
基于Web的中文期刊查收查引跨库检索系统研发
2016-03-21 10:51晓梅
中华医学图书情报杂志 2016年6期
, , ,,,晓梅,
查收查引又称为论文收录及被引用检索,主要通过文献题名、作者、作者单位、期刊名称、发表时间等检索字段查找论文被数据库收录及引用情况,并依据检索结果出具引证报告,为科研评价提供依据[1]。
作为国内科研绩效评价的重要工具,该服务已成为国内高校图书馆等信息服务机构提供的基础信息服务。据统计,96所(占81%)“211”工程大学图书馆开展了这项业务,而且业务量逐年快速增长[2]。
国内开展的引证检索服务主要依靠手动方式完成,需要查收查引人员在多种引文数据库中重复检索文献收录和引用情况,对检索结果进行去重去自引、转换格式后出具检索报告。存在多数据源检索导致的工作量倍增[3]、录入错误与格式不规范造成的查重困难、手工生成标准报告费时费力、检索工作重复低效等问题。因此,必须利用软件工具辅助人工完成查收查引并自动统计与整理形成引证报告[4]。
查收查引系统较早可追溯到北京大学图书馆的论文查收查引工具[3,5]。利用网页分析技术对SCI、EI数据源进行自动网络查询,如中国科技大学图书馆利用Excel和EndNote Web提高论文查收查引的工作效率[6];中国科学院软件研究所研发的“引证报告自动生成原型系统”[4,7],可对SCI数据库统计区分自引与他引。
基于国内中文数据源查收查引的需要,解放军医学图书馆开发了基于Web的查收查引跨库检索系统。它通过页面分析技术对CNKI、CSCD、CMCI、万方等多个异构中文期刊引文数据库进行检索,功能覆盖收录检索、引文检索、生成引证报告等环节,并结合精确匹配和模糊匹配,通过Levenshtein编辑距离计算相似度对重复文献进行查重去重。
1 跨库检索系统架构与步骤
1.1 系统架构
跨库检索系统架构如图1所示。三层体系结构主要由客户端Web页面、服务器端检索服务总线、异构多数据源组成,通过检索服务总线屏蔽各个异构数据源的位置、检索服务接口等细节差异,通过客户端Web页面提供检索入口和结果展示。
客户端Web页面是用户进行检索的界面和入口,用户通过检索界面登录到跨库检索系统,输入检索条件如题名、作者、作者单位、刊名、年代范围,显示检索结果并进行人工整理。
服务器端检索服务总线是系统的核心,接收来自客户端Web页面的检索条件,按照异构数据源的要求将检索条件转换成新的检索表达式,并转发给多个异构数据源进行检索。获得异构数据源返回的检索结果后,检索服务总线通过页面分析提取文献元数据,结合精确匹配和模糊匹配,检测相似文献进行数据分组合并或去重排序,最后将得到的检索结果返回给客户端Web页面。
异构多数据源是跨库检索系统的基础。异构数据源数据库具有不同的资源覆盖范围,使用不同的数据格式、检索方式。服务器端检索服务总线通过数据源配置,从异构多数据源获得检索结果。
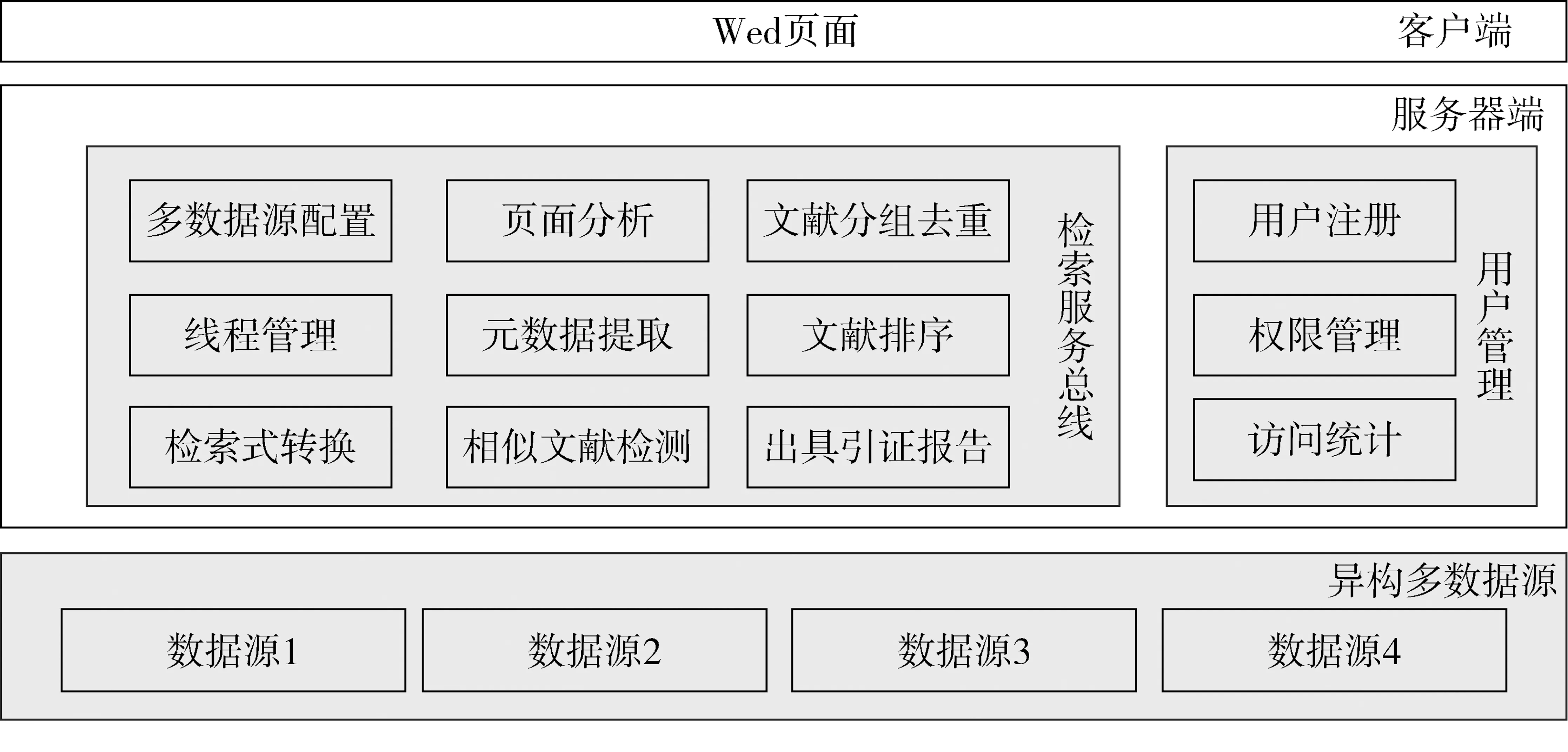
图1查收查引跨库检索系统架构
1.2 主要步骤
查收查引跨库检索系统主要操作步骤如下。
查收查引工作人员在客户端Web页面输入文献题名、作者、作者单位、期刊名称、发表时间等检索字段,并提交检索请求进行收录检索。服务器端检索服务总线获得Web页面提交的检索请求后,根据多数据源配置,将检索请求转换成符合各个异构数据源要求的检索表达式,通过多线程并发检索多个异构数据源。异构数据源根据提交的检索表达式进行检索,并将检索结果返回检索服务总线。检索服务总线接收各异构数据源的检索结果后,通过页面分析提取检索结果中的元数据,结合精确匹配与模糊匹配,将题名、第一作者、来源期刊、出版年份相同的分为一组,将检索结果返回给客户端Web页面,同时显示该文献的来源数据库。查收查引工作人员查看收录检索结果,选择部分结果文献,继续提交引文检索请求。检索服务总线将引文检索请求通过多线程转发给各异构数据源,异构数据源再将引文检索结果返回给检索服务总线;检索服务总线接收各异构数据源返回的引文信息,对引文检索结果进行相似性检测比对去重,经去重和排序后,以统一格式将结果返回客户端Web页面。最后查收查引工作人员由Web页面提交请求,生成格式规范的引证报告。
2 查收查引跨库检索系统的功能与实现
系统采用.NET框架作为开发平台,使用标准的Internet协议创建分布式Web应用,使用IIS服务器为应用提供运行环境。用户登录到系统后显示的Web页面如图2所示。系统缺省对中国知网(CNKI)、万方数据、中国科学引文数据库(CSCD)、中国生物医学期刊引文数据库(CMCI)4个数据源进行统一检索,用户也可只对其中的部分进行查收查引检索。
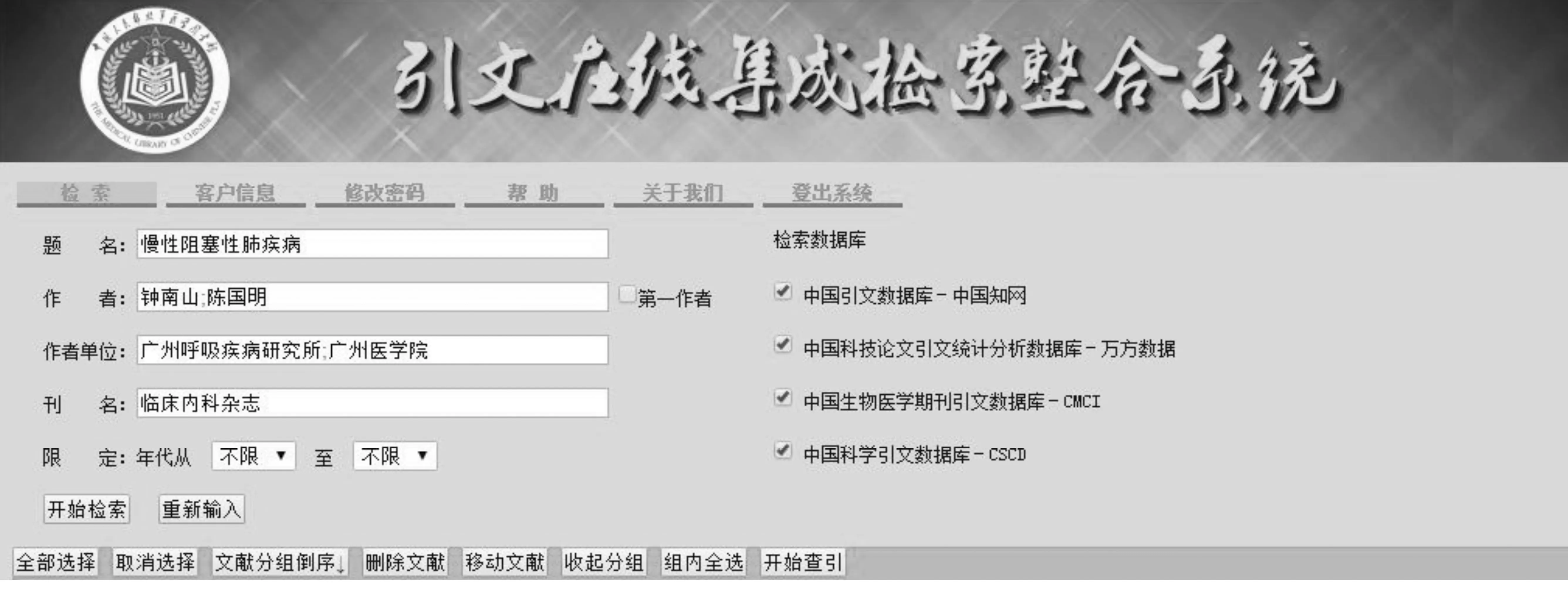
图2 系统Web页面
检索分为以下两个步骤。
第一步是收录检索。用户登录后,输入检索条件,点击“开始检索”向服务器发出检索请求。检索服务总线根据配置信息,把检索条件转换成对应于不同数据源的实际检索条件,并发地向所有数据源检索系统发出检索请求。数据源检索系统完成检索任务后将检索结果传回检索服务总线,然后总线从各数据源返回的检索结果中提取元数据,按“题名+第一作者+刊名+年份”进行分组,将不同数据源的同一篇文献分到一个文献组内。例如,检索广州呼吸疾病研究所的钟南山于2005-2015年发表在《中华医学杂志》上的关于“慢性阻塞性肺疾病”论文收录及被引情况。从图3可以看出,多个数据源检索的检索结果被分成了多个组,每个组代表1篇文献。

图3收录检索条件与结果页面
第二步是选择结果文献进行查引。勾选图3中“文献分组:文献2”,选择题名为 “简易太极拳锻炼对慢性阻塞性肺疾病患者运动耐力和生活质量的影响”分组中的3篇文献,点击“开始查引”则该篇文献的被引情况会按“题名+第一作者+刊名+年份”去重排序后显示(图4)。

图4引文检索结果页面
经检索服务总线自动整合去重后,还有部分引文因存在录入环节的格式错误需要人工干预对引文列表进行审查去重,最后形成图 5所示的引证报告,用户可直接输出或下载。

图5 引证报告
3 系统的主要关键技术
3.1 页面分析方法
跨库检索是以多个分布式异构数据源为对象的检索系统[8]。系统提供统一的检索界面,用户输入检索条件后,系统将用户的检索条件转化为不同分布式异构数据源的检索表达式,并发检索多个分布式异构数据源。由于未获得后端数据源厂商可公开访问的API接口,跨库检索系统只能通过页面分析方法对多个后端数据源进行集成检索。页面分析方法通过打开网络流量分析工具,抓取http请求与响应数据进行分析比对,找到参数部分,然后将新参数封装进http请求并发送,接收到http响应后对html页面进行分析并提取元数据。该方法虽适用于所有的Web系统的集成,但当后端数据源页面发生变化时应及时调整。
通过firefox插件的firebug进行网络流量分析。首先用firefox浏览万方专业检索页面,启用firebug进行网络流量监测抓取,输入检索表达式如“题名:(慢性阻塞性肺疾病) * 创作者:(钟南山) * 作者单位:(广州呼吸疾病研究所) * 期刊-刊名:(中华医学杂志)”,点击“检索”,通过firebug中的网络面板,对http请求与响应进行分析。基于网络流量分析,检索条件对应的万方系统http请求详见表1。

表1 对应的万方系统http请求
从万方页面源代码可看出,编码使用的是UTF-8,因此中文字符还需转换为UTF-8格式。然后发出http请求并得到http响应。接收到http响应后通过html页面查看源代码,查看包含的检索结果文献,也可利用firebug直接找到结果文献部分。然后利用XPATH和正则表达式匹配进行页面数据分析,找到有效信息,部分提取出检索结果文献的元数据包括题名、作者、刊名、年份、卷期、文献类型、被引次数、URL地址。引文检索可直接通过URL地址访问结果文献,通过页面分析提取引证文献元数据。3.2 相似文献检测
相似重复记录的检测与消除是跨库检索的重要功能,也是多数据源合并研究的热点[9]。多数据源采集的文献数据需要结合精确匹配和模糊匹配方法,由系统有效检测重复文献,自动将相似度高的文献归类到一个文献组,不同的文献归类到不同的文献组。相似文献检测算法伪代码如下:

其中,compare ()函数用于比较两篇文献的相似性,相似文献被归于同一组。用于比较的文献元数据从数据源的http响应中提取,包括题名、作者、刊名、年份。文献分组与去重时,可用“年份+第一作者+刊名”进行精确匹配。文献题名通常包含中文字符、英文字符、上下标、分隔符(空格、下划线、中划线)、特殊字符(拉丁字母等)、标点符号等,在录入时容易受全角半角、录入错误等影响,应先进行格式转换预处理后采用模糊匹配,即采用Levenshtein算法计算两个题名字符串之间的编辑距离。
4 结语
引证报告是重要的检索评价工具。通过引证报告可了解文献的被引用情况,为科研人员客观了解自身的学术影响力,提供公正、合理、科学、客观的评价依据,在科研管理和科学评价方面有重要的作用。解放军医学图书馆在原有C/S系统基础上[10]开发的基于Web的中文期刊查收查引跨库检索系统,使用户不再需要安装客户端软件,提高了软件适应性。根据后端数据源的变化调整了页面抓取过程。模糊匹配采用编辑距离计算相似度进行相似性文献检测分组与去重,输出格式统一规范的引证报告。
系统通过跨库检索屏蔽异构数据源的差异,使用户能通过统一的客户端Web页面同时检索多个异构数据源,通过页面分析方法转换检索表达式并发检索后端多数据源,通过页面元数据提取和相似文献检测对文献进行分组和去重排序,自动生成统一格式的引证报告,简化了查新查引工作人员的工作,减少了人工错误和重复性劳动,提高了工作效率。目前该系统已经在医院、图书馆、研究所等多家机构推广使用。从用户使用效果和查收查引的发展来看,系统还有需要完善的地方,主要体现在只集成检索了中文引文数据源,未将SCI、EI、ISTP等外文数据源集成进来,缺少区分自引他引的功能。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
文化创新比较研究(2019年33期)2019-12-26
铁道通信信号(2019年12期)2019-05-21
自然资源信息化(2019年3期)2019-03-29
商周刊(2019年1期)2019-01-31
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中国洗涤用品工业(2017年2期)2017-04-16
决策与信息(2016年30期)2016-11-26
通信电源技术(2016年6期)2016-04-20
