
基于不平衡数据集的蛋白质ATP结合位点集成预测
2016-11-09 23:04张金涛
数字技术与应用 2016年9期
张金涛
摘要:集成学习是一种新的机器学习范式,它通过训练若干有差异的学习器,并将它们的预测结果进行合成,相对于单个学习器,集成学习算法可以显著提高学习系统的泛化能力。因此对集成学习理论和算法的研究成为了机器学习领域的一个热点。现在,集成学习已经成功应用于航空航天、地震波分析、生物特征识别、医疗诊断等众多领域。但集成学习技术还不成熟,对集成学习的研究还存在很大的进步空间。
关键词:腺苷三磷酸 SFLA聚类算法 ELM的集成预测算法
中图分类号:TP181 文献标识码:A 文章编号:1007-9416(2016)09-0092-02
腺苷三磷酸(Adenosine Triphosphate,ATP)是一种高能磷酸化合物,在预测蛋白质功能方面起着关键作用。针对传统实验的方法鉴别ATP与蛋白质的结合位点时存在耗时、耗力、耗资的缺陷,国内外学者均开始尝试用生物信息学的方法预测ATP与蛋白质的结合位点[1]。2009年,Dr.G.P.S.Raghava的科研科研小组利用ATPint软件程序包预测ATP与蛋白质的结合位点,预测总精度达75.25%,相关系数MCC值达到0.5。2011年,Ke Chen等人组成的科研小组利用ATPsite软件程序包预测ATP与蛋白质的结合位点,预测总精度达86.13%,相关系数MCC值达到0.46。实际预测ATP和蛋白质结合位点时,结合位点(正类)的片段数量与非结合位点(负类)的片段数量相差悬殊,造成数据不平衡。为了减小数据不均衡对预测的影响,这里对负类样本运用基于混合蛙跳的(Shuffled Frog Leaping Algorithm,SFLA)聚类算法进行欠采样形成多个不相交的子集,然后在各子集上提取有代表性的样本集,与正类样本组成新的平衡训练集。然后,基于字统计模型提取特征,并利用多样性增量对所提取高维特征进行降维。最后,采用基于极端学习机(Extreme Learning Machine,ELM)的集成预测算法对蛋白质ATP结合位点进行预测[2]。
1 基于SFLA聚类算法的数据欠采样
由于在蛋白质序列数据集中,与ATP结合的氨基酸位点远远少于非结合位点,因此需要对数据集进行平衡化处理,以使其不致影响后续分类的精度。处理不平衡数据集分类问题常用的主要有算法层面和数据层面两种方法。本项目拟采用在数据层面处理不平衡数据,即首先采用基于SFLA聚类算法进行欠采样,将原始数据集中的负类样本聚类为多个不相交的子集,然后在各子集上提取有代表性的样本集,与正类样本组成新的平衡数据集。
假设原始数据集中包含N1个正类数据集A,N2个负类数据集B,算法步骤如下:
Step 1:在负类数据集B上,使用基于SFLA聚类算法对N2个负类数据进行聚类,聚类后各簇内的数据个数分别为,且,为聚类个数,[]为取整符号;
Step 2:计算各簇数据到各自聚类中心的距离,并按由小到大的顺序排列;
Step 3:分别选取各簇中距离簇中心最近的个数据组成包含N3个负类数据的新负类数据集false;
Step 4:将新负类数据集false和正类数据集A组合,生成平衡数据集。
2 特征提取与降维
2.1 基于字统计模型的特征提取方法
字统计模型是通过在蛋白质序列中统计长度为k的氨基酸片段出现的频率,以作为后续预测的特征信息。与传统统计各氨基酸频率特征的方法相比,此特征提取方法不仅统计了单个氨基酸出现的频率,还统计了氨基酸片段出现的频率,从而获取了更为全面的蛋白质序列信息。对于由20种氨基酸组成的蛋白质序列S,主要特征提取步骤如下:
Step 1:由一个n维向量来表示k-字段在序列S中出现的次数,n是所有可能的k-字的总数。
Step 2:将k-字段在序列S中出现的频率表示为向量
。
当时,该频率向量则为20种氨基酸在序列中出现的频率。
2.2 基于多样性增量的特征降维
多样性增量(Increment of diversity,ID)是基于多样性量的一个生物数学概念,它反映了两个样本之间的生物相似性关系,ID值越小表示两个样本之间越相似。本文利用ID原理对所选高维特征进行降维,可以减少降维过程中丢失的信息,避免后续分类器过训练的情况。
3 基于ELM的集成预测算法
分类器集成的主要思想是利用多个分类器来解决同一个问题,采用某种规则把学习结果进行组合,以期达到有效提高学习系统泛化能力的目的。生成差异性互补的分类器是提升预测性能的关键。目前,生成差异性及分类器的方法主要有训练样本的扰动、模型参数的设置、学习算法本身的差异等。Bagging(Bootstrap Aggregating)算法是一种基于训练样本分布扰动的分类器集成技术。算法每次从训练样本中随机有放回地抽取与训练集数目相等的样本,训练基分类器,重复T次后,就可以训练出T个基分类器。本项目基分类拟采用ELM,通过Bagging算法实现对训练样本的扰动,从而产生具有差异性的基分类器,再进行基分类器的集成学习。
将原始数据集分成训练集和测试集两个子集,算法主要步骤如下:
Step 1:采用有放回抽样从训练集的样本中选取k个样本;
Step 2:采用提取的新的k个样本对ELM基分类器进行训练;
Step 3:重复Step 1和Step 2T次,得到T个ELM基分类器。
Step 4:将测试集输入各基分类器,采用多数投票法融合各基分类器输出结果。
4 预测结果评价
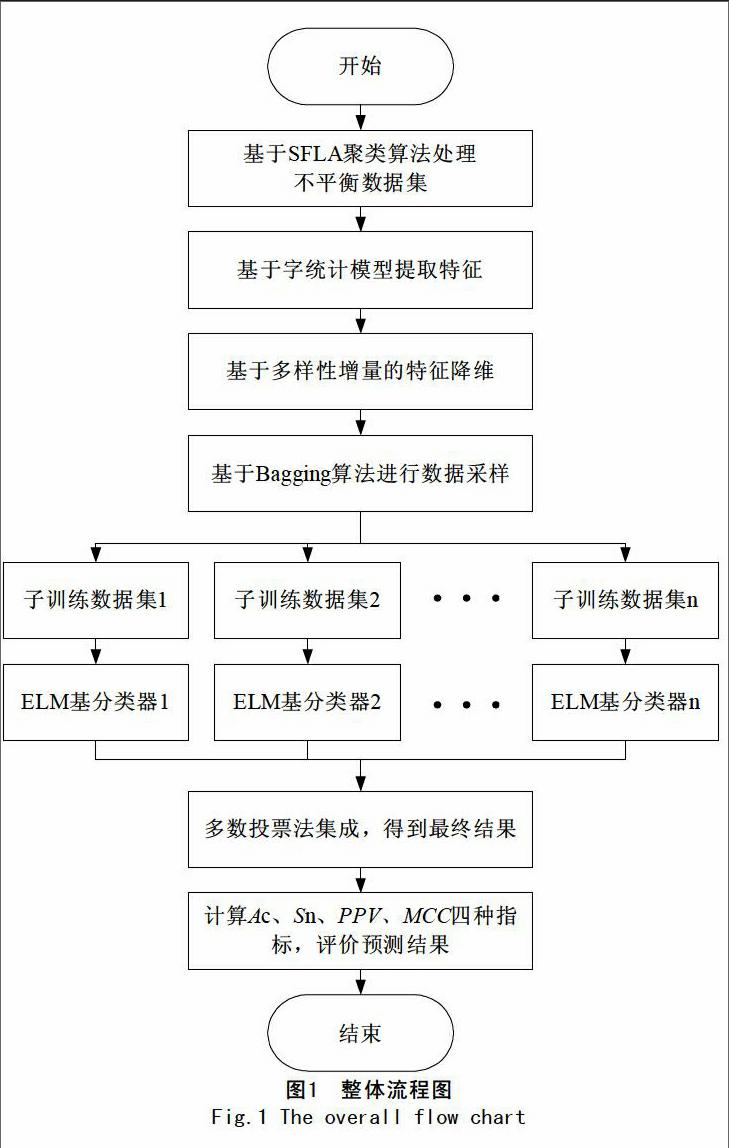
5 集成预测流程
整体预测流程如图1所示。首先,对不平衡原始数据进行处理,采用SFLA聚类算法对负类样本进行欠采样,与正类样本整合构成新的平衡数据集。然后,基于字统计模型提取特征构成特征向量,并利用多样性增量原理对所提取高维特征进行降维。再次,用Bagging算法产生差异化训练样本训练各ELM分类器,并采用多数投票法集成各分类器预测结果。最后,计算Ac、Sn、PPV、MCC四种指标,评价预测结果。
参考文献
[1]周志华,唐伟.基于Bagging的选择性聚类集成[J].2005,16(4):496-501.
[2]周志华,唐伟,吴建鑫.静态灰度图像中的人脸检测方法综述[J].计算机科学,2002Vo1.29:2-4.
