
社会网络中影响力传播的鲁棒抑制方法
2016-04-27 10:33张德海刘惟一
计算机研究与发展 2016年3期
关键词:社会网络
李 劲 岳 昆 张德海 刘惟一
1(云南大学软件学院 昆明 650091)
2(云南省软件工程重点实验室 昆明 650091)
3 (云南大学信息学院 昆明 650091)
(lijin@ynu.edu.cn)
社会网络中影响力传播的鲁棒抑制方法
李劲1,2岳昆2,3张德海1,2刘惟一3
1(云南大学软件学院昆明650091)
2(云南省软件工程重点实验室昆明650091)
3(云南大学信息学院昆明650091)
(lijin@ynu.edu.cn)
Robust Influence Blocking Maximization in Social Networks
Li Jin1,2, Yue Kun2,3, Zhang Dehai1,2, and Liu Weiyi3
1(SchoolofSoftware,YunnanUniversity,Kunming650091)
2(KeyLaboratoryofSoftwareEngineeringofYunnanProvince,Kunming650091)
3(SchoolofInformationScienceandEngineering,YunnanUniversity,Kunming650091)
AbstractInfluence blocking maximization is currently a problem of great interest in the research area of social networks. Existing influence blocking methods assume negative influence sources are definitely known or non-adversarial. However, in real applications, it is hard to obtain the accurate information of influence sources. In addition, adversarial spreader may strategically select the seeds to maximize negative spread. In this paper, we aim to tackle the problems of influence blocking maximization with uncertain and strategic negative influence sources respectively. First, in order to increase the efficiency of the algorithms for mining blocking seeds, we discuss approximate estimation of the influence spread of negative seeds under the competitive linear threshold model. Based on the estimation, we propose a blocking seeds mining algorithm under the situation of finite uncertain and negative influence sources to maximize the expected influence blocking utility. In adversarial influence spread situations, one entity strategically attempts to maximize negative influence spread while the other one tries to block the negative propagation of its competing entity as much as possible by selecting a number of seed nodes that could initiate its own influence propagation. We model the interaction as a game and propose a polynomial time approximate algorithm for solving random blocking strategy based on min-max principle to decrease the worst negative influence spread. Finally, we make experiments on real data sets of social networks to verify the feasibility and scalability of the proposed algorithms.
Key wordssocial networks; influence blocking maximization; minmax principle; approximation algorithms; submodular function
摘要社会网络中影响力传播的有效抑制是当前社会网络影响力传播机制研究关注的问题之一.针对不确定性、策略性负影响源的影响力传播抑制,讨论社会网络中影响力传播的鲁棒抑制问题.首先,作为提高算法运行效率的有效途径,讨论在竞争性线性阈值传播模型下,负种子集传播能力的近似估计方法,以此为基础,提出不确定性负影响源情况下,期望抑制效果最大化的抑制种子集挖掘算法.然后,对于策略性传播源,以最小化最坏情况下的影响力传播范围为目标,基于极小极大优化作为抑制决策准则,提出了一个随机抑制策略的多项式时间近似求解算法.最后,在真实的社会网络数据集上,通过实验验证了所提出方法的有效性.
关键词社会网络;影响力抑制最大化;极小极大原理;近似算法;次模函数
近年来,许多学者针对面向多信息源发布的信息全局传播机制及其预测模型,以影响力传播范围及传播速度最大化为目标的关键结点集选取等问题开展了积极探索,并取得了一系列成果,极大地促进了社会网络影响力传播机制问题的研究[1-7].
然而,由于社会网络本身具有开放性和虚拟性,各种不良、虚假信息、反动言论可以跨地域、跨国界地散布和传播,严重危害社会稳定及国家安全.因此,为有效抑制万维网环境下社会网络负面影响传播,影响力传播抑制问题也引起了学术界的关注,取得了一些初步的研究成果,成为社会网络影响传播机制研究的一个重要方面[8-11].
例如文献[8]扩展了经典的线性阈值模型,给出用于描述社会网络中影响力竞争性传播现象的竞争线性阈值模型(competitive linear threshold model,CLT),定义影响力传播抑制最大化问题(influence blocking maximization, IBM),提出求解IBM问题的高效近似算法.文献[9] 扩展了独立级联模型,定义多竞争独立级联模型(multi-campaign independent cascade model, MCICM),及影响力传播限制问题(eventual influence limitation problem, EIL),给出了MCICM 模型下,EIL问题目标函数满足次模性(submodular)的充分条件及EIL问题的近似求解算法.文献[8-9]的研究工作均关注影响力传播的抑制最大化问题,即最小化竞争对手的影响力传播范围.此外,文献[10]从另一角度研究了影响力传播的抑制,即限定影响力传播范围,求解最小抑制种子集.
不难看出,在解决影响力传播抑制问题时,文献[8-10]都假设在进行抑制决策时影响源已知,在此前提下,将影响力传播抑制问题建模为相应的优化问题,进而提出求解问题的近似优化算法.然而,在实际社会网络应用中,在做出抑制决策前,抑制方往往很难掌握影响源的准确信息,因此无法保证已有算法的抑制效果.其次,上述研究工作忽略了影响力传播方“策略性”传播行为,即传播方可能会根据抑制方采取的抑制决策,有针对性地、策略性地选择影响力传播源,变更影响力传播的途径,改变影响力传播结果,最终导致抑制方无法取得好的抑制效果.
由于影响力传播与抑制行为的本质是传播方与抑制方之间的一种博弈关系,最近,文献[11]以传播方和抑制方可能选取的种子集作为策略空间,将影响力传播与抑制的对抗行为建模为一个零和博弈(zero sum game)[12],最优抑制决策就是该博弈的Nash均衡解.然而,该博弈模型具有指数级的策略空间.为避免对博弈的策略空间进行枚举,文献[11]提出了基于策略生成技术的博弈Nash均衡的近似求解算法.虽然这一研究工作首次从博弈论的角度出发研究和分析传播和抑制对抗行为,充分考虑到了影响力传播行为的策略性,然而,基于策略生成技术的求解算法在最坏情况下需要穷举整个策略空间,同时算法不能保证最后收敛到博弈的Nash均衡,也无法得到保证近似下界的近似解,因此只适用于规模较小的社会网络.
综上,针对社会网络中影响力传播抑制问题,已有研究工作取得了积极的成果.但是面对不确定性和策略性影响源,如何有效、鲁棒地进行影响力传播抑制,仍是我们面临的研究挑战.对此,针对不确定性影响源、策略性影响源2种情况,本文提出社会网络中影响力传播的鲁棒抑制问题以及影响力传播鲁棒抑制的有效解决方法.
本文的研究内容主要包括:
1) 用影响源上的概率分布来描述影响传播源具有的不确定性.为有效提高算法的执行效率,采用基于局部有向无环图(local directed acyclic graph,LDAG)结构的估计方法对影响源传播范围进行高效地近似估计,基于此,以期望抑制效果最大化为目标,提出了针对不确定传影响源的抑制种子集挖掘算法.
2) 针对策略性影响源的影响传播抑制问题,基于极小极大决策准则,以最小化最坏情况下的影响力传播范围为目标,提出用于影响力传播抑制的多项式时间近似算法.
3) 在真实的社会网络数据集上,通过实验验证了本文提出方法的有效性.对于不确定性影响源,相比较已有方法,本文的算法在执行效率和抑制效果之间取得了很好的折中;对于策略性影响源,本文的算法能够有效抑制最坏情况下的影响力传播范围,达到了影响力传播的鲁棒抑制效果.
1背景知识
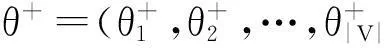

(1)
在社会网络影响力传播抑制问题中,存在决策目标对立的双方:传播方(记为MAX)旨在通过选择相应的负种子集合D(也称为负影响源),使得从D出发的负影响力传播效用最大化;抑制方(记为MIN),其通过选取相应的正种子集C,正影响从C出发传播,负、正影响力按照CLT模型在网络中传播,最终,最小化MAX的负影响力传播效用.
令{D}和{C}分别为传播方和抑制方所有可能的负、正种子集组成的集合,也分别称作传播方、抑制方的策略集.基于此,社会网络中影响传播抑制问题定义如下[8]:
定义1. 在社会网络G中,给定MAX的负种子集D∈{D},求解MIN的最优抑制种子集C*∈{C},使得MAX方的负影响力传播效用最小化:
(2)
定义1是最小化MAX的影响传播效用.此外,也可用传播效用的抑制最大化来等价定义该问题.给定D,定义种子集C的抑制效用函数:
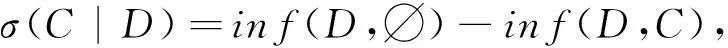
(3)
于是,影响力传播抑制问题定义为求解MIN的最优抑制种子集C*∈{C},使得负影响力传播抑制效果最大化:
(4)
文献[8]证明,给定D,σ(C|D)是结点集V上的次模函数.
2问题定义
在影响力传播抑制问题中,抑制方不一定能准确地掌握负影响源的信息,其所获得的负源信息往往带有不确定性.设P是{D}上的概率分布空间,用{D}上的概率分布P∈P来描述抑制方对于负影响源信息的不确定性(在后文中,在强调P是MIN所掌握的关于的先验概率信息时,将P记为Pprior).于是,面向不确定性影响源的影响力传播抑制问题,记为RIBprior.
定义2. 在社会网络G中,给定MAX的负种子集{D}上的概率分布Pprior,RIBprior定义为求解MIN的最优抑制种子集C*∈{C},使得MAX方的影响力传播效用最小化,即:
(5)
在影响力传播抑制问题中,双方的决策效果是相互依存的,最终影响力传播的结果不仅决定于MAX选择的影响源,同时也决定于MIN采取的抑制策略.那么,在决策效用相互依存的情况下,MIN应如何决策?从而实现对MAX的影响传播进行有效抑制.从博弈论的角度来说,影响传播、抑制对抗行为构成MAX和MIN之间的一个博弈.对于MIN来说,如果不能预先获知MAX决策行为,那么,采取极小极大准则进行抑制决策是合理、有效的选择.另外,MIN采取随机抑制策略可以获得更好的期望抑制效用.
综上,面向策略性影响源的影响力传播抑制问题,记为RIBminmax.
定义3. 令{C}是MIN的抑制种子集集合,Q是{C}上的概率分布空间.任意概率分布Q∈Q称作MIN的随机抑制策略,即MIN按照Q从{C}中选择种子集C进行抑制.面对策略性影响力传播源,MIN按照极小极大决策准则,采取随机策略Q*∈Q对MAX负影响力传播进行抑制,使得:
(6)

(7)
只是式(6)的一个特例.
3影响力传播抑制优化算法
3.1影响力传播效用的近似估计
在RIBprior和RIBminmax问题中,均涉及对影响力传播效用inf(D,C)进行计算.由式(1)可知,inf(D,C)是关于阈值随机向量θ+和θ-的期望值,准确估计inf(D,C)需要进行大量的随机实验,计算代价较高.
为有效提高算法的运行效率,本文采用文献[8]提出的基于LDAG的方法对inf(D,C)进行近似估计,即:基于网中除种子结点之外的所有结点的负激活概率之和作为负影响传播效用的度量标准:
(8)
其中,p-(v|D,C)是结点v在负种子集D,抑制种子集C下的负激活概率.关于p-(v|D,C)的计算方法详见文献[8].
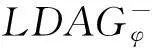
3.2RIBprior问题的抑制种子集挖掘算法
首先分析RIBprior问题目标函数的性质.由式(3)定义的抑制效用函数σ(C|D)可知,给定Pprior,有:
由于inf(Pprior,∅)是常数,RIBprior可等价地描述为
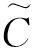
基于3.1节介绍的影响力传播效用的近似估计方法,当MAX的负种子集{D}是有限(设包含m个负种子集)的情况下,讨论期望抑制效用最大化的抑制种子集挖掘算法.设{D}m={D1,D2,…,Dm}(Di⊆V)是包含m个负种子集的集合.Pm是{D}m上的一个概率分布.随机策略Pm的期望影响力传播效用可用负激活概率表示为
为算法描述方便,引入记号γ-(v|Pm,C),即在Pm和C下,任意结点v的负激活概率的期望值:
于是,可重写:
也就是说,inf(Pm,C)是结点负激活概率的期望值之和.算法1给出了期望抑制效用最大化的抑制种子集挖掘算法,其基本思想如下:
步骤1. 初始化阶段.对于网中每个结点v,初始化与其负激活概率计算相关的子图结构.对于网中的每个结点u,初始化其单独作为抑制结点时的抑制效用.
步骤2. 抑制种子挖掘阶段.本阶段从网中挖掘k个抑制种子.算法的执行过程与采用贪心法挖掘抑制种子集是一致的,即每次迭代,从VC中选取最大边际抑制效用值的结点作为抑制种子加入到C中.每次迭代完成后,更新各个结点的边际抑制效用值.经过k次迭代完成抑制种子集的挖掘.不过,与贪心法不同的是:算法1采用γ-值来度量抑制效用值.
算法1.RIBprior问题的抑制种子集挖掘算法Aprior.
输入:G=[V,E],{D}m,{D}m上的概率分布Pm,LDAG结构控制参数φ、抑制种子集大小k;
①C←∅;
② for eachv∈Vdo
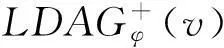
④ end for
⑤ for eachu∈Vdo
⑥Δ-(u)←0;
⑦ end for
⑧ for eachv∈Vdo
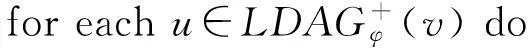
⑩before←γ-(v|Pm,∅),after←γ-(v|Pm,{u}),Δ-(u)←Δ-(u)+(before-after);


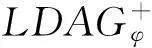

Δ-(u)←Δ-(u)-(γ-(s|Pm,C∪
{u})-γ-(s|Pm,C)),
Δ-(u)←Δ-(u)+(γ-(s|Pm,C∪
{c,u})-γ-(s|Pm,C∪{c}));



Fig. 1 Update of the nodes’ marginal blocking utility.图1 边际抑制效用更新示意图

3.3RIBminmax问题的随机抑制策略求解算法
由定义3可知,RIBminmax问题归结为一个极小极大(minmax)优化问题.求解MIN的极小极大随机抑制策略Q*等价于:MIN和MAX分别采用随机策略P和Q,并以inf(P,Q)作为决策效用函数进行零和博弈,而Q*就是MIN的Nash均衡解.
零和博弈的Nash均衡解可以通过2种方法进行求解,即基于线性规划求解[12]和基于迭代求解[16].然而,采用上述2种方法求解RIBminmax问题,存在2个困难.
1) 基于线性规划的求解方法.首先,在RIBminmax问题中,负种子集D∈{D}和抑制种子集C∈{C}的数目与网络中的结点呈指数关系增长.于是,基于线性规划求解Q*需要枚举指数级的约束关系且线性方程中含有指数级个数的变量.其次,线性规划方法需要预先确定博弈效用矩阵中的效用值,也就是说在求解RIBminmax问题时,对于任意D∈{D}和C∈{C},需先确定inf(D,C)值,当{D}或{C}的数目大时,显然是不现实的.
2) 基于迭代的求解方法.迭代方法在算法迭代求解过程中逐步生成效用矩阵,克服了规划求解方法面临的困难.然而,该方法的收敛性无法得到保证.同时,即便算法收敛,也无法保证所得解的求解质量[16].
算法2. 随机抑制策略的求解算法Aminmax.
输入:G=V,E,0<μ≤1,LDAG结构控制参数φ、拟挖掘的正种子集大小k、算法终止的阈值ε>0;
① 初始化MAX的传播策略权重:
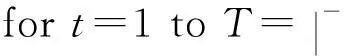
③ 生成MAX随机策略P(t),即:

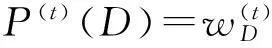
④ 针对随机策略P(t),基于算法1求解MIN的近似抑制种子集


⑥ 更新MAX传播策略的权重:
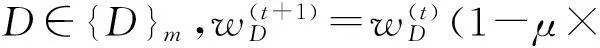
⑦t=t+1;
⑧ end for
在假定MAX的传播策略集{D}含有有限的m个负种子集的情况下(记为{D}m),提出一个求解Q*的多项式时间的近似算法,即算法2.其基本思想是:时刻t,MAX按照一定的随机策略选择负种子集,针对该随机策略,MIN选择最优抑制种子集C(t)∈{C}进行抑制.在时刻t+1,根据D∈{D}m在C(t)的传播效用,MAX更新D的权重,即传播效用越大的D,获得越大的权重,并按照各策略的在前t个时刻的累积权重来确定时刻t+1的随机传播策略P(t).完成T次博弈后,由T个抑制种子集C(1),C(2),…,C(T)确定{C}上的一个随机抑制策略,该随机抑制策略就是最优随机抑制策略的近似解.
对算法2进行说明:步骤④即MIN对P(t)的“最优响应”.在双方进行第t次博弈时,MAX采取P(t)作为随机策略(初始时P(t)是均匀分布,即P(1)=1m).MIN对P(t)进行最优响应,即MIN采取C(t)对MAX进行抑制:
(9)
由算法1可知,求解C(t)归结为一个次模函数的最大化问题,因此,存在保证近似下界的近似算法,例如基于贪心法的次模函数的最大化求解方法.于是,由算法1可获得C(t)的1β(近似抑制策略(t)(β=1-1e),满足:
(10)
其中,C*是对P(t)的最优响应.

综上,算法2 克服了已有的线性规划和迭代方法求解Q*所面临的困难,给出了求解最优随机抑制策略的有效近似方法.
定理1证明了算法2在多项时间内可求得RIBminmax问题的随机近似抑制策略.
定理1. 给定近似因子0<ε<1.设m是{D}m中负种子集的个数.在算法2 中,时刻t,MAX采取随机传播策略P(t),MIN基于1β(近似算法求解抑制种子集(t)对P(t)响应.那么,经过4lnm次迭代后可获得求解RIBminmax问题的近似解,使得:
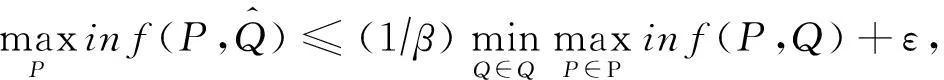
其中,β=1-1e.
定理1的证明见附录A.
4实验结果
4.1实验环境设置
所有实验在NetHEPT和NetPHY两个真实数据集上完成(数据下载自文献[17]).按照文献[8]描述的方式,我们对数据集进行了预处理,并采用广度优先搜索的方法,从完成预处理后的NetHEPT和NetPHY中抽取了相应的连通子图.表1给出了实验中所用到的子图数据的统计信息:
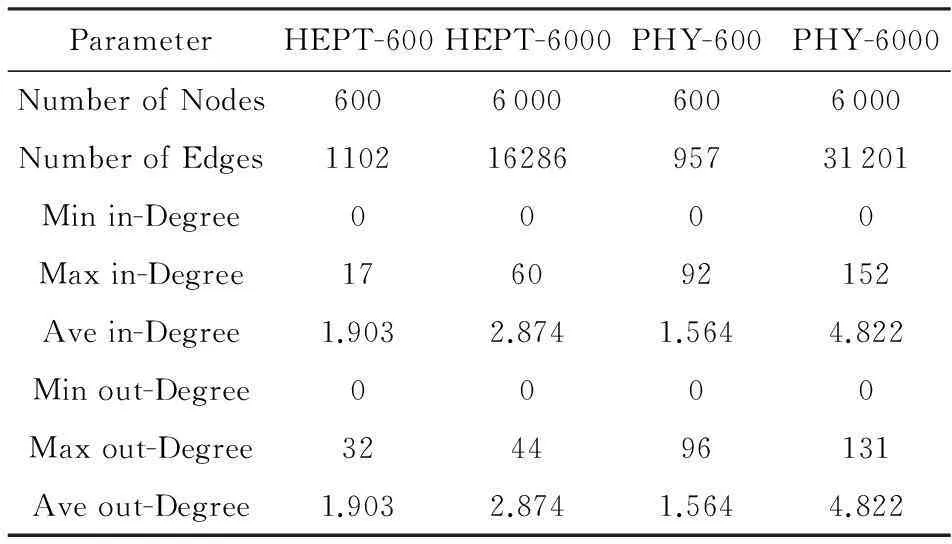
Table 1 Statistics Information of the Experimental Data
所有实验程序采用C++语言编写,编译器版本gcc 4.8.2.实验运行环境:Intel Xeon CPU E5620 2.4 GHz,8 GB内存的服务器、操作系统Linux Ubuntu 14.04 LTS.
4.2算法的抑制效果
4.2.1抑制效果的度量标准
在算法1和算法2中,算法的目标函数定义为所有结点的负激活概率的期望值之和.在求解抑制种子集(或随机抑制策略)后,为将抑制效用与式(1)的定义保持一致,求得每个结点在给定正、负种子情况下的负激活概率,并以此为基础进行重复实验1 000次,以随机实验时负激活的结点集大小的平均值,作为影响传播的抑制效果.
4.2.2Aprior算法的抑制效果

Fig. 2 Comparison of the blocking results on NetHEPT-600.图2 NetHEPT-600上不同算法抑制效果比较
为验证算法1的有效性,将其与其他抑制算法进行了对比实验.1)Greedy算法.基于贪心法挖掘抑制种子集,在每次挖掘抑制种子时,采用10 000次蒙特卡罗仿真来估计结点的期望边际抑制效用.2)Random算法.等概率从图中选取大小为k的抑制种子集.3)Degree算法以结点度为概率权重,随机选取k个抑制种子构成抑制种子集.
考虑到Greedy算法的运行效率,只在2个子图:NetHEPT-600和NetPHY-600进行实验.首先,按照均匀分布,随机地从子图结点集V中抽取20个结点生成负种子集Di,一共生成100个负种子集Di构成{D}m=100,记Pprior=1m是{D}m=100上的均匀分布.其次,对抑制种子集C= 10,20,30,40,50,60执行4种抑制种子集挖掘算法,并对比期望抑制效果.其中,Aprior算法中参数φ=0.01.
图2和图3分别给出了4种算法在NetHEPT-600和NetPHY-600数据集上的期望抑制效果对比结果.图4给出了Greedy算法和Aprior算法分别在HEPT和PHY数据集上的运行时间对比结果.
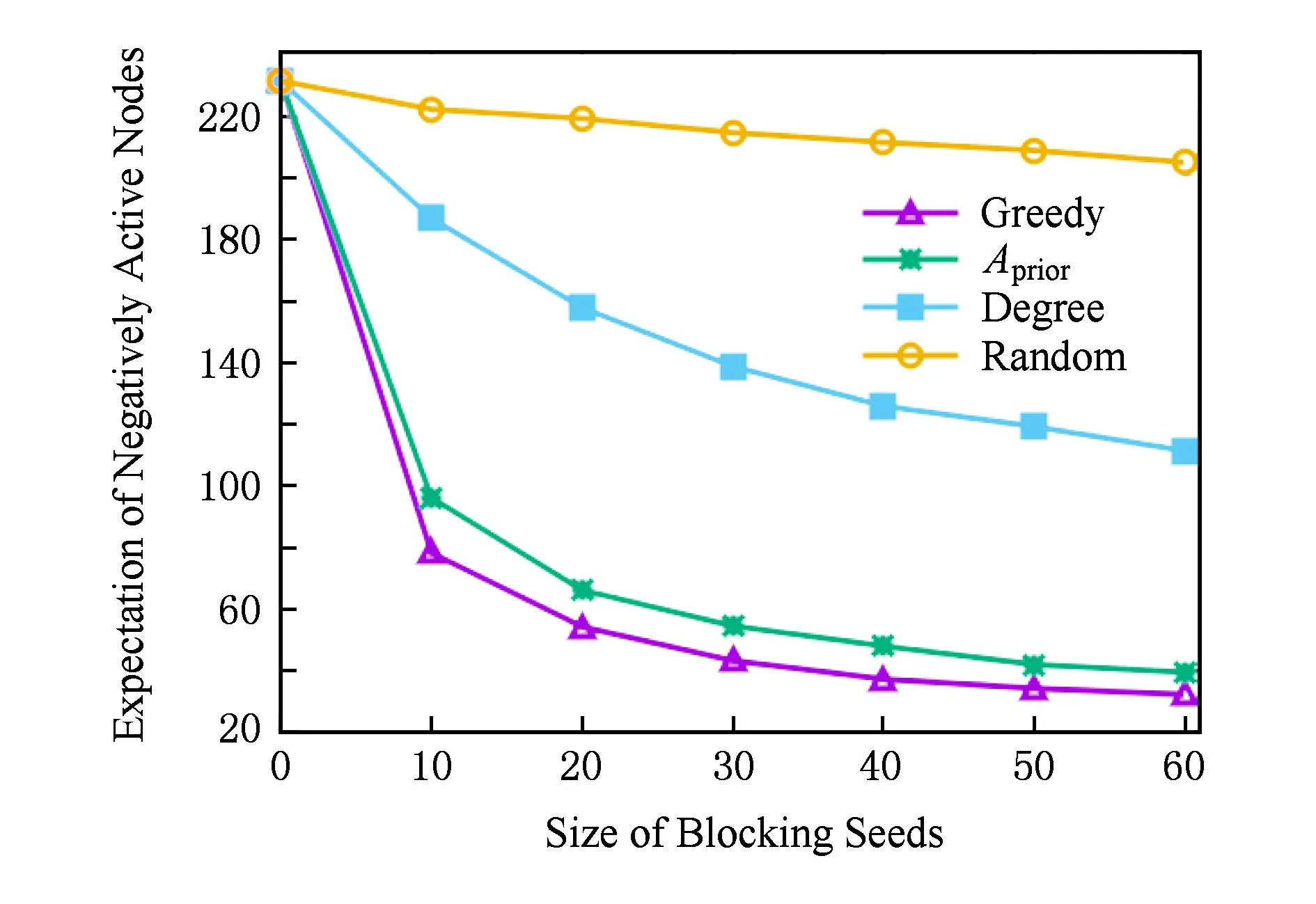
Fig. 3 Comparison of the blocking results on NetPHY-600.图3 NetPHY-600上不同算法抑制效果比较
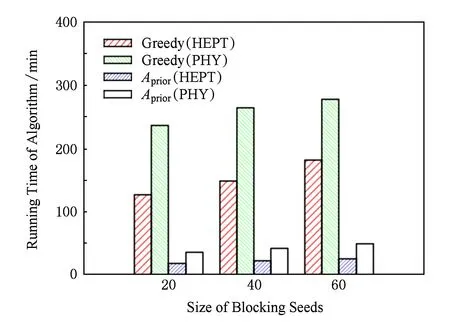
Fig. 4 Running time comparison of Greedy and Aprior algorithms.图4 Greedy与Aprior算法运行时间比较
由实验结果可知,相比较Random,Degree两种算法,Greedy,Aprior算法在抑制效果上均有显著的提升.其中,Greedy算法具有最好的抑制效果,但该算法在执行过程中需要通过随机仿真来评价结点的边际抑制效用,运行时间较长,不适用于大尺寸数据集.Aprior算法在抑制效果上与Greedy算法差距不大,且该算法采用基于LDAG结构的方法对结点的边际抑制效用进行近似评估,算法运行时间显著减少.因此,Aprior算法在抑制效果和算法运行时间2方面取得了很好的折中.
4.2.3Aminmax算法的抑制效果
首先,为直观展示Aminmax算法的抑制效果,将其与Aprior算法进行了对比.其次,为说明Aminmax算法在求解抑制策略上的有效性和优势,将其与文献[11]提出的基于迭代的零和博弈求解算法(double oracle algorithm,Aoracle)进行对比.实验采用NetHEPT-6000和NetPHY-6000数据集.

图5直观地展示Aminmax算法对最具传播能力的负种子集的传播抑制效果.对于NetPHY-6000数据集,当每个抑制种子集大小k=50时,{D}m中100个不同的负种子集分别在:无抑制种子集、Aprior算法的抑制种子集以及Aminmax算法的随机抑制策略下的负激活结点(期望)数目分布的情况.3种情况下负激活结点数目的平均值分别为:1003.15,597.54,628.21.此外,图5中用箭头标示了Aprior,Aminmax算法进行抑制时,最大的负激活结点数目(其中,Aprior算法抑制时,最大负激活结点数目为1121,而Aminmax算法抑制数目为896).

Fig. 5 Demonstration of blocking result of Aprior and Aminmax on NetPHY-6000.图5 Aprior和Aminmax算法在NetPHY-6000的抑制结果示例
文献[11]采用线性规划和Aoracle算法来求解博弈的Nash均衡解.由于数据集包含6 000个结点,因此,采用函数pagerank-oracle作为Aoracle算法,线性规划则采用软件包CPLEX 12.6[18]完成.在NetHEPT-6000和NetPHY-6000数据集上,对比实验的结果相似,因此,只给出在NetPHY-6000的结果.此外,当抑制种子集大小超过150时,Aoracle算法无法在有限时间内输出结果,于是只给出抑制种子集在150以内的对比结果.
图6给出了Aoracle和Aminmax算法的抑制效果对比结果.当抑制结点数少于70时,Aoracle算法的平均抑制效果和最差情况的抑制效果要优于Aminmax算法.随着抑制结点数增加2个算法的期望抑制效果相近,而对于最差情况的抑制效果Aminmax算法明显比Aoracle算法稳定.主要原因是随着抑制结点数的增加,Aoracle算法不能保证收敛,这影响了算法的平均抑制效果.图7给出了Aoracle和Aminmax算法的求解时间对比结果.Aminmax算法运行时间基本随抑制结点集的大小线性增长,然而,Aoracle算法的运行时间随抑制结点集大小快速增长.综上,对于小数据集而言,Aoracle算法有着不错的抑制效果和合理的求解时间,然而,对于大数据集来说,在抑制效果和求解时间上Aminmax算法更有优势.

Fig. 6 Comparison of the worst-case and average-case blocking results of Aoracle and Aminmax on NetPHY-6000.图6 Aoracle和Aminmax算法NetPHY-6000平均及最差抑制效果对比
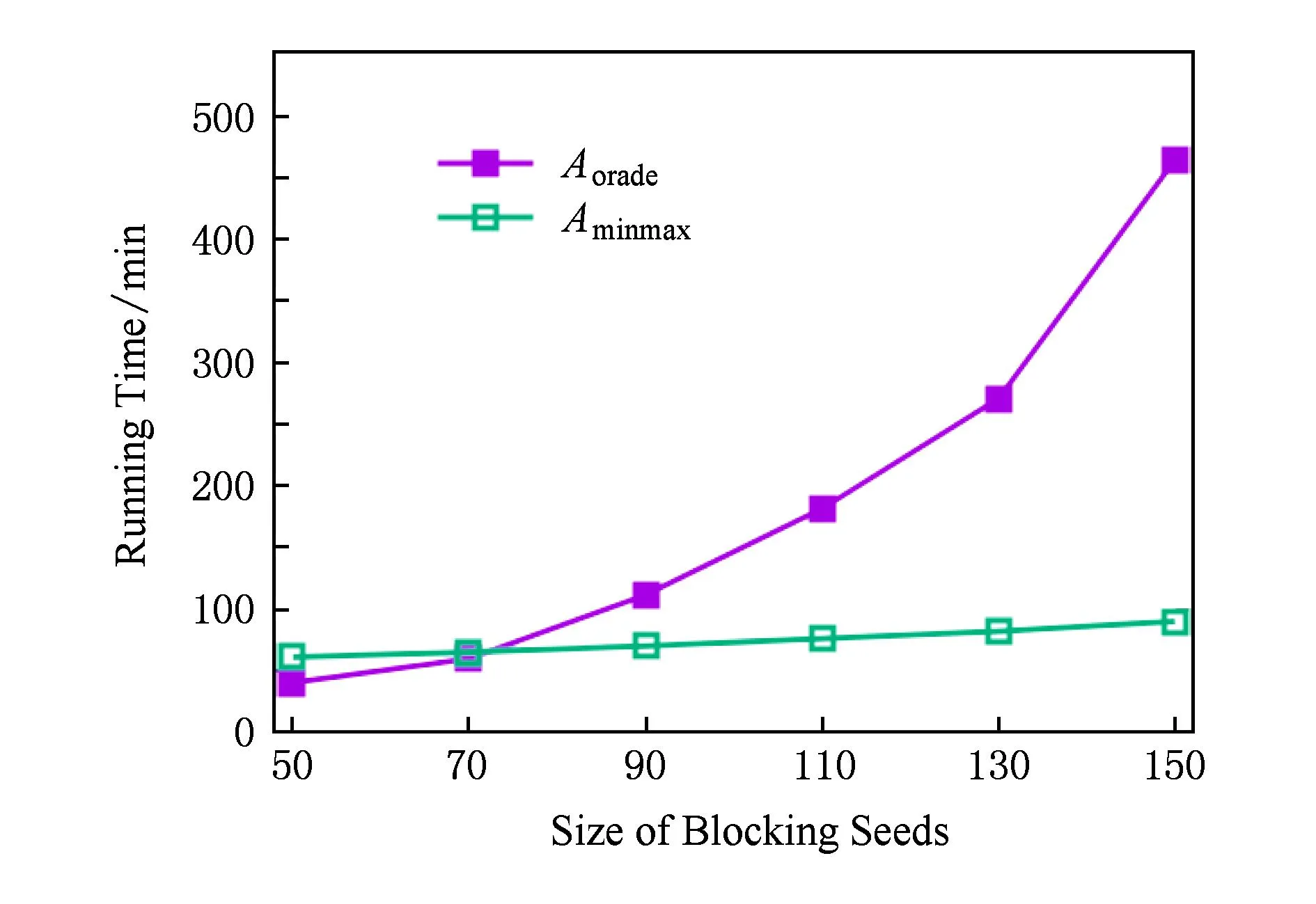
Fig. 7 Running time comparison of Aoracle and Aminmax on NetPHY-6000.图7 Aoracle和Aminmax算法在NetPHY-6000运行时间对比
5结束语
影响力传播的建模和分析及其控制是当前社会网络研究的重要内容.其中,影响传播的有效抑制是当前研究面临的一个新的挑战.针对实际应用环境中,不确定性负影响源、策略性负影响源2种情况,本文提出了社会网络中负面影响传播的鲁棒抑制问题.针对不确定性负影响源的情况,以期望抑制效果最大化为目标,提出了抑制种子集挖掘算法;针对策略性负影响源的情况,以极小极大优化作为决策准则,提出了多项式时间的随机抑制策略的近似求解算法.最后,在实际社会网络数据集的实验结果验证了本文提出算法的有效性.
在本文研究的基础上,未来可以在3个方面继续开展研究.1)本文中影响力传播模型是对线性阈值模型扩展而得,而对于其他典型的传播模型,例如独立级联模型进行扩展,进而提出相应的影响力竞争性传播模型,并提出该模型下的针对不确定性负影响源、策略性负影响源的影响传播抑制算法;2)社会网络的图结构对影响传播和抑制有很大的影响,深入研究图结构与影响传播、抑制之间的关系,并提出基于图结构信息的负影响传播的有效抑制算法;3)针对大尺寸社会网络数据,如何基于图抽样的方法[19]进一步在抑制策略的求解效率和求解质量之间进行有效折中,这些都是将来值得研究的课题.
参考文献

[1]Wu Xindong, Li Yi, Li Lei. Influence analysis of online social networks [J]. Chinese Journal of Computers, 2014, 37(4): 735-752(in Chinese)(吴信东, 李毅, 李磊. 在线社交网络影响力分析[J]. 计算机学报, 2014, 37(4): 735-752)
[2]Yang Shiqiang, Cui Peng. The Information propagation model of social media[J]. Communications of CCF, 2011, 7(12): 20- 24 (in Chinese)(杨士强, 崔鹏. 社区媒体信息传播机制[J]. 中国计算机学会通讯, 2011, 7(12): 20-24)
[3]Leskovec J, Krause A, Guestrin C, et al. Cost-effective outbreak detection in networks[C]Proc of the 13th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2007: 420-429
[4]Tian Jiatang, Wang Yitong, Feng Xiaojun. A new hybrid algorithm for influence maximization in social networks [J]. Chinese Journal of Computers, 2011, 34(10): 1956-1965 (in Chinese)(田家堂, 王轶彤, 冯小军. 一种新型的社会网络影响最大化算法 [J]. 计算机学报, 2011, 34(10): 1956-1965)
[5]Chen Hao, Wang Yitong. Threshold-based heuristic algorithm for influence maximization[J]. Journal of Computer Research and Development, 2012, 49(10): 2181-2188 (in Chinese)(陈浩, 王轶彤. 基于阈值的社交网络影响力最大化算法[J]. 计算机研究与发展, 2012, 49(10): 2181-2188)
[6]Chen W, Yuan Y, Zhang L. Scalable influence maximization in social networks under the linear threshold model [C]Proc of the 10th IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2010: 88-97
[7]Goyal A, Lu W, Lakshmanan L V S. Simpath: An efficient algorithm for influence maximization under the linear threshold model [C]Proc of the 11th IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2011: 211-220
[8]He X, Song G, Chen W, et al. Influence blocking maximization in social networks under the competitive linear threshold model [C]Proc of the SIAM Int Conf on Data Mining. Philadelphia, PA: SIAM, 2012: 463-474
[9]Nguyen N P, Yan G, Thai M T, et al. Containment of misinformation spread in online social networks[C]Proc of the 3rd Annual ACM Web Science Conf. New York: ACM, 2012: 213-222
[10]Budak C, Agrawal D, El Abbadi A. Limiting the spread of misinformation in social networks[C]Proc of the 20th Int Conf on World Wide Web. New York: ACM, 2011: 665-674
[11]Tsai J, Nguyen T H, Weller N, et al. Game-theoretic target selection in contagion-based domains [J]. The Computer Journal, 2014, 57(6): 893-905
[12]Myerson R B. Game Theory: Analysis of Conflict [M]. Cambridge, MA: Harvard University Press, 1997
[13]Kempe D, Kleinberg J, Tardos é. Maximizing the spread of influence through a social network[C]Proc of the 9th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2003: 137-146
[14]Fujishige S. Submodular Functions and Optimization [M]. Amsterdam: Elsevier Science Press, 2005
[15]Nemhauser G L, Wolsey L A, Fisher M L. An analysis of approximations for maximizing submodular set functions[J]. Mathematical Programming, 1978, 14(1): 265-294
[16]Halvorson E, Conitzer V, Parr R. Multi-step multi-sensor hider-seeker games[C]Proc of the 21st Int Joint Conf on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2009: 159-166
[17]Chen W, Social network dataset [EBOL]. Beijing: Microsoft Research Laboratory, 2010 [2014-12-09]. http:research.microsoft.comen-uspeopleweicprojects.aspx
[18]IBM Corporation. CPLEX Optimizer[CP]. New York: IBM Corporation, 2009 [2014-12-09]. http:www-01.ibm.comsoftwarecommerceoptimizationcplex-optimizerindex.html
[19]Ribeiro B, Towsley D. Estimating and sampling graphs with multidimensional random walks[C]Proc of the 10th ACM SIGCOMM Conf on Internet Measurement. New York: ACM, 2010: 390-403
[20]Freund Y, Schapire R E. Adaptive game playing using multiplicative weights [J]. Games and Economic Behavior, 1999, 29(1): 79-103Li Jin, born in 1975. PhD and associate professor. Member of China Computer Federation. His current research interests include massive data analysis and machine learning.

Yue Kun, born in 1979. PhD and professor. Member of China Computer Federation. His current research interests include massive data analysis and uncertainty in artificial intelligence.

Zhang Dehai, born in 1977. PhD and associate professor. His current research interests include knowledge engineering, machine learning.

Liu Weiyi, born in 1950. Professor and PhD supervisor in the Yunnan University. His current research interests include intelligent data analysis, social computing, and knowledge engineering.
附录A. 正文中定理1的证明.
定理A1. 即正文中的定理1.给定近似因子0<ε<1.设m是{D}m中负种子集的个数.在算法2 中,时刻t,MAX采取随机传播策略P(t),MIN基于1β(近似算法求解抑制种子集(t)对P(t)响应.那么,经过4lnm次迭代后可获得求解RIBminmax问题的近似解,使得:
其中,β=1-1e.
证明. 算法2可以看作是MAX,MIN双方T轮重复博弈的过程.因此,由文献[20]结论可知,对于MAX,如果其采取算法2与MIN进行重复博弈,其T轮博弈的累积期望传播效用:
(A1)
其中,0<μ<1,P是{D}上的任意概率分布,也就是MAX的任意随机策略.
(A2)
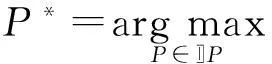
(A3)

(A4)
其中,C(t)是时刻t,MIN对P(t)的最优响应.此外,任意时刻t,有:
(A5)
(A6)
结合不等式(A3)的结果,有:
(A7)
令μ=ε2,T=4lnmε2,于是整理后,有:
(A8)


证毕.
中图法分类号TP391
通信作者:岳昆(kyue@ynu.edu.cn)
基金项目:国家自然科学基金项目(61562091,61472345,61263043);云南省自然科学基金项目(2014FA023,201501CF00022);云南大学骨干教师培养计划基金项目(XT412003);云南大学创新团队建设项目(XT412011)
收稿日期:2014-12-09;修回日期:2015-06-23
This work was supported by the National Natural Science Foundation of China (61562091,61472345,61263043), the Natural Science Foundation of Yunnan Province of China (2014FA023,201501CF00022), the Program for Backbone Teacher Development of Yunnan University (XT412003), and the Program for Innovative Research Team of Yunnan University (XT412011).
猜你喜欢
新闻世界(2017年1期)2017-01-20
西南交通大学学报(社会科学版)(2016年5期)2017-01-06
预测(2016年3期)2016-12-29
现代商贸工业(2016年11期)2016-12-26
旅游学刊(2016年9期)2016-12-06
商场现代化(2016年22期)2016-10-18
中国市场(2016年9期)2016-06-20
大众理财顾问(2016年3期)2016-06-13
人民论坛(2016年8期)2016-04-11
科技视界(2016年5期)2016-02-22
