
关系概念的Web资源语义标识模型研究*
2016-08-31 09:06程春雷夏家莉江西财经大学信息管理学院南昌330032江西中医药大学计算机学院南昌330004
计算机与生活 2016年8期
程春雷,夏家莉.江西财经大学 信息管理学院,南昌 330032 2.江西中医药大学 计算机学院,南昌 330004
关系概念的Web资源语义标识模型研究*
程春雷1,2+,夏家莉1
1.江西财经大学 信息管理学院,南昌 330032 2.江西中医药大学 计算机学院,南昌 330004
CHENG Chunlei,XIA Jiali.Research on semantic annotation model of Web resources based on relational concept.Journal of Frontiers of Computer Science and Technology,2016,10(8):1092-1103.
摘要:Web环境下资源内容丰富,形式多样,描述标准不一,组织结构离散,既有标识方法存在语义单一,缺乏领域知识背景或人工参与度大等问题,限制了它们在个性化资源推荐和获取中的应用效果。基于关系概念的激活扩散以及资源分层语义标识的思想,面向Web资源构建了关系概念语义标识模型(relational concept annotation model,RCAM)。RCAM模拟人类记忆激活扩散过程,考虑记忆的加强与遗忘机制,由此实现资源更为动态、个性化的关联组织。RCAM中资源标识以关系概念作为语义要素,以片段关系概念集为语义模式,标识粒度灵活,语义逻辑相对完整,为Web资源标识组织提供了新的研究思路。实验表明,RCAM能提供更多的领域知识背景,可适应不同学习情景、学习个性下的资源动态组织,并且针对开放的Web资源,具有更好的通用性、扩展性。
关键词:网络资源标识;关系概念;激活扩散;关系概念标识模型(RCAM)
1 引言
随着用户主导的Web2.0相关技术的发展以及数字化教育的持续推进,Web上各类资源的存量巨大,内容丰富,增长迅速,特别是“互联网+”技术在社会生活中的广泛应用,各种辅助学习方式也在技术变革中悄然发展,终端学习者对资源的获取、贡献与影响会越来越直接,由此必将进一步推动和强化资源的建设与开放。所有这些都对资源的有效获取提出了更高的要求,但同时,巨量的资源处在开放、动态和多变的Internet环境下,位置分布,形式多样,描述标准不一,针对特定学习目的,学习者往往较难实现有效的资源检索与筛选。如何利用信息技术实现资源语义层面的自动标识,关联整合不同组织、不同形式的资源数据,实现更为有效的资源组织和共享具有十分重要的理论研究和实用价值。
近年来随着生物科学在细胞微观领域的研究进展,认知心理学家提出了人类记忆基于激活扩散、抑制遗忘的认知过程的假设[1]。该假设较好地解释了人类众多的认知现象[1],该认知过程应用于计算机领域的资源标识,与其他计算机领域成熟的标识、组织模型相比,其最大优势表现为模型的自组织性、模糊动态性等特点,与人类认知方式更为接近,方便用户认知理解,针对开放的Web资源标识,具有更好的扩展性。基于以上特点,本文借助前期Web协作知识库的关系概念研究[2],得到资源文本片段的主题集合。每个资源片段主题包括资源连通关系概念和外延关键词,语义标识既考虑关系概念外延词条的精确语义,也考虑语义相对完整、复合的片段级语义,采用这些既存的领域关系概念背景对资源片段进行基础性模式标注,从而就资源片段文本的主题模式进行形式化构建与扩展。通过构建可扩散激活、遗忘衰减的资源语义标识模型,可为学习者更好获得资源以及资源转向提供动态模型能力支持。
2 相关工作
资源的标识也称为资源的元数据,元数据作为一种有效的信息资源组织和管理工具,它不仅为信息对象提供描述信息,还具有定位、检索、关联和选择等功能。国内外已经具有相对完备的元数据标识规范,如Dublin Core元数据规范[3]、《教育资源建设技术规范》(CELTS-41)等。但由于Web资源开放性的特点,采用手工或半手工元数据标识工作量是难以想象的,由此限制了元数据规范在既有开放资源标识中的使用效果。
向量空间模型(vector space model,VSM)于20世纪70年代由Salton等人提出[4],成功地应用于著名的SMART文本检索系统。该模型将一文本使用离散的词条向量来表达,词条在模型中假定为相互独立。经典的VSM为其他相关模型提供了思想基础,但针对资源的语义标识,单纯的VSM模型还具有很大的局限性。资源描述框架模型(resource description framework,RDF)[5]对资源进行统一的描述,其以类似“主—谓—客”的三元组结构描述资源。但词汇的含义、词汇之间的关系,RDF模型并没有刻画。为此其扩展模型RDFS(RDF schema)定义了一组标准类及属性的层次关系词汇,但RDFS不能描述词与词间的关系,难以适应资源个性化推荐中深层次的语义标识与组织的要求。主题图标识可追溯到20世纪90年代初[6],初衷是希望建立一个具有智能性的索引来帮助用户组织和获取电子文档资源。一个主题图包含主题(topic)、资源出处(occurrences)以及关联(association)等特征。其很好地描述了知识之间的关系与资源的位置,但需要领域专家的深度参与,存在主题及其关系自动获取困难等问题。本体思想也能较好地刻画资源的语义主题[7-8],但采用本体标识组织资源,需要预先构建此目标下的领域本体,本体推理过程基于一阶逻辑推理框架,推理规则的构建较为繁杂和严格,另外如何对本体质量进行有效评价也是一个难题。统计主题模型的基本思想是把文档表示成多个隐含主题的概率分布,主题本身看成词项集的概率分布,如LSI(latent semantic indexing)、pLSI (probabilistic LSI)、LDA(latent Dirichlet allocation)等模型[9-10],这些方法取得了较好的使用效果。但在开放环境下主题数量确定困难,计算量较大,在很多情况下,部分主题表达与人的理解会产生较大的偏差,难于满足面向用户的领域主题特征的描述、主题跳转等需要。
3 资源语义模型的建立
经典的形式背景为三元组K=(G,M,I)[11],其中G表示对象词条,M表示值标注词条,I取值为0或1,表示G是否具有M属性。为了增强在开放域概念与关系的综合表达能力,对传统形式背景进行扩展,提出了关系形式背景K=(G,M,RI)[2,12],其中G为词条对象的集合,M为标注关系取值的词条集合,RI表示标注关系。例如三元组(蜗鸢,脊索动物门,门)∈K,蜗鸢∈G,脊索动物门∈M,门∈RI,表示“蜗鸢”与“脊索动物门”具有“门”的关系。并在此基础上提出了关系概念模型(定义与运算)[2,12],关系概念包括主体概念与客体概念,如类似上例可构建主体概念<{门},{蜗鸢,棕噪鹛,…}>,该二元组分量分别表示主体概刺胞动物门,念的内涵与外延对象,<{门},{脊索动物门,…}>,为客体概念的内涵与外延对象。二元关系概念看成主体概念和客体概念一样的特殊关系概念,如<{鸟类},{蜗鸢,秃鹫,…}>。关系概念的内涵均为标识关系RI,外延为关系中出现的所有被标识主体词条G或客体词条M。
在前期研究[2,12]中,基于百度百科丰富的形式背景(主要来自词条条目与标注数据)与关系概念模型的紧密结合,对文本中的关键词所属关系概念进行识别,并采用图论中连通的思想,获取文本的关系概念的连通主题,即文本主题采用一个关系概念向量表达,向量元素按概念相关度降序排列,并保留主题关系概念对应的主要原始词条。例如某文本的关系概念向量Example1:(<社会,1.000 000>,<法律, 0.522 495>,<国家,0.230 513>,<法律术语,0.127 628>,<动漫形象,0.078 680>),及其对应的原始文本词条:(法律地位,外务部,会谈,原则,居住权,外国人,制度),上文关系概念相关度由原始文本词条与对应关系概念连通计算所得[2]。本文以上述关系概念与主题向量为标识基础,构建模拟人类记忆的资源标识模型。由于模型标识最终目的是为学习者服务,该模型模拟激活增强、抑制衰减两个对立统一的认知过程,不仅要实现资源的语义层次的标识组织,也要为后续学习者的资源演化与资源转向提供动态能力支持,具体如下文所述。
3.1资源标识模型构建
定义1(资源主题模式)资源片段的主题模式定义为四元组SM=(CT,SIMI,WS,DS),其中CT代表关系概念集[12],SIMI为与CT一一对应的归一化的关系概念相关度[12],WS为资源片段中CT对应的主要关键词集,DS代表具有该主题模式的文档id集。其中资源片段可以是文本章节段落,CT、SIMI、WS示例见上文Example1。
资源片段在逻辑或语义上相对完整独立,其对应的主题模式SM,是多个关系概念CT联合表达的语义单元,同时SM也保留了关系概念对应的重要外延词条信息。以多个关系概念作为片段的语义标识,使学习者通过CT可以了解片段的语义概念信息,也可获知WS中核心词条对应的精确语义。SM模型的主题特征组织构成,与人类基于局部词条特征和上下文概念语境[13]的并行阅读方式接近,结合人的短时注意力特点,CT、WS一般保留7±2个元素特征。
不同资源片段主题间存在语义上的关联,体现为主题模式内的关系概念之间存在更细粒度的概念联系,这种联系是片段主题的关联基础。为此首先定义了知识激活扩散连接模型KALN,用以描述领域知识概念之间的关系。
定义2(知识关联连接模型KALN)KALN定义为四元组KALN=(CT,KL,KD,KW),其中CT为领域关系概念,关联集KL⊆CT×CT,KD(kl)表示关联边kl的语义距离,KW(kl)表示kl的连接强度,kl⊆KL。
KALN中的KD反映了关系概念间的关系内涵或外延的重叠程度,由类似百度百科的关系形式概念背景获得,来源于人工协作语义标识,语义相对固定,距离越近越易联想,如三角形→等腰三角形。同时KW则反映了关系概念在特定领域频繁同时激活的强度信息,是特定学习情景下相关概念组合出现的度量,其相对动态,强度越大,也更易联想。如同人类在认知过程中,在特定场合频繁共现的强度也能激发人类情景下的联想,如几何中的三角形→面积。距离与强度是关系的两个不同方面,如同学生由于教育差异,具有不同的认知偏好和思维方式(对应不同的概念连接强度),但学科的基本知识框架还是类同的(对应类似的概念语义距离)。
在人脑中,弥散的四通八达神经网络为任意两个概念提供了关联与学习的可能[1],为一无所知的婴儿成长为头脑复杂的成人提供了物理通道基础。本文借鉴该弥散无序的思想,并且考虑领域概念获取背景的局限性,假设任意两个关系概念通过一定的距离都是连通的,如果语义距离小于间接连通的距离,则KALN关系概念间存在连接边。下面结合该思路,进行KALN基本模型的初始化,具体构建步骤如下。
(1)计算关联任意两个关系概念cti、ctj的可能边klij的距离kdij,kdij=1/emax(cti,ctj),其中emax(cti,ctj)为最大的关系概念相关度。关系概念相关度是一种偏序关系的度量,即emax(cti,ctj)=max(e(cti,ctj),e(ctj,cti))。关系概念相关度定义见文献[2,12],其基本思想就是关系概念间的外延或内涵的集合重叠程度,取值范围[0,1]。概念相关度emax(cti,ctj)∈[0,1],由此可知距离kdij取值最大为+∞,最小为1;当i=j时,emax(cti,ctj)=1,则kdij=1。
(2)通过式(1)初始化KALN连接强度kwij。

(3)重复步骤(1)、(2),直至所有的kdij、kwij计算完成,KALN初始化完成,具体见算法1。
KALN为资源片段之间的主题关联计算,提供了相对固定的基本语义与结构支持。为了对离散的SM进行管理与资源标识,下面构建了资源激活关联连接模型。
定义3(资源关联连接模型SALN)SALN可表示成三元组SALN=(SM,SL,SW),其中SM表示资源主题模式集,见定义1,关联SL⊆SM×SM,SW(sl)表示sl的关联权值,sl∈SL。
资源关联连接模型的构建基于以下思想:如果资源主题模式SM包括的关系概念间在KALN中存在紧密的语义关联时,则资源模式间也存在较强的领域关联。资源主题模式sm1、sm2间的关联强度计算如式(2)所示。
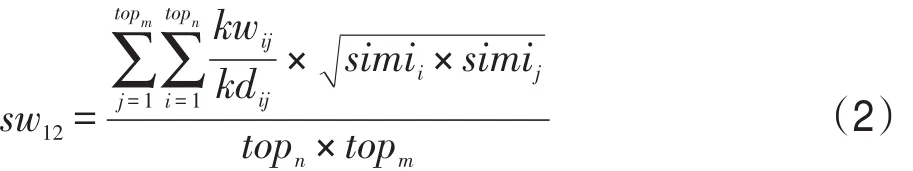
其中,kwij、kdij分别代表KALN中关系概念cti与ctj之间的关联强度与连通距离,见定义2;topn、topm分别代表sm1、sm2中的关系概念数目,simii、simij则代表关系概念cti与ctj隶属于sm1与sm2的程度,见定义1。SALN构建步骤如下。
(1)根据KALN邻接矩阵M,M只保留主题模式sm1中关系概念对应的行,以及sm2中关系概念对应的列,得到当前的KALN子集矩阵M′topn×topm,M′矩阵元素值为资源片段在当前关系概念上的关联程度。
(2)针对矩阵M′的j列,计算表达式(3)。

(3)使用表达式(3)分别计算sw12。

通过以上步骤进行SALN的构建,建立资源间的联系。sw12较大则代表主题模式1、2间领域相关程度较高。如果sw12≥θ1,并且满足表达式(5),表示主题模式1、2间雷同,则进行合并。
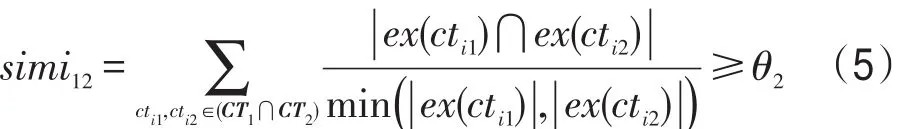
其中,CT1、CT2表示两个主题模式的主题向量;cti1、cti2表示向量中的公共关系概念;ex(cti1)、ex(cti2)表示公共关系概念的词条外延集;θ2代表相似度阈值;simi12代表两个片段主题模式之间的Jaccard相关系数,表示关系概念精确外延词条交集占比。雷同的主题模式需对共同的关系概念进行合并操作,合并后的关系概念不变,关系概念相关度的更新见表达式(6)。

其中,simi1i、simi2i表示主题模式1、2中合并前第i个公共关系概念的概念相关度。通过合并操作,可以增强一些重要的关系概念,相对也抑制了主题模式中的次要、噪音语义,为后续资源标识组织提供更为精简的主题模式集。
KALN与SALN从语义的两个不同层次,对资源进行了标识,KALN表达了知识语义级的关联,SALN则综合了语义与领域两个层面的关联。KALN、SALN子图区域的变化,可反映学习者的学习历史与兴趣迁移轨迹,可以通过它们局部激活强度和覆盖程度,从一定程度反映潜在资源推送需求,为后续资源推荐提供更多的上下文背景,为学习者提供更为准确、多样的资源。
3.2资源标识模型的扩展
资源的标识组织,最终要为用户服务,其组织形式及变化扩展应该考虑或遵循人类的认知变化规律。即KALN、SALN不是一成不变的,应该反映开放资源本身及学习者个性的演化,并可以进行自组织调整,例如不断加入新资源,学习者的兴趣偏好、学习历史、认知路径变化等。为了增加资源语义模型的自适应性,下面借鉴人类记忆扩散过程对其进行扩展,使资源的语义标识不仅反映资源内容本身,也为个性化的资源需求提供模型能力支持。例如KALN中原始的关系概念“电气”与“磁场”,由于这两个关系概念外延词条交集不大,其初始语义关联并不强,但如果学习者正在学习电磁学,则它们会在资源中频繁共现,并且在该领域关联强度应该较强,而随着学习者学习内容的偏移,它们之间的关联又会慢慢衰减。该变化过程如同人类记忆增强与衰减过程,可以体现学习状态或资源内容的变化,具有自组织、模糊性的特点。
同时基本的KALN、SALN的核心均为从关系形式背景中获得关系概念,而单纯通过协作知识库(如百度百科)获取的关系语义完整性还有一定的局限。考虑到资源主题模式对应于实际存在的资源片段,这些资源片段的语义是通过关系概念展现的,关系概念在每个资源片段的共同出现,都可看成关系概念间的一次领域激活,由此动态调整KALN中关系概念间连接强度值KW,使KALN通过更广泛的资源内容协作,关联语义反映领域知识实际组织情况。下面首先对知识关联连接模型KALN进行扩展。
3.2.1KALN基于多概念的同步激活与衰减
KALN=(CT,KL,KD,KW),包括关系概念及其之间的连通距离与连接强度。连通距离KD反映它们之间的关系概念关联程度,相对固定,其更新变化不在本文讨论范围之内。KW这个连接强度在不同的学习情景中,则是相对动态的。例如ct1、ct2之间在特定环境中(如某类资源或某类学习中)出现次数越频繁,那么ct1、ct2之间的关联激活应该更活跃、容易,反之,它们之间的激活就会慢慢衰减、困难。
如同人类认知过程中,记忆增强与衰减是对立统一的,有增强没有衰减,记忆必将达到生理认知的极限,强度必将在注意力面前失去意义。领域专家的知识组织与记忆也遵循这个规律,其可以根据变化的学习环境,为学习者提供适宜的领域知识服务与指导。同理KALN如果一成不变或只增不减,也很难突出知识服务本身的时空动态性。
通过研究,认知学家针对神经通道强度提出了以下4个假设[1]:(1)每一次激发产生与神经通道成正比的强度增量;(2)激发次数越多,增量越大;(3)神经通道会因为新陈代谢或大脑其他部分的工作,产生消退或抑制而衰减;(4)神经通道强度越强,越容易激发。借鉴认知学家的以上理论,基于假设(1)~ (3),KALN中的KW变化,满足微分方程(7)[1],KW在连接强度值方程中简单记为w。

其中,f代表激发频次;ξw代表强度可调系数;η代表衰减可调系数;t代表KALN激活时序。根据假设(4)[1],可得:

其中,ξf为激发频次可调系数。
通过对微分方程(7)、(8)求解,可以得到KALN中的连接强度KW的计算公式:

其中,w0代表关系概念初始连接强度。从式(9)对t求导可知,=0时可得表达式(10):

当初始强度w0
ξf与激发频次正相关,把某主题模式sm看成Object,其包含的ct看成Attribute,由SM模式集构建资源与概念间的形式概念背景。在此形式概念背景中,采用NGD(normalized Google distance)计算连通主题之间的领域关联关系,如式(11)所示。

其中,τ=0.000 001,λ=-1.0是经验性常数;NGD(sti,stj)表示关系概念 sti、stj的归一化谷歌距离;f(sti)、f(sti,stj)代表关系概念在资源模式集SM中单独或共同出现的次数;N代表主题模式总数。ξfij越大代表
sti、stj之间的相互激发越强。
结合以上分析,本研究通过η响应ξf值进行动态调整,实现连接强度的激活或相对抑制。强度系数ξw取固定经验值1.0,η取值半开区间为(ξfw0(1-e-ηt),ξfw0],ξf越大,则η取值越偏向半区间起点,即:
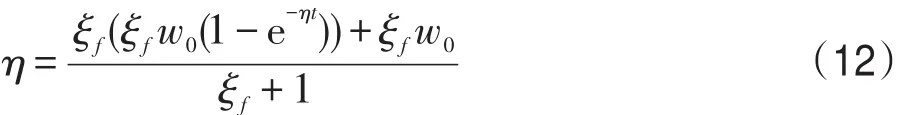
由式(9)、(10)、(12)可知,ξf的增大变化可导致关系概念连接强度w衰减变慢,甚至关系概念连接强度的增长。
综上所述,关系概念初始语义距离越相近,则激活连接强度衰减越慢;关系概念领域共现越频繁,则KALN中的激活强度越明显。通过KALN中KW的η参数调整学习,KALN可以反映关系概念语义、资源领域共现的信息,使得在资源标识过程中,实现KALN的扩展学习。
该公司引进欧洲专业涂层设备,主要提供基于工模具行业的硬质涂层和基于汽车零部件的耐磨减摩涂层服务。硬质涂层主要采用磁控电弧技术,提供铬铝基的D+涂层、超硬切削的SC涂层、不锈钢切削的专用SS涂层以及享有专利技术的铬基EPAC涂层等。基于汽车零部件的Arisimit® DLC涂层则采用PECVD技术,专注于摩擦学涂层市场,以降低(汽车)组件的摩擦与磨损。
3.2.2SALN的扩展
同属一篇文档的资源片段的主题模式间一般存在显性或隐性的领域关联,基于该假设,对SALN模型中结点间的swij可进行文档结构信息扩展,由于篇幅问题,暂不作详述。
3.2.3KALN与SALN的增量更新
在Web资源主题模式更新过程中,KALN中的KW与SALN中的SW均会动态变化更新,二者均采用离线定时更新的方式。在资源标识过程中,新的资源片段如果属于某个既有主题模式,则把文档编号加入主题模式即可,否则增加新的主题模式到SALN中。如同人类短时记忆与长时记忆的关系一样,海马中的短时记忆可以向大脑皮层的长时记忆转化。KALN的更新,必将影响SALN的局部更新。
为了减少增量更新过程中的计算工作量,SALN、KALN的增量更新只针对相关的关系概念进行,暂不作深入优化讨论。
4 算法实现
算法1 KALN初始化算法
输入参数:CT为通过开放协作知识库获取的关系概念集合,为String数组类型。
输出结果:初始的知识关联连接网络KALN,可采用三维数组k[|CT|][|CT|][2]表示,见定义2。
1.定义sr[|CT|],sc[|CT|]//汇总k数组行、列
2.for i=0 to|CT|{
3.k[i][i][0]=1,sr[i]+=1,sc[i]+=1
4.forj=i+1to|CT|{
5.kdij=1/emax(CT[i],CT[j])
6.k[i][j][0]=k[j][i][0]=kdij
7.sr[i]+=kdij,sr[j]+=kdij
8.sc[j]+=kdij,sc[i]+=kdij
9.}}
10.for i=0 to|CT|{
11.k[i][i][1]=1.0/sr(i)
12.forj=i+1to|CT|{
13.kwij=k[i][j][0]/(min(sr[i],sc[j]))
14.k[i][j][1]=k[j][i][1]=kwij
15.}}
16.输出数组k,KALN初始化完成
从算法1可知,KALN扩展的工作量主要和关系概念数量m有关,时间复杂度为O(m2),空间复杂度为O(m2),m为当前关系概念数量。KALN是资源标识的背景知识网络,该网络计算可以离线预先处理。
算法2 KALN增量扩展算法
k′=ExpdKALN(k,CT)
输入参数:k为初始的知识关联连接网络KALN的数组,见算法1;CL为新加入资源集的关系概念向量List集合,其元素为CT类型;CT为某一资源对应的关系概念集合,类似算法1。
输出结果:更新后的k′。
1.定义类型为List
2.Fori=0to|CL|{//遍历新资源主题向量
3.CTi=CL[i]//某资源的关系概念集合
4.Fork=0to|CTi|{//遍历某资源关系概念
5.if(!ST.contains(CTi[k])){//新增
6.ST=ST⋃{
7.}esle{//更新频率
8.times=ST.getvalue(CTi[k])
9.ST=ST.remove(CTi[k]).add(CTi[k],times++>)
10.}}
11.Fori=0to|ST|{
12.if(ST.getvalue(i)>θf)//出现次数大于阈值
13.ST′=ST′⋃{ST.get(i)}
14.ST.remove(i)
15.}
16.if(||ST′>θsize{//更新概念规模大于阈值
17.Form=0to||ST′{
18.Forn=mto||ST′{
19.采用式(11)、(12)、(9)计算连接强度w
20.更新ST′.get(m)、ST′.get(n)、w到k′
21.}}
22.输出k′
从算法2可知,KALN扩展的工作量主要和新增资源集数量及其对应的高频关系概念的数量有关,由于每个资源中的关系概念数量||CTi为固定常数,即7±2,时间复杂度为O(n)+O(m2),空间复杂度为O(m2)+O(n),n为当前资源数量,m为当前高频关系概念数量。算法2只针对高频的关系概念进行连接权值的批量更新,减少KALN的扩展开销。
算法3 SALN基本构建算法
SALN=InitSALN(SM)
输入参数:SM为新加入资源所涉及的关系模式集合,为List类型,其元素数据类型为
输出结果:资源关联连接网络SALN,采用二维数组SN表示,见定义3.
1.Fori=0to|SM|{
2.Forj=i+1to|SM|{
3.采用式(2),计算SN[i][j]=SN[j][i]=swij
4.}}
5.输出SN
由于每个主题模式中的关系概念数量为一个常数,从算法3可知,SALN初始化的工作量主要和资源集对应的主题模式数量m有关,空间复杂度为O(m2),时间复杂度为O(m2),从中可知主题模式的规模直接影响资源标识的效率。因此进行主题模式的合并十分必要,SM的合并与SALN的增量更新暂没讨论。
5 资源标识步骤
结合以上构建的资源标识模型,新的资源通过以下步骤完成语义标识。
(1)构建KALN:借助开放协作数据库,如百度百科条目数据,进行关系概念的获取计算,构建KALN。
(2)资源预处理:把不同格式的资源,如PDF、html、ppt、txt,转换成统一格式的文本。
(3)资源文本处理:对统一格式的文本进行预处理,如分词、词性标注等,形成离散的关键词。
(4)资源关系概念识别:借助关系形式概念及图论,对文本中的关键词进行资源关系概念标识。
(5)资源主题模式的获取:获取资源片段的关系概念向量,构建其主题模式。
(6)利用上一步获取的资源片段的主题模式,采用式(2)对资源片段在SALN中进行相似度计算。
(7)如果存在足够相似的主题模式,则该资源链接到该主题模式,否则新建一个主题模式,并增量添加到SALN。
6 实验与评测
为了评价实际资源标识性能,本文从以下两个方面进行资源语义标识模式准确性评价:
(1)资源内容的关联关系在标识模型中能否正确体现,即本身关联的资源在标识模型中是否也是关联的。
(2)对于一个资源主题模式,其所具有的关联语义链中,那些高权值的关联语义链在关联语义准确度上能否高于那些低权值的关联语义链。
最为简单可行的办法是通过人工阅读评价的方法,确定标识后的资源语义关联的效果。但为了增加评价的客观性,本文主要通过同一原始目录中的文本,使用SALN进行标识,验证标识后资源的相似性、关联性。
6.1实验环境
在CPU为Intel Core i5-4200U,内存为4 GB,OS 为64位的Windows 8的PC机上,采用Java开发语言和Eclipse开发平台进行实验,数据采用PostgreSQL9.3进行管理。
6.2实验数据
本文针对“初中物理在线”商用网站(http://www. czwlzx.com/)中的794篇物理文本资源进行标识实验,这些实用的文本教育资源从内容上分为机械运动、声现象、光现象、力、电流与电路、电与磁、能源与可持续发展等11个一级章节,以及能源、电流和电路、串联和并联、力、光的反射、长度、时间的测量、电动机、运动的描述等40个二级章节。这些资源均为全国不同学校的老师或学生上传的文本资源,结构形式不一,为了对资源标识效果进行评价分析,资源原始一、二级目录信息均保存在数据库中。
6.3实验结果及分析
6.3.1资源标识效果
本文借助百度百科开放协作知识库,通过文本分词、去除停用词等浅层文本处理,以及句法分析、关系概念连通处理后,可得到文本片段主题。由于实验文本数据长短不一,文本结构也不规范,实验中把每个文本资源看成单一片段,其对应的文本主题也看成一个主题模式。例如同为“电与磁”目录下的文档ID271、ID272对应的资源主题模式sm271、sm272如表1所示,表格第一行信息包括关系概念及其在文本中的权值,第二行信息为文本中原始的词条序列,该词条序列属于同列关系概念。

Table 1 Sketch with sm271 of ID271 and sm272 of ID272表1 ID271文本sm271和ID272文本sm272示意
sm271与sm272相关的关系概念KALN子图如图1所示,其中连接权值包括“初始连接强度/语义距离”两部分,该初始的KALN基本反映了词条之间的关联关系,如“应用物理”与“电磁学”之间的权值为0.019/1.757,而“社会”与“磁场”间的权值为0/∞,这与实际语义情况比较吻合。KALN的构建质量与爬取的形式背景的完备程度密切相关,在当前KALN状态下,两个主题模式间的关联度可通过式(2)计算得sw(sm271,sm272)=0.025 344。
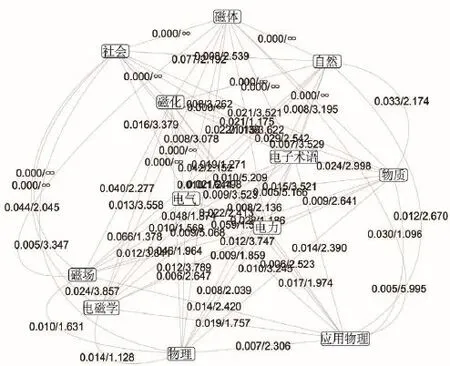
Fig.1 Sub graph of relational concept图1 关系概念的子图示意
在以上基本标识思路上,本文对KALN的扩展模型准确率、召回率、平均关联度进行了验证。根据开放资源既有标识特点,与一资源关联度大于某阈值的关联资源在同一目录下,则认为是正确标识;所有本身关联资源的标识关联度超过了平均关联度的占比为其召回率。为了体现上文说明的准确关联准则,即不仅评价模型的关联语义,同时评价模型关联的相对强弱能力,实验对资源既有一、二级目录标识,在KALN扩展前后进行了评价,具体结果如表2。
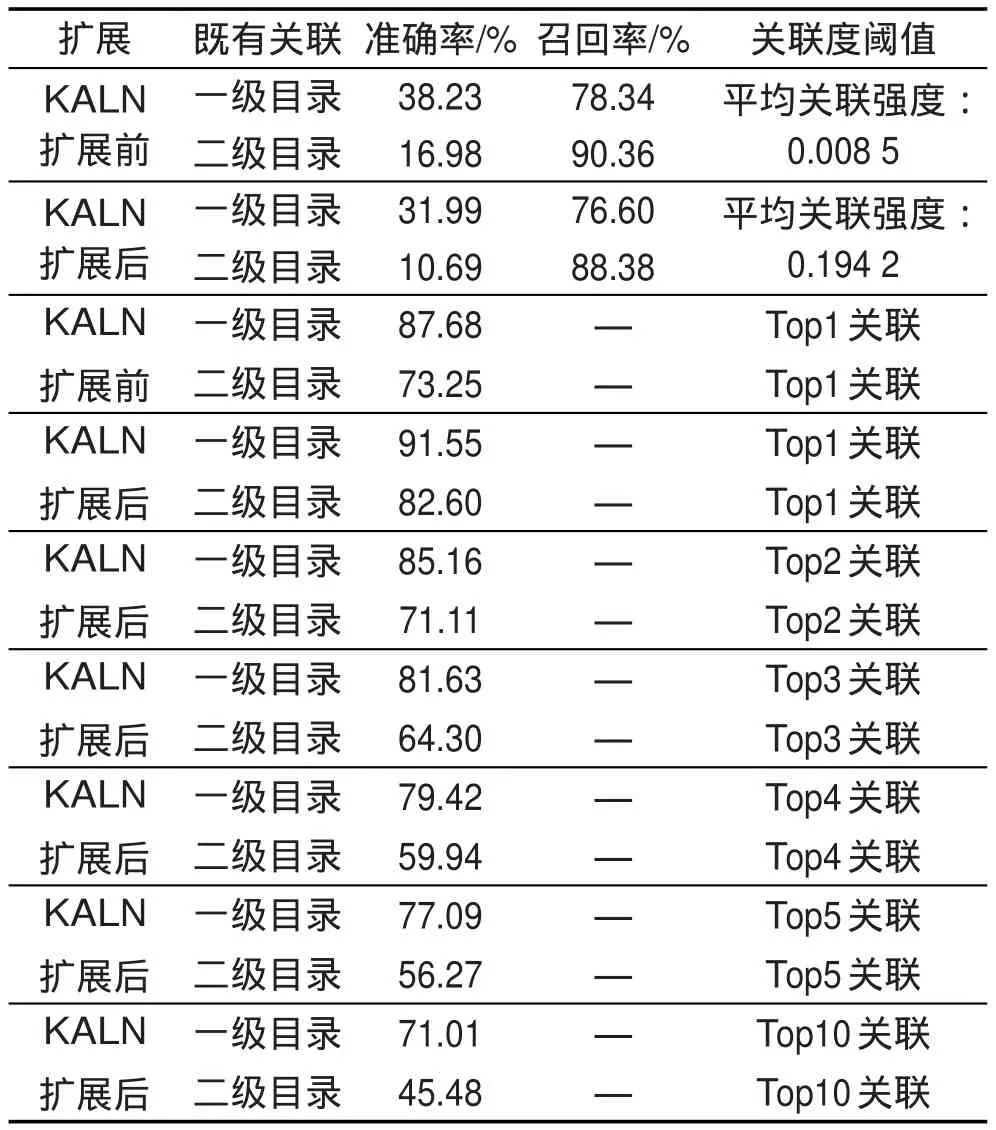
Table 2 Result of annotating resources表2 资源标识关联结果
KALN的扩展,可以动态调整领域关系概念的连接强度,使其更加符合同一语料的关系概念共现关联的情况。从表2中可知,资源间平均关联度由扩展前的0.008 5变为扩展后的0.194 2,说明资源包含的关系概念间的连接强度得以普遍加强。由于语料质量与规模的限制,主题模式间连接强度普遍增加的同时,也整体上引入了一些噪音数据,导致以平均关联度为阈值,召回率和准确率均有所下降,如一级目录的召回率由78.34%下降为76.60%,准确率由原38.23%也下降为31.99%;但资源以Top1关联度为阈值时,扩展前后准确率是上升的,其准确率扩展前后分别达到73.25%与82.60%,说明KALN的扩展对真正关联的部分概念增大程度更大。从表2中可以看出,为了提高后续资源标识的准确性,选取平均关联度作为资源的连接阈值是不合理的,一级目录选取Top3关联度较为合适,二级目录选择Top2关联度较为合适,这样资源间可以形成较为准确并且多样化的关联。Top1代表与某资源最为关联的前一个关联度,其他同理。
一、二级目录准确率的差异,是由于一级目录宽泛,二级目录标识更为精准而形成的。Top2关联度为阈值的一、二级目录的准确率相差不是很大,说明模型中的关联程度能较好体现资源本身的关联精准程度。RCAM-Top2资源SALN见图2。

Fig.2 SALN structure schematic图2SALN示意
因为KALN假设每个关系概念通过有限的距离均是连通的,所以图2不存在孤立的资源结点,每个资源平均有2.542个邻居结点。结点度的分布接近power law分布,即y=2 429.9x-2.52,其R2=0.896,Correlation= 0.708。
模型进行资源标识时,主要和既有资源主题模式数量、资源标识关系概念数量有关,与物理在线资源相关的原始主题模式数量为844个,每个资源使用前9个关系概念标识,通过多轮主题模式合并后,主题模式精简到791个主题模式。每个主题模式采用9个关系概念及其外延词条表达,而两主题模式间采用一个语义关联数值进行表达,存储空间为586 KB,较为合理。由于模型定义的特点,相比资源的开放性增长,后续资源的主题模式增长会缓慢得多,但具体数据还需后续的进一步验证和优化。
6.3.2与相关资源组织模型的结构比较
由于资源标识模型的效果不仅与模型策略有关,也与其领域知识的构建规模和质量关系密切,因此表3只给出了相关资源组织模型的网络结构比较信息。语义网本体是文献[7]中利用DAML图书馆中的语义本体构建的网络;WWW网络的数据则来自文献[14];Words Network的数据来自文献[15];关联语义链网络的数据则来自文献[16]。

Table 3 Comparison of resource organization models表3 相关资源组织模型比较
由于RCAM-Top2网络是基于Top2关联度构建的,RCAM-Top10则是基于Top10关联度构建的,故此它们资源间的平均连通路径长度变化较大,前者更为稀疏。RCAM-Top10和小世界网络Words Network模型特点接近。相比半自动的语义网本体模型,RCAM与关联语义链网络构建更为方便,均为自动构建,万维网的连接网络具有较大的随机性。RCAM构建基于关系概念以及认知规律,语义与结构可以进行扩展,可通过设置不同的网络连接阈值,控制标识的准确性或激活范围,在特定的上下文环境下,可以进行不同的资源转向控制。
7 总结与展望
本文借助对传统形式概念的扩展,建立基于关系的形式概念,采用关系概念及主题模式对资源进行标识,为资源提供概念与结构上的标识语义。同时借鉴人类记忆的激活扩散、衰减遗忘机制,对模型的关联强度进行动态学习调整,使其更好反映Web资源标识的时空动态性与学习者的个性需求。本文主题模式的合并约简、模型的增量更新以及参数调整的收敛、调整规律,更为精准的KALN扩展规律及其结合个性化资源推荐应用均需进一步深入研究。
References:
[1]Liu Hanhui.Analysis of the mechanism and application of memory model and neural system[M].Tianjin:Tianjin University Press,2015.
[2]Xia Jiali,Cheng Chunlei,Chen Hui,et al.The strategy of extracting Chinese entities relation based on predicate concept connectivity[J].Journal of Frontiers of Computer Science and Technology,2014,8(11):1345-1357.
[3]Dublin core metadata initiative(DCMI)[R/OL].(2008-06-07)[2016-02-28].http://dublincore.org/.
[4]Salton G,Yang C S.On the specification of term values in automatic indexing[J].Journal of Documentation,1973,29 (4):351-372.
[5]Resource description framework(RDF)[R/OL].[2016-02-28]. http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/.
[6]ISO/IEC.Topic maps data model[S/OL].(2006)[2016-02-28]. http://www.topicmaps.org/.
[7]Gil R,Garcia R.Measuring the semantic Web[J].AIS SIGSEMIS Bulletin,2004,1(2):69-72.
[8]Yang Yuehua,Du Junping,Ping Yuan.Ontology-based intelligent information retrieval system[J].Journal of Software, 2015,36(7):1675-1687.
[9]Xu Ge,Wang Houfeng.The development of topic models in natural language processing[J].Chinese Journal of Computers,2011,34(8):1423-1437.
[10]Wang Shaonan,Zong Chengqin.A dual-LDA method on Chinese word sense representation and induction[J/OL]. Chinese Journal of Computers.(2016-01-24)[2016-02-28]. http://www.cnki.net./kcms/detail/11.1826.TP.20160124.2008. 004.html.
[11]Wille R.Restructuring lattice theory:an approach based on hierarchies of concepts[C]//LNCS 5548:Proceedings of the7th International Conference on Formal Concept Analysis, Darmstadt,Germany,May 21-24,2009.Berlin,Heidelberg: Springer,2009:314-339.
[12]Cheng Chunlei,Xia Jiali,Cao Chonghua,et al.Research on Web text topic extraction model with relational concept[J]. Journal of Chinese Computer Systems,2016,37(5):972-978.
[13]Boulton D.Cognitive science:the conceptual components of reading&what reading does for the mind[EB/OL].[2016-02-28].http://www.childrenofthecode.org/interviews/stanovich.htm.
[14]Kleinberg J,Lawrence S.The structure of the Web[J].Science, 2001,294:1849-1850.
[15]Ferre R,Sole R.The small world of human language[J]. Proceedings of the Royal Society:B,2001,268:2261-2265.
[16]Xu Zheng.Building association link network for managing large-scale Web resources[D].Shanghai:Shanghai University,2012.
附中文参考文献:
[1]刘汉辉.记忆分析模型及其神经系统机理与应用[M].天津:天津大学出版社,2015.
[2]夏家莉,程春雷,陈辉,等.谓词概念连通度的中文实体关系抽取策略[J].计算机科学与探索,2014,8(11):1345-1357.
[8]杨月华,杜军平,平源.基于本体的智能信息检索系统[J].软件学报,2015,36(7):1675-1687.
[9]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1437.
[10]王少楠,宗成庆.一种基于双通道LDA模型的汉语词义表示与归纳方法[J/OL].计算机学报.(2016-01-24)[2016-02-28].http://www.cnki.net./kcms/detail/11.1826.TP.20160124. 2008.004.html.
[12]程春雷,夏家莉,曹重华,等.关系概念的Web文本主题抽取模型研究[J].小型微型计算机系统,2016,37(5):972-978.
[16]徐峥.大规模网络资源环境下关联语义链网络模型及其应用研究[D].上海:上海大学,2012.

CHENG Chunlei was born in 1976.He is a Ph.D.candidate and associate professor at Jiangxi University of Finance and Economics,and the member of CCF.His research interests include text mining and decision support system.程春雷(1976—),男,江西财经大学博士研究生、副教授,CCF会员,主要研究领域为文本挖掘,决策支持系统。

XIA Jiali was born in 1965.She received the Ph.D.degree from Huazhong University of Science and Technology in 2003.Now she is a professor and Ph.D.supervisor at Jiangxi University of Finance and Economics.Her research interests include data mining,real-time database system and software engineering.
夏家莉(1965—),女,2003年于华中科技大学获得博士学位,现为江西财经大学教授、博士生导师,主要研究领域为数据挖掘,实时数据库系统,软件工程。
*The Science and Technology Support Program of Jiangxi Province under Grant No.20141BBE50031(江西省科技支撑计划);the Natural Science Foundation of Jiangxi Province under Grant No.20132BAB201028(江西省自然科学基金);the Medical Research Program of Health Department of Jiangxi Province under Grant No.2013A100(江西省卫生厅中医药科研计划);the Research Program of Jiangxi University of Traditional Chinese Medicine under Grant Nos.2013ZR0069,2013jzzdxk022(江西中医药大学校级课题).
Received 2016-04,Accepted 2016-06.
CNKI网络优先出版:2016-06-01,http://www.cnki.net/kcms/detail/11.5602.TP.20160601.1517.002.html
文献标志码:A
中图分类号:TP391
doi:10.3778/j.issn.1673-9418.1604023
Research on Semantic Annotation Model of Web Resources Based on Relational Concept*
CHENG Chunlei1,2+,XIAJiali1
1.School of Information Management,Jiangxi University of Finance and Economics,Nanchang 330032,China 2.School of Computer Science,Jiangxi University of Traditional Chinese Medicine,Nanchang 330004,China +Corresponding author:E-mail:chunlei_cheng@163.com
Abstract:In the Web environment,resources have rich contents,various forms,different description standards as well as discrete organizational structures.Problems,such as the lack of semantics and domain knowledge and artificial workload,limit them in the personalized resource recommendation and the obtaining application.This paper, based on the relationship between the concept of activated diffusion and the thought of layered resource semantic identification,establishes the relational concept annotation model(RCAM).RCAM simulates human memory activation spreading process and considers memory enhancement and forgetting mechanism to achieve the more dynamic and personalized related organizations of Web resources.RCAM regards the concept of a relationship as semantic elements,and the fragment relationship concept set as the semantic scheme.With the flexible identification granularity and relatively completed sematic logic,RCAM provides new research ideas to Web education resource identification.Experiment shows that RCAM can provide more background knowledge,adapt to dynamic resource organi-zation with different learning scenarios and learning personality,and it aims at the open Web resources.As a result, RCAM has better universality and extensibility.
Key words:Web resources annotation;relational concept;activation and spreading;relational concept annotation model(RCAM)
