
基于支持向量机的云量精细化预报研究
2016-07-16 08:27赵文婧赵中军汪结华尚可政王式功柳志慧孔德兵苏俊礼
干旱气象 2016年3期
赵文婧,赵中军,汪结华,尚可政,王式功,柳志慧,孔德兵,苏俊礼
(1.兰州大学大气科学学院,甘肃 兰州 730000;2. 中国人民解放军92493部队6分队,辽宁 葫芦岛 125000;3.中国人民解放军95606部队气象台,重庆 402361;4.中国人民解放军95994部队气象台,甘肃 酒泉 735000)
基于支持向量机的云量精细化预报研究
赵文婧1,赵中军2,汪结华2,尚可政1,王式功1,柳志慧1,孔德兵3,苏俊礼4
(1.兰州大学大气科学学院,甘肃兰州730000;2. 中国人民解放军92493部队6分队,辽宁葫芦岛125000;3.中国人民解放军95606部队气象台,重庆402361;4.中国人民解放军95994部队气象台,甘肃酒泉735000)
摘要:基于T639数值预报产品与地面气象观测资料,以环渤海地区兴城站为例,选取与云的形成密切相关的4类预报因子——水汽类、大气不稳定度类、大气上升运动类和天气系统强度类,以总云量、低云量为预报对象,运用支持向量机,选取最佳参数,建立兴城站云量的逐月、逐时次精细化预报模型。试预报结果表明:平均预报准确率总云量为71%,低云量为69%,预报准确率较逐步回归模型有所提高;在大部分月份、时次,试预报值的变化趋势与观测值一致,可以较好地反映实际阴晴变换和云量变化;基于支持向量机的回归模型对云量有较好的预报能力。
关键词:支持向量机;最佳参数;云量;预报
引言
云是表示天气气候的重要要素[1-2]。云的变化直接影响居民日常生活、经济生产和部队军事活动,对云的预报一直是天气业务中的一个难点[3-5]。因此,云量的精细化预报具有重要的现实意义。
经典的云量预报方法是通过逐步回归建立线性模型。由于大气环流变化的复杂性和非线性,决定了大部分天气现象、气象要素与相应的预报因子之间的非线性关系[6-7],因此,线性模型对云量的预报存在局限性。目前,建立非线性模型的方法主要有:(1)运用人工神经网络(Artificial Neural Network, ANN)方法建立反向传播(Back Propagation, BP)模型[8-9];(2)运用支持向量机(Support Vector Machine, SVM)方法建立分类模型[1,9-11],运用最小二乘支持向量机(Least Squares Support Vector Machines, LSSVM)建立回归模型[12-13]。
BP-ANN具有极强的非线性映射能力[14],但存在以下问题:自身的优化计算存在局部极小问题[15];神经元数目、学习率和迭代次数的选择都会影响模型的准确性和稳定性,人为干预较多[9],计算量巨大。熊秋芬等[9]通过比较BP-ANN方法和SVM方法,发现二者都表现了较好的预报能力,但SVM分类模型的预报能力高于BP-ANN模型,且在计算速度上优势明显。杜亮亮[1]、熊秋芬[10]、安洁[11]等运用SVM方法建立了云量的分类预报模型,结果均表明SVM分类模型预报能力较好,模型稳定且有推广应用能力。付伟基[12]、胡邦辉[13]等运用最小二乘支持向量机方法建立了云量的回归预报模型,发现样本数较小时,模型仍具有较好的预报能力。在气象要素的释用方面,LSSVM有可观的应用前景。
本文以T639数值预报产品为基础,选取与云的形成密切相关的预报因子,以兴城站总云量、低云量为预报对象,运用SVM方法建立云量的精细化回归模型。
1资料与方法
1.1资料
所用资料为T639模式2010年、2012—2014年的数值预报产品,资料范围为0°—67°N、27°E—153°E,格点分辨率为0.5625°×0.5625°,高度层为1 000~300 hPa(共8层),预报时效为3~24 h(20:00起报,间隔3 h,共8个时次),基本物理量为气温(单位:K)、位势高度(单位:gpm)、比湿(单位:kg·kg-1)、 相对湿度(单位:%)、经向风速(单位:m·s-1)、纬向风速(单位:m·s-1)、垂直速度(单位:Pa·s-1)。格点位置取40.5°N、120.375°E。
环渤海地区兴城(40.35°N、120.42°E)地面气象观测站2010年、2012年、2013年的日8次(北京时02:00—23:00,间隔3 h)总云量、低云量观测资料和2014年08:00—20:00总云量观测资料(2014年低云量和其余时次总云量缺测)。
T639模式预报初始场为20:00,预报时效为3 h的产品,对应当天23:00云量观测数据,预报时效为6~24 h的产品,对应次日02:00—20:00云量观测数据。样本即由T639产品构造的预报因子和实测云量构成。
1.2方法
1.2.1原始数据的预处理
(1)扩大样本数:由于收集到的可用资料年限有限,只有2010年、2012—2014年,还需留出部分样本进行检验,因此建模样本偏少。为解决这一问题,取前一时次、本时次和下一时次的样本作为本时次总样本(如:取02:00样本、05:00样本和08:00样本作为05:00的总样本,用来建立05:00云量的SVM回归模型和检验模型的预报效果),这样既考虑了样本的连续性,又可使样本数增加2倍。
(2)利用T639数值预报产品,通过计算、组合,选取水汽类因子、大气不稳定度类因子、大气上升运动类因子和天气系统强度类因子作为预报因子(表1)。其中,Tt为总温度,Ts为饱和比湿下的总温度;对流性稳定度指数取925~600 hPa之间的θse差值;涡度平流X14、X16为ω方程的涡度平流随高度变化项;热力平流X15、X17为ω方程的厚度平流的拉普拉斯项,ω方程的这2项均可反映大气垂直运动,其中,总云量涡度平流1取925~500 hPa之间、热力平流1取850~500 hPa之间,低云量涡度平流1、热力平流1均取925~500 hPa之间;总云量和低云量的涡度平流2、热力平流2均取1000~500hPa之间。槽强度指数计算公式:
(1)
式中,H为对应等压面位势高度,i为经向格点,j为纬向格点。
(3)云量和预报因子归一化处理:
(2)
(3)
式中:X为预报因子,Y为总云量(低云量)。Xij、Yi为原始变量,(Xmax)j、Ymax为原始变量中的最大值,(Xmin)j、Ymin为原始变量中的最小值;xij、yi为归一化后的变量。
(4)对每类因子内部进行主成分分析:由于各主分量之间互相独立,且前几个主分量集中了大部分信息。因此,通过主成分分析,可提高因子的利用效率,将因子之间交叉的公共信息分离[16-17]。本文通过试验选取每类因子的前3个主分量(累积解释方差达到80%以上)作为最终的预报因子。如:水汽类因子X1~X7,对这7个因子进行主成分分析,选它们的前3个主分量作为最终用于建模和检验的水汽类因子。
1.2.2利用2010年和 2012年的样本建立SVM回归模型
(1) SVM方法基本思想:应用核函数展开定理,将样本空间非线性映射到一个高维的特征空间,通过在特征空间寻求最优超平面,实现样本空间的非线性分类或回归问题[7,18]。其中,要寻求的最优超平面在SVM分类问题中使得两类样本点分的“最开”,而在SVM回归问题中使得所有样本点离超平面的“总偏差”最小[19]。核函数的思想提供了一种解决维数灾难的方法[20]。
(2) SVM方法原理[20-22]
SVM方法通过引入损失函数应用于回归问题,常用损失函数为ε-不敏感函数:
(4)
引入损失函数后SVM回归问题解决方案如下:
(5)
约束条件:
(6)
其中,w∈RN,b∈R,w、b为待确定的参数;C为容错惩罚系数;ξ、ξ*为当个别样本点到所求超平面的距离>ε时引入的松弛变量。利用经典拉格朗日函数的对偶性将原问题转换为其对偶问题:
(7)
约束条件:
(8)
最终非线性回归函数如下:
(9)
其中:
(10)

本文核函数取为径向基函数(Radial Basis Function, RBF):K(x,xi)=exp(-r‖x-xi‖2),r为核函数参数。
(3) 利用Matlab软件*http://www.matlabsky.com/ ,http://www.csie.ntu.edu.tw/~cjlin/libsvm/实现SVM回归模型的建立
为得到可靠稳定的模型,将建模样本随机分为5组进行交叉验证。模型的预报效果主要取决于2个参数c(即容错惩罚系数C)和g(即核函数参数r)的选取,因此将c和g分别在区间[2-7,27]上取不同的值,比较模型均方误差的大小,找到使得均方误差最小的(c,g)组;由于c太大会出现过学习现象,因此最终选取c最小的(c,g)组作为最佳参数。
2结果分析
2.1SVM回归模型最佳参数
将2010年和2012年各月、各时次的样本随机分为5个不相交子集,进行交叉验证,使得均方误差最小的参数c和g构成一片均方误差等值区域,选取c最小的(c,g)参数组作为SVM回归模型的最佳参数(表2、表3)。由表中可以看出,就全年而言,c和g取值普遍较小。
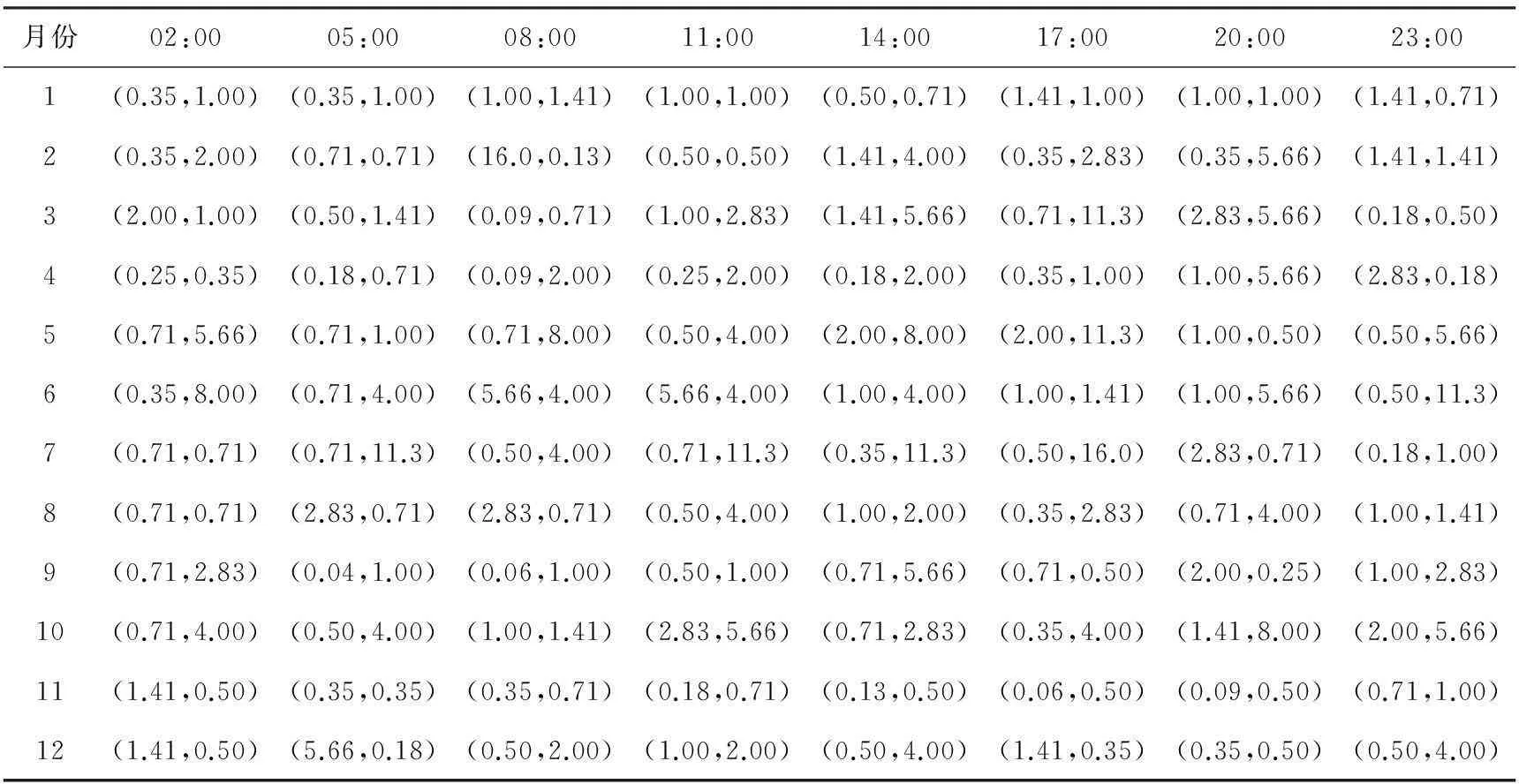
表2 兴城站总云量SVM回归模型最佳参数(c,g)
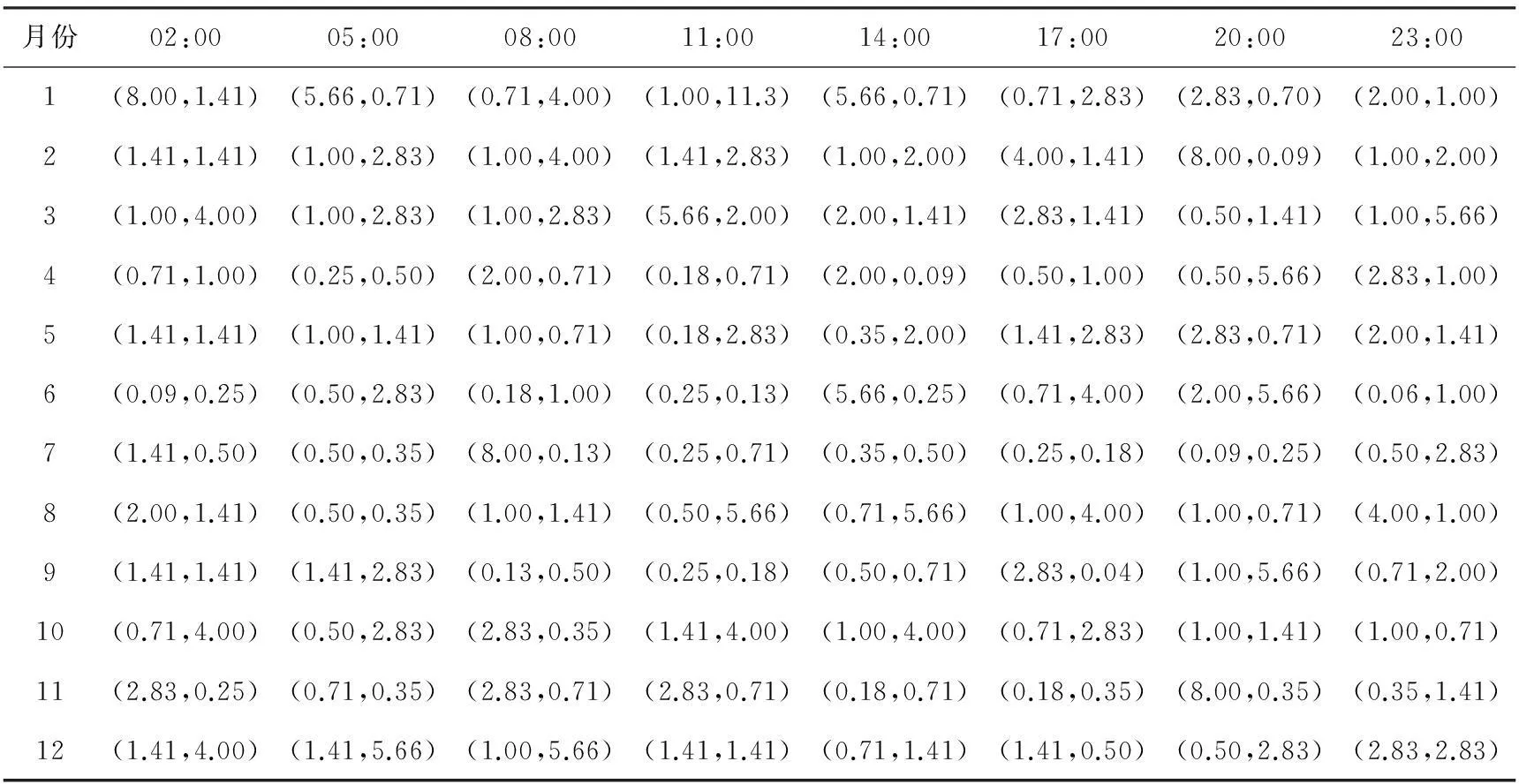
表3 兴城站低云量SVM回归模型最佳参数(c,g)
2.2SVM回归模型试预报
将2013年、2014年的样本作为测试集,代入最佳参数下的SVM回归模型进行试预报检验。并将2013年回归结果SVM与相同样本下逐步回归(Stepwise Regression)结果SWR进行比较。
预报准确率[12,23]A定义为:
(11)
式中:Pr为预报正确次数,Pt为预报总次数。其中,总云量试预报值与观测值绝对误差不超过3成规定为预报正确;低云量由于数值本身低于总云量,因此规定低云量试预报值与观测值绝对误差不超过2成为预报正确。
2.2.1试预报准确率
SVM回归模型对2013年样本试预报结果表明:(1)全年平均绝对误差总云量为2.3成、低云量为1.7成,平均预报准确率总云量为71%、低云量为69%;(2)由表4、表5可以看出,总云量夏半年平均预报准确率较冬半年高,低云量反之;(3)由于2012年3月云量资料缺失,用于建立SVM回归模型的样本数过少,模型的推广能力较差,因此总云量和低云量在3月的试预报平均准确率相对其他月份均偏低。
2014年样本试预报结果表明:总云量全年08:00—20:00平均绝对误差为2.3成,平均预报准确率为69%(表6),可见, 2014年试预报平均绝对误差和平均预报准确率较2013年无明显变化,SVM回归模型的预报结果较稳定。
2013年样本的逐步回归模型试预报准确率总云量为70%,低云量为65%,与SVM回归结果相比(表7):SVM回归模型对总云量的预报准确率略有提高,对低云量的预报准确率提高较明显。且逐月各时次总云量预报准确率超过60%的次数,SVM回归模型为81%,逐步回归模型为79%;低云量预报准确率超过60%的次数,SVM回归模型为74%,逐步回归模型为67%。

表4 兴城站2013年逐月各时次总云量试预报准确率(单位:%)

表5 兴城站2013年逐月各时次低云量试预报准确率(单位:%)
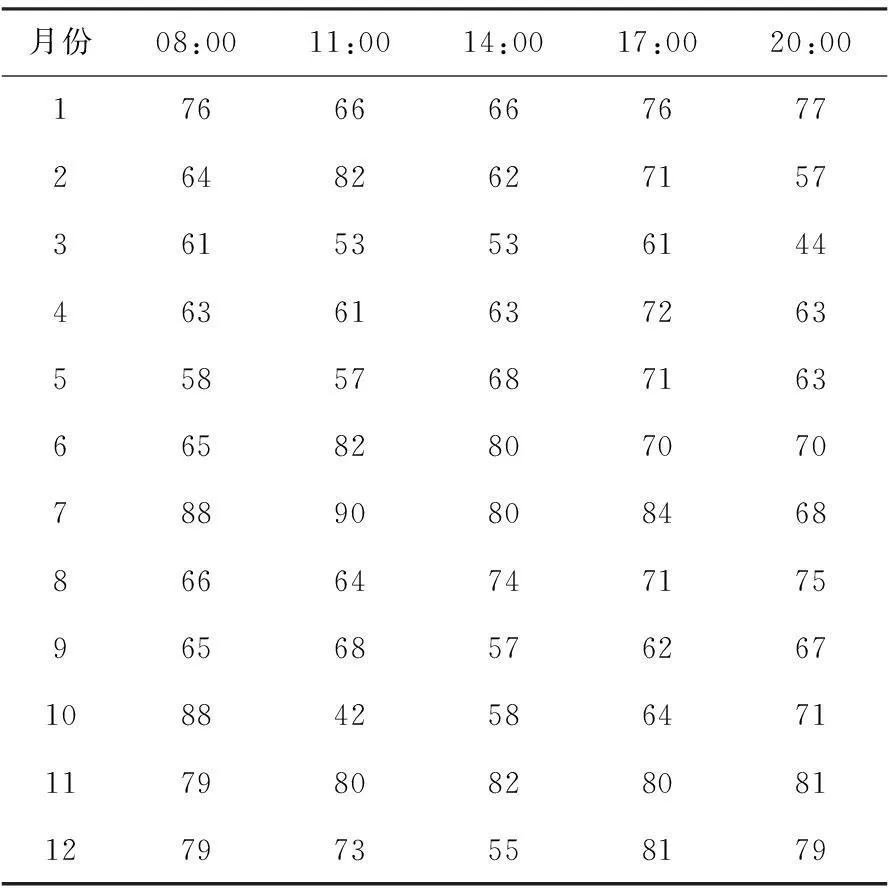
表6 兴城站2014年逐月各时次总云量

表7 2013年逐步回归与SVM
2.2.2试预报结果与观测值对比
(1) 以2013年5月05:00总云量(图1)为例,比较总云量SVM试预报值和实际观测值:二者的数值比较接近,而且预报值的变化趋势基本与观测值一致,其中,5月7—31日,预报值的起伏很好地反映了实际天气阴晴和多云、少云的变化。SWR与SVM回归预报准确率相当,但前者的绝对误差有22 d超过后者;SWR较SVM偏于平缓,如:3—5日、29—31日SWR没有反映出少云和晴天之间的转变;SWR对低值的预报能力较SVM差。

图1 2013年5月05:00兴城站总云量
(2)以2013年6月14:00低云量(图2)为例 ,比较低云量SVM试预报值和实际观测值:大部分天数二者数值接近,预报值的变化趋势与观测值大致相似,其中,6月3—12日、19—30日,预报值非常接近观测值,且变化趋势较好地反映了实际云量的变化。预报准确率SWR(48%)明显低于SVM(74%)、绝对误差SWR(2.1成)高于SVM(1.4成);除2日、17日、27日没有低云和9日、13日、21日低云量较多的情况二者没有预报正确,其他时段SVM较SWR更接近观测实况。
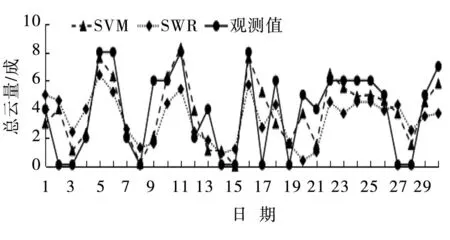
图2 2013年6月14:00兴城站低云量
(3)以2014年11月11:00总云量(图3)为例:预报值与观测值在个别日期(8日、11日、26日、28日、29日)数值差异略大(绝对误差超过3成),但预报值与观测云量的变化趋势一致,预报效果较理想。

图3 2014年11月11:00兴城站总云量
SVM回归模型对总云量和低云量的趋势预报都比较好。与SWR结果相比,SVM回归模型对云量的预报在数值和变化趋势上更接近实际观测,且对低云量预报效果改进明显,SVM回归模型更优。
3结论与讨论
(1)通过在[2-7,27]区间上比较不同的c、g参数下的均方误差,选取使得均方误差最小且c最小的(c,g)组作为最佳参数,得出最佳c和g最大取值为16,全年最佳c和g的取值普遍较小。
(2)利用2013年的样本对最佳参数下的SVM回归模型检验,试预报结果表明:总云量全年平均预报准确率为71%,低云量为69%;总云量和低云量的预报值与观测值较接近,且预报值的变化趋势可较好地反映实际天气云量变化和阴晴变换。整体上,基于最佳参数下的SVM回归模型对云量的预报效果较好,模型稳定并有一定的推广能力,且预报效果优于逐步回归模型。
由于2012年3月云量资料缺失,3月样本数过少,使得3月模型的推广能力降低,预报效果不理想。
参考文献
[1] 杜亮亮. 青藏高原东北边坡地带云水资源分析及夏季云量中短期预报方法研究[D]. 兰州:兰州大学,2012.
[2] 曹越前,张武,药静宇,等. 半干旱区云量变化特征及其与太阳辐射关系的研究[J]. 干旱气象,2015,33(4):684-693.
[3] 胡江林,李劲. 湖北省天空云量的特征分析及其预报[J]. 湖北气象,2000,2:15-17.
[4] 王建兵,敖泽建,陈洋. 近40 a甘南高原日照时数变化趋势及影响因子[J]. 干旱气象,2014,32(1):93-98.
[5] 封彩云,王式功,尚可政,等. 中国北方水汽与云和降水的关系[J]. 兰州大学学报(自然科学版), 2009,45(4):30-36.
[6] 滕卫平,俞善贤,胡波,等. SVM回归法在汛期旱涝预测中的应用研究[J]. 浙江大学学报(理学版),2008,35(3):343-347.
[7] 邓小花,魏立新,黄焕卿,等. 运用支持向量机方法对数值模拟结果的初步释用[J]. 海洋预报,2015,32(2):14-23.
[8] 张长卫. 基于BP神经网络的单站总云量预报研究[J]. 气象与环境科学,2009,32(1):68-71.
[9] 熊秋芬,胡江林,陈永义. 天空云量预报及支持向量机和神经网络方法比较研究[J]. 热带气象学报,2007,23(3):255-260.
[10] 熊秋芬,顾永刚,王丽. 支持向量机分类方法在天空云量预报中的应用[J]. 气象,2007,33(5):20-26.
[11] 安洁,王洪芳,齐琳琳,等. 支持向量机在多台站云量业务化预报中的应用[A]. 中国气象学会,第27届中国气象学会年会灾害天气研究会场论文集[C]. 北京:中国气象学会,2010.4.
[12] 付伟基,王俊,刘丹军,等. 基于最小二乘支持向量机的云量释用预报技术研究[A]. 中国气象学会,第27届中国气象学会年会灾害天气研究与预报分会场论文集[C]. 北京:中国气象学会,2010.6.
[13] 胡邦辉,刘丹军,王学忠,等. 最小二乘支持向量机在云量预报中的应用[J]. 气象科学,2011,31(2):187-193.
[14] Mathworks. Neural Network Toolbox. 2007.1-13.
[15] Philip D Wasserman. Neural Computing:Theory and Practice[M]. NewYork:Van Nostrand Reinhold,1989.
[16] 黄嘉佑. 气象统计分析与预报方法[M]. 北京:气象出版社,2004.121-139.
[17] 赵广社,张希仁. 基于主成分分析的支持向量机分类方法研究[J]. 计算机工程与应用,2004,3:37-38.
[18] 常军,李祯,朱业玉,等. 基于支持向量机(SVM)方法的冬季温度预测[J]. 气象科技,2005,33(S1):100-104.
[19] 冯汉中,杨淑群,刘波. 支持向量机(SVM)方法在气象预报中的个例试验[J]. 四川气象,2005,2:9-12.
[20] Steve R Gunn. Support Vector Machines for Classification and Regression[R]. Faculty of Engineering and Applied Science Department of Electronics and Computer Science, University of Southampton, 1998.
[21] 陈永义,俞小鼎,高学浩,等. 处理非线性分类和回归问题的一种新方法(I)—支持向量机方法简介[J]. 应用气象学报,2004,15(3):345-354.
[22] 冯汉中,陈永义. 处理非线性分类和回归问题的一种新方法(Ⅱ)—支持向量机方法在天气预报中的应用[J]. 应用气象学报,2004,15(3):355-365.
[23] 胡邦辉,张惠君,杨修群,等. 基于非参数回归模型的局部线性估计云量预报方法研究[J]. 南京大学学报(自然科学版),2009,45(1):89-97.
A Study on Refined Forecast of Cloud Cover Based on Support Vector Machine
ZHAO Wenjing1, ZHAO Zhongjun2, WANG Jiehua2, SHANG Kezheng1,WANG Shigong1, LIU Zhihui1, KONG Debing3, SU Junli4
(1.CollegeofAtmosphericScience,LanzhouUniversity,Lanzhou730000,China;2.TheSixthElementof92493UnitoftheChinesePeople’sLiberationArmy,Huludao125000,China;3.MeteorologicalObservatoryof95606UnitoftheChinesePeople’sLiberationArmy,Chongqing402361,China; 4.MeteorologicalObservatoryof95994UnitoftheChinesePeople’sLiberationArmy,Jiuquan735000,China)
Abstract:The refined forecast of cloud cover based on Support Vector Machine regression method was studied by using the products of T639 model and the data of surface meteorological observation station at Xingcheng. Physical quantities about water vapor, atmospheric instability, ascending motion of atmosphere and intensity of weather system, are closely related to cloud formation, so they were selected as forecast factors of cloud cover. Then the refined forecast models of total cloud cover and low cloud cover were built by using Support Vector Machine with best parameters. The forecast results of Support Vector Machine regression models showed that mean forecast accuracy of total cloud cover was about 71%, while that was about 69% for low cloud cover, which were higher than those of stepwise regression models. And the trend of forecasted cloud cover was close to observation data at most times and in most months. So the model based on Support Vector Machine could forecast cloud cover well.
Key words:Support Vector Machine; best parameters; cloud cover; forecast
收稿日期:2015-12-10;改回日期:2016-02-28
基金项目:国家公益性(气象)行业专项项目(GYHY201206004)、甘肃省国际科技合作计划项目(1204WCGA016)和兰州大学中央高校基本科研业务费专项(lzujbky-2013-m03)共同资助
作者简介:赵文婧(1990-),女, 汉族,甘肃天水人,硕士研究生,研究方向为现代天气预报技术和极端天气气候. E-mail:mmwenjing@163.com 通讯作者:尚可政(1960-),男,甘肃景泰人,博士,主要从事干旱气候和现代天气预报技术和方法研究. E-mail:shangkz@lzu.edu.cn
文章编号:1006-7639(2016)-03-07-0568
DOI:10.11755/j.issn.1006-7639(2016)-03-0568
中图分类号:P457.1
文献标识码:A
赵文婧,赵中军,汪结华,等.基于支持向量机的云量精细化预报研究[J].干旱气象,2016,34(3):568-574, [ZHAO Wenjing, ZHAO Zhongjun, WANG Jiehua, et al. A Study on Refined Forecast of Cloud Cover Based on Support Vector Machine[J]. Journal of Arid Meteorology, 2016, 34(3):568-574], DOI:10.11755/j.issn.1006-7639(2016)-03-0568
猜你喜欢
干旱气象(2022年4期)2022-09-23
农业灾害研究(2022年5期)2022-08-12
安徽农业科学(2019年8期)2019-09-04
西藏科技(2018年9期)2018-10-17
现代农业科技(2018年1期)2018-02-03
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
