
基于SVM的大学生热点问题的研究
2016-07-01 09:59作者杨世瀚李婷婷
电子制作 2016年9期
作者 / 杨世瀚、李婷婷
基于SVM的大学生热点问题的研究
作者 / 杨世瀚、李婷婷
基于SVM(Support Vector Machine)分类器来建立大数据的文本分类机制是目前的热点研究之一。针对于怎样将SVM应用到大学生网络社区文本数据的分析,并从中挖掘出大学生热点问题,是SVM应用的一个新尝试。利用SVM可以在大规模的网络社区文本数据中得出准确的训练模型以及预测结果,在此基础上给出了特征向量构造以及有效选取SVM参数的方法,同时给出了剔除重复样本的策略,最后还会研究特征选择对SVM分类效率的影响。
SVM;大数据;网络社区文本数据;文本分类
引言
基于SVM分类器来研究大学生热点问题是一个新的尝试。从网络上获取的网络社区文本数据是相当庞大的,针对这类文本数据的分类也是比较少见的。SVM具有很好的泛化能力和出色的分类性能,将SVM用于网络社区文本数据的分类并以此来研究大学生热点问题是可行的。
1. SVM基础
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。
SVM进行分类的步骤有:样本整理、特征选择、计算特征权重、模型训练与预测[1]。
从数据库中提取已预处理的文本,将样本标签设定为-1和1。然后根据地理、人文差异将大学生网络社区数据的文本分为两类,-1为来自北方的大学,1为来自南方的大学。
SVM进行特征选择,就是将特征的个数限制在一个合理的范围内,即确定特征集。特征选择就是从特征集中选择一些代表性的词。
针对大学生网络社区文本,还需要将这些文本转换成特征向量。首先,对文本进行分词,提取出所有的词。然后根据已经生成的词典,如果词典中的词出现,就在相应对应的位置填入该词的词频。最后将生成的向量进行归一化,例如
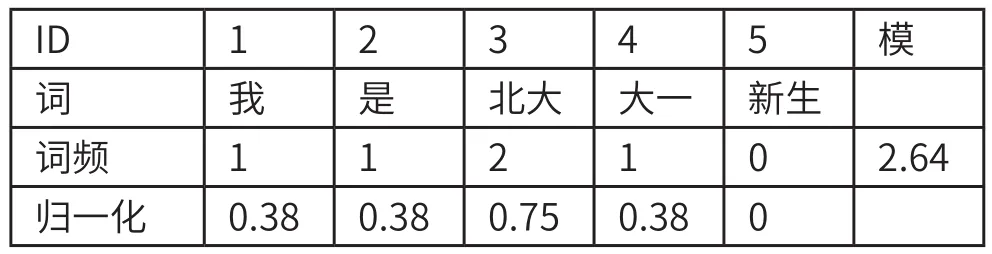
表1
经过以上几个步骤,文本转换为向量的形式后。就是进行SVM模型训练和预测了。
模型预测过程:首先将未知文本进行分词,并确定它的特征向量,然后将这些已经进行分词的样本放到SVM模型中,设置好配置文件,最后就是将这些训练好的样本进行分类,标签标识,以及得出它的隶属度分数。至于预测,一般都是通过MATLAB来实现。
2. SVM参数选择和重复样本剔除
微博是一个信息流量相当大的网络社区,其内容格式非常散乱,数据噪声较大,人工审视或基本的统计选取参数很难提炼出最有效的参数,因此必须进行严格的SVM参数的选取。
SVM中最重要的两个参数为C和gamma,C是惩罚系数,即对误差的宽容度。C越高,说明越不能容忍出现误差。C过大或过小,泛化能力都会变差。
径向基函数RBF里sigma和gamma的关系如下:
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,σ会很小,支持向量越少,gamma值越小,σ会很大,支持向量越多。同时支持向量的个数都会影响训练与预测的速度。
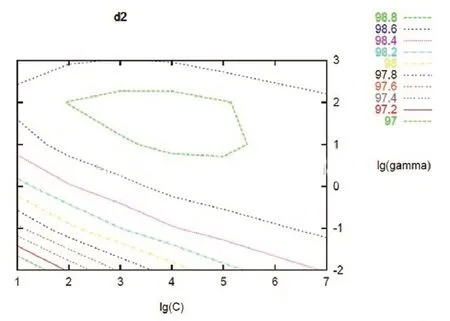
图1 C,gamma组成的二维参数矩阵
如图1所示,可以理解为:在C,gamma组成的二维参数矩阵中,依次实验每一组参数的效果。
从图1中可以看出,每组不同的C和gamma得到的矩阵相差甚远,选择不同的参数必然会有很大的偏差,造成分类不准确,甚至错误。因此参数的选择就变得极其重要了。
那么该如何选取参数C和gamma的最佳值呢?假设现在有1000个大学的大学生对热点关注的训练样本,300个大学的大学生对热点关注的测试样本(测试、训练样本不交叠),特征维数可能是足球,考研,买房,买车等热点,共选取2000维。最佳C和gamma的思想是设置C和gamma的取值范围,默认值为C=2ˆ(-8),2ˆ(-4),...,2ˆ(8),gamma= 2ˆ(-8),2ˆ(-4),...,2ˆ(8)),先把具有最小的那组C和gamma认为是最佳的C和gamma,并依次使C和gamma的幂分别加1,最后将每组C和gamma放到LIBSVM进行训练,直至得出最佳的C和gamma,如图2所示参数选择结果图。

图2 寻参数选择结果图
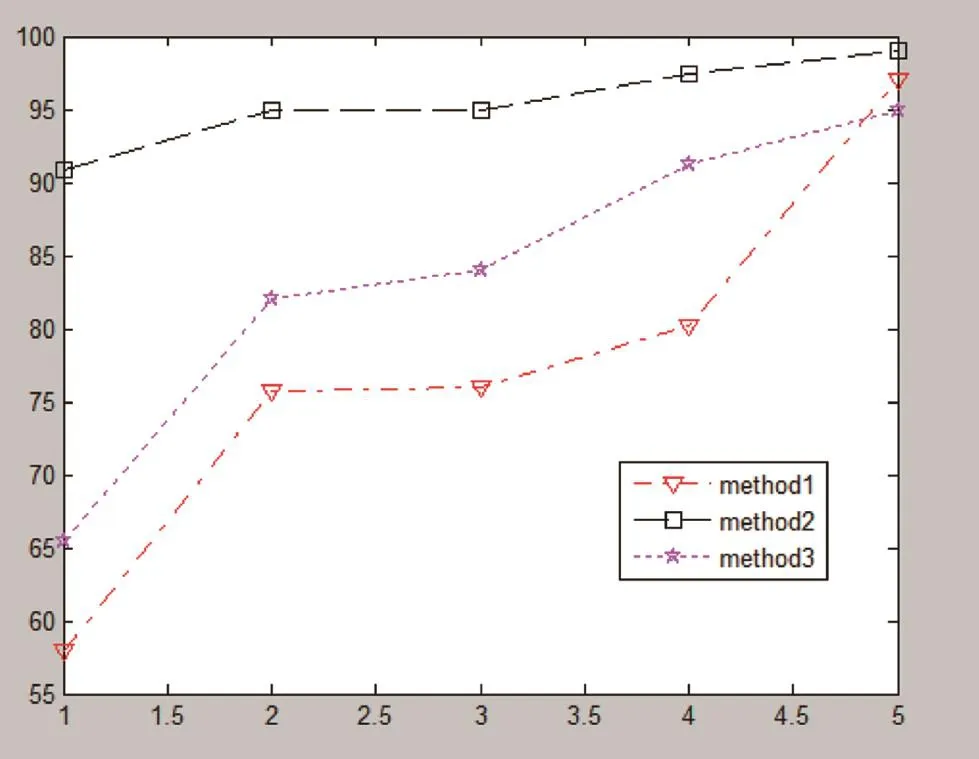
图3 参数优化前后的精确度对比
如图2所示,X、Y轴是 log2(C),log2(g),准确率97的点所对应的 C, gamma 的组合就是最佳的参数组。最后将选取一组最佳的C和gamma放到交叉验证(cross validation)中进行测试,对比参数优化前后的SVM分类精确度,如图3所示。
图3中X轴是样本数,单位是万;Y轴是精确度,单位是百分比。method1曲线和method3曲线代表的是C过大、gamma过大的SVM精确度,method2曲线代表的是最佳参数的SVM精确度。因此,在确定了最佳参数后,SVM分类的精确度最高。
尽管在整理样本时,已经进行了预处理。但是对于微博这种信息量大的平台而言,重复样本在预处理的时候还是被保留下来了。那么这些重复样本会对SVM模型产生什么影响呢?
假设在一个训练样本中北方大学生的样本数为1000,南方大学生的样本数为2000,然后将北方大学生的样本数重复一倍,即构造了一个北方大学生的样本数2000,然后测试一个包含北方大学生的样本1,南方大学生的样本9的样本。最终结果如图4所示。
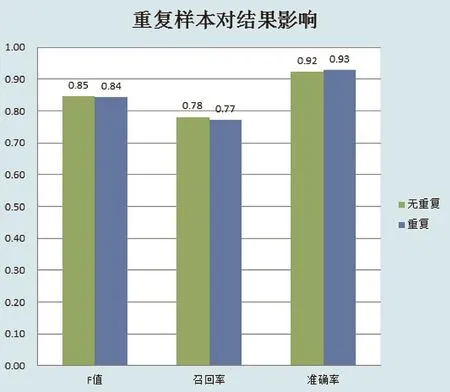
图4 重复样本对结果的影响
从结果上来看:在F值上,无重复的样本会比重复样本稍高(图中保留了2位小数,其实差异不超过0.5%)。而正确率上,重复样本会比无重复样本稍高。但是相对于这点优势而言,重复样本的劣势更为凸显。
一个样本重复,相当于增加了样本的权重,对于参数选择最佳的C和gamma时,就会导致大量的工作量。如果C和gamma都是在[2.0,1.0]进行挑选,则总会有9*9=81组参数需要挑选,在每组参数下如果要进行5-flods的交叉验证,则需要81*5=405次训练与测试的过程。如果每次训练与测试花费2分钟(在样本达到10万数量级的时候,SVM的训练时间差不多按分钟计算),则总共需要405*2/60=12.3小时。
无可厚非,剔除重复样本对训练一个好的SVM模型就显得很重要了。利用文本编辑器批处理删除重复样本,如将文本1和文本2的内容进行对比,删除文本内重复行,相同行。
3. SVM分类实现的算法
序列最小最优化SMO算法就是通过f(x)函数把输入的数据x进行分类[3]。而分类必然需要一个评判的标准,例如怎样将x分为A类,怎样将y分为B类?此时便需要划分A类和B类的边界了。如果边界越明显,就越容易区分,因此这个函数的目的就是把边界的宽度最大化。
怎样实现边界的宽度最大化呢?在SVM中要是现实边界的宽度最大化就必须最小化式。
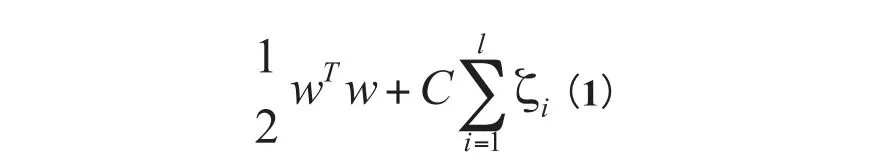
w是参数,值越大边界越明显,C是惩罚系数,ξi是松散变量。
再将问题转换为KKT条件(Karush-Kuhn-Tucker 最优化条件):
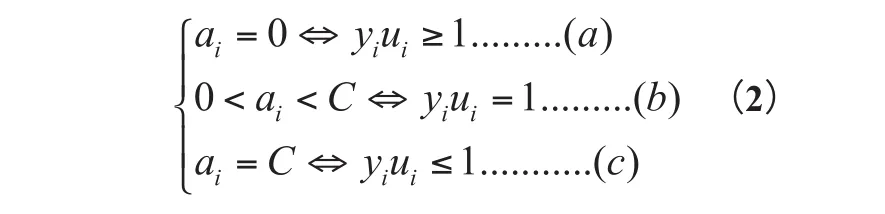
ai表示拉格朗日乘子。为了使KKT条件解答更简单,可以通过拉格朗日乘法数来求解。对于(1)(2)(3)的情况分别是ai是正常分类、在边界内部;ai是支持向量、在边界上和 ai在边界之间。最优解必须满足(a)(b)(c)的条件。因此ai的约束条件是

通过公式(2)、(3),我们引入aj,满足以下等式:
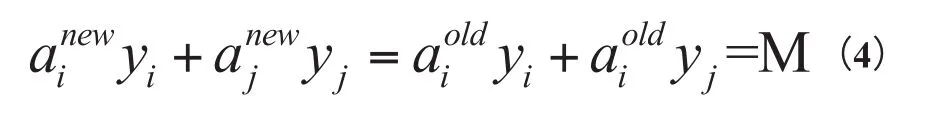
M为常数。利用yiai+yjaj=常数,消去ai,得到
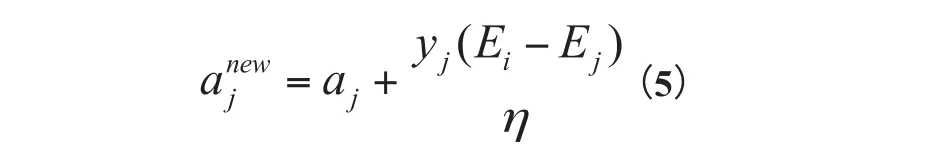
将Ei移到最左边得
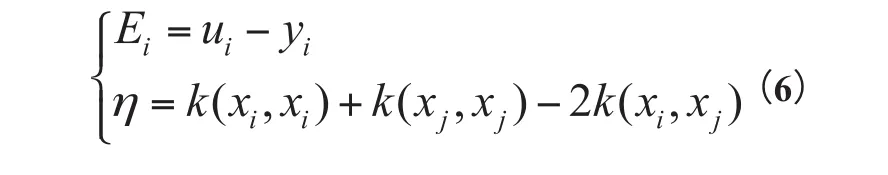
根据aj可以得到
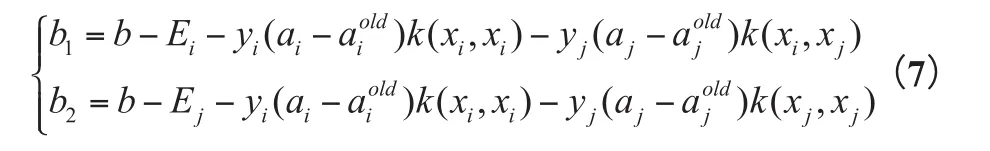
b的更新:
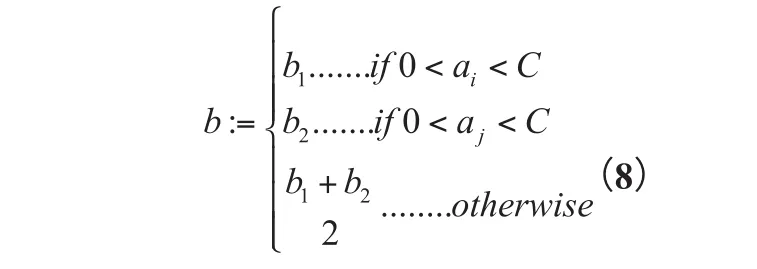
最后得到函数:
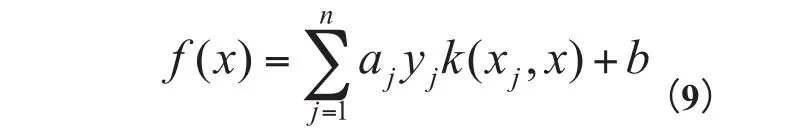
输入是x,是一个向量,向量中的每一个值表示一个特征。
假设现在有一个x(清华大学,北京大学,厦门大学,中山大学),需要将这几所大学分类,A类是北方大学,B类是南方大学。主要的步骤实现如下:
Repeat till convergence{
1. Select some pair ai and ay to update next (using a heuristic that tries to pick the two that will allow us to make biggest progress towards the global maximum).
2. Reoptimize M(a) with respect to ai and ay ,while holding all the other ak,s(k≠i,j) fixed.
}
意思是,第一步选取一对ai和ay,第二步,固定除ai和ay之外的其他参数,确定M极值条件下的ai和ay由ay表示。
运行后能准确的将这四所大学划分为南方还是北方的大学,然后再将全国所有的本科院校都进行分类。
4. SVM分类的预测
首先将全国大学生分为两大类,一类是北方大学生,另一类是南方大学生。因此就需要划分全国的本科院校是属于南方还是北方的,再将它的特征向量确定为北京大学,清华大学等本科院校,就大学生可能关注的热点问题,分为考公务员,就业,创业,谈恋爱,买房,军事,考研等。确定好这些基本要素以后,再用文本编辑器剔除重复样本,确定C和gamma的最佳取值,最后便是开始SVM样本训练和预测了。在MATLAB中进行预测时,过滤频率较低的曲线,选取最高频率的几条曲线,以免曲线过多,造成失误。首先我们先抓取2014年1月到5月的微博文本数据进行分析,如图5所示。

图5 热点问题频率统计图
图5中X轴是月数,单位是月;Y轴是频率,单位是百分比。三条曲线由上到下分别代表关注考研,关注就业,关注公务员考试的频率曲线。由图可知,未来5个月内,大学生关注考研的人数比较多,关注就业问题的人数也不少,但在4个多月后就会出现下滑趋势,关注公务员考试的人数上涨,五个月后可能处于最高。
使用词频统计的方法就2014年7月到11月的热点问题进行跟踪调查,结果如图6所示。
图5的预测中考研的概率是26%,就业的概率接近25%,考公务员的概率23%。和图6对比可知,考研、就业、考公务员的热点问题预测准确率与实际相差不大,但还是存在差距。如实际考研的概率比预测的增加1%,实际就业的概率比预测的减少1%,实际考公务员的概率比预测的增加2%;大概原因如下:
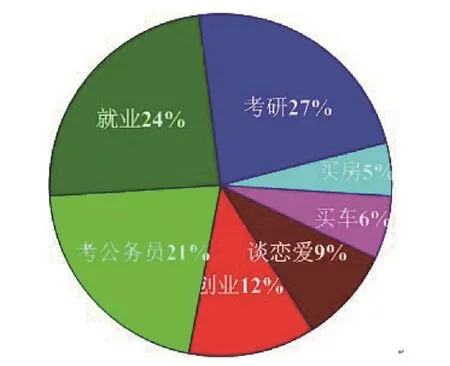
图6 热点问题跟踪表
(1)部分大学生在大三到大四的暑假期间受就业,家庭等原因影响,会突然决定考研。所以会比预测增长1%;
(2)部分大学生决定考研后,就不会更多的考虑就业问题了,而是一心扑在考研的问题上。所以会比预测减少1%;
(3)将近2%的大学生在10月中下旬的时候,由于找到了工作,或因为公务员多人报考难度加大等原因,放弃考公务员。所以会比预测减少2%。
5. 结论
在进行文本分类时,我们必须提高SVM的工作效率,即提高SVM的分类速度。对SVM参数的选择,以及剔除重复样本都是为了提高SVM分类速度,使其在模型训练和预测时得出更好更快的结果。严格进行参数的选择以及剔除重复样本,努力提高SVM的分类速度。
* [1] 张知临.文本分类SVM[DB/OL],2012,http://blog.csdn. net/zhzhl202/article/details/8197109
* [2] 程俊霞,李芝棠,邹明光,肖津.基于SVM过滤的微博新闻话题检测方法[J].通信学报,2013,34(Z2)74-78
* [3] techq'sblog.SVM算法实现[DB/OL],2011,http://blog. csdn.net/techq/article/details/6171688
* [4] 张翔,周明全,耿国华,王晓凤.基于LSVM算法的人脸识别方法研究[J].西安可视化技术研究所,2012
广西自然科学基金项目:2014GXNSFAA118359,广西民族大学创新项目《基于大数据技术的大学生热点问题预测与分析》
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
青年文学家(2022年7期)2022-04-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·高一版(2020年11期)2020-12-14
传奇故事(上旬)(2019年7期)2019-08-17
传奇故事(破茧成蝶)(2019年7期)2019-07-26
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
信息记录材料(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
