
一种基于维纳滤波的改进去混响方法*
2016-11-30 07:44牛莉莉
通信技术 2016年8期
牛莉莉,徐 岩
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
一种基于维纳滤波的改进去混响方法*
牛莉莉,徐 岩
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
针对混响对语音信号不同频率成分的影响各不相同的特点,对前人提出的基于维纳滤波的去混响方法作了改进。参照人耳的听觉感知特性,引进一组Gammatone听觉滤波器,完成对混响语音的分频带处理,从而在各个子带中独立地去混响,体现了语音频带信息的差异性。对该方法进行实验仿真,分别运用一些主客观的评价指标对实验结果进行评价和分析。结果表明,与复倒谱域滤波、维纳滤波方法相比,该方法取得了更好的去混响效果。
Gammatone听觉滤波器组;去混响;维纳滤波;评价指标
0 引 言
在相对封闭的空间里,当说话人使用电话、手机等时,如果距麦克风的位置较远,则会存在混响现象,从而使声音音质降低、含糊不清,严重影响人耳的听觉效果[1]。所以,寻求有效可行的方法实现去混响是一项重要的课题。
本文对前人提出的基于维纳滤波的去混响算法作了改进[2],参照人耳的听觉感知特性,引进一组Gammatone听觉滤波器,介绍了基于Gammatone听觉滤波器组和维纳滤波的去混响算法。主要工作包括:首先,利用常规通话起始音的特点,提出预存起始纯净语音,基于维纳滤波原理,通过反卷积运算估计出房间冲击响应;其次,针对混响对语音各个频率成分的影响各不相同的特点,利用Gammatone听觉滤波器组将语音分解成各个子带信号,在子带中分别利用第一步得到房间冲激响应;再次,获得其逆系统的冲激响应,将此估计值作为初始值,设计相应的滤波器实现去混响;最后,将各子带信号合成,进而重组纯净语音[3]。利用Gammatone听觉滤波器组完成子带的分解过程与听觉感知模型相对应,即在子带中各自实现去混响,各个频带中的特征信息被较完整地保留,最终重构的语音信号能取得较好的听觉效果。
1 Gammatone听觉滤波器组
人耳由内耳、中耳和外耳组成。耳蜗位于内耳中,可以将接收到的机械振动转换为神经冲动,由听神经传到大脑。然而,完成这一系列作用的神经末梢及感受细胞等,就在耳蜗的基底膜上。
在人耳听觉感知形成过程中,基底膜对声音的动态响应影响很大。首先,它有频率选择能力。当输入较高频率的纯音时,基底膜底部接近幅度最大的位置;当输入较低频率的纯音时,基底膜顶部出现幅度最大的位置。其次,它有频谱分析能力。当复合音输入时,不同的频率分量对应着不同位置,不同的声音强度对应着不同幅度,这样就把复合音中的不同频率分量和对应的幅度分离开,实现对声音强度和频率的编码。
由上可知,声音在基底膜各个位置上的响应过程等同于一次滤波,通过创建听觉滤波器的数学模型可以近似实现这一响应过程。常用的有Gammatone滤波器、Roex函数滤波器、共振滤波器以及Gammachirp滤波器。Roex函数滤波器和共振滤波器都存在一些缺陷。前者具有较为复杂的冲激响应函数,实现起来较为困难;而后者则不能很好地展现出基底膜的主动机制特性和非线性;Gammachirp滤波器则比较复杂,通常由Gammatone滤波器和一个无限冲激响应滤波器组成。由于Gammatone滤波器的冲激响应函数需要少量的参数,实现方便,同时能够较好地模拟人耳听觉特性,因此本文采用Gammatone滤波器作为听觉滤波器[4]。
Gammatone滤波器冲激响应函数的时域表达式:
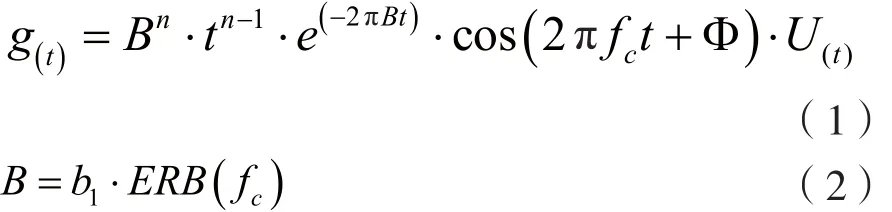
式中,参数n为滤波器阶数,B为增益,fc为中心频率,U(t)为单位阶跃函数,Φ为初始相位。为了简化模型,本文取Φ=0,n=4。参数ERB(fc)表示Gammatone滤波器的等效矩形带宽,ERB(fc)和中心频率fc的关系是:
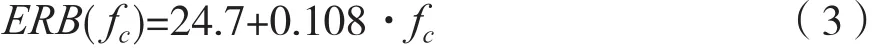
心理声学研究表明,人耳对声音的听觉感知以临界频带为基准,等同于一组不等带宽的子带滤波器完成语音从频域到临界频带域的转换。因此,通常滤波器的中心频率是和临界频带的中心频率相对应的。在人耳听阈范围内对应着26个频带,已知采样率就能得出滤波器个数。实验中取采样率为16 kHz,则最大频率为8 kHz。查看人耳临界频带表,可得出其对应的频带范围为7 000~9 500 kHz。因此,本文需要22个滤波器。Gammatone滤波器可以模拟出耳蜗的滤波特性,通过滤波器的幅频响应特性就可以直观地体现出来。图1给出了0~8 kHz频率范围内,滤波器个数为22个不同中心频率下的幅度响应曲线。

图1 Gammatone滤波器的幅频响应曲线
从幅频响应图中可以看出,Gammatone滤波器有以下频域特性:最大幅度出现在中心频率处的,即相应的滤波器;不同中心频率的滤波器有着不同的带宽,其两侧边沿都较陡,说明Gammatone滤波器的频率选择性比较好,所有的特征都与基底膜的滤波特性相对应。
2 维纳滤波去混响原理
已知t时刻的输入混响语音信号xt,设计一个滤波器(滤波因子)ht,使滤波器的实际输出yt= xt* ht与期望输出(纯净语音信号st)的误差在任何时刻都尽可能小。用每个时刻误差的平方和最小反映总误差最小:

求滤波因子ht,使式(4)误差平方和达到最小,可得:


式(5)中,ht为滤波因子ht的起始点;(m+1)为滤波因子的长度(维纳滤波器的阶数M);rxx为xt的自相关函数;rsx为st和xt的互相关函数。式(5)称为托布里兹方程,有较快递推解法[5]。
张德会等针对移动语音通信,利用上述维纳滤波算法[2],提出一种通过反卷积运算来进行语音去混响的方法。他的基本思路是利用人们日常进行语音通话时,总是习惯以“hi”“喂”等开始,将在混响较轻或者无混响环境下的通话起始音,如“hi”“喂”等作为纯净语音预存起来。在混响环境下通话时,还以“hi”“喂”等作为开始,这样便有同样语音的混响信号,通过维纳滤波反卷积运算就可以获得混响环境下的房间冲击响应;接着,当说话人发出其他声音时,就利用已求得的房间冲击响应,对其他语音经过反卷积运算进行去混响。系统框图如图2所示。
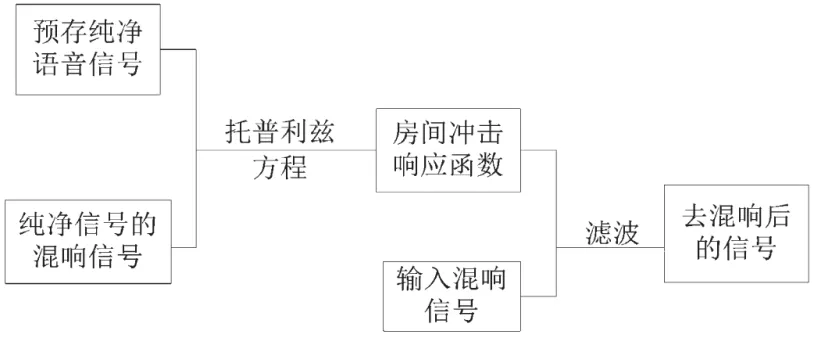
图2 混响消减系统
3 基于Gammatone听觉滤波器组和维纳滤波的去混响算法
人耳的听阈范围涵盖了语音所有的频率分量,利用一组Gammatone滤波器完成子带的分解,就可以将各个频率成分分离开来,从而在不同的子带中独立地去混响,体现出混响语音对频带影响的差异性,以进一步提高去混响的效果。具体的实现过程如下:查看人耳临界频带表,选择相应滤波器的中心频率,根据选出的Gammatone滤波器的冲激响应,计算其中心频率对应的滤波器传输函数,得到其频率响应,将混响语音通过这样一组滤波器完成滤波,最后从频域转换到时域,得到保留有不同频带信息的子带信号。
子带信号的分解是本文方法实现的预处理过程,接下来的任务便是去混响。结合第二部分叙述的内容,采用基于维纳滤波的方法来实现这一过程。即通过维纳滤波反卷积运算,得到混响环境下的房间冲击响应;然后,在已划分好的各个子带,利用已经得到的房间冲击响应,对各个子带语音经过反卷积运算进行去混响;最后,将各个子带的输出语音合成,得到去混响后的语音。整个过程的实现框图如图3所示。

图3 本文方法的实现过程
4 实验结果与分析
4.1实验结果
本文实验取标准语音库中某段语音作为纯净原始语音,语音的长度为3 s,采样频率为16 kHz,量化位数为16 bit。在适度混响环境下,分别采用本文方法、复倒谱域滤波方法和基于维纳滤波的方法实现混响消减。实验得到相应的语音时域波形图,如图4所示。
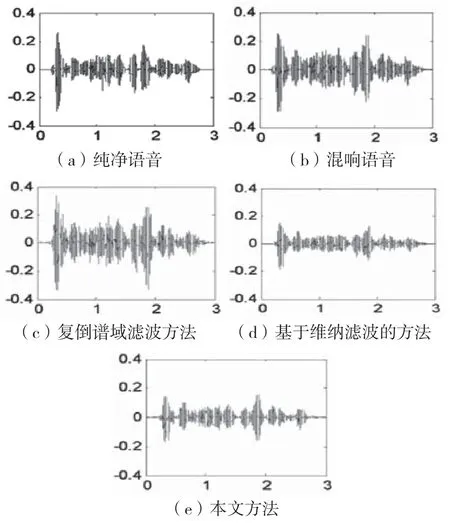
图4 不同方法得到的语音时域波形
从时域波形图可以看出,通过复倒谱域滤波方法得到的语音时域波形与混响语音很接近,表明去混响效果不理想,也说明单一的复倒谱方法去混响效果较差[6-7]。本文方法相比基于维纳滤波的方法,在适度混响条件下得到的结果更好,时域波形与纯净语音更为接近,表明去混响效果较好。
4.2语音去混响的主客观评价
评测混响消减的效果可从主客观两方面分别进行评测[8]。实验中采用的主观评测指标有:自然度、去混响度;客观评测指标有:线性预测倒谱系数(LPCC)的失真测度、Mel频率倒谱系数(MPCC)的失真测度。
4.2.1主观评价
(1)语音的自然度
语音自然度指听起来语音内容是不是可懂,整个衔接是不是流畅,即主要衡量去混响后的语音是否出现失真,主观上可分为优、良、中、差四个等级。实验中,邀请30人在相对安静的室内对几种去混响方法得到的语音进行反复评价,得到各种方法的自然度评价结果。
(2)语音的去混响度
语音去混响度指从主观听觉方面来感受混响消减的程度。同自然度类似,它在主观上也可分为优、良、中、差四个等级。同样,实验中邀请30人在相对安静的室内对几种去混响方法得到的语音进行反复评价,得到各种方法的去混响度的评价结果。
4.2.2客观评价
(1)线性预测倒谱系数的失真测度
线性预测倒谱系数的失真测度是基于语音线性预测分析提出的一种频域评测参数,能清晰地说明人耳对频率分辨的非均匀性、感知响度和声音强度之间的非线性关系。
(2)Mel频率倒谱系数的失真测度
Mel频率倒谱系数是一种以短时傅立叶变换为基础的谱包络参数,不依附全极点语音生成模型的设定,在噪声和混响环境下有着更好的鲁棒性。
在适度混响环境下,各种方法的去混响度、自然度评价结果及各自计算得到的线性预测倒谱系数的失真测度值、Mel频率倒谱系数的失真测度值如表1所示。
根据表1,从主观评测指标可以看出,比之另外两种方法,本文方法处理后的语音更为清晰、自然可懂度也要好些,说明去混响效果比较好。同时,从客观评测指标来看,另外两种方法得到的失真测度值较大,即得到的去混响语音相比原始语音出现了较大的失真,而本文方法得到的失真测度值较小且相对稳定,进一步表明本文方法得到的语音失真较小,质量较高。
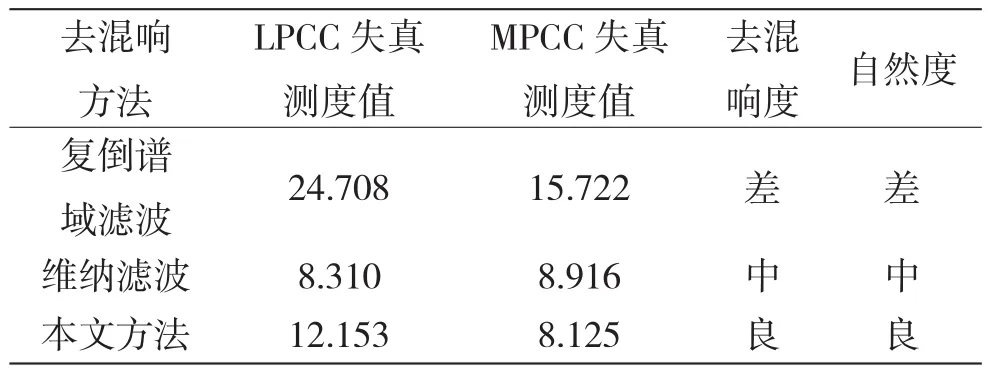
表1 三种去混响仿真实验的主客观评测
5 结 语
语音去混响的研究有着重要的理论价值和应用价值。它是语音增强的重要组成部分,同时作为语音合成、语音识别等的预处理过程,对提升室内语音通信的质量具有非常重要的作用。此外,语音去混响的研究在其他许多声学领域的应用前景也非常广阔。
本文针对基于维纳滤波的语音去混响的方法作了改进,依据人耳的听觉感知特性,引进一组Gammatone听觉滤波器,介绍了基于Gammatone听觉滤波器组和维纳滤波的去混响方法,综合人耳听觉感知特性和混响的频谱特性,利用一组Gammatone听觉滤波器,完成对混响语音的分频带处理,从而在各个子带中独立地去混响,体现了语音频带信息的差异性。接着,对几种去混响方法进行仿真实验,分别采用相应的主客观评价指标对得到的去混响语音进行评价和分析。结果表明,比之另外两种方法,本文方法取得了更好的去混响效果。
[1] 赵红,李双田.改进的多级线性预测晚期混响抑制算法[J].信号处理,2014,30(06):674-682. ZHAO Hong,LI Shuang-tian.Improved Late Reverberation Suppression Algorithm Using Multiple-step Linear Prediction[J].Journal of Signal Processing,2014, 30(06):674-682.
[2] 张德会,陈光冶.一种基于维纳滤波去除语音通信中混响的方法[J].上海交通大学学报,2009,43(06):949-952. ZHANG De-hui,CHEN Guang-ye.A Means based on Wiener Filtering for Dereverberation in Speech Communication[J].Journal of Shanghai Jiaotong University,2009,43(06):949-952.
[3] Hikichi T,Delcroix M,Miyoshi M.Inverse Filtering for Speech Dereverberation Less Sensitive to Noise and Room Transfer Function Fluctuations[J].EURASIP Journal on Applied Signal Processing,2007,2007(01): 62-62.
[4] Kumar K,Singh R,Raj B,et al.Gammatone Sub-band Magnitude-domain Dereverberation for ASR[C].IEEE International Conference on Acoustics,Speech and Signal Processing,2011:4604-4607.
[5] Yasuraoka N,Yoshioka T,Nakatani R,et al.Music Dereverberation Using Harmonic Structure Source Model and Wiener Filter[J].ICASSP,2010:53.
[6] Rotili R,Cifani S,Principi E,et a1.A Robust Terativee Inverse Filtering Approch for Speech Dereverberation in Presence of Disturbances[J].IEEE,2008:28.
[7] 廖启鹏,孔荣.基于最小相位分解的语音去混响[J].通信技术,2011,44(06):78-82. LIAO Qi-peng,KONG Rong.Dereverberation based on Minimum Phase Decomposition[J].Communications Technology,2011,44(06):78-82.
[8] 易克初,田斌,付强.语音信号处理[M].北京:国防工业出版社,2000:83-118. YI Ke-chu,TIAN Bin,FU Qiang.Speech Signal Processing[M].Beijing:National Defence Industry Press,2000:83-118.

牛莉莉(1991—),女,硕士研究生,主要研究方向为语音信号处理;
徐 岩(1963—),男,硕士,教授,主要研究方向为语音信号处理、自适应信号处理。
A Modified Method based on Wiener Filtering for Dereverberation
NIU Li-li, XU Yan
(School of Electronic and Information Engineering , Lanzhou Jiaotong University, Lanzhou Gansu 730070, China)
In order to resolve the different effects on different frequency components of speech signal by reverberation, the formerly proposed dereverberation method based on wiener filtering is modified. According to the human auditory perception characteristics, the Gammatone auditory filters are introduced, thus to implement the sub-band processing of reverberation speech and independent dereverberation in various sub-bands, and this reflects the difference of speech frequency band information.Both the subjective and objective evaluation indexes are applied to evaluating analyzing the consequences of experimental simulation. The method described in the paper,as compared with complex cepstrum domain filtering and Wiener filtering, could gain much better dereverberation effect.
Gammatone auditory filters; dereverberation; Wiener filtering;evaluation indicator
Research of speech signal enhancement technology based on the safety and protection system of Labrang Monastery in south of Gansu
TN912
A
1002-0802(2016)-08-01001-05
10.3969/j.issn.1002-0802.2016.08.009
2016-04-21;
2016-07-22
date:2016-04-21;Revised date:2016-07-22
基于甘南拉卜楞寺安全防范系统的语音信号增强技术研究
猜你喜欢
信号处理(2022年4期)2022-05-13
空间电子技术(2021年4期)2021-11-10
电子制作(2019年22期)2020-01-14
舰船电子对抗(2019年4期)2019-09-10
太原科技大学学报(2019年3期)2019-08-05
雷达科学与技术(2018年6期)2019-01-07
舰船电子工程(2018年11期)2018-11-26
剧作家(2018年2期)2018-09-10
哈尔滨理工大学学报(2018年6期)2018-02-13
计算机应用与软件(2017年3期)2017-04-14
