
高校云数据中心基于蚁群算法的资源调度研究
2016-09-09 02:51战非
电子设计工程 2016年16期
战非
(西安航空学院 计算机学院,陕西 西安 710077)
高校云数据中心基于蚁群算法的资源调度研究
战非
(西安航空学院 计算机学院,陕西 西安710077)
针对构建高校云计算数据中心的目的出发,对基于蚁群算法的云计算资源调度进行研究。通过云仿真软件CloudSim进行仿真实验,证明蚁群算法在多任务执行时间及相对标准差方面优于传统资源调度算法。
云计算;数据中心;蚁群算法;CloudSim
数字化校园建设作为高校发展的重要环节,越来越受到广泛的重视。但是随着建设的深入,数据量和信息量都海量的增加,高校现有及新建各系统之间无法做到资源共享,硬件设备利用率不高等问题也显现出来,于是高校数据中心应运而生,通过建立高校数据中心,可以实现教务、后勤、学生管理等各个职能部门数据的统一存储、统一管理和资源共享,极大地提高使用效率。
云计算作为一种新兴的计算模式,主要应用于互联网中,将基础资源设施、应用系统、软件平台等作为服务提供给用户[1-2]。同时云计算也是一种基于虚拟化为基础的架构方式,能够将大量资源进行虚拟化,构建庞大的的资源池,对外以服务方式进行管理。
如上所述,构建基于云计算的高校数据中心便于解决传统模式下数据中心的不足,可以实现对数据和资源更加统一的、高效的管理,为高校各部门之间的数据共享提供便利。云计算数据中心工作过程中,任务调度和资源分配是至关重要的环节,文中主要讨论如何基于蚁群算法对云计算中资源进行调度,进行仿真实验并分析结果。
1 构建高校中基于云计算的数据中心
1.1云计算高校数据中心的建设目标
基于云计算的高校数据中心,在保留传统数据中心的特点之上,对数据的存储和管理提出了更高的要求,建设云计算数据中心应从以下几个方面着手:
1)硬件方面,建立一定规模的机房,实现完备的硬件设施及充足的带宽,以扩展性强,能耗较低,安全可靠为基础。能够满足学校中不同职能部门的服务要求。
2)数据存储方面,建立集中管理、安全性强的统一数据存储平台,能够保证数据更新的实时性,具有完整的重要数据的备份及容灾机制。
3)网络服务方面,能够为学校各项工作提供持续不间断的网络服务,具有良好的监测机制和故障预防机制。
1.2云计算数据中心体系架构
图1给出了云计算数据中心体系中分层管理中的4个核心要素。
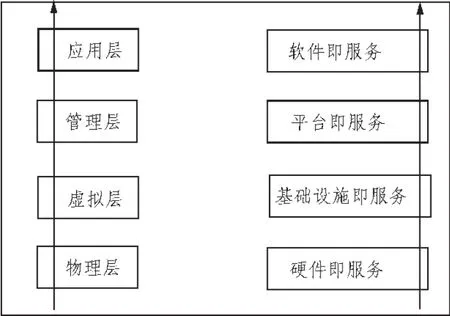
图1 云计算数据中心架构图
物理层,也称为HaaS(Hardware as a Service,硬件设施即服务)[3]。作为云数据中心的底层,主要针对硬件设施,如具有设施齐备的一定规模的机房等;
虚拟层,该层也称为IaaS(Infrastructure as a Service,基础设施即服务),将物理层硬件(包括存储设备、服务器和网络设备等)进行全面虚拟化,构建可共享的按需分配的基础资源设施;
管理层,该层是数据中心的决策层,可称为PaaS(Platform as a Service,平台及服务),它将计算平台作为一项服务,以虚拟化为基础,统一对用户、安全、任务资源等进行管理;
应用层,可称为SaaS(Software as a Service),本层是高校中直接面对用户的接口层,应该具有友好的便于操作的界面,为学校不同部门的需求提供按需获取的云计算服务。
2 任务调度在云计算中的应用
云计算的优势体现在更强的计算能力和更高的计算效率,可以为用户提供更优质的服务,而云计算中资源分配策略和任务调度策略是实现这些优势的基础。
2.1任务调度概念
调度问题指的是,在满足一定的约束规则条件下,根据提前制定好的资源分配策略对单个或者多个并行的任务进行分配,以最短处理时间和提高处理性能为目标,分配给各个处理节点按一定的顺序执行任务。
调度系统的好坏基于两个基本元素,分别是性能和效率。调度算法作为调度系统的基础,算法本身的效率和调度质量至关重要。针对云计算的特点,需要选择更高效的算法来支持。
2.2任务调度策略分类和算法
任务调度以种类划分,可以分为静态调度和动态调度。静态调度策略应用较为简单但效率往往比较低下;动态调度策在云计算中要充分考虑不同计算节点自身的处理能力,还要结合硬件条件、服务费用等各个因素,最终寻找一个具有最优组合的节点,然后将任务进行分配。实际应用中,我们也可以将动态和静态两种调度结合起来作为混合调度方式使用。
针对任务调度的经典算法比较多,从系统角度出发希望每个进程能较为公平的被执行,具有较大的吞吐量。从用户角度出发,希望响应速度较快,执行时间较短。常见的算法有FIFO算法,Dijkstra算法,Round Robin算法等。但是在云计算中有其自身的特点,需要对异构基础资源的支持,以分布式计算为基础,所以我们也多以启发式算法来进行任务调度。所谓启发式算法指:基于直观或经验构造的算法,在一定计算条件的约束下,给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度通常不可预计。较为常用的算法有模拟退火算法、禁忌搜索算法、人工神经网络遗传算法、蚁群算法等。本文的重点就是讨论蚁群算法的模型和在云计算中的应用。
3 基于蚁群算法的资源调度分析
3.1蚁群算法基本原理
蚁群算法来源于自然界蚂蚁种群觅食现象,蚁群在未知食物在什么地方的前提下开始寻找食物,当个体蚂蚁找到食物后,在其经过的路径上会释放一种挥发性分泌物,我们称之为信息素,信息素浓度的大小表征路径的远近。其他蚂蚁在寻找食物的过程中,在一定范围内感知信息素的强弱,永远朝着信息素浓度较多的方向移动,经过一段时间运行,可能会出现一条最短的路径,大多数蚂蚁依照此路径运动[4-5]。
蚁群算法本质是一种随机搜索算法,具有以下行为规律:
1)随着时间的增长,每条路径上的信息素浓度在不断变化,某些路径信息素不断累积,某些路径不断挥发,蚂蚁根据信息素浓度以一定的概率来选择下一条路径。
2)为规避蚂蚁停滞不前在本地打转,用一个禁忌表来记录已经走过的路径,通过禁忌表剔除本次循环已经走过的路径。
3)当单个蚂蚁走完某条路径后,都会以路径长度为根据释放相应浓度的信息素,被走的多的路径信息素浓度逐渐增大,走的少的信息素浓度不断挥发,这将作为其他蚂蚁选择此条路径的概率的依据。
3.2蚁群算法数学模型
设将M只蚂蚁放入到N个随机选择的地点,蚂蚁k(k= 1,2,…,m)行进规律根据信息素浓度决定,总是向着浓度高的路径运动。
开始时期,蚂蚁随机选择一条路径,因为此时各条路径上的信息素浓度基本相同,使用禁忌表tabuk(k=1,2,…,m)来记录蚂蚁k所走过的路径,该表将根据蚂蚁运动的过程实时进行调整,用(t)来表示在t时刻蚂蚁k选择地点j作为目标的
状态转移概率:
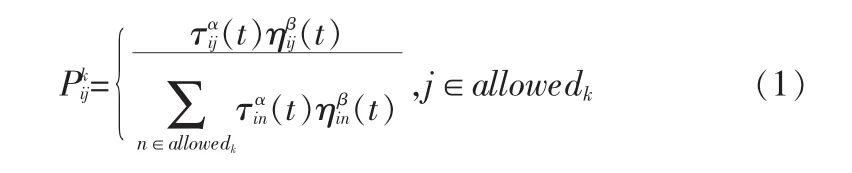
其中:
allowedk表示蚂蚁k下一步可以选择的地点。
τij(t)表示地点i到地点j的路径在t时刻的信息素量。
ηij(t)表示经地点i行进至地点j的初始信息,该信息由所求解问题得到。为地点i到地点j的先验值,dij表示地点i和j之间的距离。
α代表信息启发因子,其值越大代表当前路径越重要,蚂蚁就更倾向去选择该条路径。这里我们设α=1。
β为期望启发因子,代表蚂蚁根据起发信息去选择路径过程中受影响的程度,表示计算能力预测值的相对权重。这里我们设β=5。
在实际计算过程中,需要对路径上残余信息量动态处理,因为随着蚂蚁搜索过程的进行,路径上聚集越来越多的信息素将会淹没启发信息。所以当蚂蚁k完成一条路径或者走完多个地点后,需要更新信息素浓度,这里通过如下规则来调整路径(i,j)在t+n时刻的信息量:
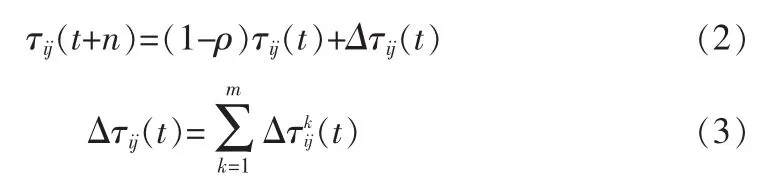
其中:
ρ表示信息素挥发系数,则1-ρ表示信息素残留因子,规定ρ的取值范围为ρ⊂[0,1],为防止信息素随时间进行无限聚集,这里取ρ=0.5。
Δτij(t)代表蚂蚁从t时刻到t+n时刻,从地点i到地点j路径上信息素的增量。初始时刻Δτij(0)=0。
其中:Q表示信息素强度;Lk表示蚂蚁k在当前循环中走过的路径总长度。
4 CloudSim仿真及结果分析
4.1蚁群算法调度流程
用蚁群算法进行调度,首先对并行的所有用户任务分类,并且给出优先级顺序,因为这样才能体现出不同任务对应不同服务质量的要求。然后依据算法进行资源分配与调度,当算法找到符合服务要求的最优路径,提供资源并进行绑定,开始执行。流程图如图2所示。
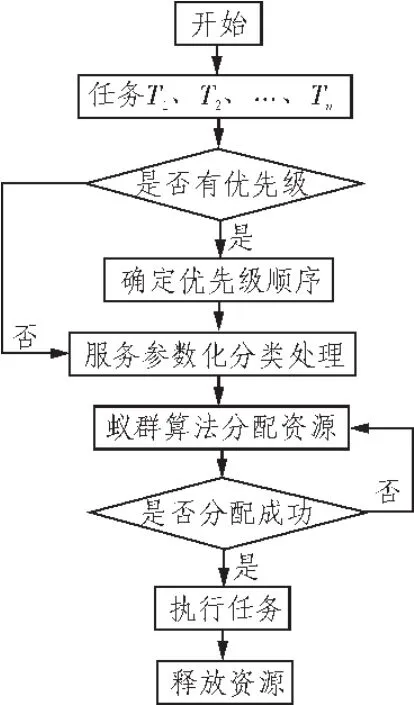
图2 蚁群算法资源调度流程图
4.2仿真测试过程
CloudSim仿真经过的步骤包括:首先新建数据中心,然后确定模拟资源参数,通过DatacenterBroker类的对象建立代理,由此代理负责信息的交互,然后创建虚拟机开始执行云任务,最终获取结果。
以下代码为仿真过程中的核心类中截取的主要流程代码,代码注释体现了整个仿真过程的具体步骤,调用方法中的一些仿真参数如带宽(bw),内存(ram),PE数(pesNumber)等等的定义语句,由于篇幅限制这里省略不写,这些参数的取值根据常规虚拟机硬件水平设置[7-8,11]。
/**初始化CloudSim,新建数据中心dt1及数据中心代理,获得ID*/

/**新建虚拟机列表,根据要仿真的虚拟机规格参数(id、PE数量、MIPS速率、内存、带宽等等)创建虚拟机vm,并提交代理*/

/**建立云任务列表,根据仿真参数(ID、PE数量、文件大小等)新建一个云任务并添加进列表,列表的创建及添加代码省略*/

4.3实验结果及分析
通过在CloudSim中进行实验,设定执行的任务数为20~100,计算节点数为10个。为了说明蚁群算法在云计算中应用的效果,选取了FIFO算法和Dijkstra算法这两种传统算法作为对比。执行10次取平均值,执行任务所需时间如图3所示。
通过该图我们分析出,当任务量较少时3种算法完成任务时间基本相同,但是随着任务量的增加,实验表明过蚁群算法完成所有任务时间要优于另外两种算法。为了更进一步的展示几种算法的区别,对任务分配的结果的相对标准差值进行计算,如图4所示。
通过该图显示,当任务数增加,蚁群算法的偏差值越来越小,且趋于线性渐进,明显优于其他两种算法。
通过以上分析,云计算的特点就是并行处理大量任务,通过蚁群算法进行资源调度可以适应常规云计算的要求。
5 结束语
云计算作为一种蓬勃发展商业计算模式,建立在将大量资源虚拟化的基础上,可以统一对高校的数据进行管理,根据用户对作业量的需求提供服务。文中给出高校中云计算数据中心的构建体系模型,重点讨论应用蚁群算法在云计算中进行作业调度和资源分配的问题,通过CloudSim仿真实验,从结果上对比了两种传统调度算法。最终证明该算法符合一般云计算任务调度和资源分配的要求。

图3 任务执行时间结果图
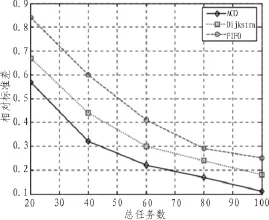
图4 相对标准差结果图
[1]陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009 (9):2563-2564.
[2]刘正伟,文中领,张海涛.云计算和云数据管理技术[J].计算机研究与发展,2012,49(z1):56-27.
[3]孟湘来.基于云计算的数据中心构建探析[J].中国企业教育,2012(22):240-241.
[4]刘鹏.云计算[M].北京:电子工业出版社,2010.
[5]吴斌,史忠植.一种基于蚁群算法的TSP问题分段求解算法[J].计算机学报,2001,24(12):1329-1330.
[6]宋雪梅,李兵.蚁群算法及其应用[J].河北理工学院学报,2006,28(1):42-43.
[7]Ran S A.A model for web service discovery with QoS[J]. ACMSIGCOM Exchanges.2003,4(1):1-10.
[8]Buyya R,Murshed M,GridSim:A Toolkit for the Modeling and Simulation of Distributed Resource Management and Scheduling for Grid Computing[J].The Journal of Concurrency and Computation:Practice and Experience(CCPE),2002(14):13-15.
[9]Buyya R,Yeo CS,Venugopal S.Cloud Computing and E-merging IT Platforms:Vision,Hype and Reality for Delivering Computing as the 5th Utility[J].Future Generation Computer Systems,2009(25):599-616.
[10]Buyya R,Murshed M.GridSim:a toolkit for the modeling and simulation of distributed resource management and scheduling for Grid computing[J].Concurrency and Computation: Practice and Experience,2002(14):1175-1220.
[11]Buyya R,Ranjan R,Calheiros RN.Modeling and Simulation of Scalable CloudComputingEnvironmentsandthe CloudSim Toolkit:Challenges and Opportunities[J].Proc. of the 7th High Performance Computing and Simulation Conference(HPCS 09),IEEE Computer Society,2009.
[12]Gustedt J,Jeannot E,Quinson M.Experimental methodologies for large-scale systems:a survey[J].Parallel Processing Letters,Sep.2009(19):399-418.
[13]TANG Wen,CHEN Zhong.Research of Subjective Trust Management Model Based on the Fuzzy Set Theory[J]. Journal of Software,2003,14(8):1401-1408.
[14]LIU Shi-Kao,LIU Xing-Tang.A New Method of Elevation of Confidence Level ofLarge-ScalePerplexingSimulation System[J].Journal of System Sim4ulation,2001,13(5):666-669.
[15]Fay Chang,Jeffrey Dean,Sanjay Ghemawat et al.BigTable: a distributed storagesystemforstructureddata[J]. Operating Systems Design and Implementation,2000.
A research on resource scheduling based on ant-colony algorithm in cloud-based data center of colleges and universities
ZHAN Fei
(School of Computer Science,Xi'an Aeronautical Universities,Xi'an 710077,China)
For the purpose of constructing the cloud computing data center of colleges and universities,this article mainly focuses on cloud computing resource scheduling based on ant-colony algorithm.The proposed resource scheduling has been verified by CloudSim simulations.The simulation results reveal that both the multitask execution time and the relative standard deviation of our proposed resource scheduling based on ant-colony algorithm are to the traditional resource schedulings.
cloud computing;data center;ant-colony algorithm;cloudSim
TN91
A
1674-6236(2016)16-0018-04
2016-01-13稿件编号:201601092
国家自然科学基金项目(71373203)
战非(1981—),男,陕西西安人,硕士,讲师。研究方向:软件工程、软件开发、移动互联网应用。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
建材发展导向(2021年7期)2021-07-16
数字通信世界(2020年3期)2020-04-06
西藏艺术研究(2019年1期)2019-09-04
制造技术与机床(2019年4期)2019-04-04
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
现代防御技术(2016年1期)2016-06-01
信息通信技术(2015年6期)2015-12-26
中国交通信息化(2015年3期)2015-06-05
