
数据挖掘在大学英语成绩预测中的应用研究
2016-05-16 01:57栾红波文福安
软件 2016年3期
栾红波+文福安


摘要:“数据驱动学校,分析变革教育”的大数据时代已经来临,数据挖掘这一技术在教育行业随之诞生。随着社会对英语的应用日益增加,英语学习日益重要,大数据及数据挖掘技术在英语教学与学习中的应用与研究将成为新的发展趋势。本研究是基于大学英语技能训练系统产生的教学数据进行的挖掘分析,选取和学生成绩相关的数据作为特征,以学生考试成绩为目标,运用GBDT模型进行模型训练,实现了学生成绩的预测,经过评估、分析发现用数据挖掘技术可以比较准确的预估学生成绩,验证了数据挖掘技术在大学英语学习中的应用,以及GBDT模型对结果预测的影响,对学生学习和教师教学有很大的指导作用和使用价值。
关键词:数据挖掘;大学英语;预测
中图分类号:TP391.1 文献标识码:A DOI:10.3969/j.issn.1003-6970.2016.03.017
0引言
近年来,教育改革一直是社会关注的重点问题之一。随着社会的不断进步,高端科学技术、产品在社会的各个领域中得到了广泛应用,使得人们生活质量在不断提高。同样,教育行业的教学质量也随之在不断地提升,教学方法、手段不断、教学环境等处于更新换代过程中。随着互联网的快速发展,大数据随之而生,使数据挖掘技术在教育领域中不断地得到应用,为学校、教师、学生都提供了便利的教学条件,而对于数据挖掘技术在教育领域的应用也受到广泛的关注。在英语学习过程中,影响学生学习英语的因素很多,需要对各因素进行综合分析。在大数据时代,如何从大量数据中找出有价值的信息并利用这些信息预测未知的或未来值的过程变得愈加重要,数据挖掘技术就是通过构建相关模型,探索信息之间的相关关系。
1数据挖掘技术理论
1.1数据挖掘概念
数据挖掘(data mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中提取隐含其中的、事先未知的、但又具有潜在价值的信息和知识过程。数据挖掘是一门由多个学科交叉与融合而形成的新兴学科,集成了众多学科中成熟的工具和技术,包括数据库技术、统计学、机器学习、模式识别、人工智能和神经网络等。
数据挖掘的技术有很多种,按照不同的分类有不同的分类法。一般分为有监督算法和无监督算法,其中有监督算法主要有逻辑回归、决策树等,无监督学习主要包括聚类、最邻近距离、支持向量机等。从应用角度上可以分为分类算法、回归算法、聚类分析算法、关联规则、时序和偏差检查算法。
1.2 GBDT算法简介
决策树是一个具有树状结构的模型,可以看成if-then的规则结合,从根节点开始在每个节点上按照给定标准选择测试属性,然后按照相应属性的所有可能取值向下建立分枝、划分训练样本,直到一个节点上的所有样本都被划分到同一个类,或者某一节点中的样本数量低于给定值时为止,这一阶段最关键的操作是在树的节点上选择最佳划分方式。最佳划分结点方法的选择标准有信息增益、基尼指数等。
GBDT的全称是Gradient Boosting Deeision Tree,其中Gradient Boosting和Deeision Tree是两个独立的概念。Boosting是用一些弱分类器的组合来构造一个强分类器,GBDT即通过迭代多棵树来共同决策。其核心就在于每一棵树都是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。因此,GBDT是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终结果。GBDT是一个应用很广泛的算法。本文主要应用GBDT算法做回归。
2英语考试成绩预测的实现
本研究运用GBDT算法对大学英语技能训练系统中学生成绩进行预测,历经了数据提取、数据预处理、特征选择、训练模型、预测未知数据等关键步骤,如图1。其中,数据提取、预处理及特征选择是处理训练数据集的过程,模型训练阶段及参数调整是个不断优化、反复执行的过程,直到得到预期的结果。
2.1数据提取和预处理
本研究主要从大学英语技能训练系统中提取学生信息,分别选取了2013至2014年春、秋季四个学年中一、二年级学生数据,最终的数据文件类型选择以纯文本形式存储表格数据的CSV格式。
数据预处理是在数据挖掘前的数据准备工作,数据的好坏是预测结果好坏的前提条件,其目的是去除与目标不相关的数据属性和内容,为数据挖掘提供干净、准确、更有针对性的数据,减少挖掘算法的数据处理量,提高挖掘效率和最终结果的准确度。数据预处理的方法有很多,主要有数据选取、数据清理、数据属性取值一致化、数据集成、数据转换和数据简化等。
本次实验按照上面所述的数据预处理规则进行相应处理,最终得到8000条数据作为训练样本。
2.2特征选择
特征选择是选择获得相应模型和算法最好性能的特征集,在数据挖掘中占有相当重要的地位。本次研究通过使用scikit-learn的MINE工具计算各个特征与预测目标的相关性,得到每个特征的相关性后对所选特征进行排序,经过对数据各维度进行选取,特征主要分为两种,一种为数值型特征,如答题时长、自评分数等,另一种为类别型特征,如性别、题型等。特征确定后,对每个特征进行编码,将每个无序特征转化为数值向量,就是所谓的词向量模型。变换后的向量长度对于词典长度,每个词对应于向量中的一个元素。
本次实验通过特征处理,确定了对挖掘学生成绩预测比较重要的特征,如学号、姓名、性别、答题时长、题型等18个维度。下表1列出了部分特征及数据。
2.3模型训练
模型训练是根据已知数据寻找模型参数的过程,通过给定数据和模型假设空间,可以构建出优化问题,确定相关参数使得预测目标最优化,即模型训练的过程是不断的调试,直至最优。
本次研究使用K-fold交叉验证法,将数据训练集随机划分为训练和测试两部分,通过Python语言、seikit-learn及其它相关第三方库进行模型训练。
输入训练集,使用GBDT模型,选择损失函数、树的最大深度、最小叶子节点个数及其它相关参数,反复调整、优化参数,使之经过数据挖掘技术预测的目标——学生英语成绩最接近真实的数据。
输入测试数据,确定预测的目标是否接近真实英语成绩,验证所选模型及相关参数的正确性、合理性。
3预测结果及分析
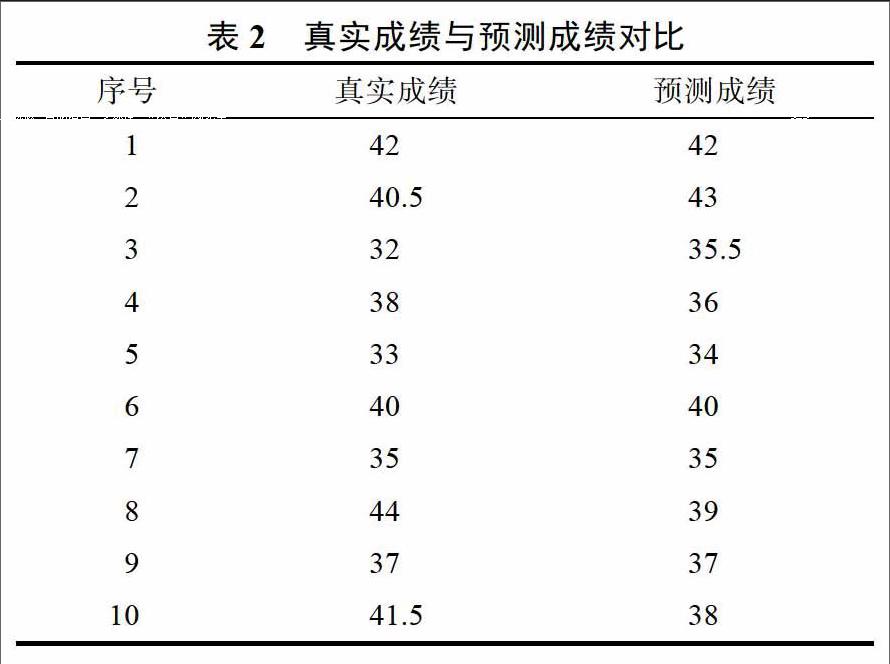
本研究采用数据挖掘回归方法GBDT模型,以大学英语技能训练系统中两个学年的学生英语考试的相关数据为训练数据,在Python及相关的学习包数据挖掘环境中,通过对相关属性的不断精简,最终构建了大学英语考试学生成绩的预测模型,并实现了学生成绩的预测,从而得到与学生真实成绩比较相近的分数。该模型以题型、答题时间、自评成绩等18个特征最终为GBDT的形成因素,构建决策树6课,最小样本叶子结点6个,最大深度为5。下表2为训练数据的部分真实成绩与预测成绩,其中满分为50分。
实验结果使用MAE(Mean Absolute Error)进行评估,MAE表示预测值与真实值之间的差距,其值越小越好,最终得到所有数据集的MAE为0.7,其中79.86%的数据误差为0,即预测的准确度为79.86%。对比真实成绩与预测成绩曲线图,发现两条曲线很相近,说明预测的分数很接近真实分数。
上实验结果表明,GBDT模型能够对大学英语考试成绩进行比较准确预测,通过数据挖掘技术,对学生考试成绩进行分析评估,提取出各个层次的学生对教学过程中英语知识的掌握程度,进行有针对性的教学。
4结论
本文用大学英语技能训练系统中和成绩相关特征的数据,使用GBDT模型实现了学生成绩的预测,通过实验证明数据挖掘技术在英语成绩的预测的准确性、可行性。数据挖掘技术在教育行业中得到很好的应用,在大数据时代,运用数据挖掘技术必将改变教育的传统面貌。本研究对大学英语成绩的预测有助于学生英语学习,以及教师对考试结果的深入了解。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
电力与能源(2017年6期)2017-05-14
考试周刊(2016年77期)2016-10-09
大学教育(2016年9期)2016-10-09
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
