
应用于公司舆情分析的改进概念图算法
2016-11-07 17:48黄苗黄奎崔欢欢朱国锐
软件导刊 2016年9期
黄苗黄奎崔欢欢朱国锐

摘要:传统的舆情分析多采用文本聚类和分类技术,但是由于自然语言自身表达的复杂性和灵活性,文本聚类和分类技术很难从根本上反映话题评论人员对待话题的真实态度。针对文本聚类和分类技术的局限性,设计了应用于公司舆情分析的改进概念图算法。改进的概念图能表示部分概念节点的倾向性,利用改进的概念图计算每条评论的健康度,可有效地从语义分析角度计算评论语句的健康度。研究结果表明,应用于公司舆情分析的改进概念图算法,其正确率普遍高于基于文本聚类和分类技术的舆情分析方法。
键词:概念图;舆情分析;文本倾向性;健康度
DOIDOI:10.11907/rjdk.161459
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2016)009002203
基金项目基金项目:国家自然科学基金项目(51178373);科技部科学技术支持项目(2008BAH37B05060);陕西省自然科学基金项目(2014JM2-6114)
作者简介作者简介:黄苗(1989-),女,河南洛阳人,西安建筑科技大学信息与控制工程学院硕士研究生,研究方向为人工智能;黄奎(1992-),男,河南洛阳人,北京京东尚科信息技术有限公司工程师,研究方向为舆情分析;崔欢欢(1989-),女,河南洛阳人,西安建筑科技大学信息与控制工程学院硕士研究生,研究方向为人工智能。
0引言
企业危机事件爆发时,负面信息在各个网站迅速传播。如果企业不及时了解舆情态势,未能及时作出正确的澄清和引导,舆情信息对企业的影响将会变得不受控制。传统舆情分析算法多采用文本聚类和分类技术,能有效地挖掘出热点话题,但是不能较为准确地分析出话题评论人员的态度及其量化值。本文以自然语言理解语义分析理论为基础[1],在分析了词汇褒贬性和副词强度的基础上,设计了应用于公司舆情分析的改进概念图算法,该算法能较好地分析出话题评论人员的态度及其量化值。
1概念图基本理论
概念图(Conceptual Graphs, CGs)是由美国的计算机科学家John F Sowa提出的一种知识表示方法。
定义1:概念图可以定义为由概念节点、关系节点、有向弧组成的有向联通图[25],即:
CGs=(Concept,Relation,F)(1)
其中,Concept = {C1,C2,.....,Cm}表示概念图的概念节点集合,用来表示实体、动作、状态和事件等;Relation={R1,R2,.....,Rn}表示概念图的关系节点集合,用来表示概念节点和概念节点之间的关系;F=(Concept×Relation ) ∪(Relation×Concept)是有向弧集合。
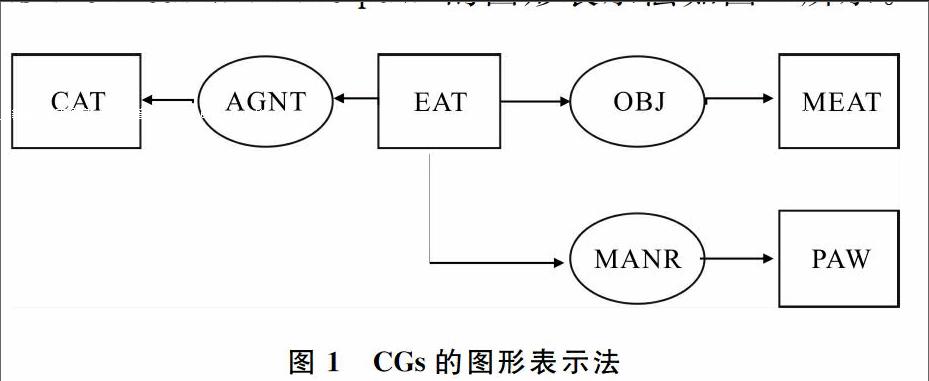
概念图的表示形式有两种[6-7],第一种是图形表示形式。概念节点用矩形表示,关系节点用椭圆表示,概念节点和关系节点间的关系用有向弧表示。例如,语句“A cat eats the meat with the paw”的图形表示法如图1所示。
第二种是线性表示形式。概念节点用方括号表示,关系节点用圆括号表示。图1用线性形式表示为:
[EAT]—(AGNT) →[CAT]
(OBJ) →[MEAT]
(MANR) →[PAW].
概念图的图形表示形式虽然形象、直观,但是采用线性表示形式,能更好地在计算机中进行表示和处理。因此,本文采用概念图的线性表示形式。
2改进的概念图及健康度计算方法
2.1改进的概念图知识表示方法
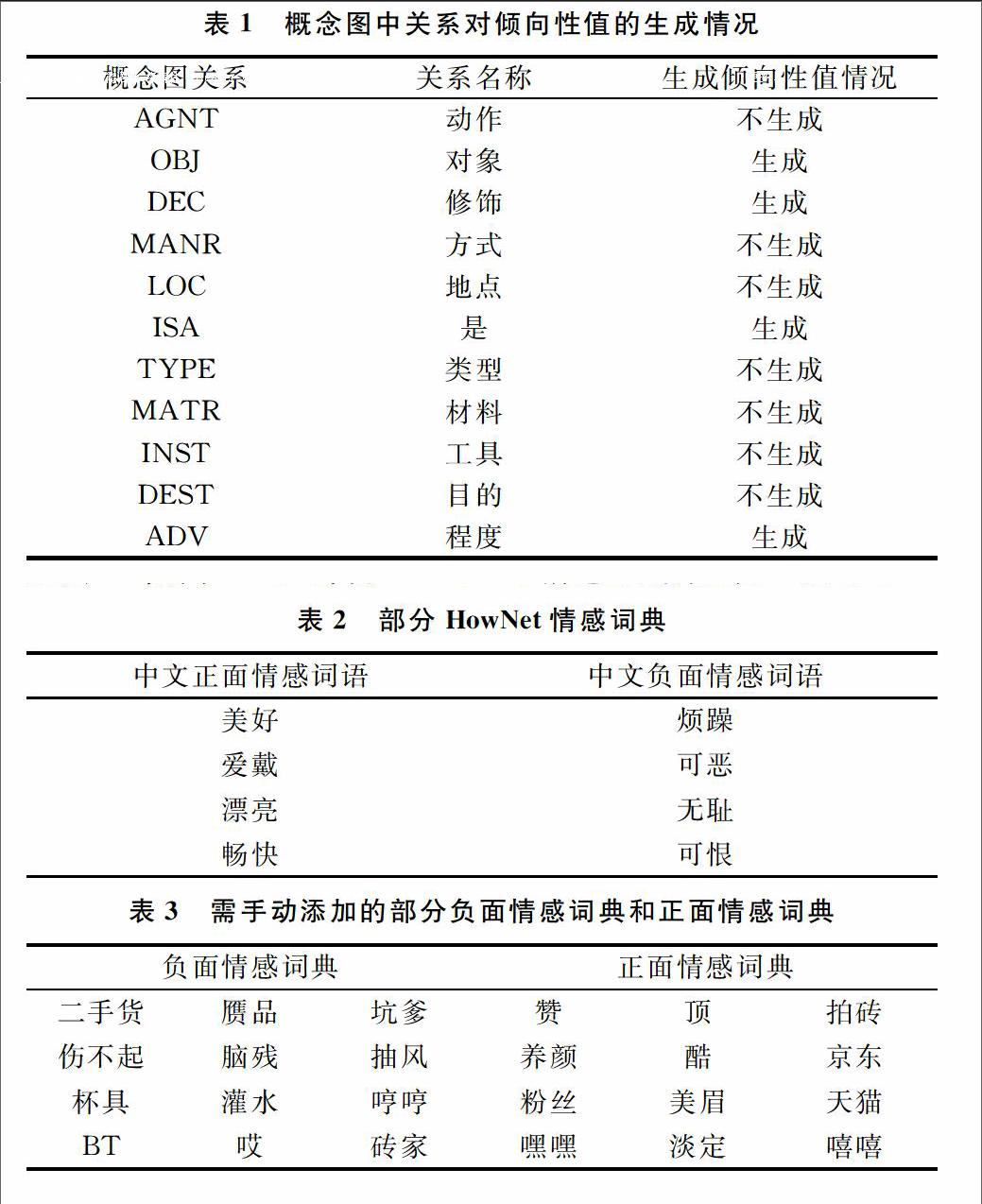
在传统概念图的知识表示中,概念节点自身的倾向性从未在概念图中反映出来。本文对部分概念节点引入了词语的褒贬倾向性,概念节点的倾向性值用T(Tendency)表示,强度值用D(Degree)表示。但有些概念节点并不需要赋倾向性值,因为在对评论句子进行倾向性分析时,材料、地点和类型等名词之间的关系并没有表示出句子所表示的立场,而作为句子的修饰词语和句子的谓语动词,则表现出该动作受体的立场。最后根据情感词库和副词强度评分表对传统概念图赋倾向性值,表1展示了概念图中关系对倾向性值的生成情况。
2.2倾向性值赋值规则
(1)HowNet情感词典。在中文的文本处理方面最有权威的资源是HowNet。目前,HowNet最新版的词典中,中文正面的情感词语有836个,中文负面情感的词语有1 254个[8]。其中正面倾向词汇的T值为+1,负面词汇的T值为-1。部分HowNet情感词语如表2所示。
(2)手动添加网络情感词汇。因为网络新词更新快,且在正规词典里没有出现,所以必须针对特定公司,收录有褒贬性的网络情感词语[9]。其中正面倾向词汇的T值为+1,负面词汇的T值为-1。以京东商城为例,需要手动添加的部分负面词汇和正面词汇如表3所示。
(3)程度副词和否定词:①程度副词:程度副词分为3个等级,分别赋程度值,程度值用D表示。具体赋值如表4所示;②否定副词:否定副词也用T表示,如:“不”、“没”、“无”等,其T值为-1。
2.3改进的概念图健康度计算方法
定义2:健康度是评论者对该公司做的某件事的一个态度,记为H。健康度的计算方法如下:
Step1:计算所有关系(ADV)中被副词修饰的动词或形容词概念节点的倾向性值,该被修饰的概念节点倾向性值为该副词强度值和此概念节点倾向性值的乘积。如果关系(ADV)连接的概念节点中有一个没有倾向性,则不进行此步的计算。
Step2:计算所有关系(DEC)中被形容词修饰的概念节点的倾向性值和计算关系(DEC)的倾向性值,该被修饰的概念节点倾向性值等于被修饰的概念节点倾向性值和修饰的概念节点倾向性值的乘积。(DEC)的倾向性值记为Tend(DEC),如果与关系(DEC)中被修饰的概念节点和关系(OBJ)连接,则不计算此关系的Tend(DEC);如果没有连接,则此关系的Tend(DEC)为关系(DEC)连接的两个概念节点倾向性值的乘积。如果关系(DEC)连接的概念节点中有一个没有倾向性,则不进行此步的计算。
Step3:计算所有关系(ISA)的倾向性值,该倾向性值记为Tend(ISA)。该关系的倾向性值即为与关系(ISA)相连接的两个概念节点倾向性值的乘积。如果关系(ISA)连接的概念节点中有一个没有倾向性,则不进行此步的计算。
Step4:计算所有关系(OBJ)的倾向性值,该倾向性值记为Tend(OBJ),该关系的倾向性值为与关系(OBJ)相连接的两个概念节点倾向性值的乘积。如果关系(OBJ)连接的概念节点中有一个没有倾向性,则不进行此步的计算。
Step5:计算健康度,此段评论的健康度等于以上所有3个关系倾向性值的相加,即:
H=Tend(DEC)+Tend(ISA)+Tend(OBJ)(2)
3算法示例
3.1概念图倾向性赋值
根据情感词库和副词强度评分表为上述的概念图赋倾向性值和程度值。例如:“可恶的京东,卖给我二手货,以后不买京东的东西了!”
主题句的概念图中关系(OBJ)、(DEC)对倾向性值生成起作用,与修饰关系(DEC)连接的修饰概念节点[可恶的]赋值为-1,[京东]、[东西]、[京东的]赋值为+1。与(OBJ)关系连接的两个概念节点分别赋值,[卖]赋值为+1,[二手货]赋值为-1。然后为另外一个与(OBJ)关系连接的两个概念节点分别赋值,[不买]赋值为-1。所以主题句赋值后的概念图为:
[卖]—(OBJ)→[二手货] →(T) →[-1]
(AGNT)→[京东]—(DEC)←[可恶的]→(T) →[-1]
(T) →[+1]
(DIR)→[我]←(AGNT)←[不买]—(OBJ)→[东西]—(DEC)←[京东的]→(T)→[+1]
(T) →[+1]
(T) →[-1]
(T) →[+1].
3.2健康度计算
计算主题句的健康度,过程如下:①主题句里没有程度副词,所以步骤1省略;②计算关系(DEC)的倾向性值,主题句里第一个(DEC)关系是:[京东]←(DEC) ←[可恶的],记为(DEC)1。该关系中被修饰的概念节点没有与关系(OBJ)连接,所以,计算Tend(DEC)1等于该关系连接的概念节点的乘积,即(-1)*(+1)=-1;第二个(DEC)关系是:[东西] ←(DEC) ←[京东的],记为(DEC)2,由于该关系中被修饰的概念节点与关系(OBJ)连接,所以不计算Tend(DEC)2,概念节点[东西]的倾向性值为[东西]和[京东的]倾向性值的乘积,即(+1)*(+1)=+1;③主题句里没有(ISA)关系,所以此步骤省略;④第一个(OBJ)关系:[卖] →(OBJ) →[二手货],记为(OBJ)1,Tend(OBJ)1=(+1)*(-1)=-1;第二个(OBJ)关系:[不买] →(OBJ) →[东西],记为(OBJ)2,Tend(OBJ)2= (-1)*(+1)=-1;⑤计算可得健康度为-3。
此评论文本的健康度表明,该评论者对该公司的某个事件持否定态度,且否定度为3。
4实验结果及分析
本试验系统采用Java语言来实现,操作系统为Windows7,CPU为AMD 四核A8处理器,内存为4G。
本文收集了新浪微博关于京东商城5个主题的1 000多条评论,通过人工测试某评论,健康度为正(负),而实验系统测试该评论的健康度也为正(负),此时为正确结果。最后再用KNN(K最近邻)、SVM(支持向量机)、Naive Bayes(朴素贝叶斯)几种分类算法分别测试该1 000多条评论的正、负、中立态度。通过比较正确率说明本算法的优越性,同时用精确率来说明本算法的可靠性。
设某个主题的总评论数为n,系统测试为正确结果的评论数为m,则系统测试的正确率为:
正确率=(m/n)*100%(3)
系统测试的健康度和人工测试的健康度的差值,与人工测试的健康度比值即为每条评论的精确度,再通过每条评论精确度的加权平均得到精确率。则系统测试的精确度和精确率公式如下:
精准度=1-|人工测试的评论健康度-系统测试的评论健康度||人工测试的评论健康度|(4)
精准度=1m∑i=mi=1|人工测试的评论健康度-系统测试的评论健康度||人工测试的评论健康度|×100%(5)
本测试系统的正确率和精确率及其它算法测试的正确率结果如表5所示。
从表5可以看出,本算法的正确率都在83%以上,普遍高于其它算法,同时也有很高的精确率。
5结语
本文针对网络上关于公司的舆情信息,设计了一个应用于公司舆情分析的改进概念图算法。综合分析表明,本算法对短评论有较好的精确度,对长评论句子的精确度有误差。本算法正确率普遍高于KNN算法、SVN算法和Naive Bayes算法,同时本算法有较高的精确率。采用该方法,在微博和论坛上摘取评论者对某个特定公司的评论,可以自动、实时地分析出评论者对于该公司某事件的态度。同时本算法首次将概念图的知识表示方法应用到公司的舆情分析系统中,对其它领域的舆情分析系统具有一定参考价值。
参考文献参考文献:
[1]STPHEN D RICHARDSON, GEORGE E HEIDORN, KEREN JENSEN. Natural language processing: the PLNLP approach[M]. New York: Kluwer Academic,1993:126128.
[2]SOWA,J F.Conceptual structures: information processing in mind and machine[M].AddisonWesley Publishing Company,1984.
[3]SOWA J F. Conceptual graphs for database interface[J].IBM J Res & Dev,1976,20(4):336357.
[4]刘培奇,凡星,段中兴.倾向性文本的概念图过滤技术的研究[J].微电子学与计算机,2012,29(12):8487.
[5]刘培奇,李增智,赵银亮.扩展产生式规则知识表示方法[J].西安交通大学学报,2004,38(6):587590.
[6]吴彬,罗钧.基于模糊认知图的资源描述框架(RDF)研究[J].微电子学与计算机,2009,26(3):4244.
[7]刘培奇,李增智.基于模糊含权概念图的主观题自动阅卷方法研究[J].计算机应用研究,2009,26(12):45654567.
[8]张鹏星.基于文本倾向性分析的网络舆情分析及其趋势预测[D].昆明:云南财经大学,2013.
[9]张超.文本倾向性分析在舆情监控系统中的应用研究[D].北京:北京邮电大学,2008.
责任编辑(责任编辑:黄健)
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24
有色金属(矿山部分)(2021年4期)2021-08-30
三门峡职业技术学院学报(2021年4期)2021-04-19
作文成功之路·小学版(2020年5期)2020-06-11
新课程研究(2016年21期)2016-02-28
新闻研究导刊(2015年17期)2015-12-25
语言与翻译(2015年4期)2015-07-18
海南热带海洋学院学报(2014年2期)2014-08-08
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
高中生学习·高三版(2014年3期)2014-04-29
