
基于单步添加团的重叠社团检测算法*
2016-10-29 07:37张兴义郑雯王从涛丁转莲苏延森
华南理工大学学报(自然科学版) 2016年9期
张兴义 郑雯 王从涛 丁转莲 苏延森
(安徽大学 计算机科学与技术学院∥生物智能与知识发现研究所, 安徽 合肥 230601)
基于单步添加团的重叠社团检测算法*
张兴义郑雯王从涛丁转莲苏延森†
(安徽大学 计算机科学与技术学院∥生物智能与知识发现研究所, 安徽 合肥 230601)
基于局部扩充的重叠社团检测算法由单个节点或团出发,不断添加新的节点而获得最终的社团划分,但现有算法均为每次添加一个节点,没有充分考虑所添加节点的局部信息,从而影响了社团检测结果的准确性.为此,文中提出了一种基于单步添加团的重叠社团检测算法,该算法从一个团开始,通过不断添加此团邻居内适应度增值最大的团,使算法在局部扩充时不仅考虑了所添加节点与已有社团的连接紧密性,而且考虑了所添加节点内部的连接情况.在真实网络和计算机生成网络上的实验结果表明,与现有基于局部扩充的重叠社团检测算法相比,文中算法可以更准确地检测出复杂网络中的重叠社团.
复杂网络;社团检测;重叠社团;局部扩充
随着信息技术的迅速发展,复杂网络在不同领域中获得了广泛的应用.复杂网络的一个重要研究问题是社团结构检测[1-3],社团结构是指网络中若干个节点的集合,属于同一集合的节点连接相对紧密,不同集合之间的节点连接较为稀疏.社团检测的目的就是要设计合适的算法自动挖掘出网络中存在的社团结构.大量研究发现,网络中的社团往往不是严格独立的,在网络中一个节点往往属于多个社团,例如在社交网络中,一个人经常同时属于家庭、朋友和同事等多个团体,因此便形成了重叠社团结构.目前,对重叠社团结构的挖掘已成为一项热门的研究工作.
近年来研究人员陆续提出了各种策略和思想用于复杂网络重叠社团结构的检测.如基于团渗透理论的复杂网络聚类检测CONCLIDE算法[4-6],基于边和点的信息聚类的NMF算法[7],基于标签传播的BIGCLAM和SLPA算法等[8-10].这些社团检测算法大多关注于如何检测整个网络的全部社团结构,但在许多复杂网络中点和边是动态变化的,导致很难获取网络的全局信息,从而很难对其进行全局社团检测,因此,局部社团检测显得十分必要.不同于全局社团检测,局部社团检测利用网络的局部结构特征进行扩张而得到重叠社团,这类算法大多是从一个初始点开始,通过不断扩充节点来增加社团的规模.
目前,国内外对基于局部扩充的重叠社团检测算法进行了大量的研究,取得了一些阶段性的研究成果.Lancichinetti等[11]提出了基于随机种子扩张的局部优化算法LFM,该算法利用适应度函数局部最优化方法得到网络的划分,既能发现重叠社团结构,又能发现网络的层次结构,但需要通过调节参数α来控制社团的大小从而实现社团层次性的发现.Lee等[12]提出了贪婪团扩充(GCE)算法,它首先确定不同的团作为种子,通过贪婪地优化适应度函数来扩充这些种子,最后得到网络的社团划分,该算法可获得很高的检测精度.Zhang等[13]提出了一种由给定节点找到核心点及其所在团来获得社团划分的方法,实验结果显示该方法具有较高的检测精度,且与初始点位置无关.Chen等[14]提出了改进的局部最大度(LMD)算法,能够更准确地发现局部社团,更有效地探索大型网络的社团结构.
目前基于局部扩充的重叠社团检测算法在扩充社团结构时,每次都只是加入一个节点,而没有充分考虑节点的局部信息,使社团检测结果有待进一步提高.为此,文中提出了基于单步添加团的重叠社团检测(LCCD)算法.该算法通过随机初始节点找到核心节点及其所在团,并以该团作为初始局部社团,在社团扩充过程中充分利用节点的局部信息,每次进行社团扩充时都是加入一个团,而不是只加入一个节点,以确保在社团扩充时充分利用节点的局部信息,使社团划分结果更为准确.
1 算法描述
1.1算法思想及流程
文中算法与其他局部扩充算法最大的不同在于,其每步添加邻域内的一个团而非一个节点,因而不仅考虑了被添加节点与已有社团的连接强度,也考虑了被添加节点内部的连接情况.具体地说,文中算法的主要流程如下:①从随机初始节点出发,寻找网络中的核心节点并把核心节点所在的团作为初始社团,添加该社团邻居内使其适应度函数值增加最大的节点所在k团形成新的社团,把适应度函数值不再增加的社团确定为最终社团;②从未被遍历的节点中随机选取一个节点,并寻找一个新的核心节点进行社团扩充,直至网络中不存在未被遍历的节点为止.
为了搜索网络中的核心节点,文中引入聚类系数[15]的概念,把聚类系数最大的节点作为核心节点,从核心节点进行社团局部扩充能够避免一定的随机性,从而确保算法具有较好的稳定性.
定义1聚类系数是表示一个图形中节点的聚集程度的系数.在无向网络中,聚类系数表示为
(1)
式中:n表示在节点v的所有t个邻居间的边数.
文中LCCD算法描述如下:
{输入:一个网络G,随机初始节点v0;
输出:网络的一个社团划分community;
(1)初始化;
CurrentNode=v0;
NeighNodes={CurrentNode的所有邻居节点};
maxCC=CC(CurrentNode);∥计算当前节点的聚类系数值
(2)通过节点v0搜索一个核心节点coreNode;
While(NeighNodes!=null)
For每个节点vi属于NeighNodesdo
计算vi的聚类系数值;
Endfor
找出聚类系数值最大且大于maxCC的节点vi,更新maxCC;
节点vi作为CurrentNode,清空NeighNodes;
把CurrentNode的所有邻居节点加入到NeighNodes;
Endwhile
coreNode=CurrentNode;
(3)将coreNode作为核心节点调用局部社团扩充算法;
(4)得到网络的一个社团划分;}
1.2局部社团扩充
文中局部社团扩充的思想与已有算法的扩充思想不同.现有的局部社团扩充算法在进行社团扩充时,每次只选择一个节点进行操作,这种方式导致算法在扩充时只考虑到单个邻居节点的信息,不能准确刻画邻居节点内部的局部信息.文中提出的基于单步添加团的重叠社团检测算法每次添加一个k团而不是一个节点,这种添加方式同时考虑了被添加节点与已有社团的连接紧密性和被添加节点内部的连接情况,从而提高算法的社团检测结果.
为了说明文中基于单步添加团进行局部社团扩充的优势,考虑图1所示的社团局部扩充示例.该网络有12个节点,设当前社团由节点{1,2,3,4,5}构成,该社团对应的适应度值为0.824,如图1(a)所示.若根据局部社团扩充的传统策略单步添加一个节点的方法,从当前社团的邻居节点{6,7,8}中选择使适应度函数增值最大的节点加入到当前社团,但由于每个邻居节点的加入得到的适应度函数值分别为0.800、0.800、0.696,都不会使社团适应度函数值增加,故当前社团规模不再增加,再从未被遍历的另一个节点出发,重复该过程,最终划分为3个社团,结果如图1(b)所示.若使用文中提出的单步添加团的方法,根据适应度函数最大增值找到当前社团的邻居节点6所在的3团{6,7,8},并将该3团加入到当前社团,形成新的社团{1,2,3,4,5,6,7,8},此时社团适应度值为0.897,若继续添加节点9所在3团不会使社团的适应度值增加,故用文中算法得到的最终社团划分结果为具有两个社团的重叠社团结构,如图1(c)所示,其中节点8为重叠节点.通过以上例子不难发现,文中算法可以找到网络中与当前社团连接更加紧密的节点加入社团,使得所寻找的社团结构更加合理.
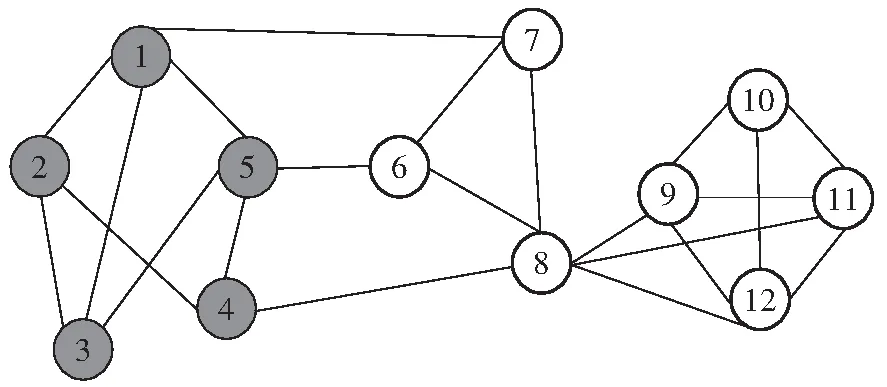
(a)当前现有社团
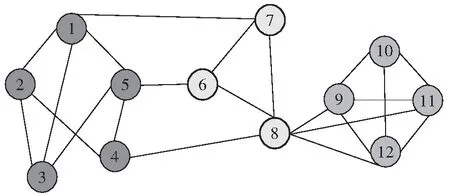
(b)传统算法的局部社团扩充结果
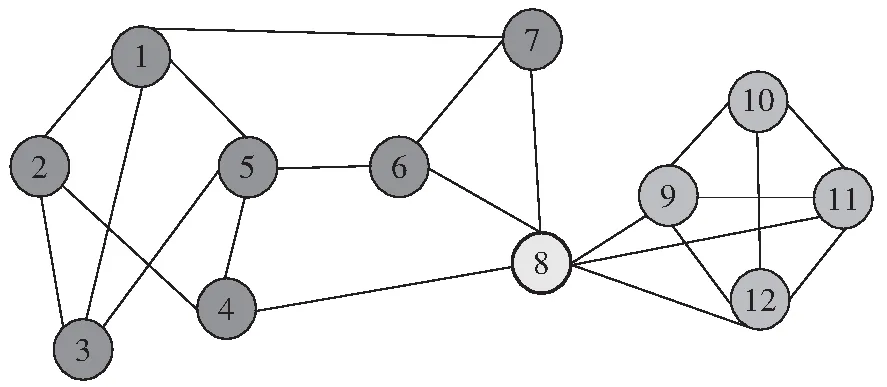
(c)文中算法的局部社团扩充结果
文中扩充局部社团采用单步添加团的方式,其具体思路如下:给定一个初始社团,找出该社团中所有节点的邻居节点,寻找这些邻居节点所在的所有k团,将使社团适应度[11]增值最大的邻居节点所在的k团添加到该社团,重复上述过程,直至社团适应度值不再增加为止.
定义2社团C的适应度
(2)

{输入:corenode;
输出:网络的一个社团划分community;
∥LC用于记录当前的局部社团
∥NS用于存储LC中所有节点的邻居节点的并集
∥NC用于存储NS中所有节点连接的一个k-clique
(1)搜索corenode连接的一个k-clique,把节点加入到LC;
(2)While(FC增值> 0)
计算LC的FC值,把LC中节点的所有邻居节点的并集加入到NS中;
If每个节点vi属于LC&& 存在k-clique
搜索vi连接的一个k-clique,加入到NC;
Else
将vi加入到NC;
EndIf
找出若NC中的元素加入到LC后FC增值最大的元素,并添加到LC;
EndWhile
(3)把LC添加到community里,随机选取一个未被遍历的节点,执行LCCD算法后返回步骤(1);
(4)若所有节点都被遍历,则返回community;}
1.3时间复杂度分析
文中LCCD算法由搜索核心节点和利用单步添加团的策略扩充局部社团两部分组成.第1部分基于贪婪策略获取核心节点,每一步搜索都是从当前节点的邻居节点中找出聚类系数最大的节点,因此,搜索核心节点的时间复杂度为O(cd),其中c为待扩充局部社团的最大规模,d为网络中节点的平均度.LCCD算法在第2部分通过单步添加k团的方式对待扩充局部社团进行扩充,检测一个节点所在的k团时间复杂度为O(dk),故扩充局部社团的时间复杂度为O(dkc).于是,LCCD算法检测出一个社团的时间复杂度为O(cd+cdk)≈O(cdk),由此可以得出LCCD算法的时间复杂度为O(cdkl),其中l为网络的社团个数.
2 实验
2.1参数设置与评价指标
为了验证文中算法的性能,将文中LCCD算法与文献[13]算法、LMD算法[14]、NMF算法[7]分别在真实网络数据集和计算机生成网络数据集上进行实验对比.由于真实网络数据集的真实社团结构一般未知,因此用EQ函数[5]作为真实复杂网络社团检测结果的评价标准,而生成网络是已知的真实社团,因此用NMI[9]评价算法在计算机生成网络数据上的检测精度,比其他精度度量标准更加公平、合理.为了对比的公平性,文中所有对比算法的参数值均根据相应文献进行设置,其中将社团适应度函数中的可控参数α均设为1.由于随着控制所添加团规模的参数k的增加,网络中越难搜索到相应的团,算法的复杂度也会越高,因此为了确保算法的高效性及可行性,文中在所有数据集上均取k为3.
2.2LFR生成网络上的对比实验
计算机生成网络采用经典的LFR生成网络模型[16],该模型能够控制所生成节点的度数,并使社团大小服从指数分布,符合真实网络的统计特性,近年来已被广泛用于测试重叠网络社团检测算法性能.LFR生成网络模型具有如下定义:LFR(N,d,dmax,μ,t1,t2,cmin,cmax,on,om),其中N为网络节点数;d为节点的平均度数,dmax为最大节点度数;t1、t2分别为度序列指数和社团规模分布指数;cmin、cmax分别为最大、最小的社团规模;on为重叠节点数,om为重叠节点所属社团的个数;μ为网络混合参数,μ越小,社团结构越明显,反之社团结构越模糊.
为了更全面验证文中算法在LFR生成网络上的有效性,分别考虑社团结构在不同明显程度和不同重叠度两种情形下的性能,并且给出各算法在LFR生成网络上的运行时间.
实验1在固定参数(k=20,kmax=50,t1=2,t2=1,on=20,om=2)的情况下,考察4种算法的重叠社团检测精度随μ的变化情况.另外,由于网络规模N和社团大小分布区间[cmin,cmax]对社团检测算法的性能有一定的影响,因此实验中同时考虑了不同网络规模和社团大小分布的4种情形,结果如图2所示.从图中可以看出:文中LCCD算法在不同μ值情况下均获得较高的检测精度,尤其在网络结构不明显时,文中算法相对其他算法具有更大的优势;随着网络规模的增加,文中算法比其他3种算法获得更高的检测精度,并且社团大小分布区间的变化对文中算法性能的影响不大.
实验2在固定参数(k=20,kmax=50,μ=0.1, t1=2,t2=1,om=2)的情况下,考察4种算法的重叠社团检测精度随LFR网络中重叠节点数占网络节点总数的百分比的变化情况,结果如图3所示.从图中可以看出:在网络规模较小时,随着重叠度的增加,文中LCCD算法的检测精度优于文献[13]算法、LMD算法,略低于NMF算法;随着网络规模的增大和重叠度的不断增加,文中算法的检测精度高于其他3种算法,这表明文中算法更适用于网络规模较大和重叠度较高的重叠社团检测.

(a)N=1 000,cmin=10,cmax=50
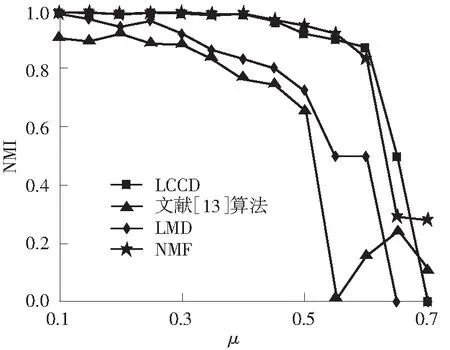
(b)N=1 000,cmin=20,cmax=100
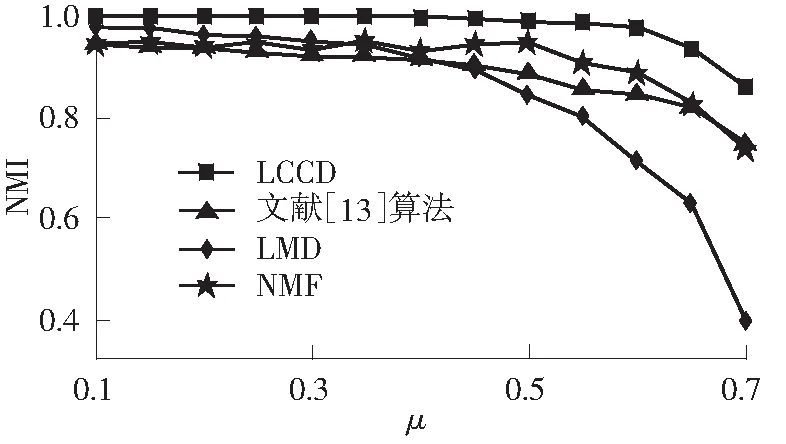
(c)N=5 000,cmin=10,cmax=50

(d)N=5 000,cmin=20,cmax=100
Fig.2Comparisonofdetectionaccuracyamongfouralgorithmsonnetworkswithdifferentnetworksizeandcommunitysize
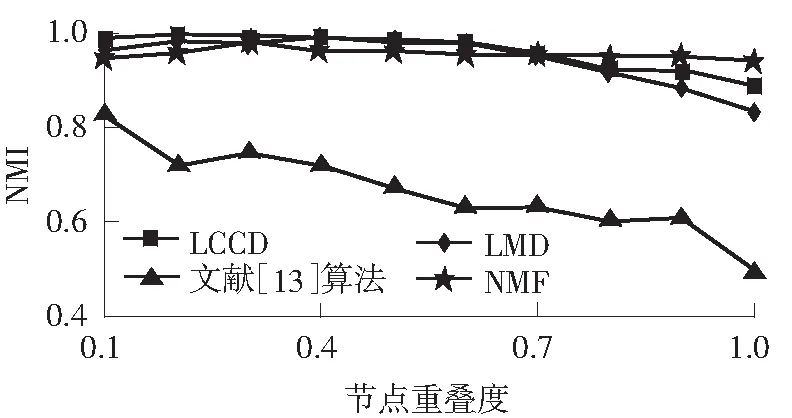
(a)N=1 000,μ=0.1,cmin=10,cmax=50

(b)N=1 000,μ=0.1,cmin=20,cmax=100
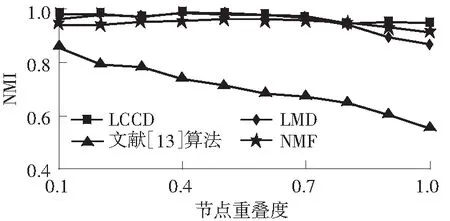
(c)N=5 000,μ=0.1,cmin=10,cmax=50

(d)N=5 000,μ=0.1,cmin=20,cmax=100
图34种算法在LFR网络中重叠节点百分比变化时的检测精度比较
Fig.3ComparisonofdetectionaccuracyamongfouralgorithmsonLFRnetworkswithvaryingpercentagesofoverlappingnodes
实验3在网络参数k=20,kmax=50,t1=2,t2=1, on=20,om=2,N=1 000,cmin=10,cmax=50时,4种算法在LFR生成网络上的运行时间比较如图4所示.从图中可以看出:算法的运行时间与网络混合参数μ有关;当社团结构明显时,文中算法的运行时间优于LMD算法和NMF算法,略低于文献[13]算法;当社团结构不明显时,文中LCCD算法的运行时间优于文献[13]算法和LMD算法,略逊于NMF算法.综合上述分析可知,文中LCCD算法在时间性能上具有一定的优势.
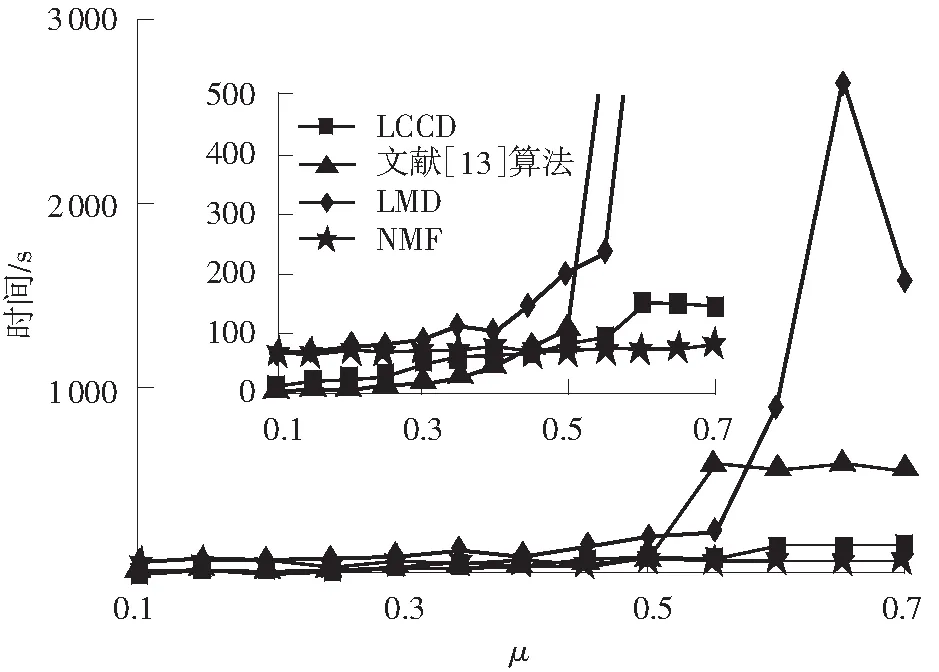
图4 4种算法在LFR生成网络上的运行时间对比
Fig.4ComparisonofrunningtimeamongfouralgorithmsonLFRnetwork
2.3真实网络上的对比实验
为了更好地验证文中算法的性能,采用7个目前广泛使用的不同规模的真实网络作为测试数据集.这些数据集不仅有包含几十个、几百个节点的小规模数据,也有包含上千个节点的较大规模数据,如表1所示.
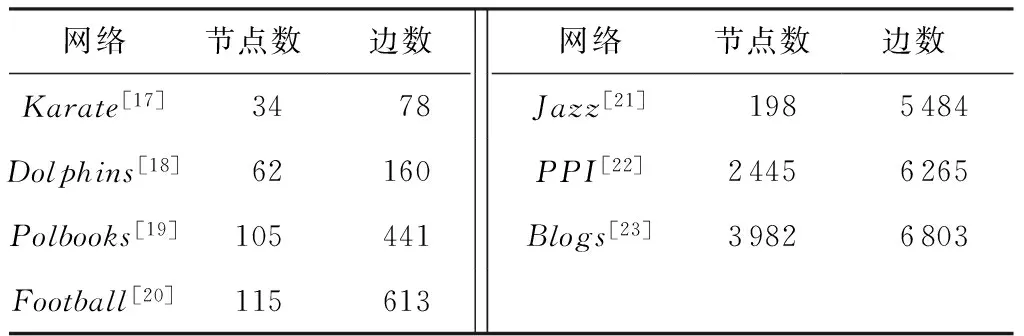
表1 真实网络数据集描述
由于7种真实网络的真实社团结构未知,因此文中使用EQ函数作为网络聚类结果好坏的评价标准.表2给出了4种算法在7种真实网络上的EQ值.从表中可以看出,文中算法在7种真实网络上均取得较好的重叠社团检测结果.对于规模较小的真实网络,文中LCCD算法的检测精度高于文献[13]算法和NMF算法,略低于LMD算法;对于规模较大的真实网络,文中LCCD算法得到的EQ值优于其他3种算法,说明文中算法更适于对大规模真实网络进行重叠社团检测.表2中同时给出了各算法在真实网络上的运行时间,从总体上看,文中LCCD算法的运行时间较其他3种算法具有一定的优势.

表2 4种算法在真实世界网络上实验结果

(a)LCCD算法

(b)文献[13]算法
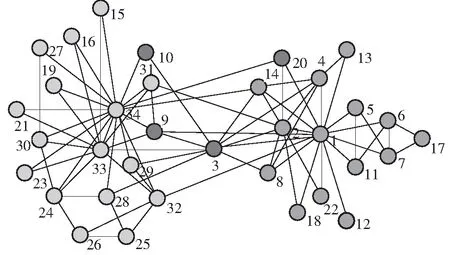
(c)LMD算法
Fig.5Anillustrativeexampleofoverlappingnodesdetectedbyseveralalgorithms
为进一步比较不同算法检测重叠社团的性能,图5给出了3种算法在检测Karate网络时所寻找的重叠节点,其中NMF算法获得的社团结构与文中算法得到的结果一致.从图中可以看出:LCCD算法将该网络划分为具有两个社团的重叠社团结构,浅灰色节点和灰色节点分别代表构成网络的两个社团,其中节点3为重叠节点;文中算法比其他算法可以更准确地挖掘出Karate网络中的重叠节点.
3 结论
文中提出了基于单步添加团的重叠社团检测算法,该算法在局部社团扩充时每次添加一个团,这样确保在社团扩充时充分考虑了节点的局部信息,从而使社团检测结果更为准确.在计算机生成网络和真实网络上的实验结果表明,与现有的基于局部扩充的社团检测算法相比,文中所提算法具有较高的检测精度,能够很好地检测出重叠社团.然而,在现实世界中存在许多有权网络,这些有权网络更形象地刻画真实社团结构,因此,今后拟将文中算法应用于有权网络社团结构的检测,并针对有权网络的结构特征对文中算法进行改进.
[1]KINGAD,PRZULJN,JURISIEAI.Proteincomplexpredictionviacost-basedclustering[J].Bioinformatics,2004,20(17):3013-3020.
[2]AHNYY,BAGROWJP,LEHMANNS.Linkcommunitiesrevealmultiscalecomplexityinnetworks[J].Nature,2010,466(7307):761-764.
[3]赵鹏,蔡庆生,王清毅.交联网络中的可重叠社团结构分析算法 [J].华南理工大学学报(自然科学版),2008,36(5):19-23.
ZHAOPeng,CAIQing-sheng,WANGQing-yi.Algorithmtoanalyzeoverlappingcommunitystructureofintersectionnetworks[J].JournalofSouthChinaUniversityofTechnology(NaturalScienceEdition),2008,36(5):19-23.
[4]DeMEOP,FERRARAE,FIUMARAG,etal.Mixinglocalandglobalinformationforcommunitydetectioninlargenetworks[J].JournalofComputerandSystemSciences,2014,80(1):72-87.
[5]SHENH,CHENGX,CAIK,etal.Detectoverlappingandhierarchicalcommunitystructureinnetworks[J].PhysicaA:StatisticalMechanicsanditsApplications,2009,388(8):1706-1712.
[6]EVANSTS.Cliquegraphsandoverlappingcommunities[J].JournalofStatisticalMechanics:TheoryandExperiment,2010,2010(12):P12037/1-21.
[7]JIND,GABRYSB,DANGJ.Combinednodeandlinkpartitionsmethodforfindingoverlappingcommunitiesincomplexnetworks[J].ScientificReports5,2015,8600,doi:10.1038/srep08600.
[8]RENW,YANG,LIAOX,etal.Simpleprobabilisticalgorithmfordetectingcommunitystructure[J].PhysicalReviewE,2009,79(3):036111/1-7.
[9]YANGJ,LESKOVECJ.Overlappingcommunitydetectionatscale:anonnegativematrixfactorizationapproach[C]∥ProceedingsoftheSixthACMInternationalConferenceonWebSearchandDataMining.Rome:ACM,2013:587-596.
[10]XIEJ,SZYMANSKIBK,LIUX.SLPA:uncoveringoverlappingcommunitiesinsocialnetworksviaaspeaker-listenerinteractiondynamicprocess[C]∥Proceedingsofthe11thIEEEInternationalConferenceonDataMiningWorkshops.Washington:IEEE,2011:344-349.
[11]LANCICHINETTIA,FORTUNATOS,KERTESZJ.Detectingtheoverlappingandhierarchicalcommunitystructureincomplexnetworks[J].NewJournalofPhy-sics,2009,11(3):033015/1-20.
[12]LEEC,REIDF,MCDAIDA,etal.Detectinghighlyoverlappingcommunitystructurebygreedycliqueexpansion[C]∥Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.Washington:ACM,2010:1-11.
[13]ZHANGT,WUB.Amethodforlocalcommunitydetectionbyfindingcorenodes[C]∥Proceedingsof2012IEEE/ACMInternationalConferenceonAdvancesinSocialNetworksAnalysisandMining.Istanbul:IEEE,2012:1171-1176.
[14]CHENQ,WUT,FANGM.Detectinglocalcommunitystructuresincomplexnetworksbasedonlocaldegreecentralnodes[J].PhysicaA:StatisticalMechanicsanditsApplications,2013,392(3):529-537.
[15]李孔文,顾庆,张尧,等.一种基于聚集系数的局部社团划分算法 [J].计算机科学,2010,37(7):46-49.
LIKong-wen,GUQing,ZHANGYao,etal.Localcommunitydetectingmethodbasedontheclusteringcoefficients[J].ComputerScience,2010,37(7):46-49.
[16]LANCICHINETTIA,FORTUNATOS,RADICCHIF.Benchmarkgraphsfortestingcommunitydetectionalgorithms[J].PhysicalReviewE,2008,78(4):046110.
[17]ZACHARYWW.Aninformationflowmodelforconflictandfissioninsmallgroups[J].JournalofAnthropologicalResearch,1977,33(4):452-473.
[18]LUSSEAUD.Theemergentpropertiesofadolphinsocialnetwork[J].ProceedingsoftheRoyalSocietyB:Biolo-gicalSciences,2003,270(S2):186-188.
[19]NEWMANMEJ.Modularityandcommunitystructureinnetworks[J].ProceedingsofNationalAcademyofSciencesoftheUnitedStatesofAmerica,2006,103(23):8577-8582.
[20]GIRVANM,NEWMANMEJ.Communitystructureinsocialandbiologicalnetworks[J].ProceedingsofNationalAcademyofSciencesoftheUnitedStatesofAmerica,2002,99(12):7821-7826.
[21]GLEISERPM,DANONL.Communitystructureinjazz[J].AdvancesinComplexSystems,2003,6(4):565-573.
[22]CUSICKME,YUH,SMOLYARA,etal.Literature-curatedproteininteractiondatasets[J].NatureMethods,2009,6(1):39-46.
[23]GREYORYS.Findingoverlappingcommunitiesinnetworksbylabelpropagation[J].NewJournalofPhysics,2010,12(10):103018/1-21.
s:SupportedbytheNationalNaturalScienceFoundationofChina(61272152,61502004,61502001)
AnOverlappingCommunityDetectionAlgorithmBasedonAddtionofaCliqueatEachStep
ZHANG Xing-yiZHENG WenWANG Cong-taoDING Zhuan-lianSU Yan-sen
(SchoolofComputerScienceandTechnology∥InstituteofBio-inspiredIntelligenceandKnowledgeMining,AnhuiUniversity,Hefei230601,Anhui,China)
Thelocalexpansion-basedoverlappingcommunitydetectionalgorithmsstartfromasinglenodeoraclique,andthenrepeatedlyaddanewnodetotheobtainedcommunity,thusobtainingthefinalcommunity.However,theexistinglocalexpansion-basedoverlappingcommunitydetectionalgorithmsalwaysaddonenodeateachstep,sothelocalinformationoftheaddednodeshasnotbeenfullyconsidered,thusreducingtheaccuracyofthealgorithms.Inordertosolvethisproblem,anoverlappingcommunitydetectionalgorithmisproposed,whichaddsacliqueateachstep.Thisalgorithmstartsfromaclique,andexpandsthecliquebyrepeatedlyaddingacliqueofthelargestfitnessvalueintheneighborhood.Inthisway,thelinksbetweentheaddednodeandtheexistingcommunityandthelinksbetweentheaddednodesarebothtakenintoaccount.Anempiricalevaluationonthesyntheticandrealdatasetsdemonstratesthattheproposedalgorithmcandetecttheoverlappingcommunitiesincomplexnetworksmoreaccuratelythantheexistingalgorithms.
complexnetworks;communitydetection;overlappingcommunity;localexpansion
2015-11-03
国家自然科学基金资助项目(61272152,61502004,61502001)
张兴义(1982-),男,博士,教授,博士生导师,主要从事非传统计算模型与算法、多目标优化及复杂网络分析研究E-mail:xyzhanghust@gmail.com
苏延森(1985-),女,博士,讲师,主要从事复杂网络分析研究.E-mail:suyansen1985@163.com
TP39
10.3969/j.issn.1000-565X.2016.09.004
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
计算机仿真(2022年8期)2022-09-28
铁道通信信号(2019年6期)2019-10-08
郑州大学学报(工学版)(2018年2期)2018-04-13
军事文摘(2017年16期)2018-01-19
雷达学报(2017年6期)2017-03-26
中学生(2016年13期)2016-12-01
互联网天地(2016年1期)2016-05-04
中国塑料(2016年11期)2016-04-16
智能系统学报(2015年4期)2015-12-27
