
Learning control of fermentation process with an improved DHP algorithm☆
2016-05-26 09:28DaziLiNingjiaMengTianhengSong
Dazi Li*,Ningjia Meng,Tianheng Song
Institute of Automation,Beijing University of Chemical Technology,Beijing 100029,China
1.Introduction
Ethanol fermentation is a complex chemical reaction process.Properties of noise,nonlinear,and dynamics make it difficult to control.An optimal substrate feeding policy problem was proposed[1],where the fed-batch fermentation process was described by four inner state variables including the substrate concentration and the product concentration.In[2],the dynamic reoptimization problem of a fed-batch biochemical process was studied to make the applicability of a class of adaptive critic designs(ACDs)for online reoptimization.
As pointed out in[3],the objectives of fed-batch processes contain maximizing biomass concentration,and minimizing ethanol formation.Also in[3],the genetic search approaches are used to solve these problems.Nonlinear optimal control methods developed for the fed-batch fermentation process have been widely researched[4].However,due to the difficulties in designing nonlinear controllers for chemical processes with uncertain dynamics,intelligent control methods including various learning control techniques have been studied in recent years[5,6].
As studied in[7],a controller based on a dynamic programming method for a fed-batch bioreactor was developed to find the optimal glucose feed rate pro file.Based on the Bellman optimality principle,the dynamic programming methods are mainly used to solve the optimization problems of the dynamic processes with the constraint conditions.However,the original dynamic programming algorithms suffer from the “curse of dimensionality”.Consequently,these methods show no good performance for the complex,nonlinear continuous environments.
Developments of Q-Learning algorithm[8]still cannot avoid the problem of the “curse of dimensionality”.Aiming at this problem,certain progresses have been made.ACDs[9]can approximately obtain the system state value functions through establishing a “critic”,that is,in order to obtain optimal solution,ACDs make use of function approximation structure(e.g.,the neural network)to approximate the value functions.As a class of ACDs,heuristic dynamic programming(HDP)is widely studied as an important learning control method for a bioreactor system[10].As well known,dual heuristic programming(DHP)algorithm needs more model information but has better learning control effect,especially when the system parameters and environmental conditions are time-variant[11,12].HDP,DHP and Globalized DHP(GDHP)[13]are all belong to adaptive dynamic programming(ADP)[14].They are applied to the online learning control and optimal control problems[15,16].In recent years,Xu et al.proposed kernel DHP and its performance is analyzed both theoretically and empirically[17,18].
In the critic learning of DHP,the critic network constructed with neural network shows low efficiency in previous research.Furthermore,derivatives of state value functions are affected by the setting of initial weights,structure selection and iteration speed in the neural network.To solve the above problems,a new DHP algorithm integrating the least squares temporal difference with gradient correction(LSTDC)algorithm[19]as the critic is developed in this paper.The main purpose is replacing neural network structure with LSTDC to simplify the weight adjustment process and to improve approximation precision and convergence speed.Then the improved DHP algorithm based on LSTDC(LSTDC-DHP)is applied to realize efficient online learning control for the fed-batch ethanol fermentation process.Simulation results demonstrate that LSTDC-DHP can obtain the near-optimal feed rate trajectory in continuous spaces.
TThe rest of this paper is organized as follows. Following the introduction,the model of fed-batch ethanol fermentation process is described in Section 2.A review of the Markov decision processes(MDPs)and ACDs is presented in Section 3.The proposed LSTDC-DHP is derived in Section 4.To show the applicability of LSTDC-DHP,simulation experiments are implemented and empirical results are presented in Section 5.Finally the main conclusions are summarized in Section 6.
2.Problem Formulation
The studied process is the fed-batch ethanol fermentation process presented in[20].The main components in reaction tank contain cell mass,nutrients,water and substrate.The most prominent feature of this process plant is continuously fed by concentrated substrate shown in Fig.1.The chemical reaction is shown in Eq.(1).
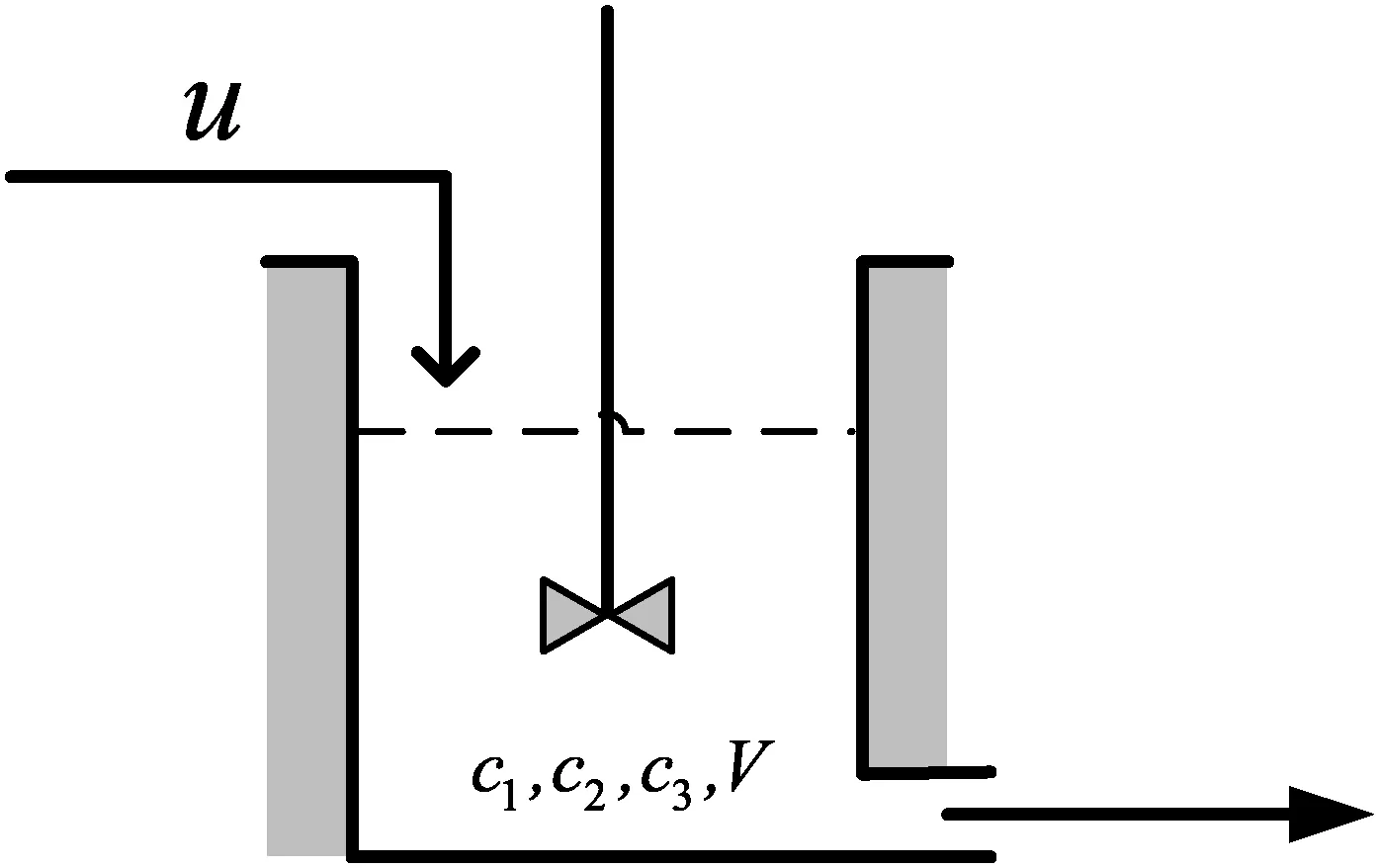
Fig.1.The ethanol fermentation plant.
In a certain temperature,the raw materials including glucose,zymase and ethanol take complex dynamic biochemical reactions.
The reaction mechanistic model can be described by the following equations:

where c1is the cell mass concentration(g·L−1),c2denotes the substrate concentration(g·L−1),c3stands for the product concentration(g·L−1),and V is the liquid volume of there actor(L).The feed-rate to there actor is denoted by u,which is constrained by 0L·h−1≤u≤12L·h−1.The specific growth rate,ε,and the specific productivity,τ,are functions of c2and c3.
In Eqs.(2)and(3),the assumed measurable initial state contains four variables which are specified as[c1,c2,c3,V]=[1,150,0,10].The liquid volume V of the reactor is limited by 200 L.The final batch time tfis fixed as 3 h.
Target of the optimal control is to maximize the yield at the end of a fixed processing time of 3 h.The operated variable is the feed-rate of substrate,u.By combining and integrating the last two differential formulas of Eq.(2),the maximum product output can be obtained as follows:

3.Brief Overview on MDPs and ACDs
3.1.Markov decision processes
Markov chain is a kind of discrete stochastic process with Markov property.This kind of stochastic process has the following characteristics:the next state of the random process is only related to the current state,but not to any other historical states.A MDP is composed of a tuple{X,A,P,R},where X is the state space,A is the action space,P is the state transition probabilities,and R is the reward function.When a certain state xtat time-step t is reached, an action atis chosen under a fixed policy πt.This deterministic stationary policy directly maps states to actions,which is denoted as
When the actions atsatisfy Eq.(7),π is called a Markov policy.The objective of a decision maker is to estimate the optimal policy π∗to satisfy
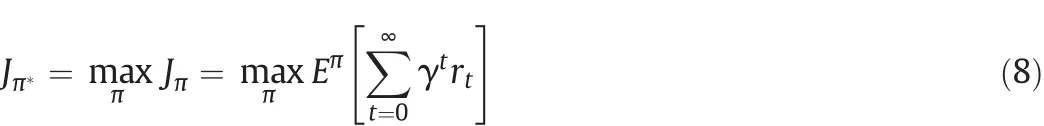
where γ∈(0,1)is a discount factor for infinite horizon problems;Eπ[·]stands for the expectation with respect to the policy π and the state transition probabilities.
The state value function V(xt)is defined as the future expected discounted total reword beginning with xtwhen getting through the action of the discount factor:

For any policy π,the value function is defined as infinite time accumulated expected discounted rewards,namely,

3.2.Adaptive critic designs
In the last few years,ACDs have been widely studied in the field of reinforcement learning.ACDs mainly consist of three parts:the critic network,the model network and the actor network.The basic idea of ACDs is to construct the approximate function that meets the Bellman optimality principle by adjusting the weights of the critic network.ACDs are applicable in the noisy,nonlinear,and non stationary environments.DHP is a very important class of ACD methods.DHP uses both value function approximation(VFA)and policy gradient learning strategy algorithm to search for a near-optimal control policy in the continuous spaces.
Generally,the training of ACDs is carried out by the policy iteration process of the dynamic programming.The critic network evaluates the control performance of actor network,which is called policy evaluation process.Meanwhile,the actor network produces the control actions and improves its policy according to the evaluation of the critic network,namely,policy improvement process.
4.The Improved DHP Algorithm Based on LSTDC
4.1.Previous work on value function approximation
Since the real-world engineering application problems with large or continuous state spaces exist widely,tabular representations of value functions suffer from the difficulties of great computation and large storage requirements.In order to deal with the generalization of Markov chain learning prediction problem with large and continuous state spaces,and to realize the temporal differences(TD)learning,the TD(λ)algorithm[21]based on VFA has been widely studied in the reinforcement learning and operations research community.
The estimated value function represented by a general linear VFA can be denoted as

For arbitrary 0≤λ≤1,the linear TD(λ)algorithm with probability 1 converges to the unique solution of the following equation:

Least squares temporal difference(LSTD)algorithm was proposed to overcome the difficulty of selecting learning factor in linear TD(λ)algorithm,and to improve the efficiency of the data and the convergence speed of the algorithm[22]. In LSTD(0), the performance function is defined as

By employing the instrumental variables approach, the least-squares solution of the above equation is given as
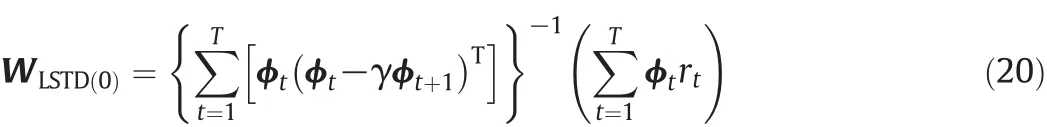
where ϕtis the instrumental variable which is not with respect to the input and output observation noises.
In order to reduce the computational burden of the matrix inversion and to realize online learning,the LSTD(0)algorithm was further derived to the recursive form RLS-TD(0)[22].The update rules of RLSTD(0)take the form of

In LSTD(0)and RLS-TD(0),the decaying factor is 0.Equivalently,the above two algorithms do not employ the eligibility trace.Accordingly,the RLS-TD(λ)algorithm[23]is considered to further improve the efficiency of TD algorithm.Therefore,Eq.(19)is further modified as

Based on the above derivation,the weight vector update rules of RLS-TD(λ)have the following form
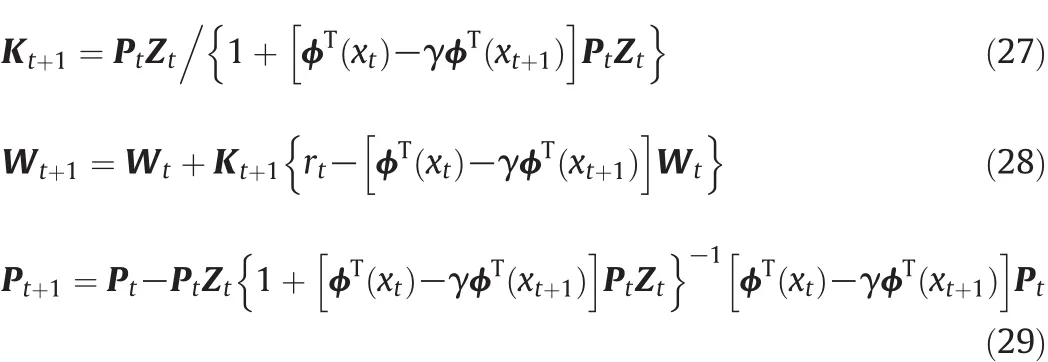
where Ktis a recursive gain matrix and Ptdenotes the variance matrix calculated in the weight updating process.
4.2.LSTDC-DHP algorithm
When facing with the more complex control problem,the online reinforcement learning algorithm is needed to further speed up the convergence,and to make the control algorithm more stable.Therefore,another improved algorithm, TD with gradient correction(TDC)[24–27],is derived.The mean-square projected Bellman error performance function employed in TDC is described by

where T is the Bellman operator and Π is a projection that can projectback to the VFA function space.
Based on the above performance function, the weight update rules of the TDC algorithm can be obtained

where αtand ηtare the learning factors,andis the temporal difference error.
Next,a framework of LSTDC is introduced to the weight adjustment in the critic learning of DHP.Based on this framework,we present the idea on how to improve the critic network in DHP.Different from previous works,our work focuses on extending LSTDC-DHP to learning control problems in the batch fermentation process. The aim is to obtain better performance compared with previous DHPs with TD algorithm.A general framework of DHP is shown in Fig.2.The main components include a critic,an actor,a model,and a plant.Model is the system model which is established.And the plant is the system process.The critic is used to approximate the derivatives of value functions.The actor receives the plant's current state xtand outputs the control at.
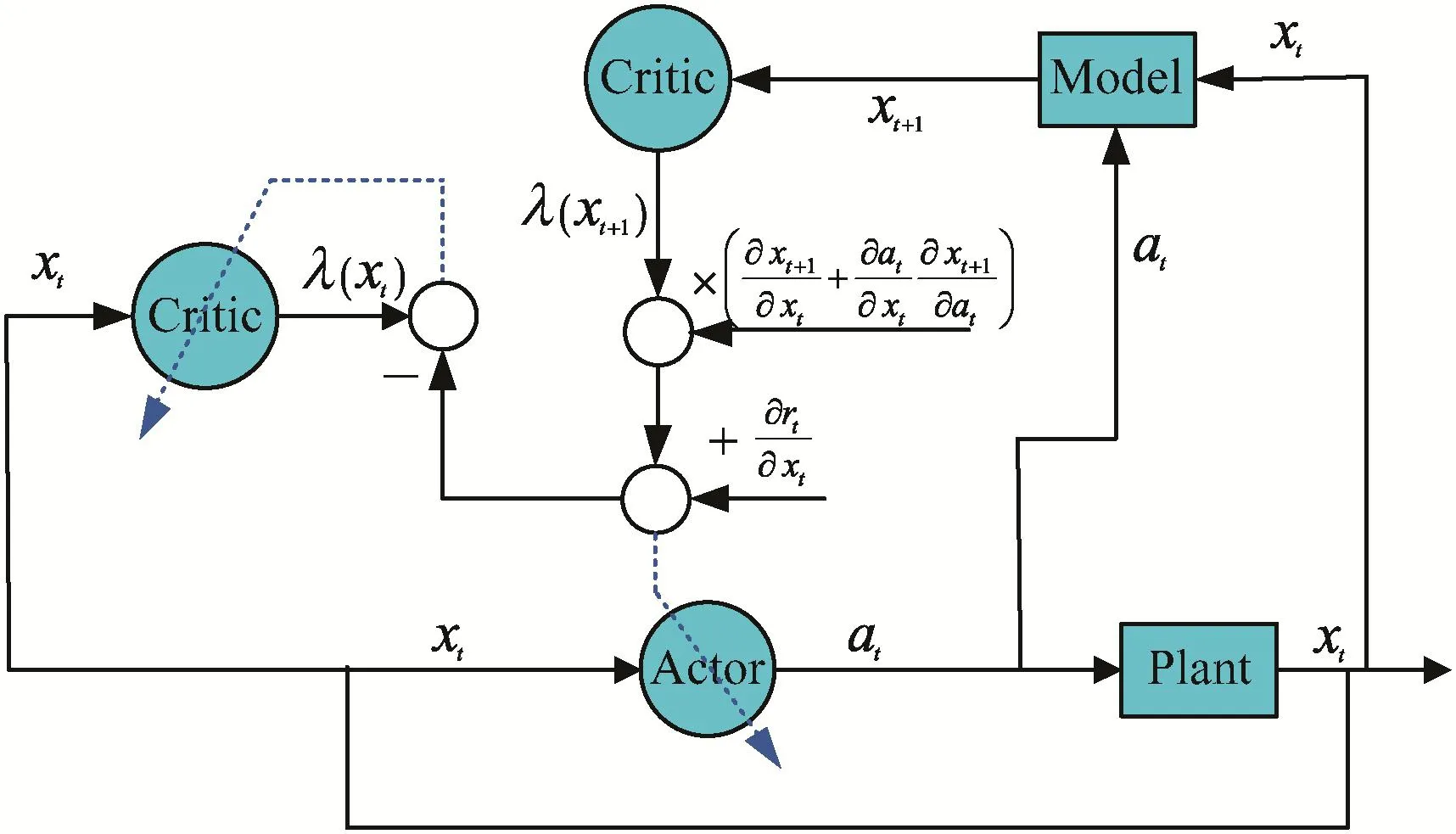
Fig.2.Learning control structure of DHP.
Then the model receives the control at,and estimates the next state x.The polynomialsare derived in the next
t+1section.
4.2.1.Critic network
ACDs are actor–critic learning control architecture forms.As shown in Fig.2,the critic network estimates the state value function V(xt)by using the following Bellman equation of dynamic programming

To approximate the derivatives of state value functions,the main route to improve the DHP algorithm is to change the approximation method of two key parameters λ(xt)and λ(xt+1).Therefore,VFA is constructed by LSTDC which is used to replace the critic neural network structure,namely
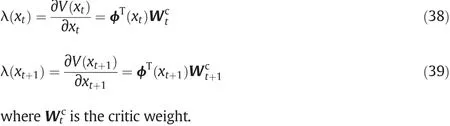
Since the value function parameters make the sum of TD updates over the observed trajectory to be zero,the sums of TDC updates in Eqs.(31)and(32)should be zero as follows:

In order to make sure Gtis full rank, the ridge regression is employed by initializing Gtwith an identity matrix multiplied by a small positive number g.As a basic ridge regression problem,the effect of g is not only to make Gtinvertible,but also to affect the critic weight on regularization.Since few literatures have previously discussed the sensitivity relating to g value choice, the choice of g value is based on trial and error in simulation experiments. The LSTDC update rules for critic learning in LSTDC-DHP are as follows

LSTDC is used to construct a proper basis function to replace the critic neural network structure in LSTDC-DHP.difficulties of selecting parameters in the previous DHP based on neural network function approximation can be overcome.Therefore,the approximation precision and convergence speed of critic network are improved.The critic weight can be rapidly estimated only by constructing a suitable basis function to obtain continuous observation data.
4.2.2.Actor network
The actor network is used to generate the control actions based on the observed states of the plant. The output of the actor network is given by

4.2.3.Model network
The model network is to approximate the characteristics of dynamic process. The mechanistic model of fed-batch ethanol fermentation process is regarded as the model network.
Algorithm 1.Learning control of fermentation process based on LSTDC-DHP
(1)Give the initial critic weightsand actor weights
(2)Set t=0 and J0=0
(3)According to the current state xt,compute the out put of the actorselect the action ut,and observe the next state xt+1,get next reward rt+1;
(4)Compute the performance index function Jtaccording to Eq.(4);
(5)Apply LSTDC described in Eqs.(47)and(48)to update the weights of the critic network;
(6)Update the weights of the actor network using Eq.(52);
(7)Until Jt+1−Jt≤0 or the fermentation time reaches tf;
(8)Let t=t+1,return to(3).
In the weight adjustment process of LSTDC-DHP,the weight is estimated by using continuous observation data which is generally easy to obtain.Therefore,LSTDC-DHP can be applied in the batch process with greatly improved efficiency of the weight update and reduced parameter setting.The procedure of LSTDC-DHP is briefly summarized in Algorithm 1.
5.Simulation Studies and Discussion
The learning control of the fed-batch ethanol fermentation process is studied to illustrate the effectiveness of LSTDC-DHP applied to the continuous process.To solve the reinforcement learning problem with continuous state space,a class of linear function approximators,which is called Cerebellar Model Articulation Controller(CMAC)is used.It is well known that CMAC has been widely used in process control and function approximation.In the LSTDC-DHP learning algorithm,a CMAC neural net work with four inputs and one output is used in the actor network.
In the experiment,the actor's learning factor is βt=0.3.The weights of the critic network and the actor network are all initialized as 0.Gtis initialized to an identity matrix and htis initialized as 0.The other parameters are set as γ=0.95,c1=0.4 and c2=0.5.The initial state vector[c1,c2,c3,V]is initialized as[1,150,0,10].The time step is 5min in the simulation process.A learning control process of ethanol fermenter is defined as starting from the initial state to 36 time steps.The learning control results are shown in Fig.3.The optimal control policy curve is continuous.The cell mass concentration,the substrate concentration and the product concentration reach steady states at the end of fixed batch time.We can find that the yield of the ethanol fermentation process is becoming smooth gradually in the learning control process. It can also be seen that the performance index converges to the steady-state value eventually.
Considering productive benefit,the specific growth rate and the specific productivity which is in the reaction mechanistic model should be strictly increasing until reaction termination.According to Eq.(3),the product concentration shown in Fig.3 should decline when the substrate concentration rises for the sake of ascending ε and τ.The liquid volume of the reactor increases all the time.Though the cell mass concentration descends,the cell mass amount is increased on the whole.In order to improve the production,the cell mass needs to consume more substrates.Therefore,the feed-rate to the reactor suddenly rises.
In addition,two other DHP methods integrated with RLSTD(λ)and TDC as the critic algorithms are also implemented for the same control problem,named RLSTD(λ)-DHP and TDC-DHP.Including RLSTD(0)-DHP by Xu et al.[18],three methods are used for comparison with LSTDC-DHP.For TDC-DHP,the critic's learning factor is αt=0.1 and ηtis initialized as 0.1.Then,in a similar way,the variance matrix Ptis set to be identity matrix in RLSTD(0)-DHP.λ is equal to 0.6 and the eligibility trace vector is initialized as 0 in RLSTD(λ)-DHP.The performances of the LSTDC-DHP,RLSTD(0)-DHP,RLSTD(λ)-DHP and TDC-DHP algorithms are compared in Fig.4.The yield of the reactor is chosen as the performance index in the simulation experiments.In LSTDC-DHP,we can see that better yield of the ethanol fermentation process and better values of performance index are obtained as shown in Table 1 due to the use of LSTDC.Fig.5 shows the product concentration comparison by different algorithms and Fig.6 shows the control policy curves of the ethanol fermentation process.We can see that the learning control of the fed-batch ethanol fermentation process is completed continuously.Therefore, suitable feed rate obtained by LSTDC-DHP can lead to the maximum yield.

Fig.4.Performance indexes of four different algorithms.

Table 1 Performance comparison under different algorithms
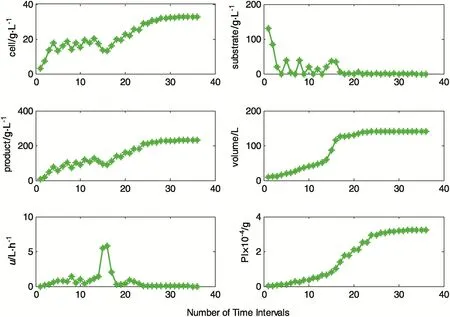
Fig.3.The learning control results of the fed-batch ethanol fermentation process.

Fig.5.Comparison of the product concentration by different algorithms.

Fig.6.Curves of control policies by four different algorithms.
6.Conclusions
In this paper,LSTDC-DHP has been developed to deal with learning control problems. LSTDC is chosen as the critic to replace the neural network structure in LSTDC-DHP.Based on the simulations,performance of LSTDC-DHP is analyzed.From the experiment results,LSTDC-DHP takes effect in simplifying the weight adjustment process and improving the critic's approximation precision.LSTDC-DHP can be used to design the optimal feed rate trajectory curve continuously.Consequently,the aim of obtaining the maximum ethanol product is achieved.Simulation results on the learning control of the fed-batch ethanol fermentation process illustrate the effectiveness of LSTDC-DHP and verify the excellent performance of LSTDC-DHP in continuous spaces.This research also shows that it is promising to study the learning control LSTDCDHP algorithm and apply it to complex,nonlinear dynamic chemical industrial process efficiently.
[1]J.Hong,Optimal substrate feeding policy for a fed batch fermentation with substrate and product inhibition kinetics,Biotechnol.Bioeng.28(9)(1986)1421–1431.
[2]M.S.Iyer,D.C.Wunsch,Dynamic re-optimization of a fed-batch fer mentor using adaptive critic designs,IEEE Trans.Neural Netw.12(6)(2001)1433–1444.
[3]U.Yüzgeç,M.Türker,A.Hocalar,On-line evolutionary optimization of an industrial fed-batch yeast fermentation process,ISA Trans.48(1)(2009)79–92.
[4]A.Ashoori,B.Moshiri,A.Khaki-Sedigh,M.R.Bakhtiari,Optimal control of a nonlinear fed-batch fermentation process using model predictive approach,J.Process Control 19(7)(2009)1162–1173.
[5]C.V.Peroni,N.S.Kaisare,J.H.Lee,Optimal control of a fed-batch bioreactor using simulation-based approximate dynamic programming,IEEE Trans.Control Syst.Technol.13(5)(2005)786–790.
[6]S.Syafiie,F.Tadeo,M.Villafín,A.Alonso,Learning control for batch thermal sterilization of canned foods,ISA Trans.50(1)(2011)82–90.
[7]C.Valencia,G.Espinosa,J.Giralt,F.Giralt,Optimization of invertase production in a fed-batch bioreactor using simulation based dynamic programming coupled with a neural classifier,Comput.Chem.Eng.31(9)(2007)1131–1140.
[8]D.Z.Li,L.Qian,Q.B.Jin,T.W.Tan,Reinforcement learning control with adaptive gain for a Saccharomyces cerevisiae fermentation process,Appl.Soft Comput.J.11(8)(2011)4488–4495.
[9]D.V.Prokhorov,D.C.Wunsch,Adaptive critic designs,IEEE Trans.Neural Netw.8(5)(1997)997–1007.
[10]C.Q.Lian,X.Xu,L.Zuo,Learning control of a bioreactor system using kernel-based heuristic dynamic programming,Proc.World Congr.Intelligent Control Autom.WCICA 2012,pp.316–321.
[11]B.Wang,D.B.Zhao,C.Alippi,D.R.Liu,Dual heuristic dynamic programming for nonlinear discrete-time uncertain systems with state delay,Neurocomputing134(2014)222–229.
[12]C.Q.Lian,X.Xu,L.Zuo,Z.H.Huang,Adaptive critic design with graph Laplacian for online learning control of nonlinear systems,Int.J.Adapt.Control Signal Process.28(2014)290–304.
[13]M.Fairbank,E.Alonso,D.Prokhorov,Simple and fast calculation of the second-order gradients for globalized dual heuristic dynamic programming in neural networks,IEEE Trans.Neural Netw.Learn.Syst.23(10)(2012)1671–1676.
[14]J.Fu,H.B.He,X.M.Zhou,Adaptive learning and control for MIMO system based on adaptive dynamic programming,IEEE Trans.Neural Netw.22(7)(2011)1133–1148.
[15]Z.Ni,H.B.He,J.Y.Wen,Adaptive learning in tracking control based on the dual critic network design,IEEE Trans.Neural Netw.Learn.Syst.24(6)(2013)913–928.
[16]F.X.Tan,D.R.Liu,X.P.Guan,Online optimal control for VTOL aircraft system based on DHP algorithm,Proc.of the 33rd Chinese Control Conf.,CCC 2014,pp.2882–2886.
[17]X.Xu,Z.S.Hou,C.Q.Lian,H.B.He,Online learning control using adaptive critic designs with sparse kernel machines,IEEE Trans.Neural Netw.Learn.Syst.24(5)(2013)762–775.
[18]X.Xu,C.Q.Lian,L.Zuo,H.B.He,Kernel-based approximate dynamic programming for real-time online learning control:An experimental study,IEEE Trans.Control Syst.Technol.22(1)(2014)146–156.
[19]T.H.Song,D.Z.Li,L.L.Cao,K.Hirasawa,Kernel-based least squares temporal difference with gradient correction,IEEE Trans.Neural Netw.Learn.Syst.27(4)(2016)771–782.
[20]Z.H.Xiong,J.Zhang,Neural network model-based on-line re-optimisation control of fed-batch processes using a modified iterative dynamic programming algorithm,Chem.Eng.Process.44(4)(2005)477–484.
[21]R.S.Sutton,Learning to predict by the method of temporal differences,Mach.Learn.3(1998)9–44.
[22]S.J.Bradtke,A.G.Barto,Linear least-squares algorithms for temporal difference learning,Mach.Learn.22(1–3)(1996)33–57.
[23]X.Xu,H.G.He,D.W.Hu,Efficient reinforcement learning using recursive least-squares methods,J.Artif.Intell.Res.16(2002)259–292.
[24]S.Bhatnagar,D.Precup,D.Silver,Convergent temporal-difference learning with arbitrary smooth function approximation,Adv.Neural Inf.Process.Syst.-Proc.Conf 2009,pp.1204–1212.
[25]R.S.Sutton,H.R.Maei,D.Precup,Fast gradient-descent methods for temporal difference learning with linear function approximation,Proc.Int.Conf.Mach.Learn.,ICML 2009,pp.993–1000.
[26]M.Geist,O.Pietquin,Algorithmic survey of parametric value function approximation,IEEE Trans.Neural Netw.Learn.Syst.24(6)(2013)845–867.
[27]H.R.Maei,C.Szepesvári,S.Bhatnagar,R.S.Sutton,Toward off-policy learning control with function approximation,Proc.Int.Conf.Mach.Learn.,ICML 2010,pp.719–726.
 Chinese Journal of Chemical Engineering2016年10期
Chinese Journal of Chemical Engineering2016年10期
- Chinese Journal of Chemical Engineering的其它文章
- CFD modeling of a headbox with injecting dilution water in a central step diffusion tube☆
- Interactions between two in-line drops rising in pure glycerin☆
- Hydrodynamics of three-phase fluidization of homogeneous ternary mixture in a conical conduit—Experimental and statistical analysis
- Adsorption of Hg(II)from aqueous solution using thiourea functionalized chelating fiber☆
- Nickel(II)removal from water using silica-based hybrid adsorbents:Fabrication and adsorption kinetics☆
- Reactive dividing wall column for hydrolysis of methyl acetate:Design and control☆