
集对分析相似预测在用水量预测中的应用
2016-03-15 05:58周戎星潘争伟金菊良罗月颖
华北水利水电大学学报(自然科学版) 2016年6期
周戎星, 潘争伟, 金菊良, 罗月颖
(1.安徽新华学院 土木与环境工程学院,安徽 合肥 230088; 2.安徽新华学院 安全与环境评价研究所,安徽合肥 230088; 3.合肥工业大学 土木与水利工程学院,安徽 合肥 230009; 4.合肥工业大学水资源与环境系统工程研究所,安徽 合肥 230009)
集对分析相似预测在用水量预测中的应用
周戎星1,2, 潘争伟1,2, 金菊良3,4, 罗月颖1,2
(1.安徽新华学院 土木与环境工程学院,安徽 合肥 230088; 2.安徽新华学院 安全与环境评价研究所,安徽合肥 230088; 3.合肥工业大学 土木与水利工程学院,安徽 合肥 230009; 4.合肥工业大学水资源与环境系统工程研究所,安徽 合肥 230009)
准确预测用水量可为水资源管理和规划提供科学依据。将基于集对分析的相似预测模型应用于用水量预测中,并对山东省2010—2014年的用水量进行了预测;将预测结果与GM(1,1)预测方法、BP神经网络预测方法以及集对分析聚类预测方法的预测结果进行了对比。结果表明:基于集对分析的相似预测方法的相对误差较小,预测精度较高,在用水量预测中具有一定的应用价值。
用水量预测;相似预测;集对分析;山东省
随着经济社会的快速发展和人口的增长,用水量不断增加,加之水污染问题日趋严重,水资源短缺已成为制约中国经济持续健康、快速发展的瓶颈[1-2]。科学、准确地预测区域用水量,可为区域水资源规划和管理提供重要参考。同时,为供水系统优化调度提供相关依据,促进区域供水规划和水资源开发利用总体规划的发展,为国民经济的平稳较快发展提供可靠的参考依据[3]。
自20世纪60年代以来,国内外专家学者就区域用水量预测问题进行了研究,并取得了丰硕成果。目前,用水量预测的常用方法有线性回归法[4]、时间序列法[5]、灰色预测法[6]、神经网络法[7]等。而基于集对分析的相似预测模型[8](Set Pair Analysis-based Similarity Forecast model,SPA-SF)是用联系数来测度历史样本之间的相似性,进而采用相似预测(Similarity Forecast,SF)方法来预测用水量未来某一时期的发展趋势和状况,这是一种新颖的预测方法。本文将SPA-SF引入用水量预测研究中,选取山东省为研究对象,采用该省1997—2009年的用水量历史数据预测该省2010—2014年的用水量。
1 集对分析相似预测模型
相似预测是按照原因相似从而导致结果相似的原则,通过一定的方法,找出历史样本中与预测年最相似的样本,并运用最相似样本的结果对预测年进行预测的一种预测方法[8]。基于相似预测的用水量预测模型的基本思路是:用水量驱动因子变化相似,由此而引起的用水量变化也相似。这就要求准确地识别出影响用水量变化的主要驱动因子,并采用定量分析的方法对历年样本之间的相似性进行度量。集对分析是赵克勤于1989年提出的利用联系数处理系统确定性与不确定性相互作用的系统分析方法,利用它可以有效地解决驱动因子识别问题和相似性度量问题,进而可建立SPA-SF模型。SPA-SF的建模步骤[8]如下:
1)对历史样本数据进行平稳化处理。
由于用水量及其驱动因子与人类活动关系密切,历年样本数据存在一定的趋势性。而相关预测方法仅适用于平稳的历史样本数据。为此,本文采用用水量及其驱动因子的年增长率进行建模。
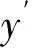
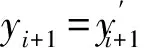
(1)
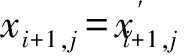
(2)
2)采用互相关系数统计假设检验与集对分析检验相结合的方法,确定影响用水量年增长率变化的主要驱动因子。
①互相关系数统计假设检验。xi,j与yi的互相关系数rj为[8]
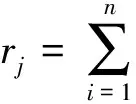

(3)
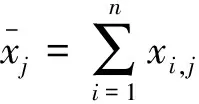
根据抽样分布理论,当rj满足式(4)时,驱动因子年增长率xi,j与用水量年增长率yi显著相关[8]:
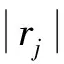
(4)
式中:α为显著性水平;tα/2为自由度为n-2、显著性水平为α时的t分布双侧检验临界值;rmin为xi,j与yi显著相关时要求相关系数的最小值。
②集对分析检验。将用水量年增长率Y与各驱动因子年增长率Xj建立集对H(Y,Xj)。设集对H所具有的特性总数为N,其中Y和Xj共有的特性个数为Sj,Y和Xi对立的特性个数为Pj,此外Y和Xj既不对立也不共有的特性个数为Fj,则该集对的联系度为[9,11]:
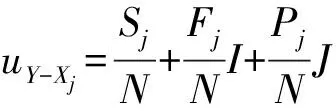
(5)
式中:Sj/N称为同一度,记为aj,它表示集合Y和Xj之间的相关结构存在正相关趋势的比例;Fj/N称为差异度,记为bj,它表示集合Y和Xj之间的相关结构存在不确定的相关关系的比例;Pj/N称为对立度,记为cj,它表示集合Y和Xj之间的相关结构存在负相关趋势的比例;I为差异度系数,在[-1,1]中取值;J为对立度系数,一般取-1。
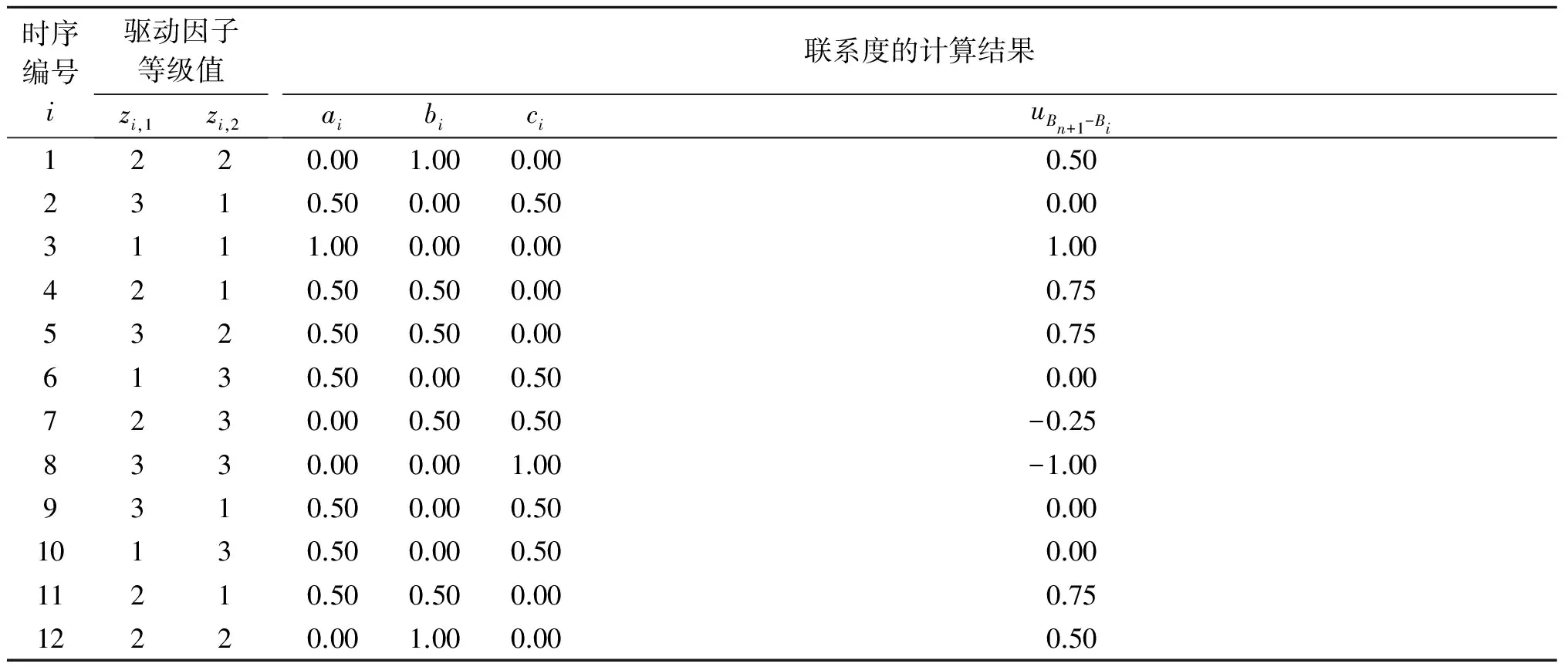
当aj>cj时,表示变量之间的关系为正相关;当aj bj<0.5, (6) 则表示变量间的关系是相对确定的;反之,则表示变量间的关系是相对不确定的。为计算联系度,可将yi和xi,j分别进行如下等级符号化处理[8]: (7) (8) 同时满足式(4)和式(6)的驱动因子即为影响用水量年增长率的主要驱动因子。 3)确定历史样本主要驱动因子年增长率与预测年主要驱动因子年增长率之间的联系度。 uBn+1-Bi=ai+biI+ciJ,uBn+1-Bi∈[-1,1]。 (9) 式中:ai为Bn+1和Bi的对应分量处于同一等级的比例;bi为Bn+1和Bi的对应分量处于相邻等级的比例;ci为Bn+1和Bi的对应分量处于相隔等级的比例;i=1,2,…,n。 uBn+1-Bi越接近于-1,表示Bn+1与Bi的差异性越大;uBn+1-Bi越接近于1,表示这两因子集间的相似性越大。 4)对预测年的用水量进行预测。 从n个历史样本中选取与Bn+1相似性最大的K个历史样本,对选取的K个历史样本所对应的相对隶属度vn+1,i进行归一化,得归一化值wi,以此为权重进行加权平均,得到预测年用水量年增长率yn+1的预测值[8]: (10) 式中:k1,k2,…,kK为K个与Bn+1最相似的历史样本的序号;vn+1,i为可变模糊集“Bn+1与Bi间的相似性”的相对隶属度[11],即 vn+1,i=0.5+0.5uBn+1-Bi。 (11) 由式(1)—(10)可得预测年的用水量的预测值。 山东省经济发展状况良好,农业发达,水资源消耗较大[13]。水资源总量少、人均占有量不足以及水资源时空分布不均是山东省水资源的主要特点,水资源短缺成为制约山东省国民经济和社会快速发展的重要因素。准确预测山东省的用水量有利于山东省制定合理、有效的水资源利用规划,调节供需平衡,保障经济社会持久、稳定地发展。根据统计年鉴资料,用水量包括生产用水、生活用水、生态用水3部分。分别选取灌溉用水定额、万元工业增加值用水量、旅游业收入、总人口、园林绿地面积作为表征第一产业、第二产业、第三产业、生活、生态用水的驱动因子。从山东省水资源公报和统计年鉴中获取1997—2013年的相关数据,由式(1)和式(2)得年增长率,结果见表1(受版面所限,仅保留3位有效数字)。将1998—2009年的相关因子的年增长率作为历史数据,对2010—2014年用水量的年增长率进行预测。 记灌溉用水定额年增长率为xi,1,万元工业增加值用水量年增长率为xi,2,总人口年增长率为xi,3,旅游业总收入年增长率为xi,4,园林绿地面积年增长率为xi,5,用水量年增长率为yi。 由式(3)得yi与xi,1、xi,2、xi,3、xi,4、xi,5的相关系数,计算结果见表2。在显著性水平α=0.05时,允许的最低相关系数值为rmin=0.576 0,根据式(4)知,xi,1和xi,5与yi在统计上显著相关。根据式(5)、式(7)和式(8)计算出yi与xi,1、xi,2、xi,3、xi,4、xi,5的联系度,见表2。 由前述可知,同时满足∣r∣>rmin与bj<0.5的驱动因子xi,j,为影响用水量年增长率变化的主要驱动因子。由表2所列的计算结果可看出,主要驱动因子为xi,1和xi,5,即影响用水量年增长率的主要因子为灌溉用水定额的年增长率和园林绿地面积年增长率。 表1 山东省用水量及各驱动因子的年增长率 表2 各驱动因子年增长率与用水量年增长率的联系度和相关系数计算值 建立预测年用水量yn+1的主要驱动因子的年增长率集合Bn+1与历史样本的用水量yi的主要驱动因子年增长率集合Bi之间的集对H(Bn+1,Bi),i=1,2,…,12。I和J分别取0.5和-1.0,按式(9)计算得各联系度值uBn+1-Bi,见表3。 选取与Bn+1最相似的4个历史样本,即时序编号为3、4、5、11的历史样本,以其uBn+1-Bi对应的相对隶属度vn+1,i的归一化值wi为最相似的历史样本的用水量yi的权重,由式(10)得2010年用水量年增长率yn+1的预测值,与2009年用水量相比,还原得2010年用水量的预测值,见表4。 为了验证基于集对分析的相似预测模型的预测精度和可靠性,表4同时列出了GM(1,1)预测方法、BP神经网络预测方法以及集对分析聚类预测的结果[14]。 表3 用水量年增长率驱动因子等级值和联系度计算结果 表4 2010年用水量预测结果及与其他方法的对比 为了进一步验证该方法的可行性,采用上述方法分别预测山东省2011—2014年的用水量年增长率,并与实际值进行对比,结果见表5。 表5 山东省2011—2014年用水量年增长率实际值与预测值对比 1)2010年山东省用水量的预测结果的相对误差为-1.48%,相较于集对分析聚类预测方法略大,但优于GM(1,1)和BP神经网络的预测结果,预测精度较好。 2)由2011—2014年的预测结果可知,基于集对分析的相似预测结果与实际值相差较小,进一步验证了该方法用于用水量预测的可靠性。 3)基于集对分析的相似预测方法,通过计算相关系数和不确定相关系数,筛选出影响用水量年增长率的主要因子;定量计算预测年的用水量年增长率的主要驱动因子集Bn+1与历史样本的主要物理因子集Bi之间的相似性,选取多个相似性最大的历史样本的用水量年增长率,对其进行加权平均计算,得到预测年用水量年增长率的预测值。预测结果表明:基于集对分析的相似预测方法计算简便,实用性强,预测精度较高,在区域用水量预测中具有应用价值。 [1]魏东岚,高杰,关伟.大连城市用水变化及其驱动因子分析[J].辽宁师范大学学报(自然科学版),2005,28(4):480-483. [2]胡蓓琳,潘争伟,金菊良,等.基于集对分析模型的巢湖流域水资源系统脆弱性评价[J].水电能源科学,2013,31(10):25-29. [3]孙志强.需水预测的意义和发展[J].农村经济与科技,2014,25(4):105-106. [4]ZHANG D W,NI G H,CONG Z T,et al.Statistical inter-pretation of the daily variation of urban water consumption in Beijing,China[J].Hydrological Sciences Journal,2012,59(1):181-192. [5]纪长顺.天津市区2000 年需水量预测[J].天津建设科技,1994(3):14-20. [6]徐洪福,袁一星,赵洪宾.灰色预测模型在年用水量预测中的应用[J].哈尔滨建筑大学学报,2001,34(4):61-64. [7]ODAN F K.Hybrid water demand forecasting model associating artificial neural network with fourierseries[J].Journal of Water Resources Planning and Management,2012,138(3):245. [8]金菊良,魏一鸣,王文圣.基于集对分析的水资源相似预测模型[J].水力发电学报,2009,28(1):72-76. [9]赵克勤.集对分析及其初步应用[M].杭州:浙江科学技术出版社,2000:15-19. [10]田景环,于昊明,亢晓龙.改进的集对分析法在水质评价中的应用[J].华北水利水电大学学报(自然科学版),2015,36(6):20-23. [11]张金萍,林小敏,徐波.北京市降雨量与参考作物腾发量多时间尺度的集对分析[J].华北水利水电大学学报(自然科学版),2016,37(4):54-58. [12]陈守煜.水资源与防洪系统可变模糊集理论与方法[M].大连:大连理工大学出版社,2005:209-215. [13]贾程程,张礼兵,徐勇俊,等.基于信息熵的山东省用水结构与产业结构协调性分析[J].水电能源科学,2016,34(5):17-19. [14]袁朝阳,吴成国,张礼兵,等.集对分析聚类预测法在区域用水量中的应用[J].华北水利水电大学学报(自然科学版),2015,36(4):32-35. (责任编辑:乔翠平) Application of the Method of Set Pair Analysis Based on Similarity Forecast Model in Water Consumption Prediction ZHOU Rongxing1,2, PAN Zhengwei1,2, JIN Juliang3,4, LUO Yueying1,2 (1.School of Civil and Environmental Engineering, Anhui Xinhua University, Hefei 230088, China; 2.Institute for Environment and Security Assessment, Anhui Xinhua University, Hefei 230088, China; 3.School of Civil and Hydraulic Engineering, Hefei University of Technology, Hefei 23009, China; 4.Institute of Water Resources and Environment Systems Engineering, Hefei University of Technology, Hefei 230009, China) Accurate prediction of water consumption can provide a scientific basis for water resource management and planning. In this paper, a set pair analysis based on similarity forecast (SPA-SF) model was applied to the prediction of water consumption, and the water consumption from 2010 to 2014 in Shandong Province was forecasted. The prediction results were compared with that predicted by GM (1,1) prediction method, BP neural network prediction method and set pair analysis method. The results show that the relative error of SPA-SF is relatively small and the prediction accuracy is high, and SPA-SF has certain application value in the prediction of water consumption. prediction of water consumption; similarity prediction; set pair analysis; Shandong Province 2016-07-21 国家重点研发计划项目(2016YFC0401305);国家自然科学基金项目(51309004,51309072,51579059);安徽省高等学校自然科学研究项目(KJ2016A302);安徽新华学院科研团队项目(2016td013)。 周戎星(1990—),女,安徽合肥人,助教,硕士,主要从事水资源系统工程方面的研究。E-mail:594971550@qq.com。通信作者:金菊良(1966—),男,江苏吴江人,教授,博士,博导,主要从事水资源系统工程方面的研究。E-mail:JINJL66@126.com。 10.3969/j.issn.1002-5634.2016.06.012 TV213.4 A 1002-5634(2016)06-0067-05


2 实例分析




3 结语
猜你喜欢
山东交通科技(2022年3期)2022-08-05
中国集体经济(2022年9期)2022-04-12
——山东省济宁市老年大学之歌
老年教育(老年大学)(2021年10期)2021-11-12
陕西水利(2021年10期)2021-11-08
小学科学(学生版)(2021年5期)2021-07-22
小学科学(2021年5期)2021-06-24
今日农业(2020年14期)2020-12-14
瞭望东方周刊(2018年45期)2018-11-28
中国房地产·市场版(2017年10期)2018-01-15
时代金融(2016年36期)2017-03-31
