
结合运动时序性的人脸表情识别方法
2016-08-12 05:47赵杰煜汪燕芳
电子学报 2016年6期
邱 玉,赵杰煜,汪燕芳
(宁波大学信息科学与工程学院,浙江宁波 315211)
结合运动时序性的人脸表情识别方法
邱玉,赵杰煜,汪燕芳
(宁波大学信息科学与工程学院,浙江宁波 315211)
脸部肌肉之间的时空关系在人脸表情识别中起着重要作用,而当前的模型无法高效地捕获人脸的复杂全局时空关系使其未被广泛应用.为了解决上述问题,本文提出一种基于区间代数贝叶斯网络的人脸表情建模方法,该方法不仅能够捕获脸部的空间关系,也能捕获脸部的复杂时序关系,从而能够更加有效地对人脸表情进行识别.且该方法仅利用基于跟踪的特征且不需要手动标记峰值帧,可提高训练与识别的速度.在标准数据库CK+和MMI上进行实验发现本文方法在识别人脸表情过程中有效提高了准确率.
表情识别;脸部肌肉运动的时序性;贝叶斯网络;区间代数
1 引言
人脸表情识别技术是涉及生物特征识别、图像处理、运动跟踪、机器视觉、模式识别、生理学、心理学等研究领域的一个富有挑战性的交叉课题,是多年以来模式识别与人工智能领域研究的一个热点问题.
传统的表情识别方法是在静态图片上分析表情.最常用的是基于人脸几何结构的方法[1,2],优点是数据量少,内存需求小,但几何特征的提取忽略了皮肤纹理变化等脸部其他重要信息,且识别效果的好坏很大程度依赖于基准点提取的准确性,在图像质量差和背景复杂的情况下不易实现.还有一些基于像素、频域的方法,通过滤波器来提取特征.如Gabor小波变换[3,4]、LBP(Local Binary Patterns)特征[5].LBP 特征可以更快地从原始图像中提取出来且维度较低,同时又保留了有效的图像局部信息.另外还有一些基于模型匹配的方法.如主动外观模型(AAM,Active Appearance Models)方法[6]描述了脸部运动的空间关系,但没有表达不同表情下运动时序关系的差别,因此未能全面捕捉表情识别中的关键信息,识别率还有待提高.
然而研究表明,运动信息而非仅仅静态特征对识别细微的表情变化更有效.心理学家也表明,人通过静态图片来识别表情的准确率不如通过视频来得高.
光流模型是提取图像运动信息的重要方法,在表情识别中被用于估计肌肉活动或特征点的位移[7].但光流分析很容易受到非刚性运动或者光线变化的影响,对运动的连续性要求比较高,一旦丢帧或者脸部定位有误,效果便不好.近来很多研究在提取表情特征中,越来越注重提取时空域的特征.Koelstra等人[8]使用了两种基于动态纹理的特征提取方法来提取人脸动作特征:基于运动历史图像的方法和使用 FFD 的非刚性配准方法.Wu等人[9]使用考虑时域信息的Gabor运动能量滤波器来提取特征,并通过SVM来分类.经过比较,其效果比Gabor滤波好.
利用动态模型可以研究脸部肌肉的时间动态,很多研究人员已经将动态模型应用于表情识别.其中动态贝叶斯网络(DBN,Dynamic Bayesian Network)是比较常用的.Tong等人[10]将DBN用于识别面部动作单元,Zhang等人[11]用多传感器信息融合技术和DBN为人脸表情的时序关系建模.李永强[12]则将动态贝叶斯网络用于人面部运动识别的研究.动态贝叶斯网络提供了一个连贯统一的分层概率框架来表示各表情单元之间的概率关系,并且考虑到随时间变化面部活动的发展.但DBN模型中不同单元之间的依存关系主要是手动设置的[12],若先验知识不足可能导致信息的缺失.
面部运动单元(AU,Action Unit)作为表情识别的特征是目前的研究热点,国内外有很多研究是通过对面部动作单元进行定位、检测来实现表情识别的[13,14].利用AU可以非常精确的描述人脸表情,但AU很难精确定位,尤其在图像序列中间AU强度较低的图片很难准确识别其AU,因此会出现计算量大、耗时长等难题.
为了突破上述表情识别方法的限制,本文将人脸表情视为一个复杂的活动并建模为一些顺序或重叠发生的基本运动组合,每一个基本运动占用一个时间区间.进而通过训练数据而自动学习这些脸部肌肉运动之间的依存关系,并用区间代数贝叶斯网络(IABN,Interval Algebra Bayesian Network)表达全局时空关系,提高人脸表情的识别效率.
区间代数贝叶斯网络是将区间代数(IA,interval algebra)与贝叶斯网络(BNs,Bayesian networks)相结合,这种将时序语义与概率语义结合的思想早在1996就由Young等人[15]提出,他们以区间代数理论为基础,提出了贝叶斯网络的时间诱导问题.之后一些研究对该思想进行了改进与应用,Arroyo-Figueroa等人[16]介绍了一种应用于诊断与预测的时序贝叶斯网络;Shi等人[17]提出了一种时间节点贝叶斯网络P- Nets,用于识别部分有序的活动序列;涂传飞[18]利用了贝叶斯网络进行本体知识的不确定推理,并将区间代数理论引入到本体建模方法中.
本文将区间代数贝叶斯网络应用于人脸表情识别,基于表情图像序列对人脸表情进行建模与识别.这样就可以充分利用贝叶斯网络的概率基础和区间代数的时间关系基础,可以同时表示脸部活动之间的空间关系及时间关系.在对表情进行识别的过程中,首先要识别所有相关的脸部基本运动,然后跟踪这些运动提取其在每一帧图片中的空间位置,并根据空间位置的变化计算出运动的时间区间,从而可以根据区间代数理论得出这些运动之间的时序关系.最后利用IABN表达基本运动之间的时间空间关系,训练得到在不同表情下的不同IABN结构及参数,进而对不同表情进行分类.
2 基于IABN的表情识别
2.1脸部基本运动及其时序关系
为了综合人脸表情中多层次的信息,首先要识别出所有相关的脸部基本运动.本文将人脸基本运动定义为局部脸部肌肉的移动,但直接计算脸部肌肉的移动比较困难,所以用脸部特征点的移动来近似代替.因此,一个基本运动即为一个特征点的移动.图1(a)中画出了两个基本运动,其中特征点P1的移动对应于运动E1,特征点P2的移动对应于运动E2.
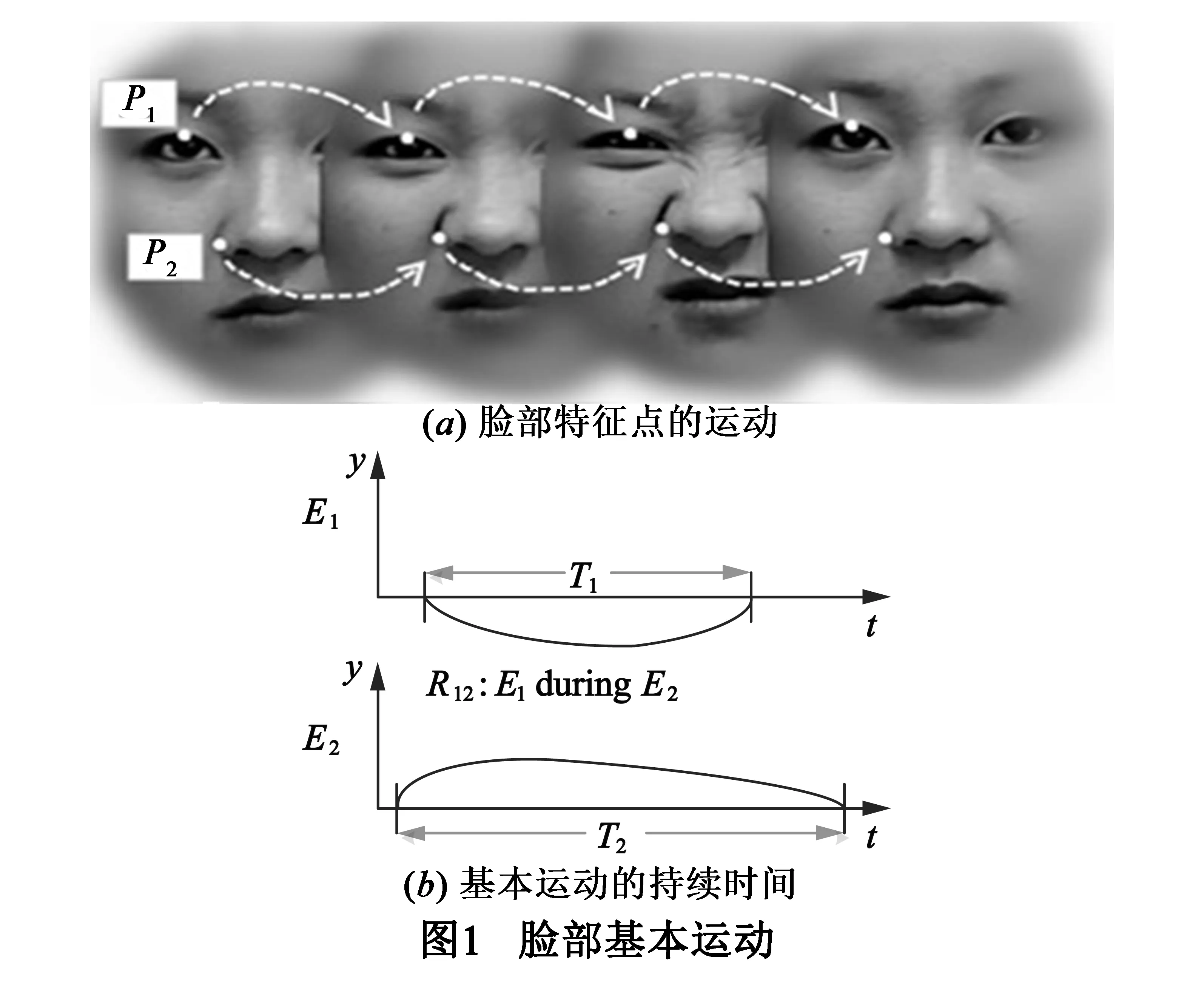
一个基本运动有一定的持续时间,持续时间即为对应的特征点从离开中间位置开始到重新回到中间位置为止的时间段.中间位置是指人脸在无表情时特征点的位置,如图1(a)中第一个和第四个人脸中P1和P2的位置即为中间位置.在图1(b)中,T1和T2分别是基本运动E1和E2的持续时间.
通过跟踪脸部特征点可以得到每个基本运动的持续时间,从而研究它们之间的时序关系.在这里,时序关系就涉及到区间代数的概念.
区间代数[19]是由James F.Allen在1983年提出的,它可以方便地表示两个时间区间的关系,表达能力强,也容易理解,因此被广泛的应用在自然语言理解等领域.在区间代数中定义了13种基本区间关系,它们分别是Ⅱ={b,bi,m,mi,o,oi,s,si,d,di,f,fi,eq},如表1所示为其中的7种关系,其中x和y分别表示连续的时间区间,txs表示x的起始时刻,txe表示x的终止时刻,tys表示y的起始时刻,tye表示y的终止时刻.而若x对y的基本区间关系为b,则y对x的基本区间关系为bi,此即为一对逆关系.在这13种关系中,有6对关系互逆,即b与bi、d与di、o与oi、m与mi、s与si、f与fi,而equals关系和它自身互逆.
给定两个时间区间X和Y,它们之间的时序关系可以根据表1而得到.如在图1(b)中,运动E1和E2的时序关系为E1duringE2,即E1含于E2.
2.2IABN及其学习
区间代数贝叶斯网络IABN是一个有向图G(V,E),其中V是节点集合,在本文中表示脸部基本运动,E是连线集合,在本文中表示的是脸部基本运动之间的时间及空间关系.IABN中的一条连线就是一个时序关系的载体.如图2(a)为一个IABN的例子,其中包含三个节点:A,B和C.
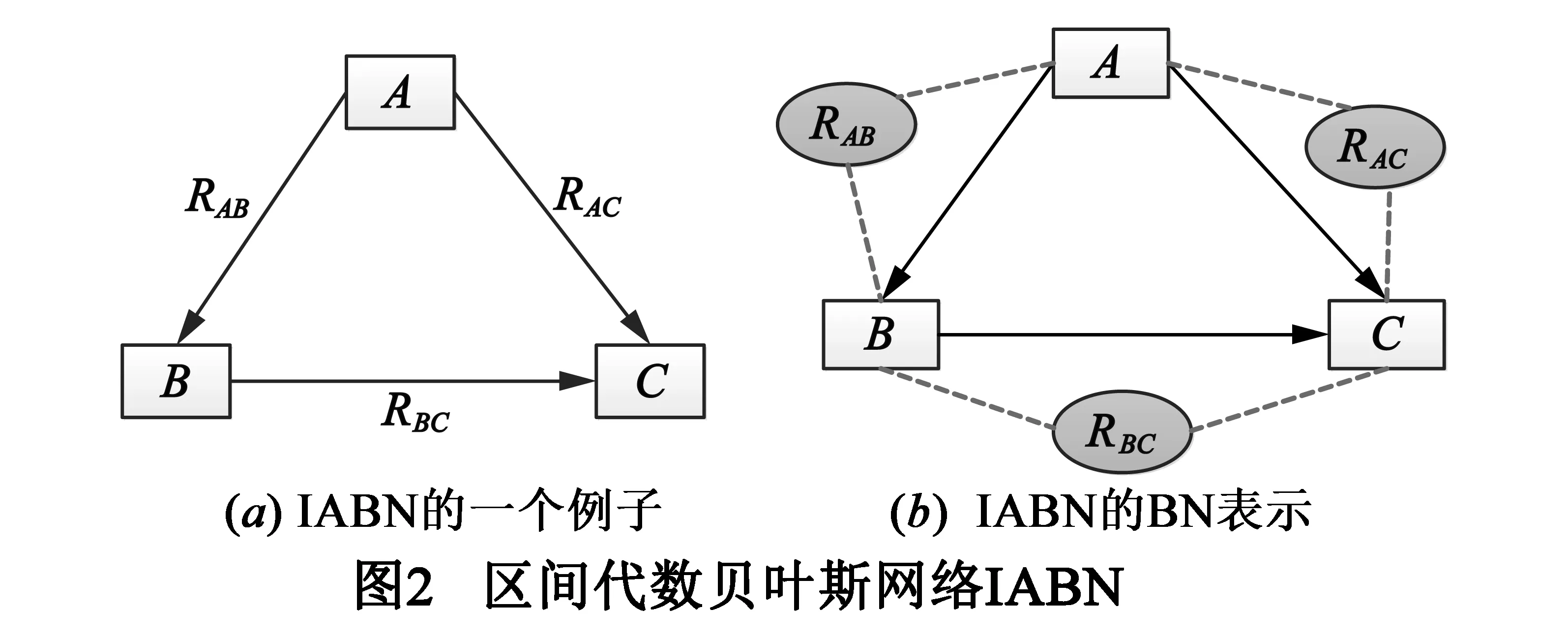
用一个对应的贝叶斯网络(BN)来实现IABN,这样可以利用贝叶斯网络良好的数学结构.图2(b)是对应于图2(a)中的IABN的贝叶斯网络图形表示,引入了另一类节点来代表时间关系.如此,一个IABN被表示为一个BN,其中包括两类节点:基本运动节点(方形)和时序关系节点(椭圆形).因此,也会有两类连线:空间关系(实线)和时间关系(虚线).空间关系连线将基本运动连接起来,描述它们之间的空间关系;时间关系连线将时序关系节点和与之对应的基本运动连接起来,表达两个相连接的基本运动之间的时间关系.这样,基本运动以及它们之间时空信息的联合概率可以由式(1)计算:
贝叶斯网络的训练包括结构学习与参数估计,则被简化为BN的IABN同样也包括这两个步骤,区别在于IABN的结构学习由两部分组成:时间关系的结构学习、空间关系的结构学习.
2.2.1结构学习
(1)时间关系的结构学习
对时间关系的结构进行学习即为对时间关系节点的选择.由于有些基本运动之间的时间关系并不能对表情识别起到作用,甚至可能不利于表情的识别,所以要选择对表情识别有利的基本运动对,即选择合适的时间关系节点.为此,本文引入了一个基于KL距离得分制的方法用于评估每一对运动之间的时间关系节点,最终选择出那些得分相对较高的节点.基本运动A和基本运动B之间的时间关系RAB的得分为式(2)所示.其中i,j=1,2,…,m(表情种类数),Pi和Pj分别是在第i种表情和第j种表情下RAB的条件概率,DKL代表的是KL距离,计算方法如式(3)、式(4)所示.所有实体对根据它们的得分进行顺序排列,得分最高的k对将会被选择出来,则它们之间的时间关系也将被保留在IABN模型里.
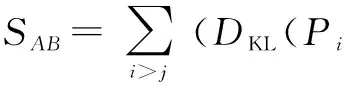
(2)
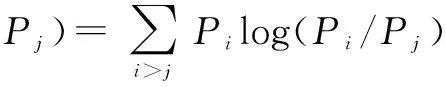
(3)
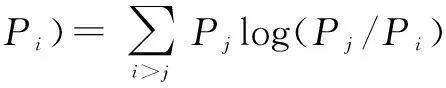
(4)
(2)空间关系的结构学习
学习IABN的空间结构也就是找到一个网络G使其可以与训练数据D进行最好配对.本文采用K2算法进行结构学习,用贝叶斯信息准则BIC值来评估每个IABN.
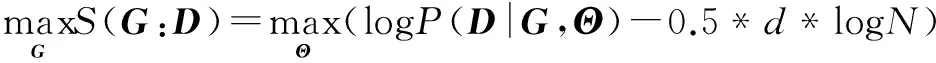
(5)
其中,S(G:D)表示网络G的BIC值,Θ表示估计的参数向量,logP(D|G,Θ)表示对数似然函数,d表示自由参数的个数.
2.2.2参数估计
IABN的参数包括每个节点在给定其父亲节点时的条件概率分布.给定一个数据集D,其中包含了每个基本运动的合理预测形态以及他们之间的时间关系.进行参数估计的目的就是找到参数Θ的最大似然估计,如式(6)所示.
(6)
求此Θ的最大似然估计值的步骤为:
(1)对似然函数(6)取对数,并将得到对数函数进行整理;
(2)求导数,令导数为0,得到似然方程;
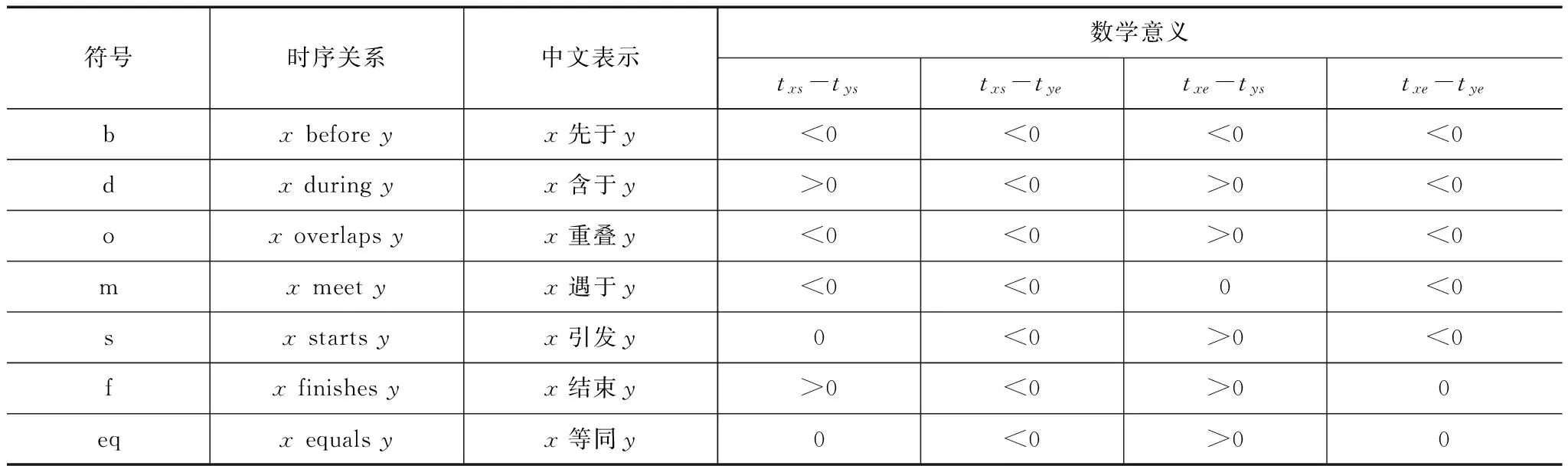
表1 7种基本区间关系
(3)解似然方程,得到的参数即为所求.
2.3人脸表情识别
为了识别N种人脸表情,本文将建立N个区间代数贝叶斯网络IABN,使得每一个IABN对应一种表情.在每个IABN中,一个实体节点代表一个基本运动.对于一个采样x,它的表情由式(7)来计算得到.
(7)
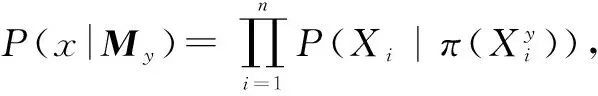
3 实验及结果分析
3.1实验设计
实验利用CK+数据库[20]和MMI数据库[21]对本文的方法进行了评估,并与当前识别效果最好的方法进行了对比.
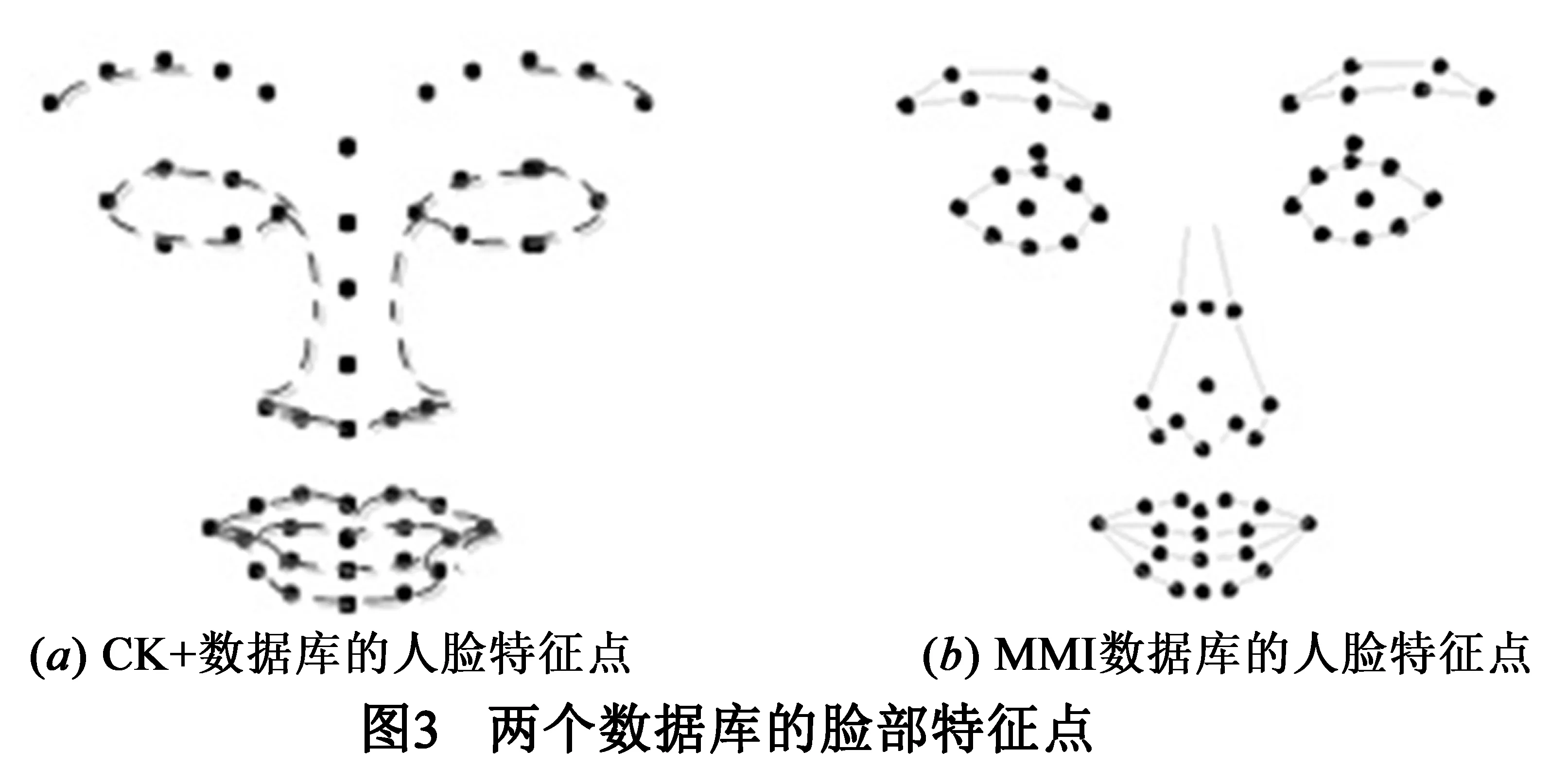
CK+数据库:扩展的Cohn-Kanade人脸表情数据库.它是由卡内基梅隆大学中的机器人研究所和心理学系共同建立的一个人脸表情数据库,是对CK数据库的一个扩充,在很多研究中被看作算法之间比较的标准.在数据集中共标出7种表情,分别为:生气(An),蔑视(Co),讨厌(Di),害怕(Fe),高兴(Ha),悲伤(Sa),惊奇(Su).CK+数据集的脸部特征点有51个,如图3(a).
MMI数据库:由英国帝国理工大学的人机交互研究实验室所创建,包括30多个对象的740幅静态图像以及848个动态的图像序列.在数据集中被标记了表情标签的有213个序列,其中有205个是正面人脸.用这所有的205个表情序列作为样本进行网络的训练,它们共被标记为6种表情,分别为:生气(An),讨厌(Di),害怕(Fe),高兴(Ha),悲伤(Sa),惊奇(Su).MMI数据集的脸部特征点有61个,如图3(b).
在时间关系的结构学习中,先要确定被选中的时间关系节点的个数.针对两个数据库,研究进行表情识别时逐渐增加时间关系节点的个数时IABN的识别效果,发现对CK+数据库选择50个时间关系节点可使识别率达到最大值88.1%,比未引入时间关系时提高了5.8%;对MMI数据库选择52个时间关系节点可使识别率达到最大值62.5%,比未引入时间关系时提高了9%.在空间关系的结构学习中,将图像序列的中间帧图像中特征点的空间位置作为区间代数贝叶斯网络节点的空间位置,其间的空间关系即为节点间的空间关系.
3.2实验结果
分别跟踪两个数据库的脸部特征点,得出与特征点个数相同的一些基本运动,跟踪这些基本运动得出其运动开始时间和运动结束时间,并根据区间代数理论和式1、表1来计算这些基本运动之间的时序关系,进而依据2.2节的方法学习IABN的时间关系结构.同时,针对每一种表情进行IABN的空间关系结构学习.
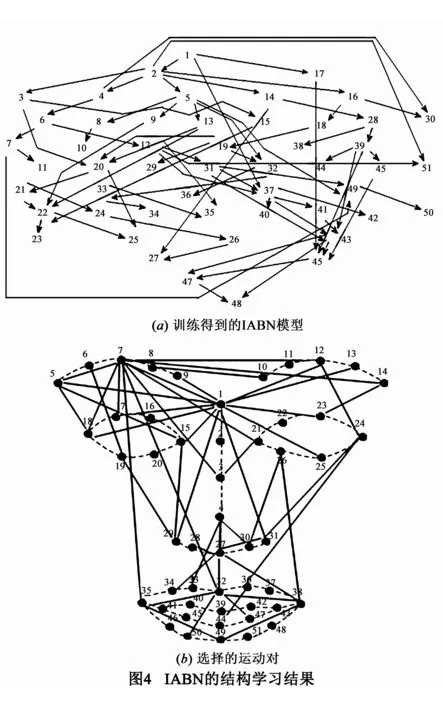
实验可得两个数据库上产生的IABN空间结构及时间关系结构.图4(a)展示了针对CK+数据库在表情An下训练得到的IABN空间结构,其中每个节点代表一个特征点对应的运动,每条连线代表运动之间的空间关系.图4(b)表示了选择出的50个时间关系节点.如果RAB被选择,则在运动A和运动B之间划一条线,表示A、B之间的时间关系在不同的表情下差别较大.如图中特征点7与特征点32之间的连线表示E7与E32之间的时序关系在7种不同表情中表现出较大的差异,从而可以较好地分辨这7种表情.对数据库MMI,可得类似空间结构与时间关系结构,文中不再单独列出.
对每一个测试样本,按2.3节方法选择相似性最高的IABN模型,该IABN模型所对应的表情即为最终识别的表情.对这两个数据库,最终的平均识别准确率分别为:对数据库CK+,识别率为88.1%;对数据库MMI,识别率为62.5%.
3.3与相关工作的比较
从上面的实验结果可以看出IABN可以成功捕捉并运用时空信息进行表情识别.表2将不同方法在数据库CK+上的表情识别准确率进行了比较,其中Lucey等[20]采用的特征是SPTS和CAPP,与本文类似,是对脸部51个特征点进行跟踪得到的.陈雄[22]选取CK+数据库全部593个表情序列中的包含验证表情的327个进行表情识别试验,利用AU构建贝叶斯网络.其中训练样本占总实验样本的36.70%,测试样本占总样本的63.30%.本文也是将数据库的全部标记表情的327个表情序列进行实验,其中训练样本占总实验样本的30.58%,测试样本占69.42%.对比发现:利用AU与贝叶斯网络相结合来进行表情识别比IABN方法的识别率更高,证实了AU描述人脸表情的高效性.但在进行AU定位时会增加耗时,具体比较如表3所示.
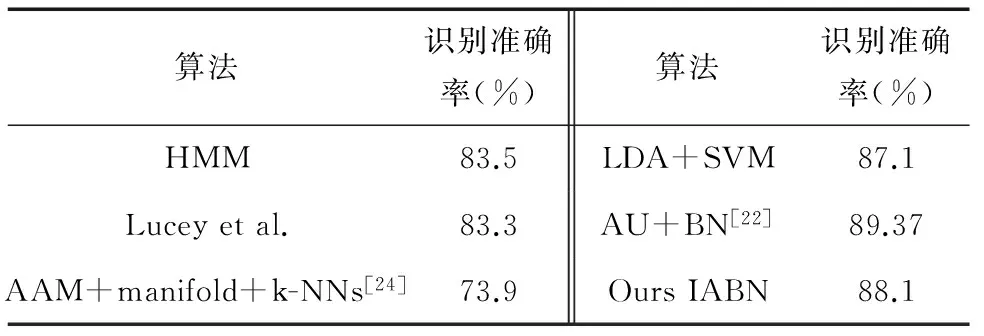
表2 数据库CK+的表情识别准确率比较
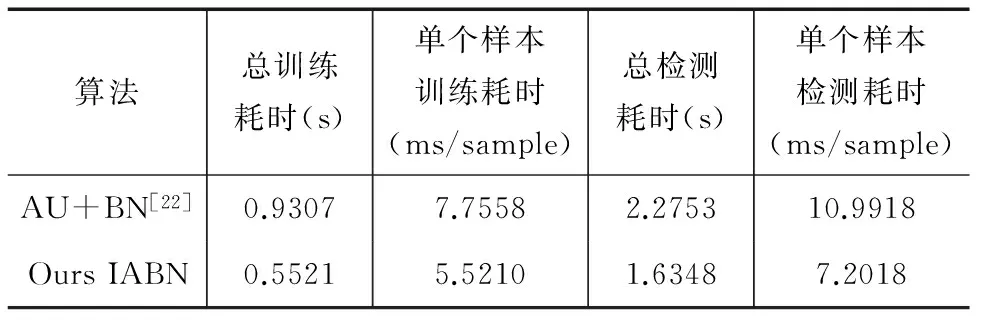
表3 数据库CK+的表情识别耗时分析
表4将不同方法在数据库MMI上的表情识别准确率进行了比较.在所有对数据集MMI进行表情识别的方法中,文献[23]的方法是与本文最相似的,他们进行训练的样本与本文一样,为所有的正面人脸表情序列(205个).不同的是,他们的方法是基于LBP特征并通过学习图像块的共性与特性来进行表情分类.表4中把该文方法与本文方法进行了比较,其中CPL是仅使用普通图像块的方法,CSPL是既用了普通图像块又用了特有图像块的方法,ADL是使用了由Adaboost算法选择出的图像块的方法.可以看出,本文方法比CPL和ADL方法的识别效果要好很多.虽然CSPL方法比本文方法效果好,但是该方法是基于外观特征的并且需要手工标定峰值帧,而本文方法仅仅利用了基于跟踪的特征并且不需要手工标定峰值帧.
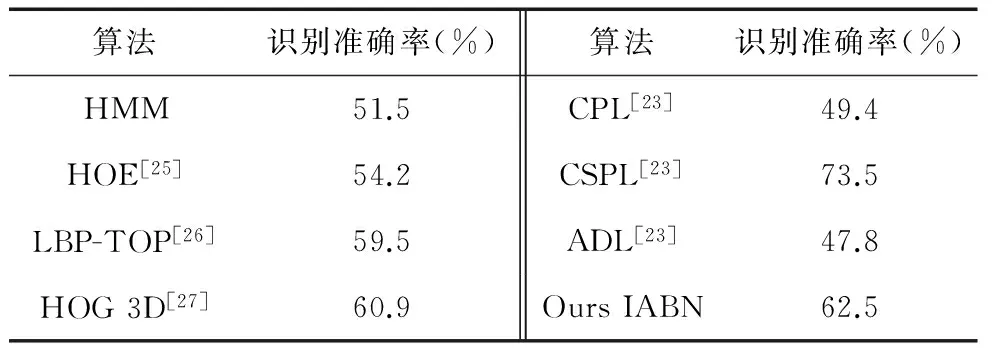
表4 数据库MMI的表情识别准确率比较
综上可以看出IABN成功地捕捉了复杂的时空关系并将其转换为对表情识别有用的信息.其表现明显优于基于时间片的动态模型和其他同样使用基于跟踪的特征的方法,而且与基于外观的方法效果相当甚至比它们效果更佳.
4 结论
本文将人脸表情建模为一个复杂的活动,这个活动是由在时间上重叠或连续的脸部基本运动组成的.并提出将时间区间代数与贝叶斯网络结合起来,以便充分利用表情识别中脸部基本运动之间的时空关系.在标准数据集上的实验表明:与现有动态模型相比,本文方法在研究复杂关系上表现更佳,即使它仅仅以人脸肌肉的运动为基础而未使用任何外观的信息.但本文方法得出的区间代数贝叶斯网络结构复杂,存在冗余信息,需要进一步优化网络,去除冗余,实现网络的最优结构.
[1]Pantic M,Rothkrantz L J.Expert system for automatic analysis of facial expressions[J].Image and Vision Computing,2000,18(11):881-905.
[2]Pantic M,Rothkrantz L J.Facial action recognition for facial expression analysis from static face images[J].Systems,Man,and Cybernetics,Part B:Cybernetics,IEEE Transactions on,2004,34(3):1449-1461.
[3]Buciu I,Kotropoulos C,Pitas I.ICA and Gabor representation for facial expression recognition[A].Proceedings of the International Conference on Image Processing[C].Barcelona:IEEE Computer Society,2003.855-858.
[4]刘晓旻,章毓晋.基于Gabor直方图特征和MVBoost的人脸表情识别[J].计算机研究与发展,2007,44(7):1089-1096.
Xiaomin L,Yujin Z.Facial expression recognition based on Gabor histogram feature and MVBoost[J].Journal of Computer Research and Development,2007,44(7):1089-1096.(in Chinese)
[5]Ahonen T,Hadid A,Pietikainen M.Face description with local binary patterns:Application to face recognition[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2006,28(12):2037-2041.
[6]Cheon Y,Kim D.Natural facial expression recognition using differential-AAM and manifold learning[J].Pattern Recognition,2009,42(7):1340-1350.
[7]Sánchez A,Ruiz J V,Moreno A B,et al.Differential optical flow applied to automatic facial expression recognition[J].Neurocomputing,2011,74(8):1272-1282.
[8]Koelstra S,Pantic M,Patras I.A dynamic texture-based approach to recognition of facial actions and their temporal models[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2010,32(11):1940-1954.
[9]Wu T,Bartlett M S,Movellan J R.Facial expression recognition using gabor motion energy filters[A].Proceedings of the Computer Vision and Pattern Recognition Workshops[C].San Francisco,CA:IEEE Computer Society,2010.42-47.
[10]Tong Y,Liao W,Ji Q.Facial action unit recognition by exploiting their dynamic and semantic relationships[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2007,29(10):1683-1699.
[11]Zhang Y,Ji Q.Active and dynamic information fusion for facial expression understanding from image sequences[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2005,27(5):699-714.
[12]李永强.基于动态贝叶斯网络的人面部运动识别方法研究[D].哈尔滨:哈尔滨工业大学,2013.
[13]Yang P,Liu Q,Metaxas D N.Exploring facial expressions with compositional features[A].Proceedings of the Computer Vision and Pattern Recognition[C].San Francisco,CA:IEEE Computer Society,2010.2638-2644.
[14]Valstar M F,Pantic M.Fully automatic recognition of the temporal phases of facial actions[J].Systems,Man,and Cybernetics,Part B:Cybernetics,IEEE Transactions on,2012,42(1):28-43.
[15]Young J D,Santos Jr E.Introduction to temporal bayesian networks[ED/OL].http://www.cs.indiana.edu/event/maics96/Proceedings/ Young/maics-96.html,1996.
[16]Arroyo-Figueroa G,Suear L E.A temporal Bayesian network for diagnosis and prediction[A].Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence[C].Stockholm:Eprint Arxiv,1999.13-20.
[17]Shi Y,Huang Y,Minnen D,et al.Propagation networks for recognition of partially ordered sequential action[A].Proceedings of Conference on Computer Vision and Pattern Recognition[C].Atlanta,GA:IEEE Computer Society,2004.862-869.
[18]涂传飞.考虑时态信息的本体知识的不确定性推理研究[D].武汉:华中科技大学,2013.
[19]Allen J F.Maintaining knowledge about temporal intervals[J].Communications of the ACM,1983,26(11):832-843.
[20]Lucey P,Cohn J F,Kanade T,et al.The extended Cohn-Kanade Dataset (CK+):A complete dataset for action unit and emotion-specified expression[A].Proceedings of Conference on Computer Vision and Pattern Recognition Workshops[C].San Francisco,CA:IEEE Computer Society,2010.94-101.
[21]Pantic M,Valstar M,Rademaker R,et al.Web-based database for facial expression analysis[A].Proceedings of Conference on the Multimedia and Expo[C].Netherlands:IEEE Computer Society,2005.317-321.
[22]陈雄.基于序列特征的随机森林表情识别[D].成都:电子科技大学,2013.
[23]Zhong L,Liu Q,Yang P,et al.Learning active facial patches for expression analysis[A].Proceedings of Conference on Computer Vision and Pattern Recognition[C].Providence,RI:IEEE Computer Society,2012.2562-2569.
[24]Cheon Y,Kim D.A natural facial expression recognition using differential-AAM and k-NNS[A].Proceedings of International Symposium on Multimedia[C].Berkeley,CA:IEEE Computer Society,2008.220-227.
[25]Wang L,Qiao Y,Tang X.Motionlets:Mid-level 3D parts for human motion recognition[A].Proceedings of Conference on Computer Vision and Pattern Recognition[C].Portland,OR:IEEE Computer Society,2013.2674-2681.
[26]Zhao G,Pietikainen M.Dynamic texture recognition using local binary patterns with an application to facial expressions[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2007,29(6):915-928.
[27]Klaser A,Marszalek M.A spatio-temporal descriptor based on 3d-gradients[A].Proceedings of the the 19th British Machine Vision Conference[C].Leeds:British Machine Vision Association,2008.1-10.

邱玉女,1990年12月生于山东济宁,硕士研究生.研究方向:图像处理、模式识别.
E-mail:qiuyu1204@126.com

赵杰煜男,1965年11月生于浙江宁波,教授,博士生导师.研究方向:计算智能、模式识别、人机自然交互.
E-mail:zhao-jieyu @nbu.edu.cn
汪燕芳女,1989年1月生于安徽安庆,硕士研究生.研究方向:软件开发.
Facial Expression Recognition Using Temporal RelationsAmong Facial Movements
QIU Yu,ZHAO Jie-yu,WANG Yan-fang
(FacultyofElectricalEngineeringandComputerScience,NingboUniversity,Ningbo,Zhejiang315211,China)
Spatial and temporal relations between different facial muscles are very important in the facial expression recognition process.However,these implicit relations have not been widely used due to the limitation of the current models.In order to make full use of spatial and temporal information,we model the facial expression as a complex activity consisting of different facial events.Furthermore,we introduce a special Bayesian network to capture the temporal relations among facial events and develop the corresponding algorithm for facial expression modeling and recognition.We only use the features based on tracking results and this method does not require the peak frames,which can improve the speed of training and recognition.Experimental results on the benchmark databases CK+ and MMI show that the proposed method is feasible in facial expression recognition and considerably improves the recognition accuracy.
facial expression recognition;sequential facial events;Bayesian network;interval algebra
2014-08-08;修回日期:2015-05-17;责任编辑:梅志强
国家自然科学基金(No.61571247);科技部国际科技合作专项(No.2013DFG12810,No.2012BAF12B11);浙江省国际科技合作专项(No.2013C24027);浙江省自然科学基金(No.LZ16F030001)
TN391.4
A
0372-2112 (2016)06-1307-07
猜你喜欢
养生月刊(2022年8期)2022-11-25
小猕猴智力画刊(2022年3期)2022-03-28
法律方法(2021年4期)2021-03-16
铁道建筑技术(2020年11期)2020-05-22
电子制作(2017年13期)2017-12-15
黄河黄土黄种人(2017年4期)2017-04-26
小学生导刊(2017年21期)2017-02-25
铁道通信信号(2016年6期)2016-06-01
自动化学报(2016年5期)2016-04-16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
