
基于多模态学习的深度玻尔兹曼机分析微博用户的心理压力
2016-07-26 01:20杜文才
海南大学学报(自然科学版) 2016年2期
杨 展,杜文才
(海南大学 信息科学技术学院,海南 海口 570228)
基于多模态学习的深度玻尔兹曼机分析微博用户的心理压力
杨展,杜文才
(海南大学 信息科学技术学院,海南 海口 570228)
摘要:提出了利用基于多模态学习的深度玻尔兹曼机模型(DBM)对微博图片和文本数据进行处理和分析,在模型中可以实现文本和图片的低层次特征向稀疏高层次抽象特征的转变,最后用一个联合层表示来自2种不同模态数据的融合特征.此外,该模型发现2种不同模态数据的输入特征处在低层次时是高度非线性的.实验结果证明了本文所提出方法的有效性.
关键词:微博数据; 多模态学习; 玻尔兹曼机; 心理压力分析
心理健康问题一直以来受到大众的关注,过去对心理健康问题的研究主要通过心理学家和心理咨询师的分析和评估.如今大数据时代,社交平台数据呈爆炸式增长,2014年全球每个月活跃微博用户数增长0.74亿,相对于2014年,2015年同比增长1.76亿.微博平台是网络虚拟平台,微博用户可以通过文本和图片信息表达其情感、体验、感受和意见,因此可以利用微博数据分析用户的心理压力.
现阶段针对社交平台数据的分析方法包括文本分析和图片分析.文本分析方法有:最大熵[1]、朴素贝叶斯、支持向量机(SVM, Support Vector Machine)和基于依存关系分析的极性分类等.白鸽[2]等利用SVM对汉语的句子级别和评论级别进行分类;梁坤[3]等采用SVM对中文情感进行分类研究,通过加入一些网络评论判断一篇评论为正面还是负面,采用具有语意倾向的词并综合其词性作为特征项,用TF-IDF值作为特征项权值,取得较好的结果;李超[4]等通过基于受限玻尔兹曼机(RBM)的分析模型对微博平台上的短文本信息进行建模,挖掘出潜在主题信息,并根据短文本潜在主题信息实现对短文本的分类以及找到用户感兴趣的信息;Dai[5]等提出用户态度权重的概念,用情感权重计算器计算中国论坛用户的情感指数,了解公众观点以便做出相应地决策;刘鲁[6]等通过使用3种机器学习算法、3种特征选取算法和3种特征权重计算方法对微博评论进行情感分类的实证研究,研究表明采用SVM和IG,TF-IDF作为权重的分类效果较优秀;李培[7]等介绍一种利用句法依存关系对网络评论的极性进行自动分类的方法,通过将评论中提出的依存关系和词性构成依存关系词性对,同时利用自定义的极性词典进行分类,其方法能有效地减少计算的复杂度和提高分类的精度,实验表明是一种可行且有效的对社交平台文本数据极性分类的方法.图片分析方法主要从图片中识别人类情感的视觉特征,如,物体(球,生日贺卡,玩具等)、人物表情(哭,笑等)和其他特征比如色温等分析预测人类情感[8-10].Borth[11]等在语义层面上提出一个新颖的视觉概念检测库SentiBank,用来检测图片中1 200个ANPs(Adjective Noun Pairs).
目前社交平台文本分析方法无论是智能算法还是传统优化算法都是通过纯文本数据进行分析,从而忽略了相关的图片信息.图片分析方法分析人类情感存在“视觉情感间隙”的问题[12],因为同样的物体或人物表情在不同的环境中可能代表完全相反的意思,比如一张带有“哭”的人类情感视觉特征的图片,在不同的环境代表不同的“哭”:“高兴的哭”或“悲伤的哭”,因此离开文本数据对图片数据的视觉特征进行分析也存在不足.以玻尔兹曼机为基础的深度学习是机器学习中一个新的研究领域,能很好的解决自然语言理解等复杂问题.在深度学习基础上多模态学习模型已经广泛用于各种复杂层次概率模型[13-18],并且多模态学习模型还有3个优点:处理自然语言,减少训练过拟合和避免误差积累.针对上述研究缺陷,笔者建立一个能让图片和文本特征相互结合,减少“视觉情感间隙”的系统框架,采用多模态学习的深度玻尔兹曼机对含有多模态数据结构的微博数据进行分析.
1原理与方法
所涉及的微博数据包括2种数据模态:文本数据和图片数据,2种数据模态有着不同的表现形式和结构,其中文本数据是稀疏和离散的,图片数据是实值和密集的.通过Salakhutdinov[19]等研究表明,采用多模态学习的深度玻尔兹曼机模型可以发掘2种不同模态之间高度非线性关系,并且模型能提供一个从文本和图片的子空间特征映射到概念级特征上的学习信号,模型中各单元的连接都是无向的,因此模型在处理自然语言样本时健壮性更强.采用的多模态学习的深度玻尔兹曼机模型含有2个训练路径,每个训练路径中含有一个输入层和2个隐藏层,随着隐藏层深度增加,输入层数据特征逐渐被放大,不相关的变量就能被更加准确地识别和抑制,训练的数据越多,联合层就越能真实和准确的反映出数据的内部信息、简化分析过程,系统本身就能获得更多有用的特征向量[19].此外,针对不同的数据模态,不同的路径采用不同的模型进行建模,文本处理路径采用重复软最大化模型RSM(Replicated Softmax Model)结构[20],图片处理路径采用高斯伯努利受限玻尔兹曼机GRBM(Gaussian-Bernoulli Restricted Boltzmann Machines)结构[21-22].RSM和GRBM都是基于常见的RBM[23].


ERSM(v,h;θ),
(1)
其中,Wij表示连接可见单元和隐藏单元之间的权重,ai和bj分别是可见单元和隐藏单元的偏置,θ是RSM的参数{W,a,b},i,j,l,分别表示可见层vi单元数,隐藏层hj单元数,隐藏层hl单元数.根据式(1),模型能量函数的联合分布定义为
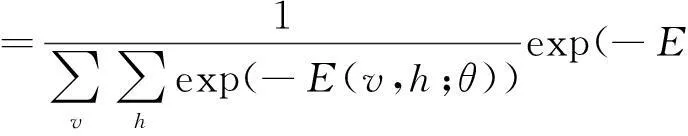
(2)
通过式(2),条件分布为
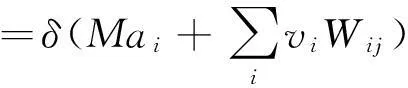
(3)

(4)


(5)
其中,PData表示观察数据,PModel表示模型.


(6)
其中,Wij表示连接可见单元和隐藏单元之间的权重,ai和bj分别是可见单元和隐藏单元的偏置,θ是GRBM的参数{W,a,b,σ}.根据式(6),v,h的联合密度概率为

(7)

(8)

(9)
其中,i,j,l分别表示可见层vi单元数,隐藏层hj单元数,隐藏层hl单元数,σ表示可见单元高斯分布的方差.GRBM的最终权重可以通过给定一组图片样本的实值向量{vn}N由式(10)获得

(10)
其中,PData表示观察数据,PModel表示模型.
式(5)和(10)采用最大似然学习法求模型的最终权重Wij是非常复杂的,因为PModel的期望复杂度是呈指数级,当样本非常大时,计算的效率非常低.Hinton提出采用对比散度算法通过接近最小化KL散度目标求数据的最大似然函数达到接近目标解[24]

(11)
其中,∂0表示可见数据,∂1表示模型经过多次吉布斯采样(Gibbs sample)后的分布.
根据1.1,文本训练路径中vt的概率函数为
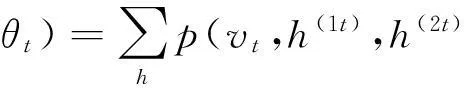

(12)
根据1.2,图片训练路径中vm的概率函数为


(13)

在2个不同模型结构训练路径的顶端设置一个联合层,联合层的输入是文本和图片训练路径上顶端隐藏层h(2t)和h(2m)的输出.用h3代表联合层,整个网络用h={h(1m),h(2m),h(1t),h(1t),h3}定义,联合层的密度分布由式(12)、(13)和h(2t),h(2m)得到


(14)
在含有不同模态数据输入和多层隐藏层的模型中,直接训练网络是非常困难的.那么训练过程将分为2步(如图2b和c所示),第1步使用layer-wise进行预训练,预训练能保证每个隐藏单元的期望输入;第2步将已学习到的参数用于初始化深度玻尔兹曼机模型的每一层,用增强输入q(h(3)|v)代理联合层h(3),这一步保证当预训练结束后模型能从相同的层进行微调(fine-tune)[19,23].预训练是采用Hinton提出的CD-n(n次吉布斯采样),大多数情况下CD-1训练的效果比较理想[24].
对于联合层特征的提取,通过式(14)得到联合层的条件分布为
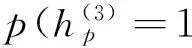
(15)
针对系统出现某一模态数据输入缺失的情况,Salakhutdinov等提出采用mean-field更新法近似所提取特征的真实后验分布概率,同时也能生成和得到联合层的特征[23].各层更新的条件分布可以通过式(16)~(21)得到

(16)

(17)

(18)

(19)

(20)

(21)
2实验与结果
2.1数据处理与实验设置实验所采用的数据来自新浪微博平台从2014年8月到2014年10月的1 000条含有图片和文本的微博数据,其中包括600条(无心理压力的)数据和400条(有心理压力的)数据.
对于实验文本数据的预处理,首先将每条微博文本进行分段,通过使用NLPIR/ICTCLAS进行特征提取[25].此外,文本字典是从Hownet和NTUSD字典里选出256个频率较高的词汇.图片数据预处理有许多方法,如,MPEG-7[26], PHOW[27], SSIM[28].在本文中,使用VLFeat 0.9.23对图片特征进行提取,图片特征向量为3 509维度.
模型的框架结构及处理过程如图3所示,其中采用RSM的文本数据训练路径中包括一个神经元为256个的输入层和2个隐藏层,其中每个隐藏层神经元为1 024个;采用GRBM的图片数据训练路径中包括3 509个线性神经元输入层和2个隐藏层,每个隐藏层神经元为1 024个.联合层神经元设置为2 048个.模型的训练算法见算法1(见附录),预训练采用CD-1,为了避免运行分离马克尔夫链时每个词汇计数获得模型分布的充分统计量,将词汇向量的和设置为1[19].

图3 多模态学习的深度玻尔兹曼机的框架和训练过程
微博用户心理压力的分析是使用逻辑回归分类器(LR-classifier)对联合层输出的特征向量进行分类.
2.2分类性能针对2种不同的训练方式对模型进行分类性能测试.
2.2.1多模态输入在实验中,用N(0,0.12)随机化模型初始参数,并将实验数据分为5份,随机选出4份作为训练数据,剩下1份作为测试数据,每次向模型中输入一组数据,训练完4份数据称为一个训练周期.首先运行mean-field更新和微调(fine-tune)前馈网络,运行mean-field更新次数为5次[19].为了确定学习速率,将学习速率设置在0.001~0.1之间进行测试.测试结果见表1.本模型对用户心理压力分析的准确度最高可以达到88.16%,平均准确度为86.09%.实验结果表明学习速率选择在0.008~0.01是最优的,虽然小于0.008会增加模型精确度,但训练时间过长,大于0.01则精确度会下降.训练的周期选择6次,超过6次分类精准度几乎保持不变(如图4所示).分别测试了从3层网络结构和2层网络结构的模型中提取出每一层的特征向量用逻辑回归分类器分类的性能.图5可得出联合层能更好地发现并融合2种不同模态数据中有用的特征,从而达到最高分类性能;3层网络结构的模型分类性能高于2层网络结构的模型分类性能,原因是隐藏层越多则越能表示更加复杂的函数,提高特征表现的能力.实验结果证明联合层能非常有效地平衡并融合文本和图片特征.

表1 不同学习速率下模型的训练耗时和精确度

2.2.2单模态输入对于单模态输入的性能评估,将模型针对仅输入文本数据的条件下进行测试.模型训练的步骤是首先将处理图片数据的GRBM训练路径初始化为零,这条路径的特征通过mean-field进行更新,采用标准吉布斯采样[23].文本数据vt作为输入,其他隐藏单元都随机初始化,用吉布斯采样通过模型中相邻的层更新并生成图片的代理样本P(vm|vt).将相同的文本数据用Xiang[29]等提出的VSM进行分析,VSM模型算法不仅采用一系列过滤器把文本中含有情感的词汇全部过滤掉,还结合个人输入习惯,而且VSM模型对于文本的特征提取非常全面,采用2种规则解决分词中标点符号和一些错误词汇的分割.表2中给出了单模态输入和目前流行的VSM算法的分析结果.

表2 多模态/单模态输入及VSM处理的总体精度
2.3 实验结果从表2中得出多模态学习的深度玻尔兹曼机处理多模态数据时性能最好,其次是VSM,多模态学习的深度玻尔兹曼机处理单模态数据时性能最差.表3给出了传统微博文本分析模型和多模态学习的深度玻尔兹曼机模型处理微博多模态数据分类结果的部分例子,在第3个例子中用户心理压力状态被传统微博文本分析模型错误分类了,但多模态学习的深度玻尔兹曼机结合用户所发的图片信息能正确识别用户的心理压力状态.但在第2和第4个例子中多模态学习的深度玻尔兹曼机将用户的心理压力状态错误分类了,其原因是用户使用了讥讽的表达手法,模型中没有加入人类逻辑思考,且附带的是中性、无感情色彩的图片.在表3中,-1代表有心理压力;1代表无心理压力;真实为用户心理压力的真实情况.

表3 多模态学习的深度玻尔兹曼机模型和传统微博文本分析模型对部分微博数据分类的结果
3结束语
提出了通过微博平台多模态数据分析用户的心理压力,与现有分析模型不同的是,采用多模态学习的深度玻尔兹曼机模型将文本信息和图片信息结合分析,并解决了跨模态数据特征向量融合的问题,实验结果得出了多模态学习的深度玻尔兹曼机处理纯文本数据时性能低于VSM,但处理多模态数据时性能高于VSM.因此随着社交平台上传感器和插件的增多,越来越多不同模态的数据出现在微博平台上,合理结合不同模态的数据提高分类精确度是未来微博数据挖掘的一个热点,但仍有一些问题值得考虑:1)如何加入视频模态的数据进行分析;2)在实时的微博海量数据中怎样智能地找出存在心理压力的用户.下一步的工作将针对以上2个问题进行研究.
参考文献:
[1] Pang B, Lee L, Vaithyanathan S. Thumbs up Sentiment classification using machine learning techniques: proceedings of the Conference on Empirical Methods in Natural Language Processing, Philadelphia, July 6-7, 2002[C]. New York:[s.n.],2002.
[2] 白鸽,左万利,赵乾坤,等.使用机器学习对汉语评论进行情感分类[J].吉林大学学报(理学版), 2009,47(6):1 260-1 263.
[3] 梁坤,古丽拉·阿东别克.基于SVM的中文新闻评论的情感自动分类研究[J].电脑知识与技术,2009,5(13):3 496-3 498.
[4] 李超,李昂,朱耿良.基于限制性玻尔兹曼机的微博主题分类[J].电信网技术,2014(7):26-29.
[5] Dai L, Ding L. Sentiment analysis in Chinese BBS: proceedings of the International Conference of Intelligence Computation and Evolutionary Computation ICEC 2012, Wuhan, July 7, 2012 [C]. Heidelberg: Springer-Verlag,2013.
[6] 刘鲁,刘志明.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[7] 李培,何中市,黄永文.基于依存关系分析的网络评论极性分类研究[J].计算机工程与应用,2010,46(11):138-141.
[8] You Q, Luo J, Jin H, et al. Robust image sentiment analysis using progressively trained and domain transferred deep networks:proceedings of the Twenty Ninth AAAI Conference on Artificial Intelligence, Austin, January 25-30, 2015[C]. [S.l.]:[s.n.],2015.
[9] Borth D, Ji R, Chen T, et al. Large-scale visual sentiment ontology and detectors using adjective noun pairs: proceedings of the 21st ACM international conference on Multimedia, Barcelona, October 21-25, 2013[C]. New York: [s.n.], 2013.
[10] Yuan J, Mcdonough S, You Q, et al. Sentribute: image sentiment analysis from a mid-level perspective: proceeding of the Second International workshop on Issues of Sentiment Discovery and Opinion Mining, Chicago, August 11, 2013[C]. New York: [s.n.],2013.
[11] Jia J, Wu S, Wang X, et al. Can we understand van gogh’s mood?: learning to infer affects from images in social networks:proceedings of the 20th ACM international conference on Multimedia, Nara, October 29-November 2, 2012[C]. New York: ACM press,2012.
[12] Machajdik J, Hanbury A. Affective image classification using features inspired by psychology and art theory: proceedings of the 18th International Conference on Multimedea 2010, Firenze, October 25-29, 2010[C]. Piscataway: [s.n.],2010.
[13] 刘建伟, 刘媛, 罗雄麟.玻尔兹曼机研究进展[J].计算机研究与发展,2014,51(1):1-16.
[14] 胡晓林,朱军.深度学习—机器学习领域的新热点[J].中国计算机学会通信,2013,9(7):64-69.
[15] Ngiam J, Khosla A, Kim M, et al. Multimodal deep learning:proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, June 28-July 2, 2011[C]. Massachusetts: [s.n.],2011.
[16] Ouyang W, Chu X, Wang X. Multi-source deep learning for human pose estimation:proceedings of the Computer Vision and Pattern Recognition (CVPR) 2014, Columbus, June 24-27, 2014[C]. Piscataway:[s.n.],2014.
[17] 邱立达,刘天键,林南,等.基于深度学习模型的无线传感器网络数据融合算法[J].传感技术学报,2014(12):1 704-1 709.
[18] Kiros R, Salakhutdinov R, Zemel R. Multimodal neural language models:proceedings of the 31st International Conference on Machin Leraning, Beijing, June 21-June 26, 2014[C]. [S.l.]:[s.n.],2014.
[19] Srivastava N, Salakhutdinov R. Multimodal learning with deep boltzmann machines[J]. Journal of Machine Learning Research,2014,15(8):1 967-2 006.
[20] Salakhutdinov R, Hinton G E. Replicated softmax: an undirected topic model: proceedings of the Neural Information Processing Systems 2009, Vancouver, December 7-10, 2009[C]. Massachusetts:[s.n.],2009.
[21] Freund Y, Haussler D. Unsupervised learning of distributions on binary vectors using two layer networks:proceedings of the Advances in Neural Information Processing Systems 1992, Denver, November 30-December 3, 1992[C]. San Francisco: Morgan Kaufmann Publishers,1993.
[22] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science,2006,313(5786):504-507.
[23] Salakhutdinov R, Hinton G E. Deep boltzmann machines[J]. Journal of Machine Learning Research,2009,5(2):1 967-2 006.
[24] Hinton G. Training products of experts by minimizing contrastive divergence[J]. Neural Computation,2002,14(8):1 771-1 800.
[25] Zhang H P, Yu H K, Xiong D Y, et al. HHMM-based Chinese lexical analyzer ICTCLAS:proceedings of the second SIGHAN workshop on Chinese language processing, Sapporo, July 11-12, 2003[C]. [S.l.]:Association for Computational Linguistics,2003.
[26] Manjunath B S, Ohm J R, Vasudevan V V, et al. Color and texture descriptors[J]. Circuits & Systems for Video Technology IEEE Transactions on,2001,11(6):703-715.
[27] Bosch A, Zisserman A, Munoz X. Image classification using random forests and ferns:proceedings of the IEEE International Conference on Computer Vision 2007, Rio de Janeiro, October 14-20, 2007[C]. Piscataway: IEEE Computer Society,2007.
[28] Shechtman E, Irani M. Matching local self-similarities across images and videos:proceedings of the Conference on Computer Vision and Pattern Recognition 2007, Minneapolis, June 18, 2007[C]. Piscataway: [s.n.],2007.
[29] Xiang Z Q, Zou Y X, Wang X. Sentiment analysis of Chinese micro-blog using vector space model:proceedings of the Asia-pacific Signal and Information Processing Association Annual Summit and Conference 2014, Siem Reap, December 9-12, 2014[C]. Piscataway: [s.n.],2014.
附录:
算法1:整个模型的学习训练学习算法
1. 输入:一组N个集合的向量vn={vm,vt},其中n=1,…,N,用S表示马尔科夫链,Λ为对角矩阵且Λ=1/σi,h={h(1m),h(2m),h(1t),h(1t),h3}, T为迭代次数.
3. For t=0 to T do
4. // 变分推理
5. For each vn,n=1toN do
6. 运行mean-field更新直至收敛[15].
7. End for
8. // 随机近似
9. For s=1 to S do
10. 样本:(vt+1,S,ht+1,S)→(vt,S,ht,S) 通过式(16)~(21)进行一次吉布斯采样.
11. End for
12. // 参数更新:
13. // 图片路径参数更新


16. // 文本路径参数更新

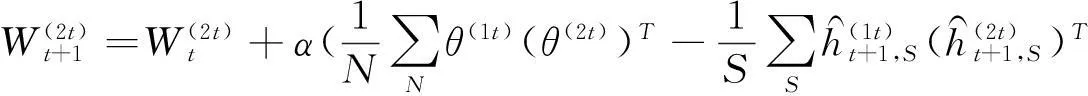
19. // 联合层参数更新


22. α↓
23. End for
收稿日期:2016-02-21
基金项目:海南省应用技术研发与示范推广专项(ZDXM2015105)
作者简介:杨展(1990—),男,湖南衡阳人,海南大学2013级研究生,研究方向:计算机应用,E-mail:zhanyang1122@outlook.com 通信作者: 杜文才(1953—),男,江苏徐州人,海南大学信息科学技术学院,澳门城市大学博士,教授,E-mail:wencai@hainu.edu.cn
文章编号:1004-1729(2016)02-0121-10
中图分类号:TP 391
文献标志码:ADOl:10.15886/j.cnki.hdxbzkb.2016.0019
Mental Stress State Analysis of Microblog User Based on Multimodal Learning with Deep Boltzmann Machine
Yang Zhan, Du Wencai
(College of Information Science and Technology, Hainan University, Haikou 570228, China)
Abstract:In the study, Deep Boltzmann Machine (DBM) based on multimodal learning algorithm was used to analyze microblog image and textual data. The model can transform low-level features of images and texts to sparse high-level abstract concepts. A joint representation layer was employed to fuse common features derived from the two different input modalities. Additionally, the model can detect that the input characteristic of two different model data at low-level was non-linear relations. The experiment results suggested that the proposed method is effective.
Keywords:microblog; multimodal learning; Boltzmann Machine; mental state analysis
