
语义转换影响因素评价方法研究
2016-11-04 02:14刘平芝张卫柱徐道柱
测绘科学与工程 2016年1期
熊 顺,刘平芝,张卫柱,徐道柱
1.信息工程大学地理空间信息学院,河南 郑州,450052;2.西安测绘研究所,陕西 西安,710054;3.地理信息工程国家重点实验室,陕西 西安,710054
语义转换影响因素评价方法研究
熊顺1,2,3,刘平芝2,3,张卫柱2,3,徐道柱1,2,3
1.信息工程大学地理空间信息学院,河南 郑州,450052;2.西安测绘研究所,陕西 西安,710054;3.地理信息工程国家重点实验室,陕西 西安,710054
影响语义信息转换模型算法结果的因素很多,其模糊性和随机性的特点使模型算法的影响因素选取问题很难解决。本文分析了语义相似性算法影响因素,引入模糊数学思想,针对算法因子提出多级模糊综合评价方法,通过对算法因子的评价,为相似性模型算法因子的选取提供重要判断依据,对于提高算法模型的效率和准确度具有重要意义。
语义;相似性;多级模糊评价;语义距离
1 前 言
目前,国内系列比例尺的基础地理信息数据库基本建立,数据信息更新速度越来越快,数据内容涵盖范围越来越广泛,数据类型也越来越繁多,数据应用对于属性信息多样化的要求也越来越高,因此,数据共享服务中针对解决语义信息转换的需求也越来越迫切。语义信息的无损转换,是实现不同类型地理信息之间数据交换和共享的基本技术途径,也是当前信息共享迫切需要解决的关键技术问题。
语义信息的转换,可以从定量的角度,通过语义相似关系的判断来实现。相似性是现实世界中不同地理现象之间所存在的一种普遍关系。研究地理信息的相似性,是人类认知地理空间关系的重要内容。相似性通常采用基于人工判断的方法、基于领域应用的定性方法和基于计算机语言学的定量方法对概念之间的关系进行描述。其中,定量的方法是通过计算元素(概念)之间的语义相似度(Semantic Similarity)或者语义距离(Semantic Distance)等具体数值来表示概念之间的关系[1,2]。语义相似度的计算须借助数学理论和方法,建立语义相似度量模型实现语义相似程度的量化,这是解决本体语义异质问题的有效技术途径。语义相似性度量是语义关系的重要判断依据。影响语义相似性模型算法结果的因素很多,如何判断并选取这些影响因素,对于提高算法模型的效率和准确度具有重要意义,解决该问题的关键在于对语义相似性算法因子评价方法的研究。
由于语义相似性结果涉及因素较多,如可以进行定量描述的概念节点的深度、密度、属性容量和属性的重要度、关系描述、类型等,这些因素都具有模糊性和随机性,这就决定了语义相似性算法因子权重取值的不确定性[3]。根据这些因子的模糊性和复杂性,本文引入多级模糊数学综合评判的原理和方法,对语义相似性算法因子进行评价,来研究这些因子对算法结果的影响度。
2 语义相似性模型及算法因子的选择
语义相似性的量化计算方法,比较流行的有两种[4]:一是同义词词典方法。该方法基于本体库,利用同义词词典(Thesaurus)来计算相似度。Princeton大学的WordNet就是一部树状的英语语义字典,树状图上两片树叶之间的距离,就是这两个概念的语义距离,由语义距离可进一步得出语义相似度。二是词语相关性方法。该方法是基于大规模的本体库统计信息,利用词语的相关性来计算相似度。通常选取一组特征词,利用在实际大规模本体库中上下文的出现频率得到相关性的特征向量,用向量的夹角余弦来计算相似度[5]。本文采用第一种方法,通过概念之间的词义距离来衡量概念语义的相似程度[6]。现有的语义距离计算方法比较成熟,其中,戴维民(2008)根据概念之间边的关系以及最低共同祖先与语义距离的关系,提出了一个经典的语义距离计算公式[7]:
(1)

(2)
以上公式对于基于语义距离的语义相似度计算比较准确,但是该方法忽略了其它因素的影响,比如概念节点的密度、重要度等。为了更为准确地获得语义相似性计算的算法因子,必须针对概念层次结构以及概念的相关属性进行研究,找出影响相似性计算结果的因素,从而实现对上述算法的优化。
算法因子的引入,必须充分考虑到概念节点的实际含义、所处的层次、相对的位置、出现的频率和属性描述等信息。通过概念语义关系的分析,确定引入以下算法因子:语义距离、节点密度den(vi,vj)、节点深度dep(vi,vj)、节点重要度imp(vi,vj)、节点类型rel(vi,vj)、属性容量cap(vi,vj)、知识范围reg(vi,vj)。其中语义距离、节点密度、节点深度与语义相似性之间成反比,节点重要度、属性容量与语义相似性之间成正比,而节点类型和知识范围是从节点之间的关系来界定其相似性的。

(3)
其中,ω=[α,β,γ,δ,ε,θ,μ]为运算因子的调节参数,且(α,β,γ,δ,ε,θ,μ)∈[0,1],满足α+β+γ+δ+ε+θ+μ=1。
3 基于多级模糊的算法因子评价方法
针对模糊综合评价的不足[3],多级模糊综合评价能充分考虑到算法因子的不确定性对相似性算法的影响,从影响因素的层次关系入手,弥补模糊综合评价的缺陷[8]。
3.1多级模糊综合评价原理[8]
首先设定选择的m个因素的集合为U={U1,U2,…,Um},n个评价集合为W={W1,W2,…,Wn}。然后,确定评价等级,即确定相应的相似性置信区间。本文分为4个区间,即完全不等价V1∈[0,0.2],低概念等价V2∈(0.2,0.5],基本等价V3∈(0.5,0.9),完全的等价V4∈[0.9,1]。评价等级标准集为V={ V1,V2, V3, V4}。如果选择 rij表示第i个因素对第j种评价的隶属度[3],则所有的影响因素集合和评价集合之间的关系可以用模糊矩阵表达
(4)
其中,rij必须满足0≤rij=μR(Ui,Wj)≤1,i=1,2,…,m,j=1,2,…,n。

(5)
其中B是最终的综合评价集合,整个评价过程是从最低级向上逐级运算的,也就是说第k级的评价结果就是第k-1级影响因素的隶属度。计算的步骤如下:
1)因为k=3,所以首先进行第三级的计算,获得Bij=Aij×Rij,然后令
(6)
2)完成第三级计算后开始第二级计算,获得Bi=Ai×Ri,然后令
(7)
3)通过最后一级的运算,可以获得最终的评价集合
B=A×RT
(8)
3.2算法因子的多级模糊评价
改进的算法模型在计算中考虑的影响因素有:概念语义距离、概念的节点密度、节点深度、节点重要度、节点类型、属性容量、知识范围等7个因素,因此设定影响因素集合U={U1,U2,U3,U4,U5,U6,U7},具体的影响因素定义如表1所示。
U1为概念语义距离因素,U1所对应的下一级因素为U1={U11,U12},U11为概念集合的总深度,U12为节点之间的最短距离,而U12={U121,U122},其中U121为节点vi的位置,U122为节点vj的位置;
U2为概念节点密度因素,U2所对应的下一级因素为U2={U21,U22,U23},U21为节点层次,U22为节点总数,U23为节点差值,而U23={U231,U232},其中U231为节点vi位置的节点数,U232为节点vj位置的节点数;
U3为概念节点深度因素,U3所对应的下一级因素为U3={U31,U32,U33,U34},U31为概念集合的总深度,U32为节点总数,U33为节点差值,U34为概念之间的公共节点,而U33={U331,U332},其中U331为节点vi位置,U332为节点vj位置;
U4为概念节点重要度因素,U4所对应的下一级因素为U4={U41,U42},U41为概念集合的数据集大小,U42为概念节点在数据集中的频率关系,而U42={U421,U422},其中U421为节点vi在数据集中的频率,U422为节点vj在数据集中的频率;
U5为概念节点类型因素,U5所对应的下一级因素为U5={U51,U52},U51为概念节点类型分布特征,U52为节点类型关系;
U6为概念属性容量因素,U6所对应的下一级因素为U6={U61,U62},U61为概念节点之间的属性总量,U62为节点之间的公共属性,而U62={U621,U622},其中U621为节点vi的属性总数,U622为节点vj的属性总数;
U7为概念节点知识范围因素,则U7所对应的下一级因素为U7={U71,U72,U73},U71为概念为同一领域知识,U72为相关领域知识,U73为不同领域知识。
表1影响因素定义

因素描述二级因素描述三级因素描述U1概念语义距离U11概念集合的总深度——————U12节点之间的最短距离U121vi节点位置U122vj节点位置U2节点密度U21节点层次——————U22节点总数——————U23节点差值U231vi节点数U232vj节点数U3节点深度U31概念集合总深度——————U32节点总数——————U33节点差值U331vi节点位置U332vj节点位置U34概念之间公共节点——————U4节点重要度U41集合的数据集大小——————U42在数据集中的频率关系U421vi节点频率U422vj节点频率U5节点类型U51概念节点类型分布特征——————U52节点类型关系——————U6属性容量U61节点之间的属性总量——————U62节点之间的公共属性U621vi属性数U622vj属性数U7知识范围U71同一领域知识——————U72相关领域知识——————U73不同领域知识——————
由于评价等级标准集为V={ V1,V2, V3, V4},根据隶属函数[3]确定方法,可以计算所有的因素评价集合W的隶属度,如表2所示。
表2影响因素的评价集合

影响因素二级影响因素V1V2V3V4U1U110.300.400.150.15U12U1210.240.220.310.23U1220.200.250.310.24U2U210.340.260.180.22U220.410.330.110.16U23U2310.220.130.370.28U2320.310.350.230.11U3U310.200.430.220.15U320.190.440.160.21U33U3310.320.330.250.10U3320.250.300.190.26U340.360.220.180.24
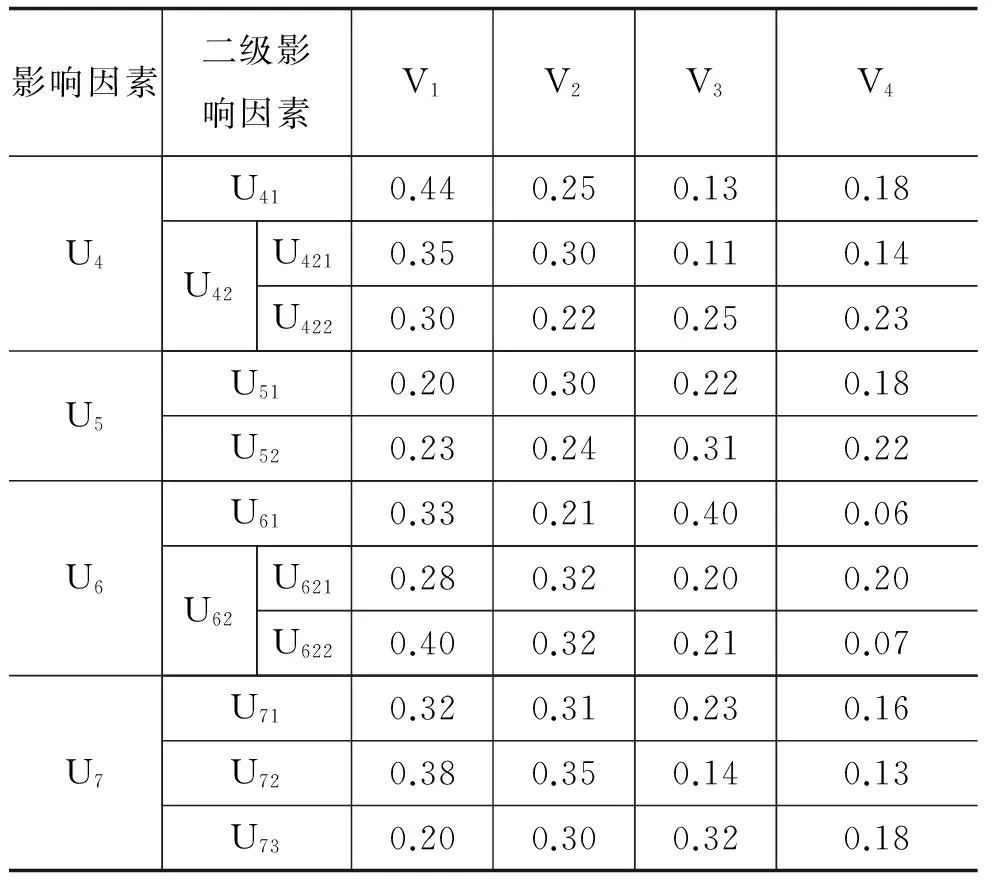
续表2
按照多级模糊综合评价方法,从第三级到第一级的顺序进行计算:
1)计算第三级结果。表2中U12、U23、U33、U42、U62有第三级影响因素,通过专家评估,可以获得其权向量A12、A23、A33、A42、A62都为[0.50.5],根据表2得到:
R12=[0.200.250.310.24]
由B12=A12×R12,可以得到:
B12=A12×R12=[0.50.5]×[0.200.250.310.24]=[0.220.2350.310.235]
同理可得:
B23=A23×R23=[0.50.5]×[0.310.350.230.11]=[0.2650.240.300.195]
B33=A33×R33=[0.50.5]×[0.250.300.190.26]=[0.2850.3150.220.18]
B42=A42×R42=[0.50.5]×[0.300.220.250.23]=[0.3250.260.180.185]
B62=A62×R62=[0.50.5]×[0.400.320.210.07]=[0.340.320.2050.135]
结合表2,可以获得U1、U2、U3、U4、U6的第二级模糊关系矩阵,分别为:
2)计算第二级结果。据表2,继续计算剩下几个因子的模糊关系矩阵,分别为:
根据专家评价每一个因素的下一级因素的权向量,可以获得:
A1=[0.400.60]
A2=[0.320.300.38]
A3=[0.200.200.300.30]
A4=[0.400.60]
A5=[0.500.50]
A6=[0.400.60]
A7=[0.330.340.33]
由B1=A1×R1,可以得到:
B1=[0.2520.3010.2460.201]
B2=[0.2230.2620.2030.332]
B3=[0.2460.2120.3010.241]
B4=[0.3710.2560.1600.213]
B5=[0.2150.2700.2650.200]
B6=[0.3360.2760.2830.105]
B7=[0.2170.3230.2340.226]
由此可以获得最高级的模糊矩阵:
3)计算最高级结果。通过专家知识确定影响因子的权向量为:
A=[0.30.20.10.10.10.10.1]
根据前两个步骤获得的模糊矩阵R,可以计算影响因子的评价集合:
B=A×RT=[0.4010.1010.1710.0710.0650.1400.052]
3.3评价结果分析
为了与实际结果进行比对,本文通过人工方法对算法因子的重要性进行描述,采用调查统计、数据实验和专家经验相结合的方法进行评价,根据相似置信区间,设计算法因子评价调查表,并通过调节算法转换因子的参数,进行1∶5万、1∶1万地形图数据之间的语义信息转换结果对比实验,获得语义相似性算法因子的综合评语,如表3。
表3综合评语

因素V1V2V3V4U10.250.300.270.19U20.220.320.200.26U30.210.350.200.19U40.240.290.280.19U50.200.300.220.18U60.230.360.220.14U70.210.370.210.16
可以得到模糊关系矩阵:
影响因子的权向量为:
A=[0.30.20.10.10.10.10.1]
根据前两个步骤获得的模糊矩阵R,可以计算影响因子的评价集合:
B′=A×R′T=[0.4680.1410.1340.0630.0600.1120.032]
评价向量的偏移量ε=|B′-B|,结果如表4:
表4评价向量偏移量

序号向量B向量B'偏移量ε10.4010.4680.06720.1010.1410.04030.1710.1340.03740.0710.0630.00850.0650.0600.00560.1400.1120.02870.0520.0320.020
通过计算结果可以发现,专家的综合评语结果B′与模糊综合评判结果B是相近的,同时也可以发现算法因子中,语义距离、节点密度、节点深度和属性容量等因素对相似性算法结果的影响是不可忽略的。通过这种评价方式,选择合适的语义相似性算法因子,可以适应语义转换的实际情况,减少算法的计算量,从而提高模型算法的运算效率和准确度。
4 结 论
基于多级模糊评价的方法对于影响因素多级多层次的问题有很好的适用性,通过综合考虑影响因素的复杂关系,尽量对不同级别的因素进行量化,减少主观的人为判断,从而使评价的结果科学合理,更加符合客观实际。语义相似性算法因子对于算法结果的影响存在复杂性和不确定性,但是引入模糊数学思想,创新性地应用模糊综合评价方法,对于算法因子影响效果的量化具有重要意义。
但是,该方法还存在两个问题。一是各级因素的权向量确定,通过专家知识来确定权向量,很显然增加了人为的主观因素,对计算结果不可避免地产生负面影响;二是评价等级的划分,等级划分的详细程度对评价对象的评价结果有影响,划分的越细,评价结果就越明确,但是通过人为主观的划分,也不可避免地对计算的结果产生负面的影响。
[1]张晨或.基于语义度量的本体映射及语义查询的研究[D].合肥:合肥工业大学,2005.
[2]何娟,高志强,陆青健等.基于词汇相似度的元素级本体匹配[J].计算机工程,2006,32(16):185~187.
[3]熊顺.语义相似性算法因子评价方法研究[J].测绘科学与工程,2014(3):68-72.
[4]Dao-I Lin,Kedem Z M .Pincer-search,All Efficient Algorithm for Discovering the Maximum-equent set[C].London:Proceedings of the 6th European Conference on Extending Database Technology,1998.
[5]LEACOCK C,CHODOROW M.Combining Local Context and Word-net Similarity for Word Sense Identification[M]. Cambridge:M1T Press,1998.
[6]CROSS V.Fuzzy semantic distance measures between ontologicalconcepts[C]. Washington,DC:IEEE Annual Meeting of the Fuzzy Information, 2004.
[7]戴维民.语义网信息组织技术与方法[M].上海:学林出版社,2008.
[8]胡圣武.GIS质量评价与可靠性分析[M].北京:测绘出版社,2006.
Evaluation Method of Semantic Conversion Influence Factors
Xiong Shun1,2,3,Liu Pingzhi2,3,Zhang Weizhu2,3,Xu Daozhu1,2,3
1. Institute of Geospatial Information, Information Engineering University, Zhengzhou 450052, China 2. Xi’an Research Institute of Surveying and Mapping, Xi’an 710054, China 3. State Key Laboratory of Geo-information Engineering, Xi’an 710054, China
Many factors have influences on the semantic conversion model, and it is difficult to select proper ones due to their fuzziness and randomness. In this paper, the influence factors of the semantic similarity algorithm are analyzed and the fuzzy mathematics is introduced. A multi-level fuzzy comprehensive evaluation method is proposed for the algorithm factor. The algorithm factor evaluation provides an important basis for the similarity model algorithm factor selection, and will make important contribution to the efficiency and accuracy improvement of the model.
semantic; similarity; multi-level fuzzy evaluation; semantic distance
2015-12-09。
熊顺(1976—),男,工程师,主要从事地图制图学与地理信息研究。
P231
A
猜你喜欢
数学物理学报(2022年5期)2022-10-09
现代装饰(2022年1期)2022-04-19
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
现代装饰(2020年2期)2020-03-03
中学生数理化·高一版(2018年9期)2018-10-09
中学生数理化·高一版(2017年9期)2017-12-19
浙江大学学报(工学版)(2016年2期)2016-06-05
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
