存储到HDFS。文献[12]尽量将同一文件夹的文件合并到一起,文献[13]也采取了达到合并阈值就进行文件合并的思路处理小文件。文献[14]利用文献图片之间的相关性来合并小文件。这一类的合并算法常以文件总体积溢出为合并条件,会造成合并后的块内存浪费,文件体积分布不均。如图1所示,按照普通算法合并时,数据块的使用率较低。
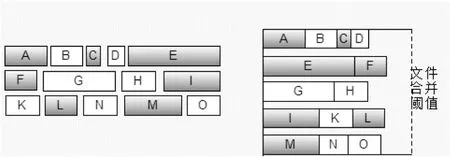
图1 普通文件合并算法过程示意图
2.2 算法设计
文中提出了基于双重合并的小文件合并算法。该算法的核心思想是根据小文件集合的文件体积分布,尽量将同一用户的文件资源首先合并在一起,其次再将文件进行均匀分布,合并成大文件,使每一个数据块得到充分利用(即达到阈值64 M)。相比普通的文件合并,该方案能够保证合并后的大文件不会被分割出多余的块,也不会出现数据块空间使用率过低的情况。该算法能够在一定程度上最大化利用每一个数据块的空间,使文件体积分布均匀,也能够降低NameNode节点的内存负载。其中的小文件合并策略是寻找合适的文件部分来尽可能填充数据块,因此命名为PS算法(Partner Seeking)。
该算法中使用的数据结构有三种:用户文件映射、小文件存储池和小文件合并队列。小文件存储池用于收集用户上传的小文件,是一个可配置的参数,共有m个,用于保证系统有可用的存储池。共有n个小文件合并队列,当队列中的文件总大小达到系统指定的文件大小时,将指定的文件合并后存入HDFS。接下来将介绍文件合并策略与合并条件。
算法执行流程如下:
(1) 根据配置文件创建m个小文件存储池P、n个小文件合并队列和用户文件映射Map。
(2) 用户上传小文件时,先查看是否达到当前文件存储池容量阈值,如果没到,继续上传;如果达到阈值,上传到其他文件存储池。
(3) 对于当前上传的小文件,查看Map中是否有该用户上传的文件,如果有,则合并该用户的小文件(此为第一次合并);如果没有,文件信息加入Map中,Map中的文件按照第一次合并后的文件体积排列。
(4) 文件存储池P达到阈值后,启动合并模块(第二次合并),遍历Map,找出体积最大的文件,如果该文件体积大于合并阈值的1/2,进入步骤(5),如果该文件体积小于合并阈值的1/2,进入步骤(6)。
(5) 将该文件放入当前队列,然后寻找该文件的伙伴文件,即寻找文件体积最接近合并阈值减去当前遍历队列文件总体积的文件,找到伙伴文件后加入到当前队列,然后继续寻找当前队列的伙伴文件直到找不到伙伴文件为止,此时一个队列完成。对该队列进行合并,开启新的队列循环步骤(4),直到队列用完。
(6) 如果当前文件体积小于文件合并阈值的1/2,将当前文件存入当前队列,继续遍历Map找到最大的文件加入到当前队列,直到队列的总体积大于文件合并阈值的1/2,进入到步骤(5)。
(7) 前面的6步就是文件合并阶段。
经过PS算法合并后的图1实例,其合并效果如图2所示。

图2 PS算法文件合并效果
3 实 验
在此实验中,文中的Hadoop集群是由一个NameNode节点、两个DataNode节点构成。实验环境:操作系统为Ubuntu14.04,CPU为Intel(R)Core(TM)i5 2.4GHz,内存为4GB,硬盘大小为320G,搭建了完全的虚拟机分布式Hadoop集群。Hadoop版本为2.5,Java运行环境版本为1.7。HDFS中数据块默认采用64MB,每个数据块的副本数量为2。
为了验证提出算法的可行性,收集了一系列的测试用小文件,测试的文件集合总大小是4.78GB,文件体积小于5MB以下的小文件占所有测试文件集合大小的81%,而5~64MB的文件则用来观察文件合并效果。
3.1 向HDFS导入文件消耗对比实验
图3使用柱状图更为直观地表示了三种导入算法的时间消耗(单位:s)表现对比。经过PS算法合并后的文件总数为77个,正常导入的文件总数为1 640个,采用普通的单文件合并算法合并后的文件总数为87个。三种导入方法的数据块大小采用相同的64 M。通过对比测试实验可以看出,在导入文件消耗方面,PS合并算法导入要比正常导入提升39.4%的效率,和单文件导入的效率基本持平。可以看出,通过PS合并算法进行合并后大大减少了总的大文件数目,相比于单文件合并算法在数据块使用量方面也有一些下降,主要是因为PS合并算法通过文件关联关系和文件体积的重新分布来进行小文件的合并,能够达到比正常导入和单文件合并算法更好的效果。上传文件消耗时间与单文件合并算法基本持平。

图3 小文件导入消耗时间对比
3.2 NameNode节点内存消耗对比
图4使用柱状图的形式更为直观地对比了三种导入算法的名字节点(NameNode)的内存消耗。正常导入NameNode内存消耗为24 600字节,合并后的文件数量为1 640个;单文件合并算法合并导入的NameNode消耗为13 050字节,合并后的文件数量为87个;而PS合并算法合并导入的NameNode内存消耗为11 550字节,合并后的文件数量为77个。通过实验测试相比于正常导入,PS文件合并算法对NameNode节点的内存消耗具有十分显著的效果,节约了95.3%的内存空间。单文件合并算法和PS合并算法都考虑到了数据块大小对于内存消耗的影响,但PS合并算法较之单文件合并算法,NameNode节点内存消耗节省了11.5%。由此可见,通过文件体积分布和利用文件关联关系,PS文件合并算法有更好的效率和空间使用率。
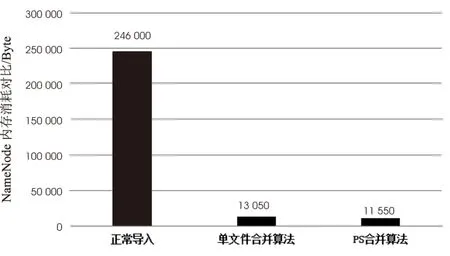
图4 NameNode内存消耗对比
4 结束语
文中提出了一种基于HDFS的小文件合并算法-PS合并算法,能够优化HDFS在小文件存储方面表现出的不足,通过对文件关联关系的挖掘和文件体积的合理分布实现对小文件的合并重组,大幅降低了Hadoop集群中NameNode节点的内存消耗,减少了上传大量小文件所需时间。接下来的工作中可以在文件类型方面进行合并工作的研究,探讨文件类型对于数据处理以及文件合并的影响,以便能达到更好的效果。
[1] 李国琦. 中国产业互联网峰会[EB/OL]. 2015.http://www.sootoo.com/content/548884.shtml.
[2] Finta I,Farkas L,Szenasi S,et al.Buffering strategies in HDFS environment with STORM framework[C]//16th IEEE international symposium on computational intelligence and informatics.[s.l.]:IEEE,2015:297-302.
[3] 杜忠晖,何 慧,王 星.一种Hadoop小文件存储优化策略研究[J].智能计算机与应用,2015,5(3):28-32.
[4] Zhang Q F,Zhang W D,Li W J,et al.Cloud storage system for small file based on P2P[J].Journal of Zhejiang University (Engineering Science),2013,47(1):7-8.
[5] Mackey G,Sehrish S,Wang J.Improving metadata management for small files in HDFS[C]//IEEE international conference on cluster computing and workshops.[s.l.]:IEEE,2009:1-4.
[6] Apache.The homepage of Hadoop[EB/OL].2012.http://Hadoop.apache.org/.
[7] Liu X,Han J,Zhong Y,et al.Implementing WebGIS on Hadoop:a case study of improving small file I/O performance on HDFS[C]//IEEE international conference on cluster computing and workshops.[s.l.]:IEEE,2009:1-8.
[8] 赵晓永,杨 扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构[J].计算机应用,2012,32(6):1724-1726.
[9] 游小容,曹 晟.海量教育资源中小文件的存储研究[J].计算机科学,2015,42(10):76-80.
[10] 江 柳.HDFS下小文件存储优化相关技术研究[D].北京:北京邮电大学,2011.
[11] 李 铁,燕彩蓉,黄永锋,等.面向Hadoop分布式文件系统的小文件存取优化方法[J].计算机应用,2014,34(11):3091-3095.
[12] 张 丹.HDFS中文件存储优化的相关技术研究[D].南京:南京师范大学,2013.
[13] 胡海峰,贾玉辰.一种Hadoop存取海量小文件的优化方法:CN,CN104536959A[P].2015-04-22.
[14] 张春明,芮建武,何婷婷.一种Hadoop小文件存储和读取的方法[J].计算机应用与软件,2012,29(11):95-100.
A Small Hadoop File Storage Optimization Scheme
WANG Quan-min,ZHANG Cheng,ZHAO Xiao-tong,LEI Jia-wei
(School of Computer Science,Beijing University of Technology,Beijing 100124,China)
The performance of Hadoop Distributed File System (HDFS) in dealing with the problem of storing and handling large files is excellent,but the performance and efficiency is down significantly when dealing with a huge number of small files.Too many small files will lead to the high load of entire cluster.In order to improve the performance of HDFS handling small files,the double-merging algorithm is put forward based on the relationship between files and merging algorithm based on the data block balance and used for uniform distribution of file size for small file.The program can further improve the effect of small file merging,decreasing the memory spending of HDFS cluster master node,reducing workload,and effectively declining the number of data blocks combined.Eventually the performance of HDFS is improved when dealing with large small files.
HDFS;small files;merge algorithm;file connection
2016-01-20
2016-05-11
时间:2016-10-24
国家自然科学基金资助项目(61272500)
王全民(1963-),男,副教授,博士,硕士生导师,CCF高级会员,研究方向为网络与信息安全;张 程(1991-),男,硕士研究生,研究方向为分布式系统与网络与信息安全。
http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1113.036.html
TP301
A
1673-629X(2016)11-0041-04
10.3969/j.issn.1673-629X.2016.11.009
猜你喜欢
昆钢科技(2022年4期)2022-12-30
昆钢科技(2022年1期)2022-04-19
昆钢科技(2021年6期)2021-03-09
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
当代陕西(2019年13期)2019-08-20
小学科学(学生版)(2019年4期)2019-05-11
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
电脑爱好者(2015年21期)2015-09-10
