
增强的K-均值算法在城市能源计量数据平台的应用研究*
2016-08-11 06:59郑细端
计算机与数字工程 2016年4期
关键词:数据挖掘
郑细端
(福建工程学院管理学院 福州 350118)
增强的K-均值算法在城市能源计量数据平台的应用研究*
郑细端
(福建工程学院管理学院福州350118)
摘要能源的节能降耗一直是个热点问题,论文根据Oracle数据挖掘流程,运用Oracle Data Miner,阐述了如何将ODM增强的K-均值聚类算法应用于城市能源计量数据平台。选定某公司的煤耗数据为研究对象,对增强的K-均值聚类算法结果进行分析,为行业发展提供科学决策。
关键词Oracle数据挖掘; 增强的K-均值算法; Oracle Data Miner; 数据挖掘
Class NumberTP393
1 引言
知识挖掘的主要步骤有:数据清洗、数据集成、数据转换、数据挖掘、模式评估、知识表示。人们常使用“数据挖掘”来表示整个知识挖掘过程[1~2]。国家城市能源计量中心(福建)把城市能源计量数据平台的建设作为工作重点。该平台利用能源数据采集终端对煤、水、油、气、电等能耗数据进行采集和科学计量。如何充分利用采集数据分析能耗情况,获得数据信息价值,提高数据准确性、降低虚假程度、精细管理,促进节能降耗,缩小成本,提高企业竞争力,为行业发展提供策略依据,已成为亟待解决的问题[3]。
2 Oracle数据挖掘
2.1Oracle数据挖掘流程
Oracle数据挖掘(Oracle Data Mining,ODM)支持数据挖掘的跨行业标准流程CRISP-DM(Cross Industry Standard Process for Data Mining),流程构成如图1所示[4~5]。
1) 确定应用问题:确定应用目标,背景分析,确定数据挖掘目的、工具和技术。
2) 数据采集和准备:利用能源数据采集终端进行数据采集,并用相关技术对数据进行预处理,完成ODM模型应用的数据准备。
3) 建模和评估:通过不断调试设置参数选项,进行过程控制,评估模型结果,测试数据挖掘目标是否达到。
4) 部署分析:分析数据挖掘结果,做出部署计划,做好监测和维护,回顾数据挖掘流程,预测下一步的数据挖掘工作[3~6]。
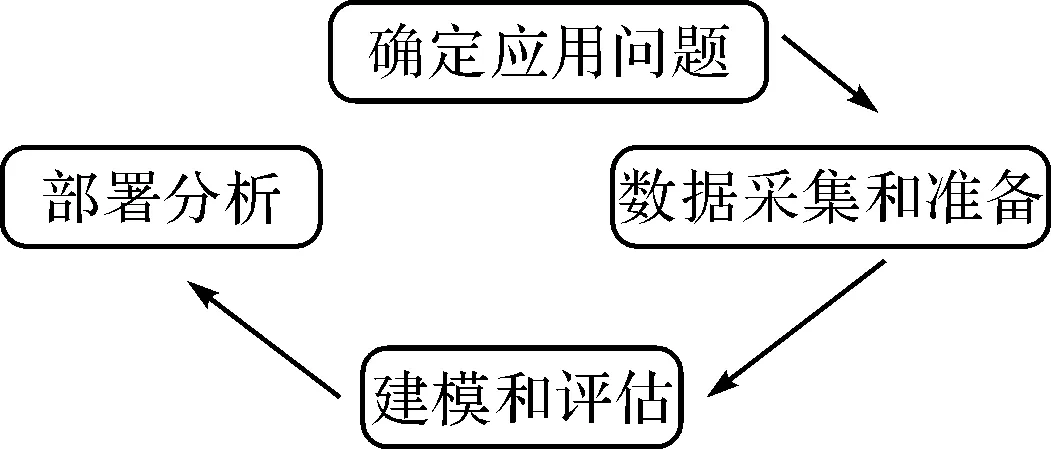
图1 Oracle数据挖掘过程
2.2增强的K-均值算法
ODM增强的K-均值(Enhanced K-means,EKM)聚类算法,是在保持传统的K-均值算法优点基础上,用与层次有关的方式加以改进[7~8],具有以下特点:
1) 以分层方式构建模型。采用二进制构建了一个自顶向下分裂模型,在结点形成簇后继续分裂和细化。在层次结构中以内部节点的质心改变来反映树的变化,返回整棵树。
2) 建成的树可形成平衡和不平衡两种树。分裂最大的结点,增加树的大小,直到达到所需叶簇的数量。
3) 提供聚类数据的概率计分和分配。
4) 有一个内部数据汇总的步骤,允许具有大量案例的数据集。
5) 返回时,为每个簇返回一个质心、直方图、和规则。质心报告了分类属性或数值属性的均值和方差模式。
增强的K-均值的这种渐进的方式,避免了需要建设多个K-均值模型,并提供始终优于传统的K-均值聚类结果。
2.3Oracle数据挖掘工具
Oracle Data Miner是Oracle Data Mining提供的一个图形用户界面(GUI)[9~10]。生成的代码只使用PL/SQL和SQL,不生成Java代码,但是生成的PL/SQL包,可以从一个Java程序中使用JDBC调用[10~11]。Oracle Data Miner在Tools->Publish as Database Table,可发布以下数据挖掘结果:属性重要性、关联规则、应用结果、决策树规则、聚类规则、分类测试度量、表或视图[3~12]。
3 Oracle数据挖掘的应用
3.1确定应用问题
富煤、少气、贫油是我国的能源结构,煤炭是重要的一次能源[5]。所以煤炭行业要参与各种发展机制,发展煤炭能源策略,促进并落实节能降耗,同时也要为以煤作为原料的企业减少成本,提高竞争力。因此选定煤耗数据为增强的K-均值算法的研究对象[3]。
3.2数据采集和准备
3.2.1数据集说明
能源数据采集终端包括记录ID、数据段信息FILEDINFOID、设备唯一标识码MN、采集时间DATATIME、通信代码PARAMNO、通信字段CPNO、传输值VALUE等字段。数据集中通信代码A01代表一线原煤1路、A02代表二线原煤1路、A03代表一线原煤2路、A04代表二线原煤2路[3]。
3.2.2数据预处理
数据预处理是数据挖掘过程的重要工作。数据预处理得精妙与否直接影响数据分析的成败[1,3]。首先,通过SQL语句进行数据清洗去除不规范数据;然后,筛选出大于0的煤炭数据,集成到统一格式的Excel表中;最后,用写字板把数据转换成能导入Oracle Data Miner中的文本文件格式。
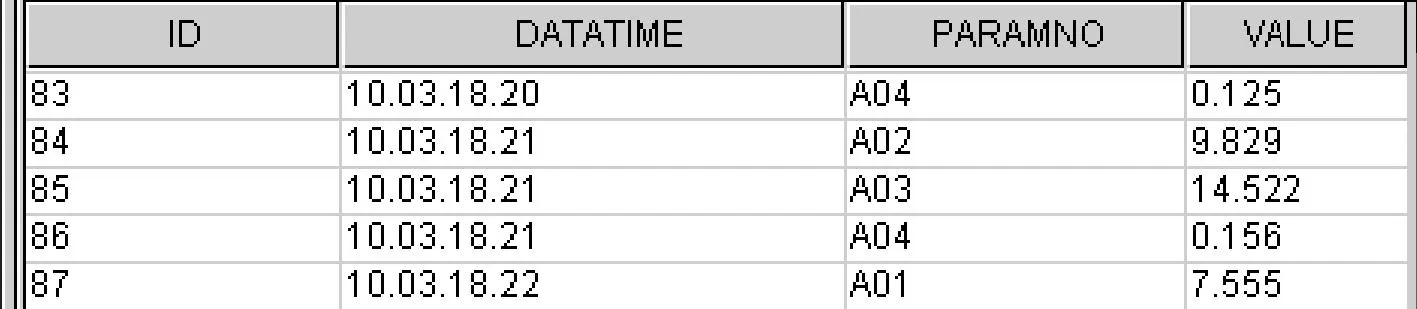
图2 数据预处理后的部分数据
经分析和筛选,ID、DATATIME、PARAMNO、和VALUE四个字段会影响数据挖掘结果,完成应用于Oracle Data Mining的增强的K-均值算法的数据准备。部分数据结果形式如图2所示[3]。
3.3增强的K-均值算法应用
1) 建立模型
增强的K-均值是以分层方式构建模型的,最终形成平衡或不平衡二叉树[1]。按Oracle Data Miner的既定模式建模,在Advanced Settings Dialog对话框中EMK算法的具体参数设置如下[12]:
· 样本(Sample):样本总数选择Retrieve Case Count自行计算,样本类型为随机,创建为表格,样本大小中事件和随机迭代数按默认设置,其中的Percentage of cases自动计算为39.63%;
· 异常处理(Outlier Treatment):中断点按标准误差形式(i取3),并以边界值进行替代;
· 缺失值(Missing Values):均值代数值形式替,模式代替分类形式;
· 正常化(Normalize):非稀疏属性按最大最小的默认形式,最大值为1,最小值为0,稀疏属性按线性比例处理;
· 建模属性(Build):叶簇数量设置为4,按欧几里德距离函数进行聚类,分类标准是按标准方差的形式,最小容错率为0.1,最大的迭代次数为2,最小支持度为0.1,分箱的数量为4,块增长为2。
增强的K-均值算法生成的层次二叉树如图3所示,其中叶结点(2、4、6、7)即为叶簇的数目。
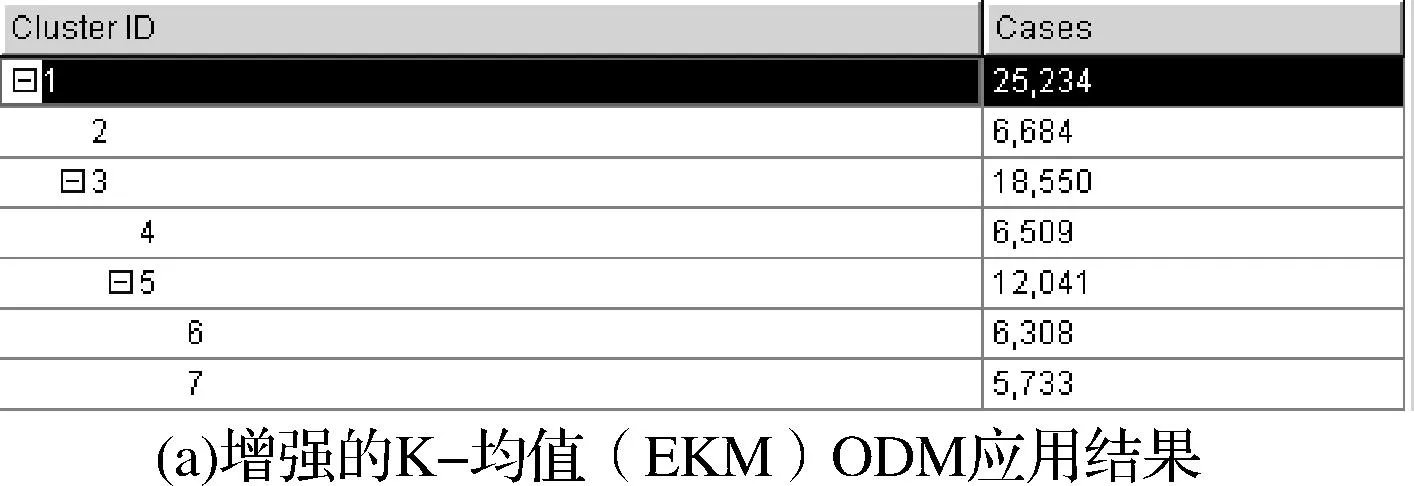
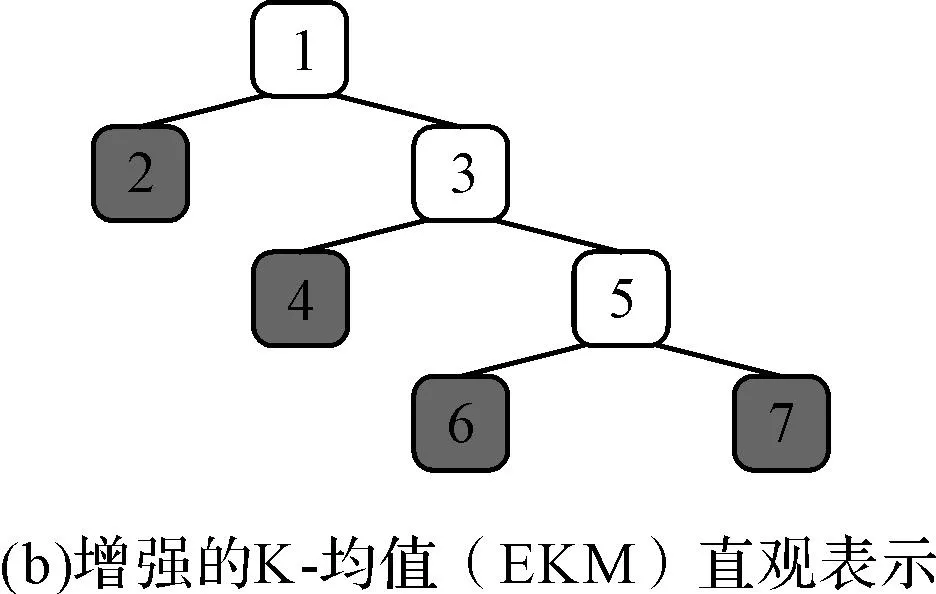
图3 增强的K-均值算法生成的层次二叉树
从Detail按扭,即可查询每个簇属性的质心报告和直方图,图4是其中一个簇的质心和属性直方图,增强的K-均值所获得的簇的质心情况如表1所示。
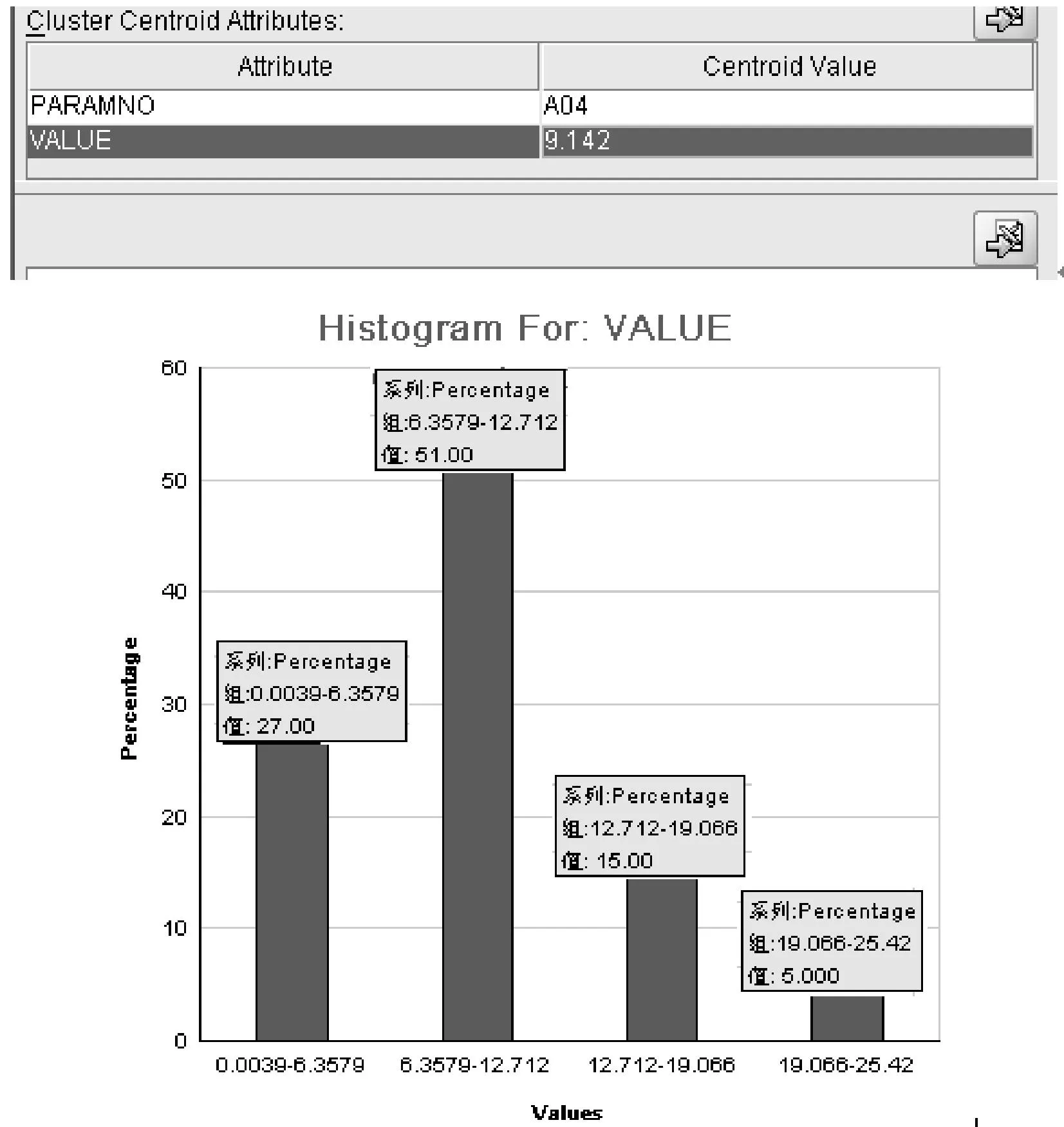
图4 增强的K-均值算法A04部分簇的质心和属性直方图
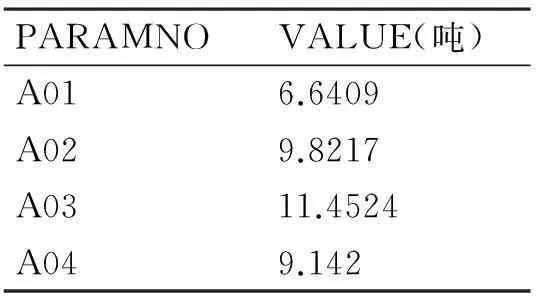
PARAMNOVALUE(吨)A016.6409A029.8217A0311.4524A049.142
A01~A04分别代表四个采煤点,因为分布于不同的地方,所以需要通过四条线路进行数据采集。由图4直方图示意每路数据的分布百分比和表1的质心报告可知,应用增强的K-均值算法可得A01-A04四条通信线路的质心分别为:6.6409吨、9.8217吨、11.4524吨、9.142吨,即四条线路所采集的煤数据的大致消耗情况。
2) 生成规则
在生成的二叉树中,每个叶簇都代表着一条判定规则。例如从根节点1到叶结点2对应的规则如下:
IF PARAMNO in (A04) and VALUE >= 0.0039 and VALUE <= 19.065975 THEN Cluster equal 2 Confidence (%)=94.71873129862361 and Support =6331
规则解释如下:如果PARAMNO为(A04)、VALUE值在(0.0039,19.065975)之间,那么它属于簇2,置信度为94.72%,一共有6331支持数。
EKM算法根据所设置的参数,所获得的规则置信度,即准确率较高,一共生成了四条规则,另外三个叶结点4、6、7对应的规则如下:
(1)IF PARAMNO in (A03) and VALUE >= 0.0039 and VALUE <= 25.42 THEN Cluster equal 4 Confidence (%)=100.0 and Support =6509。
(2)IF PARAMNO in (A02) and VALUE >= 0.0039 and VALUE <= 19.065975 THEN Cluster equal 6 Confidence (%)=98.36715282181359 and Support =6205。
(3)IF PARAMNO in (A01) and VALUE >= 0.0039 and VALUE <= 12.71195 THEN Cluster equal 7 Confidence (%)=91.1041339612768 and Support =5223。
3) 模型应用
将生成质心、属性直方图和规则的模型应用于预处理后的煤耗数据。由算法原理可知,增强的K-均值算法所有组件有相同的方差,符合贝叶斯概率模型的数据点分配到相应的簇中。图5是模型应用的部分结果。
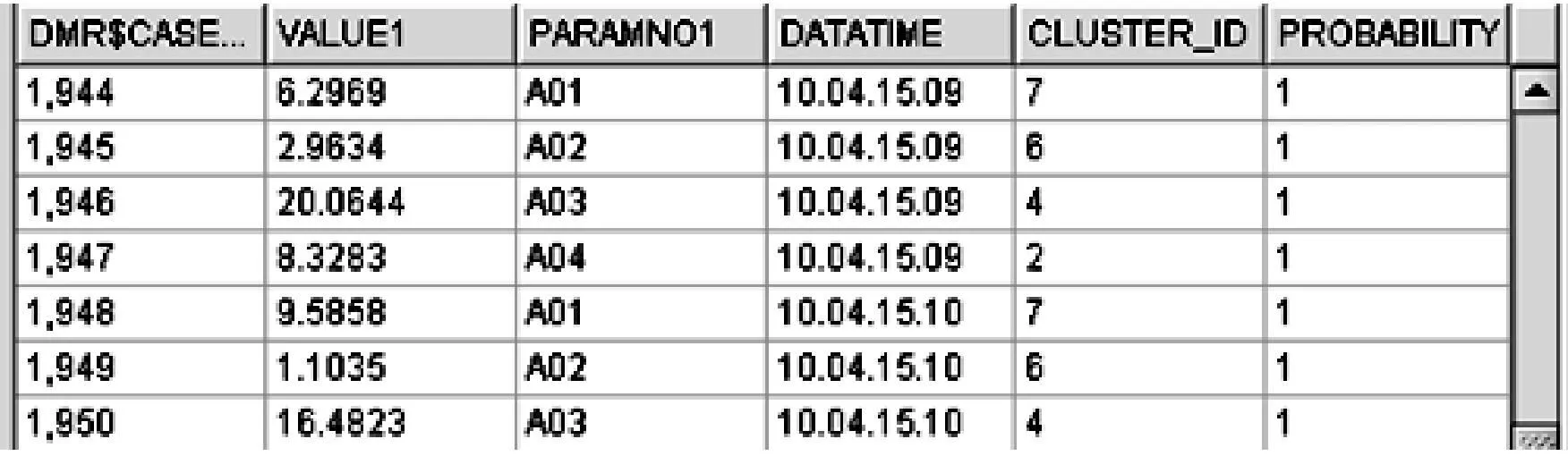
图5 增强的K-均值算法应用结果
PROBABILITY即为概率模型,也相对于算法形成的叶簇所对应的规则,由图5的结果显示可知,增强的K-均值算法的应用效果好,准确率高,在设置参数下应用,概率均为1,说明Oracle Data Mining数据挖掘工具聚类算法在煤耗数据应用分析确实可行。每个叶簇,所对应的规则如下:
叶簇2:VALUE less Or Equal 0.75 AND VALUE greater Or Equal 0.0;
叶簇4:VALUE less Or Equal 1.0 AND VALUE greater Or Equal 0.0;
叶簇6:VALUE less Or Equal 0.75 AND VALUE greater Or Equal 0.0;
叶簇7:VALUE less Or Equal 0.5 AND VALUE greater Or Equal 0.0。
3.4应用结果分析与说明
从增强的K-均值算法模型的应用表明,该数据挖掘算法在城市能源计量数据平台的应用确实可行,运用所获的数据挖掘结果有较高的准确率。在数据形式的应用中,增强的K-均值算法有较好的容忍度,对缺失值和“0”值较为敏感,处理不当会影响数据挖掘结果。下面对增强的K-均值(EKM)算法挖掘出的煤耗数据知识进行说明[3]:
1) 从时间的记录,如“12.03.11.00”、“12.03.11.23”说明该公司的运作是24小时流水线作业。从能源数据采集终端的记录可知,终端对数据的采集稳定。
2) 终端采集的煤耗数据中有诸如0.0000等异常值,A01~A04四个采集点所采集的煤耗数据情况有差异。
3) 该公司属于煤耗万吨的企业,需要改进的是煤耗热量的外排处理,确实落实节能减排工作。
4 结语
结合着能源的节能降耗的热点问题,将数据挖掘技术应用在城市能源计量平台中具有较高的研究价值和实践指导意义。节能减耗工作的有效落实任重道远,希望增强的K-均值算法在城市能源计量数据平台应用的数据挖掘结果,能为煤炭行业的发展提供参考意见,也为其他能源行业带来借鉴依据。
参 考 文 献
[1] 冯宠亮.数据挖掘中若干关键算法的研究[D].西安:西安电子科技大学,2010.
FENG Hongliang. Some Critical Algorithms Study of Data Mining[D]. Xi’an: Xidian University,2010.
[2] 蔡少伟.数据挖掘在入侵检测中的应用研究[D].广州:华南理工大学,2010.
CAI Shaowei. Application Research on Data Mining to Intrusion Detection[D]. Guangzhou: South China University of Technology,2010.
[3] 郑细端.Oracle数据挖掘在城市能源计量数据平台的应用[J].计算机与数字工程,2014,32(7):1299-1302.ZHENG Xiduan. Application of Oracl Data Mining in the Urban Energy Measurement Data Platform[J]. Computer & Digital Engineering,2014,42(7):1299-1302.
[4] 石磊.数据挖掘在金融业中的应用[D].上海:上海交通大学,2011.
SHI Lei. Data Mining in Finance by Discussing IPO Underpricing[D]. Shanghai: Shanghai Jiaotong University,2011.
[5] 白冬艳.数据挖掘在煤炭综合统计系统的应用研究[D].邯郸:河北工程大学,2010.
BAI Dongyan. Application and Research of Data Mining in Comprehensive Statistic System for Coal Enterprise[D]. Handan: Hebei University of Engineering,2010.
[6] 张虹波,匡银虎.一种应用ODM的人侵检测原型系统[J].计算机与现代化,2009(9):92-95.
ZHANG Hongbo, KUANG Yinhu. Model of Instrsion Decection on System Based on ODM[J]. Computer and Modernization,2009(9):92-95.
[7] 左国才,杨金民.K-means算法在电信CRM客户分类中的应用[J].计算机系统应用,2010,19(2):155-159.
ZUO Guocai, YANG Jinmin. K-means Algorithun for CRM Customers in the Telecommunications Classification[J]. Computer Systems & Applications,2010,19(2):155-159.
[8] 吴湘宁,胡炫,胡光道.Oracle中使用支持向量机的时间序列预测方法[J].计算机工程与应用,2013,49(14):121-125.
WU Xiangning, HU Xian, HU Guangdao. Applying Support Vector Machines to Time Series Prediction in Oracle[J]. Computer Engineering and Applications,2013,49(14):121-125.
[9] 司桂琴.基于GIS数据库的数据挖掘研究[D].乌鲁木齐:新疆大学,2011.
SI Guiqin. Research of Data Mining Based on GIS Database[D]. Urumqi: Xinjiang University,2011.
[10] 王春华.基于互联网的人力资源供求信息挖掘分析系统研究与实现[D].济南:山东大学,2011.
WANG Chuahua. Based on the Internet Human resources Supply and Demang Information Minging Analysis System Research and Implemetation[D]. Jinan: Shandong University,2011.
[11] 张涛.ODM数据挖掘技术在塔河数字营林中的探索与研究[D].哈尔滨:东北林业大学,2007.
ZHANG Tao. Exporation and Research of ODM Data Mining to Forest Management in Tahe[D]. Harbin: Northeast Forestry Universiy,2007.
[12] Oracle 10g Release 2 Data Mining Tutorial April 2006 Copyright, Oracle. All rights reserved,2006.
收稿日期:2015年10月9日,修回日期:2015年11月25日
作者简介:郑细端,女,硕士研究生,助教,研究方向:系统工程、管理科学、数据挖掘、计算机审计、计算机过程控制系统等。
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.04.041
Application of Enhanced K-means Algorithm in Urban Energy Measurement Data Platform
ZHENG Xiduan
(School of Management, Fujian University of Technology, Fuzhou350118)
AbstractSaving energy and reducing consumption of energy have always been a hot issue. According to oracle data mining process. The application of Enhanced K-means algorithm in the urban energy measurement data platform is described by using data mining tools Oracle Data Miner(ODM). A company’s coal consumption in Fujian is selected as the research object. Scientific decision will be provided to coal industry by analyzing the results of the Enhanced K-means clustering algorithm.
Key WordsOracle data mining, enhanced K-means algorithm, Oracle Data Miner, data mining
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
中国中医药信息杂志(2016年7期)2016-12-01
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
智能系统学报(2013年1期)2013-01-28
