
基于MATLAB转置矩阵的学生学习成绩预警快速算法
2016-03-22 21:59宋绍云陈一民
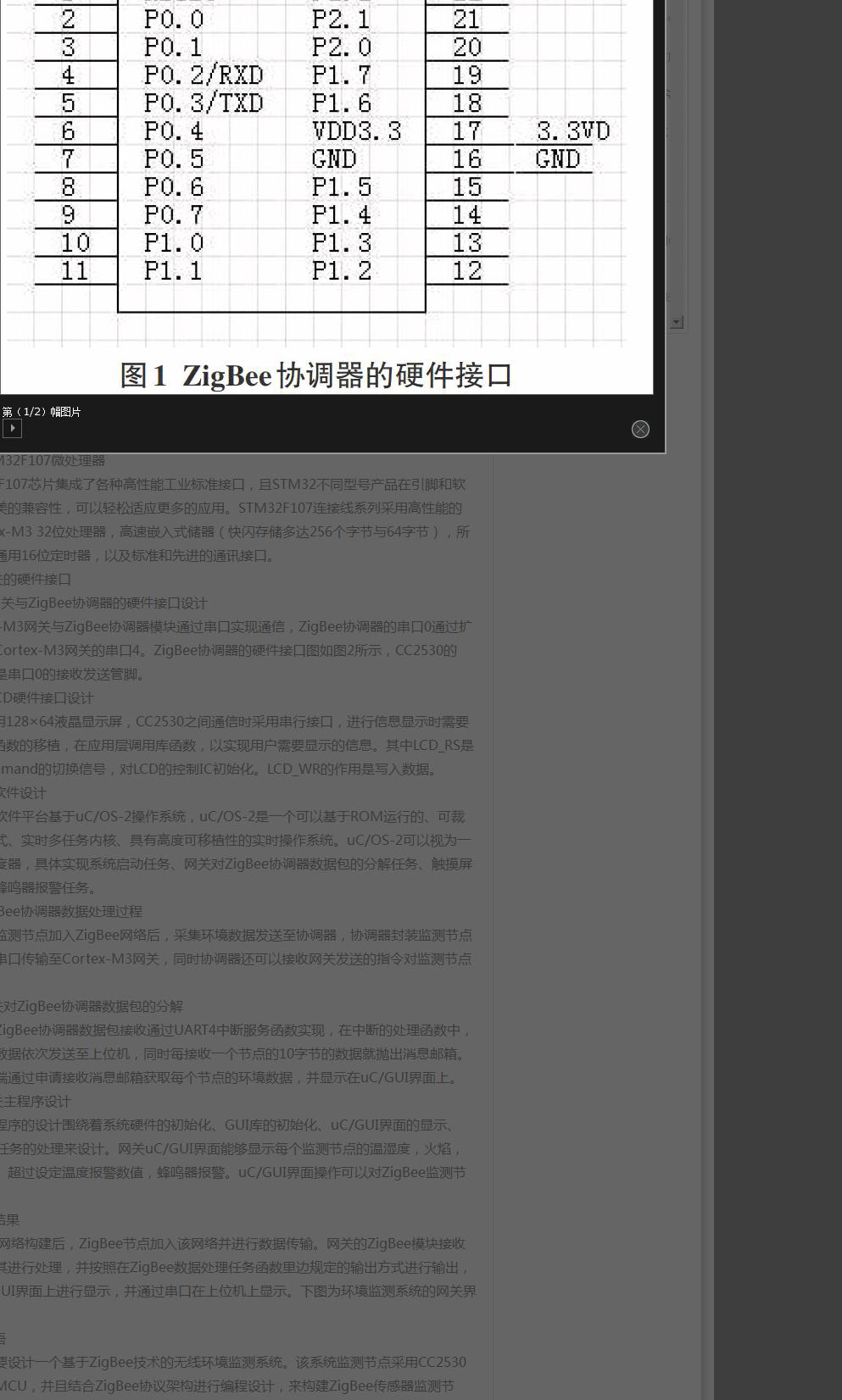
电脑知识与技术 2016年2期
宋绍云 陈一民


摘要:通过对目前基于矩阵的关联规则挖掘算法进行分析,提出一种更加高效的学生学科成绩的关联规则挖掘算法,通过实际案例进行对比,证明所提出的算法在学生成绩预警的关联规则挖掘中具有明显的效果。
关键词:MATLAB;转置矩阵;关联规则;学生成绩;快速算法
中图分类号:TP391.3 文献标识码:A 文章编号:1009-3044(2016)02-0200-04
Abstract: Through the current mining association rules based on matrix analysis algorithms, association rules proposed a more efficient algorithm for mining student academic performance, comparing actual cases, proves that the proposed algorithm has obvious warning in association rule mining in student achievement Effect.
Key words: MATLAB; transposed matrix; association rules; student achievement; fast algorithm
1 引言
学生成绩预测是学校教学管理的关键因素,随着招生规模的扩大,高校教学管理中积累大量学生的各个学科的成绩数据,这些数据中隐含了大量的学生学习情况的信息,充分利用数据挖掘,发现成绩中隐含在学科之间成绩的知识信息,对学生各个学科的未来学习成绩进行预测预报,将是高等学校教学管理的重要研究和应用。
提出一种基于MATLAB的学生成绩预警关联规则挖掘的关键算法,使用该算法所挖掘的学生预警规则集,生成预警信息,在用户设定的支持度下,通过在MATLAB下导入Excel学生成绩,并使用比特矩阵运算,获得学生成绩预警规则,对高校的素质教育和创新人才的培养等方面具有重要的作用和意义。
2 目前矩阵算法分析
文献[1]提出的基于矩阵的关联规则算法挖掘算法,将Apriori算法的剪枝与矩阵联系起来,这种方法只需扫描一次数据库,并且无需候选集Ck,即可得到频繁集Lk,从而大大提高了算法的效率,在生成关联规则中,利用了概率论的基本性质,也大大减少了计算量。但该算法在生成K-项频繁集时仍然采用了Apriori算法,降低了执行效率。
文献[2]提出的算法,由m个任务和n个项目来构建m×n的布尔矩阵,该算法需要先构造一个2维行向量,其中元素均为“1",将该2维行向量与候选2项集中的每个项集所组成的向量进行内积运算得到各项集的支持数,通过与支持度比较从而得到频繁2项集;在频繁2项集连接生成候选3项集之前,对频繁2项集进行一次裁剪,利用得出的推论删除掉不可能成为频繁3项集的项目元素,这将减少生成候选3项集的规模。依次类推,在求第k-项集的支持度时候,构造k维向量与各个k项候选集组成的向量进行内积运算,同时在连接生成k+I项候选集时,先对k项集进行裁剪。该算法需要进行大量的内积运算,且需要通过与支持度比较从而得到频繁集,消耗了大量的CPU时间和内存空间。
文献[3] 首先扫描数据库生成对应的初始矩阵;其次,利用分析得到的频繁项集的大小对矩阵进行修剪;然后,直接生成频繁k项集,通过矩阵向量相乘后相加得到待生成k项集的支持度。在算法确实提高了获得频繁k项集的效率,但对矩阵进行修剪还可以进行更高效修剪。
文献[4]算法引入了两个矩阵,一个矩阵用于映射数据库,另一个用来存储2-项频繁集相关信息。该算法在剪裁事务矩阵时,确实提高了算法的效率。但在求K-项频繁集时,需要对K个项目的映射矩阵中的列向量做内积运算,降低了算法的效率。
3 基本概念
3.1 关联规则
(1) 关联规则:设[I={I1,I2,…,In}]是n个不同项目的集合,事务数据库[D={T1,T2,…,Tm}],其中[Ti={Ii1,Ii2,…,Iik}],并且[Iij∈I],关联规则是形如[X?Y]的蕴含式,其中[X,Y?I],且[X?Y=Φ]。
(2) 项目集的支持度:[D]中支持项目集[X]的事务数称为[X]的支持数,记为[Count(X)]。设[D]中的总事务数位[D],则[Sup(X)=Count(X)/D]称为项目集[X]的支持度。
(3) 关联规则的支持数与支持度: 数据库[D]中支持项目集[X?Y]的事务数称为关联规则[X?Y]的支持数,记为[Count(X?Y)],[Count(X?Y)/D],称为规则的支持度,记为[Sup(X?Y)]
(4)项集合:包含k个项的项集称为k-项集。
(5) k-项频繁集:满足最小支持的k-项集。
(6) 强关联规则:同事满足最小支持度阀值和最小置信度阀值的规则。
关联规则的挖掘就是要发现满足用户给定最小支持度和最小置信度的所有条件的蕴含式,即强关联规则。
3.2 比特矩阵
设事务数据库中有m条记录和n个不同的项,为此构建一个由m+1行和n+1列组成的事务矩阵[M?m+1?×?n+1?],并将矩阵各个元素初始化为0。
扫描事务数据库并计算事务矩阵[M],其中[Mij=0,Ij∈Ti1,Ij?Ti,i=1,2,…,m;j=1,2,…,n]。计算后的事务矩阵[M]称为事务比特矩阵。矩阵的最后一列的[Mi(n+1)]是第[i]行的“1”的个数,表示事务[Tj]的长度,即[Tj]包含的项目数。矩阵最后一行的[M(m+1)j]是第[j]列“1”的个数,表示项目[Ii]的支持数。
4 转置矩阵算法
4.1 算法设计
设事务数据库为:[D={T1,T2,…,Tn}], 项目集为:[I={I1,I2,…,Im}],最小支持度为minsup,最小置信度为minconf。
算法步骤如下:
(1)构建事务比特矩阵,并获得1-项频繁集
根据[D={T1,T2,…,Tn}]和[I={I1,I2,…,Im}]创建n+1行m+1列事务比特矩阵[M],方法如上所述。[M]的最后一行的数值是所在列项目的支持数,大于minsup所有列所在的项目就组成了1-项频繁集。最后一列的数值时事务的长度,即包含项的数目。
(2)剪裁事务矩阵[M]
把[M]最后一行数值小于minsup所在的列删除,且删除最后一列数值小于k(k>=2)的行,重新计算[M]的最后一行和最后一列的数值。
(3)利用转置矩阵计算2-项频繁集
[Lm×m=MTm×n×Mn×m],该矩阵中上三角中的数值是组成2-项频繁集的支持数,主对角线上的数值是1-项频繁集的支持数。根据上三角矩阵中数值大于minsup所在的行列项目组合可获得2-项频繁集。
(4)剪裁2-项频繁集,生成k-项频繁集(k>2)
定义1:若[k]-项集[X={i1,i2,…,ik}]中存在一个项[j∈X],[j]表示为[Lk]中包含[j]的频繁项集的个数,如果[j 证明:假设[X]是[?k+1)]-项频繁集,则它的[k+1]个[k]-子集均在[Lk]中。则在生成的[k+1]个[k]-子集中,每一个项目[j∈X]共出现[k]次,任给[j∈X]均有[j>k].因此假若出现[j 根据以上性质对k-项频繁集进行剪裁:首先对[Lm×m]的矩阵进行处理,把矩阵的对角线和下三角元素设置为0,可以用MatLab的函数triu(triu(L)-tril(L))实现,把上三角矩阵中若数值大于minsup的元素设置为1,否则设置为0,可以用MatLab的函数L(L 把A中数值小于k的所对应的列删除,可以使用Matlab函数L(:,n)实现,其中n为要删除的列号。根据矩阵L中的1所在行的组合就可以得到k-频繁集。它们的支持数可以根据事务比特矩阵所在的列的内积得到。 以上算法不需要产生大量的候选集合,挖掘频繁集的时间效率和空间效率较高,下面给出实例,并进行了分析。数据来自多年的本校教务处的学科成绩数据,经过处理获取部分数据进行计算。把成绩大于等于60分的在比特矩阵中设置为1,成绩小于60分的设置为0。各学科的表示:高数Ⅰ—A,高数Ⅱ—B,计算机网络—C,数据结构—D,C语言—E,路由与交换—F。如表1所示。 把图4的矩阵进行k-1行的内积运算,把计算结果等于k-1的行项目和列项目组合就可与得到k项频繁集。 本列的3-项频繁集为:[L3={BEF,CEF}],由于没有k行内积后等于k的行,所以运算到此为止。 5 性能比较和实验结果 5.1 性能比较 所提出的转置矩阵算法只需要扫描数据库一次就可得到1-项频繁集,通过矩阵转置相乘可以得到2-项频繁集,而不需要通过候选集的计算,减少了读取数据库的时间。通过对2-项频繁集的剪裁和内积运算可以得到k-项频繁集。ABM算法是一种高效的关联规则挖掘算法,与之相比较,ABTM采用矩阵映射事物数据库,而不是建立单个项目的位向量,尽管两种算法将数据库映射到内存中占用的空间相同,但矩阵存储能够实现对规模的有效剪裁,随着项目集维数的增长,ABTM算法将矩阵中无用的行和列删除,使得内存空间逐步得到释放,同时参与运算的向量的长度越短,计算量也越小。ABTM算法能节省存储空降。 5.2 实验结果与分析 算法采用Matlab进行仿真实验, 数据采用Mashroom数据集,为了比较在不同支持度下的所用时间,实验机器的CPU为Inter Pentium3.0GHz,内存为2GB。针对Apriori算法、矩阵算法和ABTM算法比较,对不同支持度下的运行时间的测试。结果图5所示。 从图6可以看出,ABTM算法运行所需时间明显小于Apriori算法和ABM算法。图5中,随着所设定的支持度越来越小,Apriori算法和ABM算法总运算量与支持度呈费线性增长,所需时间也大大增加,而由于ABTM算法仅需扫描数据库一次,减少了读取数据库的时间,而且k-项频繁集的产生式通过扩展项集和向量内积运算求解,不需要连接等操作,随着支持度减少,算法所需要的时间并未显著增加。图2中,随着属性数量的增加,Apriori算法和ABM算法运行时间迅速上升,而ABTM得扩展项集合向量内积运算并不会因为属性等数量增加而受到较大的影响。 在支持度越小的情况下,转置矩阵法算法的优势越加明显,与Apriori算法相比较,运行时间得到较大程度的减少,在频繁项集数量增大的同时,只需要扫描数据库一次,节省了很多开销。实验结果表明,随着事物记录的增加,Apriori算法将花费大的开销来扫描多次数据库,而引入转置矩阵算法只需要扫描数据库一次,通过对比,可以看出转置矩阵算法的优势。 6 结论 所提出的算法引入了两个矩阵,分别从时间和空间上进行优化,使得算法效率得到显著的提高,是一种容易且可行的较好算法。算法还可以在以下两个方面做进一步的优化: (1)由于在构造事物矩阵后直接获得了1-项频繁集,所以可以在构造2-项支持矩阵前进行一次映射矩阵的剪裁。 (2)由于可能存在一些项并非是1-项频繁集,则这些项不可能再出现在更高阶的频繁项集中。因此在构造2-项支持矩阵时也没有必要考虑这些项。 针对典型的频繁项集挖掘Apriori算法及相关矩阵算法进行分析,提出了一种新的基于转置矩阵的频繁集挖掘算法,并对新算法做了详细分析和描述。理论和实验证明,该算法在性能上臂Apriori算法及矩阵算法更优越。特别是在学生成绩预警预报方面更加出色。 参考文献: [1] 宋绍云. 基于SQL Server数据挖掘的学生成绩预警预报研究. 电脑知识与技术[J]. 2015,11(17). [2] 曹风华. 改进的基于两个矩阵的关联规则挖掘算法.电子科技[J] .2012-05-15. [3] 吕桃霞,刘培玉. 一种基于矩阵的强关联规则生成算法. 计算机应用研究[J]. 2011-4-20. [4] Park J S, Chen M S, Yu P S. An effective hash-based algorithm for mining association rules [C]. Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data, San Jose, California: ACM Press, 1995: 175-186.
