
社会网中基于主题的局部影响最大化算法研究*
2016-06-07 02:35谢胜男朱敬华
计算机与生活 2016年5期
谢胜男,刘 勇,朱敬华,谭 龙
社会网中基于主题的局部影响最大化算法研究*
谢胜男,刘勇+,朱敬华,谭龙
黑龙江大学计算机科学与技术学院,哈尔滨150080
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(05)-0646-11
E-mail: fcst@vip.163.com
http: //www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant No. 81273649 (国家自然科学基金); the Natural Science Foundation of Heilongjiang Province under Grant No. F201430 (黑龙江省自然科学基金); the Scientific Research Fund of Heilongjiang Provincial Education Department under Grant Nos. 12531476, 12531498 (黑龙江省教育厅科学技术研究项目).
Received 2015-07,Accepted 2015-09.
CNKI网络优先出版: 2015-09-15, http://www.cnki.net/kcms/detail/11.5602.TP.20150915.1615.006.htm l
XIE Shengnan, LIU Yong, ZHU Jinghua, et al. Research on topic-based local in fluence m axim ization algorithm in social network. Journal of Frontiersof Com puter Science and Technology, 2016, 10(5): 646-656.
摘要:局部影响最大化问题是在社会网中寻找最能影响某个目标节点的种集。现有的研究只考虑对单一目标节点的影响,忽略了传播项上的主题分布以及用户之间基于主题的影响概率。重点研究了在主题分布的条
件下,如何选取最能影响目标节点集合的种集,提出了针对目标节点集合的局部影响程度计算方法(topicbased local influence degree computational method,T-LID),在此基础上提出了基于主题的局部影响最大化(topic-based local influence maxim ization,TLIM)问题,并证明了该问题为NP-hard问题。为求解TLIM问题,提出了基于主题的局部贪心算法(topic-based local greedy algorithm,TLGA)以及基于主题的局部传播算法(topic-based local propagation algorithm,TLPA)。多个真实数据的实验结果表明,所提算法可以有效并高效地求解基于主题的局部影响最大化问题。
关键词:社会网;基于主题;局部影响最大化;目标集合
1 引言
最近,许多大型社会网络,例如Facebook和微博,变得越来越受欢迎,因为它们可以把人们联系起来,方便人们进行信息交流。社会网中一个重要问题就是影响最大化问题。影响最大化问题的任务是在社会网中寻找一个种集,使得从这个种集出发能影响到社会网中尽可能多的用户。
Kempe等人[1]首次将影响最大化问题形式化为离散型优化问题。现已存在许多关于社会网影响最大化问题的研究[2-5],其中大多数都集中于寻找在整个社会网中最具影响力的节点,通过这些节点可以使得影响范围达到最大值。然而,这些研究至少忽略了以下两方面问题:第一,在一些应用中,例如个性化推荐、目标广告投放以及个人产品推广等,寻找在整个网络中最能影响目标集合的种集显得更为重要。第二,在真实影响传播过程中,由于传播主题的不同会使得用户之间的影响差异很大,例如导师在研究方向上会对他的学生有极大的影响力,但在流行商品购买方面对他的学生很少具有影响力。
实际上,寻找最能影响目标节点集合的种集,既不能直接选择目标节点的邻居节点,也不能简单地选择全局最具影响力的节点。首先分析以下现象来说明:新浪微博是近几年特别受欢迎的一个社交软件,利用一组从该网站爬取的数据[6]来做进一步的解释。该新浪微博数据集有602个节点,17 595条边,分析新浪微博数据集的统计特征,结果如图1和图2所示。
由图1可以观察到,对于一个给定用户,他通常有几十甚至上百个邻居。因此,对于目标用户集合,很难确定哪些邻居是最能影响目标集合的k个节点,尤其当k比较小的时候。
在图2中,通过总结全局影响力top-k节点的影响覆盖率(k从1到30)可以观察到,即使是影响力top-30的节点集合,在影响覆盖率上也存在很大的空白,这也证明了寻找全局影响力top-k节点不能解决局部影响最大化问题。
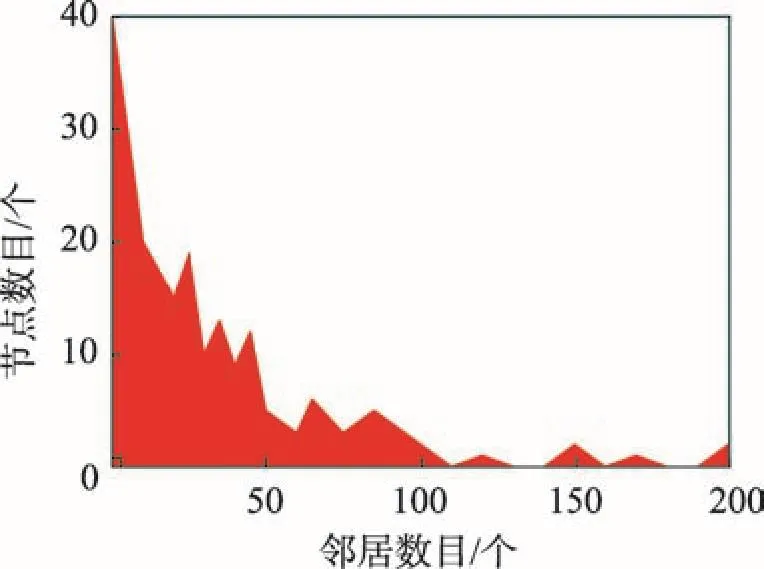
Fig.1 User-neighbor distribution图1 用户-邻居分布
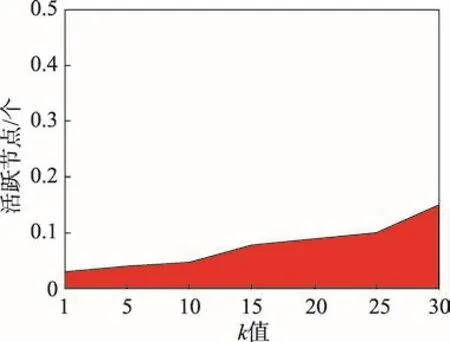
Fig.2 Influence spread vs top-k influential users图2 影响范围和影响力top-k用户
通过分析以上现象可证明,并不可以用现有的解决影响最大化问题的方法解决局部影响最大化问题。并且现有的多数影响最大化研究都忽略了用户之间在不同主题上有不同影响力的情况。显然,提出基于主题的局部影响最大化解决方法有重要的理论意义和广泛的应用价值。本文主要贡献如下:
(1)提出了基于主题的局部影响程度计算方法(topic-based local influence degree computational method,T-LID),在此基础上,提出了基于主题的局部影响最大化(topic-based localinfluencemaximization,TLIM)问题,并证明了该问题为NP-hard问题。
(2)为求解TLIM问题,提出了近似比为1-1/e的基于主题的局部贪心算法(topic-based local greedy algorithm,TLGA)。为支持大规模网络上求解TLIM问题,又提出了一个基于主题的局部传播算法(topicbased local propagation algorithm,TLPA)。
(3)多个真实数据集上的实验结果表明,算法TLGA和TLPA可以有效地解决TLIM问题。尽管TLPA没有近似比保证,但是TLPA比TLGA快近5个数量级,而且TLPA求得的局部影响程度非常接近TLGA。此外,实验结果也证明了在解决局部影响最大化问题时,考虑主题因素可以使得影响程度计算更准确。
本文组织结构如下:第2章介绍了相关工作;第3章给出了基于主题的局部影响程度计算方法T-LID 及TLIM问题定义;第4章提出了基于主题的局部贪心算法TLGA及局部传播算法TLPA;第5章给出了实验结果及分析;第6章对本文工作进行总结。
2 相关工作
Domingos等人[7]最先考虑社会网中具有影响力的节点选择问题。2003年,Kempe等人[1]首次提出了影响最大化问题,证明了影响最大化问题在独立级联模型和线性阈值模型上都为NP-hard问题,并且设计出具有1-1/e近似比的贪心算法。贪心算法虽然简单,但是由于在每次迭代选择种子节点的过程中都需要进行大量的蒙特卡洛模拟来估计影响范围,导致贪心算法的效率较低。Leskovec等人[8]提出了一个CELF优化的方法来改进贪心算法的效率,在保持和简单贪心算法一致的近似比的前提下,比简单贪心算法快700倍。
许多研究通过设计高效的启发式算法来改进大规模网络上影响最大化问题的计算效率。例如,Kimura等人[9]为了更高效地估计影响范围提出了两个基于最短路径的影响级联模型。Goyal等人[10]通过计算邻居节点的简单路径估计影响范围。启发式算法通常没有近似比保证,但具有很高的效率。
Guo等人[6]提出了局部影响最大化问题,即给定一个目标节点w,选择k个对w影响程度最大的节点。同时提出了具有近似比保证的局部影响最大化算法。然而Guo等人的研究中并没有考虑针对目标节点集合T,如何选择最具影响力的k个节点。
以上的求解传统影响最大化和局部影响最大化的研究中都忽略了主题因素。而一些考虑主题的研究也并没有考虑局部影响最大化问题。如Liu等人[11]提出了一个概率模型用来学习主题分布以及主题感知的影响力度。Barbieri等人[12]扩展了传统IC模型,提出了主题感知的独立级联模型(topic-aware influence cascade, TIC),并利用用户的历史动作日志学习TIC模型参数。
为解决上述研究忽略的问题,本文在解决局部影响最大化问题的同时考虑了主题因素。在TIC模型的基础上设计了求解局部影响最大化问题的高效算法。
3 计算方法及问题定义
本文介绍了基于主题的影响传播模型TIC,提出了基于主题的局部影响程度计算方法T-LID,并给出了基于主题的局部影响最大化问题的形式化定义。
3.1 TIC模型
本文使用在文献[12]中提出的TIC模型,该模型是IC模型的扩展,用来将主题混合在每一个传播项中。例如,一个电影可能会包含如下基本的主题:喜剧、爱情、动作等。现给定一个社会网G=(V, E)和用户的历史动作日志D(User, Item, Time),其中元组(u, i, t)代表用户u在时间t采纳商品i。TIC模型要从以上两个给定的数据集中学习参数。假设有Z个基本的主题,z∈[1,Z]代表一个主题。这里认为每个传播项i都存在一个主题分布,用表示,并且。定义概率pzu, v∈[0, 1],代表用户u在主题z上对用户v的影响程度,对于所有的(u, v)∉E 或u=v,pzu, v=0。这里可以得出传播项i在边(u, v)上的影响概率
TIC模型的工作原理与IC模型的工作原理相同:每个节点只有一次机会由不活跃状态变为活跃状态,并且该过程不可逆。在时刻t=0,只有种集S⊆V中的节点为活跃节点,在时刻t≥1,如果节点u在时刻t-1变得活跃,那么它有一次机会以概率p(u, v)激活它的邻居节点v。每个活跃节点有且仅有一次激活其不活跃邻居的机会,传播过程一直持续到没有再被激活的节点为止。
3.2 T-LID计算方法
在这一部分中,将给出基于主题的局部影响程度计算方法T-LID。
令DT(S)表示种集S对目标节点集合T的影响程度。那么,基于主题的局部影响最大化问题的目标就是找到一个集合S,使得DT(S)的值达到最大。因此TLIM问题可以形式化表示为下式:
令ΩS表示整个网络中种集S可能激活的结果构成的样本空间,则DT(S)可以表示为如下形式:
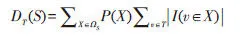
下面利用一个例子简单说明TLD计算过程。
例1利用T-LID方法计算图3中的DT(S),其中。
首先列出ΩS,如表1所示。以ID4为例,ΩS中的概率计算过程如下:
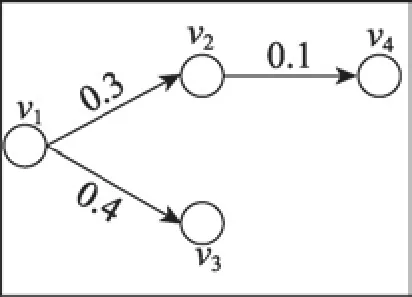
Fig.3 Graph G w ithout topics图3 无主题的图G
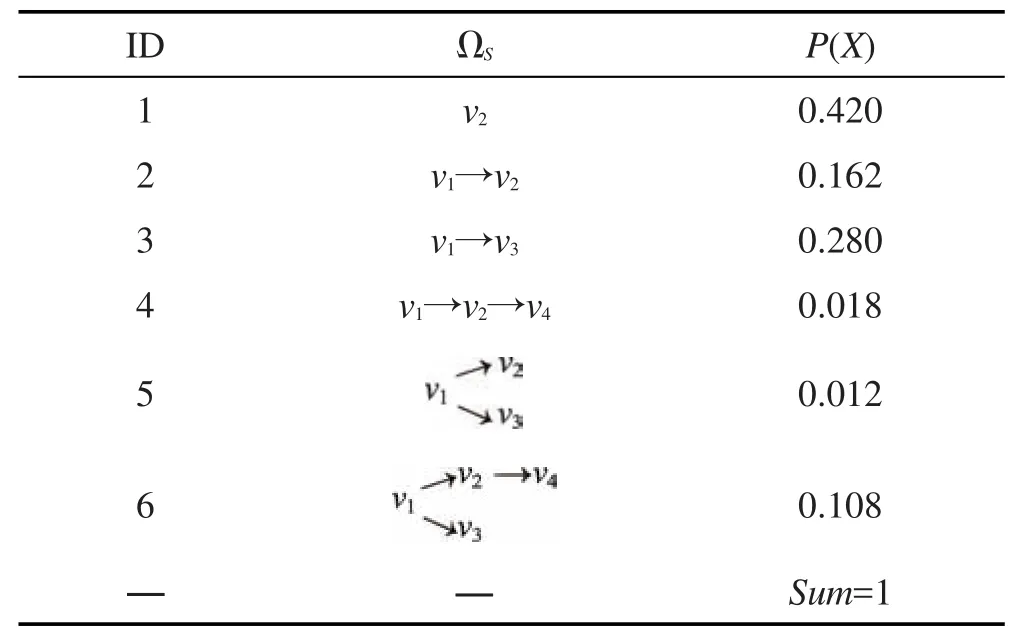
Table 1 P(X) of each X in ΩS表1 ΩS中每个样本X的概率P(X)

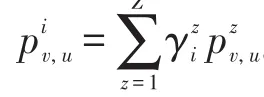
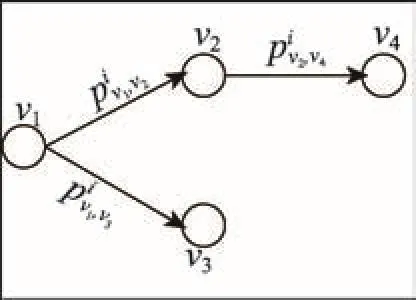
Fig.4 Graph G w ith topics图4 基于主题的图G
3.3问题定义基于主题的局部影响最大化:给定有向图G=(V,
E),动作日志D(User, Item, Time),目标节点集合T,种集大小k,传播项i以及传播项的主题分布γzi。选择大小为k的种集S,使得S对T的影响程度最大。
定理1基于主题的局部影响最大化问题是NP-hard问题。
证明通过将集合覆盖问题规约为局部影响最大化问题来证明局部影响最大化问题是NP-hard。
集合覆盖问题的定义如下:给定集合U={u1,u2,…, um},U的部分子集构成的子集族S={S1,S2,…, Sn},以及正整数k,问是否存在S的一个大小为k的子集S′,使得S′能覆盖U的所有元素。
给定集合覆盖问题的实例,构造一个节点数目为|V|+|T|的有向二分图,如图5所示。V代表不包含目标节点T的图中节点,每个节点vi∈V对应集合Si。T代表目标节点集合,每个节点wj∈T代表一个元素uj。如果uj∈Si,则边上的概率pi, j=1。
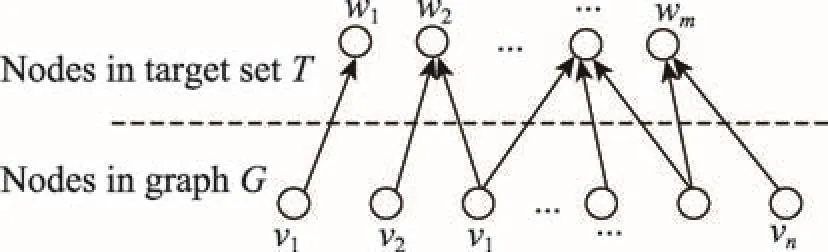
Fig.5 Bipartite graph w ith |V|+|T| nodes图5 节点数目为|V|+|T|的有向二分图
这样,集合覆盖问题可以等价地看作:在这个二分图中,是否能找到有k个节点的集合可以激活所有T中的节点。如果存在能达到这个目标的k个节点的集合,那么集合覆盖问题就得到了解决。□
4 基于主题的局部影响最大化算法
本文为解决TLIM问题,提出了两个算法:基于主题的局部贪心算法(topic-based local greedy algorithm,TLGA)和基于主题的局部传播算法(topic
based local propagation algorithm,TLPA)。
4.1基于主题的局部贪心算法
3.2节中提出的DT(S)具有子模性。如果当A⊆B⊆V,对∀v∈V有f(A⋃{v})-f(A)≥f(B⋃{v})-f(B),则称一个集合函数f具有子模性。
定理2 DT(S)具有子模性。
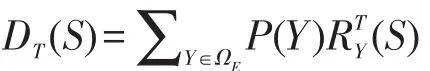

因为子模函数的非负线性组合也具有子模性[1],所以DT(S)具有子模性。□
对于一个非负的单调且具有子模性的集合函数f,选择贪心方法可提供1-1/e的近似比。令S初始化为空。接下来每次都选择使f获得最大增益的节点加入S。S为最终选择的k个种集,则f(S)≥(1-1/e)× f(S*)。其中S*为最优的k个种集。
因为DT(S)具有子模性,所以利用贪心方法设计了基于主题的局部贪心算法TLGA。算法的输入为图G,目标节点集合T,正整数k表示种集中节点数目,正整数R表示蒙特卡洛模拟要进行的次数。RanCas表示蒙特卡洛模拟中的一个随机过程,TIC模型参数为pzv, u,该参数利用文献[11]中EM算法学习获得。算法首先计算基于主题的混合影响概率pi
算法1基于主题的局部贪心算法
输入:G=(V, E),目标集合T,pzv, u,k,γzi,R。
4. S=ϕ
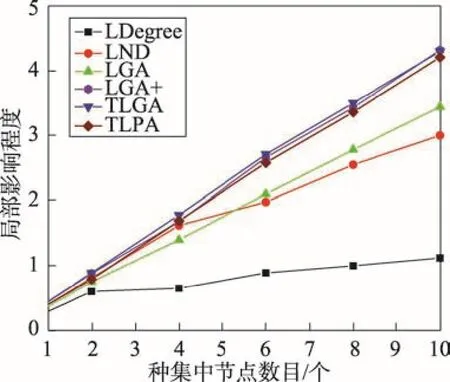
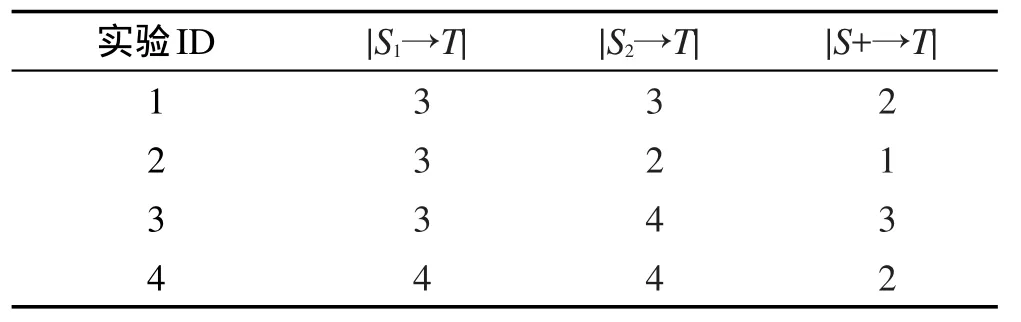
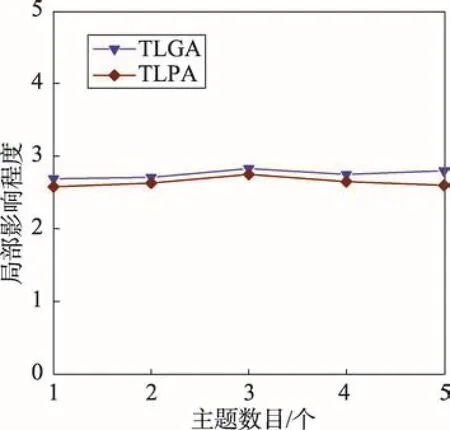
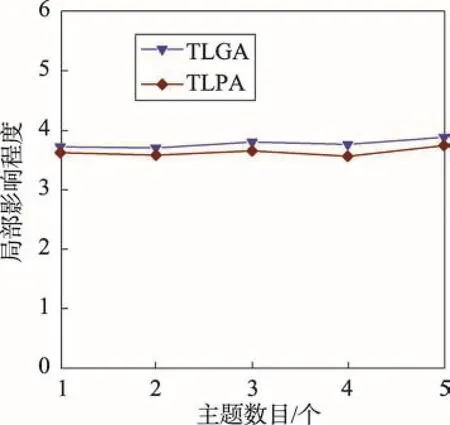
5. while| | S 6. for each v∈V S do 7.DT(S⋃{v})=0 8.for r = 1 to R 9.RanCas DMT(v) 10.DT(S⋃{v})+=DMT(v) 11.end for 12.DT(S⋃{v})=DT(S⋃{v})/R 13. end for 14.S=S⋃argmaxv∈VT⋃SDT(S⋃{v}) 15. return S 其中,DMT(v)表示节点v加入当前种集后对集合T的影响程度。 接下来,讨论TLGA的时间复杂度。算法第1~3行计算所有piv, u的复杂性为O(mZ),m为图中边的数目,Z为主题个数。第9行使用一次蒙特卡洛模拟计算节点加入种集后对目标集合的影响程度,时间复杂性为O(m)。估计某个节点的影响增益要进行R次蒙特卡洛模拟,因此第8~11行的复杂性为O(mR)。因为每次选择最大增益节点需要考察全部剩余节点,所以第6~12行的时间复杂性为O(mnR),n为图中节点个数。由于一共需要选择k个种子节点,则TLGA的复杂性为O(mZ+kmnR)。 4.2基于主题的局部传播算法 算法TLGA为了模拟估计节点的精确影响范围。通常需要大量的蒙特卡洛(R值会设得较大)。TLGA的复杂性为O(mZ+kmnR),如果网络规模变大,算法的效率会很低。 本节提出了一个高效的启发式算法,称为基于主题的局部传播算法TLPA。不同于简单贪心算法,TLPA不采用蒙特卡洛模拟来估计图中节点对目标节点集合的影响程度,而是通过构建网络中节点与目标节点集合之间的最短路径集合来减少计算量。 定义1(最短路径集合)对于图G=(V, E),将节点u∈VT到目标节点集合T的最短路径集合定义为u 到T中每个节点的最大传播概率路径构成的集合,记为PathP(u, T)。PathP(u, T)形式化表示为: PathP(u, T)={path(u→v)|v∈T} 令p(u→v)为u、v之间最短路径path(u→v)上的传播概率。显然,节点u对目标节点集合T的影响程度DT(v)可以近似地计算为DT(u)=∑v∈Tp(u→v)。因此,种集S对目标集合T的影响程度DT(S)可以近似地计算为DT(S)=∑u∈S∑v∈Tp(u→v)。算法的伪代码如算法2所示。 算法2基于主题的局部传播算法 输入:G=(V, E),目标集合T,pzv, u,k,γzi。 输出:种集S,|S| = k。 接下来,讨论TLPA的时间复杂度。计算所有piv, u的复杂性为O(mZ),m为图中边的数目,Z为主题个数。构造某个节点u到目标节点集合T的最短路径集合的复杂性为O(|T|L),其中|T|为图中节点个数,L为在所有PathP(u, T)路径中边的平均个数。因此,算法第6行的时间复杂性为O(n|T|L),n为图中节点个数。由于算法在最后选择k个具有最大DT(v)的节点,则TLPA的复杂性为O(mZ+nL+k)。显然,TLPA要比TLGA快很多。 在两个真实数据集上测试和评估了本文算法,并且与多个现有算法进行了比较。 5.1实验设置 实验中使用了两个真实数据集进行测试和比较。两个数据集都包含一个社会网G=(V, E)和一组动作日志D(User, Item, Time)。数据集分别是Digg[14]和Last.fm[15]。其中,Digg是一个社交新闻网站,用户在网站上对文章进行投票评论,D中包含的元组信息为(u, i, t),代表用户u在时刻t投票给了故事i。如果用户u投票给故事i,u的朋友v在之后不久也投票给故事i,就认为这个投票的动作从u传播到了v。Last. fm是世界最大的社交音乐平台,用户可以在这个网站中搜索、收听以及评论自己喜欢的音乐。D中包含的元组信息为(u, i, t),代表用户u在时刻t评论了歌手i。 从Digg数据集中提取了15 000个节点和395 513条边以及相应的动作日志。从Last.fm数据集中提取了5 100个节点和23 453条边以及相应的动作日志。在两个数据集中,都不考虑断开连接的节点,即在D中有动作记录,但是在图G中却没有朋友的节点。 实验中所有算法均用C++编写,在M icrosoft Visual Studio 2005环境下编译。所有实验都在Intel®CoreTM2 Duo CPU,2 GB主存的台式机上运行。 5.2对比方法描述 与下面几个算法进行实验对比:(1)LND算法,选择目标集合的邻居节点中度最大的k个节点作为种集。(2)LDegree算法,选择全局具有最大度的k个节点作为种集。(3)LGA算法[7],局部贪心算法。该算法在不考虑主题的前提下,采用贪心算法选择k个对目标节点影响程度最大的节点作为种集。(4)LGA+算法,LGA的改进算法。先利用文献[6]中提出的方法学习边上概率,然后调用LGA算法。 所有对比算法在计算种集对目标集合的影响程度时都使用10 000次蒙特卡洛模拟。对于不考虑主题的算法,除LGA+,均按照文献[1]提出的WC模型设置边上概率:p(u, v)=1/deg(v),其中deg(v)表示节点v的入度。在学习TIC模型参数pzv, u的实验中发现,在Digg数据集上的最佳主题数目为5,Last数据集上的最佳主题数为3。 5.3种集大小对目标集合影响程度的影响 本组实验考察种集大小k对影响程度的影响。 Fig.6 Influence degree vs seeds number in Last dataset图6 在Last数据集上影响程度和种集大小 Fig.7 Influence degree vs seeds number in Digg dataset图7 在Digg数据集上影响程度和种集大小 这3个算法都采用了真实数据学习边上概率。在后续实验中将证明TLGA和TLPA选择的种集要好于LGA+。 5.4目标集合大小对影响程度的影响 本组实验考察目标集合T的大小对影响程度的影响。实验中设置。从图8和图9可以看出,当固定种集大小k时,随着目标集合中节点数目的增加,影响程度也在增加。LDegree在不同目标节点数目的影响程度都比较差,因为LDegree在选择种集的时候没有考虑拓扑结构。LND在Digg数据集上|T|=1到4的时候结果最差,这也证明了该算法的实验结果不稳定。LGA的影响程度好于LDegree和LND,因为LGA在计算影响程度的时候考虑了目标集合的局部拓扑结构,并且利用有近似比保证的贪心方法计算影响程度。LGA+、TLGA和TLPA算法的效果最优,因为利用真实数据计算节点间的影响概率。 Fig.8 Influence degree vs |T| in Last dataset图8 在Last数据集上影响程度和目标集合T节点数目 Fig.9 Influence degree vs |T| in Digg dataset图9 在Digg数据集上影响程度和目标集合T节点数目 5.5不同算法的运行时间的比较 本组实验考察本文算法与其他算法运行时间上的差异。实验中设置k值分别为2、4、6、8、10, |T|=5,Z=2,γzi=(1/2, 1/2)。从图10和图11中可以看出,LND运行时间最短,这是因为LND只是在目标节点集合的邻居集中选择k个具有最大度的节点作为种集。LDegree运行时间也很短,因为LDegree在整个网络中寻找k个具有最大度的节点作为种集。TLPA的运行时间比较接近LND和LDegree,并且由前面进行的实验可知,TLPA可以得到很好的影响程度结果,也证明了TLPA的有效性和高效性。TLGA、LGA以及LGA+的运行效率要远低于其他3种算法,因为这3种算法都需要利用大量次数的蒙特卡洛模拟来保证得到精确的影响程度。 Fig.10 Running time vs seeds number in Last dataset图10 在Last数据集上运行时间和种集大小 5.6主题对目标集合影响程度的作用 本组实验考察主题对影响程度的影响,主要从两个方面进行考察:(1)有无主题因素对影响程度的作用;(2)主题数目变化对影响程度的影响。 第一组实验中,比较了LGA+、TLGA和TLPA算法。在之前的实验中可以发现,这3种算法计算的影响程度结果十分接近。本文进行4次独立的实验,设置k=5,|T|=5。观察实验结果中种集节点的动作日志与目标集合的动作日志得出结论,如表2所示。其中S1、S2和S+分别表示由TLGA、TLPA和LGA+计算的种集。、|和分别表示T中与3个种集节点执行动作相同的节点个数。从表2中可以看出和比的值大,表示基于主题的算法TLGA和TLPA选出的种集要比LGA+选出的好,证实了在解决影响最大化问题时考虑主题的意义。 Table 2 |S1→T|,|S2→T| and |S+→T| in 5 experiments表2 5次实验中|S1→T|、|S2→T|和|S+→T| 第二组实验中,通过改变主题的个数来观察影响程度的变化。在利用TIC模型学习参数pzv, u时,可通过合并同类主题减少主题数目,将主题拆分为更细类别子目来增加主题数目。实验过程中设置k=5, |T|=5。对于主题分布本文简单设置γzi的每一个分量都为1/Z,即当Z=2时,。在本组实验中仅观察基于主题的两个算法TLGA和TLPA。从图12和图13可以看出,在两个网络上主题个数的变化对影响程度的影响并不明显,这是因为计算传播项上的影响概率公式为 Z,从而影响程度变化不明显。可以看出,在Last数据集上,当Z=3时,影响程度最大。在Digg数据集上,当Z=5时,影响程度最大。这也证实了在学习TIC模型时得出的结论:Digg数据集上的最佳主题数目为5,Last数据集上的最佳主题数为3。 Fig.12 Influence degree vs topics number in Last dataset图12 在Last数据集上影响程度和主题数目 Fig.13 Influence degree vs topics number in Digg dataset图13 在Digg数据集上影响程度和主题数目 本文提出了基于主题的局部影响程度计算方法和基于主题的局部影响最大化问题。为解决局部影响最大化问题,提出了一个基于主题的局部贪心算法和一个基于主题的局部传播算法。多个数据集上的实验结果验证了本文算法的有效性和高效性。未来将研究用户自身的主题分布,从而能更准确地求解局部影响最大化问题。 References: [1] Kempe D, K leinberg J, Tardos É. Maxim izing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD International Conference on Know l-edge Discovery and Data M ining, Washington, USA, Aug 24-27, 2003. New York, USA:ACM, 2003: 137-146. [2] Chen Wei. Time-critical influence maxim ization in social networks w ith time- delayed diffusion process[C]//Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec, Canada, Jul 27-31, 2014. Menlo Park, USA: AAAI, 2014: 73-84. [3] Li Yanhua, Chen Wei, Wang Yajun. Influence diffusion dynamics and influence maximization in social networks w ith friend and foe relationships[C]//Proceedings of the 6th ACM International Conference on Web Search and Data M ining, Rome, Italy, Feb 6-8, 2013. New York, USA: ACM, 2013: 657-666. [4] Aslay C, Baribieri N, Barbieri N. Online topic-aware influence maxim ization queries[C]//Proceedings of the 17th International Conference on Extending Database Technology, Athens, Greece, Mar 24-28, 2014. New York, USA: ACM, 2014: 279-291. [5] Kutzkov K, Bifet A, Bonchi F. Strip: stream learning of influence probabilities[C]//Proceedings of the 19th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining, Chicago, USA, Aug 11- 14, 2013. New York, USA:ACM, 2013: 275-283. [6] Guo Jing, Zhang Peng, Zhou Chuan. Personalized influence maximization on social networks[C]//Proceedings of the 2013 ACM Conference on Information and Know ledge Management, Burlingame, USA, Oct 27-Nov 1, 2013. New York, USA:ACM, 2013: 199-208. [7] Domingos P, Richardson M. M ining the network value of customers[C]//Proceedings of the 7th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining, San Francisco, USA, Aug 26- 29, 2001. New York, USA: ACM, 2001: 57-66. [8] Leskovec J, Krause A, Guestrin C, et al. Cost-effective outbreak detection in networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining, San Jose, USA, Aug 12-15, 2007. New York, USA:ACM, 2007: 420-429. [9] Kimura M, Saito K. Tractable models for information diffusion in social networks[C]//LNCS 4213: Proceedings of the 10th European Conference on Principles and Practice of Know ledge Discovery in Databases, Berlin, Germany, Sep 18-22, 2006. Berlin, Heidelberg: Springer, 2006: 259-271. [10] Goyal A, Bonchi F, Lakshmanan L. Learning influence probabilities in social networks[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data M ining, New York, USA, Feb 3-6, 2010. New York, USA: ACM, 2010: 241-250. [11] Liu Lu, Tang Jie, Han Jiawei, et al. M ining topic-level influence in heterogeneous networks[C]//Proceedings of the 2010 ACM Conference on Information and Know ledge Management, Toronto, Canada, Oct 26-30, 2010. New York, USA: ACM, 2010: 545-576. [12] Barbieri N, Bonchi F, Manco G. Topic-aware social influence propagation models[C]//Proceedings of 5th ACM International Conference on Web Search and Data M ining, Brussels, Belgium, Dec 10-13, 2012. New York, USA: ACM, 2012: 81-90. [13] Chen Wei, Wang Yajun, Yang Siyu. Efficient influence maximization in social networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining, Paris, France, Jun 28-Jul 1, 2009. New York, USA:ACM, 2009: 199-208. [14] Barbieri N, Bonchi F, Manco G. Cascade-based community detection[C]//Proceedings of the 6th ACM International Conference on Web Search and Data M ining, Rome, Italy, Feb 6-8, 2013. New York, USA:ACM, 2013: 33-42. [15] Cantador I, Brusilovsky P, Kuflik T. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011)[C]//Proceedings of the 5th ACM Conference on Recommender Systems, Chicago, USA, Oct 23-27, 2011. New York, USA:ACM, 2011: 387-388. XIE Shengnan was born in 1991. She is an M.S. candidate at School of Computer Science and Technology, Heilongjiang University. Her research interest is data mining. 谢胜男(1991—),女,黑龙江黑河人,黑龙江大学计算机科学与技术学院硕士研究生,主要研究领域为数据挖掘。 LIU Yong was born in 1975. He received the Ph.D. degree in computer science from Harbin Institute of Technology in 2010. Now he is an associate professor and M.S. supervisor at School of Computer and Science Technology, Heilongjiang University. His research interests include data m ining and database, etc. 刘勇(1975—),男,河北昌黎人,2010年于哈尔滨工业大学计算机科学专业获得博士学位,现为黑龙江大学计算机科学与技术学院副教授、硕士生导师,主要研究领域为数据挖掘,数据库等。 ZHU Jinghua was born in 1976. She received the Ph.D. degree in computer science from Harbin Institute of Technology in 2009. Now she is an associate professor and M.S. supervisor at Heilongjiang University. Her research interests include data mining and database, etc. 朱敬华(1976—),女,黑龙江齐齐哈尔人,2009年于哈尔滨工业大学计算机科学专业获得博士学位,现为黑龙江大学计算机科学与技术学院副教授、硕士生导师,主要研究领域为数据挖掘,数据库等。 TAN Long was born in 1971. He is an associate professor and M.S. supervisor at School of Computer and Science Technology, Heilongjiang University. His research interests include cognitive radio network and data m ining, etc. 谭龙(1971—),男,黑龙江哈尔滨人,黑龙江大学计算机科学与技术学院副教授、硕士生导师,主要研究领域为无线认知传感器网络,数据挖掘等。 Research on Topic-Based Local InfluenceMaxim ization Algorithm in Social Networkƽ XIE Shengnan, LIU Yong+, ZHU Jinghua, TAN Long Key words:social network; topic-based; local influence maxim ization; target set Abstract:Local influence maximization is the problem of finding a small set of seed nodes in a social network that maximizes the influence on a target node. Existing works only consider the influence on a single target node, and also ignore the topic distribution of diffusion items and the influence probabilities between users based on topics. This paper focuses on how to select a seed set that has the maximum influence on a given target set based on the topic distribution, and proposes a new topic-based local influence degree computational method (T-LID). Based on T-LID, this paper also proposes a topic-based local influence maxim ization (TLIM) problem and proves that TLIM is NP-hard. In order to solve TLIM, this paper proposes a topic-based local greedy algorithm (TLGA) and a topic-based local propagation algorithm (TLPA). The experimental results on several real datasets show that the proposed algorithms can solve the TLIM problem effectively and efficiently. doi:10.3778/j.issn.1673-9418.1507073 文献标志码:A 中图分类号:TP311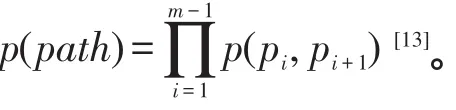
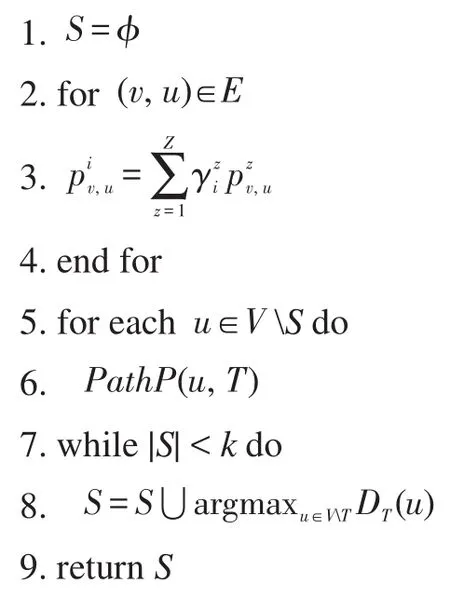
5 实验与结果分析
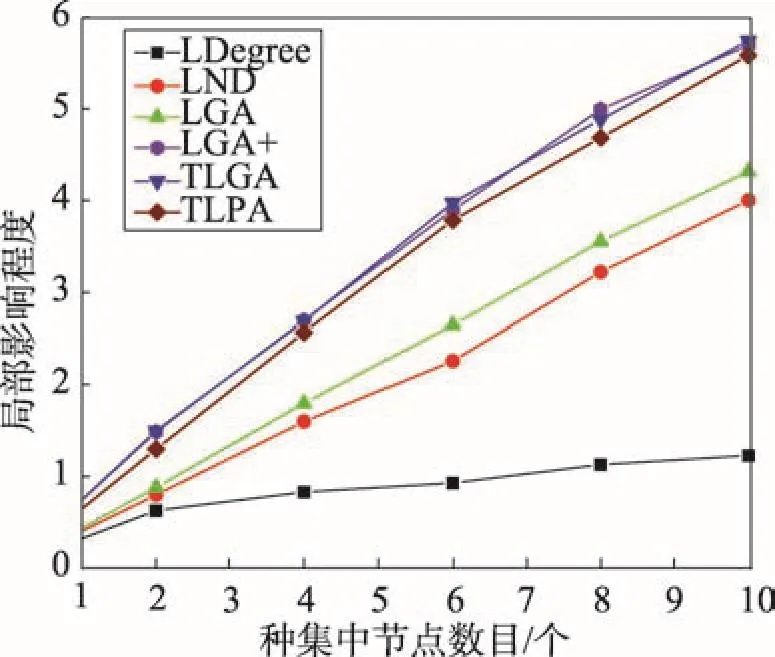
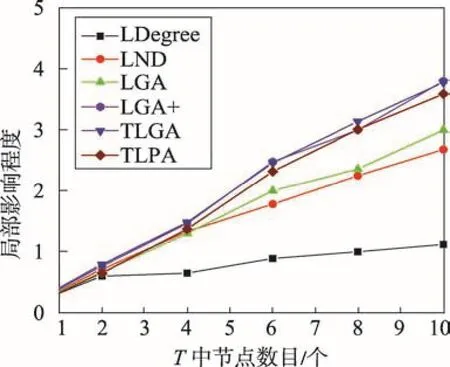
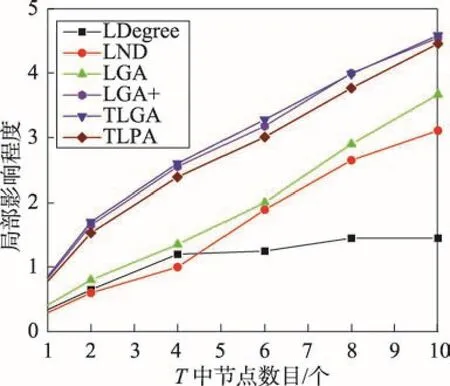
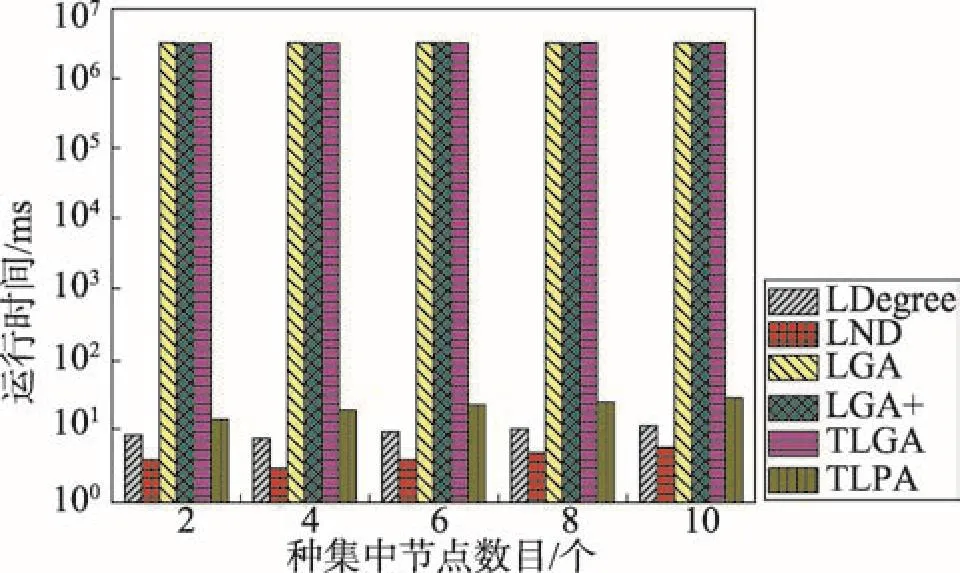
6 结束语




School of Computer Science and Technology, Heilongjiang University, Harbin 150080, China + Corresponding author: E-mail: acliuyong@sina.com
