
基于模糊C均值聚类的科研管理数据库调度算法
2016-07-02 01:44陆兴华李国恒余文权陈永聪
计算机与数字工程 2016年6期
陆兴华 李国恒 余文权 陈永聪
(广东工业大学华立学院 广州 511325)
基于模糊C均值聚类的科研管理数据库调度算法
陆兴华李国恒余文权陈永聪
(广东工业大学华立学院广州511325)
摘要在科研管理系统设计中,需要对科研管理数据库进行优化调度处理,提高数据库中科研管理信息的访问和调度能力。传统方法采用K均值聚类算法进行数据库的信息属性聚类和调度,数据个体间的子空间配对容易使得数据访问过程陷入局部最优解,数据库调度性能不好。提出一种基于模糊C均值聚类的科研管理数据库调度算法。首先构建了科研管理数据库多层矢量自回归空间,进行数据库中访问信息流的特征提取,采用模糊C均值聚类算法实现对数据库的优化调度。仿真结果表明,采用该算法进行科研管理数据库的数据信息聚类和调度,具有较好的特征峰值,数据的特征信息反映准确,提高数据库访问的信息定位能力,数据库调度的准确性和收敛性较好。
关键词模糊C均值聚类; 科研管理系统; 数据库; 调度
Class NumberTP391.9
1引言
随着信息处理技术的发展,人类进入大数据存储和处理时代,通过构建数据库进行数据调度和访问,实现信息共享和利用。在高校的科研管理信息系统构建过程中,需要对科研管理数据进行数据优化存储和属性分析,结合云计算和云储存技术实现数据的分类处理和聚类分析,研究科研信息管理系统的数据库优化调度算法,提高数据库中科研管理信息的访问和调度能力,在科研管理信息的调度和数据分析中具有重要意义,相关的算法研究受到人们的极大重视[1]。
本文研究的科研管理信息系统的数据库就是采用分布式数据库构建方法,对这类分布式数据库的数据信息访问和调度建立在数据聚类分析的基础上,传统方法中,对数据库的调度和数据聚类分析采用的是K均值聚类算法,在K均值聚类过程中,由于数据个体间的子空间配对容易导致数据访问过程陷入局部最优解,数据库调度性能不好[2~3]。对此,相关文献进行了算法改进设计,其中,文献[4]提出一种基于多层空间模糊减法聚类的数据库优化访问算法,采用图模型的科研管理数据库采样方法,实现数据的属性聚类,提高数据库的调度能力,但是该算法具有计算开销大,特征空间维数较高的问题;文献[5]提出一种基于时频特征提取的数据库访问算法,采用数据库访问指令信息流的属性相关度时频特征提取实现数据库优化调度和访问,提高数据调度和属性特征分解能力,但该算法在进行多次迭代后容易出现系统发散,性能不好,针对上述问题,本文提出一种基于模糊C均值聚类的科研管理数据库调度算法,首先构建了科研管理数据库多层矢量自回归空间,进行数据库中访问信息流的特征提取,采用模糊C均值聚类算法实现对数据库的优化调度,仿真实验进行了性能验证,展示了本文算法在优化数据库访问性能,提高科研管理系统的数据分析能力方面的优越性。
2科研管理数据库矢量空间构建和特征提取
2.1科研管理数据库矢量空间构建
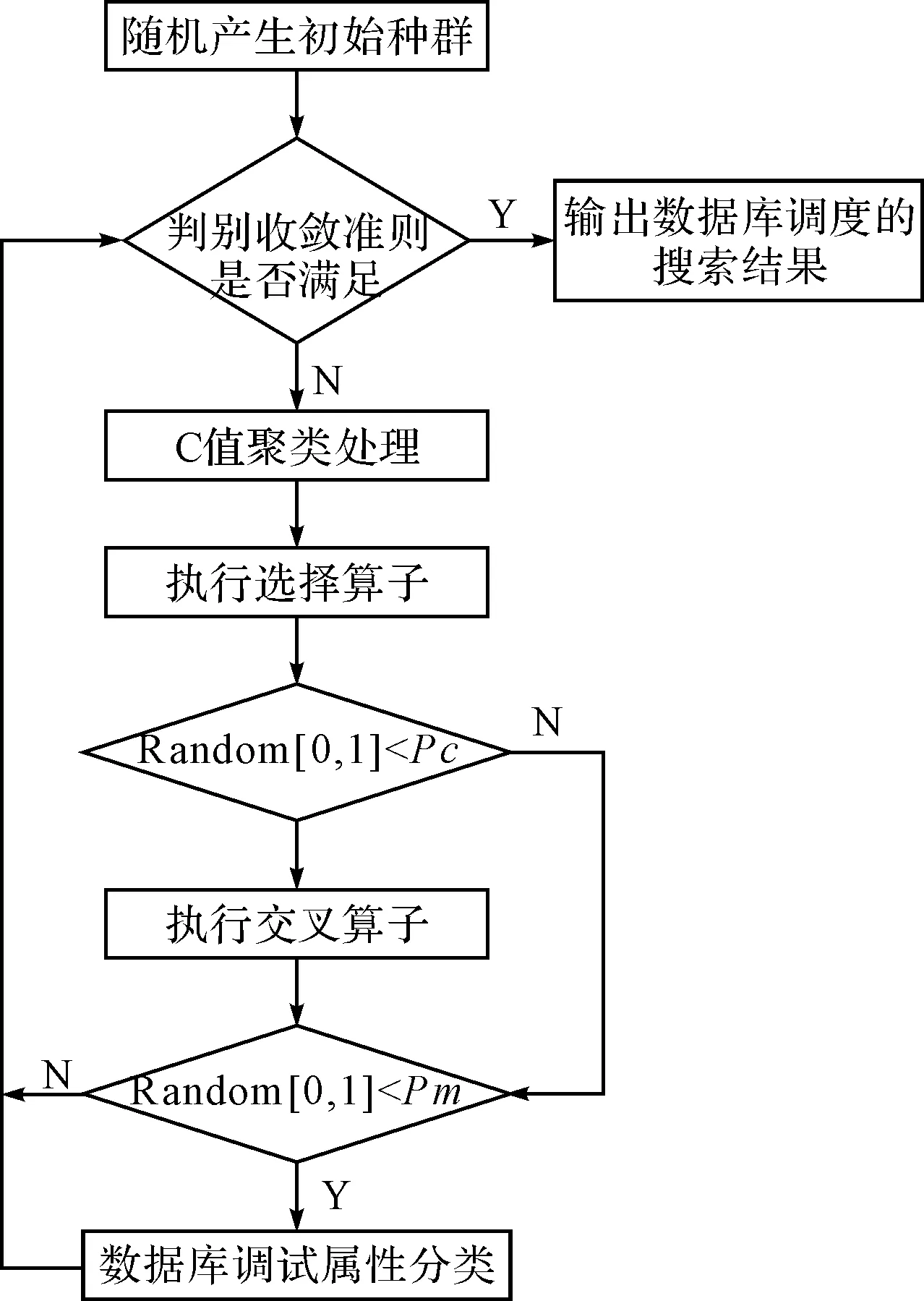
为了实现对科研管理系统的数据库的访问和调度能力,需要构建数据库的矢量空间,在矢量空间中进行特征信息流分析,通过特征提取进行信号模型构建[6],以此为基础进行数据聚类分析,实现数据库调度,基于数据聚类的科研管理系统数据库调度模型的基本实现流程如图1所示。
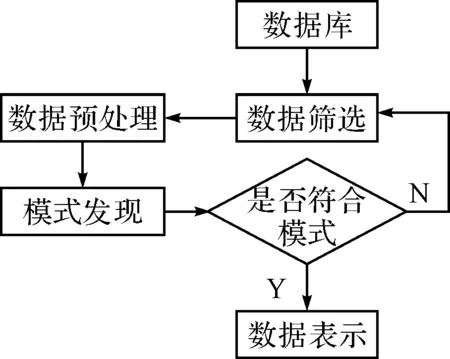
图1 数据库调度设计流程
假设数据库库信息流属性集为一个分布式数据库属性集合,首先对科研管理数据库信息流进行多维相空间重建,把科研管理数据库的数据信息流信息聚焦为时间序列A={a1,a2,…,an},B={b1,b2,…,bm}为数据库属性类别集,ai的科研管理信息的模糊聚类中心,表现为{c1,c2,…,ck}。科研管理数据库信息流通过数据聚类进行属性集分类,得到多层矢量空间的信息增益表达式为
(1)
(2)
Gain(A)=Info(B)-InfoA(B)
(3)
令ax属性中的cv值为科研管理数据库信息流的息增益,数据信息流矢量场映射到一个多维状态空间中进行特征提取,得到多层矢量空间系统表示为:
Φ(z)=(h(z),h(φ1(z)),…,h(φ2d(z)))T
(4)
其中,数据库访问的时间序列{x(t0+iΔt)},i=0,1,…,N-1,在多层空间的状态特征矩阵描述为
X=[x(t0),x(t0+Δt),…,x(t0+(K-1)Δt)]
(5)
------------------------------
式中,x(t)表示数据库信息流倾斜因子,J是数据聚类簇的总数,m是相空间重构的维数。在上述重构的科研管理数据库矢量空间中,进行信息特征提取实现数据聚类分析和数据库调度。
2.2数据库的访问状态信息特征提取
在上述构建的多维矢量空间中,进行数据库的访问状态信息特征提取。数据库的访问状态信息特征提取的流程分以下五个部分:
1) 考察科研管理数据库信息流矢量x和xn+τ,选择一个C值,确定数据访问的聚类簇总数。若数据集为m,令Aj(L)作为多层空间模糊聚类中心,其中j=1,2,…,k,并特征空间中矢量轨迹的距离,采用欧式距离表示;
2) 在数据集中变尺度调整聚类中心矢量,两个数据库访问时刻t和t+τ相互关联的初始化簇中心F(xi,Aj(L)),i=1,2,…,m,j=1,2,…,k;
3) 使用关联维特征提取方法得到剩余簇分配到的数据属性的聚类密度特征,如满足:
D(xi,Aj(L))=min{D(xi,Aj(L))}
(6)
那么xi∈ωk;
4) 使用散布查询类别S(t)的平均值作为下一次数据聚类迭代的簇平均值:
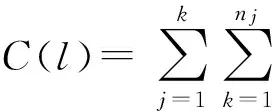
(7)
5) 如果数据信息流x(t)的聚类中心的迭代平均值小于阈值,‖C(l)-C(l-1)‖<ξ,则中止程序,否则返回步骤2),令l=l+1,进行数据聚类中心搜索:
(8)
通过上述方法,完成数据库的访问状态信息特征提取。
3模糊C均值聚类算法和数据库调度算法改进设计
3.1模糊C均值聚类算法的提出
在上述特征空间重构和数据库访问信息的特征提取的基础上,采用K均值聚类算法进行数据库的信息属性聚类和调度,数据个体间的子空间配对容易导致数据访问过程陷入局部最优解,数据库调度性能不好[7~10]。为了克服传统方法的弊端,本文提出一种基于模糊C均值聚类的科研管理数据库调度算法。首先进行模糊C均值聚类算法的描述,假设数据库中存在有限数据集:
X={x1,x2,…,xn}⊂Rs
(9)
根据某个距离函数把数据库访问中的状态信息数据集合分为C个类别,其中样本xi,i=1,2,…,n的初始的聚类中心为
xi=(xi1,xi2,…,xis)T
(10)
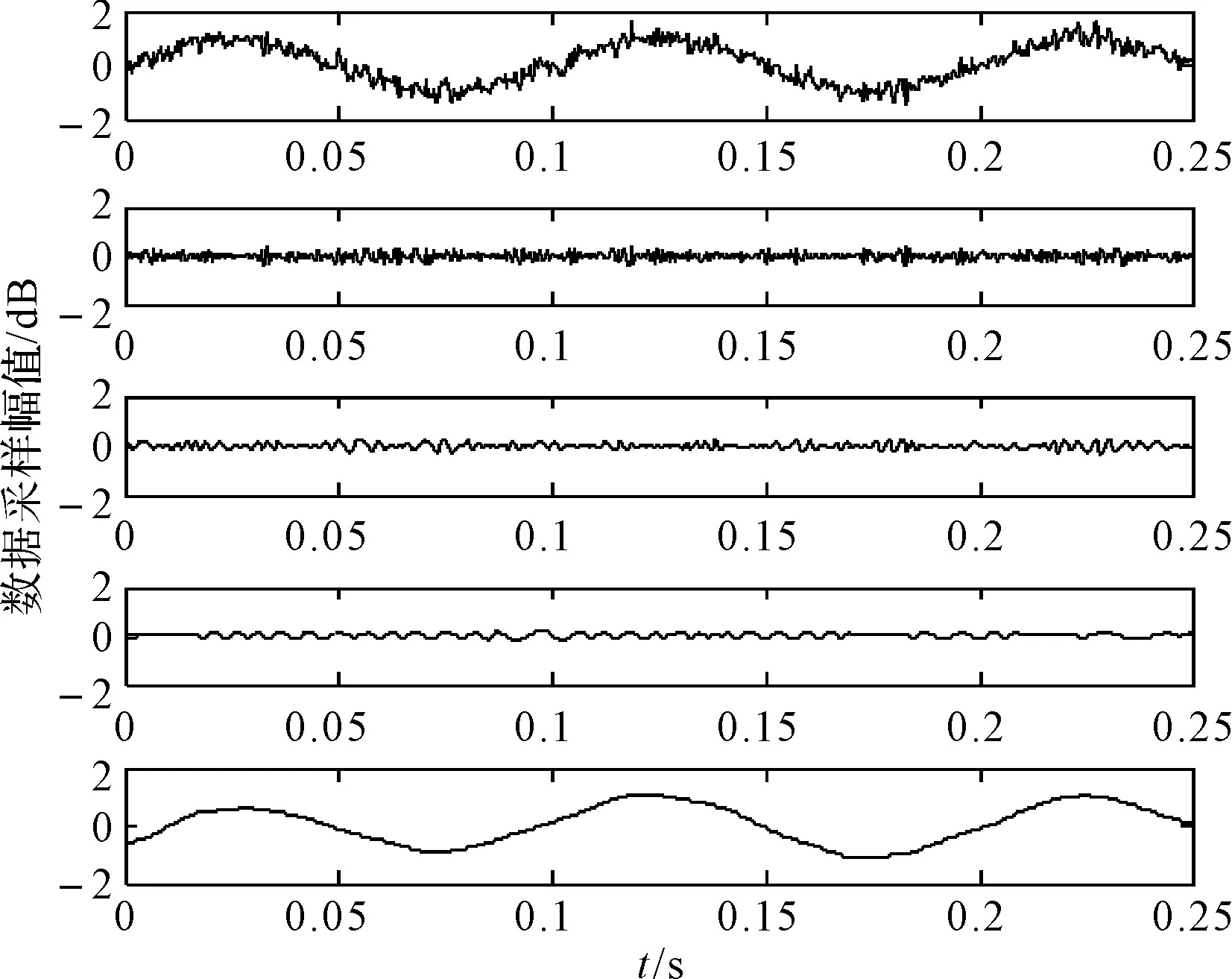
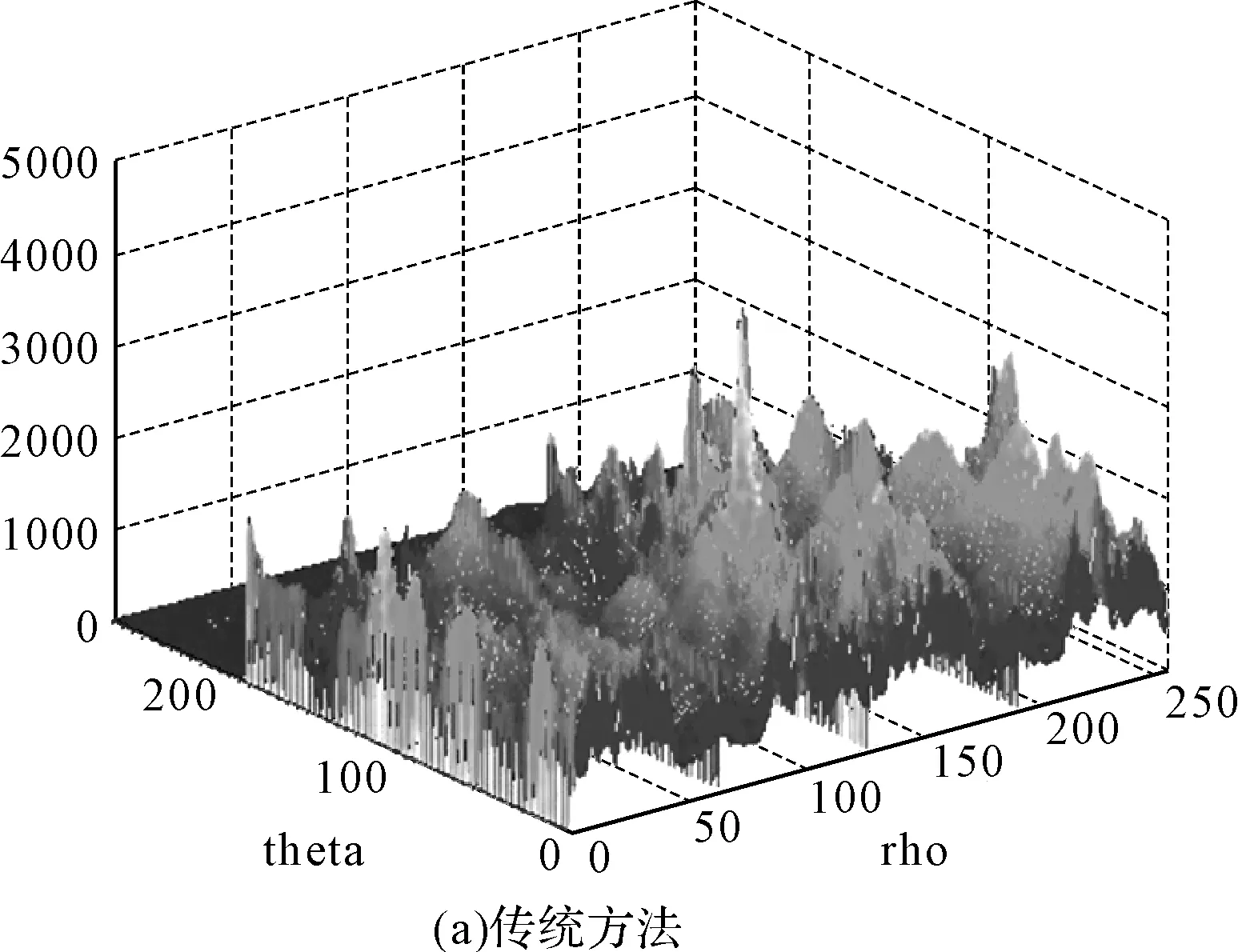
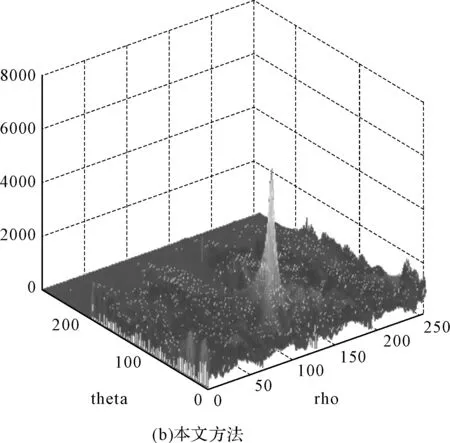
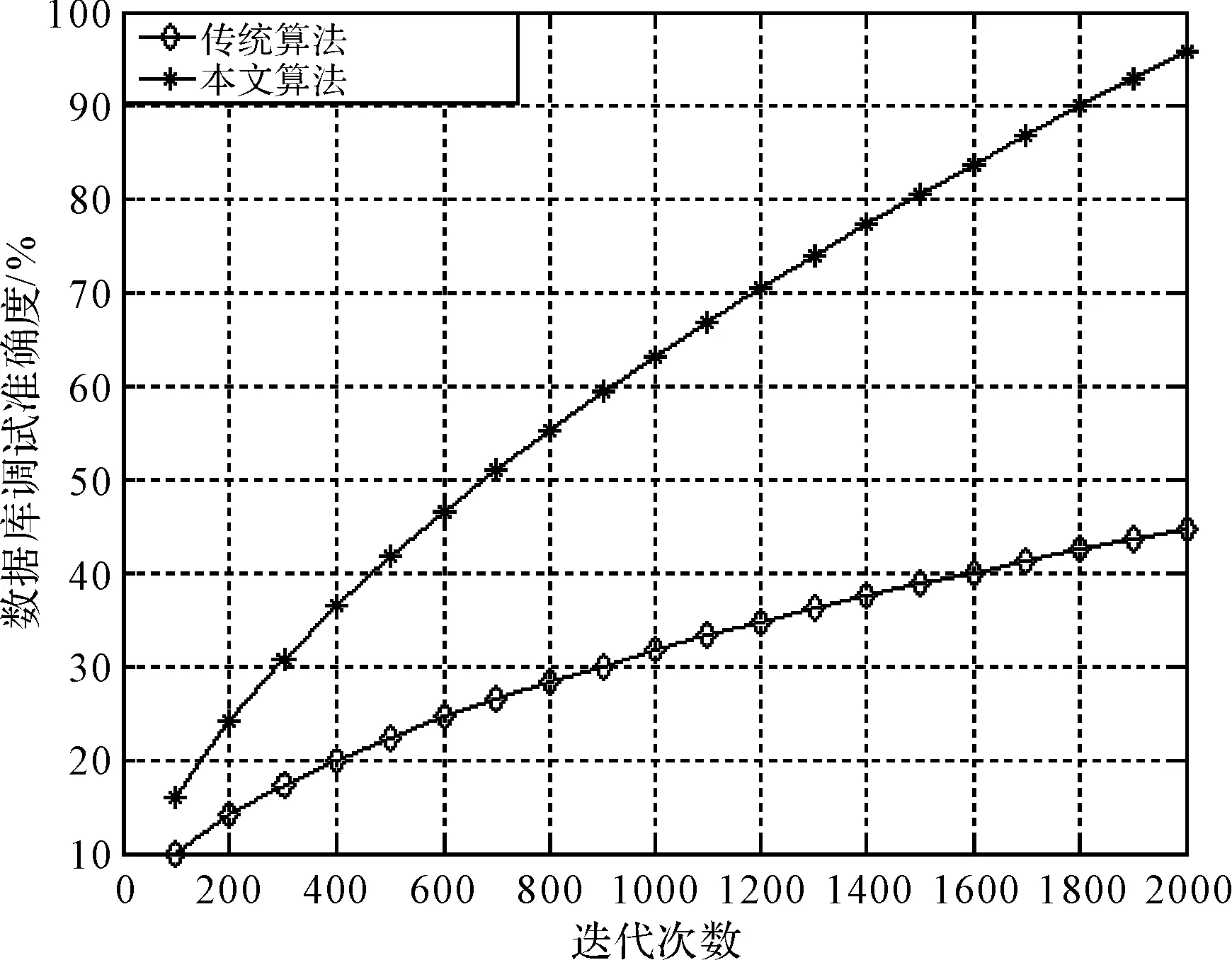
当所有个体分配完毕,聚类数目中的属性值X分为c类,其中1 V={vij|i=1,2,…,c;j=1,2,…,s} (11) 其中Vi为数据库访问过程中的聚类中心的第i个矢量,确定聚类簇的总数,得到数据库属性的模糊划分矩阵表示为 U={μik|i=1,2,…,c;k=1,2,…,n} (12) 通过定义,对初始群体进行处理,得到数据属性聚类目标函数为(定义聚类目标函数): (13) 式中,m为交叉运算权重,(dik)2为数据集采样样本xk与Vi的特征空间分布概率密度函数,群体P(t)经过筛选: (dik)2=‖xk-Vi‖2 (14) 且 (15) 结合模糊C均值聚类约束条件式,采用Lagrange定理,求得数据库调度的模糊C均值聚类的聚类中心为 (16) (17) 在聚类中心初始值已知的情况,设定代数,结合模糊度指标m,得到的适应度最优解作为最终的聚类解结果。 for(i in1∶2 000){x=runif(n,0,1); y=(sum(x)-n×0.5)/sqrt(n/12); A[i]=y} 3.2科研管理数据库调度优化实现 根据上述模糊C均值聚类算法,进行科研管理数据看的优化调度设计,假设科研管理数据库调度响应函数为 (18) 逐层挖大数据信息流的频繁模式集,进行数据信息流的特征提取,设计数据库调度传输算子hi(t),进行卷积,其中npi(t)为数据库调度的干扰项,得到数据库调度的寻优子集表示为 pri(t)=p(t)*hi(t)+npi(t) (19) 式中,hi(t)表示p(t)在科研管理数据集查询均匀遍历特征,计算孤立点的隶属度: (20) (21) 式中: *hi(-t)+nsi(t)*npi(-t) (22) 通过上述处理,设置为变异遗传散布控制量,由此实现对科研管理数据库的优化调度,算法实现过程如图2所示。 图2 基于模糊C均值聚类的科研管理数据库调度实现流程 4仿真实验与结果分析 为了测试本文算法在实现科研管理数据库库调度,提高数据库访问能力方面的性能,进行仿真实验,实验平台计算机使用Intel i5-3230M 2.6GHz双核CPU,采用Matlab仿真软件进行数学编程,首先进行数据聚类参数的初始化设置。设定参量Gmax=30,D=12,c=3,NP=30,数据采样样本的个数为1024,科研管理数据库采用分布式数据库设计,数据采样的周期为T=12s,数据聚类算法运行100次,采用多层矢量空间重构,对采样的数据库访问信息状态进行特征分解,获得的3层8个特征量,得到数据库调度的属性特征分解结果如图3所示。 图3 数据库调度的属性特征分解结果 以上述特征分解结果为原始测试样本集,进行模糊C均值聚类,实现数据库的优化调度,采用Monte Carlo算法,进行10000次运算,得到数据集的聚类结果,为了对比算法性能,采用本文算法和传统的K均值聚类算法进行对比,得到科研管理数据库的数据聚类对比结果如图4所示。 图4 数据聚类性能对比 从图可见,采用本文算法进行科研管理数据库的数据聚类,具有较好的特征峰值,旁瓣干扰较少,数据的特征信息反映准确,展示了较好的数据分析和聚类能力,以此为基础实现数据库的信息调度,提高数据库访问的信息定位能力,以数据库调度准确度为测试指标,得到本文算法和传统算法下数据库调度性能对比结果如图5所示。 图5 数据库调度性能对比 从图可见,采用本文算法进行数据库调度的准确度较高,收敛性好,性能优越于传统算法。 5结语 通过研究科研信息管理系统的数据库优化调度算法,提高数据库中科研管理信息的访问和调度能力,本文提出一种基于模糊C均值聚类的科研管理数据库调度算法,首先构建了科研管理数据库多层矢量自回归空间,进行数据库中访问信息流的特征提取,采用模糊C均值聚类算法实现对数据库的优化调度,仿真实验进行了性能验证,展示了本文算法在优化数据库访问性能,提高科研管理系统的数据分析能力方面的优越性,本文方法将在科研管理系统的优化设计和数据库优化访问设计中具有较好的应用价值。 参 考 文 献 [1] 高志春,陈冠玮,胡光波,等.倾斜因子K均值优化数据聚类及故障诊断研究[J].计算机与数字工程,2014,42(1):14-18. GAO Zhichun, CHEN Guanwei, HU Guangbo, et al. Fault Diagnosis and Optimal Data Clustering Based on K-Means with Slope Factor[J]. Computer & Digital Engineering,2014,42(1):14-18. [2] 张冬冬,李宏元.医疗设备计算机管理系统的设计与应用[J].电子设计工程,2015,(19):104-106. ZHANG Dongdong, LI Hongyuan. Medical equipment design and application of computer management system[J]. SAMSON,2015,(19):104-106. [3] 田刚,何克清,王健,等.面向领域标签辅助的服务聚类方法[J].电子学报,2015,43(7):1266-1274. TIAN Gang, HE Keqing, WANG Jian, et al. Domain-Oriented and Tag-Aided Web Service Clustering Method[J]. Chinese Journal of Electronics,2015,43(7):1266-1274. [4] 吴涛,陈黎飞,郭躬德.优化子空间的高维聚类算法[J].计算机应用,2014,34(8):2279-2284. WU Tao, CHEN Lifei, GUO Gongde. High-dimensional data clustering algorithm with subspace optimization[J]. Journal of Computer Applications,2014,34(8):2279-2284. [5] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015,(5):74-80. YU Xiaodong, LEI Yingjie, YUE Shaohua, et al. Research on PSO-based intuitionistic fuzzy kernel clustering algorithm[J]. Journal of Communication,2015,(5):74-80. [6] 张博,郝杰,马刚,等.混合概率典型相关性分析[J].计算机研究与发展,2015,52(7):1463-1476. ZHANG Bo, HAO Jie, MA Gang, et al. Mixture of Probabilistic Canonical Correlation Analysis[J]. Journal of Computer Research and Development,2015,52(7):1463-1476. [7] 孙超,杨春曦,范莎,等.能量高效的无线传感器网络分布式分簇一致性滤波算法[J].信息与控制,2015,44(3):379-384. SUN Chao, YANG Chunxi, FAN Sha, et al. Energy Efficient Distributed Clustering Consensus Filtering Algorithm for Wireless Sensor Networks[J]. Information and Control,2015,44(3):379-384. [8] 文天柱,许爱强,程恭.基于改进ENN2聚类算法的多故障诊断方法[J].控制与决策,2015,30(6):1021-1026. WEN Tianzhu, XU Aiqiang, CHNEG Gong. Multi-fault diagnosis method based on improved ENN2 clustering algorithm[J]. Control and Decision,2015,30(6):1021-1026. [9] Kumar A, Pooja R, Singh G K. Design and performance of closed form method for cosine modulated filter bank using different windows functions[J]. International Journal of Speech Technology,2014,17(4):427-441. [10] Rajapaksha N, Madanayake A, Bruton L T. 2D space- time wave-digital multi-fan filter banks for signals consistingof multiple plane waves[J]. Multidimensional Systems and Signal Processing,2014,25(1):17-39. Management Database Scheduling Algorithm Based on Fuzzy C Means Clustering LU XinghuaLI GuohengYU WenquanCHEN Yongcong (Huali College, Guangdong University of Technology, Guangzhou511325) AbstractIn the design of scientific research management system, it is necessary to optimize the management of scientific research management database to improve the access and scheduling ability of scientific research management information in the database. The traditional method uses K means clustering algorithm to carry out the information attribute clustering and scheduling of the database, and the sub space of the data is easy to make the data access process into local optimal solution, and the database scheduling performance is not good. A research management database scheduling algorithm based on fuzzy C means clustering is proposed. Firstly, the database of research management database is constructed, and the feature extraction of the information flow is extracted. The fuzzy C means clustering algorithm is adopted to optimize the database. Simulation results show that the data information clustering and scheduling of scientific research management database using the proposed algorithm has good characteristics, and the characteristics of data can reflect accurately, improve the information location ability of database access, and the accuracy and convergence of database scheduling is better. Key Wordsfuzzy C means clustering, scientific research management system, database, scheduling 收稿日期:2015年12月10日,修回日期:2016年1月20日 基金项目:2015年度广东大学生科技创新培育专项资金立项项目(编号:pdjh2015b0940);2012广东省质量工程项目“独立学院电子信息创新人才培养实验区”(编号:粤教高函[2012]204号)资助。 作者简介:陆兴华,男,硕士,讲师,研究方向:计算机控制算法、人工智能。李国恒,男,研究方向:人工智能。余文权,男,研究方向:通讯技术。陈永聪,男,实验员,研究方向:计算机网络技术。 中图分类号TP391.9 DOI:10.3969/j.issn.1672-9722.2016.06.006
猜你喜欢
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
财经(2017年15期)2017-07-03
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
