
基于自组合核的增量分类方法
2016-08-15 08:14吴振宇
系统工程与电子技术 2016年8期
冯 林, 张 晶, 吴振宇
(1. 大连理工大学电子信息与电气工程学部计算机科学与技术学院, 辽宁 大连 116024;2. 大连理工大学创新创业学院, 辽宁 大连 116024)
基于自组合核的增量分类方法
冯林1,2, 张晶1,2, 吴振宇2
(1. 大连理工大学电子信息与电气工程学部计算机科学与技术学院, 辽宁 大连 116024;2. 大连理工大学创新创业学院, 辽宁 大连 116024)
在线极端学习机(online sequential extreme learning machine,OSELM)模型在解决动态数据实时分类问题时,无需批量计算,仅保留前一时刻训练模型,根据当前时刻样本调整原有模型即可。然而,该增量方法在离线训练阶段随机指定隐层神经元使模型鲁棒性差,且求解过程难以拓展于核方法,降低了分类效果。针对上述问题,提出一种基于自组合核的在线极端学习机(self-compounding kernel online sequential extreme learning machine,SCK-OSELM)模型。首先,提出一种新的自组合核(self-compounding kernel,SCK)方法,构建样本不同核空间的非线性特征组合,该方法可被应用于其他监督核方法中。其次,以稀疏贝叶斯为理论基础将训练数据的先验分布作为模型权值引入,并利用超参调整权值后验分布,从而达到对当前时间点参数稀疏的目的。最后,将稀疏得到的参数并入下一时刻运算。对动态数据的实时分类实验表明,该方法是一种有效的增量学习算法。相比于OSELM,该方法在解决动态数据实时分类问题时获得更稳定、准确的分类效果。
动态数据; 在线极端学习机; 自组合核; 稀疏贝叶斯
0 引 言
在互联网时代,各个领域每一时刻均产生大量数据,如网络流量数据、金融交易数据、医学诊断数据、移动终端数据等。如何实时、准确地获得数据并更新已有知识,成为研究热点。模式分类是数据挖掘领域的重要分支,广泛应用于图像识别、故障排查、医疗检测等领域。上述应用中数据由时序动态更新,后续到来的数据对已有知识更新、补充。传统的模式分类模型需要对所有时刻累积的数据进行学习,该方法将耗费大量的时间与空间资源,并难以拓展于动态数据实时分类问题。因此,如何实时高效处理这些按时间序列动态到来的数据,同时保持训练速度与数据更新速度的平衡,成为亟待解决的问题。早在1962年,文献[1]就提出增量学习方法,该方法在保持对已有模型可追溯的基础上,直接对新数据进行学习,进而得到新的训练模型。研究者们将增量算法的研究重点放在算法的稳定性与可追溯性两个方面,本文的研究主要与第二点相关。
从算法稳定性方面,每批次到来的动态数据难以预测,其性态是不稳定的,称为非稳定环境(non-stationary environment,NSE)[1-2]。因此,可能出现数据分布改变甚至产生“概念漂移现象”。文献[3-4]对上述NSE现象进行了定义并对其漂移程度进行了评价。早期的研究均从如何发现该现象的产生以及如何保证算法的稳定性出发,这些方法普遍存在较高的时空复杂度。文献[5]较早提出时间窗识别概念漂移的方法,该方法将导致对之前时刻数据的遗忘,使学习效果降低。文献[6]通过自适应调节时间窗宽度保证对产生漂移的类别进行学习。文献[7-9]分别利用控制图、JIT分类器与信息论等方法解决该问题。集成分类算法在文献[10]中被用于解决动态数据增量分类问题。文献[11]提出Learning++算法,该方法为一种增量学习算法,可与各种监督学习分类器相组合,其主要思想是:对一批新到来的样本学习得到多个弱分类器后将其加权组合得到分类结果。该方法天生具有解决概念漂移的能力,通过弱分类器对已有数据类别空间记忆,后续一些学者对该方法进行了改进[12-13]。以上方法针对动态数据增量学习过程中产生的非渐进概念漂移检测有较好效果,当动态数据中出现渐进概念漂移时[14],上述方法为保证较小的空间复杂度,丢失了原有数据信息,增量学习能力被减弱。
在模型的可追溯性方面,文献[15-16]提出样本选择方法,通过保留之前的部分样本,当新数据到来时,结合保留的样本重新训练得到新的分类器。该方法由于保留了前序时间点的有用信息,有效提高了分类效果。单隐层前馈神经网络(single hidden layer neural network,SLNF)可通过学习连续函数达到任意精度的拟合效果,从而被应用于解决模式分类问题与增量学习方法。文献[17]提出自适应增量神经网络(self-organizing incremental neural network,SOINN),利用原样本与新样本近邻关系移除多余的样本,并利用两层神经网络训练得到分类器实现增量分类。该方法采用类内插入机制处理新来的样本,由于实现过程中用到过多参数,使得算法难以控制且非常复杂。为增强算法的稳定性,文献[18]对上述方法进行改进。SLNF虽然有诸多优点,但在求解过程中采用迭代方式,使得求解速度缓慢,且解容易陷入局部极小值。文献[19]提出极端学习机模型(extreme learning machine, ELM),将求解过程转化为简单的线性系统,可以任意指定输入层参数,且无需迭代调整。该方法不仅简化了求解过程,且不会陷入局部极小解,自提出以来被广泛应用于模式分类[20-21]与时间序列预测[22-23]等领域。为了推广算法的应用,文献[24-25]对ELM模型进行改进。
在对动态数据适应性方面,文献[26]在ELM基础上推导了增量学习模型。当新数据按照时间先后分批到来时,该方法无需对所有累积数据重新训练,仅训练新到来数据,调整分类模型即可。该方法是一种速度很快的增量学习算法,其改进算法在图像分类、预测等应用领域取得了很好效果[27-28]。在离线训练阶段采用ELM方法,通过最小化经验风险调整隐层结点。为避免过拟合,文献[29]引入结构风险,利用正则化参数平衡经验风险。文献[30]受LS-SVM算法启发,在ELM上进行推导得到LS-IELM算法,但该方法在不同应用背景下,仍存在隐层参数难以确定的问题,且随机指定的输入隐层参数无法保证算法的稳定性。文献[30]提出KB-IELM算法,在原有LS-IELM中引入核方法,避免了上述隐层参数选择等问题。文献[31-32]提出OS-ELMK方法和KOSELM方法。然而,上述方法中均存在两个问题:①复杂的推导与大量的矩阵运算,使得算法效率偏低;②算法需根据数据分布对核函数选择预判,当无法预先得知数据分布时,难以对核函数进行合适的选择从而降低分类效果。
针对上述问题,本文提出一种自组合核在线极端学习机模型(self-compounding kernels online sequential kernel extreme learning machine,SCK-OSELM)。首先,在每批动态数据到来的训练阶段将样本映射到不同核空间,并将其特征进行非线性融合得到核矩阵。之后,利用稀疏贝叶斯方法对其后验概率进行估计从而代替拟合数据的方法训练得到隐层输出权值,并对当前时刻参数进行稀疏以便于后续的增量学习。本文在3类数据集上验证了SCK-OSELM算法的有效性,存在以下优点:
(1) 该方法避免了人为选择隐层参数,增强了算法的鲁棒性。通过对当前时间点计算将参数进行稀疏,不仅保留了已有的判别信息,且降低了下一时刻的计算复杂度,实现了增量学习。
(2) 提出自组合核方法,实现了不同高维空间特征融合,同时避免了需根据样本分布选择核函数的问题。该方法可被拓展应用于其他监督的组合核方法中。
1 OSELM算法及本文算法思路
1.1OSELM算法回顾
ELM模型为SLNF的改进算法,避免了其求解速度慢,容易陷入局部极小值的问题,可描述如下:N个不同样本



(1)
式中,ξi=[ξi,1,…,ξi,m]T为训练误差向量。根据KKT理论,由拉格朗日乘子法有
(2)
式中,τ为拉格朗日乘子。此处g(xi)g(xj),可转化为K(xi,xj)=g(xi)g(xj)。式(2)可写为
(3)
式中,K(xi,xj)为ELM的核函数,可为径向基函数等任意核函数。
上述模型针对静态数据,采用批量分类方法。文献[26]提出了增量分类模型OSELM,其为ELM模型的在线求解方法,能快速处理在线分类问题。对ΔN(ΔN≥1)个新样本学习得到模型后与原有模型进行矩阵计算即可得到新的输出权值βN+ΔN。当ΔN个新样本到达时,隐层输出矩阵为
(4)
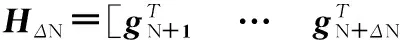
(5)
从而,可得到
(6)

(7)
结合式(6)和式(7),可得到输出权值的增量表达式为
(8)
由上述求解过程可知,新数据动态到来时,式(7)和式(8)仅需在原有模型基础上进行调整,即可实现增量学习。
1.2OSELM增量学习问题与本文思路
OSELM仅在当前时间点对已得到的分类器进行调整,无需对全部累积数据重新训练即可获得适应于新数据的分类器。该方法虽然在保证计算精度的前提下,提高了计算速度,但由式(5)可知矩阵需通过随机指定参数的方法获得,这种操作将产生较差的鲁棒性。同时,由式(3)可知核ELM难以直接拓展于式(7)和式(8)成为基于核方法的增量极端学习机,或需通过复杂矩阵计算将OSELM拓展成核方法。如文献[30-32]指出,该方法不仅计算复杂,且存在难以针对输入数据分布特点选择合适核函数的问题。
稀疏贝叶斯分类方法利用先验概率使部分参数值趋于0,这些参数对判别模型的影响较小,从而达到参数稀疏的目的。上述特性恰好可被用于增量模型中。本文受其启发,提出一种基于核的增量学习算法。通过保留当前时刻约减后参数,降低下一时刻计算复杂度。同时,为避免原始核映射方法对核函数选择人为干预问题,提出一种新的组合核方法SCK,该方法同时可被用于其他监督的核方法中。
SCK-OSELM可简述如下:首先,将输入样本映射到不同核空间,利用SCK方法获得高维特征的非线性融合;其次,利用稀疏贝叶斯方法对高维特征训练并保留在分类中贡献大的参数;最后,将之前得到的稀疏参数并入下一时刻与新样本共同训练。
算法原理如图1所示。图中红色结点为经过稀疏后得到的参数结点,同时加入到下一次的运算。该操作保持了之前训练模型可追溯性,降低了算法下一时刻计算复杂度。

图1 SCK-OSELM算法基本原理
2 SCK算法

(9)
式中,β为模型权值向量。
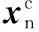
(10)
式中,ηc为权值,用于控制不同核函数的权值。对ηc的求解可根据监督算法,通过获得样本训练误差范数得到优化方程:
(11)

(12)
式中,p>1。该监督学习中,判别模型获得了多个不同核对学习过程产生的不同贡献。根据式(12),方程需求解一个非线性、非凸优化问题。根据优化理论,无法直接找到该问题的全局最优解,本文根据文献[33]中的交替优化形式,采用迭代求解方法,获得方程局部最优解。该方法通过交替更新tj与ηc值优化求解。首先,tj值被固定更新ηc值,利用拉格朗日乘子法,得到
式中,λ为拉格朗日乘子,通过求偏导,并使其变量值为0,可得到
式中,i=1,…,m。
经推导后可得到ηc的值为
(13)
求得当前ηc后,固定该值,交替迭代求解tj值。同时,由式(13)可知,p值可影响ηc。当p→∞时ηc值将彼此相近,p值的选取应获得所有互补的核空间。
3 增量分类
(14)
式中,g(·)为Sigmod激活函数,g[f(x;β)]=1+e-f(x;β),且f(x;β)=xβ。为避免模型训练过拟合,在稀疏贝叶斯学习中β的求解不直接利用最大似然估计求解,此处引入β的高斯先验分布对其约束:
(15)
式中,α为超参数,该参数最终决定了参数的稀疏性。由自相关性判定理论可知,先验概率会使神经元中影响较小的神经元对应的β值趋于0值。对于任意x对应的t均独立,得到以α为条件的边际似然函数:

在训练过程中通过最大化该似然函数求解α。为了简化求解过程,将式(14)和式(15)代入,有如下拉普拉斯近似:

(16)
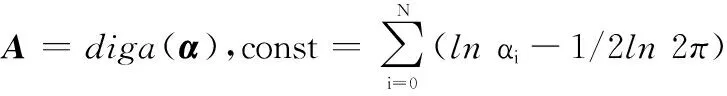
式中,B为N×N的对角矩阵,元素βi=fi(1-fi)且dg/df=g(1-g)。利用牛顿法可以求解β为
(17)

(18)
(19)
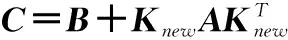
(20)

分类方法通过似然函数调整输出权值,使得部分权值为0,从而达到当前时刻参数稀疏的目的。SCK-OSELM算法的具体步骤如下,其中包含离线训练部分与在线训练部分:
(1) 离线训练部分
步骤 1随机初始化ηc为1/c,βi与αi为任意值,指定组合核函数(多个核函数,指定核函数参数)与最大迭代次数;
步骤 2计算输入离线样本的不同核矩阵与组合核矩阵;


(2) 在线训练部分
步骤 7计算输入在线样本的多个核矩阵与组合核矩阵;
步骤 9计算tj并计算更新后的ηc;
步骤 11如果在线数据到来结束则利用最终约减后的参数集训练得到分类模型,反之则转到步骤6继续训练。
4 实验结果与分析
4.1实验设置
实验运行在2.93GHzCPU,8GBRAM的PC上,计算平台为Matlab213a。为更加全面地评价本文提出算法的效果,选择3类数据集进行验证:12个UCI数据集、3组MNIst手写体数据集与一组手工数据集。

4.2数据集描述
UCI数据集被广泛用于验证分类算法效果的实验中,本文选择6个二分类、6个多分类数据集。数据集的具体描述见表1。本文设置增量算法的滑窗大小为训练样本数量的10%。
MNIst数据集为手写体图像数据集,其维度较高。在该数据集上进行了实验对比,验证了算法在高维度数据集上的效果。其包含10类60 000个样本,每个样本为28×28的灰度图像,图2为测试集示意图。为测试算法的稳定性本文随机选择3组样本进行实验,3组实验数据的具体描述被总结在表2中。

表1 UCI数据集描述

图2 MNIst数据测试集实例

实验训练集/每批次样本数测试集样本数实验1386/39193实验28660/8664330实验319500/19509730
增量学习中除了数据量的增加,同时面临不同类别样本分布非平衡的问题。本文利用手工数据集,对算法对类别敏感性进行了测试。该数据集包含5个类别,共1 000个样本,维度为2。该数据集的散点如图3所示,数据集的数据分布为单位面积均匀分布,但不同类别样本分布不同。实验中随机选择训练集样本为667,测试集样本为334。

图3 手工数据集散点图
4.3参数选择
本文所用核函数参数采用遍历的方式获得,Linear,Gaussian,Laplacian的参数选择为2γ,(γ∈{-2,-1,0,1,2}),polynomial的参数选择为γ(γ∈{1,2,3})。分别选择UCI数据集中的二分类数据集Heart与多分类数据集Iris对以上参数遍历选择。此时,固定p=2,且迭代次数为500。由图4可知,当为(2-2,2-2,20,3),(2-2,22,20,3)等参数时,两个数据集的分类准确率均较高,本文在后续试验中选择核函数参数为(2-2,2-2,20,3)。

图4 核函数参数选择
SCK-OSELM利用牛顿法求解似然方程。为保证算法收敛,本文采用平凡收敛条件,需对迭代次数进行设置。算法中p值的选择对分类效果有较大影响,此处选择p=2,p=5,后续本文将对不同p(p∈{2,3,4,5,6,7,8,9,10})值进行遍历并讨论分类效果。图5(a)和图5(b)所示分别为二分类UCI数据集Heart与多分类UCI数据集Iiris的分类效果,随着迭代次数的增加,曲线在迭代次数为200时趋于稳定。为确保算法收敛同时尽量减少算法运行时间,后续实验中设置迭代次数为200。
对比算法中的参数设置如下,OSELM与LS-IELM中,隐层神经元为Sigmod:(G(a,b,x)=1/(1+exp(-(ax+b)))),参数a在[-1,1]随机选取,b在[0,1]随机选取。参数a与b选取对算法分类效果有一定影响,本文实验均采用10次运算后取均值的方式。由文献[26]可知,OSELM中隐层神经元的选择对算法效果有严重影响,个数过多模型训练将产生过拟合,过少则模型训练不足。该参数的普遍选择方式是交叉验证或指定范围内遍历,本文中采用后一种方式,在[1,5,10,50,80,100,200,300, 400,500,800, 1 000]范围内遍历隐层结点。图6(a)为UCI二分类数据集中Heart和Cx1在不同隐层结点下的分类效果统计,图6(b)为UCI多分类数据集Iirs和PageBlocks在不同隐层结点下的分类效果统计(数据集详细描述见表1)。如图可见,随着隐层结点个数的上升,识别率随之提高,到200时趋于稳定,超过400后模型处于过拟合状态,分类准确率有所下降。由此,本文设置OSELM与LS-IELM中隐层结点个数为200。

图5 算法迭代次数设置
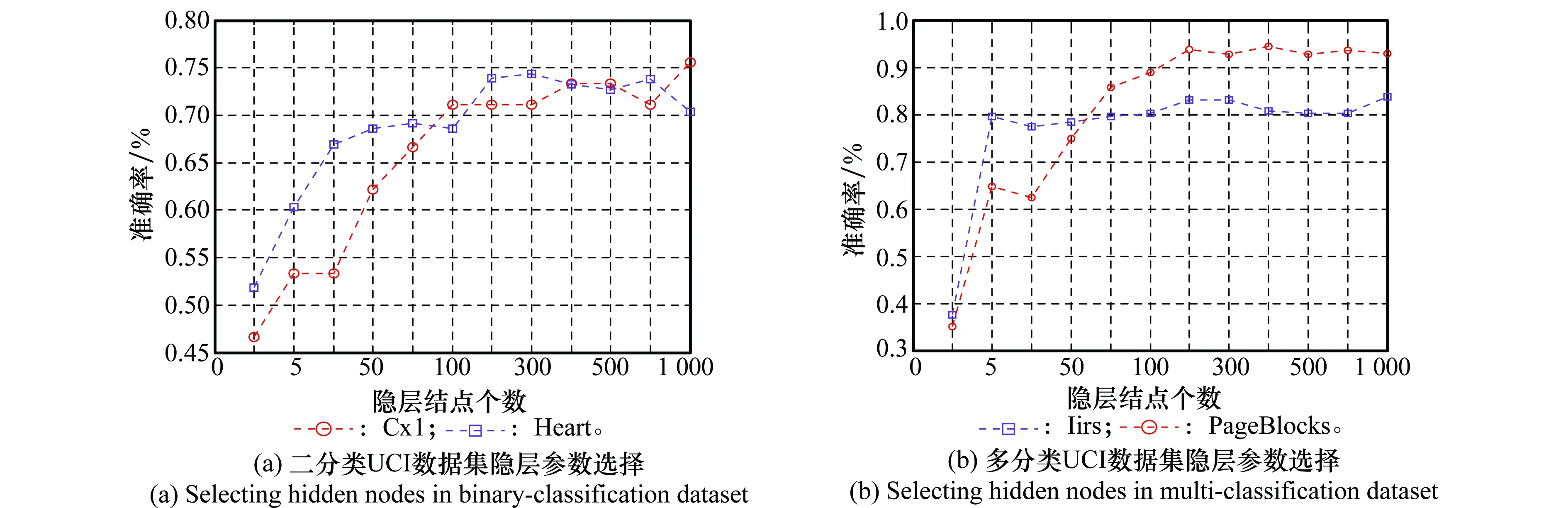
图6 OSELM隐层参数选择
4.4实验结果
4.4.1UCI数据集
表3给出在不同p值下所有UCI数据集的分类识别率。从表中可知不同数据集对应不同的p值获得的分类效果不同,例如,Segment数据集对应p=3时获得较高的分类效果,而Glass数据集中p=8,9时获得较高的分类效果。由本文第3.1节分析可知,p越大所有的组合核函数权值越为平均,算法对所有特征空间平均融合。在该组实验中多数数据集在p为2时效果较好,后续实验中本文选择p=2时的不同数据集实验效果对比。
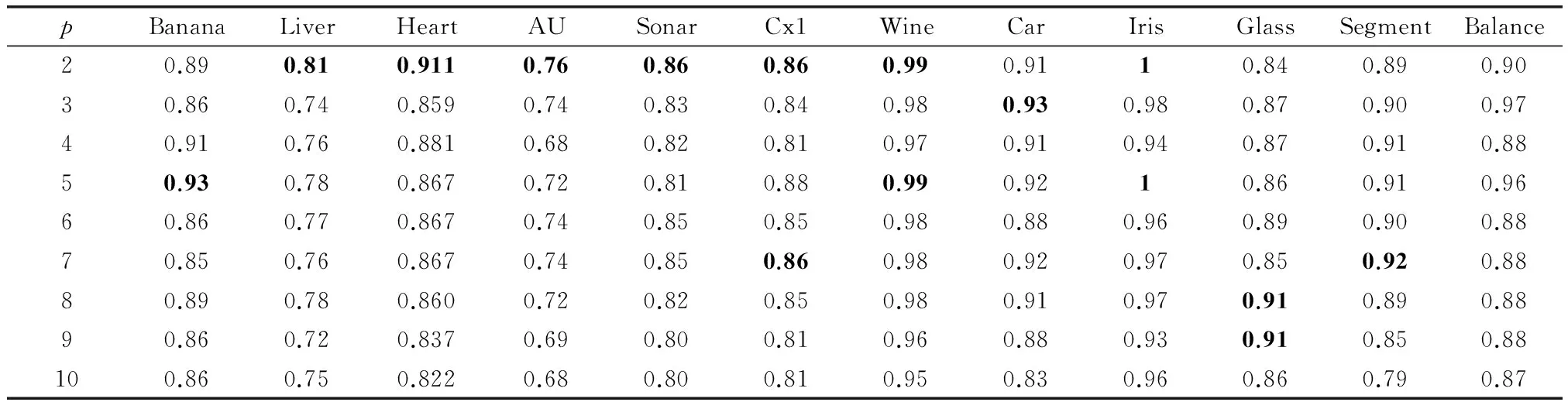
表3 不同p值时UCI数据集分类效果对比
为测试算法的增量学习能力与稳定性,图7给出了不同算法在UCI二分类数据集上的分类效果对比。从图中可看到随着数据量的增加,所有算法的分类准确率均有所上升,在大部分数据集上本文算法获得了较好的分类效果,在Banana与Au数据集上SKC-OSELM算法在初期样本量较少的情况下效果较差,但随着样本量的增加分类效果有所上升。从识别率曲线可见,对比算法,特别是OSELM算法曲线的波动较大,说明该算法对动态增量数据识别过程不稳定。
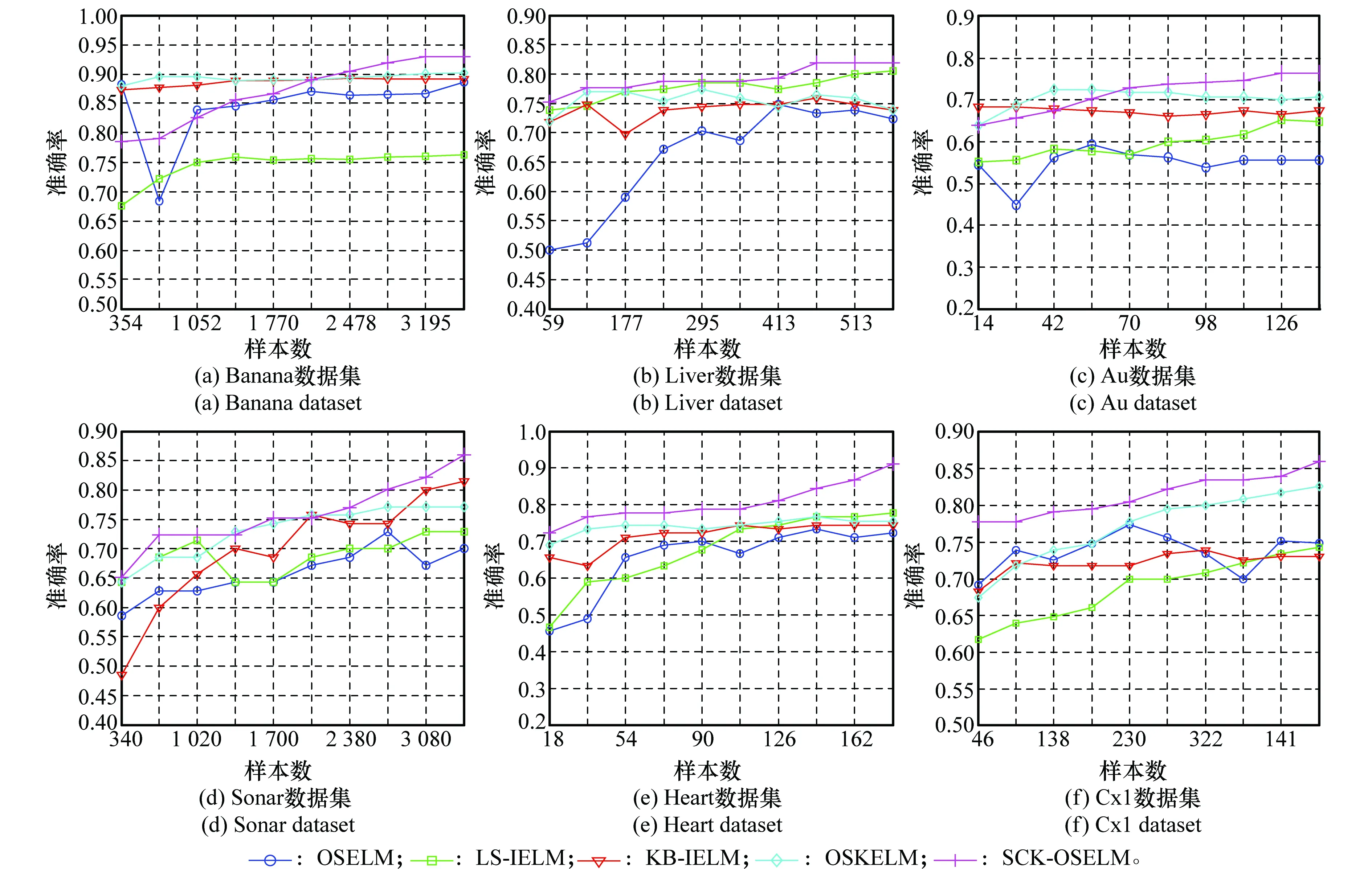
图7 UCI二分类数据集实验对比结果
图8为不同算法在UCI多分类数据集上的分类准确率对比曲线,由图可见本文算法在多数数据集上获得了较好的分类效果,且随数据量的增加平稳上升。本文算法在数据集Glass上表现不如单核方法,该类样本可能趋于单一分布,在多空间特征融合的情况下反而效果不佳。
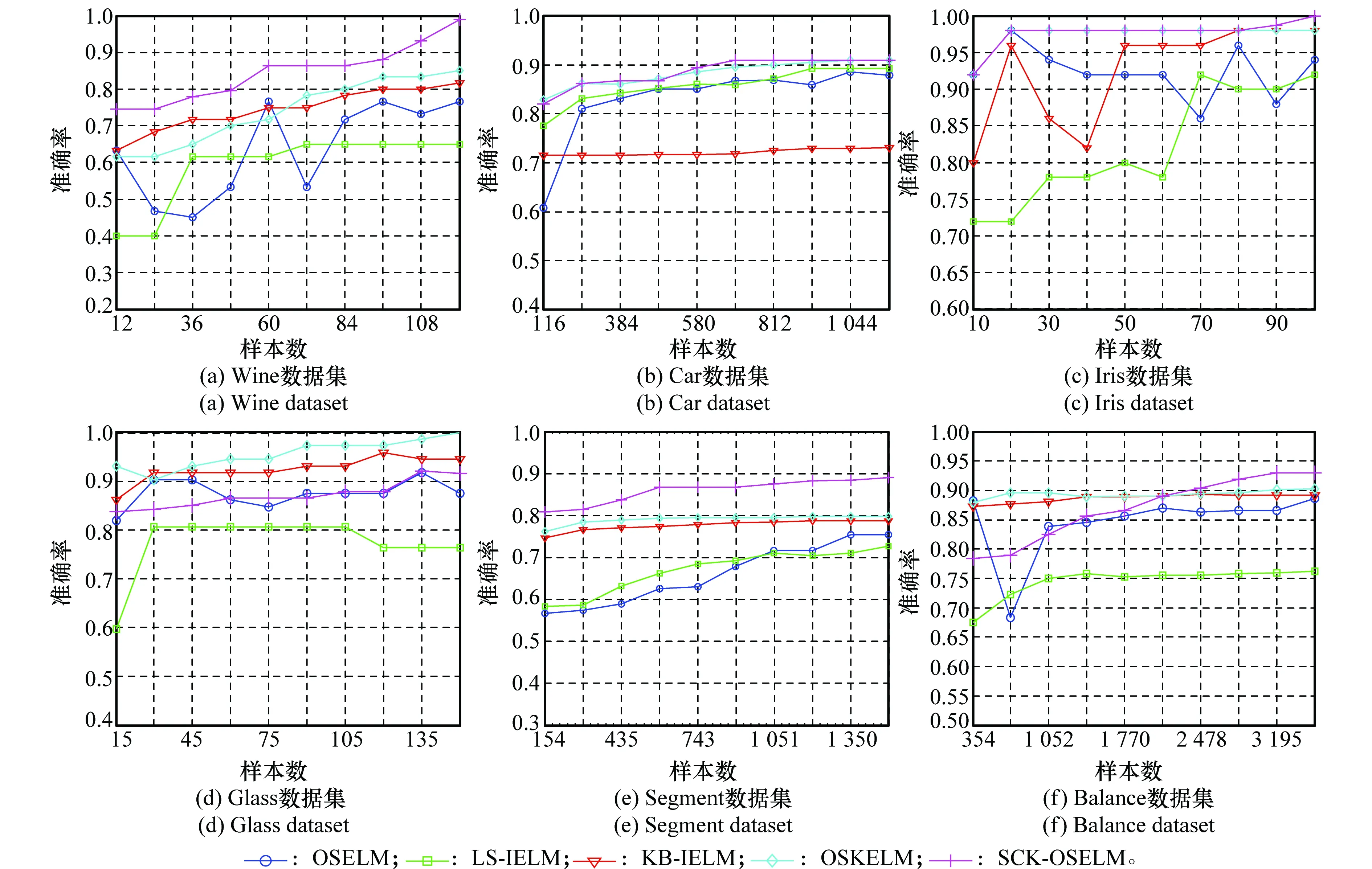
图8 UCI多分类数据集实验对比结果


表4 Iris数据集算法运行时间对比

表5 Banana数据集算法运行时间对比
4.4.2MNIst数据集
表6给出了针对MNIst数据集的第一组实验中随着p值的不同分类效果随之改变,当p=7时分类效果最好。对比实验中仍然选择p=2的结果对比,表7中统计了3组实验中4种算法分别运行10次分类准确率的均值与方差。由表可知,针对于3组实验数据,OSKELM的单核分类效果在实验1中优于其他算法,当样本数量增加时SCK-OSELM与OSKELM算法效果相当。SCK-OSELM在数据集维度较高且样本量较小时,效果不如单核算法。同时,由于SCK-OSELM、OSKELM与KB-IELM算法无需随机指定隐层参数,获得了较好的稳定性。

表6 不同p值时MNIst-test1数据集分类效果对比
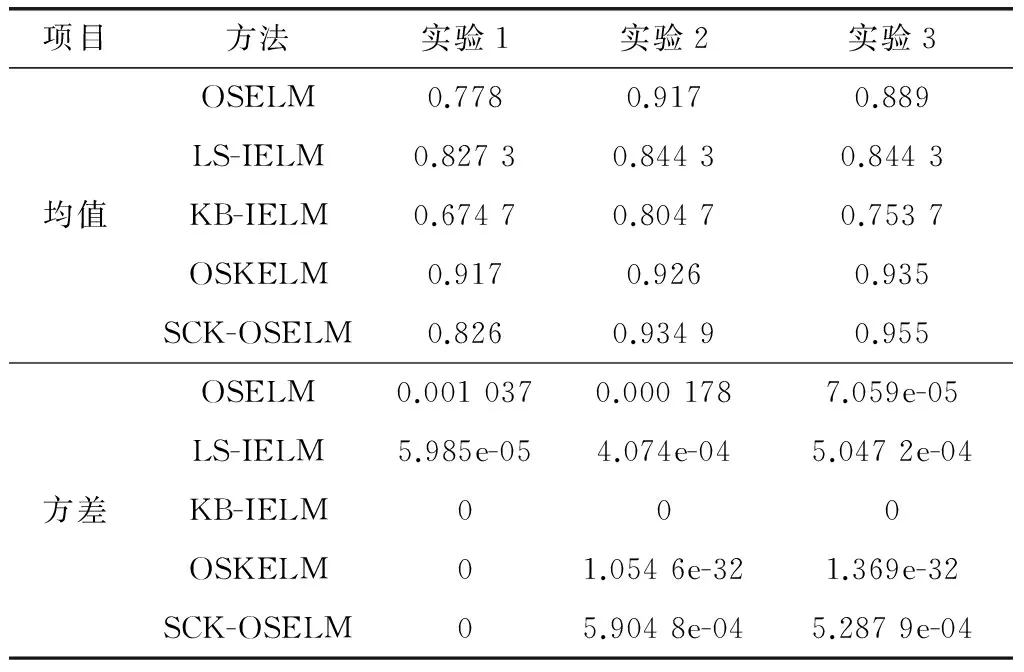
表7 MNIst数据集3组实验10次实验结果的均值与方差
4.4.3手工数据集
本文在手工数据集上对OSELM,OSKELM与SCK-OSELM的10次运行均值与方差进行了对比。从表8中可看到OSKELM与SCK-OSELM的方差为均较低,说明两种算法的稳定性远好于OSELM算法。同时,由表9可见无论p为何值,SCK-OSELM算法的分类效果在该类非均匀样本数据集中均高于其他两种算法。

表8 手工数据集10次实验结果均值与方差

表9 不同p值时手工数据集分类效果对比
5 结 论
实际应用中每一时刻涌入的动态数据量越来越多,增量学习成为学者研究的热点。本文针对有时间特性的增量数据分类问题,基于稀疏贝叶斯学习理论,提出了SCK-OSELM算法。首先,提出自组合方法对不同核空间特征进行融合,这种新的组合核方法可被拓展应用于其他监督学习中。同时,对未知标签数据输出的概率分布进行估计,自动使某些输出权值调整为0,达到参数稀疏的目的。由于每次增量学习的过程仅需要将上次稀疏后的参数加入本次计算,不仅使得原有分类模型具有可追溯性,且降低了算法的空间复杂度。在每一次单独计算中,利用最大化边缘似然函数代替最小化模型训练误差的方式,降低了模型的过拟合,提高了模型的泛化性。本文利用3组不同的数据集对模型的性能进行验证,取得了较好的效果。但在实际应用中无标签样本越来越多,如何对半监督的数据集进行有效的增量分类将成为一个值得研究的问题。
[1] Coppock H W, Freund J E. All-or-none versus incremental learning of errorless shock escapes by the rat[J].Science, 1962, 135(3500): 318-319.
[2] O′Reilly C, Gluhak A, Imran M A, et al. Anomaly detection in wireless sensor networks in a non-stationary environment[J].IEEECommunicationsSurveys&Tutorials,2014,16(3):1413-1432.
[3] Helmbold D P, Long P M. Tracking drifting concepts by minimizing disagreements[J].MachineLearning, 1994, 14(1): 27-45.
[4] Kuh A, Petsche T, Rivest R L. Learning time-varying concepts[C]∥Proc.oftheAdvancesinNeuralInformationProcessingSystems,1991: 183-189.
[5] Klinkenberg R, Renz I. Adaptive information filtering: learning drifting concepts[C]∥Proc.oftheAAAIWorkshoponLearningforTextCategorization,1998: 33-40.
[6] Widmer G, Kubat M. Learning in the presence of concept drift and hidden contexts[J].Machinelearning,1996, 23(1): 69-101.
[7] Hamker F H. Life-long learning cell structures—continuously learning without catastrophic interference[J].NeuralNetworks, 2001, 14(4): 551-573.
[8] Eslami S M A, Tarlow D, Kohli P, et al. Just-in-time learning for fast and flexible inference[C]∥Proc.oftheAdvancesinNeuralInformationProcessingSystems,2014: 154-162.
[9] Tsai C J, Lee C I, Yang W P. Mining decision rules on data streams in the presence of concept drifts[J].ExpertSystemswithApplications, 2009, 36(2): 1164-1178.
[10] Liu J C, Miao Q G, Cao Y. Ensemble one-class classifiers based on hybrid diversity generation and pruning[J].JournalofElectronics&InformationTechnology, 2015, 37(2):386-393.(刘家辰, 苗启广, 曹莹. 基于混合多样性生成与修剪的集成单类分类算法[J]. 电子与信息学报,2015, 37(2): 386-393.)
[11] Polikar R, Upda L, Upda S S, et al. Learn++: an incremental learning algorithm for supervised neural networks[J].IEEETrans.onSystems,Man,andCybernetics,PartC:ApplicationsandReviews, 2001, 31(4): 497-508.
[12] Zheng F, Shao L, Brownjohn J, et al. Learn++ for robust object tracking[C]∥Proc.oftheBritishMachineVisionConference, 2014: 1342-1346.
[13] Chen B, Meng B. Power transformer fault diagnosis system based on learn++[C]∥Proc.oftheAppliedMechanicsandMaterials,2014: 2053-2056.
[14] Ditzler G, Polikar R. Incremental learning of concept drift from streaming imbalanced data[J].IEEETrans.onKnowledgeandDataEngineering, 2013, 25(10): 2283-2301.
[15] Maloof M A, Michalski R S. Incremental learning with partial instance memory[J].ArtificialIntelligence, 2004, 154(1): 95-126.
[16] Klinkenberg R. Learning drifting concepts: example selection vs. example weighting[J].IntelligentDataAnalysis, 2004,8(3): 281-300.
[17] Furao S, Hasegawa O. An incremental network for on-line unsupervised classification and topology learning[J].NeuralNetworks, 2006, 19(1): 90-106.
[18] Friedman J, Hastie T, Tibshirani R.Theelementsofstatisticallearning[M]. Berlin:Springer, 2001:605-624.
[19] Huang G B. An insight into extreme learning machines: random neurons, random features and kernels[J].CognitiveComputation, 2014, 6(3): 376-390.
[20] Zhang J, Feng L, Wang L. Real-time big data classification under mapreduce[J].JournalofComputer-AidedDesign&ComputerGraphics, 2014, 26(8): 1263-1271. (张晶, 冯林, 王乐. MapReduce 框架下的实时大数据图像分类[J]. 计算机辅助设计与图形学学报, 2014, 26(8): 1263-1271.)
[21] Liu X, Wang L, Huang G B, et al. Multiple kernel extreme lear-ning machine[J].Neurocomputing, 2015(149): 253-264.
[22] Wong P K, Wong H C, Vong C M, et al. Model predictive engine air-ratio control using online sequential extreme learning machine[J].NeuralComputingandApplications, 2014: 1-14.
[23] Wong P K, Vong C M, Gao X H, et al. Adaptive control using fully online sequential-extreme learning machine and a case study on engine air-fuel ratio regulation[J].MathematicalProblemsinEngineering, 2014.DOI: 10.1155/2014/246964.
[24] Horata P, Chiewchanwattana S, Sunat K. Robust extreme learning machine[J].Neurocomputing, 2013(102): 31-44.
[25] Zong W, Huang G B, Chen Y. Weighted extreme learning machine for imbalance learning[J].Neurocomputing, 2013(101): 229-242.
[26] Liang N Y, Huang G B, Saratchandran P, et al. A fast and accurate online sequential learning algorithm for feedforward networks[J].IEEETrans.onNeuralNetworks, 2006, 17(6): 1411-1423.
[27] Yin J C, Zou Z J, Xu F, et al. Online ship roll motion prediction based on grey sequential extreme learning machine[J].Neurocomputing, 2014(129): 168-174.
[28] Zou H, Jiang H, Lu X, et al. An online sequential extreme learning machine approach to WiFi based indoor positioning[C]∥Proc.oftheIEEEWorldonForumInternetofThings, 2014: 111-116.
[29] Deng W, Zheng Q, Chen L. Regularized extreme learning machine[C]∥Proc.oftheIEEESymposiumonComputationalIntelligenceandDataMining, 2009: 389-395.
[30] Guo L, Hao J, Liu M. An incremental extreme learning machine for online sequential learning problems[J].Neurocomputing, 2014(128): 50-58.
[31] Wang X, Han M. Online sequential extreme learning machine with kernels for nonstationary time series prediction[J].Neurocomputing, 2014(145): 90-97.
[32] Scardapane S, Comminiello D, Scarpiniti M, et al. Online sequential extreme learning machine with kernels[J].IEEETrans.onNeuralNetworksandLearningSystems, 2015, 26(9): 2214-2220.
[33] Bezdek J C, Hathaway R J.Somenotesonalternatingoptimization[M]. Heidelberg: Berlin, 2002: 288-300.
Incremental classification based on self-compounding kernel
FENG Lin1,2, ZHANG Jing1, WU Zhen-yu2
(1. School of Computer Science and Technology, Faculty of Electronic Information and Electrical Engineering, Dalian University of Technology, Dalian 116024, China; 2. School of Innovation Experiment, Dalian University of Technology, Dalian 116024, China)
Online sequential kernel extreme learning machine (OSELM) is an increment classification algorithm, and it only keeps training model at last time, then adjusts the original model from the current samples. However, it does not batch calculation when solving the problem of real-time dynamic data classification. This method by minimizing the empirical risk leads to the over-fitting, and randomly assigns hidden layer neurons in offline training, which makes the model have poor robust. Moreover, the solving process is difficult to be extended to the kernel method, which reduces the classification accuracy. Pointing to above-mentioned problems, a new online classification method, self-compounding kernels OSELM (SCK-OSELM), is proposed based on the kernel method. Firstly, inputted samples are mapped to multi-kernel spaces to obtain different features, and the nonlinear combination of features are calculated. Proposed self-compounding kernels method is used to others supervised kernel methods. Secondly, the prior distribution of training samples as model weights are introduced to maintain the model generalization, and by using the super weight to make the posterior distribution of weights to zero, thus sparse parameter is achieved. Finally, the parameter of sparse are incorporated into the next moment common operations. Numerical experiments indicate that the proposed method is effective.In comparison with OSELM, the proposed method has better performance in the sense of stability and classification accuracy, and is suitable for real-time dynamic data classification.
dynamic data; online sequential extreme learning machine; self-compounding kernel; sparse Bayesian
2015-10-26;
2016-03-16;网络优先出版日期:2016-07-06。
国家自然科学基金(61173163,61370200)资助课题
TP 319
A
10.3969/j.issn.1001-506X.2016.08.36
冯林(1969-),男,教授,博士,主要研究方向为智能图像处理、机器学习、数据挖掘。
E-mail:fenglin@dlut.edu.cn
张晶(1984-),女,博士研究生,主要研究方向为数据挖掘、机器学习、计算机视觉。
E-mail:zhangjing_0412@mail.dlut.edu.cn
吴振宇(1971-),男,副教授,博士,主要研究方向为嵌入式系统应用、工业电源及传感器。
E-mail: zhenyuwu@dlut.edu.cn
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20160706.1030.004.html
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·中考版(2019年9期)2019-11-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
