
网络知识资源表示学习模型
2016-11-02 06:43朱国进李承前
智能计算机与应用 2016年3期
朱国进,李承前
(东华大学计算机科学与技术学院,上海 201620)
网络知识资源表示学习模型
朱国进,李承前
(东华大学计算机科学与技术学院,上海201620)
随着电子计算机技术和互联网的快速发展,网络知识资源呈爆炸式增长,人们往往不能有效地获取、利用所需的网络知识资源。为了更好地利用网络知识资源,需要应用自动化、智能化的数据挖掘、信息提取方法。Web文档作为网络知识资源的一种载体,有着自然语言非结构化的特点,所以在运用聚类、分类等挖掘技术进行文本挖掘之前,需要将Web文档转化为机器学习算法可以理解的格式,即将文本数据转换成数值数据。针对现有常用文本表示方法的局限性,本文提出了一种基于命名实体和词向量相结合的网络知识资源表示学习模型。并在算法知识领域内进行实现与应用探索,包括网络解题报告的聚类和对网络解题报告的搜索,实验结果显示本文提出的方法在这些任务上取得了较好的效果。
文本表示;命名实体识别;条件随机场;算法知识;词向量
0 引 言
近年来计算机的普及和互联网技术的飞跃发展使得信息的生产和传播变得简便快捷,大量的网络知识资源开始涌现。顾名思义,网络知识资源就是网络中含有知识的信息资源,在互联网上往往以网页的形式出现,在经过爬取、预处理、正文提取[1]等过程之后,会以自然语言文本的形式存在,其中蕴含有人们想要获取的知识。例如,ACM国际大学生程序设计竞赛(International Collegiate Programming Contest,ICPC)的解题报告就是这样一种网络知识资源,具体就是人们针对程序算法设计竞赛中题目的解题心得记录,其中包含了丰富的算法知识。在ACM参赛队员的训练和数据结构算法课程的教学中,往往有这样的需求:需要通过一个知识点搜索相关的题目及其网络解题报告,或者通过给定的一篇解题报告搜索在算法知识上相关的解题报告。例如希望通过搜索“动态规划”这个知识点来从网络获得关于动态规划的竞赛题目的解题报告。
正因为存在着上述的种种需求,需要对网络知识资源中的知识进行挖掘,但目前自动化、智能化的数据挖掘技术往往都离不开利用机器学习算法进行模型训练,而此时首先发生的就是要将非结构化的自然语言文本转化为机器学习算法可以理解的形式。也就是说,在进一步应用机器学习算法之前,需要有一个网络知识资源到文本再到数字向量表示的转化过程。词袋法(Bag of word,BOW)是表示一个文件的基本方法。该法重点是以文档中的每个词语的计数形成的频率向量去表示文档。这种文档表示法则可称为一个向量空间模型(VSM)[2]。但却仍需指出,词袋法/向量空间模型表示法有其自己的限制:表示向量的维度过高,损失了与相邻单词的相关性,而且也损失了文档中词语之间存在的语义关系。词语加权方法用于分配适当的权重给各个词语,以增强文本分类的最终呈现[3-4]。Razavi等人使用潜在狄利克雷分布LDA(Latent Dirichlet Allocation)降低空间维度,从主题角度表示文档,优化了文档表示质量[5]。Jain等人使用小波扩撒,在短文本表示上取得了不错的表现[6]。Hsieh等人使用神经网络学习词向量的表示更趋完善地进行文档表示,在读者情感分类任务上获得了良好实效[7]。Harish等人用聚类之后的词语频率向量表示文档,取得了较好的效果[8]。传统的文本表示方法如One-Hot表示[2]和TFIDF(词频-逆文档频率)[9]常常只是简单的词频统计,割裂了词与上下文之间的联系,具有一定局限性,不能很好地利用文本中的语法、语义信息。而流行的LDA主题模型虽然能一定程度反映文档的主题结构,但却不能有效表示文本中的知识。
针对以上问题,本文提出一种基于命名实体与词向量相结合的网络知识资源表示方法,能从知识的角度对网络资源进行表示,并且更好地利用文本的语法,语义信息,充分挖掘词与上下文的关系。最后,利用本文所提出的模型方法,实现了网络解题报告的聚类和搜索应用,实验取得了较好的效果。
1 背景介绍
1.1命名实体识别
命名实体识别是信息提取的子任务,意在从自然语言文本中寻找实体的位置和对实体进行正确的分类。命名实体识别是许多自然语言处理应用不可或缺的一部分,例如问答系统,机器翻译等。
传统的通用命名实体识别任务主要是识别出待处理文本中三大类(实体类、时间类和数字类),七小类(人名、机构名、地名、时间、日期、货币、和百分比)命名实体。领域命名实体识别是针对特殊的应用领域与文本体裁中特定类型的命名实体,有产品名称实体,基因名称实体等相关的研究[10]。
命名实体识别基本上可分为3种方法:基于规则的、基于词典的和基于统计的。其中,基于统计的条件随机场模型(conditional random field,CRF)是由Lafferty在2001年提出的一种典型的判别式模型[11-12]。实现中,可在观测序列的基础上对目标序列进行建模,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,条件随机场的参数化一般模型为:

其中,x为观测序列,y为标记序列,Z(x)是归一化因子,F为特征函数,λ是需要训练学习的参数。模型常使用BFGS优化算法进行训练,解码时用维特比算法输出标记序列。
条件随机场模型既具有判别式模型的优点,又具有产生式模型考虑到上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型(如最大熵马尔科夫模型)难以避免的标记偏见问题。本文将规则和词典作为一种特征与统计方法结合,使用条件随机场模型应用在知识实体识别中。
1.2词向量
分布式表示(Distributed representation)最早是由Hinton在1986年的论文中提出的一种低维实数向量[13]。例如[0.792,-0.177,-0.107,0.109,-0.542,…],维度以50维和100维比较常见。Distributed representation用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文译称“词向量”[14]。这种表示法的优点在于可以让相似的词在距离上更为接近,能体现出词与词之间、词与上下文之间的相关性,从而反映词之间的依赖关系。Bengio等人在2001年提出神经网络语言模型(NNLM),在用神经网络对N-gram语言模型实施建模过程的同时获得词向量。Mikolov等提出的Word2vec用CBOW模型和Skip-gram模型获取上下文相关词向量,对NNLM进行了优化,从而在大规模语料训练上处理得到了更好的性能和表示效果。综合以上研究分析,本文将选用开源word2vec实现gensim作为实验工具进行词向量训练。
2 网络知识资源表示方法
2.1模型总体框架图
命名实体识别的条件随机场模型可以通过对词性特征和组合特征的选取,并优质利用文本中的语义和语法信息,从而高效识别并标记出文本中的知识。词向量作为一种深度学习的副产品,在神经网络对语言模型的建模过程中,获得一种单词在向量空间上的表示,与潜在语义分析(Latent Semantic Index,LSI)、潜在狄立克雷分配(Latent Dirichlet Allocation,LDA)的经典过程相比[15],词向量利用词的上下文,语义信息更加地丰富,能够更好地对词进行表示。所以,在本文中提出了一种基于命名实体和词向量相结合的网络知识资源深层表示学习模型,模型框图如图1所示。
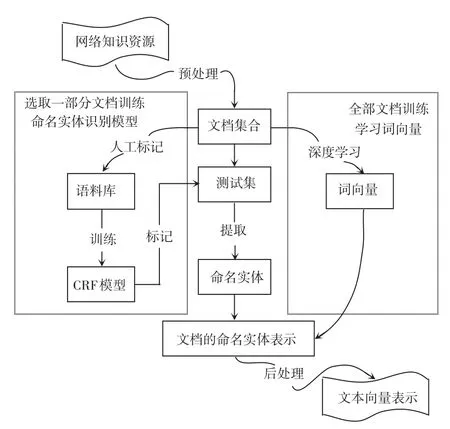
图1 模型总体框架图Fig.1 General framework of the model
模型输入为网络知识资源,经过爬虫爬取、网页正文提取等过程转化为文档集合。图1的左半部分通过条件随机场在训练语料的学习得到命名实体标注器,从而提取文档中人们所关心的知识实体。图1的右半部分通过在领域语料上对神经网络skip-gram模型进行训练获得词向量的良好表示,最后将两者进行加权平均,由此而获得文档的向量表示。
2.2模型的定义
本文以文档中识别出的命名实体作为文档特征,作为一个领域中定义的命名实体,其本身就是研究中想要获取的知识。在该领域内,命名实体可以充分表示文档的语义内涵。下面给出定义:
经过爬取,预处理的网络知识资源转化为文档D可以表示为词的集合,其中t代表文档中的一个词,n为文档中词的个数:

经过领域命名实体识别,由词表示的文档可以转换为由命名实体表示的文档D:

具体地,NE表示命名实体,m表示命名实体个数,m<<n。而且,其中可能有重复的实体。
定义model为在领域语料上进行了深度学习训练好的词向量模型,其中d为一个维度,k为训练时规定的词向量的维度数。
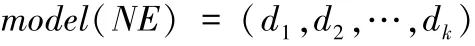
对文档中识别出的每个命名实体对应的词向量进行TFIDF(词频-逆文档频率,TF-IDF与实体在文档中的出现次数成正比,与该实体在整个语料中的出现次数成反比)加权平均计算。计算公式如下所示:
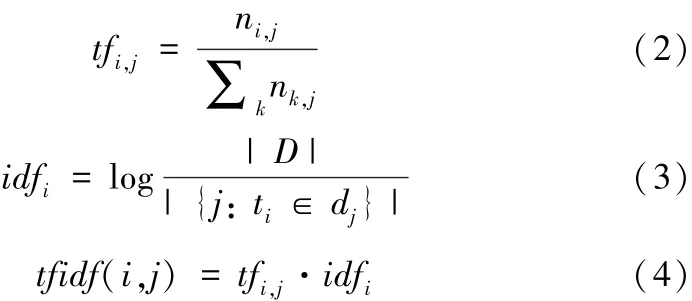
其中,式(2)计算词i在文档j中的词频,ni,j指词i在文档j中出现的次数,k代表文档j中词的总数;式(3)计算词i的逆文档频率,分子代表语料库中的文档总数,分母代表包含词i的文档数;最后将tf和idf相乘就得到了词i在文档j中的tfidf权重。
最终文档D可以表示为公式(5)。数学描述如下:
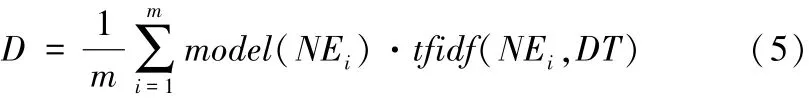
其中,m代表文档中的命名实体数,DT指由词表示的文档。
经过计算,文档D最终表示为向量后,文档之间的语义距离或者语义相似度就可以通过余弦相似度来度量。
3 实 验
本文在算法知识领域以网络解题报告为数据进行网络资源表示实验。分为算法知识实体标注器训练和算法知识领域词向量训练2个部分。本文通过编写爬虫程序从CSDN,百度空间等知名博客网站抓取17 000余原始网页。利用文献[1]中所述的解题报告正文提取方法,将原始网页进行处理,得到只有解题报告正文的文本。
3.1算法知识实体标注器训练
本文使用开源包CRF++作为命名实体识别工具,开源包jieba作为分词工具,知识实体标注器的训练流程如图2所示。
本文定义了2种实体OJ,KNOWLEDGE分别代表解题报告中的在线评测系统(online judge)和算法知识,实体的标注标签如表1所示。
接着从17 000篇经过正文提取的文档集中随机选取400篇文档、包含约90 000个句子作为待标注集,使用开源的brat工具进行标注,OJ实体由浅粉色标签标记,Knowledge实体由绿色标签标记。
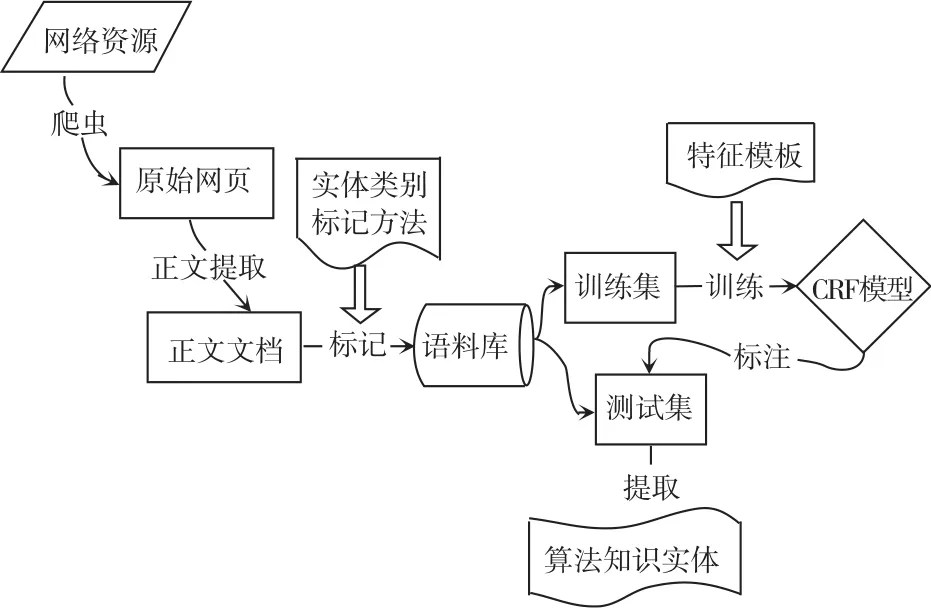
图2 知识实体标注器训练流程Fig.2 Knowledge entity tagging training process

表1 定义2种实体标签Tab.1 Define two entity Tags
接下来,将brat输出的格式转化为CRF++要求的输出格式如表2所示,其中省略了几列对应下文介绍的各个特征,限于篇幅原因,表2中未标示出来。

表2 CRF++输入语料格式Tab.2 CRF++input data format
本文根据算法知识领域网络解题报告的特点,构建了单词特征、构词特征、指示词特征、词性特征、词典特征和停用词特征。并且编写了特征模板[16],CRF++会利用特征模板将以上特征组合、计算转化为数字向量,进行CRF模型训练。最后选取了199篇文档作为测试集,5折交叉检验的结果如表3所示,从而得到了算法知识实体标注器。
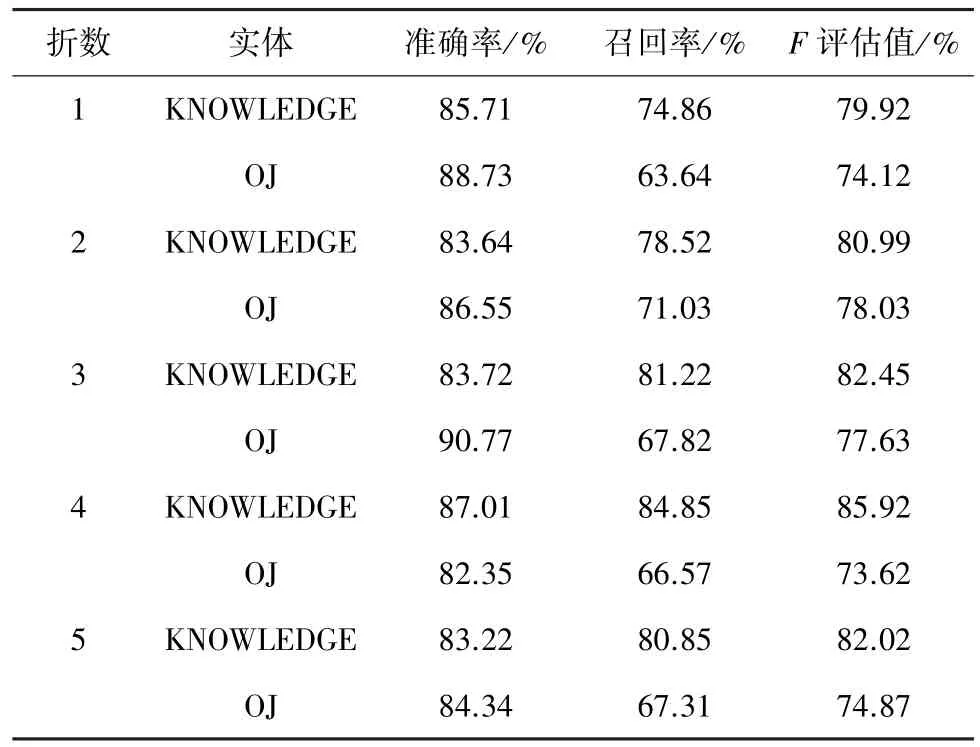
表3 CRF模型测试结果Tab.3 CRF model test results
3.2算法知识领域词向量训练
本文使用17 000篇算法知识领域的网络解题报告经过分词等预处理过程后作为word2vec的训练语料。一般认为模型、语料、参数3方面会影响词向量的训练,因为Skip-Gram在小语料上有更好效果,所以本文词向量训练选择Skip-Gram模型。语料方面,传统看法认为语料越大越好,所有语料都集聚到一起,不管是什么内容,语料越庞大,涵盖的语义信息就越丰富,效果就越趋于理想。但是Lai等研究表明语料的领域更重要,领域选择正确,可能只要1/10甚至1/100的语料,就能达到一个大规模泛领域语料的效果,有时候语料选取不当,甚至会导致负面效果(比随机词向量效果还差),文章还做了实验,当只有小规模的领域内语料,而有大规模的领域外语料时,到底是语料越纯越好,还是越大越好,在该文章实验中,结论是越纯越好[17],与本文思路相吻合。训练时所用参数如表4所示。

表4 word2vec训练参数Tab.4 Training parameter
词向量的训练结果如表5所示,展示了与“栈”、“图”、“DP”和“树”等词各自最相似的3个词。其中与“DP”相似的词看上去与词“树”有关,但实际上,在算法知识领域却与“DP”形成更多关联。至此,获得了算法知识领域语料上训练完成的词向量模型model。

表5 词与词之间的相似度Tab.5 The similarity between words
3.3网络解题报告表示的生成
最终网络资源表示生成的流程图如图3所示。在得到算法知识实体标注器与训练完成的词向量模型之后,就可以计算知识实体在文档中的TF-IDF权值,由于词向量模型中的分词过程不可能完美分割一些领域知识词汇,就使得算法知识命名实体的词向量表示需要由构成该实体的词对应的词向量合并而成,并且忽略一些无意义的符号,而命名实体的TFIDF值则选取构成该实体的词的TF-IDF的平均值。例如“动态规划”这一KNOWLEDGE实体的词向量即是由“动态”和“规划”相加得到,并且取“动态”和“规划”的TF-IDF平均值作为“动态规划”的TF-IDF值。此后,经过计算,一篇网络解题报告就可以表示为100维的向量,如前文公式(5)所述。

图3 表示的生成Fig.3 Generation of representation
4 应用探索
4.1网络解题报告的聚类
本文使用前文提出的方法将随机选择的199篇网络解题报告转化为特征向量(最初200篇,有1篇文档为空,实际为199篇),并使用K-means算法进行聚类,其中使用余弦相似度定义距离,而且只考虑算法知识实体。经过多次试验,选取不同的K-means初始簇数参数,初始中心使用“Kmeans++”方法,该方法可实现初始中心各自彼此远离。实验结果如图4所示,这里从众多实验组中选择4组,从左到右,至上而下分别是初始簇数为3、7、15、20的聚类结果展示。本文使用PCA(Principal Component Analysis)主成分分析将原100维的文本向量降维为2维向量,方便在二维坐标上进行可视化。图中每种颜色色块代表一种簇的边界,每一个黑点是数据实例,白叉代表每个簇的中心点。
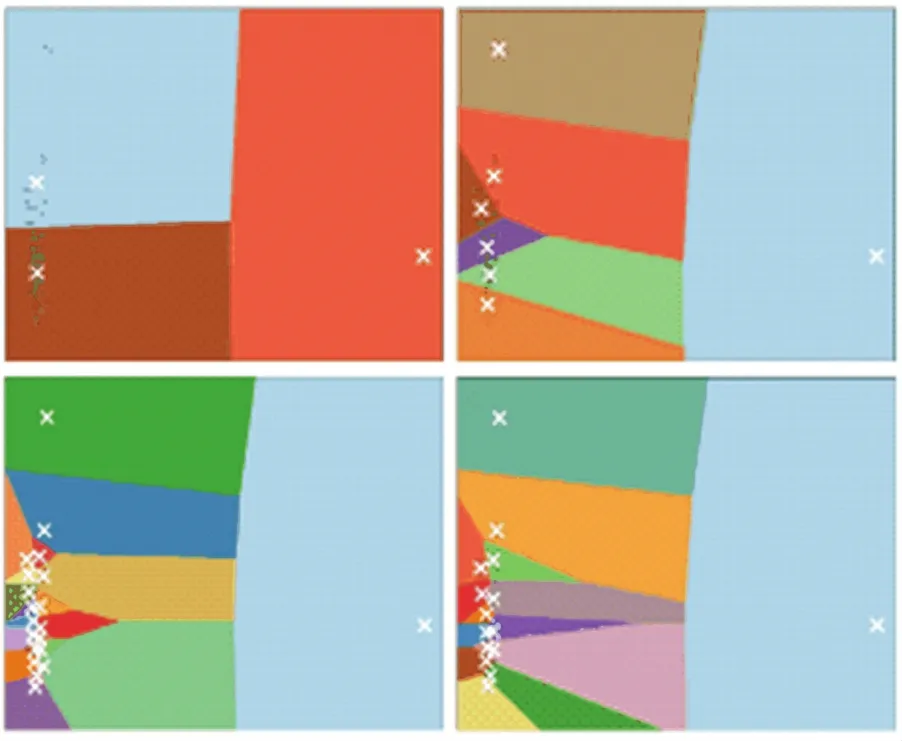
图4 聚类实验结果Fig.4 Cluster experiment result
实验主要针对算法知识实体(KNOWLEDGE),而将OJ实体向量置为零向量,通过对聚类结果与原始文本进行对照分析,簇数分别为15、20的聚类结果对于199篇解题报告来说有些过拟合,划分类别过多、过细,而簇数为3的聚类结果又有些欠拟合,分类则过少、过粗。最后,簇数为7的聚类结果与测试数据集有着较为吻合的分类边界,见图4右上角。聚类结果分析则如表6所示。

表6 初始簇数为7的聚类结果分析Tab.6 Clustering results
从表6可以看出,基于命名实体与词向量的网络知识资源表示方法在网络解题报告的聚类上达到了一定效果。
4.2网络解题报告的搜索
在ACM队员的训练和数据结构算法课程的教学中,往往有这样的需求:需要通过一个知识点搜索相关的题目或者解题报告。例如希望通过搜索“动态规划”来获得关于动态规划知识点的网络解题报告。本次研究使用前文所述方法实现了通过知识点对网络解题报告进行搜索。
如表7所示,分别以“动态规划”、“二分图”、“二叉树”为知识点进行了搜索,该应用默认显示了与知识点相似度最高的前3篇网络解题报告的第一行,有些报告中虽然没有关键字,但是报告对应的题目是与知识名称相关的知识点。

表7 算法知识点搜索Tab.7 Algorithm knowledge search
可以看出,通过本文提出的网络知识资源设计模型表示的网络解题报告的特征向量与关键词的词向量也有良好的相关性。
5 结束语
本文提出了一种基于命名实体与词向量相结合的网络知识资源表示学习模型,能够从知识的角度对文本进行解析,从而更趋充分、全面地利用文本的语法、语义等信息,也更加利于针对某个领域的文本进行表示。本文以网络知识资源表示方法为基础在算法知识领域进行了应用探索,包括网络解题报告聚类实验和网络解题报告的搜索,实验结果显示网络知识资源表示方法在这些任务上有较为良好的效果。在未来工作中,希望能够在更大语料,更广的领域上进行实验,与其它文本表示方法进行对比,进一步研究探索深度学习框架的命名实体识别与词向量联合学习的方法。
[1]朱国进,郑宁.基于自然语言处理的算法知识名称发现[J].计算机工程,2014,40(12):126-131.
[2]SALTON G,WANG A,YANG C S.A vector space model for automatic indexing[J].Communications of the ACM,1975(18):613-620.
[3]LAN M,TAN C L,SU J,et al.Supervised and traditional term weighting methods for automatic text categorization[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(4):721-735.
[4]ALTINCAY H,ERENEL Z.Analytical evaluation of term weighting schemes for text categorization[J].Journal of Pattern Recognition Letters,2010,31(11):1310-1323.
[5]BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J]. the Journal of machine Learning research,2003,3:993-1022.
[6]JAIN V,MAHADEOKAR J.Short-text representation using diffusion wavelets[C]//Proceedings of the companion publication of the 23rdinternational conference on World wide web companion.International World Wide Web Conferences Steering Committee.Seoul,Republic of Korea:ACM,2014:301-302.
[7]HSIEH Y L,LIU S H,CHANG Y C,et al.Neural network-based vector representation of documents for reader-emotion categorization[C]//Information Reuse andIntegration(IRI),2015IEEE International Conference on.Miami,Florida,USA:IEEE,2015:569-573.
[8]HARISH B S,ARUNA K S V,MANJUNATH S.Classifying text documents using unconventional representation[C]//Big Data and Smart Computing(BIGCOMP),2014 International Conference on. Bangkok,Thail:IEEE,2014:210-216.
[9]RAMOS J.Using tf-idf to determine word relevance in document queries[C]//Proceedings of the 20thinternational conference on machine learning.Washington,DC,USA:ICML,2003:1-4.
[10]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2014.
[11]MCCALLUM A,BELLARE K,PEREIRA F.A conditional random field for discriminatively-trained finite-state string edit distance[J]. arXiv preprint arXiv:1207.1406,2012.
[12]TSENG H,CHANG P,ANDREW G,et al.A conditional random field word segmenter for sighan bakeoff 2005[C]//Proceedings of the fourth SIGHAN workshop on Chinese language Processing.Jeju Island,Korea:SIGHAN,2005:171.
[13]HINTON G E.Learning distributed representations of concepts[C]// Proceedings of the eighth annual conference of the cognitive science society.Amherst,Mass:COGSS,1986:12.
[14]MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vector space[J].arXiv preprint arXiv:1301. 3781,2013.
[15]CHANG Y L,CHIEN J T.Latent Dirichlet learning for document summarization[C]//Acoustics,Speech and Signal Processing,2009. ICASSP 2009.IEEE International Conference on.Taipei,Taiwan:IEEE,2009:1689-1692.
[16]刘章勋.中文命名实体识别粒度和特征选择研究[D].哈尔滨:哈尔滨工业大学,2010.
[17]LAI S,LIU K,XU L,et al.How to generate a good word embedding?[J].arXiv preprint arXiv:1507.05523,2015.
A learning model for representation of knowledge resources on the Web
ZHU Guojin,LI Chengqian
(School of Computer Science and Technology,Donghua University,Shanghai 201620,China)
With the rapid development of computer technology and the Internet,the network knowledge resources are increasing,people often can not effectively access and use the network knowledge resources.In order to make better use of the network knowledge resources,the application of automation and intelligent data mining and information extraction methods are needed.As a carrier of knowledge resource on Web,Web document was non structured natural language,so before in using clustering and classification mining technology to text mining,the web document is required to be transformed into the format which can be understood for machine learning algorithms,that is to realize the conversion text data into numerical data.In view of the limitations of the existing common text representation methods,this paper proposes a network knowledge resource representation learning model based on the combination of named entity and word vector.And the paper discusses the implementation and application in the field of algorithm of knowledge,including clustering network solving report and search for network problem solving report.The experimental results show that method presented in this paper on these tasks achieved good results.
text representation;named entity recognition;CRF;the algorithm knowledge;word representation
TP391
A
2095-2163(2016)03-0005-06
2016-04-11
朱国进(1958-),男,博士,副教授,主要研究方向:计算机网络、分布式技术;李承前(1989-),男,硕士研究生,主要研究方向:机器学习。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
海外华文教育(2016年1期)2017-01-20
信息安全研究(2016年4期)2016-12-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
