
云存储日志文件系统中垃圾数据回收的设计与实现
2016-09-08 10:30贾威威张延园
计算机应用与软件 2016年8期
贾威威 林 奕 张延园
(西北工业大学计算机学院 陕西 西安 710129)
云存储日志文件系统中垃圾数据回收的设计与实现
贾威威林奕张延园
(西北工业大学计算机学院陕西 西安 710129)
互联网大数据蓬勃发展,各个行业都围绕着大数据展开研究。与此同时,由于数据量的异常膨胀,随之而来的问题就是如何回收垃圾数据。基于云存储日志文件系统HLFS(Hadoop distributed file system based Log-structured File System),设计与实现了垃圾数据回收子系统。通过在HLFS中添加垃圾回收子系统,不但可以提高数据空间的利用率,还可以有效地避免数据空间不够用。为了分析HLFS中垃圾回收子系统的性能,最后对比了HLFS垃圾回收子系统和其他系统中垃圾数据回收机制的优缺点,从而帮助用户选择合适的垃圾回收机制提高磁盘利用率和系统性能。
云存储日志文件系统垃圾数据回收
0 引 言
随着互联网大数据的日益增长,各大互联网巨头推出了各自的存储系统,这些存储系统也成为了行业标准。Google设计与实现了Google File System (GFS)[1]和键值存储系统LevelDB[2],Amazon设计与实现了Simple Storage System (S3)[3]和键值存储系统Dynamo[4],Yahoo!设计与实现了PNUTS[5],Facebook设计与实现了Cassandra[6]等。这些存储系统大部分是不开源的,因此开源组织也针对其公布的文献设计与实现了开源版存储系统,例如Apache基金会设计与实现了GFS开源版Hadoop Distributed File System[7]。这些存储系统是针对互联网业务的特性而设计的,比如需要具备高可用性、可扩展性、容错性等。但是大部分都没有考虑设计与实现垃圾数据回收子系统,这主要是互联网公司对用户数据的依赖性,用户的任何数据都具有价值,即使用户删除,其系统也不会自动删除,而是保存这些数据。有些应用场景如果不及时删除用户的垃圾数据,存储空间很快就不够用了,例如,嵌入式系统、云存储时代大数据暴增等。
垃圾回收通常意义上是指对内存空间进行管理,因为计算机内存有限,所以使用完的内存要及时回收,然后用于下次计算再使用。本文中的垃圾数据回收主要是指存储空间(包含内存和外存)的回收利用。因为云存储时代,数据量的巨增,外存空间如果不加以合理的管理,也会被很快使用完,这就要求系统工程师设计与实现垃圾数据回收子系统从而可以提高存储空间的利用率。实际上,存储空间的垃圾数据回收是一个永久的话题,尤其是当前互联网用户数据量日益增大,垃圾数据回收的设计与实现就迫在眉睫。垃圾数据回收的主要作用是能够在线或者离线回收用户的垃圾数据,这样就可以提高存储空间的利用率,一定程度上还可以提高数据检索速度。设想如果垃圾数据被回收,数据检索时的数据量就可以减少,从而提高数据检索速度。但是这也存在一个折衷,因为系统在垃圾回收时,可能会降低系统的整体性能,因此需要设计有效的垃圾回收子系统,从而降低系统性能损耗。
实际上,当前很多存储系统已经设计与实现了垃圾数据回收子系统。Sheepdog[8]是一个基于QEMU[9]/KVM[10]设计与实现的分布式存储系统,可以为虚拟机提供高可靠的块级别卷存储解决方案,Sheepdog目前支持快照,克隆和垃圾数据回收。当然还有很多垃圾回收机制针对基于闪存硬件的存储系统,这是由于闪存无法覆盖写所引起的。本文基于分布式存储系统,设计与实现了垃圾数据回收子系统,从而提高了系统的存储空间利用率。本文最后还对比了HLFS垃圾回收子系统和Sheepdog垃圾回收子系统的优缺点,方便以后的设计者和用户选择合理的垃圾回收子系统。
1 HLFS的设计与实现
为了给网页应用,如维基百科、论坛等,提供小数据密集写服务,以及虚拟机提供后台存储服务,基于HDFS设计与实现了HLFS。HLFS结合了HDFS和LFS的优点,不但可以提供随机读写功能,同时还能支持垃圾数据回收等特性。

图1 Linux文件系统架构
HLFS是一个在用户态基于Hadoop分布式文件系统设计与实现的分布式文件系统,Linux文件系统总体架构如图1所示。经典的文件系统都挂接在Virtual File System(VFS)之上,对用户提供统一的接口,HLFS位于在VFS和用户之间,这样HLFS就可以在用户态给用户提供存储服务。Hadoop分布式文件系统是Apache基金会根据Google公布的GFS论文而设计与实现的分布式文件系统,但是Hadoop分布式文件系统不支持随机读写,其读写语义为一次写入只能读取(once-write-many-read)。因此HLFS在其基础之上借助日志结构文件系统的思想设计与实现可以随机读写的分布式文件系统HLFS。

图2 HLFS文件系统架构
HLFS有两种模式:一种是本地模式,另一种是HDFS模式。当格式化HLFS文件系统的时候可以选择格式化为其中的一种模式。HLFS本地模式就和普通文件系统一样,这种模式主要用于数据的本地化,这样可以降低网络负载,提高读写性能。还有一个用途就是方便设计与调试,而HLFS的HDFS模式主要是把数据存放到HDFS这个分布式文件系统之上,提供高可靠、高可扩展以及可容错的大数据存储服务。HLFS架构如图2所示,在操作系统内核空间之上就HLFS的两种模式,分别是HDFS文件系统服务和本地文件系统服务,而这之上就是HLFS的日志文件系统层。
HLFS借助经典日志文件系统的思想,因此对HLFS文件的每次更新都会追加一个日志,逻辑上HLFS的存储空间是由很多个log组成的,如图3所示。每个日志分为五个部分,依次为日志头、数据块、索引块、索引节点和索引节点映射。日志头包含了整个日志的大小和其他日志元数据,数据块存储了用户的数据,索引块是用来存储数据块的索引地址,索引节点包含了HLFS文件的索引地址,索引节点映射可以很快找到索引节点,日志结构如图4所示。
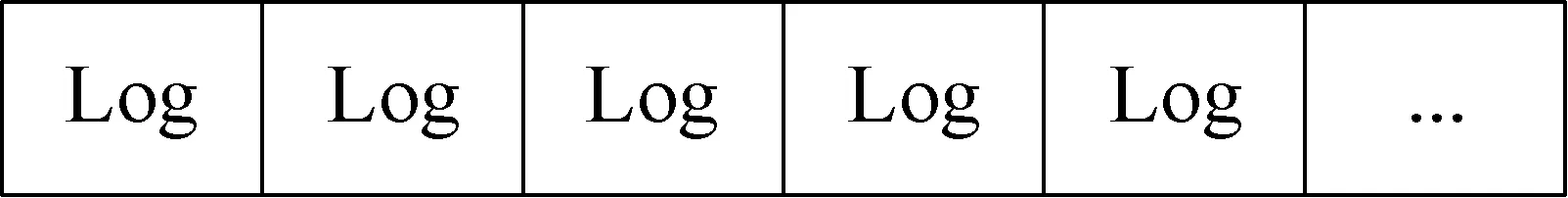
图3HLFS存储结构
图4HLFS日志结构
为了方便垃圾数据回收以及管理HLFS数据,HLFS在日志结构之上又划分了段结构。HLFS段文件是由很多个日志组成,每个段文件不超过64 MB,而HDFS默认数据块是64 MB,这样刚好吻合,可以提高数据在HDFS之上的存储和读取。HLFS分层架构如图5所示,当用户提出一个文件随机写请求,首先被封装成一个日志,然后被追加到当前最新的段文件末尾,而用户的读请求只需要读取最新段文件的最新日志就可以通过索引结构读取到所有数据。HLFS索引节点中的索引结构和经典文件系统一样,直接索引存储数据块,一级索引存储索引块的地址,以此类推。
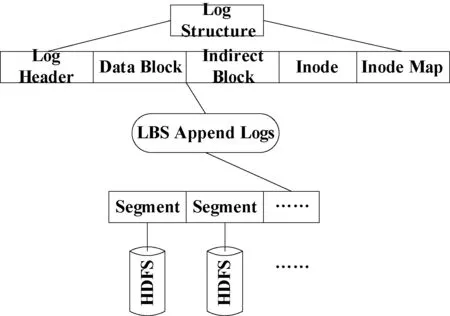
图5 HLFS分层结构
2 HLFS快照
快照在存储系统中具有很重要的意义,因为存储系统中存储的用户数据可能会因为各种原因而被污染或者丢失。如果存储系统具有快照功能,那么用户可以很容易就回滚到指定的时刻,然后恢复需要的数据。尤其是在互联网行业,快照的作用更明显,用户的数据就是公司赖以生存的基础,因此需要保护用户数据的安全正确。HLFS的存储空间逻辑上是由很多个日志依次追加形成的,因此每次顺序追加的日志就是天然的线性快照。如图6所示,HLFS线性快照所示,Tn表示在这个时间点创建快照snapshotn,回滚只需要加载指定的日志就可以恢复用户数据。这种线性快照显然是不够的,因为这种快照只能按照顺序生成,而且快照中的垃圾数据也可能会被回收,因此需要设计更为灵活的线性快照。如图7所示,HLFS树形快照所示,Tn表示在这个时间点创建一个快照,树形快照是用户手动生成的,而非系统自动生成,因此垃圾回收不会回收这些快照中所包含的数据。树形快照只需要一个实体用来记录快照点所记录的日志信息,如索引节点地址等。

图7 HLFS树形快照

图6HLFS线性快照
很多存储系统使用多副本来提升系统容错能力,但是这种方式不但占用多倍的存储空间,而且恢复数据的时候会降低系统的性能。HLFS快照系统借助日志结构文件系统的思想具备天然的快照功能,在此基础之上又设计了树形快照功能,不但回滚快捷而且提高了系统的可靠性和容错性。
3 HLFS垃圾回收子系统的设计与实现
HLFS垃圾数据回收子系统分为两个部分:快照下的垃圾数据回收和非快照下的垃圾数据回收子系统。因为不能回收用户设置快照的数据,所以即使用户设置快照的数据是垃圾数据也不能对其进行回收。
3.1HLFS垃圾数据
对HLFS文件的任何更新都会追加新的日志,每个日志包含五个域,其中索引节点实体域包含了HLFS文件的主要元数据信息,具体如下所示:
struct inode {
uint64_t length;/* the length of hlfs file */
uint64_t ctime; /* time of hlfs create */
uint64_t mtime; /* time of last modification */
uint64_t atime; /* time of last access */
int64_t blocks[12]; /* the first 8KB*12=96KB */
int64_t iblock; /* the next 8KB/8*8KB=8MB */
int64_t doubly_iblock; /* the next 8K/8*8K/8*8K=8GB */
int64_t triply_iblock; /* the next 8K/8*8K/8*8K/8*8K=8TB */
} __attribute__((packed));
在以上索引节点数据结构中length表示hlfs的大小,ctime、mtime、atime分别表示hlfs文件的创建、最后修改、最后访问时间,blocks、iblock、doubly_iblock、triply_iblock是hlfs文件的三级索引结构,blocks是直接索引,iblock是一级索引,doubly_iblock是二级索引,triply_iblock是三级索引。三级索引结构是hlfs索引节点最重要的信息,三级索引结构具体如图8所示。
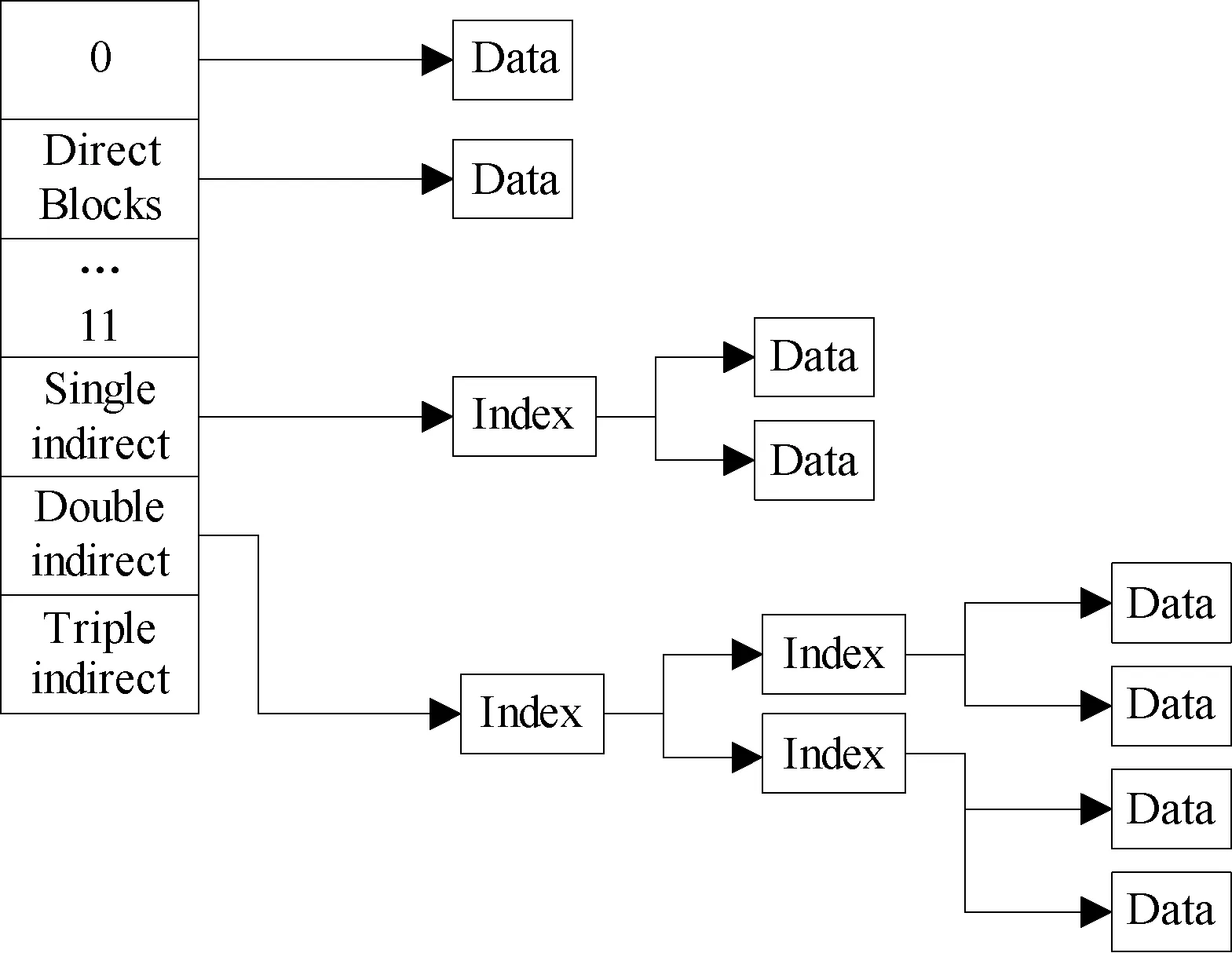
图8 HLFS文件索引结构
当用户需要更新或者写入新的数据,需要创建新的数据块。如果要更新之前的数据,那就先把之前的数据块加载到内存,修改要更改的部分。然后创建新的数据块,接着把内存修改过的数据块拷贝到创建的数据块上。最后用新创建数据块的逻辑地址覆盖旧数据块的逻辑地址,旧的数据块就是垃圾数据。如果是写入新的数据,只需要把写入数据从内存拷贝到新创建的数据块,最后添加逻辑地址到三级索引结构。在这个过程中的内存数据的一致性和持久性都是由HDFS(HLFS HDFS模式)或者本地文件系统(HLFS 本地模式)保证的。
3.2HLFS垃圾数据回收
HLFS垃圾数据节描述了HLFS文件系统中垃圾数据的产生原因。为了保证数据存储空间的高可用性,要对垃圾数据所占用的存储空间进行回收。为了更高效地管理HLFS存储空间,垃圾数据回收的单位并非以日志为单位。因为如果以日志为单位那么管理回收效率很低,力度不够大,所以在日志之上划分了HLFS段文件,每个HLFS段文件都是由若干个日志组成的,段文件大小不超过64 MB。HLFS的存储空间是64位,前38位是段号,后26位是段内偏移地址,因此HLFS文件系统可以有238个段文件,而每个段的大小为64 MB。
HLFS垃圾数据回收分为两个步骤,首先需要统计当前已生成段文件的段使用情况,这里存在一个段内可用数据块的阈值。如果这个段内的可用数据块数量低于这个阈值就需要段回收,相反则保留这个段文件。这个垃圾回收段阈值是可以配置的,根据不同的需求可以在系统初始化的时候设置。当段统计完成之后,就需要对段文件可用数据块低于阈值的段文件进行回收,HLFS段文件回收采用move-and-remove语义。首先创建新的段文件,把要回收的段文件的可用数据块写入到新创建的段文件,然后删除要回收的段文件,整个段回收工作是后台进程完成的,只有在当前没有写入任务的时候才开始执行段回收工作,这样就可以避免并发带来的一系列问题。
3.3HLFS快照下的垃圾数据回收
HLFS快照分为线性快照和树形快照,线性快照是HLFS文件系统天然具备的,而树形快照是用户手动生成的。因此HLFS垃圾数据回收不能回收用户打了快照的日志,HLFS快照下的垃圾数据回收需要重新设计。当没有快照的时候,段统计是把当前所有段文件中的日志和HLFS最新日志做比较,如果数据块的索引地址和最新日志的索引地址不一样,那么说明这个数据块中所包含的数据就是垃圾数据。而快照下的垃圾回收则是把HLFS存储空间划分为若干个部分,具体由当前快照数决定,以第一个快照为参照点开始进行垃圾数据回收。然后从第一个快照点之后的日志开始,以第二个快照为参照点开始进行垃圾数据回收,依次类推,完成HLFS垃圾数据回收段统计。最后对划分的这些部分执行段回收工作,这个阶段和没有快照一样。
4 HLFS垃圾数据回收子系统性能分析
垃圾数据回收是存储系统永久的一个话题,由于磁盘很廉价以及互联网应用特征,因此这个问题一直研究的很少,但是目前由于数据量暴增,垃圾数据回收已经是一个不可避免的话题。一些存储系统已经引进了垃圾回收子系统,例如,Sheepdog等。
Sheepdog是日本NTT公司设计与实现的一款基于QEMU/KVM虚拟机的分布式块存储系统,Sheepdog存储系统中包含了垃圾数据回收子系统,其采用Generational Reference Counting (GRC)[11]算法进行垃圾回收。这个算法的核心思想是:一个存储对象包含代数和引用计数,这里的代数指的是这个存储对象是第几代引用,而引用计数用来记录这个存储对象被做了几次拷贝。这个算法还引进了一个存储表,这个存储表包含了存储镜像中每个存储对象的总引用计数。每个存储镜像可以包含很多个存储对象。
当一个存储对象A被创建的时候,它的代数和引用计数被初始化为零,同时存储表的第一个域初始化为一,其他均为零,这是因为第一个存储对象已经创建了。当另一个存储对象B基于A对象被克隆,那么B的代数就初始化为A的代数加一,这是因为B是基于A克隆的,A是第一代那么B就是第二代。B的引用计数初始化为零,同时A的引用计数加一。当存储表中的存储对象(A或者B)被删除时,那么一个删除消息发送给存储表,这个删除消息包含要删除的存储对象的代数和引用计数。最后在存储表中通过代数找到这个域,然后减一,同时把这个引用计数值加到下一个域,这是因为这个存储对象被拷贝了引用计数次。当存储表的每个域都为零时,这个存储镜像就可以回收了。
在Sheepdog中快照也是要做拷贝的,因此快照也会执行以上操作。而HLFS快照[12]不需要消耗额外的存储空间,在HLFS垃圾回收子系统中,不需要开辟存储空间。Sheepdog垃圾回收是基于GRC算法,需要开辟新的存储空间,如果没有拷贝操作,那么每个存储对象都要产生额外的存储空间来存储代数和引用计数。如表1所示,HLFS和Sheepdog数据操作相关性对比,可以发现,HLFS的数据内聚性更高,而Sheepdog则相反。

表1 HLFS和Sheepdog数据操作相关性对比
如表2所示,HLFS垃圾数据回收系统和Sheepdog垃圾回收系统对比,HLFS垃圾数据回收是细粒度回收,基于段文件,而Sheepdog垃圾数据回收是针对一个镜像文件,灵活度更低。HLFS垃圾数据回收也不需要开辟新的存储空间,而Sheepdog垃圾回收则需要开辟新的存储空间。HLFS垃圾回收子系统支持手动垃圾数据回收,而且支持手动配置段文件回收阈值,这样可以随时回收垃圾数据所占用的存储空间。

表2 HLFS垃圾数据回收系统和Sheepdog垃圾数据系统对比
当把HLFS垃圾回收子系统的段回收阈值设置为不同的值时,HLFS垃圾数据回收子系统的空间回收率可以不断调整,而Sheepdog垃圾回收子系统垃圾数据回收率无法手动控制,具体如表3所示。

表3 HLFS和Sheepdog垃圾数据回收率对比
HLFS垃圾数据回收率V是根据段文件回收阈值以及回收代价和系统负载,然后判断是否进行垃圾回收,当所有段文件中的垃圾数据量小于回收阈值,就不进行回收操作,垃圾数据回收率就是0%。因为回收操作的代价很高,严重影响系统性能。而当所有段中的垃圾数据大于回收阈值,则进行垃圾数据回收操作,垃圾数据回收率是100%。相反,Sheepdog的垃圾数据回收策略单一,无论系统负载多大,数据量多大,垃圾数据回收率都为V’。
5 结 语
在分析了云存储日志文件系统的基础上,设计与实现了基于HLFS云存储日志文件系统垃圾数据回收子系统。HLFS支持垃圾数据回收子系统之后,系统存储空间利用率更高,有效地提升了本地存储,避免了网络负载。最后对比了HLFS垃圾回收子系统和Sheepdog垃圾回收子系统优缺点,方便用户根据特定场景选择适合的垃圾回收子系统。
[1] Ghemawat Sanjay,Howard Gobioff,Shun-Tak Leung.The Google file system[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[2] Leveldb project[EB/OL].(2011-07-20).[2014-11-03].https://github.com/google/leveldb.
[3] Amazon S3 project[EB/OL].(2011-07-20).[2014-11-03].http://aws.amazon.com/cn/s3/.
[4] DeCandia Giuseppe,Hastorun Deniz,Jampani Madon,et al.Dynamo:amazon’s highly available key-value store[J].ACM SIGOPS Operating Systems Review,2007,41(6):205-220.
[5] Cooper Brian F,Ramakrishnan R,Srivastva U,et al.PNUTS: Yahoo!′s hosted data serving platform[C]//Proceedings of the VLDB Endowment 1.2,2008:1277-1288.
[6] Lakshman,Avinash,Prashant Malik.Cassandra: a decentralized structured storage system[J].ACM SIGOPS Operating Systems Review ,2010,44(2):35-40.
[7] Shvachko Konstantin,Huang Hairong,Radia Sanjay,et al.The hadoop distributed file system[C]//Mass Storage Systems and Technologies (MSST),2010 IEEE 26th Symposium on.IEEE,2010,26(1):1-10.
[8] Sheepdog project[EB/OL].(2012-09-09).[2014-11-03].http://sheepdog.github.io/sheepdog/.
[9] QEMU project[EB/OL].(2010-06-09).[2014-11-03].http://wiki.qemu.org/Main_Page.
[10] KVM project[EB/OL].(2012-06-05).[2014-11-03].http://www.linux-kvm.org/page/Main_Page.
[11] Goldberg,Benjamin.Generational reference counting:A reduced-communication distributed storage reclamation scheme[J].ACM SIGPLAN Notices,1989,24(7):43-81.
[12] 陈莉君,康华,贾威威.云存储日志文件系统中快照的设计与实现[J].计算机应用与软件,2013,30(7):204-208.
DESIGN AND IMPLEMENTATION OF JUNK DATA RETRIEVE IN LOG-STRUCTURED FILE SYSTEM OF CLOUD STORAGE
Jia WeiweiLin YiZhang Yanyuan
(SchoolofComputingScience,NorthwesternPolytechnicalUniversity,Xi’an710129,Shaanxi,China)
With the booming development of network big data, industry of all sectors are carrying out study around it. Meanwhile, because of the abnormal data expansion, the ensuing problem is how to retrieve junk data. In this paper, we design and implement a junk data retrieve subsystem based on log-structured file system of cloud storage, HLFS (Hadoop distributed file system based log-structured file system). By appending the subsystem to HLFS, not only the utilisation of data space can be enhanced, but the insufficient data space is also effectively avoided. In order to analyse the performance of junk data retrieve subsystem in HLFS, in end of the paper we compare the pros and cons of this subsystem in HLFS with the junk data retrieve mechanism in other systems, thereby help users to choose proper junk data retrieve mechanism to improve disk utilisation and system performance.
Cloud storageLog-structured file systemJunk data retrieve
2015-01-13。国家自然科学基金项目(61272123)。贾威威,硕士生,主研领域:存储系统。林奕,副教授。张延园,教授。
TP3
A
10.3969/j.issn.1000-386x.2016.08.012
猜你喜欢
天津科技(2022年5期)2022-05-31
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
哈尔滨轴承(2020年2期)2020-11-06
电脑爱好者(2019年17期)2019-10-30
发明与创新·大科技(2019年12期)2019-03-17
现代计算机(2017年7期)2017-04-22
网络安全和信息化(2017年3期)2017-03-10
中国教育信息化(2015年12期)2015-08-24
电测与仪表(2015年10期)2015-04-09
