
GPU加速技术在图论算法中的应用探讨
2016-08-12 02:15纪泽宇
中国新通信 2016年13期
关键词:最短路径
纪泽宇
【摘要】 对于图数据来说,其是当前很多学科的基础理论,特别是对于数学和计算机学科,如何实现图算法的计算效率是最主要的研究内容之一,伴随着算法的成熟,传统的图算法已经无法满足发展需要,为此,人们逐渐开始进行并行图算法的研究。但由于传统的CPU对数据处理受到限制,研究人员逐渐引进了新型的GPU运算处理器,其具有运算核心数量多和能力强等优点,随着对GPU研究的增多,GPU领域的图算法发展也得到了有效的提高。本文对当前的GPU加速技术在图论算法中的应用进行了简单的介绍。
【关键词】 CUDA 强连通分量 最小生成树 最短路径
随着信息时代的发展,数据总量也在逐渐增加,这使得人们对高性能的计算能力迫切需要,像基因序列的分析以及天气预报等,但传统的CPU单核计算已经无法满足人们工作的需要,为此,开发多核计算工具和并行算法是当前信息技术发展的重要需求。这种情况下,图算法作为图论的核心内容,逐渐被人们关注,其能够通过海量的图结构数据进行有效的分析,但由于其算法的不规则访存特性使其设计难度不断增加。为此,本文对如何实现图算法的加速进行了简单的介绍,通过GPU加速技术的应用能够使图算法的应用成为现实。
一、GPU同传统并行计算架构的区别
1.1 同多核CPU的区别研究
对于CPU,其应用目的对其体系是一种严重的限制,在CPU芯片上,大部分的电路都是用作逻辑控制或者缓存,这导致计算单元的晶体管数量非常少。通过大量的研究可以发现,对于GPU来说,其在应用的过程中,并行指令的数量非常少,但CPU却大部分采用的是长指令字等指令级的并行技术,这种技术使其架构和GPU之间存在着本质上的区别。此外,设计目的也存在着较大的差别,对于CPU,其主要是实现ALU指令的获取和执行,因此,逻辑控制电路等数量较大,但对于GPU来说,其主要是为了提高自身的计算能力,其更加注重的是对数据的吞吐效率,因此,对于逻辑控制设计相对较为简单。
1.2 同分布式集群的区别
对于GPU和集群之间的区别,其主要分为两个方面:首先是在计算方式上,对于集群,其采用的是主从模式,这种计算方式采用的是分割计算,通过Slave的计算和Master的集合和处理功能对数据进行计算。对于GPU来说,其通用计算和集群的模式相似,但GPU是Slave。然后是通信方式之间的区别,对于集群,其通信主要是通过局域网或者互联网等,这种算法在计算时需要对传输的细节进行重点的考虑,防止设计方面出现传输限制。而对于GPU芯片而言,其采用的是PCI-E接口进行数据等的传输,因此,其仅仅需要考虑的是如何对计算内容进行分配以及哪一部分的CPU具有什么样的特性等。
二、GPU加速计算有向图的强连通分量
对于有向图的强连通分量计算,其是图论中一个非常基本性的问题,像对复杂产品设计中的耦合任务集进行识别等。若将设计过程中所涉及到的各个人物看做是图的顶点,然后通过不同任务之间的关系能够建立一个有向图,而其中的耦合任务集的识别就变为了对途中的强连通分量进行寻找。在GPU加技术应用之后,设计了一个FB算法,其能够对非平凡图的强连通分量进行计算。
2.1 FB算法
对于FB算法,其在计算过程中不是依靠DFS为子的一种算法,而是通过分配模式将不同的子问题分配到各个单元中对其进行处理,而对于每个子问题,其都是通过顶点的可达性来进行分析,因此,FB算法具有较强的并行化能力。对于FB算法,其需要对下面两个引理进行重点的观察: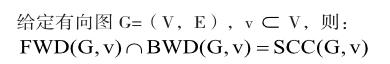
给定有向图G=(V,E),v?V,那么对于任何不包含v的强连通分量,其一定是FWD(G,v)BWD(G,v)和Rem(G,v)三个和集中的一个。
通过这两个理论可以得知,对于FB算法,其具体的计算过程是:首先选择一个顶点,然后对其前闭包和后闭包进行计算,两个集合之间的交集就是强连通分量值。然后通过剩余的顶点对原图进行3个子集的划分,并通过迭代计算对三个子图进行重复性的上述计算过程,这样就能够实现子图的并行处理计算。
2.2 基于CUDA的FB算法
首先是GPU中的图存储,对于当前的图算法,其采用的都是邻接表或者邻接矩阵,对于G=(V,E),其采用邻接表来对其进行表示,定义数组Adj代表|V|,其包含了满足(v,u)∈E的全部顶点,然后通过|V|×|V|来对矩阵进行表示,通过邻接表对无向图进行表示时,其大小为2|E|,而有向图的表达则是|E|。而采用邻接矩阵进行表示时,其空间需求都是O(V2)。而在通过GPU技术进行图数据的存储时,需要对下面几点内容进行考虑:首先,同现代的传统CPU主机系统相比,GPU的系统内存相对较小,然后是CUDA的模型,其采用的是一种CPU-GPU的异构模型,这种模型在进行数据的传输时同传统的计算机不同,最后则是对于CUDA的存储系统,其内存和主存两者之间选择不同的地址空间,因此,在进行指针数据的操作时较为困难,且设备的内存采用的是线性内存,这种存储方式更加适合数组形式的数据结构存取。
然后是算法的主体结构,对于FB算法,其SIMT架构也能够对顶点的闭包进行计算,通过迭代方式能够对非平凡的强连通分量进行计算,然后通过核函数起到时的线程分配来实现线程的计算和访存。
三、 GPU加速计算图的最小生成树
加入G的一个子图包含了G的全部顶点,那么就将其称为G的生成树。对于生成树中的各边权,将其综合定义为G的耗费,由于不同的子图生成的生成树具有不同的耗费,而其中耗费最小的就是最小生成树。下面对CUDA模式下的最小生成树进行了简单的介绍。
为了能够更好的对图的数据结构进行处理,同时节省存储空间,在对生成树进行计算时,往往采用的是两种图的数据结构,下面的(a)和(b)两种不同的结构构成了两种不同的计算方法,其中,(a)可以将所有的边都看做是没有方向的,然后通过(S,E,W)来对其进行表示,而对于(b)来说,其采用的是压缩邻接表而对方法,将每一条边看做是方向完全相反的两条边对其进行表示,采用的是(E,W)元组。而对于VP,其中存放的则是索引位置,而W数组的使用是为了对边的权值进行存储。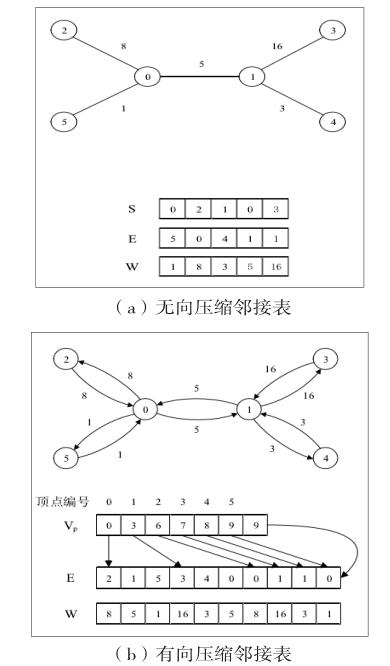
四、GPU加速计算图的最短路径
对于这一问题,其在当前的网络和物流等中应用非常频繁,而对于如何高效的选择最短路径一直是科学家关注和研究的热点问题。在本文中采用了一种基于CUDA的并行算法,其能够通过对SSSP算法进行多次的重复运行来实现边权值的非负APSP问题。下面对基于CUDA的SSSP算法进行了简单的介绍:为了能够实现这一算法,可以通过压缩邻接表对图中的数据结构进行计算,而在当前的CUDA编程中,采用的是CPU和GPU两种线程的同步运行,而通过开发multiprocer之间的同步,能够对全局线程进行有效的同步。为了实现APSP问题,可以通过在每一个顶点上运行上一节的SSSP算法来实现,这种并行方案能够对GPU的全局内存进行有效的利用。
五、总结
伴随着GPU计算能力的不断发展,其在各个领域中的应用和计算能力也将得到有效的提高,对比与传统的CPU和集群算法,GPU具有成本低和功耗少等优点,在未来的图论算法中,GPU加速技术应用将越来越广泛。
参 考 文 献
[1]王一同.GPU加速技术在图论算法中的应用[D].电子科技大学,2014.
[2]郭绍忠,王伟,周刚,胡艳.基于GPU的单源最短路径算法设计与实现[J].计算机工程,2012,02:42-44.
[3]郭绍忠,王伟,王磊.基于GPU的并行最小生成树算法的设计与实现[J].计算机应用研究,2011,05:1682-1684+1702.
猜你喜欢
科技创新导报(2016年25期)2017-03-13
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年23期)2016-11-02
电脑知识与技术(2016年18期)2016-11-02
物联网技术(2015年12期)2015-12-28
物联网技术(2015年11期)2015-11-26
哈尔滨理工大学学报(2015年2期)2015-07-22
物联网技术(2015年7期)2015-07-21
软件导刊(2015年4期)2015-04-30
