
可变结构的并行计算中任务粒度细化可扩展方法
2016-11-23 06:02熊焕亮曾国荪
同济大学学报(自然科学版) 2016年10期
熊焕亮, 曾国荪
(1.同济大学 电子与信息工程学院,上海 200092; 2.江西农业大学 软件学院,江西 南昌 330045;3.国家高性能计算机工程技术中心同济分中心,上海 200092)
可变结构的并行计算中任务粒度细化可扩展方法
熊焕亮1,2,3, 曾国荪1,3
(1.同济大学 电子与信息工程学院,上海 200092; 2.江西农业大学 软件学院,江西 南昌 330045;3.国家高性能计算机工程技术中心同济分中心,上海 200092)
首先评估并行任务及体系结构中影响可扩展性的关键因素,并对并行任务及体系结构进行图建模.然后,提出一种DAG任务粒度细化的可扩展方法,本质上是变换图的结构、调整图节点权值和边权值.进一步推导得出一些关于新扩展方法的有用结论.最后,应用网格模拟工具SimGrid开展实验,结果表明所提出的扩展方法,能实现可变结构并行计算的等速度效率扩展,对于并行计算扩展实践有指导意义.
并行计算; 机器与算法; 可变结构; 扩展方法
并行计算系统常通过扩展其规模来获得更高的计算性能.可扩展性是评价并行计算系统能否扩展的一个极其重要性能指标[1].开展可扩展性研究首要问题是如何定义和度量并行计算可扩展性.关于并行计算可扩展性度量机制的研究中,比较有代表性的成果有:等效率(Iso-efficiency)[2]机制,等平均速度(Iso-speed)[3]机制,延迟度量(Latency metric)机制[4]等.国内对并行计算可扩展性的研究也取得了一些重要研究成果:李等提出了一种等并行计算时间与通信开销之比的可扩展性模型[5],李等提出了一种近优可扩展模型[6],杨等提出了一种加速比增大的倍数与机器规模增大的倍数之比的可扩展性模型[7],孙等将等平均速度度量机制扩展至异构系统,提出了等平均速度效率度量机制(Iso-speed-e scalability metric)[8].杨学军院士特别指出可扩展性度量在并行计算发展进程中的重要地位[9].
可扩展性研究的另外一个重要内容是可扩展方法的研究.最初,可扩展方法的研究聚焦于机器的扩展,主要思路是通过增加诸如CPU、内存、输入/输出接口等重要处理部件的数量,从而实现机器的扩展.对于体系结构的可扩展研究,则主要关注节点间互连结构的可扩展性,例如树形的互连结构可扩展性良好,而超立方体结构却难以扩展.并行算法的可扩展方法则主要在于可扩展性度量和试验测量两方面,此类扩展方法中较突出的有Speedup方法[10-11]、Iso-efficiency方法[2]、Iso-speed方法[3]、Latency方法[4]、以及同济大学曾国荪教授提出的等综合性能面积方法[12].
目前,改善并行计算系统的可扩展性取得一些新成果,包括硬件可编程可重构方法、程序编译优化和重写技术等.硬件可编程重构技术通过硬件可编程适应计算任务需求的变化,以期达到最佳性能.Tessier等[13]全面地综述了可重构体系结构,指出可重构体系结构在计算并行任务时,对于不同的软件实现,计算硬件均能获得较好的性能和能效.程序编译优化等软件可重构技术则是通过优化任务程序算法,变换程序算法结构,以适应硬件体系结构的变化升级,较之硬件可重构技术,更为灵活和方便.曾国荪等[14]给出了计算任务与体系结构匹配的异构计算等速度可扩展定义及可扩展性条件.熊焕亮等[15]针对一类结构固定的并行计算,开展了等速度效率的可扩展性研究,针对并行任务的算法结构和并行机的体系结构同构情形,提出了一种变图权的等速度效率可扩展方法,而针对两者结构异构情形,提出了一种关键路径不变的等速度效率可扩展方法.
近年建设的并行计算系统在设计和建造时大多兼顾了后续可能的扩展升级.而对于拥有源码等所有文档资料的并行任务求解程序,不受算法结构固定的约束,完全可根据硬件体系结构的特性,优化并行任务的粒度和算法结构.本文对此类可变结构的并行计算,提炼其可扩展关联变量,对并行任务和体系结构进行图建模,给出满足实际扩展需求及可扩展性目标的扩展方法.
1 可变结构并行计算的概念及扩展性度量
在实际应用中,诸如地球模拟,气象预报等诸多领域,不断对计算性能提出了更高的挑战性需求.大量并行计算机系统迫切需要扩展升级,相应地,并行任务的求解算法也急需扩展优化,以匹配扩展后的计算机系统.此类并行计算机系统的软硬件升级往往需要改变软硬件的结构.
定义1 可变结构的并行计算:指开展并行计算时,为提高并行计算系统的计算能力,允许并行机的体系结构做合理的调整,或者为了求解更大规模的问题以及更高精度的问题解,并行任务的求解算法结构可做合理的调整.
由定义1可知,对于可变结构的并行计算,结构可变意味着可在原体系结构基础上增加更多的计算节点,以及相应的通信链路,也可增加并行任务的计算负载,优化任务的计算粒度,实现可变结构并行计算的扩展.可扩展性是并行计算的重要性能指标之一,是指一个并行计算系统随着其计算节点规模的扩展,其计算性能相应增强的能力,其度量如下定义.
定义2 可扩展性度量函数:是指并行计算扩展实践中,用于计算及度量其可扩展性程度的关系表达式.记并行任务扩展前、后的计算负载分别为W1,W2,并行机体系结构扩展前、后的标记速度分别为C1,C2,则可扩展性度量函数定义为Φ(C1,C2)=(W1/C1)/(W2/C2).
定义2给出了并行计算等速度效率可扩展性的度量函数,其中体系结构的标记速度等于其每个计算节点分别运行基准测试程序所测得的计算速度之和,速度效率等于并行任务运行于体系结构上的平均速度与体系结构标记速度的比值.函数Φ(C1,C2)∈(0,1],在理想情况下,Φ(C1,C2)=1.一般情况下,Φ(C1,C2)<1.
2 可变结构并行计算的图模型
2.1 可变结构体系结构的图描述
定义3 可变结构的体系结构: 是指一类建设好的、开放的,并已成功运行的并行计算机系统,即指由若干计算节点及网络设备,通过高速网络连接而成的并行计算环境,且其计算节点可再次增加、网络结构可相应调整,可表示为一个带权图HSG=〈P,U,C,B〉,其中:
(1)图顶点集合P={pi|i∈[1,m]}表示体系结构中计算节点集,m=|P|表示计算节点数.
(2)图边集U={uk|k∈[1,s]}表示体系结构中计算节点的互连情况,边数s=|U|表示其中通信链路数.边uk=(pi,pj),pi,pj∈P表示计算节点pi,pj由高速通信网络连接在一起.
(3)权值集合C={ci|i∈[1,m]}表示各计算节点标记速度集,其中ci为计算节点pi的标记速度.
(4)权值集合B={bk|k∈[1,s]}表示互连计算节点间通信链路的带宽集.∀uk=(pi,pj)∈U,边uk的权值bk表示计算节点pi和pj间通信链路的带宽.
定义3中的结构可变是指扩展时可增加新的计算节点及通信链路,由此引起计算节点之间互连结构的变化,在体系结构图模型中表现为图的拓扑结构是可变的.
2.2 可变结构并行任务的图描述
定义4 可变结构的并行任务: 是指一类开发好的,可重构的,并已成功运行过的并行程序,即为适应扩展后的体系结构,程序任务的求解流程和算法可重构,如任务的求解粒度及任务依赖关系可重新调整,可表示为一个有向无环图PTG=〈Q,L,E,Γ,A,Δ〉,其中:
(1)顶点集Q={qi|i∈[1,n]}表示并行任务集,图阶n=|Q|表示并行任务数,且n可变.
(2)有向边集L={lh|h∈[1,r]}表示关联任务间的数据依赖集,L⊆Q×Q.∀lh=〈qi,qj〉,lh表示任务qj对qi存在数据依赖.
(3)权值集E={εi|i∈[1,n]}表示并行任务计算精度集, 计算精度用相对误差率表示, 如ε1=0.1表示计算结果精确到小数点后1位, 精度ε1提高10倍,则ε1变为0.1/10=0.01.
(4)权值集Γ={γi|i∈[1,n]}表示并行任务问题规模集,如在矩阵相乘算法中,问题规模为矩阵维数.
(5)权值集A={αi|i∈[1,n]}表示并行任务的串行分量集.
(6)权值集Δ={δi|h∈[1,r]}表示关联任务之间传输负载集.
通常,在改变任务程序的计算精度或问题规模时,会引起任务程序计算负载的变化,不妨设并行任务qi的计算负载wi为其计算精度εi和问题规模γi的函数Ψi,即wi=Ψi(εi,γi).理论上任务之间的数据传输量与相关任务的计算负载密切相关,为便于扩展性分析,将数据传输量作为独立的参数.
3 可变结构DAG任务粒度细化的扩展方法
3.1 DAG任务粒度细化扩展的前提假设
(1)假设扩展前DAG并行任务已在原有并行机上成功运行,满足既定的功能和性能要求.
对于一DAG图并行任务PTG1=〈Q1,L1,E1,Γ1,A1,Δ1〉,并行任务总数为n1,数据依赖关系数为r1.假设任务按照某种调度策略调度在体系结构HSG1=〈P1,U1,C1,B1〉上成功地执行,体系结构中计算节点总数为m1,通信链路总数为s1,则PTG1的执行时间T1和速度效率Ev1可通过如下分析计算得到.
(1)
(2)
在并行任务DAG图中,从起始子任务至终止子任务存在多条执行路径,为便于描述每条路径的执行时间,分别定义任务节点隶属路径函数φj(i),如式(1)所示,以及数据传输边隶属路径函数φj(h),如式(2)所示.φj(i)=1表示任务qi在第j条路径Pathj上,φj(h)=1表示数据依赖lh在第j条路径Pathj上且lh对应的两个任务不在同一计算节点.记并行任务路径总数为N1,则整个并行任务的执行时间T1为
(3)
其中f和g为并行任务在并行机上执行时采用的调度策略.并行任务的执行时间T1取决于关键路径的执行时间,关键路径执行时间可参考文献[15]中方法求解.在并行任务的执行时间T1确定后,任务执行的速度效率Ev1为
(4)
(2)并行机系统体系结构已扩展完成

图1 体系结构的扩展
假设并行机的体系结构从HSG1=〈P1,U1,C1,B1〉扩展为HSG2=〈P2,U2,C2,B2〉,系统的标记速度从C1扩展为C2,计算节点数从m1增加至m2,通信链路数从s1增加为s2,新增通信链路带宽足够大.然后在此基础上,研究如何扩展重构并行任务以匹配新的体系结构.
3.2 DAG任务粒度细化的扩展过程
由假设(2)可知,体系结构扩展后,标记速度扩展了β=C2/C1倍.自然地,随体系结构性能的增强将DAG并行任务中每个任务的计算负载也扩展β倍,以实现待求解问题更高的求解精度.假设DAG任务的扩展过程中,串行计算部分保持不变,仅并行计算部分增加.
记扩展前DAG并行任务PTG1的任务序列为Q1=(q11,q12,…,q1n1),对应的计算负载序列为W1=(w11,w12,…,w1n1),每个任务的串行分量序列为A=(α1,α2,…,αn1),则任务q1i扩展后的计算负载w2i=αiw1i+β(1-αi)w1i,其中β(1-αi)w1i为可并行计算负载.
在任务的可并行计算负载扩展后,需要将任务执行的粒度细化,以尽可能均衡任务的计算负载,使加速计算任务的执行成为可能.DAG并行任务粒度细化的启发式方法如下:



(6) 根据PTG1的DAG图,采用算法1确定每个任务节点所在层的并发度.
(9) 若PTG1中所有任务节点均处理完毕,则DAG任务细化结束,否则转(7).
假设经过分析,DAG并行任务中每个任务均实施扩展细化,则其扩展后的DAG并行任务如图2b所示,每个任务均扩展细化为3个子任务,即2个可并行计算的子任务,1个规约任务,任务之间的依赖为粒度细化而产生的额外通信,例如任务q11,扩展为(q21-1,q21-2,q21-0)3个子任务,其中q21-1,q21-2为可并行计算的子任务,q21-0为规约子任务.
算法1. ComputeDOPForLevel//计算DAG并行任务中每个任务所在层及该层并发度.
输入:初始的并行任务DAG图(以邻接表存储)
输出:DAG并行任务中每个任务所在层nodeLevel[]及每层的节点数levelCount[]
{
初始化任务队列Queue,节点所在层号数组nodeLevel[],每层的计算节点数levelCount[]全为0;
初始化变量currentLevel=0,totalNodeNum=0;
将DAG图中所有入度为0的任务节点入队;
while(Queue不为空){
GetQueuelength;//取当前队列的长度
totalNodeNum+=Queuelength;//计算DAG并行任务总任务数.
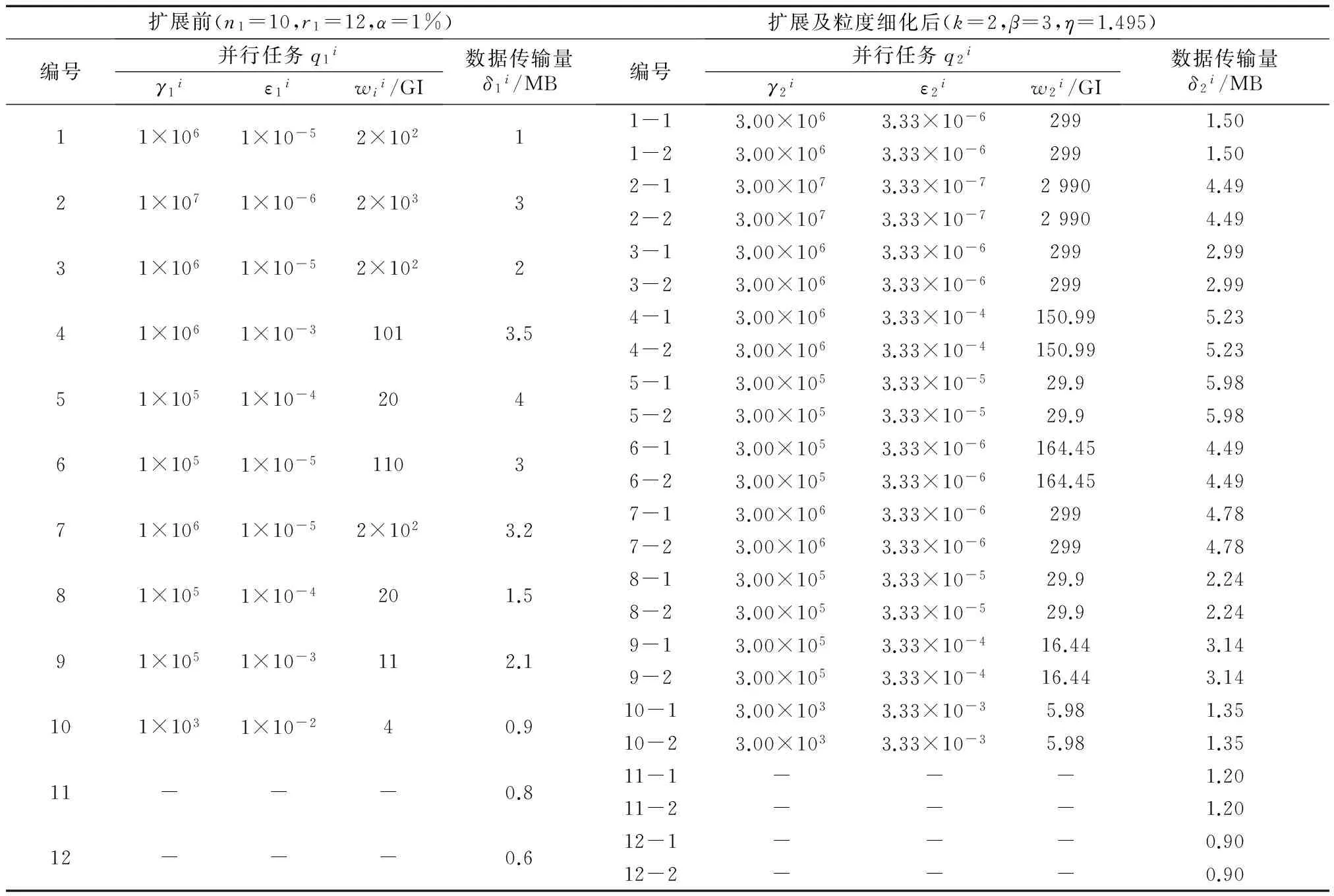
for(int i=0;i 队头节点head出队; nodeLevel[head.nodeNumber]=currentLevel;//标记节点所在层号. head指向的全部节点入队;//head节点的所有邻接节点入队. } currentLevel++; } for(int i=0;i levelCount[nodeLevel[i]]++;//计算每层的节点数. } } } 图2 DAG并行任务的扩展及其粒度细化 4.1 DAG任务扩展及粒度细化后并行计算性能分析 4.1.1 可变结构并行计算扩展参数的详细假定 (1)并行机体系结构扩展参数的假定 (2)DAG并行任务扩展细化参数的假定 根据假设(1),扩展前DAG并行任务已成功调度至所匹配的计算节点.不妨假设任务DAG图的N1条执行路径中,第j条路径为关键路径,则由式(3)可得DAG并行任务的执行时间T1为 (5) 随着体系结构标记速度由C1扩展提高为C2,DAG并行任务中每个任务的并行计算负载相应地扩展β=C2/C1倍,任务q1i扩展后的计算负载由原串行部分和扩展后的并行部分组成,即w2i=αiw1i+β(1-αi)w1i. 为便于分析,假设DAG并行任务中所有任务均细化为k+1个子任务,k=m2/m1.任务q1i在扩展并实施粒度细化后,生成k个子并行任务(q2i-1,q2i-2,…,q2i-k),每个子任务的计算负载为扩展前任务q1i负载w1i的η倍,η=α+β(1-α)/k,即w2i-1=w2i-2=…=w2i-k=ηw1i,以及1个规约子任务q2i-0. 对于数据依赖关系l1h=〈q1i,q1j〉,不妨设DAG并行任务扩展后,传输给每个后继子任务的通信负载为扩展前通信负载δ1h的η倍,即为ηδ1h. (3)扩展及粒度细化后的DAG并行任务与新体系结构的匹配映射 扩展前,任务q1i映射至匹配的计算节点p1f(i),不妨设q1i扩展及粒度细化生成的子任务q2i-1及q2i-0映射至计算节点p1f(i)),生成的其它子任务(q2i-2,…,q2i-k)映射至新增计算节点(p2f(i)-2,…,p2f(i)-k),如图3所示. a 关键路径任务粒度细化 b 扩展后的体系结构 扩展前,任务之间的数据通信l1h映射至链路u1g(h), 扩展后,依赖数据在传输给新增计算节点时,需经原通信链路u1g(h)传输至原计算节点,再经新增通信链路传输至新增计算节点,如图3所示. 4.1.2 可变结构并行计算DAG并行任务关键路径的扩展分析 根据假定(3),子任务q2i-1与q2i-0在计算节点p1f(i)上执行,由于与p1f(i)直连的新增计算节点标记速度不低于p1f(i)的标记速度,故q2i-1与q2i-0在p1f(i)上的计算时间不小于其它子并行任务在新增节点上的计算时间,而q2i-0的计算时间可理解为子并行任务(q2i-1,…,q2i-k)之间的数据规约等产生的时间开销Toi,Toi=max(δi-1/b,δi-2/b,…,δi-k/b),因此任务q1i扩展及粒度细化后,在匹配的计算节点上的执行时间为ηw1j/c1f(i)+Toi,其中η=α+β(1-α)/k.数据通信l1h的传输负载扩展η倍后,数据传输时间可近似为ηδ1h/b1g(h)+ηδ1h/b. 命题1 可变结构并行计算中,DAG并行任务PTG1=〈Q1,L1,E1,Γ1,A1,Δ1〉在匹配的体系结构HSG1 根据命题1,可变结构并行计算中,体系结构HSG1扩展为HSG2,DAG并行任务PTG1扩展为PTG2后,PTG2的执行时间为T2,即 (6) 并行计算的速度效率近似为 (7) 命题2 可变结构并行计算中,DAG并行任务PTG1=〈Q1,L1,E1,Γ1,A1,Δ1〉在匹配的体系结构HSG1〈P1,U1,C1,B1〉上执行的关键路径为j,如果HSG1按照假设(1)已扩展为HSG2,PTG1中每个任务的串行分量均为α,并按照假设(2)实施粒度细化扩展为PTG2,且PTG2和HSG2已按照假设(3)匹配映射好,则PTG2在HSG2上执行的速度效率Ev2小于等于Ev1. 由命题2可知,可变结构的并行计算实施任务粒度细化扩展时,速度效率保持近似相等.根据定义2,等速度效率可扩展性函数Φ=(W1/C1)/(W2/C2)=(C2/C1)/(W2/W1)=β/(kα+β(1-α)+χ)=1/(αk/β+(1-α)+χ/β),其中χ为规约子任务计算负载比重.若忽略规约子任务计算负载,即χ=0,且α一定时,显然有 (8) 当k<β时,即总计算负载的增长较系统标记速度的增长更慢,故有Φ>1,反之,当k≥β时,总计算负载的增长较体系结构标记速度的增长更快,故有Φ≤1. 4.2 可变结构并行计算扩展的仿真实验 4.2.1 仿真实验工具及实验设计 为验证所提出可扩展方法的有效性,在实验室的Dell PC集群上,利用SimGrid3.10开展扩展模拟实验.集群平台包括32个计算节点,由千兆以太网互连组成,每个节点的CPU为Intel(R) XeonTM3.0 GHz,缓存4 GB,内存32 GB.操作系统为Redhat Linux9.0,并行计算软件环境为MPICH2. 表1 可变结构的体系结构扩展前后的性能参数(带下划线项为关键路径对应的数据项) 可变结构的并行计算仿真实验中,扩展前的并行任务PTG1如图2a所示,体系结构HSG1如图1a所示,HSG1及PTG1的具体参数取值如表1和表2所示,且实验中任务的计算负载与问题规模及计算精度的函数关系假设为wi=105γi+106/εi.表2中参数α=1%为任务PTG1的串行分量,任务PTG1的计算规模和计算精度提升,任务计算负载相应地扩展β=C2/C1=3倍,k=m2/m1=2为任务PTG1的粒度细化因子,任务PTG1粒度细化后,通信负载的扩展倍数η=α+β(1-α)/k=1.495. 实验中,并行任务qi调度至计算节点pf(i),表示为二元组(qi,pf(i)),DAG并行任务PTG1与体系结构HSG1中计算节点的映射关系具体为:(q11,p11),(q12,p11),(q13,p13),(q14,p11),(q15,p12),(q16,p14),(q17,p13),(q18,p12),(q19,p15),(q110,p15).在体系结构HSG1扩展为HSG2,并行任务PTG1扩展细化为PTG2后,各并行子任务与计算节点的映射参照扩展之前的匹配映射,例如,任务q11细化为(q21-1,q21-2,q21-0),其中q21-1和q21-0映射至计算节点p21-1(即原计算节点p11),q21-2映射至新增计算节点p21-2,其它子任务与计算节点的映射类似. 4.2.2 仿真实验结果及分析 对于可变结构的并行计算,在体系结构已扩展升级好之后,并行任务采用任务粒度细化的扩展方法进行模拟扩展,在SimGrid3.1上运行模拟程序Simulator,实验结果如表3所示. 表3中扩展后的速度效率0.361近似于扩展前的速度效率0.373,表明实验中任务粒度细化扩展方法基本上实现了等速度效率扩展,扩展后的速度效率略低于扩展前的速度效率,主要是由于细化后的子任务之间规约开销,从而影响了实际运行速度.另外,实验中k=2,β=3.0, 根据公式(8),有Φ>1,但实际上规约子任务计算负载总是客观存在,实验中取χ=0.14,χW1=390GI,从而有Φ=0.959. 为揭示不同的(k,β)对计算密集型、通信密集型及计算通信平衡型三类并行任务速度效率及可扩展性的影响,我们以表1中所描述的体系结构,表2所描述的并行任务算法结构为基准,以高通信负载比重模拟通信密集型任务,变换k和β,实施多次模拟扩展实验.扩展实验的速度效率变化曲线如图4所示,可扩展性变化曲线如图5所示.图4中速度效率的变化曲线表明,在任务的结构和计算负载,扩展参数(k,β)均相同时,通信密集型任务因通信延迟开销较大,速度效率较计算密集型任务的速度效率明显偏低,而计算通信平衡型任务的速度效率则介于两者之间. 根据式(8),当上述两类任务的串行比α,以及参数k,β相同时,其可扩展性理应相同,但图5中扩展性曲线表明,任务类型为通信密集型的并行计算,其可扩展性较计算密集型更小,计算通信平衡型任务的可扩展性介于两者之间,这是由于通信密集型任务计算中通信负载比重较大,任务粒度细化生成的规约任务的计算负载明显增加,致使其可扩展性降低.另外,图5中计算密集型任务与通信密集型任务相比较,其可扩展性基本保持不变,这是因为计算密集型任务粒度细化扩展方法中,产生的额外通信、规约等开销极少,可扩展性主要取决于参数k和β. 表2 可变结构的并行任务扩展前后的性能参数(带下划线项为关键路径包含的数据项) 表3 可变结构并行计算任务粒度细化扩展实验结果 (k,β),k:任务粒度细化因子;β:计算负载扩展因子 (k,β),k:任务粒度细化因子;β:计算负载扩展因子 对于一些成熟的、已成功运行的并行计算应用系统,为获得更高的计算性能,通常会扩展计算节点规模,增大任务计算负载,优化任务算法结构.针对此类可变结构并行计算的可扩展问题,本文分析影响其可扩展性的并行任务因素及体系结构因素,对并行任务及体系结构进行图建模.特别针对体系结构业已扩展升级好,如何增大并行任务的计算负载,优化任务算法结构的扩展问题,提出了DAG任务粒度细化的可扩展方法,实质上为变换图结构的可扩展方法.通过分析扩展前后的速度效率性能,证明了DAG任务粒度细化的扩展方法可基本实现可变结构并行计算的等速度效率扩展.最后,为验证所提出可扩展方法的有效性,编写了基于网格计算模拟工具SimGrid3.10的C语言程序Simulator,模拟任务在体系结构上的运行,从而实现模拟扩展实验,结果表明所提出的扩展方法实现了可变结构并行计算的等速度效率扩展. [1] 李晓梅, 莫则尧, 胡庆丰,等. 可扩展并行算法的设计和分析[M]. 长沙:国防工业出版社,2000. LI Xiaomei, MAO Zeyao, HU Qingfeng,etal. Design & analysis of scalable parallel algorithms[M]. Changsha: National Defense Industry Press, 2000. [2] Grama A, Gupta A, Kumar V. Iso-efficiency: measuring the scalability of parallel algorithms and architectures[J]. IEEE Parallel & Distributed Technology, 1993, 1(3): 12. [3] Sun X H, Rover D T. Scalability of parallel algorithm machine combinations[J]. IEEE Transactions on Parallel Distributed Systems, 1994, 5(6):599. [4] Zhang X D, Yan Y, He K. Latency metric: an experimental method for measuring and evaluating parallel program and architecture scalability[J]. Journal of Parallel and Distributed Computing, 1994, 22(3): 392. [5] Wu X F, Li W. Performance models for scalable cluster computing[J]. Journal of Systems Architecture, 1997, 44(3):189. [6] 陈军. 李晓梅. 近优可扩展性:一种实用的可扩展性度量[J]. 计算机学报, 2001, 24(2):179. CHEN Jun, LI Xiaomei. Near-optimal scalability: a practical scalability metric[J]. Chinese Journal of Computers, 2001, 24(2):179. [7] 王与力, 杨晓东. 一种更有效的并行系统可扩展性模型[J].计算机学报, 2001, 24(1): 84. WANG Yuli, YANG Xiaodong. A more effective scalability model for parallel system[J]. Chinese Journal of Computers, 2001, 24(1): 84. [8] Chen Y, Sun X H, Wu M. Algorithm-system scalability of heterogeneous computing[J]. Journal of Parallel and Distributed Computing, 2008, 68(11): 1403. [9] Yang X J, Wang Z Y, Xue J L. The reliability wall for exascale supercomputing[J]. IEEE Transactions on Computers, 2012, 61(6):767. [10] Sun X H, Ni L M. Scalable problems and memory-bounded speedup[J]. Journal of Parallel and Distributed Computing, 1993, 19(1): 27. [11] Yang X J, Du J, Wang Z Y. An effective speedup metric for measuring productivity in large-scale parallel computer systems[J]. Journal of Supercomputing, 2011, 56(2):164. [12] Xiong H L, Zeng G S, Zeng Y. A novel scalability metric about iso-area of performance for parallel computing[J]. Journal of Supercomputing, 2014, 68(2):652. [13] Tessier R, Pocek K, DeHon A. Reconfigurable computing architectures[J]. Proceedings of the IEEE, 2015, 103(3):332. [14] 郝水侠, 曾国荪, 谭一鸣. 计算任务与体系结构匹配的异构计算可扩展性分析[J]. 电子学报, 2010, 38(11): 2585. HAO Shuixia, ZENG Guosun, TAN Yiming. Scalability analysis of heterogeneous computing based on computation task and architecture to match[J].ActaElectronicaSinica, 2010, 38(11): 2585. [15] Xiong H L, Zeng G S, Ding C L,etal. Extensions by graph weight for parallel computing under the constraint of fixed structure[J]. IETE Journal of Research, 2015:doi:10.1080/03772063.2015.1093967, 2015. Extension by Refining Task Granularity for Parallel Computation with Variable Structures XIONG Huanliang1,2,3, ZENG Guosun1,3 (1. College of Electronics and Information Engineering, Tongji University, Shanghai 201804, China; 2. Software College, Jiangxi Agricultural University, Nanchang 330045, China; 3. Tongji Branch National Engineering & Technology Center of High Performance Computer, Shanghai 201804, China) Aiming at such extension problem in parallel computation, this paper evaluates the key factors from parallel tasks and architecture which affect the scalability, and then models parallel tasks as well as architecture by the weighted graph. Especially, we propose the extension method of refining task granularity to realize an extension in parallel computation. The extension method transforms the graph’s structure and adjusts the weights of its nodes and edges in essence. Additionally, by further derivation, some significant conclusions about the new extension methods are drawn. Finally, the simulative experiments are conducted on the platform SimGrid to verify the effectiveness of the proposed extension methods. The results show that the new methods can realize iso-speed-e extension in parallel computation with variable structures, which is helpful for its practical extension. parallel computation; machine and algorithm; variable structures; extension method 2015-10-08 上海市优秀学科带头人计划(10XD1404400);江西省自然科学基金(20161BAB212047,20151BAB207040);华为创新研究计划(IRP-2013-12-03);高效能服务器和存储技术国家重点实验室开放基金(2014HSSA10);江西省教育厅科研项目(GJJ150426). 熊焕亮(1977—),男,博士生,主要研究方向为并行分布处理.E-mail: 2012_xionghuanliang@tongji.edu.cn 曾国荪(1964—),男,教授,博士生导师,工学博士,主要研究方向为并行计算、可信软件和信息安全. E-mail:gszeng@tongji.edu.cn TP338 A
4 可变结构并行计算DAG任务粒度细化扩展方法的性能评估

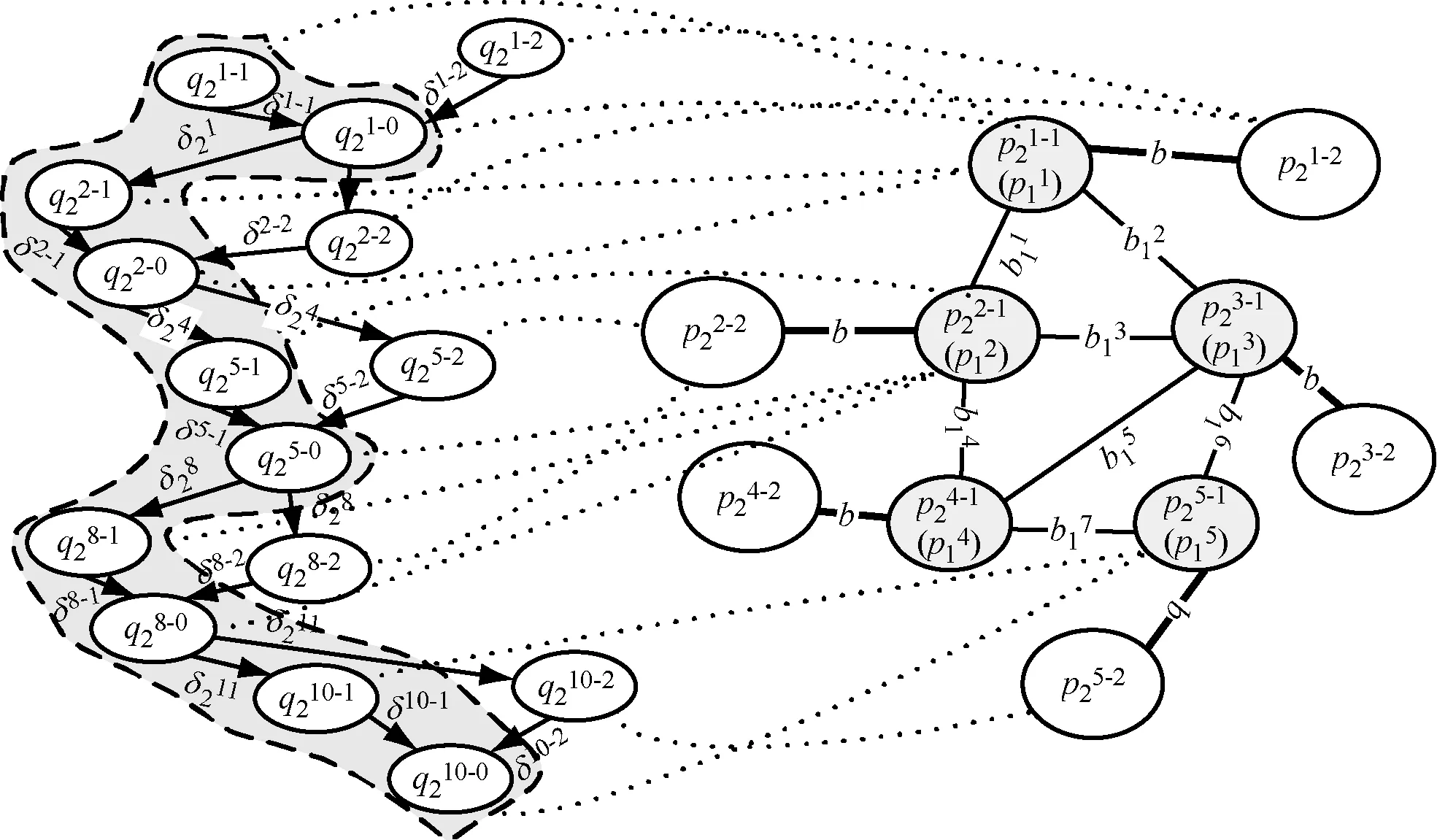
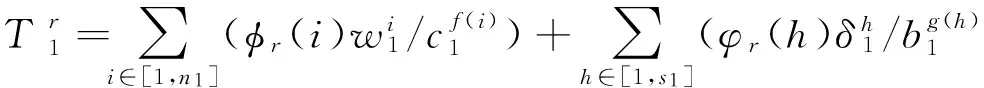
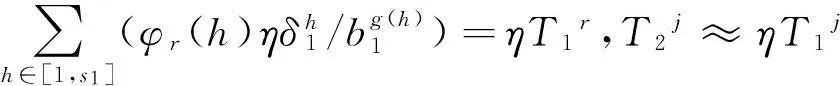







5 结束语
猜你喜欢
电子制作(2019年10期)2019-06-17劳动保护(2018年5期)2018-06-05华人时刊(2018年23期)2018-03-21汽车零部件(2017年3期)2017-07-12中华建设(2017年3期)2017-06-08自动化博览(2017年2期)2017-06-05电脑知识与技术(2016年14期)2016-06-30现代防御技术(2016年1期)2016-06-01海军航空大学学报(2015年1期)2015-11-11空间控制技术与应用(2015年4期)2015-06-05
