
基于Logistic回归的犯罪概率预测研究
2016-10-24 02:16杜益虹刘世华
绍兴文理学院学报(自然科学版) 2016年2期
杜益虹 刘世华,2
(1.温州职业技术学院 信息技术系,浙江 温州325035;2.浙江工业大学 计算机科学与技术学院,浙江 杭州310023)摘 要:国内能够指导基层公安机关工作的犯罪微观预测研究甚少.基于Logistic回归模型构建了一个犯罪概率预测模型,对模型指标体系选取、数据预处理、模型训练等关键问题进行了重点研究,并进行了理论检验和实证分析证明.
基于Logistic回归的犯罪概率预测研究
杜益虹1刘世华1,2
(1.温州职业技术学院信息技术系,浙江温州325035;2.浙江工业大学计算机科学与技术学院,浙江杭州310023)摘要:国内能够指导基层公安机关工作的犯罪微观预测研究甚少.基于Logistic回归模型构建了一个犯罪概率预测模型,对模型指标体系选取、数据预处理、模型训练等关键问题进行了重点研究,并进行了理论检验和实证分析证明.
犯罪预测;犯罪概率;Logistic回归
0 引言
目前,我国正处于公安信息化和“情报信息主导警务”深入发展的关键时期.在整个“情报主导警务”的工作模式中,犯罪情报的分析研判是一个核心环节[1],犯罪预测则是其中的重中之重.
国外对于犯罪预测的研究主要采取实证的方法,通过调查、数据收集、分析、归纳,得出重要的相关因子,从而揭示犯罪发生的规律[2].其多数偏重微观预测领域并与地理信息结合起来,对民警日常工作起到了良好的辅助作用.
我国犯罪预测研究起步较晚,已有对犯罪预测的研究多偏重于“大而全”的宏观预测和长期预测,对短期微观预测重视不够,并且很多只是一些定性研究或个人主观经验总结[3].而短期微观预测是大量基层警务部门所需要的情报,用户更多更广泛,对推动情报主导警务有着更为重要的作用[4].
犯罪微观预测主要有累犯预测和犯前预测[5].重点人员的犯前预测和管控历来是公安工作的一大重点,如何在现有警力的基础上对大量重点人员进行有针对性地管控,始终是困扰各地公安机关的一大难题.
本文提出了一种基于Logistic回归分析的犯罪嫌疑概率预测模型,该模型通过对一线公安部门已抓获的犯罪人员的属性信息和活动轨迹等历史数据进行清理转换,然后采用Delphi专家分析法和特征提取方法提取出犯罪预测的主要技术指标,最后采用Logistic回归分析法构建出犯罪嫌疑概率预测模型.
该模型将公安情报信息部门采集的情报进行分析后,能够得出某个人犯某种罪的概率,且根据概率值大小排序,给出某类案件最有可能犯罪的人员名单等信息,以指导公安机关的警力部署,提高出警效率和质量.
通过该预测模型构建的智能系统能定期自动筛选出一批值得重点怀疑的对象进行重点管控,无疑会减轻基层民警工作的压力和减少工作部署的盲目性,从而在一定程度上解决我国基层警力严重不足的问题.目前该模型在某区公安情报信息中心得到了应用,并协助当地公安机关抓获了数名重要的犯罪嫌疑人.
1 相关研究
早在1928年,美国芝加哥大学E·W·伯吉斯教授对伊利诺斯州三个矫正机构所假释的三千名罪犯所作的释后研究,设计了假释成败的关联表,形成了伯吉斯犯罪预测法.1950年美国哈佛大学教授格卢克夫妇提出了格卢克少年犯罪早期预测法.近几十年来,回归分析、博弈论、人工智能、神经网络、群集智能、灰色理论、数据挖掘等技术在犯罪预测中得到广泛的应用,2010年,美国警察开始使用一套投资超过110亿元的“犯罪预测”软件[6].该软件可以通过测定目标对象的脸部特征、言行举止、个人经历、社会关系、习惯嗜好、结交圈子等,来精确测定哪些是犯罪嫌疑人,帮助警方提前预警.
学术上,Hsincbun[7]利用聚类分析,识别具有相似犯罪行为的犯罪嫌疑人.Ma[8]等人为了发现大量案件数据集中作案特征相似的案件,提出了两阶段的聚类算法AK-Modes,首先使用信息增益率(IGR)计算与该犯罪嫌疑人相关的案件的作案特征的属性权值,然后将重新设定好权值的属性利用聚类算法运行得到相似的案件集合.Bruin[9]等人开发了一个用于决策犯罪嫌疑人行为趋势变化的工具,主要考虑了犯罪类别、犯罪频率、持续时间、严重程度这四个因素,并应用新的距离度量公式计算嫌疑人个体之间的相似程度,从而实现聚类的效果.Jin[10]等人从已知的犯罪嫌疑人员信息表以及其犯罪程度,采用决策树算法对嫌疑人犯罪风险进行预测.Xu[11]利用社会关系网络分析,通过构建由犯罪嫌疑人之间的角色和关系组成的社会关系网络,分析该网络可挖掘出的关键人物以及犯罪团伙等.LDing[12-13]等人首先开发了LETS((Law Enforcement Tactical System)和Relation Finder的社会网络分析系统,并在此基础之上提出了“PerpSearch”的嫌疑人预测系统,该系统综合考虑包括犯罪地点、犯罪类型、嫌疑人的外形描述等犯罪信息.由于国家安全和技术保密等原因,国内无法直接利用其成果.
国内犯罪预测研究多为经验预测,进入21世纪后才逐步采用了数理分析的方法,目前主要采用的有回归分析法、灰色系统理论分析法、最优组合分析法等[14].如魏智远采用三元法对刑事案件进行了非线性回归分析[15];韦立华、朱德林提出了犯罪预测的动态回归分析方法[16];刘晓娟、高连生等采用灰色系统理论的分析方法对刑事案件进行了动态分析[17];李明等采用优化组合预测方法对犯罪量进行了动态预测[18];黄超等人对影响盗窃案件的结构因素的重要度进行分析,提出了事故树预测方法[19].但国内这些犯罪预测研究多偏重于宏观领域,为决策者提供某地区某时段某类案件的发展趋势,对基层民警的工作指导意义不明显.
2 犯罪概率预测模型
本文采用Logistic回归分析方法来构建一个犯罪嫌疑概率预测模型,此模型主要解决以下三个问题:指标体系选取问题;特征指标的量化、数值化等数据预处理问题;模型训练构建问题.
2.1指标体系选取
犯罪微观预测系统需要详细分析每一种高发且容易重犯的犯罪行为的历史数据,细究每项数据在其犯罪结果的占比情况,剔除离散的数据,挑选几项关键影响因子组成该类犯罪行为的判断元素.
我们采用Dephi法收集了公安各部门专家的实战经验总结,并通过对获取的数据资料进行了数理统计分析,得出可用于统计和预测的数据包括人员的属性信息,活动轨迹信息和前科记录信息三大类.每类信息中包含若干指标,如人员属性中的性别、年龄、民族、职业等,具体如图1所示.

图1 犯罪嫌疑概率预测模型的指标体系
2.2指标数据预处理
从公安部门获得的原始数据来源各异,表示方式也不同,还有很多字段值缺失,为了保证模型的可靠性和效率,必须对各指标数据进行预处理,主要的处理工作包括如下几类.
(1)数值化赋值
数值化赋值一般对采集数据中的活动轨迹等数据采用连续函数进行转换和归集,同时也可结合部分数据统计信息对采集的一至多项离散数据进行数值化赋值.
对于活动轨迹和前科记录中的时间特征,根据越是近期发生的轨迹越有参考意义,故采用如下连续函数作为时间转换函数:
(1)
其中t为轨迹发生的时间(前科以年为单位,工作以月为单位,生活以天为单位),t0为当前时间.比如对象盗窃前科记录的时间在半年之前,则这条前科轨迹记录可赋值为:p=e-0.5=0.61,而如果是1年前,则p=e-1=0.37.
当数据表中有多条轨迹记录时,可采用多次累积的方法以体现其重要性,即采用公式(2)进行累加计算:
(2)
其中km为专家设定的放大系数, m为前科轨迹条数.比如对象有两次盗窃前科,记录时间在半年和一年之前,则其前科记录赋值为:1.5x(e-0.5+e-1)=1.47.
对于有后验统计概率的特征变量,如旅馆入住时段、网吧入住时段,根据统计可知一些罪犯的入住旅馆高危时段,比如23∶00-24∶00时段内盗窃犯罪分子入住该旅馆的历史统计数据为30%,非犯罪分子为5%,这个时段即为盗窃罪犯高危入住时段.其赋值采用如下公式近似表示:
(3)
其中k1(t)为该案件类型该时段内犯罪分子入住旅馆的比例,k2(t)为该案件类型该时段内正常非犯罪的人入住旅馆的比例.则上述高危时段记录入住记录的赋值为:k1=0.3, k2=0.05,μ=e0.3-0.05=1.28
其他字段的赋值可采用类似函数处理.
(2)数据归约
数据归约的策略主要有数据立方体聚集、维归约、数据压缩、数值压缩、离散化和概念分层.
对于维归约可采用下述的共线性检测或主成分分析等其他属性选择方法进行指标筛选.对于如年龄这样的字段,由于原始数据中是按每1岁进行统计的,在Logistic分析中对犯罪概率的预测没有必要精确到一岁,因此可以将其分为几个大的年龄段,如年龄可分为少年、青年、中年、老年等几组即可.
(3)缺失值处理
数据采集的缺失几乎是不可避免的,公安情报信息中的数据缺失现象尤为严重,据统计,对于个人信息的采集,有些数据的缺失率达到60%以上,而对于任何数据分析、数据挖掘、评估决策系统而言,数据缺失都将对系统效能产生负面影响.
缺失值处理一直是数据分析与数据挖掘领域的一个研究难题,目前常见的处理方法有简单丢弃、插补和不处理三种方法.将含有缺失值的记录简单丢弃通常在样本数据量较大而缺失值较少的情况下使用;不处理缺失值直接在包含空值的数据上进行数据挖掘,这类方法通常在贝叶斯网络和人工神经网络中可用,但对于很多的模型都将影响到模型的准确性和可用性.插补是目前缺失值处理中最常用的方法,其具体算法也非常多,根据数据模型的不同,可以采用人工填充、特殊值/缺省值填充、众数/均值填充、热卡填充以及其他众多的统计和数据挖掘算法来进行填充,如回归法、关联规则法、极大似然法、EM算法、MCMC算法、C&RT算法、多重插补法、Gibbs抽样法等.
对犯罪预测模型构建中所采用的数据集,根据各字段性质和缺失状况不同,主要采用人工填充、特殊值填充、关联规则填充和C&RT算法填充几种,如对于人员身份(缺失19.82%)、婚姻状况(缺失0.3%)、从事职业(缺失9.11%)等分类数据,直接采用一个“未知”类别进行填充;而对于高危时段上网次数、高危时段住宿次数、前科次数等,缺失比例达到67.6%~85.5%,对于缺失数据我们只能当成是未发生这些敏感事件,缺失值直接赋值为“0”.而对于民族数据,由于知道其籍贯地,针对不同籍贯地其属于不同民族的概率不一样,如来自西藏的人属于藏族的居多,因此可根据关联填充民族为“藏族”.
2.3Logistic回归模型
Logistic回归模型是一种广义线性模型[20],广泛应用于流行病学的疾病预测和经济预测领域.最典型的应用如通过病患者的各种属性和症状,预测出患者得某种病的概率是多少.而这种状况与犯罪微观预测中通过嫌犯的各类属性和活动信息(类似疾病症状)来预测其犯罪的概率多少是基本相同的,因此,我们可以利用Logistic回归模型来预测犯罪概率.
设因变量Y是一个二分类变量,其取值为Y=1(表示犯罪)和Y=0(表示不犯罪).
影响Y取值的m个自变量分别为X1,X2,…,Xm.在m个自变量(即暴露因素)作用下阳性结果(即犯罪)发生的条件概率为
(4)
采用Logistic变换,令logit(P)= ln[P/(1-P)],则Logistic 回归模型为:
(5)
经数学变换后,logistic回归模型可表示为:
(6)
其中,β0为常数项,β1,β2,…βm为偏回归系数.
令Z=β0+β1X1+β2X2+…+βmXm,则Z与P之间关系的logistic曲线如图2所示.

图2 Logistic回归模型曲线
从图中可看出,当Z趋于+∞时,P值渐进于1;当Z趋于-∞时,P值渐进于0;P值的变化在0~1之间并且随Z值的变化以点(0,0.5)为中心成对称S形变化.
2.4犯罪概率预测的Logistic回归模型构建
采用公安部门采集的747条嫌犯记录,其中犯罪的记录有377条,对照组无犯罪的记录370条,通过数值填充、缺失值处理、数据归约与转换等预处理过程,去除掉带明显错误的极值或离群值的记录,剩余701条记录作为训练集.
数据处理和Logistic建模采用IBM SPSS Modeler17.0软件平台.训练处理流程如图3所示.
模型训练采用简单的二项式进入法(Enter)简单模式训练法,经训练分析,模型最终选定了文化程度、从事职业、关系人前科次数、民族、前科类型、高危时段上网次数、高危时段入住次数、年龄、婚姻状况、身高等12个指标参数作为预测变量.预测变量的重要性如图4所示.
从模型训练过程可以看出,因变量内部编码与原始编码一致,自变量如民族、前科类型、从事职业、文化程度等名义变量进行了分类变量的编码转换,如图5所示.
经过13次迭代运算,模型参数逐渐收敛到稳定值,于是我们得到最终模型参数.由于篇幅和保密原因,最终获得的模型公式不具体列出,参数截取部分如图6所示.
利用最终的logistic 模型,可以对因变量进行预测,预测结果分类表如表1所示.从表1可以看出,嫌疑指数中观测值为0的359条记录中,预测值有334个0和25个1,预测正确率为93%,观测值为1的342条记录中,预测值有325个1,17个0,正确率为95%,整体预测正确率为94%,预测正确率达到相当高的水平,说明模型具有良好的实用性.

图3 SPSS Modeler中Logistic回归模型训练流程

图4 模型中使用的预测变量重要性
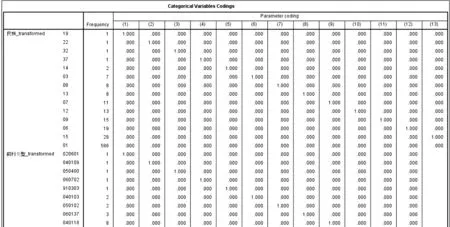
图5 自变量分类变量编码示例

图6 公式中的部分变量参数
表1最终模型的预测分类表

observedPredicted嫌疑指数01PercentageCorrectStep1嫌疑指数03342593.011732595.0OverallPercentage94.
2.5模型的检验
针对步骤、模块和模型开展模型系数的综合性检验.表2的模型系数的混合检验给出了卡方值及其相应的自由度、显著性指标即Sig值.取显著性水平0.05,考虑到自由度数目df=55,可计算出卡方临界值为73.31,当前卡方值765.773远大于临界值,检验通过.
表2模型系数的混合检验

Chi-squaredfSigStep1Step765.77355.000Block765.77355.000Model765.77355.000
表3的模型摘要(Modle Summary)给出最大似然平方的对数、Cox-Snell 拟合优度以及Nagelkerke 拟合优度值,最大似然平方的对数值(-2loglikelihood=205.607)用于检验模型的整体性拟合效果,该值在理论上服从卡方分布,上面给出的卡方临界值为73.31,因此,最大似然对数值检验通过.
表3模型摘要

Step-2LoglikelihoodCox&SnellRSquareNagelkerkeRSquare1205.603a.665.886
似然比函数的自然对数值对样品数目很敏感,作为补充和参照,我们需要Hosmer-Lemeshow 检验.如表4,取显著性水平0.05,考虑到自由度数目df=8,计算得临界值为15.507,作为Hosmer-Lemeshow检验的卡方值4.730<15.507,检验通过.
表4模型的Hosmer-Lemeshow 检验

StepChi-squaredfSig.14.3518.824
3 犯罪概率预测的实战应用
在实战应用中,采用上述获得的Logistic回归分析模型开发了一个预测软件,对犯罪信息进行预测打分,根据得分的高低来预测其犯盗窃罪的概率,其中得分值超过0.5的认为有可能犯罪.通过对计算出来的概率进行排序并结合人工筛查,对排名较高的嫌疑人进行重点查控,指导公安机关抓获犯罪嫌疑人数名.
本文利用上述模型对新采集的93条记录数据(其中犯罪记录74条,未犯罪记录19条)进行了预测验证分析,结果正确率达到97.85%,只有2条记录预测错误,且两条记录均来自未犯罪记录中误判为有犯罪倾向(一条得分0.656,一条为0.986).
从实验检验结果和实战效果来看,本文基于Logistic回归分析构建的犯罪概率预测模型预测准确度高,对公安部门提高犯罪打击的针对性有一定的指导作用.
4 结束语
本文采用Logistic回归分析方法来构建一个犯罪嫌疑概率预测模型.通过实证数据分析可知,模型具有一定的实战指导意义.
模型构建中的主要难点在于采集的原始数据有限,且数据采集质量较差,本文通过一定的手段对数据进行修正、转换和填充.同时,由于数据采集的限制和模型构建过程中的数学检验,模型构建之初通过专家分析出来的所有指标并未全部使用上.关于测试数据集得出的较好的结果,有可能有一定的巧合成分,我们所采集的犯罪数据可能会有一定的同质性倾向.
实战中,随着犯罪数据的增加,所建立的模型需要进一步的改进和学习,通过反馈进行指标调整和重新训练.
[1]马忠洪.我国犯罪情报分析研判研究述评[J].中国人民公安大学学报(社会科学版),2011(4):75-83.
[2]李继红,黄超.中外犯罪预测比较研究[J].学理论,2010(29):155-156.
[3]赵军.我国犯罪预测及其研究的现状、问题与发展趋势--对”中国知网”的内容分析[J].湖南大学学报(社会科学版),2011(5):155-160.
[4]王欣.治安预测方法与技术比较研究[J].中国人民公安大学学报(自然科学版),2011(3):29-35.
[5]陈岳.试论犯罪的微观预测[J].法律学习与研究,1990(01):44-46.
[6]预防犯罪并非天方夜谭教授开发软件助预知犯罪[EB/OL].中国新闻网,2010,http://www.chinanews.com/fz/2010/10-20/2599938.shtml
[7]HSINCBUN C, WINGYAN C, JENNIFER J X. Crim data mining: a general framework and some examples[J]. IEEE Computer, 2004,50-60.
[8]LIANHANG MA,YEFANG CHEN,HAO HUANG. AK-Modes: A weighted clustering algorithm for finding similar case subsets[C]. 2010 International Conference on Intelligent Systems and Knowledge Engineering, 2010, 218 - 223.
[9]J S BRUIN, T KCOCX, W A KOSTERS, et al. Data Mining Approches to Criminal Career Analysis[C]. Proceedings of the Sixth International Conference on Data Mining, 2006, 171-177.[10]JIN G,QIAN J,QIAN J, et al. A Forecasting Model of Crime-risk Using Data-mining Based on Decision-tree[J]. Computer Engineering, 2003,183-185.[11]XU J, CHEN H. Criminal network analysis and visualization[J]. Communications of the ACM, 2005, 107-111.[12]L. DING, DANASTEIL, MATTHEW HUDNALL, et al. PerpSearch: An Integrated Crime Detection System[C]. IEEE International Conference on Intelligence and Security Informatics, 2009, 161-163[13]L DING, B DIXON. Using an Edge-dual Graph and k-connectivity to Identify Strong Connections in Social Networks[C]. in Proc. ACM SE 2008,Auburn, AL, US, 2008.
[14]黄超,李继红.犯罪预测的方法[J].江苏警官学院学报,2011(1):107-110.
[15]魏智远.刑事犯罪回归分析与数量预测[J].公安大学学报,1993(1):47-51.
[16]韦立华,朱德林.犯罪预测动态回归分析方法[J].江苏警官学院学报,2004(3):24-27.
[17]刘小娟,高连生.灰色系统理论在犯罪动态预测中的应用[J].中国人民公安大学学报,2005(1):44-48.
[18]李明,薛安荣,王富强,等.犯罪量动态优化组合预测方法[J].计算机工程,2011,37(17):274-278.
[19]黄超,李继红.盗窃案件的事故树分析[J].江苏警官学院学报,2010(3):135-141.
[20][美]斯科特梅纳德ScottMenard.应用logistic回归分析[M].第二版.李俊秀译.上海:格致出版社,2012.
(责任编辑王海雷)
The Crime Probability Prediction Based on Logistic Regression
Du Yihong1Liu Shihua1,2
(1.Department of Information Technology, Wenzhou Vocational & Technical College, Wenzhou, Zhejiang 325035;2. College of Computer Science & Technology, Zhejiang University of Technology, Hangzhou, Zhejiang 310012)
There is little research on the crime prediction which can guide the work of grass-root public security bureau. Grounded on the logistic regression model, the paper attempts to construct a prediction model of crime probability by studying such key issues as the selection of index system of the model, the preprocessing of the data and the training in accordance with the model, etc. The model is theoretically tested and empirically verified.
crime prediction; crime probability; logistic regression
2016-06-01
浙江省教育厅科研计划项目(Y201329845)
杜益虹(1966-),女,浙江绍兴人,副教授,高级工程师,主要研究方向为信息管理.
10.16169/j.issn.1008-293x.k.2016.08.05
DF792.6;TP301.6
A
1008-293X(2016)08-0024-07
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
学生导报·东方少年(2019年8期)2019-06-11
中国慈善家(2017年6期)2017-07-29
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
