
一种面向分布式策略自管理的方法
2016-09-08 10:31马增帮杨英杰代向东
计算机应用与软件 2016年8期
马增帮 杨英杰 代向东 刘 江
(信息工程大学 河南 郑州 450001)
一种面向分布式策略自管理的方法
马增帮杨英杰代向东刘江
(信息工程大学河南 郑州 450001)
针对目前分布式策略管理依靠管理员手工配置和分发策略难以及时准确地进行策略更新调整,以适应动态多变的分布式系统环境下策略动态管理的问题,提出基于元策略的分布式策略自管理框架。设计了基于改进的ID3算法的策略自管理算法,实现了元策略随系统环境变化动态调整,进而实现了基本策略的动态更新调整。最后,实验验证了该方法的可行性和有效性。
策略管理自管理框架元策略改进的ID3算法
0 引 言
近年来,基于策略的管理被认为是解决大规模分布式管理问题最有效的方法,得到了IETF(Internet Engineering Task Force)、DMTF(Desktop Management Task Force)等标准组织以及许多学术机构和网络设备厂商的支持。
策略管理框架是部署和实施策略管理的基础,针对策略管理的需求,目前研究已经提出了多种策略管理框架。具体而言,IETF策略管理框架[1],如图1所示。其组成包括策略管理点PAP、策略库、策略决策点PDP和策略执行点PEP。PAP为策略管理员提供操作接口,管理员通过接口制定策略;策略库存放策略及相关的各种信息;PDP负责接收PEP提交的策略请求,根据策略库内的策略进行决策并将决策结果返回给PEP;PEP负责向PDP发送请求以及执行策略。
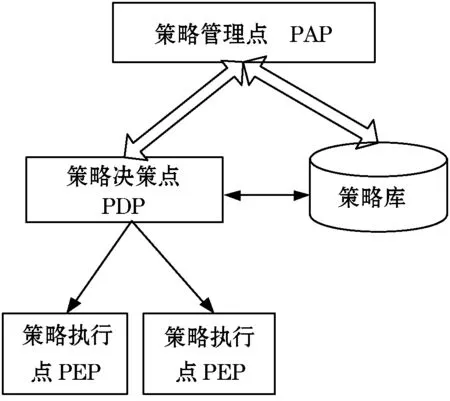
图1 IETF策略管理框架
其他学术组织及机构在IETF策略管理框架的基础上推出各自的策略管理框架。例如,结构化信息标准促进组织OASIS批准了集中式管理的XACML策略管理框架[2],与IETF策略管理框架相比,XACML策略管理框架增加了策略信息点以及上下文处理,策略信息点用于查询环境以及策略作用对象的基本信息,上下文处理是将请求和决策在外部系统可识别形式以及XACML可识别形式之间转变。集中式策略管理框架在进行策略决策时会出现性能瓶颈问题,Daniel Diaz-Lopez等人[3]对XACML策略管理框架进行改进,通过增加管理中心及策略决策点的方式实现将集中式策略管理改为分布式策略管理,他们引入约束基本策略的元策略,通过元策略控制基本策略优先级避免策略冲突问题。这为策略管理提供一个好方法:利用元策略管理基本策略。其他许多策略管理框架是支持分布式管理的,如英国皇家学院提出的Ponder策略管理框架[4]。
以上对于策略管理框架的研究主要是为了实现对分布式管理的支持。分布式系统环境动态多变,因此策略需要实时变更来适应动态多变的环境,然而,这些策略管理框架并没有考虑环境变化对策略的影响,也不能对策略进行自动的管理和控制,而是依靠管理员手动下发策略,因而不能及时根据环境变化进行策略的动态调整,不能满足分布式系统多变环境下策略快速、动态调整和实施的需要。以时间环境为例,在运营时间及非运营时间,对资源的控制粒度不同,此种情况下在不同的时间需要采用不同的基本策略。
目前,对于策略自动管理及生成的研究相对较少。Sonkoly等人[5]提出数字化策略以适应分布式环境下策略的管理,指出数字化策略需支持策略自动生成,但是并没有指出具体如何实现。Gwyduk Yeom等人[6]提出一种动态策略管理框架可以根据环境变化实时改变策略,该框架通过一个黑盒系统捕捉事件变化,运行策略同步算法、策略优先级算法以及策略决策算法查找出相应策略并使其生效以取代先前策略。特定环境需要多条策略共同作用,但上述方法只针对一条策略,需要不断运行算法来查找合适策略,效率较低。文献[7]总结了目前策略自动生成的方法:束法、直接法、本体论以及决策树,这些算法使策略自动生成成为可能。然而,这些算法都是直接自动生成基本策略,准确性不能保证,这与安全策略对准确性的要求不符,如果完全依赖策略自动生成一旦出错将对系统造成难以估量的损害。
为保证策略的准确性,同时又能适应快速多变环境,由管理员制定基本策略,并制定元策略来管理基本策略,根据环境变化动态变更元策略进而变更基本策略是一个较好的方法。基于此,本文提出一种分布式策略自管理方法,并设计其部署框架,该框架的核心是根据环境变化动态实时变更元策略,从而实现基本策略的动态调整。本文所提元策略不考虑对基本策略优先级的限制及策略冲突问题。
1 分布式策略自管理框架
目前,策略管理框架分为集中式和分布式两种类型。本文所提策略管理框架采用分布式管理方式。
集中式策略管理只有一个PDP,PDP决策来自所有PEP的请求,随着系统规模的扩大,请求数量越来越大,PDP决策效率必然会受到影响,成为整个系统的性能瓶颈。而分布式的策略管理将PDP与PEP结合,一个管理系统对应多个PDP,不再进行集中式决策。将基本策略下发到各个执行点,由执行点决策并执行策略,有效解决了PDP性能瓶颈问题。同时,为了实现策略的自动化管理,在IETF策略管理框架的基础上,设计了分布式策略自管理框架,如图2所示。
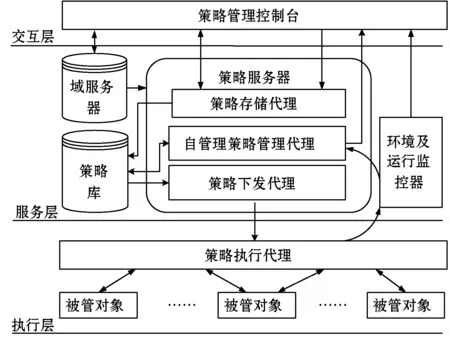
图2 分布式策略自管理框架
该框架共分三层:交互层、服务层和执行层。
交互层提供人机接口,管理员通过策略管理控制台制定策略,实现与服务层之间的交互。
服务层提供域服务[8]、策略服务、策略下发服务以及环境与运行监控。域服务在概念上与目录服务类似,管理分布式层次结构的域对象,能够在运行时定位策略作用目标,因此采用域服务器为策略服务器提供域服务。策略库用于策略的存储,既存储可以被执行的基本策略,也存储元策略,元策略历史数据为自管理策略管理代理自学习变更新的元策略提供支撑。策略服务器包括三个模块,其中,策略存储代理将策略存入策略库;自管理策略管理代理执行算法,根据环境变化动态变更元策略;策略下发代理根据元策略将基本策略下发到策略执行代理。环境及运行监控器捕捉环境变化信息并提供给自管理策略管理代理,同时,它还对策略在执行代理的执行情况进行审计并将策略执行情况以及策略作用效果反馈给策略管理控制台,管理员可根据反馈结果对策略进行调整。
执行层负责策略的具体执行。策略执行代理综合了策略决策点PDP和策略执行点PEP,作为守护进程驻留在被管对象上。在完成策略执行任务的同时监控环境信息并反馈策略执行情况。
与IETF策略管理框架相比,分布式策略自管理框架有以下改变:①将PDP部署到PEP并与之结合,将集中式决策改为分布式决策,实现了分布式策略管理;②引入域服务,为分布式管理提供便利;③增加了自管理策略管理代理和环境及运行监控器,实现捕捉环境变化信息,并根据环境变化动态变更元策略从而实现基本策略的动态调整。
已有的策略管理框架要实现策略自管理,需要根据策略自管理框架进行升级。
对策略自管理框架而言,元策略的动态变更是其正常运行的关键。
2 元策略管理机制
元策略是环境与基本策略之间的桥梁。不同环境需要不同的基本策略共同作用,这些基本策略数量庞大,环境状况改变时必须对所有基本策略进行动态调整,实施难度较大且易出错。元策略可以有效解决这一问题。元策略管理基本策略,将基本策略按照一定规则组织起来,实现特定环境状态对应少量元策略,而这些元策略管理达到该环境状态安全需求的全部基本策略。环境改变时只需变换少量元策略就可实现全部基本策略的变更,这种方式高效且不易出错。
为了更加清楚地描述元策略的桥梁作用,采用形式化的方式进行描述。
元策略管理基本策略,设Mi表示任意元策略,Pj表示任意基本策略,符号→表示管理关系,则元策略与基本策略的逻辑关系可表示为Mi→{Pi1,Pi2,…,Pij}。元策略之间的关系满足:
不同元策略可能管理相同基本策略:
∃Mi,Mj,stMi∩Mj=Pi
不同元策略的组合实现不同基本策略的组合:
{Mi,Mj}=Mi∪Mj={Pi1,Pi2,…,Pim}∪{Pj1,Pj2,…,Pjn}
设Ei表示环境状态,Ei={ei1,ei2,…,ein},eij表示环境属性,多个环境属性标识一种环境状态。Ei≈{M1,M2,…,Mn}表示Ei环境状态对应元策略集合{M1,M2,…,Mn}。另外,Ei与Mi的关系还满足:
∃Ei,Ej,stEi∩Ej=Mi
即有的元策略适用于多种环境状态下,实现了元策略的复用。
通过元策略的桥梁作用,环境状态与基本策略的关系可表示为:
Ei≈{M1,M2,…,Mn}={P11,P12,…,P1m}∪…
∪{Pn1,Pn2,…,Pnn}
为了更方便描述元策略与环境状态的关系,引入安全等级,不同的环境状态对应不同的安全等级,不同安全等级需要不同安全策略。当环境变化时,安全等级随之改变,安全策略也需要动态更新调整。
不同环境状态对应着不同的元策略,当环境状态改变元策略随之改变,元策略所对应的基本策略也要动态调整。然而,某种环境状态可能重复出现,即该种环境状态所对应的元策略重复出现,元策略所管理的基本策略重复生效。为了避免重复下发相同策略,为基本策略引入策略状态,基本策略一旦下发,通过改变状态来决定是否生效。
基本策略维持初始、休眠、启用、删除四种状态,这四种状态之间的转换关系如图3所示。由管理员制定的新的基本策略存储于策略库中处于初始态。初始态的策略被下发到策略执行点并执行,策略处于启用态。启用态的策略可以被禁用,禁用后处于休眠态,休眠态的策略可以被启用。被删除的策略不会立即从策略库中移除,此时的策略被标记为删除态,经过一个时间周期,对策略库进行更新才会将处于删除态的策略从策略库中移除。

图3状态转换图
元策略是基本策略的策略,包含五种元素,元策略可以表示为:MetaPolicy=
当外界环境发生改变,通过环境属性判断出安全等级,根据安全等级及作用目标找到相应的元策略,若元策略处于初始态,则将元策略管理的基本策略下发并启用,同时将元策略状态改为启用态并将前种环境对应的元策略状态改为休眠态;若元策略为休眠态,则基本策略已下发处于休眠态,将元策略管理的基本策略启用并将元策略状态改为启用态并将前种环境对应的元策略状态改为休眠态。
3 基于改进的ID3算法的策略自管理算法
如何实现根据环境状态的改变动态地变更元策略是实现策略自管理的关键。为了解决这个问题,设计了基于改进的ID3算法的策略自管理算法。
3.1ID3算法简介
机器学习[9]是研究计算机模拟人类的学习行为,通过重新组织已有的知识结构以获取新的知识或技能,实现不断改善自身能力的一种方法,决策树学习是机器学习的一种,而ID3算法[10]是决策树学习的核心算法。
ID3算法是基于信息熵的决策树分类算法,其核心思想是检测所有属性并根据属性值的取值判断实例的类别,选择信息增益最大的属性作为决策树的节点,对各分支的子集递归找出属性和类别间的关系,最终生成一棵决策树。
设S为一个包含n个数据的样本集合,假设目标类属性具有m个不同的取值{C1,C2,…,Cm}。设Si为类别Ci中样本数,对一个给定样本分类所需的信息熵为:
其中,Pi=Si/S为任意样本属于Ci的概率。
如果以属性A作为决策树的根,设属性A取n个不同的值{a1,a2,…,an},它将集合划分为n个子集{S1,S2, …,Sn},若属性A被用于对当前样本集进行划分,则所期望的信息熵为:
则在A分支上的信息增益为:
Gain(S,A)=E(S)-E(S,A)
ID3算法对信息熵的计算依赖于特征取值较多的特征属性,这样并不合理。采用简单的方法对特征值进行分解,虽然特征取值数目不同,但可以把它们全部转换成二值特征。例如,年龄取值大、小可以分解为两个特征:年龄—大、年龄—小,取值均为是(Y)或否(N)。这样可以避免出现偏向于取值较多的属性的现象。
3.2基于改进的ID3算法的策略自管理算法

算法:基于改进的ID3算法的策略自管理算法
训练集由环境信息及相应元策略组成,对训练集进行自学习,计算各属性的信息增益,其中,此处的属性为原属性进行二值属性转化后的属性。选择信息增益最大的属性作为分类节点,判断各属性取值的信息熵,若为0则生成叶子节点,否则继续迭代判断其余属性的信息增益及其属性值对应的信息熵,最终得到决策树。环境监控器监控环境状况,当环境发生改变时,捕捉环境信息得到环境属性E,遍历决策树,得到该环境下的安全等级,根据安全等级和策略作用对象到策略库中检索到相应元策略并将元策略状态变更为启用。查询数据库,根据元策略定位到基本策略并将基本策略下发执行,实现了根据环境变化变更元策略,进而调整基本策略以适应环境的变化。
4 实验及分析
针对以上研究成果,为了验证有效性,从元策略支持策略描述语言的描述以及算法有效性两个方面进行验证。
4.1元策略对Ponder支持的验证
策略管理框架的运行需要策略描述语言的支持,元策略作为实现策略自管理的基础,必须能够用策略描述语言进行描述。以Ponder为例进行验证。
Ponder是一种声明性的面向对象的策略描述语言,以授权策略为例,其语法格式为:
inst (auth+|auth-) policyName{
subject domain-Scope-Expression;
target domain-Scope-Expression;
action action-list;
[when constraint-Exprssion;]
}
inst声明描述的是策略实例,auth+|auth-表示策略类型,大括号内是策略元素的声明。
Ponder本身支持元策略,但那种元策略是为解决冲突的,本文所指元策略可用Ponder描述为:
inst (meta) policyName{
TargetTarget-Expression;
TargetPolicyTargetPolicy-Expression;
Security_LevelLevel-Expression;
StateState-Expression;}
其中,policyName即为元策略标识。
为了使Ponder部署框架实现策略自管理,需要对其框架进行升级,增加自管理策略管理代理和环境及运行监控器模块。
除了Ponder,元策略也可实现对其他策略描述语言的支持且部署框架经过升级后能支持策略自管理。
4.2基于改进的ID3算法的策略自管理算法验证
下面的实验是根据环境属性来确定安全等级,进而确定元策略。环境属性包括多个非类别属性,本实验根据攻击威胁、流量情况、时间、操作类别四个非类别属性确定类别属性安全等级。
非类别属性及取值如表1所示,全体训练集如表2所示。

表1 属性及取值

表2 样本训练集
对于上述训练集,令类别属性信息熵为A,安全等级高记为p1,p1的个数是12,安全等级低记为p2,p2的个数是12,类别属性的信息熵是:
E(A)=-P(p1)log2P(p1)-P(p2)log2P(p2)=1.0000
二值转化后的非类别属性信息熵计算方式为(以“攻击威胁=无”为例):
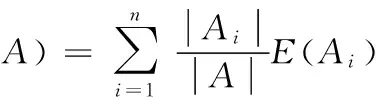
信息增益量:
Gain(攻击威胁=无,A)=E(A)-E(攻击威胁=无,A)
=0.6283
分别计算其余10种情况信息增益并比较,Gain(攻击威胁=有,A)的值最大,所以说明“攻击威胁=有”的信息对于分类的帮助最大,因此选择“攻击威胁=有”作为测试属性。
根据算法递归计算,可以得到一棵二叉树决策树,如图4所示。

图4 二叉树决策树
为方便实验,策略作用对象采用单一目标T,相关元策略如表3所示,省略了策略目标以及元策略状态。
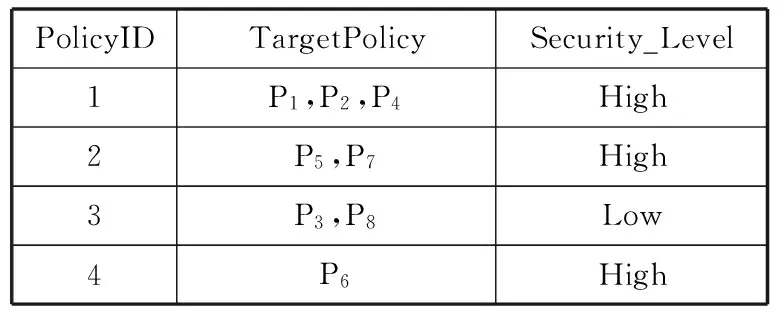
表3 元策略表
根据环境的改变,得到的基本策略如表4所示。
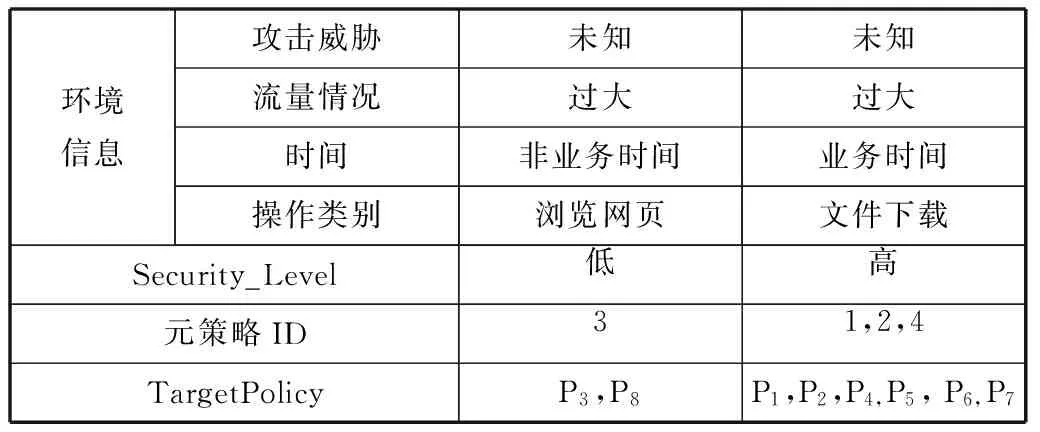
表4 环境信息及基本策略
实验数据显示,该算法能够根据环境变化变更元策略并最终实现基本策略的动态变化。
4.3实验分析
以上两方面的验证,显示了元策略方式的可行性以及自管理算法的有效性。元策略支持策略描述语言的描述,已有策略管理框架经过升级以及其策略描述语言包含增加对元策略的描述后,便可进行策略自管理。改进的ID3算法对数据进行自学习,得到分类决策树。同时,根据目标环境状态得到安全等级及相应元策略,最后,根据元策略管理相应基本策略。
通过元策略管理基本策略,元策略随环境动态改变而改变,进而实现基本策略的改变。有效减少了根据环境动态变化逐条改变策略所带来的时间消耗。
ID3算法用来构建决策树,传统的ID3算法以信息熵作为属性选择标准,而信息熵的计算依赖于取值较多的特征,这样就会出现属性偏向[11]问题。本文采用改进的ID3算法,在进行安全等级分类时采用二叉树存储,有效地避免属性偏向问题。
5 结 语
本文针对目前策略管理需要管理员手工操作无法应对分布式环境动态多变的问题提出一种分布式策略自管理方法,该方法适用于目前多数策略管理框架。引进元策略对基本策略进行管理,通过基于改进的ID3算法的策略自管理算法实现根据环境变化动态地改变元策略进而改变基本策略。
目前策略自管理算法虽然对ID3算法进行改进,但还不够成熟,下一步将对策略自管理算法进行改进。
[1] Weili Han, Chang Lei. A Survey on Policy Languages in Network and Security Management [J]. Computer Networks, 2012, 56:477-489.
[2] Erik Rissanen. eXtensible Access Control Markup Language(XACML) Version 3.0[S]. OASIS, 2013.
[3] Daniel Diaz Lopez, Gines Dolera Tormo, Felix Gomez Marmol, et al.Managing XACML systems in distributed environments through Meta-Policies[J]. Computers & Security, 2015,48:92-115.
[4] Nicodemos Damianou, Naranker Dulay, Lupu E, et al. Ponder:A Language for Specifying Security and Management Policies for Distributed Systems[R]. London:Imperial College of Science Technology and Medicine,2000.
[5] Abdur Rahim Choudhary, Bel G Raggad. Digital Policy Management Requirements and Architecture[C]//IEEE International Inter-Disciphinary Conference on Cognitive Methods in Situation Awareness and Decision Support. The United States :2014:144-150.
[6] Yeom G, Tsai W T, Tseng Y, et al. A dynamic policy management framework in service-oriented architecture[C]//Networked Computing and Advanced Information Management (NCM), 2011 7th International Conference on. IEEE, 2011:35-40.
[7] 杨明. 分布式环境下的安全策略关键技术研究[D]. 吉林大学, 2011.
[8] Sonkoly B, Czentye J, Szabo R, et al. Multi-Domain Service Orchestration Over Networks and Clouds:A Unified Approach[C]//Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication. ACM, 2015:377-378.
[9] 何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014, 27(4):327-336.
[10] 王小巍, 蒋玉明. 决策树ID3算法的分析与改进[J]. 计算机工程与设计, 2011, 32(9):3069-3072.
[11] 喻金平, 黄细妹, 李康顺. 基于一种新的属性选择标准的ID3改进算法[J]. 计算机应用研究, 2012,29(8):2895-2898.
A METHOD OF SELF-MANAGEMENT FOR DISTRIBUTED POLICY
Ma ZengbangYang YingjieDai XiangdongLiu Jiang
(InformationEngineeringUniversity,Zhengzhou450001,Henan,China)
Nowadays, distributed policy management relies on administrators to configure and distribute policies manually, it is difficult to update policy timely and accurately in order to adjust the dynamic policy management in changing dynamics distributed system environment. Towards this issue, the distributed policy self-management framework based on meta-policy is proposed, and the policy self-management algorithm based on improved ID3 algorithm is designed to achieve meta-policy adjusting dynamically with the changing of environment information, so as to realize the basic policy updating and adjusting dynamically. Finally, the experiment verifies the feasibility and effectiveness of this method.
Policy managementSelf-management frameworkMeta-policy Improved ID3 algorithm
2015-11-24。国家高技术研究发展计划项目(2012A A012704)。马增帮,硕士生,主研领域:网络安全与策略管理。杨英杰,副教授。代向东,讲师。刘江,博士生。
TP393.08
A
10.3969/j.issn.1000-386x.2016.08.059
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
燕山大学学报(2015年4期)2015-12-25
雷达与对抗(2015年3期)2015-12-09
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
