
基于模糊RBF神经网络的乙烯装置生产能力预测
2016-05-11 02:13耿志强陈杰韩永明北京化工大学信息科学与技术学院北京0009智能过程系统工程教育部工程研究中心北京0009
化工学报 2016年3期
耿志强,陈杰,韩永明(北京化工大学信息科学与技术学院,北京 0009;智能过程系统工程教育部工程研究中心,北京 0009)
基于模糊RBF神经网络的乙烯装置生产能力预测
耿志强1,2,陈杰1,2,韩永明1,2
(1北京化工大学信息科学与技术学院,北京 100029;2智能过程系统工程教育部工程研究中心,北京 100029)
摘要:针对传统的径向基函数(RBF)神经网络隐藏层节点的不确定和初始中心敏感性、收敛速度过慢等问题,提出一种基于模糊C均值的RBF神经网络(FCM-RBF)模型,通过模糊C均值聚类(FCM)得到各聚类中心,基于误差反传的梯度下降法训练隐藏层到输出层之间的权值,克服传统RBF模型对数据中心的敏感性,优化确定RBF神经网络隐藏层的节点数,提高网络训练速度和精度。最后将其用于乙烯装置生产能力预测中,分析预测不同技术、不同规模乙烯装置生产情况,指导乙烯生产,提高生产效率,结果验证了所提出算法的有效性和实用性。
关键词:乙烯装置;生产能力预测;模糊C均值聚类;径向基神经网络;模型预测控制;神经网络;生产
2015-12-16收到初稿,2015-12-26收到修改稿。
联系人:韩永明。第一作者:耿志强(1973—),男,博士研究生,教授。
引 言
乙烯作为石油化工的龙头装置,其生产水平的高低常常成为判断一个国家工业发展水平的主要标志之一。据统计,2008年中国石化集团乙烯生产能力为6359.4 kt·a−1,而乙烯燃动能耗(标油)为649.36 kg·t−1[1],中国石油天然气股份有限公司生产乙烯2676 kt·a−1,而平均燃动能耗(标油)为714 kg·t−1[2],能效明显低于国外先进水平,因而国内乙烯行业存在较大的能效提升空间。乙烯的能源消耗费用占乙烯装置操作成本的50%以上[3],因此建立一个乙烯装置生产预测模型对降低乙烯工业能耗有着很好的指导意义。
建模在分析当前数据方面扮演着一种非常重要的角色[4]。目前常见的是通过BP算法进行建模,BP算法是一种基于梯度下降的误差逆向传播算法[5]。容易陷于局部最优,且训练时间过长。实际应用中,需要融合的时序数据的数据量一般是巨大的(可能是GB,甚至是TB的量级),需要以较快的速度对数据进行建模,同时时序数据还存在多个变量相关的情形,所以有必要先对时序数据进行聚类分析,有效提取嵌入到时序数据中的相关信息。同时随着时间的变化,变量状态也会发生一定的变化,有时还会出现异常状态,而聚类分析方法具有适用于序列与异类数据分析的特点[6],可以有效地剔除时序数据中的散点。相比其他的神经网络,径向基函数神经网络(radial basis function, RBF)具有通过更简单的设计过程而有着更好的泛化能力的优势[6-7],为此可以建立一个非线性时间序列RBF网络模型,从而对乙烯工业数据进行建模。
Broomhead等[8]于1988年提出了RBF神经网络,它是一个三层结构的网络:输入层、隐藏层及输出层,将径向基函数作为网络隐藏层的激励函数,输入层与隐藏层之间的权值一般通过K均值(K-means)聚类算法得到;隐藏层与输出层之间的权值一般通过BP算法得到。相比BP算法,RBF网络有着更快的收敛速度,也可避免局部最优。基于K-means聚类的RBF网络(K-RBF)对工业数据进行建模时,需要考虑K-means初始值的选取,同时得到的权值为负值,融合结果偏差较大[9],而比起其他传统的聚类算法,模糊C均值聚类算法(fuzzy C-means, FCM)对网络拓扑结构优化有着更好的效果[10],为此提出FCM-RBF网络。对于FCM算法,每个数据点可以不只属于一个聚类,通过一个隶属度矩阵记录着每个数据点与每个聚类的相关性[11]。与K-means聚类算法不同的是:对于K-means聚类,每个数据点仅仅属于一个聚类。在许多实际应用中,聚类的分界线往往不是那么明显时[12],FCM算法将更能适应这种应用。
本文将根据乙烯时序数据建立RBF网络,为了获得最优的RBF网络,采用FCM算法对乙烯装置能效相关时序数据进行聚类挖掘,获取多变量时序数据的分类及其聚类中心。结合某一年度的乙烯生产数据对RBF网络进行训练,最后通过训练得到的RBF网络模型对乙烯装置生产数据进行预测。
1 基于FCM-RBF模型的建立
1.1 FCM算法
传统的硬聚类算法如K-means算法对初始聚类中心敏感[13-14],聚类结果随不同的初始输入而波动。而FCM算法的主要思想是将经典划分的定义模糊化,用隶属度来确定属于某个聚类程度的一种软聚类方法[15]。它有两个参数:一个是聚类数目c;另一个是模糊加权指数m。c >1且取值通常远小于聚类样本的总个数,m又称为平滑参数。如果m取值过大,聚类效果不好,如果取值过小则会很接近硬聚类算法,通常m取[1.5,2.5]。
模糊C均值聚类算法把n个向量xk⊂RS分成c 组(k=1,2,…,n);S是向量xk的维数,并求得每个组的聚类中心。通过求解隶属度矩阵U={uik}c×n对数据进行分类,其中uik表示第k个样本属于第i个聚类中心的属性度,其取值都在[0,1]区间上,且每个样本的隶属度之和等于1,具体数学表达如下,设

为c个聚类中心,其中vi=[vi1,vi2,…,vis]为s维的向量(i=1,2,…,c),则目标函数T的一般化形式为

式中,
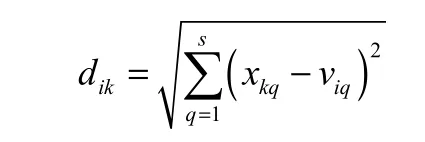
为第k个模糊组与第i个聚类中心的欧几里得距离;m为模糊加权指数,且m∈(1,+∞),2≤c≤n,且。
为了使式(2)达到最小,可以得到求取聚类中心及隶属度矩阵的公式,如下所示

FCM算法就是通过反复迭代优化T( U, V )来进行的,具体步骤如下:
(1)设定c和m,设定迭代停止阈值ε> 0,置迭代次数t = 0,初始化隶属度矩阵U;
(2)根据式(3)更新聚类中心;
(3)根据式(4)更新隶属度矩阵;
1.2 RBF神经网络
RBF网络有两个参数需要确定或训练得到,一个是高斯函数中的宽度(即方差)σij的确定,其中i=1,2,…,n,j=1,2,…,c,n为样本数,c为聚类中心个数,即RBF网络的隐藏层节点数;一个是RBF网络隐藏层到输出层之间的权值W=(wi)T,其中i=1,2,…,c,wi=(wi1,wi2,wi3,…,wim),其中m为RBF网络的输出节点数。其结构简图如图1所示。

图1 RBF网络结构简图Fig.1 Network structure diagram
首先需要根据聚类算法得到聚类中心Ci=(c1,c2,c3,…,cs)T,(i=1,2,…,p),p为聚类中心数,s为样本数据输入维数,之后计算每个输入向量与各聚类中心之间的距离Dik,一般会用欧几里得距离公式进行距离的计算,其公式如下
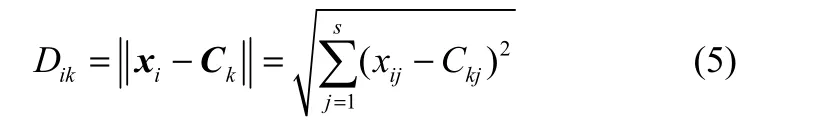
其中k=1,2,…,p,i=1,2,…,n。然后通过高斯函数得到RBF网络隐藏层中各个节点的输出Hik,其公式如下

其中,k=1,2,…,p,p为聚类中心数;i=1,2,…,n,n为样本数;δk是RBF网络隐藏层第k个节点的宽度,其公式如下
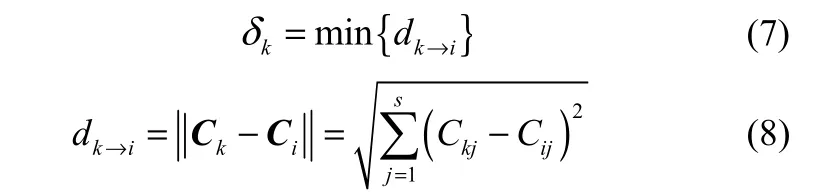
其中i={i|(i=1,2,…,p) ∩(i≠k)};k=1,2,…,p。
为了能够得到RBF网络隐藏层与输出层之间的权值,采用传统的BP算法进行训练,其网络实际输出公式如下

其中,yi为1×m阶矩阵,m为样本数据输出维数;i=1,2,…,n,n为样本数;t=0,1,…,t为BP算法训练过程中的迭代次数,当t=0时,W0表示初始权值,通过随机产生,其范围为[−1,1];Hi为1×p阶矩阵,表示输入第i个样本时,隐藏层各个节点的输出,其形式如下所示:Hi=(Hi1,Hi2,Hi3,…,Hip)。t时刻RBF网络隐藏层到输出层之间的权值Wt为p×m阶矩阵,其形式如下所示

最后将进行隐藏层与输出层之间权值的更新,其权值更新公式如式(11)所示
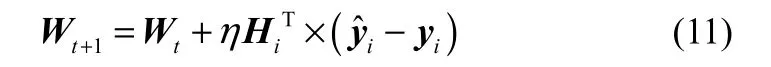
如果训练次数达到设定训练次数或者训练误差不大于设定训练误差上限,则训练停止,得到RBF神经网络模型。
1.3 FCM-RBF模型
由上分析可知,模糊C均值聚类方法有着K均值聚类方法所欠缺的优点,基于模糊C均值的RBF神经网络步骤如下。
(1)给定一个训练样本数据集X=(x1,x2,x3,…,xn| y1,y2,y3,…,yn)T,其中xi∈Rs,yi∈Rm,i=1,2,…,n,s为训练样本数据输入维数,m为训练样本数据输出维数。
其中s个变量时序投入数据集合X,如式(12)所示,其中t为时序长度。
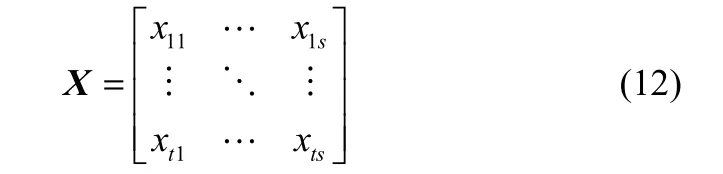
由于时序数据中各个变量的量纲一般并不相同,使得变量之间的数值没有可比性,为此在聚类之前需要对时序数据集进行归一化处理。常用的转换方法为比例转换[15],采用下面转换公式
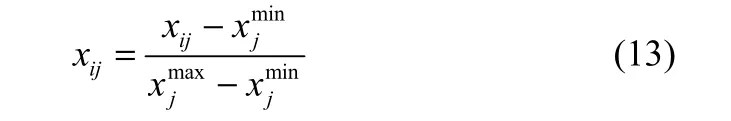
经过上述转换后可以确保用于模糊C均值聚类的信息阵为正定矩阵,以确保聚类结果的正确性与可理解性。

图2 FCM-RBF算法流程图Fig.2 Flow diagram of FCM-RBF algorithm
采用上述算法对归一化后的时序多变量数据X应用模糊C均值算法聚类得到n类的聚类中心,结果如式(14)所示

(2)设定误差上限ε及迭代上限Tmax,置迭代次数t=0,及聚类中心C,初始化权值W0。
(3)根据式(6)得到隐藏层各个节点的输出。
(4)根据式(9)得到网络实际输出。
(5)如果(t>Tmax)∪(E≤ε),算法停止,根据式(15)对输出进行反归一化,否则t=t+1,E=0。
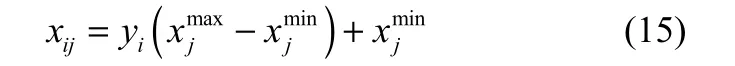
(6)根据式(11)更新隐藏层与输出层之间的权值并转向步骤(4)。
本文FCM-RBF的算法流程如图2所示。
2 ZOO及WINE标准数据集测试
为初步验证本文所提FCM-RBF模型的有效性,分别就UCI数据库中ZOO及WINE标准数据集[16-17]进行测试。ZOO数据集有16个输入属性和1个输出属性,WINE数据集中有13个输入属性和1个输出属性。设置单层BP网络学习因子为0.01,动量因子为0.9,迭代次数为1000,隐藏层节点数分别为30和8,激励函数为S型函数;RBF网络(K-RBF和FCM-RBF)隐藏层节点数分别为30和8,迭代次数为1000,学习因子为0.01,其中FCM-RBF中的加权指数根据实验选取M=1.5。通过95组ZOO训练样本建立模型,对ZOO测试样本进行预测;通过150组WINE训练样本建立模型,对28组WINE测试样本进行预测,结果如表1、表2所示。
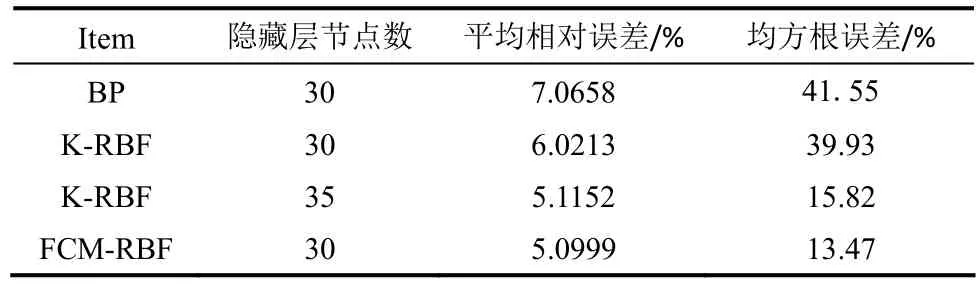
表1 ZOO标准数据集测试结果Table 1 Testing results of ZOO standard data set
从表1、表2可以看出,测试结果中,采用相同隐藏层节点数时,FCM-RBF的泛化误差或是泛化均方根误差都要明显好于BP网络及K-RBF。当增加隐藏层节点数时,如表2中隐藏层节点数为20时,K-RBF的平均相对误差为6.5839%,泛化均方根误差为26.73%,而隐藏层节点数为8的FCM-RBF,其平均相对误差为6.3803%,泛化均方根误差为26.62%,当增加隐藏层节点数后,K-RBF逐渐逼近FCM-RBF的精度。从上述分析可知,对于FCM-RBF,有着更好的预测能力,能够以更少的隐藏层节点数达到甚至超过K-RBF、BP网络的精度,由此初步验证了FCM-RBF模型的有效性。
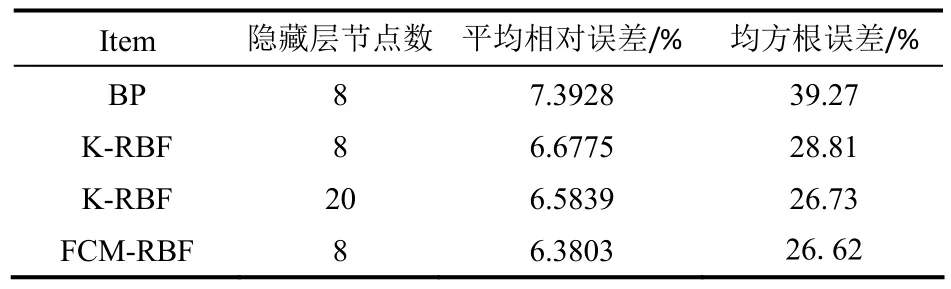
表2 WINE标准数据集测试结果Table 2 Testing results of WINE standard data set
3 基于FCM-RBF乙烯装置生产预测
3.1 乙烯投入产出数据分析
在乙烯工业中,不同的乙烯能效分析界区和计算方法被不同企业所采用。因此,为更好地分析乙烯装置能效,本文参照乙烯行业标准DB 37/751—2007[18]和GB/T 2589—2008[19]进行乙烯生产装置界区的划分。
乙烯生产过程能量界区如图3所示。
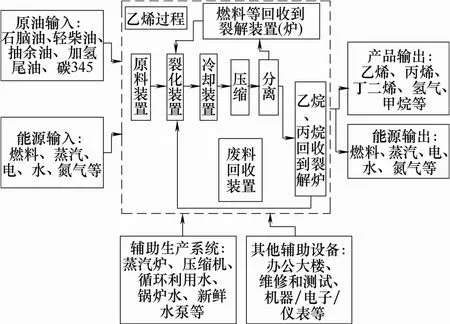
图3 乙烯生产过程能量界区Fig.3 Energy utilization boundary of ethylene product process
对于乙烯装置而言,与生产效率直接相关的因素主要包括:①原料;②燃料、动力消耗;③产品。由乙烯生产能量界区可知:原油、燃料、蒸汽、水、电作为乙烯生产的投入指标,而主要生产的乙烯、丙烯、碳四的产量为产出指标[20-23]。同时表示乙烯装置能耗水平比较通用的方法是按照《石油化工设计能量消耗计算方法》(SH/T 3110—2001)中的表3.0.2和表3.0.3的换算关系将能耗相关参数中的燃料、蒸汽、水、电的计量单位统一换算成GJ[24],原油、乙烯、丙烯、碳四生产单位以t计量。故本文将燃料、蒸汽、水、电,再加上原油作为RBF网络的输入,乙烯、丙烯及碳四产量之和作为RBF网络的输出。同时对乙烯产能建模数据进行处理[25]。
3.2 乙烯装置生产预测分析
本文选取全国7种主要乙烯生产技术[23]中19个乙烯生产装置2010~2014年的月生产数据为分析对象。首先,选取某生产装置2012年原油、燃料、蒸汽、水、电作为网络的输入,将产物乙烯、丙烯、碳四之和作为网络的输出,构成5输入单输出训练样本数据,分别比较三层BP网络、K-RBF与FCM-RBF的平均误差随隐藏层节点数增加的变化情况,如表3所示(AA/BB,AA为平均训练误差,BB为平均泛化误差)。

表3 BP、K-RBF和FCM-RBF相对误差与隐含层节点相对情况Table 3 Relative situation between relative error and hidden node of K-RBF and FCM-RBF
上述实验选取网络学习因子为0.01,动量因子为0.9,BP网络及RBF网络最大迭代次数为1000次,激励函数为S型函数,对于RBF-FCM网络,通过实验选取加权指数M = 1.5。从整体上可知,RBF网络的收敛速度要快于BP网络的收敛速度,同时FCM-RBF的训练效果要优于K-RBF网络。当隐藏层节点数大于1时,对于RBF网络(包括K-RBF 和FCM-RBF)其相对训练误差及相对泛化误差都在5%之内,就泛化能力而言,K-RBF与FCM-RBF相差无几,但是当节点数大于6时(K-RBF的相对泛化误差分别为:4.52%,4.67%,4.27%,4.25%;FCM-RBF的相对泛化误差分别为:4.17%,4.14%,4.13%,4.11%),FCM-RBF的泛化能力要优于K-RBF。
基于上述分析,本文选用FCM-RBF网络中隐藏层节点数为7,加权指数为1.4,迭代次数为1000,进行乙烯装置生产预测分析。并选用2010年228组真实统计数据建立模型,并对2011年乙烯装置生产产量进行预测,结果如图4、图5所示。
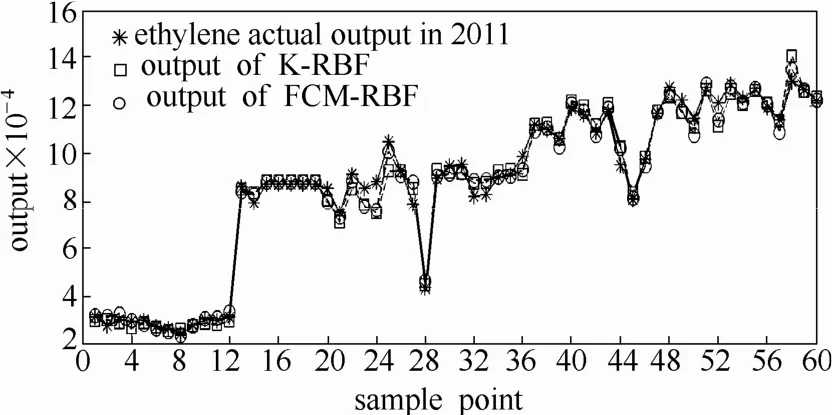
图5 K-RBF和FCM-RBF预测结果的比较Fig.5 Comparison of predictive results between K-RBF and FCM-RBF
从图4中可以看出,FCM-RBF的训练结果较K-RBF更接近实际值,经过计算,K-RBF的平均相对训练误差为6.61%;而FCM-RBF的平均相对训练误差为3.31%。根据图5可以看出,FCM-RBF的预测结果较K-RBF更接近实际值,对2011年的预测,FCM-RBF与K-RBF的平均相对误差分别为3.50%、3.97%。因此利用FCM-RBF模型进行预测,可以更小误差地预测某一年度的乙烯生产量。
为了能够预测相同规模(80万吨级)不同技术下的乙烯生产装置,本文选用LUMMUS顺序分离与S&W技术下某两个乙烯装置2012年的能效相关的真实统计资料建立预测模型,并对2013年乙烯产出进行预测。对两装置预测数据对比情况如图6所示。
由图6中不同技术下两乙烯生产装置2013年预测结果可知,其平均相对泛化误差分别为:4.31%(K-RBF)、4.21%(FCM-RBF)及1.78%(K-RBF)、1.74%(FCM-RBF)。第二个乙烯生产装置预测更准确,说明该技术下该生产装置生产比较稳定,生产状况良好,而第一种技术下乙烯生产波动较大,可以根据生产状况调整乙烯投入量或者引入第一种技术,改进乙烯生产状况,达到生产稳定,投入产出平衡。例如2013年9月投入原油217340.35 t,燃料19.61 GJ,蒸汽0.46 GJ,水2.01 GJ,电0.61 GJ,而实际乙烯、丙烯、碳四的产出总量为121243 t,预测模型产出量为118777 t,说明该装置超负荷运行,在以后生产中应该调整投入产出比,达到满负荷工作,实际10~12月的生产是按照预测模型进行生产的。第二种技术下投入原油199859 t,燃料19.19 GJ,蒸汽1.29 GJ,水2.69 GJ,电2.03 GJ,而实际乙烯、丙烯、碳四的产出总量为92585 t,预测模型产出量为92807 t,说明该装置满负荷生产,在后续生产中该装置可维持该生产状况,而实际后续生产符合该预测模型,生产良好。
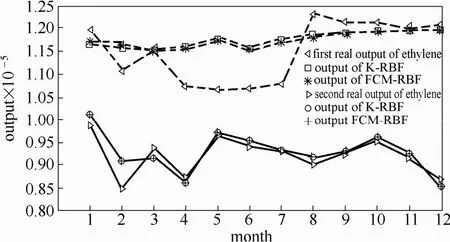
图6 不同技术的乙烯生产装置的预测结果Fig.6 Predictive results of ethylene production plant with different technologies
同时也选取相同技术不同规模下的两装置进行对比,即LUMMUS技术下20万吨及80万吨的两不同乙烯装置2010和2011年真实统计资料,得到如图7所示结果。
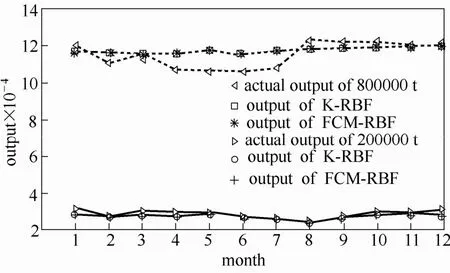
图7 不同规模下的两个不同乙烯生产装置预测结果Fig.7 Predictive results of two different ethylene production plants with different scales
图7中80万吨、20万吨规模下的泛化误差为:4.41%(K-RBF)、4.33%(FCM-RBF)及4.45% (K-RBF)、4.42%(FCM-RBF)。同种技术下20万吨乙烯生产装置比80万吨乙烯生产装置生产稳定,高产出生产规模乙烯投入量大,影响因素多,可以根据预测模型,调整后续各月的投入量到达生产最佳产出值,稳定生产,提高能效。
通过预测结果的比较,不同技术、不同规模下FCM-RBF预测能力都要优于K-RBF,因此可以建立更加精确的乙烯生产预测模型。投入不同比例的原料:原油、燃料、蒸汽、水及电,通过预测模型获得不同比例投入指标下的产量输出,可以指导获得最大效益的原料投入产出比,因此为乙烯生产原料投入分析提供一个新思路。
4 结 论
本文提出了FCM-RBF网络预测模型,模糊C均值算法能够对大型时序数据降维,并消除初始聚类中心对聚类结果的影响;同时通过UCI标准数据集测试验证了本文所提方法相对于BP和K-RBF网络,隐藏层节点数更少,训练速度更快,训练误差更小,同时也不会减弱RBF网络模型的回想及泛化能力。并预测比较了不同技术、不同规模下乙烯装置的生产状况,分析原料投入与产品产出比,能够较准确地预测乙烯生产能力情况,指导乙烯生产,提高能效。在以后的研究中,将基于乙烯动态实变数据进行实时预测,进一步实时准确地分析优化乙烯生产效率,提高乙烯能效。
References
[1] 管调生, 姬伟毅. 中国石化2008年乙烯业务述评 [J]. 乙烯工业, 2009, 21(1): 1-6.
GUAN D S, JI W Y. Review of Sinopec’s ethylene production in 2008 [J]. Ethylene Industry, 2009, 21(1):1-6.
[2] 章龙江, 胡杰. 中国石油2008年乙烯业务述评 [J]. 乙烯工业, 2009, 21(1): 7-10.
ZHANG L J, HU J. Review of Petrochina’s ethylene production in 2008 [J]. Ethylene Industry, 2009, 21(1): 7-10.
[3] REN T, PATEL M, BLOK K. Olefins from conventional and heavy feedstocks [J]. Energy, 2006, 31(4): 425-451.
[4] GAN M, PENG H, CHEN L Y. A global-local optimization approach to parameter estimation of rbf-type models [J]. Information Sciences, 2012, 197(15): 144-160.
[5] RUMELHART D E, HINTON G E, WILLIAMS R J. Learning representations by back-propagating errors [J]. Nature, 1986, 323: 533-536.
[6] YU H, XIE T T, PASZCZYÑSKI S, et al. Advantages of radial basis function networks for dynamic system design [J]. IEEE Trans. Ind. Electron., 2011, 58(12): 5438-5450.
[7] XIE T T, YU H, WILAMOWSKI B. Comparison between traditional neural networks and radial basis function networks[C]// Proceedings of the IEEE International Symposium on Industrial Electronics. 2011: 1194-1199.
[8] BROOMHEAD D S, LOWE D. Multivariable functional interpolation and adaptive networks [J]. Complex Systems, 1988, 2: 321-355.
[9] 朱群雄, 石晓赟, 顾祥柏, 等. 基于时序数据融合的乙烯装置能效价值研究及应用 [J]. 化工学报, 2010, 61(10): 2620-2626.
ZHU Q X, SHI X Y, GU X B, et al. Time-series data fusion and its application to energy efficiency value for ethylene plants [J]. CIESC Journal, 2010, 61(10): 2620-2626.
[10] CENK B, IREM D, BIRGONUL M T. Comparing the performance of traditional cluster analysis, self-organizing maps and fuzzy c-means method for strategic grouping [J]. Expert Systems with Applications, 2009, 36(9): 11772-11781.
[11] OLIVEIRA J V D, PEDRYCZ W. Advances in Fuzzy Clustering and Its Applications[M]. West Sussex: Wiley, 2007.
[12] CHUANG K H, CHIU M J, LIN C C, et al. Model free functional MRI analysis using Kohonen clustering neural network and fuzzy C-means [J]. IEEE Transactions on Medical Imaging, 1999, 18(12): 1117-1128.
[13] 袁方, 周志勇, 宋鑫. 初始中心优化的K-means聚类算法 [J]. 计算机工程, 2007, 33(3): 224-227.
YUAN F, ZHOU Z Y, SONG X. K-means clustering algorithm with meliorated initial center [J]. Computer Engineering, 2007, 33(3): 224-227.
[14] 徐义峰, 陈春明, 徐云青. 一种改进的K2均值聚类算法 [J]. 计算机应用与软件, 2008, 25(3): 27-31.
XU Y F, CHEN C M, XU Y Q. An improved clustering algorithm for K2-means [J]. Computer System Application, 2008, 25(3): 27-31.
[15] 刘德馨, 李晓理, 周翔, 等. 模糊C均值聚类算法在高炉料面分类中的应用 [J]. 北京科技大学学报, 2012, 34(6): 683-690.
LIU D X, LI X L, ZHOU X, et al. Application of the fuzzy c-means clustering algorithm in blast furnace burden surface identification [J]. Journal of University of Science and Technology Beijing, 2012, 34(6): 683-690.
[16] ZOO Data Set, UCI Machine Learning Repository [DB/OL]. Irvine, CA: University of California. http://archive.ics.uci.edu/ml.
[17] WINE Data Set, UCI Machine Learning Repository [DB/OL]. Irvine, CA: University of California. http://archive.ics.uci.edu/ml.
[18] The limitation of energy consumption for ethylene product: DB 37/751-2007 [S].
[19] The general computing guide of special energy consumption: GB/T 2589—2008 [S].
[20] 耿志强, 朱群雄, 顾祥柏. 基于关联层次模型的乙烯装置能效虚拟对标及应用 [J]. 化工学报, 2011, 62(8): 2372-2377.
GENG Z Q, ZHU Q X, GU X B. Dependent function analytic hierarchy process model for energy efficiency virtual benchmark and its applications in ethylene equipments [J]. CIESC Journal, 2011, 62(8): 2372-2377.
[21] GENG Z Q, HAN Y M, YU C P. Energy efficiency evaluation of ethylene product system based on density clustering data envelopment analysis model [J]. Advanced Science Letters, 2012, 5: 1-7.
[22] 王学雷. 面向乙烯生产流程的能源消耗动态定标方法 [J]. 计算机与应用化学, 2010, 27(9): 1166-1170.
WANG X L. A Dynamic benchmarking method for energy consumption of ethylene production process [J]. Computers and Applied Chemistry, 2010, 27(9): 1166-1170.
[23] GENG Z Q, HAN Y M, GU X B, et al. Energy efficiency estimation based on data fusion strategy: case study of ethylene product industry [J]. Industrial & Engineering Chemistry Research, 2012, 51: 8526-8534.
[24] Calculation method for energy consumption in petrochemical engineering design: SH/T 3110—2001 [S].
[25] HAN Y M, GENG Z Q, LIU Q Y. Energy efficiency evaluation based on data envelopment analysis integrated analytic hierarchy process in ethylene production [J]. Chinese Journal of Chemical Engineering, 2014, 22(11/12): 1279-1284.
研究论文
Received date: 2015-12-16.
Foundation item: supported by the National Natural Science Foundation of China (61374166, 71572008), the Specialized Research Fund for the Doctoral Program of Higher Education of China (20120010110010), and the Fundamental Research Funds for the Central Universities (YS1404, ZY1502).
Ethylene plants production capacity forecast based on fuzzy RBF neural network
GENG Zhiqiang1,2, CHEN Jie1,2, HAN Yongming1,2
(1College of Information Science and Technology, Beijing University of Chemical Technology, Beijing 100029, China;2Engineering Research Center of Intelligent PSE, Ministry of Education in China, Beijing 100029, China)
Abstract:For the conventional radial basis function (RBF) neural network, there are many problems like uncertain nodes in the hidden layer, sensitivity to initial centers and slow convergence speed, etc. This paper proposes an RBF neural network model based on the fuzzy C-means method (FCM-RBF), with each cluster center obtained by fuzzy C-means clustering. And weights between the hidden layer and the output layer are trained by the gradient descent method based on error back-propagation (BP). The proposed method overcomes the sensitivity of the data center for traditional RBF model, determines optimally the number of nodes in the hidden layer of RBF neural network, and improves the network training speed and precision. Finally, the proposed method is applied in the production capacity forecast of the ethylene plants. The production statuses of ethylene plants of different technologies or different scales are analyzed and predicted to guide the ethylene production and improve energy efficiency. The empirical results demonstrate the effectiveness and practicability of the proposed algorithm.
Key words:ethylene plant;production capacity forecast;fuzzy C-means cluster;radial basis function neural network;model-predictive control;neural networks;production
DOI:10.11949/j.issn.0438-1157.20151910
中图分类号:TP 29
文献标志码:A
文章编号:0438—1157(2016)03—0812—08
基金项目:国家自然科学基金项目(61374166, 71572008);高等学校博士学科点专项科研基金(20120010110010);中央高校基本科研业务费(YS1404,ZY1502)。
Corresponding author:HAN Yongming, hanym@mail.buct.edu.cn
猜你喜欢
现代电力(2022年2期)2022-05-23
小学科学(学生版)(2020年10期)2020-10-28
中国化肥信息(2020年7期)2020-03-19
电子制作(2019年19期)2019-11-23
汽车观察(2018年12期)2018-12-26
中国军转民(2017年6期)2018-01-31
消费导刊(2017年24期)2018-01-31
北京航空航天大学学报(2017年12期)2017-04-23
重型机械(2016年1期)2016-03-01
现代计算机(2016年17期)2016-02-28
